大家好,我是王有志。关注
王有志
,一起聊技术,聊游戏,聊在外漂泊的生活。
鸽了这么久怪不好意思的,因此送一本《多处理器编程的艺术》,快点击
此处
参加吧。另外欢迎大家加入“
共同富裕的Java人
”互助群。
今天的主题是
AbstractQueuedSynchronizer
,即AQS
。
作为
java.util.concurrent
的基础,AQS在工作中的重要性是毋庸置疑的。通常在面试中也会有两道“必考”题等着你
原理相关:
AQS是什么?它是怎样实现的?
设计相关:
如何使用AQS实现Mutex?
原理相关的问题几乎会出现在每场Java面试中
,是面试中的“明枪”,是必须要准备的内容;而设计相关的问题更多的是对技术深度的考察,算是“暗箭”,要尤为谨慎的去应对。
我和很多小伙伴交流关于AQS的问题时发现,大部分都只是为了应付面试而“背”了AQS的实现过程。为了全面地理解AQS的设计,今天我们会从1990年T.E.Anderson引入排队的思想萌芽开始,到Mellor-Crummey和Scott提出的MCS锁,以及Craig,Landin和Hagersten设计的CLH锁。
AQS的内容整体规划了4个部分:
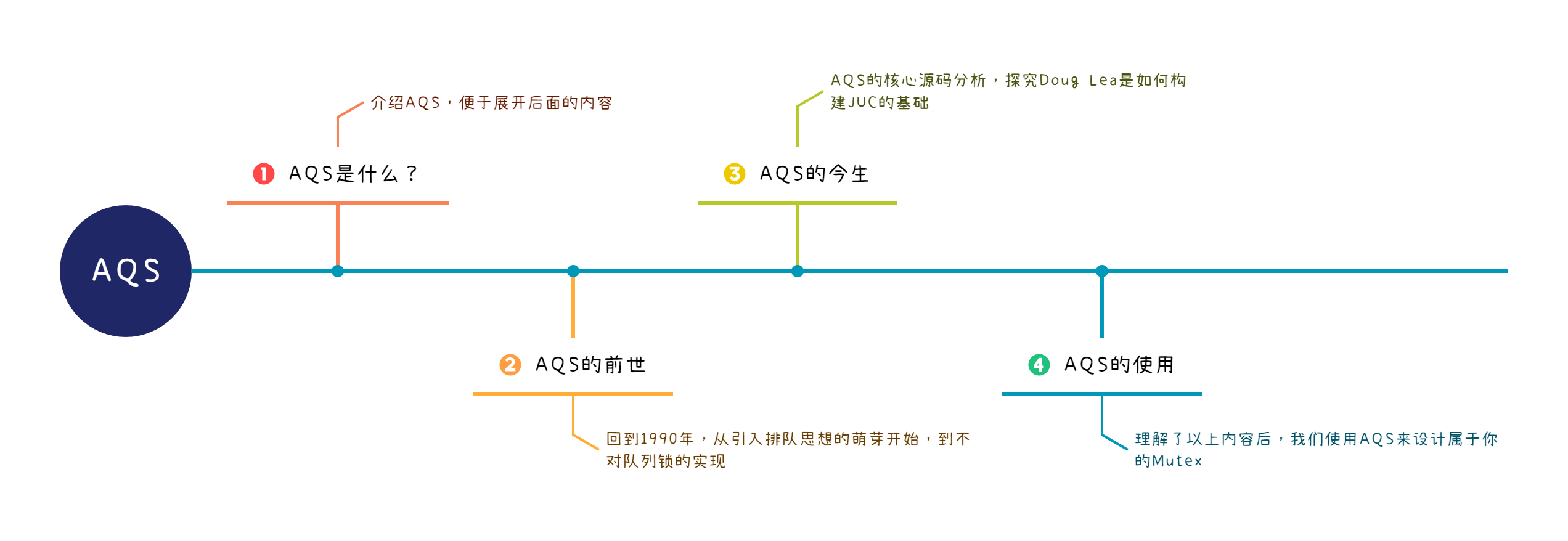
今天我们一起学习前两个部分,了解AQS的前世。
Tips
:本文基于Java 11完成,与Java 8存在部分差异,请注意区分源码之间的差异。
AQS是什么?
通常我们按照类名将
AbstractQueuedSynchronizer
翻译为
抽象队列同步器
。单从类名来看,我们就已经可以得到3个重要信息:
源码中的注释也对AQS做了全面的概括:
Provides a framework for implementing blocking locks and related synchronizers (semaphores, events, etc) that rely on first-in-first-out (FIFO) wait queues.
提供了依赖于FIFO等待队列用于实现阻塞锁和同步器(信号量,事件等)的框架。
这段描述恰好印证了我们通过类名得到的信息,我们来看Java中有哪些AQS的实现:

