2023年3月
局部异常因子(Local Outlier Factor, LOF)算法详解及实验
局部异常因子(Local Outlier Factor, LOF)通过计算样本点的局部相对密度来衡量这个样本点的异常情况,可以算是一类无监督学习算法。下面首先对算法的进行介绍,然后进行实验。
LOF算法
下面介绍LOF算法的每个概念,以样本点集合中的样本点$P$为例。下面的概念名称中都加了一个k-,实际上部分名称原文没有加,但是感觉这样更严谨一些。
k-邻近距离(k-distance)
:样本点$P$与其最近的第$k$个样本点之间的距离,表示为$d_k(P)$。其中距离可以用各种方式度量,通常使用欧氏距离。
k-距离邻域
:以$P$为圆心,$d_k(P)$为半径的邻域,表示为$N_k(P)$。
k-可达距离
:$P$到某个样本点$O$的k-可达距离,取$d_k(O)$或$P$与$O$之间距离的较大值,表示为
$reach\_dist_k(P,O)=\max\{d_k(O),d(P,O)\}$
也就是说,如果$P$在$N_k(O)$内部,$reach\_dist_k(P,O)$取$O$的k-邻近距离$d_k(O)$,在$N_k(O)$外部则取$P$与$O$之间距离$d(P,O)$。需要注意k-可达距离不是对称的。
k-局部可达密度(local reachability density, lrd)
:$P$的k-局部可达密度表示为
$\displaystyle lrd_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}reach\_dist_k(P,O)}{|N_k(P)|}\right)^{-1}$
括号内,分子计算了$P$到其k-距离邻域内所有样本点$O$的k-可达距离之和,然后除以$P$的k-距离邻域内部的样本点个数进行平均。再加一个倒数,表示为密度,即$P$到每个点的平均距离越小,密度越大。可以推理出,如果$P$在所有$O$的k-邻域内部,其局部可达密度即为
$\displaystyle lrd_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}d_k(O)}{|N_k(P)|}\right)^{-1}$
可以看出,如果$P$是一个离群点,那么它不太可能存在于$N_k(P)$中各点的k-距离邻域内,从而导致其局部可达密度偏小;如果$P$不是离群点,其局部可达密度最大取为上式。
实际上我有点奇怪为什么要用一个最大值来将距离作一个限制,也就是使用k-可达距离,而不是直接使用距离,即定义局部密度为下式
$\displaystyle ld_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}d(O,P)}{|N_k(P)|}\right)^{-1}$
k-局部异常因子(Local Outlier Factor, LOF)
:$P$的k-局部异常因子表示为
$\displaystyle LOF_k(P)=\frac{\frac{1}{|N_k(P)|}\sum\limits_{O\in N_k(P)}lrd_k(O)}{lrd_k(P)}$
从直觉上理解:当$LOF_k(P)\le1$时,表明$P$处密度比其周围点大或相当,则$P$是内点;当$LOF_k(P)>1$时,表明$P$处密度比其周围点小,可以判别为离群(异常)点。
实验
LOF算法实现
实验设置样本维度为2以便可视化。由于样本点只包含连续值,实验默认设置$|N_k(P)|=k$。设置$k=5$,并将阈值设为1.2,即将LOF大于1.2的样本点视作异常。函数定义、抽样、计算以及可视化代码如下。
#%% 定义函数 importtorchimportmatplotlib.pyplot as plt#计算所有样本点[N, M]之间的距离,得到[N, N] defget_dists(points:torch.Tensor):
x= torch.sum(points**2, 1).reshape(-1, 1)
y= torch.sum(points**2, 1).reshape(1, -1)
dists= x + y - 2 * torch.mm(points, points.permute(1,0))#数值计算问题,防止对角线小于0 dists = dists -torch.diag_embed(torch.diag(dists))returntorch.sqrt(dists)#计算所有样本点到其k-邻域点的k-可达距离 defget_LOFs(dists:torch.Tensor, k):#距离排序,获取所有样本点的k-临近距离 sorted_dists, sorted_inds = torch.sort(dists, 1, descending=False)
k_dists=sorted_dists[:, k]
neighbor_inds= sorted_inds[:, 1:k+1].reshape(-1)
neighbor_k_dists= k_dists[neighbor_inds].reshape(-1, k)
neighbor_k_reach_dists= torch.max(neighbor_k_dists, dists[:, 1:k+1])
lrds= (neighbor_k_reach_dists.sum(1)/k)**-1neighbor_lrds= lrds[neighbor_inds].reshape(-1, k)
LOFs= neighbor_lrds.sum(1)/k/lrdsreturnLOFs#%% 随机生成聚集点和异常点 from torch.distributions importMultivariateNormal
torch.manual_seed(0)
