原文:《Fast, Scalable, Streaming AJAX Proxy - continuously deliver data from across domains》
作者:
Omar Al Zabir
URL:
http://www.codeproject.com/KB/ajax/ajaxproxy.aspx
Introduction
Due to browsers' prohibition on cross domain XMLHTTP calls, all AJAX websites must have a server side proxy to fetch content from external domains like Flickr or Digg. From the client-side JavaScript code, an XMLHTTP call goes to the server-side proxy hosted on the same domain, and then the proxy downloads the content from the external server and sends back to the browser. In general, all AJAX websites on the Internet that are showing content from external domains are following this proxy approach, except for some rare ones who are using JSONP. Such a proxy gets a very large number of hits when a lot of components on the website are downloading content from external domains. So, it becomes a scalability issue when the proxy starts getting millions of hits. Moreover, a web page's overall load performance largely depends on the performance of the proxy as it delivers content to the page. In this article, we will take a look at how we can take a conventional AJAX Proxy and make it faster, asynchronous, continuously stream content, and thus make it more scalable.
AJAX Proxy in Action
You can see such a proxy in action when you go to
Pageflakes.com
. You will see flakes (widgets) loading many different content like weather feed, flickr photo, YouTube videos, and RSS from many different external domains. All these are done via a
Content Proxy
. The Content Proxy served about
42.3 million URLs
last month, which is quite an engineering challenge for us to make it both fast and scalable. Sometimes the Content Proxy serves megabytes of data, which poses an even greater engineering challenge. As such, the proxy gets a large number of hits; if we can save on an average of 100ms from each call, we can save
4.23 million seconds
of download/upload/processing time every month. That's about 1175 man hours wasted throughout the world by millions of people staring at a browser waiting for content to download.
Such a content proxy takes an external server's URL as a query parameter. It downloads the content from the URL, and then writes the content as the response back to the browser.
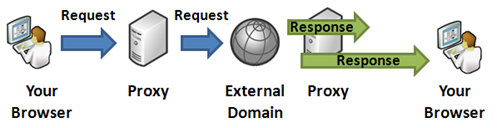
Figure: Content proxy working as a middleman between the browser and the external domain
The above timeline shows how a request goes to the server and then the server makes a request to the external server, downloads the response, and then transmits it back to the browser. The response arrow from the proxy to the browser is larger than the response arrow from the external server to the proxy because generally, a proxy server's hosting environment has a better download speed than the user's Internet connectivity.
A Basic Proxy
Such a content proxy is also available in my open source AJAX Web Portal,
Dropthings.com
. You can see from
its code from CodePlex
how such a proxy is implemented.
The following is a very simple, synchronous, non-streaming, blocking proxy:
 Collapse
Collapse[WebMethod]
[ScriptMethod(UseHttpGet=true)]
public string GetString(string url)
{
using (WebClient client = new WebClient())
{
string response = client.DownloadString(url);
return response;
}
}
}
Although it shows the general principle, it's no where close to a real proxy, because:
- It's a synchronous proxy and thus not scalable. Every call to this web method causes the ASP.NET thread to wait until the call to the external URL completes.
- It's
non streaming
. It first downloads the entire content on the server, storing it in a string and then uploading that entire content to the browser. If you pass an
MSDN feed URL
, it will download that gigantic 220 KB RSS XML on the server and store it on a 220 KB long string (actually, double the size as .NET strings are all Unicode), and then write the 220 KB to an ASP.NET Response buffer, consuming another 220 KB UTF8 byte array in memory. Then, that 220 KB will be passed to IIS in chunks so that it can transmit it to the browser.
- It does not produce a proper response header to cache the response on the server. Nor does it deliver important headers like
Content-Type
from the source.
- If an external URL is providing gzipped content, it decompresses the content into a string representation and thus wastes server memory.
- It does not cache the content on the server. So, repeated calls to the same external URL within the same second or minute will download content from the external URL and thus waste bandwidth on your server.
We need an asynchronous
streaming proxy
that transmits the content to the browser while it downloads from the external domain server. So, it will download bytes from the external URL in small chunks and immediately transmit that to the browser. As a result, the browser will see a continuous transmission of bytes right after calling the web service. There will be no delay while the content is fully downloaded on the server.