可以看到,JUC中有大量的同步工具内部都是通过继承AQS来实现的,而这也正是Doug Lea对AQS的期望:
成为大部分同步工具的基础组件。
Tips
:至少在Java 8中,
FutureTask
已经不再依赖AQS实现了(未考证具体版本)。
接着我们来看注释中提到的“rely on first-in-first-out (FIFO) wait queues”,这句话指出AQS依赖了FIFO的等待队列。那么这个队列是什么?我们可以在注释中找到答案:
The wait queue is a variant of a "CLH" (Craig, Landin, and Hagersten) lock queue. CLH locks are normally used for spinlocks.
AQS中使用的等待队列时CLH队列的变种
。那么CLH队列是什么呢?AQS做了哪些改变呢?
AQS的前世
AQS明确揭示了它使用CLH队列的变种,因此我从CLH队列的相关论文入手:
这两篇文章都引用了T.E.Anderson于1990年发表的的《The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors》,因此我们以这篇文章中提出的
基于数组的自旋锁设计
作为切入点。
Tips
:
《Efficient Software Synchronization on Large Cache Coherent Multiprocessors》的作者有3个人~~
Landin和Hagersten的《Efficient Software Synchronization on Large Cache Coherent Multiprocessors》中引用了Craig的《Building FIFO and priority-queueing spin locks from atomic swap》,Craig率先提出了CLH锁的结构,不知道为什么学术界以他们3人进行命名;
由于论文是很多年前收集的,现在去查找原始网站较为困难,只能提供下载链接了,对不起各位祖师爷~~
《
多处理器编程的艺术
》中第7章详细讨论了队列锁的设计,包括基于数组的设计,MCS锁,CLH锁。
基于
数组
的自旋锁
1990年T.E.Anderson发表了《The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors》,文章讨论了基于CPU原子指令自旋锁的性能瓶颈,并提出了基于数组的自旋锁设计。
基于原子指令的自旋锁
第一种设计(SPIN ON TEST-AND-SET),即
TASLock
,使用CPU提供的原子指令test-and-set尝试更新锁标识:

初始化锁标识为CLEAR,获取锁时尝试更新锁标识为BUSY,更新成功则获取到锁,释放时将锁标识更新为CLEAR。
设计非常简单,竞争并不激烈的场景下性能也是完全没问题,但是一旦CPU的核心数增多,问题就出现了:
因此提出了第二种设计(SPIN ON READ),即
TTASLock
,加入test指令,避免频繁的:

该设计中,在执行test-and-set指令前,先进行锁标识状态的判断,处于BUSY状态,直接进入自旋逻辑(或运算的短路特性),跳过test-and-set指令的执行。
额外一次读取操作,避免了频繁的test-and-set指令造成的内存争抢,也减少了总线事务
,竞争者只需要自旋在自己的缓存上即可,只有锁标识发生改变时,才会执行test-and-set指令。
这种设计依旧有些性能问题无法解决:
T.E.Anderson对两种设计进行了测试,计算了在不同数量的CPU上执行了100万次操作的耗时,执行等待锁,执行临界区,释放锁和延迟一段时间。

可以看到SPIN ON READ的设计随着CPU数量的增多性能确实得到了改善,但距离理想的性能曲线仍有着不小的差距。
除了这两种设计外,T.E.Anderson还考虑了在自旋逻辑中引入延迟来减少冲突:

此时需要考虑设置合理的延迟时间,选择合适的退避(backoff)算法来减少竞争。
Tips
:
Java版TA
S
Lock
和
T
T
A
S
Lock
,供大家参考。
基于
数组
的自旋锁
前面的设计中,自旋锁的性能问题是由多个CPU同时争抢内存访问权限产生的,那么让它们按顺序排队是不是就解决了这个问题?T.E.Anderson引入了队列的设计:

初始化
加锁
解锁
每个CPU只访问自己的锁标识(myPlace),避免了争抢内存访问的权限,另外锁会直接释放给队列中的下一个CPU,避免了通过竞争获取,减少了从释放锁到获取锁的时间。
当然缺点也很明显,仅从伪代码的行数上也能看出来,
基于队列的自旋锁设计更复杂,当竞争并不激烈时,它的性能会更差
。T.E.Anderson也给出了他的测试结果:

很明显,在竞争激烈的场景中,引入队列后的自旋锁性能更加优秀,并没有过多的额外开销。
Tips
:
MCS锁的设计
基于数组的自旋锁是排队思想的实现
,T.E.Anderson的论文发表后,又涌现出了许多使用排队思想锁,例如:Mellor-Crummey和Scott于1991年在论文《Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors》中提出的MCS锁,也是基于排队思想实现,只不过在数据结构上选择了
单向链表
。
描述MCS锁的初始化与加解锁的原理,我使用经过“本地化”的Java实现版本的MCS锁:
MCS锁的
初始化
public class MCSLock {
AtomicReference<QNode> lock;
ThreadLocal<QNode> myNode;
public MCSLock() {
this.lock = new AtomicReference<>(null);
this.myNode = ThreadLocal.withInitial(QNode::new);
}
private static class QNode {
private boolean locked;
private QNode next;
}
}
MCS锁的
加锁
public void lock() {
QNode I = this.myNode.get();
QNode predecessor = this.lock.getAndSet(I);
if (predecessor != null) {
I.locked = true;
predecessor.next = I;
while (I.locked) {
System.out.println("自旋,可以加入退避算法");
}
}
}
MCS锁的
解锁
public void unlock() {
QNode I = this.I.get();
if (I.next == null) {
if (lock.compareAndSet(I, null)) {
return;
}
while (I.next == null) {
System.out.println("自旋");
}
}
I.next.locked = false;
I.next = null;
}
MCS锁的逻辑并不复杂,不过有些细节设计的非常巧妙,提个问题供大家思考下:加锁过程中
I.locked = true
和
predecessor.next = I
的顺序可以调整吗?
MCS锁的整体设计思路到这里就结束了,Mellor-Crummey和Scott给出了MCS锁的4个优点:
FIFO保证了公平性,避免了锁饥饿;
自旋标识是线程自身的变量,避免了共享内存的访问冲突;
每个锁的创建只需要极短的时间(requires a small constant amount of space per lock);
无论是否采用一致性缓存架构, 每次获取锁只需要$ O(1)$ 级别的通信开销。
除此之外,相较于T.E.Anderson的设计,
MCS锁在内存空间上是按需分配,并不需要初始化固定长度数组,避免了内存浪费
。
Tips
:
CLH锁的设计
1993年Craig发表了《Building FIFO and priority-queueing spin locks from atomic swap》,文章中描述了另一种基于排队思想的队列锁,即CLH 锁(我觉得称为Craig Lock更合适)的雏形,它和MCS锁很相似,但有一些差异:
CLH旋转在队列前驱节点的锁标识上;
CLH锁使用了一种“隐式”的链表结果。
我们带着这两个差异来看CLH的锁的设计,原文使用Pascal风格的伪代码,这里我们使用《多处理器编程的艺术》中提供的Java版本,与论文中的差异较大,重点理解实现思路即可。
CLH锁的
初始化
public class CLHLock {
AtomicReference<Node> tail;
ThreadLocal<Node> myPred;
ThreadLocal<Node> myNode;
public CLHLock() {
this.tail = new AtomicReference<>(new Node());
this.myNode = ThreadLocal.withInitial(Node::new);
this.myPred = new ThreadLocal<>();
}
private static class Node {
private volatile boolean locked = false;
}
}
Craig的设计中,请求锁的队列节点有两种状态,在实现中可以使用布尔变量代替:
另外CLHLock的初始化中,
this.tail = new AtomicReference<>(new QNode())