crowd_mu_covs=[
[[0.0, 0.0], [[1.0, 0.0], [0.0, 2.0]], 10],
[[-10.0, -1.0], [[2.0, 0.8], [0.8, 2.0]], 10],
[[-10.0, -20.0], [[5.0, -2], [-2, 3.0]], 50],
[[5.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-3.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-13.0, -10.0], [[0.3, -0.1], [-0.1, 0.5]], 10],
[[-4.0, -10.0], [[0.3, -0.1], [-0.1, 0.1]], 100],
]#正态分布点的均值和方差 outliers = [[5, 5.], [3, 4], [5, -3], [4, -30], [-2, -35], [-10, -35]] #异常点 points=[]for i incrowd_mu_covs:
mu=torch.tensor(i[0])
cov= torch.tensor(i[1])
ps= MultivariateNormal(mu, cov).sample([i[2]]).to('cuda')
points.append(ps)for o inoutliers:
points.append(torch.tensor([o]).to('cuda'))
points=torch.cat(points)#%% 计算LOFs并可视化可视化 k, threshold = 5, 1.2dists=get_dists(points)
LOFs=get_LOFs(dists, k)for i, p inenumerate(points.cpu().numpy()):
shape, color= '.', 'black' if len(points) - i <=len(outliers):
shape= '^'plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]))if LOFs[i] >threshold:
color= 'red'plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]), color='blue')
plt.plot(p[0], p[1], shape, color=color)
plt.show()
实验可视化结果如下图所示,其中红色点表示被标为异常的点,三角点表示实验设置的真实异常点。可以看出LOF的确能有效将异常离群点找出。但是,发现下面三个人眼看来非常离群的点的LOF值还不到1.5,比上面异常点的LOF低得多,这说明算法还有些不合理之处。

距离代替局部可达距离
根据前面的疑问,用距离代替局部可达距离进行相应实验。仅在get_LOFs函数处做了相关改动,并将阈值threshold改为2。代码如下。
#%% 定义函数 importtorchimportmatplotlib.pyplot as plt#计算所有样本点[N, M]之间的距离,得到[N, N] defget_dists(points:torch.Tensor):
x= torch.sum(points**2, 1).reshape(-1, 1)
y= torch.sum(points**2, 1).reshape(1, -1)
dists= x + y - 2 * torch.mm(points, points.permute(1,0))#数值计算问题,防止对角线小于0 dists = dists -torch.diag_embed(torch.diag(dists))returntorch.sqrt(dists)#计算所有样本点到其k-邻域点的k-可达距离 defget_LOFs(dists:torch.Tensor, k):#距离排序,获取所有样本点的k-临近距离 sorted_dists, sorted_inds = torch.sort(dists, 1, descending=False)
densities= (sorted_dists[:, 1:k+1].sum(1)/k)**-1neighbor_inds= sorted_inds[:, 1:k+1].reshape(-1)
neighbor_densities= densities[neighbor_inds].reshape(-1, k)
LOFs= neighbor_densities.sum(1)/k/densitiesreturnLOFs#%% 随机生成聚集点和异常点 from torch.distributions importMultivariateNormal
torch.manual_seed(0)
crowd_mu_covs=[
[[0.0, 0.0], [[1.0, 0.0], [0.0, 2.0]], 10],
[[-10.0, -1.0], [[2.0, 0.8], [0.8, 2.0]], 10],
[[-10.0, -20.0], [[5.0, -2], [-2, 3.0]], 50],
[[5.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-3.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-13.0, -10.0], [[0.3, -0.1], [-0.1, 0.5]], 10],
[[-4.0, -10.0], [[0.3, -0.1], [-0.1, 0.1]], 100],