A Better Proxy
Before I show you the complex streaming proxy code, let's take an evolutionary approach. Let's build a better Content Proxy than the one shown above, which is synchronous and non-streaming, but does not have the other problems mentioned above. We will build an HTTP Handler named
RegularProxy.ashx
which will take a URL as a query parameter. It will also take a cache as a query parameter which it will use to produce proper response headers in order to cache the content on the browser. Thus, it will save the browser from downloading the same content again and again.
Collapse using System;
using System.Web;
using System.Web.Caching;
using System.Net;
using ProxyHelpers;
public class RegularProxy : IHttpHandler {
public void ProcessRequest (HttpContext context) {
string url = context.Request["url"];
int cacheDuration = Convert.ToInt32(context.Request["cache"]?? "0");
string contentType = context.Request["type"];
context.Response.Buffer = false;
if (context.Cache[url] != null)
{
context.Response.BinaryWrite(context.Cache[url] as byte[]);
context.Response.Flush();
return;
}
using (WebClient client = new WebClient())
{
if (!string.IsNullOrEmpty(contentType))
client.Headers["Content-Type"] = contentType;
client.Headers["Accept-Encoding"] = "gzip";
client.Headers["Accept"] = "*/*";
client.Headers["Accept-Language"] = "en-US";
client.Headers["User-Agent"] =
"Mozilla/5.0 (Windows; U; Windows NT 6.0; " +
"en-US; rv:1.8.1.6) Gecko/20070725 Firefox/2.0.0.6";
byte[] data = client.DownloadData(url);
context.Cache.Insert(url, data, null,
Cache.NoAbsoluteExpiration,
TimeSpan.FromMinutes(cacheDuration),
CacheItemPriority.Normal, null);
if (!context.Response.IsClientConnected) return;
context.Response.ContentType =
client.ResponseHeaders["Content-Type"];
string contentEncoding =
client.ResponseHeaders["Content-Encoding"];
string contentLength =
client.ResponseHeaders["Content-Length"];
if (!string.IsNullOrEmpty(contentEncoding))
context.Response.AppendHeader("Content-Encoding",
contentEncoding);
if (!string.IsNullOrEmpty(contentLength))
context.Response.AppendHeader("Content-Length",
contentLength);
if (cacheDuration > 0)
HttpHelper.CacheResponse(context, cacheDuration);
context.Response.BinaryWrite(data);
}
}
public bool IsReusable {
get {
return false;
}
}
}
There are two enhancements in this proxy:
- It allows server side caching of content. The same URL requested by a different browser within a time period will not be downloaded on the server again, instead it will be served from a cache.
- It generates a proper response cache header so that the content can be cached on the browser.
- It does not decompress the downloaded content in memory. It keeps the original byte stream intact. This saves memory allocation.
- It transmits the data in a non-buffered fashion, which means the ASP.NET
Response
object does not buffer the response and thus saves memory.
However, this is a blocking proxy.
Even Better Proxy - Stream!
We need to make a streaming asynchronous proxy for better performance. Here's why:
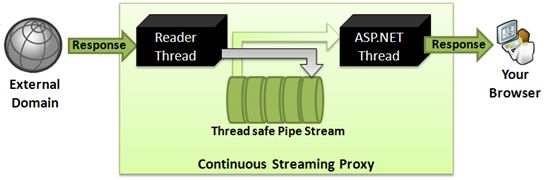
Figure: Continuous streaming proxy
As you see, when data is transmitted from the server to the browser while the server downloads the content, the delay for the server-side download is eliminated. So, if the server takes 300ms to download something from an external source, and then 700ms to send it back to the browser, you can save up to 300ms Network Latency between the server and the browser. The situation gets even better when the external server that serves the content is slow and takes quite some time to deliver the content. The slower the external site is, the more saving you get in this continuous streaming approach. This is significantly faster than the blocking approach when the external server is in Asia or Australia and your server is in the USA.
The approach for a continuous proxy is:
- Read bytes from the external server in chunks of 8KB from a separate thread (reader thread) so that it's not blocked.