添加了默认节点,该节点的locked默认为false,这是借鉴了链表处理时常用到技巧虚拟头节点。
CLH锁的
加锁
public void lock() {
Node myNode = this.myNode.get();
myNode.locked = true;
Node pred = this.tail.getAndSet(myNode);
this.myPred.set(pred);
while(myPred.locked) {
System.out.println("自旋,可以加入退避算法");
}
}
实现中巧妙的使用了两个ThreadLocal变量来构建出了逻辑上的链表,和传统意义的单向链表不同,
CLH的链表从尾节点开始指向头部
。
另外,CLH锁中的节点只关心自身前驱节点的状态,当前驱节点释放锁的那一刻,节点就知道轮到自己获取锁了。
CLH锁的
解锁
public void unlock() {
Node myNode = this.myNode.get();
myNode.locked = false;
this.myNode.set(this.myPred.get());
}
解锁的逻辑也非常简单,只需要更新自身的锁标识即可。但是你可能会疑问
this.myNode.set(this.myPred.get())
是用来干嘛的?删除会产生什么影响吗?
Tips
:
Java版
CLH
Lock
,供大家参考,代码有详细的注释。
单线程场景
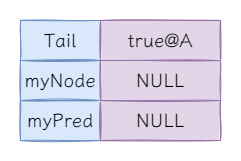
在单线程场景中,完成CLH锁的初始化后,锁的内部结构是如下:
Tips
:@后表示Node节点的地址。
第一次加锁后状态如下:
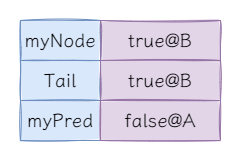
这时前驱节点的锁标记为false,表示当前节点可以直接获取锁。
第一次解锁后状态如下:
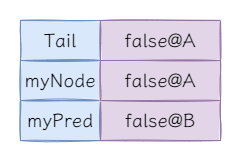
到目前为止一切都很正常,但是当我们再次加锁时会发现,好像没办法加锁了,我们来逐行代码分析锁的状态。当获取myNode后并更新锁标识,即执行如下代码后:
Node myNode = this.myNode.get();
myNode.locked = true;
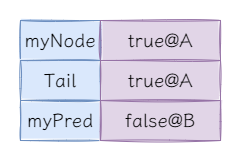
当获取并更新tail和myPred后,即执行如下代码后:
Node pred = this.tail.getAndSet(myNode);
this.myPred.set(pred);
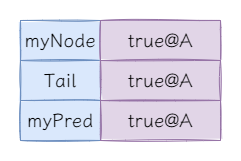
这时候问题出现了,
myNode == myPred
,导致永远无法获取锁。
this.myNode.set(this.myPred.get())
相当于在链表中移除当前节点,
使获取锁的节点的直接前驱节点永远是初始化时锁标识为false的默认节点。
多线程场景
再来考虑多线程的场景,假设有线程t1和线程t2争抢锁,此时t1率先获取到锁:
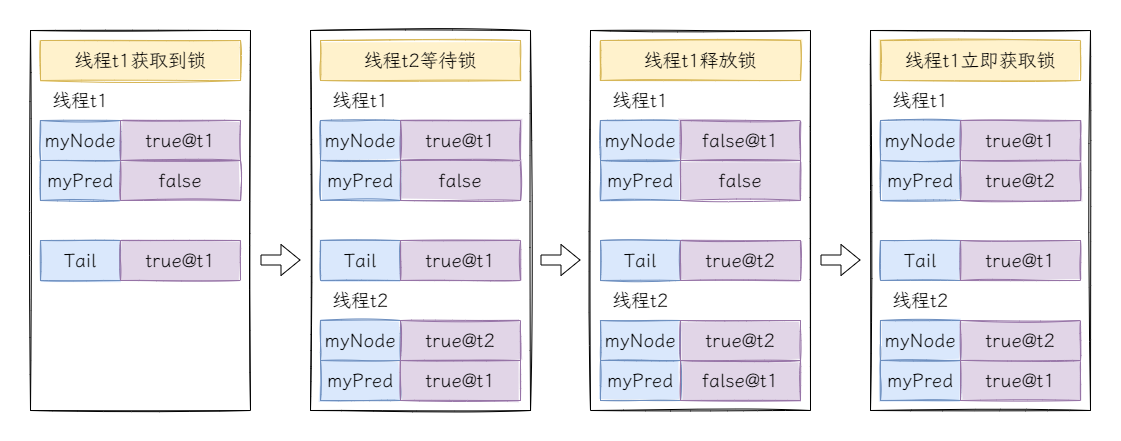
线程t1释放后再次立即获取是有可能出现的,最典型的情况是如果为自旋逻辑添加了退避算法,当线程t2多次自旋后再次进入自旋逻辑,此时线程t1释放锁后立即尝试获取锁,先更新线程t1的锁标记为true,接着从tail节点中获取前驱节点线程t2,然后再更新tail节点,此时线程t1在线程t2的锁标记上自旋,线程t2在线程t1的锁标记上自旋,凉凉~~
留个思考题,为什么
this.myNode.set(this.myPred.get())
可以避免这种情况?
CLH锁和MCS锁的对比
首先是代码实现上,CLH锁的实现非常简单,除了自旋的部分其余全是平铺直叙,反观MCS锁,分支,嵌套,从实现难度上来看CLH锁更胜一筹(难点在于逆向思维,让当前节点自旋在直接前驱节点的锁标识上)。另外,CLH锁只在加锁时使用了一次原子指令,而MCS锁的加解锁中都需要使用原子指令,性能上也略胜一筹。
那么CLH锁是全面超越了MCS锁吗?不是的,在
NUMA
架构下,CLH锁的自旋性能非常差。先来看NUMA架构的示意图:
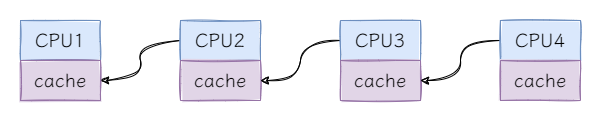
NUMA架构中,每个CPU有自己缓存,访问不同CPU缓存的成本较高,在需要频繁进入自旋的场景中CLH锁自旋的性能较差,而在需要频繁解锁更新其他CPU锁标识的场景中MCS锁的性能较差。
结语
到目前为止,我们一起学习了3种基于排队思想的自旋锁设计,作为AQS的“前世”,理解它们的设计能够帮助我们理解AQS的原理。当然并非只有这3种基于排队思想的自旋锁,还有如RHLock,HCLHLock等,感兴趣的可以自行探索,这里提供论文链接:
好了,今天就到这里了,Bye~~