]#正态分布点的均值和方差 outliers = [[5, 5.], [3, 4], [5, -3], [4, -30], [-2, -35], [-10, -35]] #异常点 points=[]for i incrowd_mu_covs:
mu=torch.tensor(i[0])
cov= torch.tensor(i[1])
ps= MultivariateNormal(mu, cov).sample([i[2]]).to('cuda')
points.append(ps)for o inoutliers:
points.append(torch.tensor([o]).to('cuda'))
points=torch.cat(points)#%% 计算LOFs并可视化可视化 k, threshold = 5, 2dists=get_dists(points)
LOFs=get_LOFs(dists, k)for i, p inenumerate(points.cpu().numpy()):
shape, color= '.', 'black' if len(points) - i <=len(outliers):
shape= '^'plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]))if LOFs[i] >threshold:
color= 'red'plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]), color='blue')
plt.plot(p[0], p[1], shape, color=color)
plt.show()
可视化结果如下图所示。
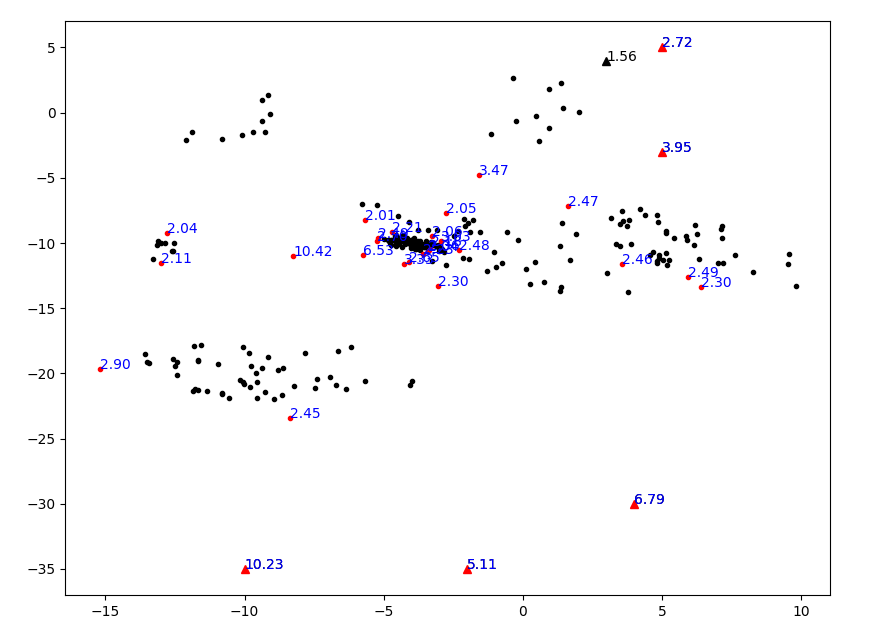
部分离群点的确能被有效找出,但是看起来似乎这个算法对“相对”的概念太显著了,导致一个聚集的点群里面也有很多不是那么聚集的点被划分为离群点。看来用距离代替局部可达距离是不行的。但是如何从理论上来解释,本文不再作深究,欢迎前来讨论。
linux网络编程中的errno处理
在Linux网络编程中,errno是一个非常重要的变量。它记录了最近发生的系统调用错误代码。在编写网络应用程序时,合理处理errno可以帮助我们更好地了解程序出现的问题并进行调试。
通常,在Linux网络编程中发生错误时,errno会被设置为一个非零值。因此,在进行系统调用之后,我们应该始终检查errno的值。我们可以使用perror函数将错误信息打印到标准错误输出中,或者使用strerror函数将错误代码转换为错误信息字符串。
在网络编程中,处理网络连接、连接收发数据等经常会涉及到errno的处理。经过查阅了很多资料,发现没有一个系统的讲解,在不同阶段会遇到哪些errno,以及对这些errno需要如何处理。因此,本文将分为三个部分来讲解。
1. 接受连接(accept)
这一阶段发生在 accept 接收 tcp 连接中。
在accept接收tcp连接的过程中,可能会遇到以下errno:
- EAGAIN或EWOULDBLOCK:表示当前没有连接可以接受,非阻塞模式下可以继续尝试接受连接
- ECONNABORTED:表示连接因为某种原因被终止,可以重新尝试接受连接
- EINTR:表示系统调用被中断,可以重新尝试接受连接
- EINVAL:表示套接字不支持接受连接操作,需要检查套接字是否正确
其中 EINTR、EAGAIN与EWOULDBLOCK,表示可能遇到了系统中断,需要对这些errno忽略,如果是其他错误,则需要执行错误回调或者直接处理错误。
在 libevent 为这些需要忽略的errno定义了宏 EVUTIL_ERR_ACCEPT_RETRIABLE,宏里定义了上面三个需要忽略的信号,在 accept 处理时会判断如果遇到这些信号则进行忽略,下次重试就好。
/* True iff e is an error that means a accept can be retried. */
#define EVUTIL_ERR_ACCEPT_RETRIABLE(e) \
((e) == EINTR || EVUTIL_ERR_IS_EAGAIN(e) || (e) == ECONNABORTED)
// libevent accept 处理代码
static void listener_read_cb(evutil_socket_t fd, short what, void *p)
{
struct evconnlistener *lev = p;
int err;
evconnlistener_cb cb;
evconnlistener_errorcb errorcb;
void *user_data;
LOCK(lev);
while (1) {
struct sockaddr_storage ss;
ev_socklen_t socklen = sizeof(ss);
evutil_socket_t new_fd = evutil_accept4_(fd, (struct sockaddr*)&ss, &socklen, lev->accept4_flags);
if (new_fd < 0)
break;
if (socklen == 0) {
/* This can happen with some older linux kernels in
* response to nmap. */
evutil_closesocket(new_fd);
continue;
}
..........
}
err = evutil_socket_geterror(fd);
if (EVUTIL_ERR_ACCEPT_RETRIABLE(err)) {
UNLOCK(lev);
return;
}
if (lev->errorcb != NULL) {