- Store the chunks in an in-memory Queue called Pipe Stream.
- Write the chunks to ASP.NET Response from that same queue.
- If the queue is finished, wait until more bytes are downloaded by the reader thread.
The Pipe Stream needs to be thread-safe, and it needs to support blocking-read. By blocking-read, it means, if a thread tries to read a chunk from it and the stream is empty, it will suspend that thread until another thread writes something on the stream. Once a write happens, it will resume the reader thread and allow it to read. I have taken the code of
PipeStream
from the
CodeProject article by James Kolpack
and extended it to make sure it has high performance, supports chunks of bytes to be stored instead of single bytes, supports timeout on waits, and so on.
I did some comparison between a regular proxy (blocking, synchronous, download all then deliver) and a streaming proxy (continuous transmission from the external server to the browser). Both proxy downloads the MSDN feed and delivers it to the browser. The time taken here shows the total duration of the browser making the request to the proxy and then getting the entire response:
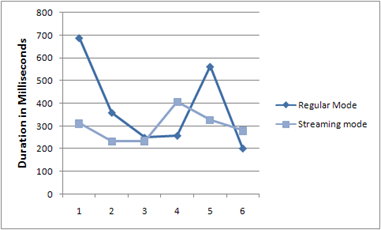
Figure: Time taken by a streaming proxy vs. a regular proxy while downloading the MSDN feed
Not a very scientific graph, and the response time varies on the link speed between the browser and the proxy server and then from the proxy server to the external server. But, it shows that most of the time, the streaming proxy outperformed the regular proxy.
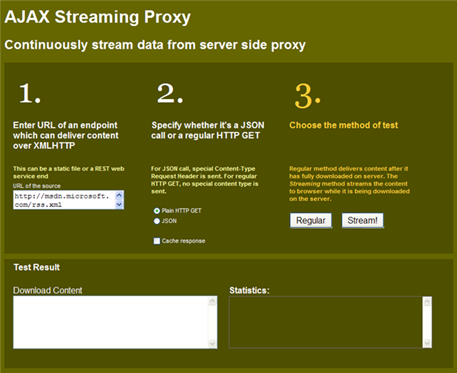
Figure: Test client to compare between a regular proxy and a streaming proxy
You can also test both proxy's response times by going to
this link
. Put your URL and hit Regular/Stream button, and see the "Statistics" text box for the total duration. You can turn on "Cache response" and hit a URL from one browser. Then, go to another browser and hit the URL to see the response coming from the server cache directly. Also, if you hit the URL again on the same browser, you will see that the response comes instantly without ever making a call to the server. That's browser cache at work.
Learn more about HTTP Response caching from my blog post:
Making the best use of cache for high performance websites
.
A Visual Studio Web Test run inside a Load Test shows a better picture:
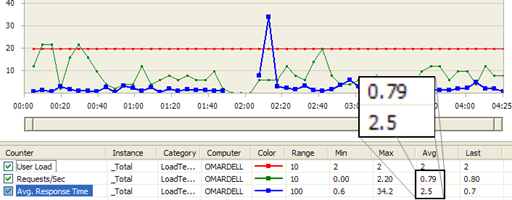
Figure: Regular proxy load test result shows
Average Requests/Sec is 0.79
and
Average Response Time 2.5 sec
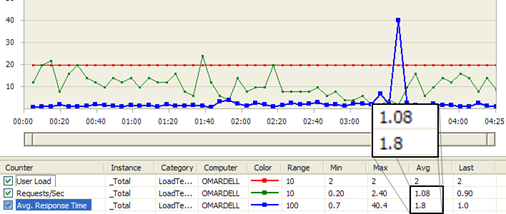
Figure: Streaming proxy load test result shows
Average Requests/Sec is 1.08
and
Average Response Time 1.8 sec
.
From the above load test results, the streaming proxy has
26% better Requests/Sec, and the Average Response Time is 29% better
. The numbers may sound small, but at
Pageflakes
, 29% better response time means
1.29 million seconds
saved per month for all the users on the website. So, we are effectively saving 353 man hours per month, which was wasted staring at the browser screen while it downloads content.
