扫码登录认证技术原理介绍及实践
一、背景
最近业务要求PC端系统登录使用APP应用扫码登录。
主要目的是:
1、简化用户录入账号密码,达到快速登录PC;
2、账号登录使用更加安全性;
3、为了推广更多让大家打开使用APP(因为行业的特殊性,实际业务场景中大都设计师都在使用PC端设计软件,同时也习惯了PC端下单)。
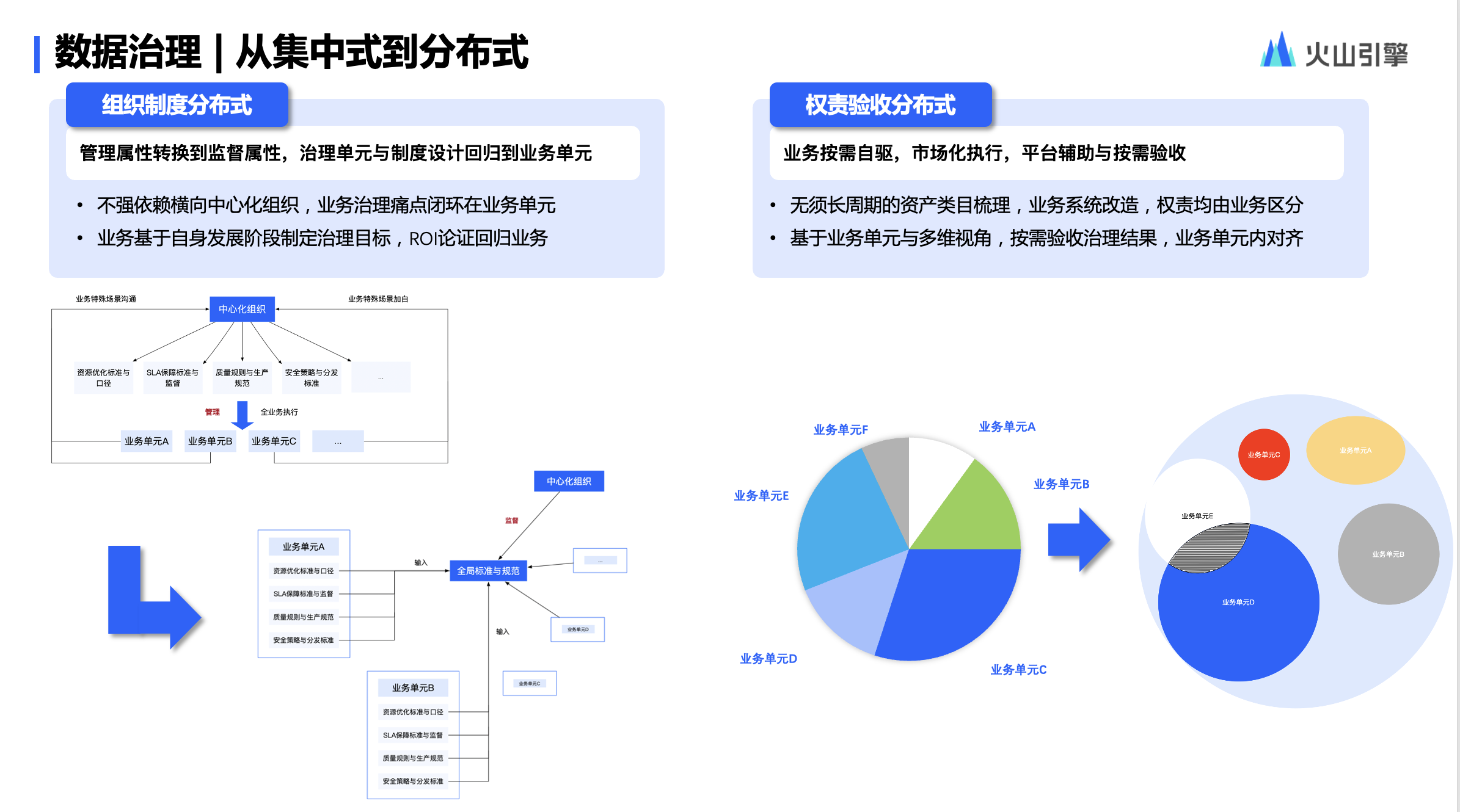
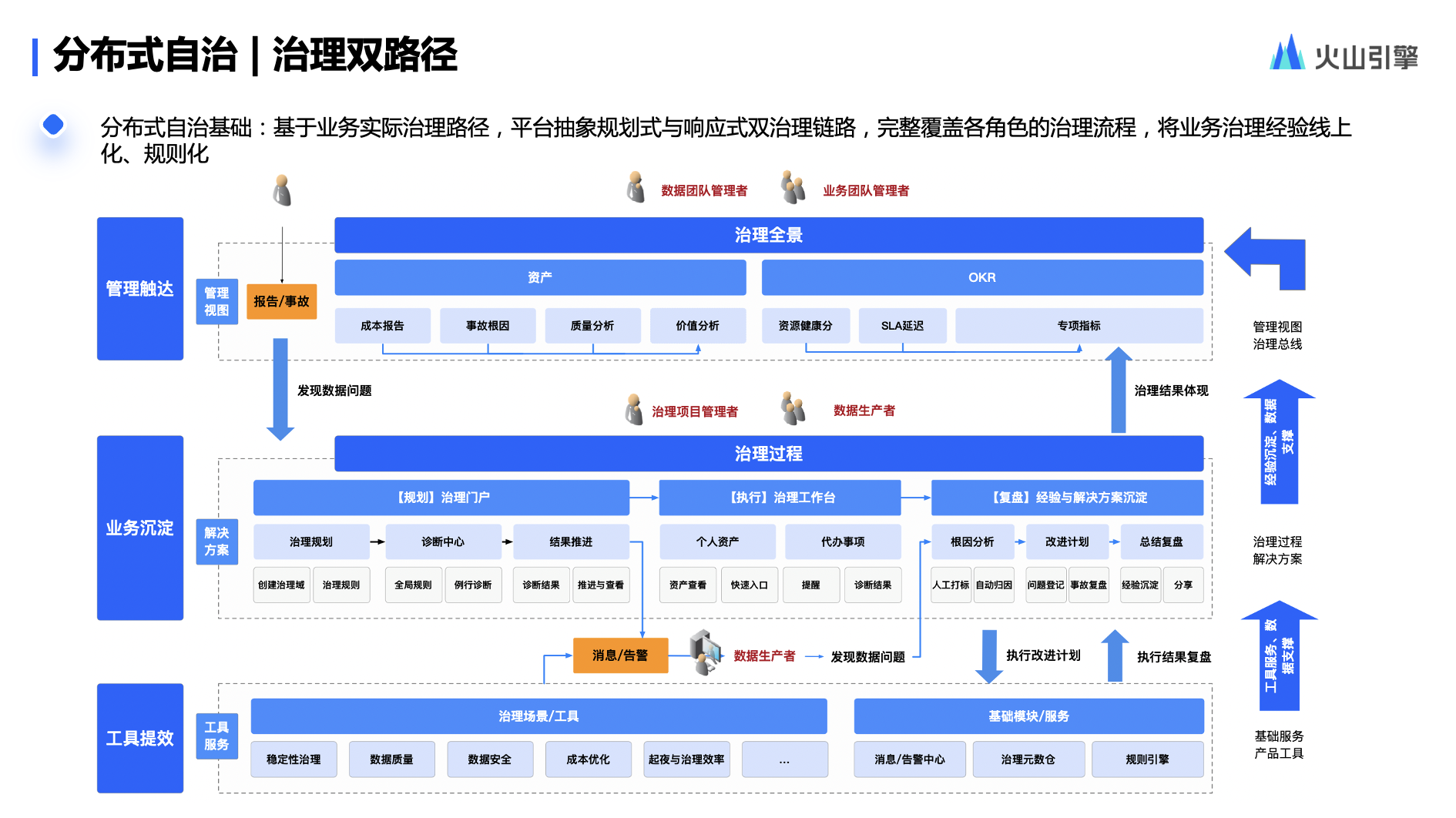
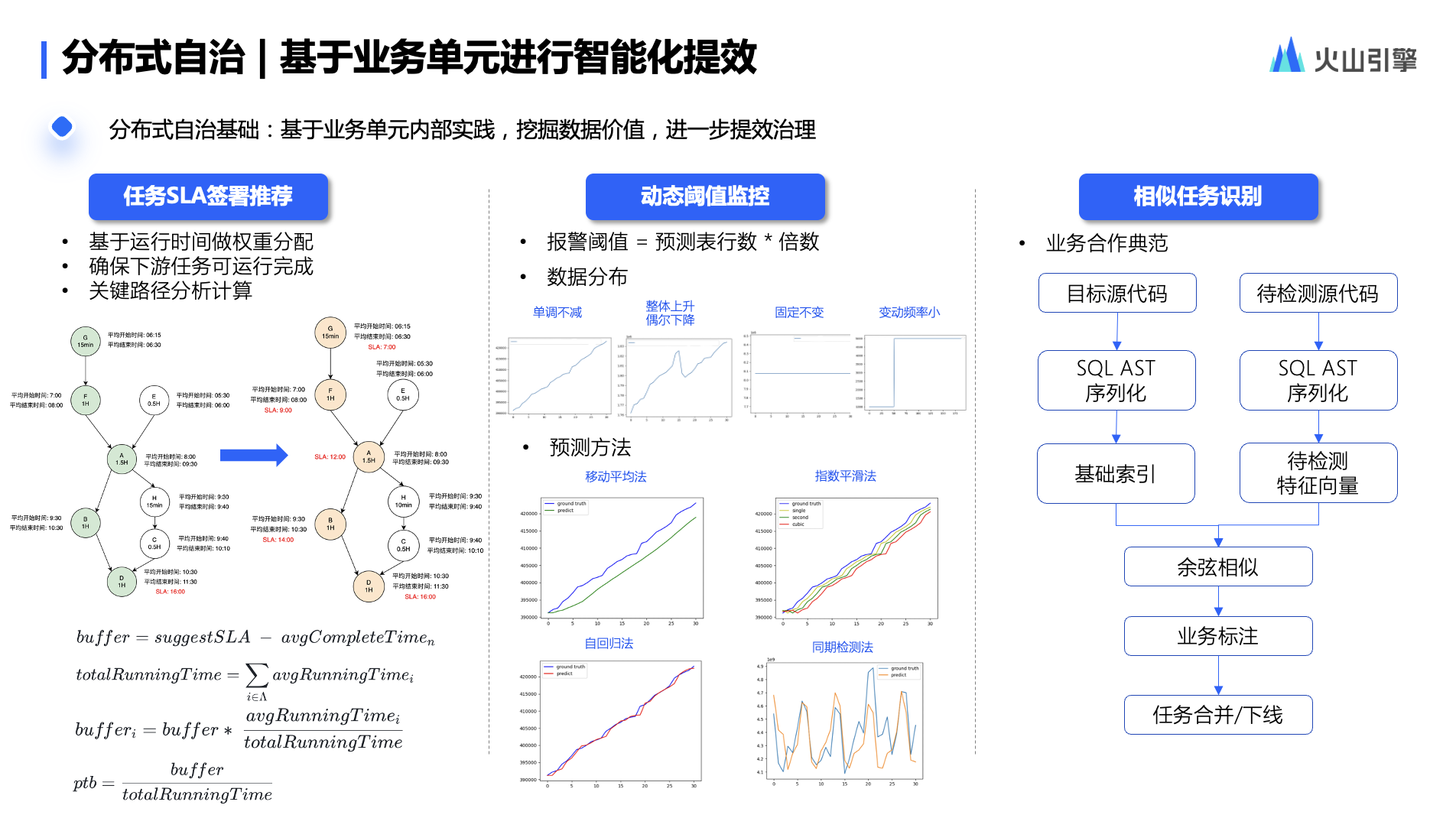
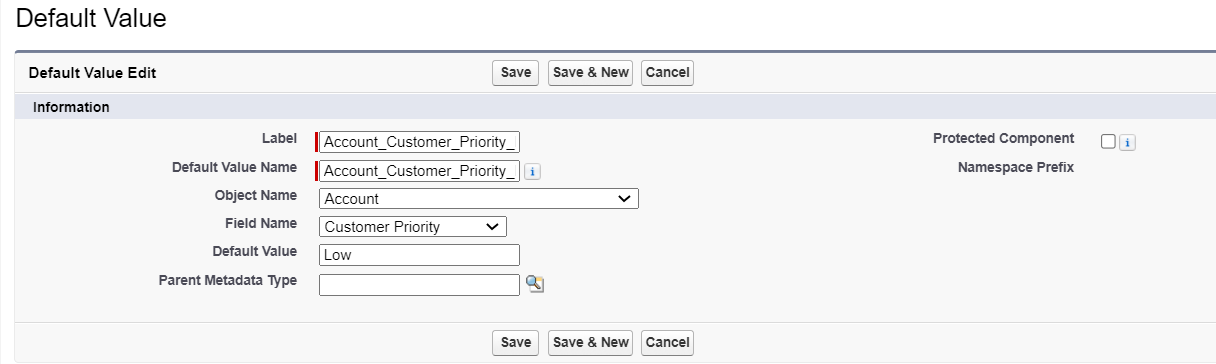
二、处理流程
1、业务流程图

因为扫码的时候有两种处理逻辑,所以流程图有业务处理方案。但不管哪种方案,背后技术处理逻辑是一样的。
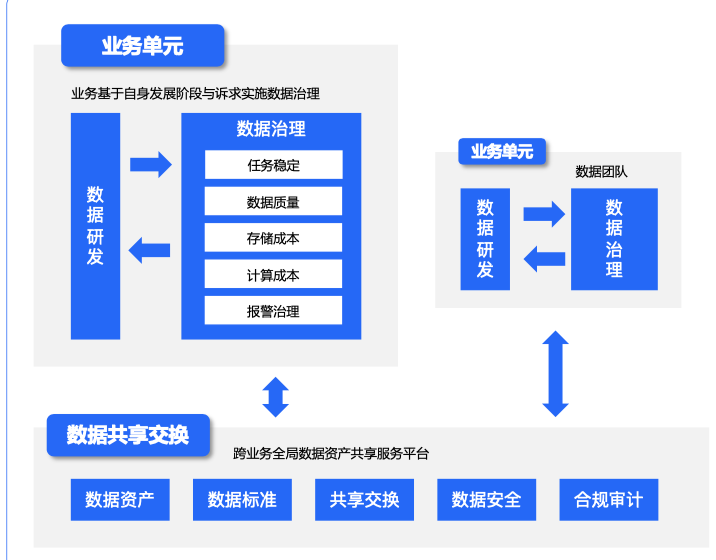
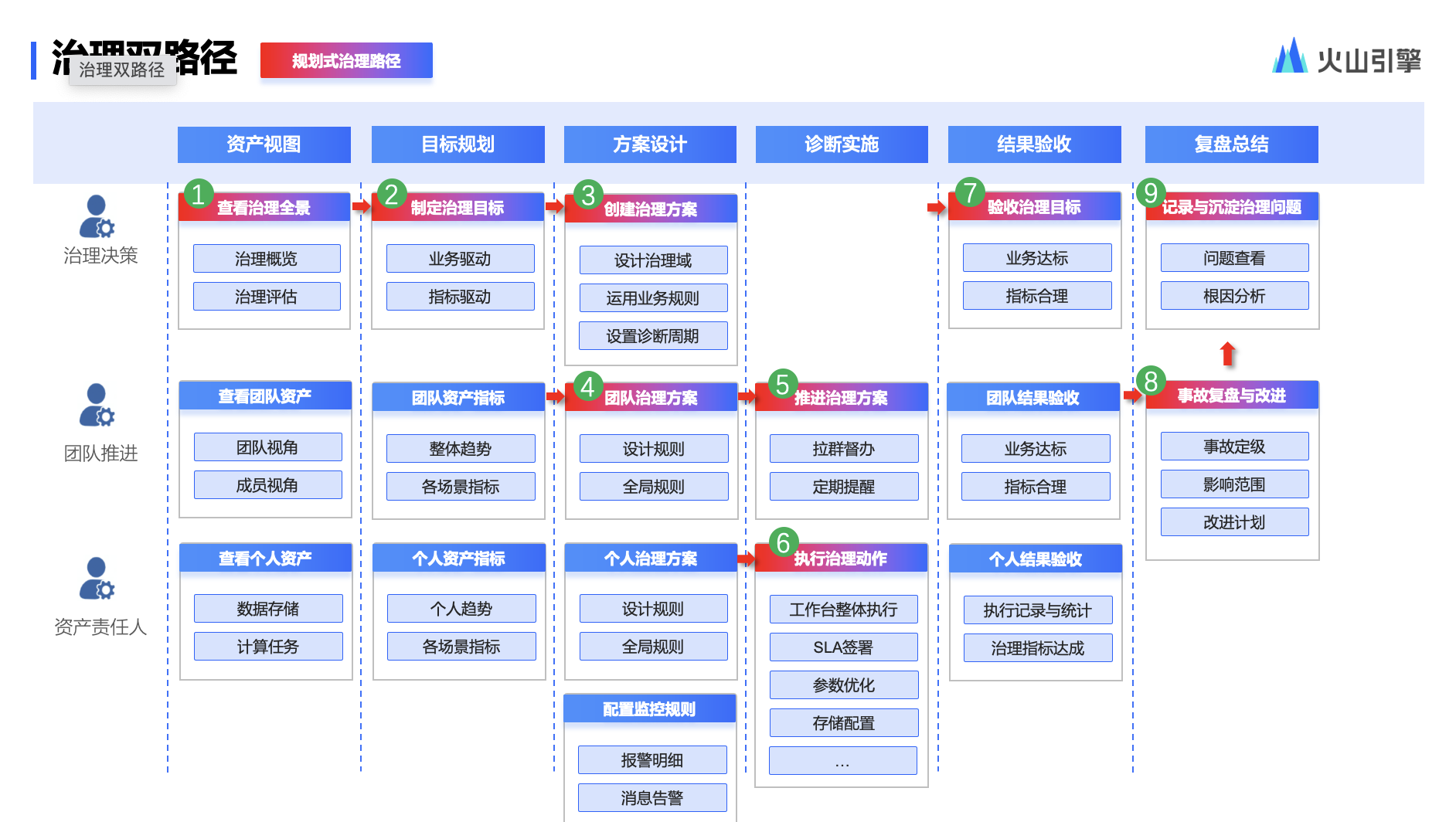
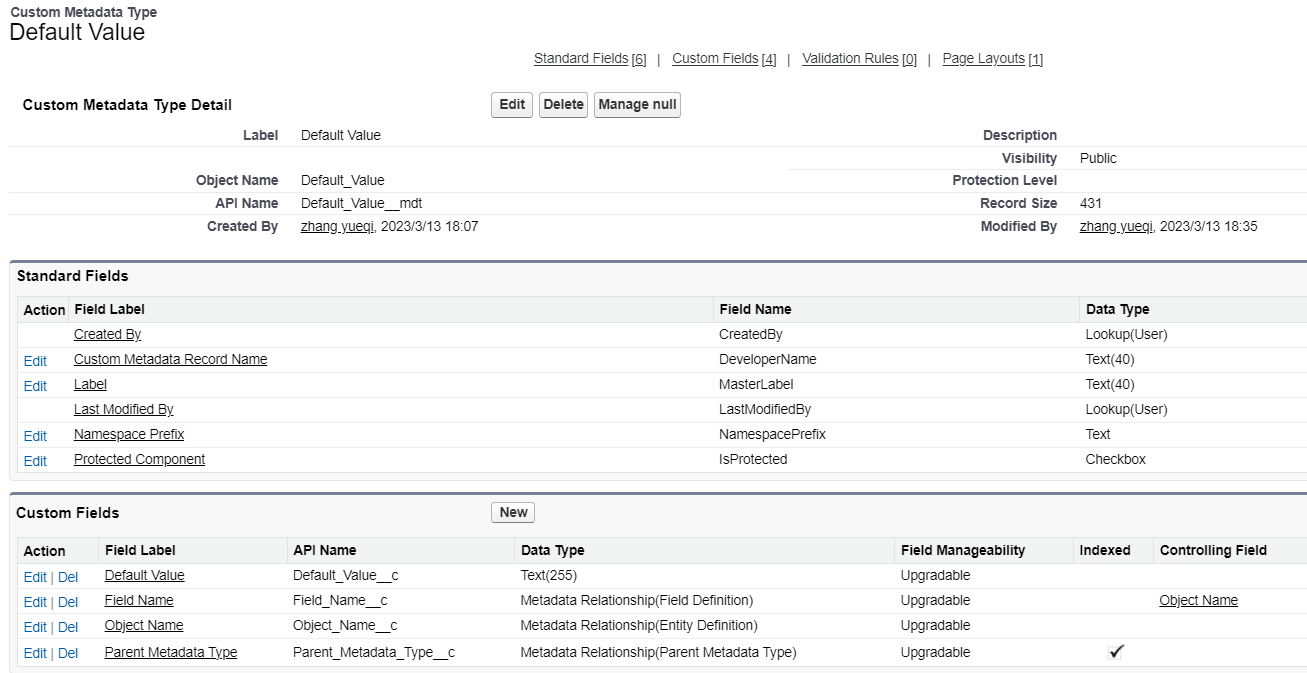
2、技术实现设计流图程

3、处理步骤说明
a、用户打开PC登录页面,PC登录页面向认证中心发起请求,认证中心生成uuid等信息,返回uuid等信息给前端,前端展示一个包含uuid的二维码。
b、PC端登录页面定时向认证中心轮询二维码的状态。
c、用户登录移动端,打开移动端摄像头扫描PC端登录页面的二维码。
d、移动端将二维码中包含的uuid等信息发送给认证中心,认证中心将二维码状态设置为“扫描成功”。
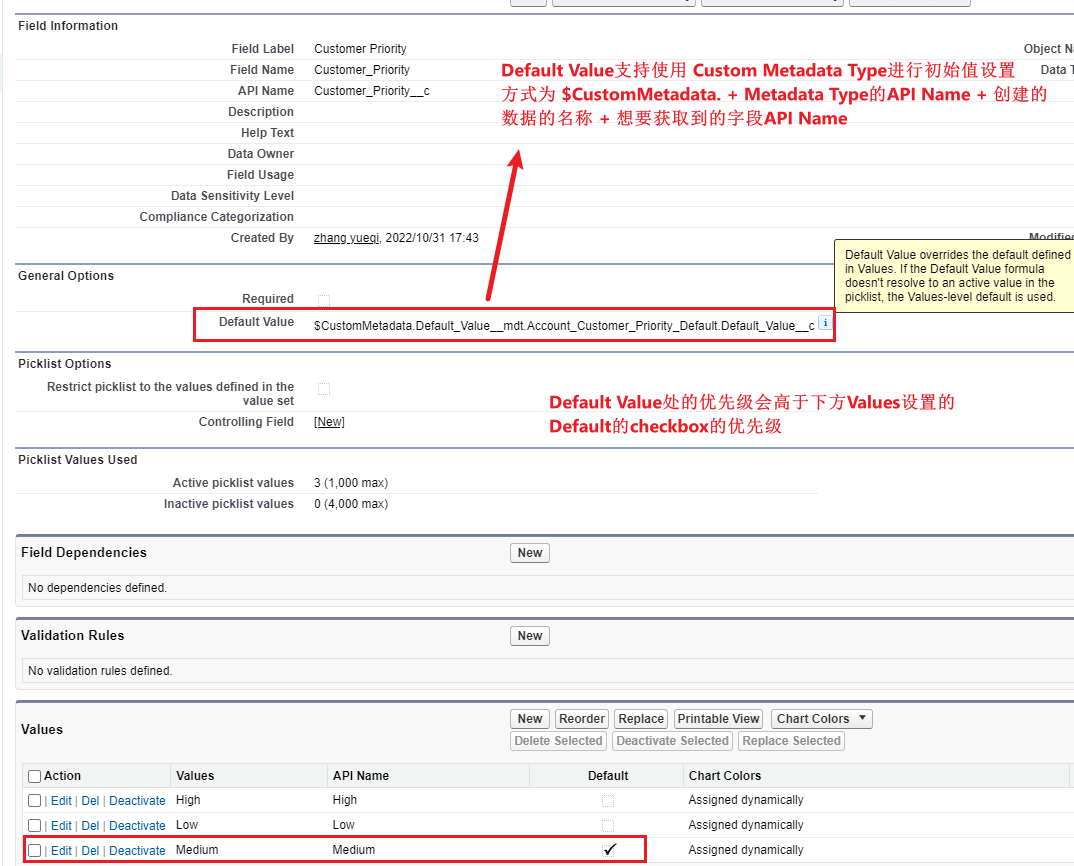