++lev->refcnt;
errorcb = lev->errorcb;
user_data = lev->user_data;
errorcb(lev, user_data);
listener_decref_and_unlock(lev);
} else {
event_sock_warn(fd, "Error from accept() call");
UNLOCK(lev);
}
}
2. 建立连接(connect )
这一阶段发生在 connect 连接中。
在connect连接的过程中,可能会遇到以下errno:
- EINPROGRESS:表示连接正在进行中,需要等待连接完成
- EALREADY:表示套接字非阻塞模式下连接请求已经发送,但连接还未完成,需要等待连接完成
- EISCONN:表示套接字已经连接,无需再次连接
- EINTR:表示系统调用被中断,可以重新尝试连接
- ENETUNREACH:表示网络不可达,需要检查网络连接是否正常
其中 EINPROGRESS、EALREADY、EINTR 表示连接正在进行中,需要等待连接完成或重新尝试连接。如果是其他错误,则需要执行错误回调或者直接处理错误。
一般情况下,我们需要通过 select、poll、epoll 等 I/O 多路复用函数来等待连接完成,或者使用非阻塞的方式进行连接,等待连接完成后再进行下一步操作。
在 libevent 中,为这些需要忽略的 errno 定义了宏 EVUTIL_ERR_CONNECT_RETRIABLE,宏里定义了上面三个需要忽略的信号,在 connect 处理时会判断如果遇到这些信号则进行忽略,下次重试就好。
/* True iff e is an error that means a connect can be retried. */
#define EVUTIL_ERR_CONNECT_RETRIABLE(e) \\
((e) == EINTR || (e) == EINPROGRESS || (e) == EALREADY)
// libevent connect 处理代码
/* XXX we should use an enum here. */
/* 2 for connection refused, 1 for connected, 0 for not yet, -1 for error. */
int evutil_socket_connect_(evutil_socket_t *fd_ptr, const struct sockaddr *sa, int socklen)
{
int made_fd = 0;
if (*fd_ptr < 0) {
if ((*fd_ptr = socket(sa->sa_family, SOCK_STREAM, 0)) < 0)
goto err;
made_fd = 1;
if (evutil_make_socket_nonblocking(*fd_ptr) < 0) {
goto err;
}
}
if (connect(*fd_ptr, sa, socklen) < 0) {
int e = evutil_socket_geterror(*fd_ptr);
// 处理忽略的 errno
if (EVUTIL_ERR_CONNECT_RETRIABLE(e))
return 0;
if (EVUTIL_ERR_CONNECT_REFUSED(e))
return 2;
goto err;
} else {
return 1;
}
err:
if (made_fd) {
evutil_closesocket(*fd_ptr);
*fd_ptr = -1;
}
return -1;
}
3. 连接的读写
在 Linux 网络编程中,连接读写阶段可能会遇到以下 errno:
- EINTR:表示系统调用被中断,可以重新尝试读写
- EAGAIN 或 EWOULDBLOCK:表示当前没有数据可读或没有缓冲区可写,需要等待下一次读写事件再尝试读写,非阻塞模式下可以继续尝试读写
- ECONNRESET 或 EPIPE:表示连接被重置或对端关闭了连接,需要重新建立连接
- ENOTCONN:表示连接未建立或已断开,需要重新建立连接
- ETIMEDOUT:表示连接超时,需要重新建立连接
- ECONNREFUSED:表示连接被拒绝,需要重新建立连接
- EINVAL:表示套接字不支持读写操作,需要检查套接字是否正确
其中 EINTR、EAGAIN 或 EWOULDBLOCK 表示可能遇到了系统中断或当前没有数据可读或没有缓冲区可写,需要对这些 errno 忽略,如果是其他错误,则需要执行错误回调或者直接处理错误。
在 libevent 中,为这些需要忽略的 errno 定义了宏 EVUTIL_ERR_RW_RETRIABLE,宏里定义了 EINTR、EAGAIN 或 EWOULDBLOCK 需要忽略的信号,在连接的读写处理时会判断如果遇到这些信号则进行忽略,下次重试就好。
/* True iff e is an error that means a read or write can be retried. */
#define EVUTIL_ERR_RW_RETRIABLE(e) \\
((e) == EINTR || EVUTIL_ERR_IS_EAGAIN(e))
// 连接读写处理代码例子
static void bufferevent_readcb(evutil_socket_t fd, short event, void *arg)
{
struct bufferevent *bufev = arg;
struct bufferevent_private *bufev_p = BEV_UPCAST(bufev);