Building the streaming proxy
It was not straightforward to build a streaming proxy that can outperform a regular proxy. I tried three ways to finally find the optimal combination that can outperform a regular proxy.
The streaming proxy uses
HttpWebRequest
and
HttpWebResponse
to download data from an external server. They are used to gain more control over how data is read, more specifically, read in chunks of bytes that
WebClient
does not offer. Moreover, there's some optimization in building a fast scalable
HttpWebRequest
that this proxy requires.
Collapse public class SteamingProxy : IHttpHandler
{
const int BUFFER_SIZE = 8 * 1024;
private Utility.PipeStream _PipeStream;
private Stream _ResponseStream;
public void ProcessRequest (HttpContext context)
{
string url = context.Request["url"];
int cacheDuration = Convert.ToInt32(context.Request["cache"] ?? "0");
string contentType = context.Request["type"];
if (cacheDuration > 0)
{
if (context.Cache[url] != null)
{
CachedContent content = context.Cache[url] as CachedContent;
if (!string.IsNullOrEmpty(content.ContentEncoding))
context.Response.AppendHeader("Content-Encoding",
content.ContentEncoding);
if (!string.IsNullOrEmpty(content.ContentLength))
context.Response.AppendHeader("Content-Length",
content.ContentLength);
context.Response.ContentType = content.ContentType;
content.Content.Position = 0;
content.Content.WriteTo(context.Response.OutputStream);
}
}
HttpWebRequest request =
HttpHelper.CreateScalableHttpWebRequest(url);
request.AutomaticDecompression = DecompressionMethods.None;
if (!string.IsNullOrEmpty(contentType))
request.ContentType = contentType;
using (new TimedLog("StreamingProxy\tTotal " +
"GetResponse and transmit data"))
using (HttpWebResponse response =
request.GetResponse() as HttpWebResponse)
{
this.DownloadData(request, response, context, cacheDuration);
}
}
The
DownloadData
method downloads data from the response stream (connected to the external server) and then delivers it to the ASP.NET
Response
stream.
Collapse private void DownloadData(HttpWebRequest request, HttpWebResponse response,
HttpContext context, int cacheDuration)
{
MemoryStream responseBuffer = new MemoryStream();
context.Response.Buffer = false;
try
{
if (response.StatusCode != HttpStatusCode.OK)
{
context.Response.StatusCode = (int)response.StatusCode;
return;
}
using (Stream readStream = response.GetResponseStream())
{
if (context.Response.IsClientConnected)
{
string contentLength = string.Empty;
string contentEncoding = string.Empty;
ProduceResponseHeader(response, context, cacheDuration,
out contentLength, out contentEncoding);
int totalBytesWritten = TransmitDataAsyncOptimized(context,
readStream, responseBuffer);
if (cacheDuration > 0)
{
#region Cache Response in memory
CachedContent cache = new CachedContent();
cache.Content = responseBuffer;
cache.ContentEncoding = contentEncoding;
cache.ContentLength = contentLength;
cache.ContentType = response.ContentType;
context.Cache.Insert(request.RequestUri.ToString(),
cache, null, Cache.NoAbsoluteExpiration,
TimeSpan.FromMinutes(cacheDuration),
CacheItemPriority.Normal, null);
#endregion
}
}
context.Response.Flush();
}
}
catch (Exception x)
{
Log.WriteLine(x.ToString());
request.Abort();
}
}
Here, I have tried three different approaches. The one that's uncommented now, called
TransmitDataAsyncOptimized
, is the best approach. I will explain all the three approaches soon. The purpose of the
DownloadData
function is to prepare the ASP.NET Response stream before sending data. Then, it sends the data using one of the three approaches and caches the downloaded bytes in a memory stream.
The first approach was to read 8192 bytes from the response stream that's connected to the external server and then immediately write it to the response (
TransmitDataInChunks
).