e、PC端登录页面轮询到二维码状态为“扫描成功”,提示“扫描成功”,以下图片仅供参考。

f、移动端展示消息确认弹出框,显示“登录”、“取消登录”按钮,同时将移动端当前登录的用账号、当前移动端登录的token和二维码uuid等信息发送给认证中心。
g、认证中心将用户所选要登录的账号保存在二维码信息里面,并将二维码状态设置为“已授权”。
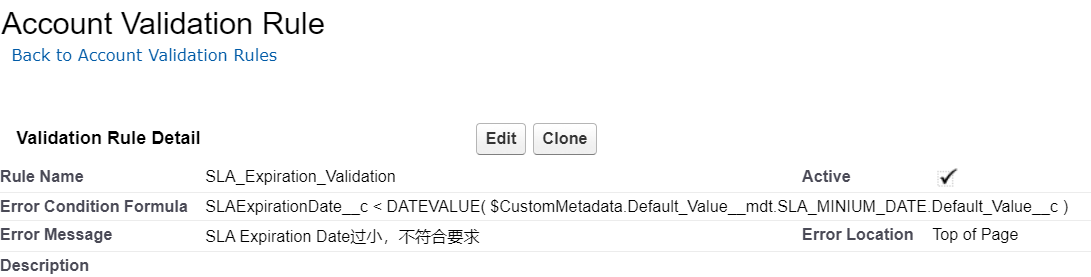
h、登录页面从轮询二维码不存在时,提示“二维码已过期” ,以下图片仅供参考。

i、登录页面从轮询二维码状态为“已取销”时,提示“你已取消此次操作,你可再次扫描,或关闭窗口”。
j、登录页面从轮询二维码状态为“已授权”时,认证中心生成PC端登录的token,设置cookie,并向PC端前端发起重定向跳转。
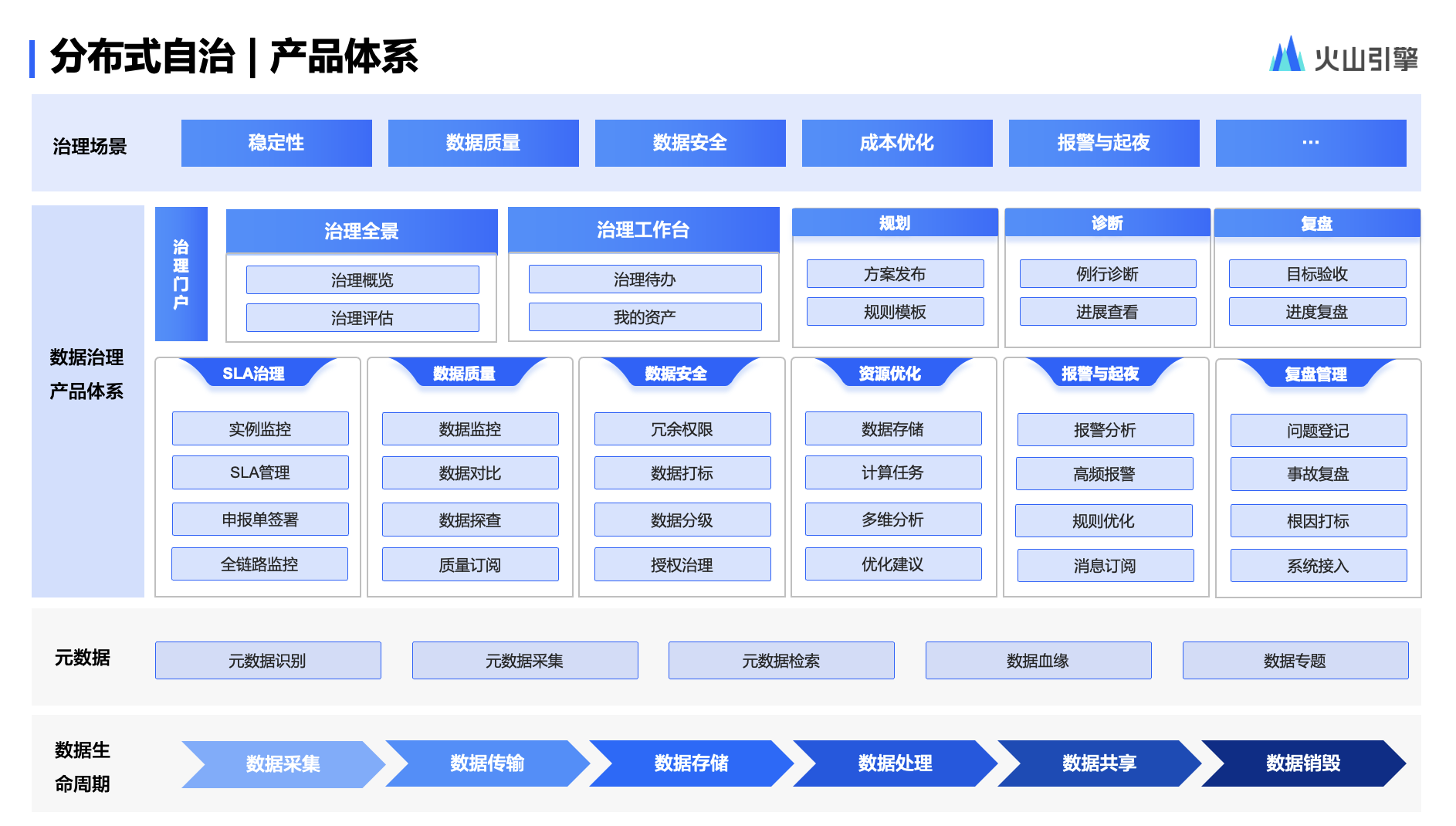
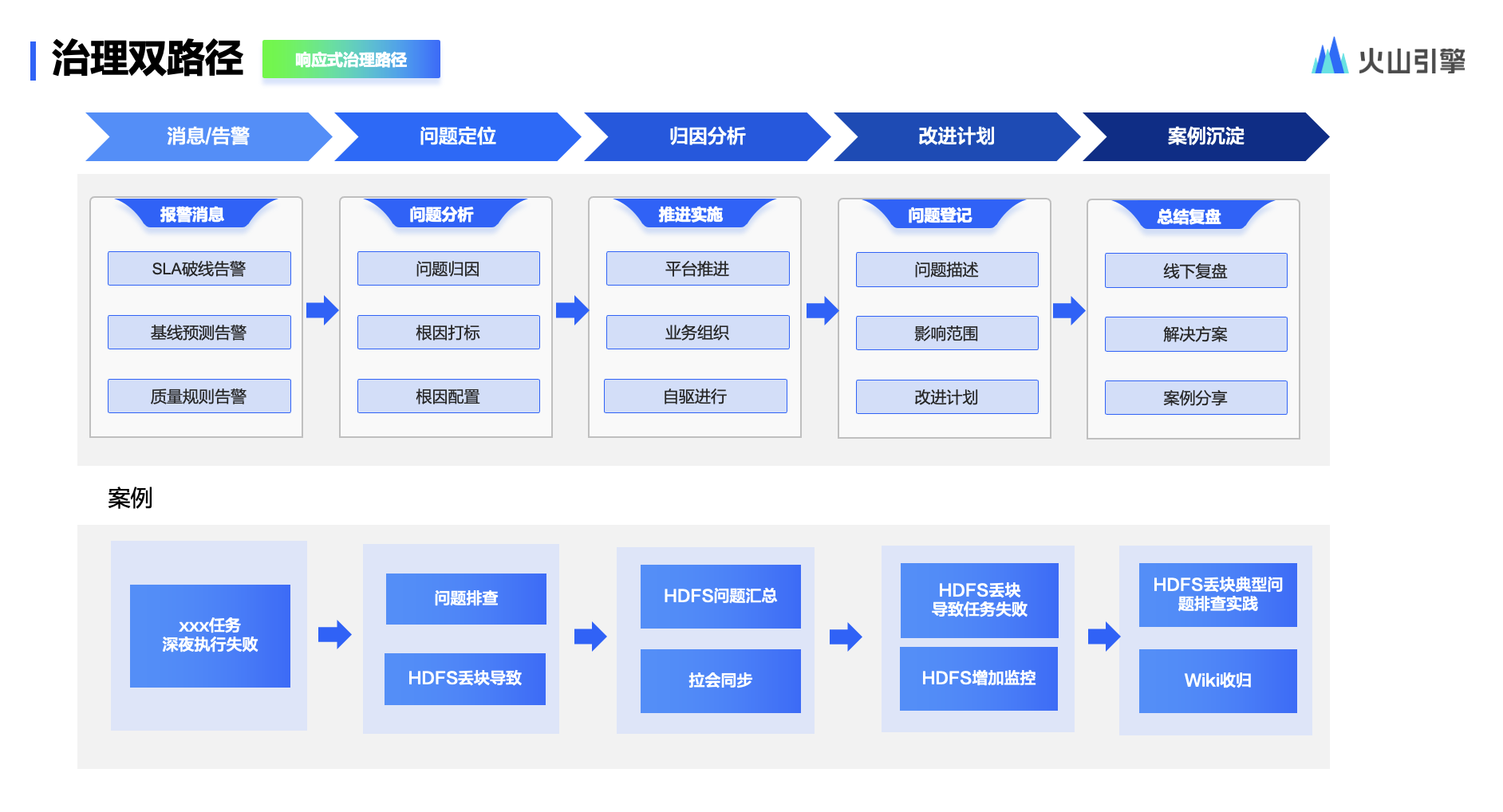
程序处理时序图

三、代码实现
auth2认证最简单的代码结构示例
public class Auth2Login {
public static void main(String[] args) {
//Step 1: 获取授权请求URL
String authRequestUrl = "https://example.com/oauth/authorize";
//Step 2: 向授权服务器发送请求,获取授权码
String authCode = getAuthCode(authRequestUrl);
//Step 3: 使用授权码,向认证服务器发送请求,获取access token