struct evbuffer *input;
int res = 0;
short what = BEV_EVENT_READING;
ev_ssize_t howmuch = -1, readmax=-1;
bufferevent_incref_and_lock_(bufev);
if (event == EV_TIMEOUT) {
/* Note that we only check for event==EV_TIMEOUT. If
* event==EV_TIMEOUT|EV_READ, we can safely ignore the
* timeout, since a read has occurred */
what |= BEV_EVENT_TIMEOUT;
goto error;
}
input = bufev->input;
/*
* If we have a high watermark configured then we don't want to
* read more data than would make us reach the watermark.
*/
if (bufev->wm_read.high != 0) {
howmuch = bufev->wm_read.high - evbuffer_get_length(input);
/* we somehow lowered the watermark, stop reading */
if (howmuch <= 0) {
bufferevent_wm_suspend_read(bufev);
goto done;
}
}
readmax = bufferevent_get_read_max_(bufev_p);
if (howmuch < 0 || howmuch > readmax) /* The use of -1 for "unlimited"
* uglifies this code. XXXX */
howmuch = readmax;
if (bufev_p->read_suspended)
goto done;
evbuffer_unfreeze(input, 0);
res = evbuffer_read(input, fd, (int)howmuch); /* XXXX evbuffer_read would do better to take and return ev_ssize_t */
evbuffer_freeze(input, 0);
if (res == -1) {
int err = evutil_socket_geterror(fd);
// 处理需要忽略的errno
if (EVUTIL_ERR_RW_RETRIABLE(err))
goto reschedule;
if (EVUTIL_ERR_CONNECT_REFUSED(err)) {
bufev_p->connection_refused = 1;
goto done;
}
/* error case */
what |= BEV_EVENT_ERROR;
} else if (res == 0) {
/* eof case */
what |= BEV_EVENT_EOF;
}
if (res <= 0)
goto error;
bufferevent_decrement_read_buckets_(bufev_p, res);
/* Invoke the user callback - must always be called last */
bufferevent_trigger_nolock_(bufev, EV_READ, 0);
goto done;
reschedule:
goto done;
error:
bufferevent_disable(bufev, EV_READ);
bufferevent_run_eventcb_(bufev, what, 0);
done:
bufferevent_decref_and_unlock_(bufev);
}
static void bufferevent_writecb(evutil_socket_t fd, short event, void *arg)
{
struct bufferevent *bufev = arg;
struct bufferevent_private *bufev_p = BEV_UPCAST(bufev);
int res = 0;
short what = BEV_EVENT_WRITING;
int connected = 0;
ev_ssize_t atmost = -1;
bufferevent_incref_and_lock_(bufev);
if (evbuffer_get_length(bufev->output)) {
evbuffer_unfreeze(bufev->output, 1);
res = evbuffer_write_atmost(bufev->output, fd, atmost);
evbuffer_freeze(bufev->output, 1);
if (res == -1) {
int err = evutil_socket_geterror(fd);
// 处理需要忽略的 errno
if (EVUTIL_ERR_RW_RETRIABLE(err))
goto reschedule;
what |= BEV_EVENT_ERROR;
} else if (res == 0) {
/* eof case
XXXX Actually, a 0 on write doesn't indicate
an EOF. An ECONNRESET might be more typical.