Collapse private int TransmitDataInChunks(HttpContext context, Stream readStream,
MemoryStream responseBuffer)
{
byte[] buffer = new byte[BUFFER_SIZE];
int bytesRead;
int totalBytesWritten = 0;
while ((bytesRead = readStream.Read(buffer, 0, BUFFER_SIZE)) > 0)
{
context.Response.OutputStream.Write(buffer, 0, bytesRead);
responseBuffer.Write(buffer, 0, bytesRead);
totalBytesWritten += bytesRead;
}
return totalBytesWritten;
}
Here,
readStream
is the response stream received from the
HttpWebResponse.GetResponseStream
call. It's downloading from the external server.
responseBuffer
is just a memory stream to hold the entire response in memory so that we can cache it.
This approach was even slower than a regular proxy. After doing some code level performance profiling, it looks like writing to
OutputStream
takes quite some time as IIS tries to send the bytes to the browser. So, there was the delay of network latency + the time taken to transmit a chunk. The cumulative network latency from frequent calls to
OutputStream.Write
added significant delay to the total operation.
The second approach was to try multithreading. A new thread launched from the ASP.NET thread continuously reads from
Socket
without ever waiting for the
Response.OutputStream
that sends the bytes to the browser. The main ASP.NET thread waits until bytes are collected, and then transmits them to the response immediately.
Collapse private int TransmitDataAsync(HttpContext context, Stream readStream,
MemoryStream responseBuffer)
{
this._ResponseStream = readStream;
_PipeStream = new Utility.PipeStreamBlock(5000);
byte[] buffer = new byte[BUFFER_SIZE];
Thread readerThread = new Thread(new ThreadStart(this.ReadData));
readerThread.Start();
int totalBytesWritten = 0;
int dataReceived;
while ((dataReceived = this._PipeStream.Read(buffer, 0, BUFFER_SIZE)) > 0)
{
context.Response.OutputStream.Write(buffer, 0, dataReceived);
responseBuffer.Write(buffer, 0, dataReceived);
totalBytesWritten += dataReceived;
}
_PipeStream.Dispose();
return totalBytesWritten;
}
Here, the read is performed on the
PipeStream
instead of the socket from the ASP.NET thread. There's a new thread spawned which writes data to
PipeStream
as it downloads bytes from the external site. As a result, we have the ASP.NET thread writing data to
OutputStream
continuously, and there's another thread that's downloading data from the external server uninterrupted. The following code downloads data from the external server and then stores in the
PipeStream
.
Collapse private void ReadData()
{
byte[] buffer = new byte[BUFFER_SIZE];
int dataReceived;
int totalBytesFromSocket = 0;
try
{
while ((dataReceived = this._ResponseStream.Read(buffer, 0,
BUFFER_SIZE)) > 0)
{
this._PipeStream.Write(buffer, 0, dataReceived);
totalBytesFromSocket += dataReceived;
}
}
catch (Exception x)
{
Log.WriteLine(x.ToString());
}
finally
{
this._ResponseStream.Dispose();
this._PipeStream.Flush();
}
}
The problem with this approach is that, there are still too many
Response.OutputStream.Write
calls happening. The external server delivers content in variable number of bytes, sometimes 3592 bytes, sometimes 8192 bytes, and sometimes only 501 bytes. It all depends on how fast the connectivity from your server to the external server is. Generally, Microsoft servers are only a door step away, so you almost always get 8192 (the buffer max size) bytes when you call
_ResponseStream.Read
while reading from the MSDN feed. But, when you are talking to a non-reliable server, say in Australia, you will not get 8192 bytes per read call all the time. So, you will end up making more
Response.OutputStream.Write
s than you should. So, a better and the final approach is to introduce another buffer which will hold the bytes being written to the ASP.NET
Response
and flush itself to
Respose.OutputStream
as soon as 8192 bytes are ready to be delivered. This intermediate buffer will ensure that always 8192 bytes are delivered to the
Response.OutputStream
.