String accessToken = getAccessToken(authCode);
//Step 4: 使用access token,访问资源服务器,进行用户登录
String userInfo = getUserInfo(accessToken);
//Step 5: 根据user info进行用户登录
login(userInfo);
}
public static String getAuthCode(String authRequestUrl) {
//TODO
return null;
}
public static String getAccessToken(String authCode) {
//TODO
return null;
}
public static String getUserInfo(String accessToken) {
//TODO
return null;
}
public static void login(String userInfo) {
//TODO
}
}扫码登录认证关键代码片段
/**
* 初始化,主要通过请求基本参娄生成UUID,并把uuid写入redis
* @param cmd 请求参数
* @return
*/
public Response init(LoginQrCodeInitCmd cmd) {
String clientId = cmd.getClientId();
String clientRedirectUri = cmd.getClientRedirectUri();
ClientDetailsE clientDetails = oauthService.loadClientDetails(clientId);
if (clientDetails == null || clientDetails.getId() == null) {
return Response.buildFailure(AuthcenterCode.INVALID_CLIENT, String.format(AuthcenterCode.INVALID_CLIENT.getDesc(), clientId));
}
if (!clientDetails.getGrantTypes().contains(GrantType.QR_CODE.toString())) {
return Response.buildFailure(AuthcenterCode.INVALID_GRANT_TYPE, String.format(AuthcenterCode.INVALID_GRANT_TYPE.getDesc(), clientId));
}
LoginQrCodeE qrCodeE = LoginQrCodeE.instance().init(clientId, clientRedirectUri);
return DataResponse.of(BeanToolkit.instance().copy(qrCodeE, LoginQrCodeCO.class));
}
/**
* 通过UUID获取登录二维码
* @param uuid 唯一字符串
* @return QR code对象
*/
public LoginQrCodeE getLoginQrCode(String uuid) {
return LoginQrCodeE.instance().of(uuid);
}
/**
* 通过UUID扫码