*/
what |= BEV_EVENT_EOF;
}
if (res <= 0)
goto error;
bufferevent_decrement_write_buckets_(bufev_p, res);
}
if (evbuffer_get_length(bufev->output) == 0) {
event_del(&bufev->ev_write);
}
/*
* Invoke the user callback if our buffer is drained or below the
* low watermark.
*/
if (res || !connected) {
bufferevent_trigger_nolock_(bufev, EV_WRITE, 0);
}
goto done;
reschedule:
if (evbuffer_get_length(bufev->output) == 0) {
event_del(&bufev->ev_write);
}
goto done;
error:
bufferevent_disable(bufev, EV_WRITE);
bufferevent_run_eventcb_(bufev, what, 0);
done:
bufferevent_decref_and_unlock_(bufev);
}
4. 总结
本文介绍了在 Linux 网络编程中处理 errno 的方法。在接受连接、建立连接和连接读写阶段可能会遇到多种 errno,如 EINTR、EAGAIN、EWOULDBLOCK、ECONNRESET、EPIPE、ENOTCONN、ETIMEDOUT、ECONNREFUSED、EINVAL 等,需要对一些 errno 进行忽略,对于其他错误则需要执行错误回调或者直接处理错误。在 libevent 中,为这些需要忽略的 errno 定义了宏,如 EVUTIL_ERR_ACCEPT_RETRIABLE、EVUTIL_ERR_CONNECT_RETRIABLE、EVUTIL_ERR_RW_RETRIABLE 等,方便开发者处理这些 errno。
从0搭建Vue3组件库(六):前端流程化控制工具gulp的使用
前言
随着前端诸如webpack,rollup,vite的发展,gulp感觉似乎好像被取代了。其实并没有,只不过它从台前退居到了幕后。我们仍然可以在很多项目中看到它的身影,比如elementplus、vant等。现在gulp更多的是做流程化的控制。
比如我们要把一个大象放进冰箱里就需要 打开冰箱门->把大象放进冰箱->关上冰箱门,这就是一个简单的流程,使用gulp就可以规定这些流程,将这个流程自动化。
所以我们可以使用它在项目开发过程中自动执行常见任务。比如打包一个组件库,我们可能要移除文件、copy文件,打包样式、打包组件、执行一些命令还有一键打包多个package等等都可以由gulp进行自定义流程的控制,非常的方便。
本文将主要介绍gulp的一些常用功能
安装gulp
首先全局安装gulp的脚手架
npm install --global gulp-cli
然后我们新建文件夹gulpdemo,然后执行
npm init -y
,然后在这个项目下安装本地依赖gulp
npm install gulp -D
此时我们gulp便安装好了,接下来我们在根目录下创建
gulpfile.js
文件,当gulp执行的时候会自动寻找这个文件。
创建一个任务Task
每个gulp任务(task)都是一个异步的JavaScript函数,此函数是一个可以接收callback作为参数的函数,或者返回一个Promise等异步操作对象,比如创建一个任务可以这样写
exports.default = (cb) => {
console.log("my task");
cb();
};
或者这样写
exports.default = () => {
console.log("my task");
return Promise.resolve();
};
然后终端输入
gulp
就会执行我们这个任务
串行(series)和并行(parallel)
这两个其实很好理解,串行就是任务一个一个执行,并行就是所有任务一起执行。下面先看串行演示
const { series, parallel } = require("gulp");
const task1 = () => {
console.log("task1");
return new Promise((resolve) => {
setTimeout(() => {
resolve();
}, 5000);
});
};
const task2 = () => {
console.log("task2");
return Promise.resolve();