Collapse private int TransmitDataAsyncOptimized(HttpContext context, Stream readStream,
MemoryStream responseBuffer)
{
this._ResponseStream = readStream;
_PipeStream = new Utility.PipeStreamBlock(10000);
byte[] buffer = new byte[BUFFER_SIZE];
Thread readerThread = new Thread(new ThreadStart(this.ReadData));
readerThread.Start();
int totalBytesWritten = 0;
int dataReceived;
byte[] outputBuffer = new byte[BUFFER_SIZE];
int responseBufferPos = 0;
while ((dataReceived = this._PipeStream.Read(buffer, 0, BUFFER_SIZE)) > 0)
{
int bufferSpaceLeft = BUFFER_SIZE - responseBufferPos;
if (bufferSpaceLeft < dataReceived)
{
Buffer.BlockCopy(buffer, 0, outputBuffer,
responseBufferPos, bufferSpaceLeft);
context.Response.OutputStream.Write(outputBuffer, 0, BUFFER_SIZE);
responseBuffer.Write(outputBuffer, 0, BUFFER_SIZE);
totalBytesWritten += BUFFER_SIZE;
responseBufferPos = 0;
int bytesLeftOver = dataReceived - bufferSpaceLeft;
Buffer.BlockCopy(buffer, bufferSpaceLeft,
outputBuffer, 0, bytesLeftOver);
responseBufferPos = bytesLeftOver;
}
else
{
Buffer.BlockCopy(buffer, 0, outputBuffer,
responseBufferPos, dataReceived);
responseBufferPos += dataReceived;
}
}
if (responseBufferPos > 0)
{
context.Response.OutputStream.Write(outputBuffer, 0, responseBufferPos);
responseBuffer.Write(outputBuffer, 0, responseBufferPos);
totalBytesWritten += responseBufferPos;
}
_PipeStream.Dispose();
return totalBytesWritten;
}
The above method ensures only 8192 bytes are written at a time to the ASP.NET Response Stream. This way, the total number of times the response is written is (total bytes read/8192).
Streaming proxy with asynchronous HTTP handler
Now that we are streaming the bytes, we need to make this proxy asynchronous so that it does not hold the main ASP.NET thread for too long. Being asynchronous means it will release the ASP.NET thread as soon as it makes a call to the external server. When the external server call completes and bytes are available for download, it will grab a thread from the ASP.NET thread pool and complete the execution.
When the proxy is not asynchronous, it keeps the ASP.NET thread busy until the entire connect and download operation completes. If the external server is slow to respond to, it's unnecessarily holding the ASP.NET thread for too long. As a result, if the proxy is getting too many requests to the slow server, ASP.NET threads will soon get exhausted and your server will stop responding to any new request. Users hitting any part of your website on that server will get no response from it. We had such a problem at Pageflakes. We were requesting data from a Stock Quote web service. The web service was taking more than 60 seconds to respond to the call. As we did not have asynchronous handlers back then, our Content Proxy was taking up all the ASP.NET threads from the thread pool and our site was not responding. We were restarting IIS every 10 minutes to get around this problem for a couple of days until the Stock Quote web service fixed itself.
Making an asynchronous HTTP handler is not so easy to understand.
This MSDN article
tries to explain it, but it's hard to understand the concept fully from this article. So, I have written an entire chapter on my book, "
Building a Web 2.0 portal using ASP.NET 3.5
", that explains how an asynchronous handler is built. From my experience, I have seen most people are confused when to use it. So, I have shown three specific scenarios where async handlers are useful. I also explained several other scalability issues with such a content proxy that you will find interesting to read. Especially, several ingenious hacking attempts to bring a website down by exploiting the Content Proxy and how to defend them.
The first step is to implement the
IHttpAsyncHandler
and break the
ProcessRequest
function's code into two parts -
BeginProcessRequest
and
EndProcessRequest
. The Begin method will make an asynchronous call to
HttpWebRequest.BeginGetResponse
and return the thread back to the ASP.NET thread pool.
Collapse public IAsyncResult BeginProcessRequest(HttpContext context, AsyncCallback cb,
object extraData)
{
string url = context.Request["url"];
int cacheDuration = Convert.ToInt32(context.Request["cache"] ?? "0");
string contentType = context.Request["type"];
if (cacheDuration > 0)
{
if (context.Cache[url] != null)
{
SyncResult result = new SyncResult();
result.Context = context;
result.Content = context.Cache[url] as CachedContent;
return result;
}
}
HttpWebRequest request = HttpHelper.CreateScalableHttpWebRequest(url);
request.AutomaticDecompression = DecompressionMethods.None;
if (!string.IsNullOrEmpty(contentType))
request.ContentType = contentType;
AsyncState state = new AsyncState();
state.Context = context;
state.Url = url;
state.CacheDuration = cacheDuration;
state.Request = request;
return request.BeginGetResponse(cb, state);
}
When the
BeginGetResponse
call completes and the external server has started sending us the response bytes, ASP.NET calls the
EndProcessRequest
method. This method downloads the bytes from the external server and then delivers it back to the browser.