* @param uuid 唯一字符串
* @return
*/
public Response scan(String uuid) {
LoginQrCodeE.instance().scan(uuid);
return Response.buildSuccess();
}
/**
* 取消登录确认
* @param uuid 唯一字符串
* @return
*/
public Response cancel(String uuid) {
LoginQrCodeE.instance().cancel(uuid);
return Response.buildSuccess();
}
/***
* 验证登录
* @param cmd 用户登录对象信息
* @return 如果成功返回登录信息结构体
*/
public Response authorize(LoginQrCodeAuthorizeCmd cmd) {
String uuid = cmd.getUuid();
String selectedAccountId = cmd.getSelectedAccountId();
String token = cmd.getToken();
//是否有扫码
if (LoginQrCodeE.instance().of(uuid).notScanned()) {
return Response.buildFailure(AuthcenterCode.QR_CODE_NOT_SCANNED);
}
/**
* 找出token
*/
AccessTokenE accessTokenE = oauthRepository.findAccessToken(token);
if (accessTokenE == null) {
return Response.buildFailure(AuthcenterCode.INVALID_TOKEN);
}
AccountE userAccount = oauthRepository.findAccountByToken(token);
if (userAccount == null) {
// 当前令牌不存在用户态(账号)
return Response.buildFailure(AuthcenterCode.TOKEN_ACCOUNT_RELA_NOT_EXIST);
}
List<String> userAccountIds = accountRepository.forceGetAccountIdsByMainUserId(userAccount.getMainUserId());
if (userAccountIds == null) {
// 当前账号异常
return Response.buildFailure(AuthcenterCode.UNKNOWN_ACCOUNT);
}
if (!userAccountIds.contains(selectedAccountId)) {
// 所选账号与当前令牌登录人信息不一致
return Response.buildFailure(AuthcenterCode.INVALID_SWITCH_ACCOUNT);
}
LoginQrCodeE.instance().authorize(uuid, selectedAccountId);
return Response.buildSuccess();
}
/**
* 对外提供轮旬时间服务方法,当查询redis key=uuid是否超时