};
exports.default = series(task1, task2);
控制台输出结果如下
可以看出执行task1用了5s,然后再执行task2,再看下并行
const { series, parallel } = require("gulp");
const task1 = () => {
console.log("task1");
return new Promise((resolve) => {
setTimeout(() => {
resolve();
}, 5000);
});
};
const task2 = () => {
console.log("task2");
return Promise.resolve();
};
exports.default = parallel(task1, task2);
可以看出两个任务是同时执行的
src()和dest()
src()和dest()这两个函数在我们实际项目中经常会用到。src()表示创建一个读取文件系统的流,dest()是创建一个写入到文件系统的流。我们直接写一个copy 的示例
复制
在写之前我们先在我们项目根目录下新建一个src目录用于存放我们被复制的文件,在src下随便新建几个文件,如下图
然后我们在
gulpfile.js
写下我们的copy任务:将src下的所有文件复制到dist文件夹下
const { src, dest } = require("gulp");
const copy = () => {
return src("src/*").pipe(dest("dist/"));
};
exports.default = copy;
然后执行gulp(默认执行exports.default),我们就会发现根目录下多了个dist文件夹
处理less文件
下面我们写个处理less文件的任务,首先我们先安装
gulp-less
npm i -D gulp-less
然后我们在src下新建一个style/index.less并写下一段less语法样式
@color: #fff;
.wrap {
color: @color;
}
然后
gulpfile.js
写下我们的lessTask:将我们style下的less文件解析成css并写入dist/style中
const { src, dest } = require("gulp");
const less = require("gulp-less");
const lessTask = () => {
return src("src/style/*.less").pipe(less()).pipe(dest("dist/style"));
};
exports.default = lessTask;
然后我们执行gulp命令就会发现dist/style/index.css
.wrap {
color: #fff;
}
我们还可以给css加前缀
npm install gulp-autoprefixer -D
将我们的src/style/index.less改为
@color: #fff;
.wrap {
color: @color;
display: flex;
}
然后在
gulpfile.js
中使用gulp-autoprefixer
const { src, dest } = require("gulp");
const less = require("gulp-less");
const autoprefixer = require("gulp-autoprefixer");
const lessTask = () => {
return src("src/style/*.less")
.pipe(less())
.pipe(
autoprefixer({
overrideBrowserslist: ["> 1%", "last 2 versions"],
cascade: false, // 是否美化属性值
})
)
.pipe(dest("dist/style"));
};
exports.default = lessTask;
处理后的dist/style/index.css就变成了
.wrap {
color: #fff;
display: -webkit-box;
display: -ms-flexbox;
display: flex;
}
监听文件更改browser-sync
browser-sync
是一个十分好用的浏览器同步测试工具,它可以搭建静态服务器,监听文件更改,并刷新页面(HMR),下面来看下它的使用
首先肯定要先安装
npm i browser-sync -D
然后我们在根目录下新建index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