Collapse public void EndProcessRequest(IAsyncResult result)
{
if (result.CompletedSynchronously)
{
SyncResult syncResult = result as SyncResult;
syncResult.Context.Response.ContentType =
syncResult.Content.ContentType;
syncResult.Context.Response.AppendHeader("Content-Encoding",
syncResult.Content.ContentEncoding);
syncResult.Context.Response.AppendHeader("Content-Length",
syncResult.Content.ContentLength);
syncResult.Content.Content.Seek(0, SeekOrigin.Begin);
syncResult.Content.Content.WriteTo(
syncResult.Context.Response.OutputStream);
}
else
{
AsyncState state = result.AsyncState as AsyncState;
state.Context.Response.Buffer = false;
HttpWebRequest request = state.Request;
using (HttpWebResponse response =
request.EndGetResponse(result) as HttpWebResponse)
{
this.DownloadData(request, response, state.Context, state.CacheDuration);
}
}
}
There you have it. A fast, scalable, continuous AJAX streaming proxy that can always outperform any regular AJAX proxy out their on the web.
In case you are wondering what are the
HttpHelper
,
AsyncState
, and
SyncResult
classes, they are some helper classes. Here's the code for these helper classes:
Collapse public static class HttpHelper
{
public static HttpWebRequest CreateScalableHttpWebRequest(string url)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
request.Headers.Add("Accept-Encoding", "gzip");
request.AutomaticDecompression = DecompressionMethods.GZip;
request.MaximumAutomaticRedirections = 2;
request.ReadWriteTimeout = 5000;
request.Timeout = 3000;
request.Accept = "*/*";
request.Headers.Add("Accept-Language", "en-US");
request.UserAgent = "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US;" +
"rv:1.8.1.6) Gecko/20070725 Firefox/2.0.0.6";
return request;
}
public static void CacheResponse(HttpContext context,
int durationInMinutes)
{
TimeSpan duration = TimeSpan.FromMinutes(durationInMinutes);
context.Response.Cache.SetCacheability(HttpCacheability.Public);
context.Response.Cache.SetExpires(DateTime.Now.Add(duration));
context.Response.Cache.
AppendCacheExtension("must-revalidate, proxy-revalidate");
context.Response.Cache.SetMaxAge(duration);
}
public static void DoNotCacheResponse(HttpContext context)
{
context.Response.Cache.SetNoServerCaching();
context.Response.Cache.SetNoStore();
context.Response.Cache.SetMaxAge(TimeSpan.Zero);
context.Response.Cache.
AppendCacheExtension("must-revalidate, proxy-revalidate");
context.Response.Cache.SetExpires(DateTime.Now.AddYears(-1));
}
}
public class CachedContent
{
public string ContentType;
public string ContentEncoding;
public string ContentLength;
public MemoryStream Content;
}
public class AsyncState
{
public HttpContext Context;
public string Url;
public int CacheDuration;
public HttpWebRequest Request;
}
public class SyncResult : IAsyncResult
{
public CachedContent Content;
public HttpContext Context;
#region IAsyncResult Members
object IAsyncResult.AsyncState
{
get { return new object(); }
}
WaitHandle IAsyncResult.AsyncWaitHandle
{
get { return new ManualResetEvent(true); }
}
bool IAsyncResult.CompletedSynchronously
{
get { return true; }
}
bool IAsyncResult.IsCompleted
{
get { return true; }
}
#endregion
}
That's all folks.
Conclusion
Well, you have a faster and more scalable AJAX proxy than anyone else out there. So, feel really good about it :)