* @param uuid 用户访问请求的UUID
* @return 登录码状态对象
* @throws OAuthSystemException
*/
public LoginQrCodeE handle(String uuid) throws OAuthSystemException {
LoginQrCodeE loginQrCode = getLoginQrCode(uuid);
// 当处于“已授权”状态时,才能触发准备登录
if (loginQrCode.authorized()) {
return loginQrCode.ready();
}
// 当处于“准备登录”状态时,才能触发登录
if (loginQrCode.loginReady()) {
return login(loginQrCode);
}
return loginQrCode;
}
/**
* 扫码登录
* @param loginQrCode 二维码带的对象信息
* @return
* @throws OAuthSystemException 认证异常
*/
public LoginQrCodeE login(LoginQrCodeE loginQrCode) throws OAuthSystemException {
String clientId = loginQrCode.getClientId();
String accountId = loginQrCode.getAccountId();
ClientDetailsE clientDetails = clientDetailsRepository.findByClientId(clientId);
AccountE userAccount = accountRepository.getAccountById(accountId);
accountRepository.checkAccount(userAccount);
AuthorizeE authorize = oauthRepository.findAccountAuthorizeByAccountId(accountId);
authorizeRepository.checkAuthorizeDataIntegrity(authorize);
if (authorize == null) {
throw new UnknownAuthorizeException("Cannot find AuthorizeE mainUserId="+mainUserId);
}
AccessTokenE accessToken = oauthService.retrieveQrCodeAccessToken(clientDetails, authorize, userAccount, new HashSet<>(),
new BizCodeE(loginQrCode.getAppCode(), loginQrCode.getSubAppCode()));
return loginQrCode.login(accessToken.getToken(), accessToken.getRefreshToken(), accessToken.getCastgt());
}代码仅是展示关键的处理过程,结构还是比较清晰的;这里不提供完整的项目工程,因为这是公司的产权,况且每个公司的业务要求不同,大家理解后再去实现的自己扫码认证逻辑,处理方法大同小异。