hello world
</body>
</html>
然后在
gulpfile.js
中进行配置
const browserSync = require("browser-sync");
const browserTask = () => {
browserSync.init({
server: {
baseDir: "./",
},
});
};
exports.default = browserTask;
这时候就会启动一个默认3000端口的页面. 下面我们看如何监听页面变化。
首先我们要监听文件的改变,可以使用browserSync的watch,监听到文件改变后再刷新页面
const { watch } = require("browser-sync");
const browserSync = require("browser-sync");
const { series } = require("gulp");
const reloadTask = () => {
browserSync.reload();
};
const browserTask = () => {
browserSync.init({
server: {
baseDir: "./",
},
});
watch("。/*", series(reloadTask));
};
exports.default = browserTask;
此时改动src下的文件浏览器便会刷新。
下面我们将index.html引入dist/style/index.css的样式,然后来模拟一个简单的构建流
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<link rel="stylesheet" href="../dist/style/index.css" />
</head>
<body>
<div class="wrap">hello world</div>
</body>
</html>
此时我们的流程是
编译less文件
->
将css写入dist/style
->
触发页面更新
我们
gulpfile.js
可以这样写
const { src, dest } = require("gulp");
const { watch } = require("browser-sync");
const browserSync = require("browser-sync");
const { series } = require("gulp");
const less = require("gulp-less");
const autoprefixer = require("gulp-autoprefixer");
const lessTask = () => {
return src("src/style/*.less")
.pipe(less())
.pipe(
autoprefixer({
overrideBrowserslist: ["> 1%", "last 2 versions"],
cascade: false, // 是否美化属性值
})
)
.pipe(dest("dist/style"));
};
//页面刷新
const reloadTask = () => {
browserSync.reload();
};
const browserTask = () => {
browserSync.init({
server: {
baseDir: "./",
},
});
watch("./*.html", series(reloadTask));
//监听样式更新触发两个任务
watch("src/style/*", series(lessTask, reloadTask));
};
exports.default = browserTask;
此时无论我们更改的是样式还是html都可以触发页面更新。
最后
后面我会将正在开发的vue3组件库的样式打包部分使用gulp处理,如果你对组件库开发感兴趣的话可以关注我,后续会持续更新本系列内容
创作不易,你的点赞就是我的动力!如果感觉这篇文章对你有帮助的话就请点个赞吧,感谢~
关注公众号
web前端进阶
查看完整教程
前端性能优化——启用文本压缩
前端性能优化——启用文本压缩
一、发现性能问题
1、通过 Google Chrome 打开需要进行性能优化的站点
2、打开 Chrome 开发者工具 Lighthouse 面板:
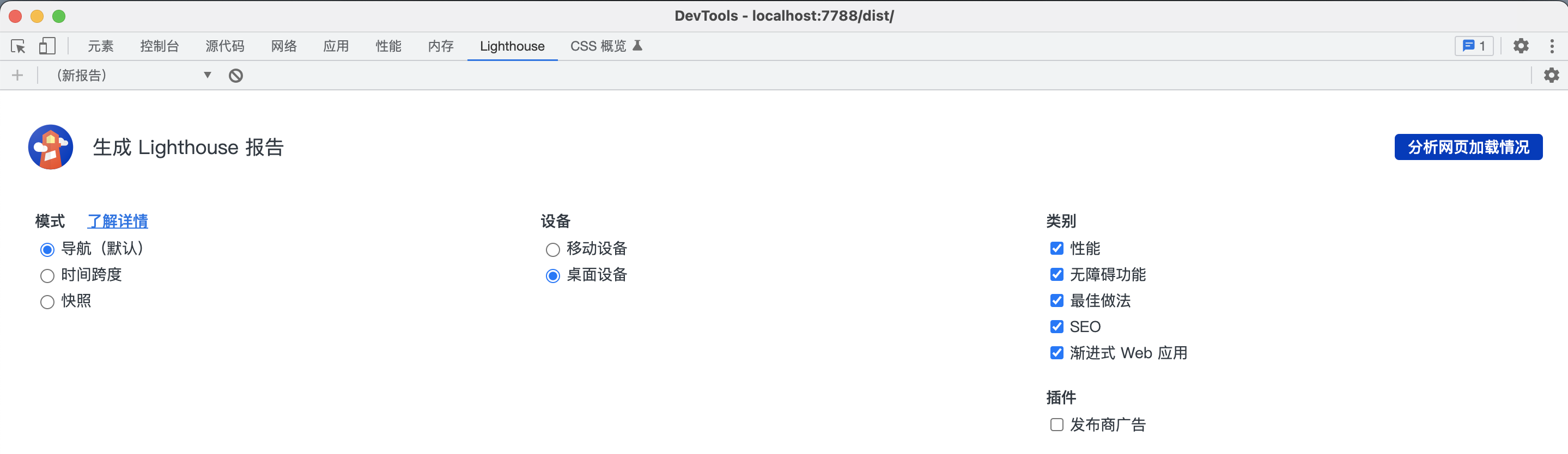
3、在 Lighthouse 面板中根据自己的需求自定义分析项和分析配置,点击”分析网页加载情况“对页面进行性能等方面的分析:
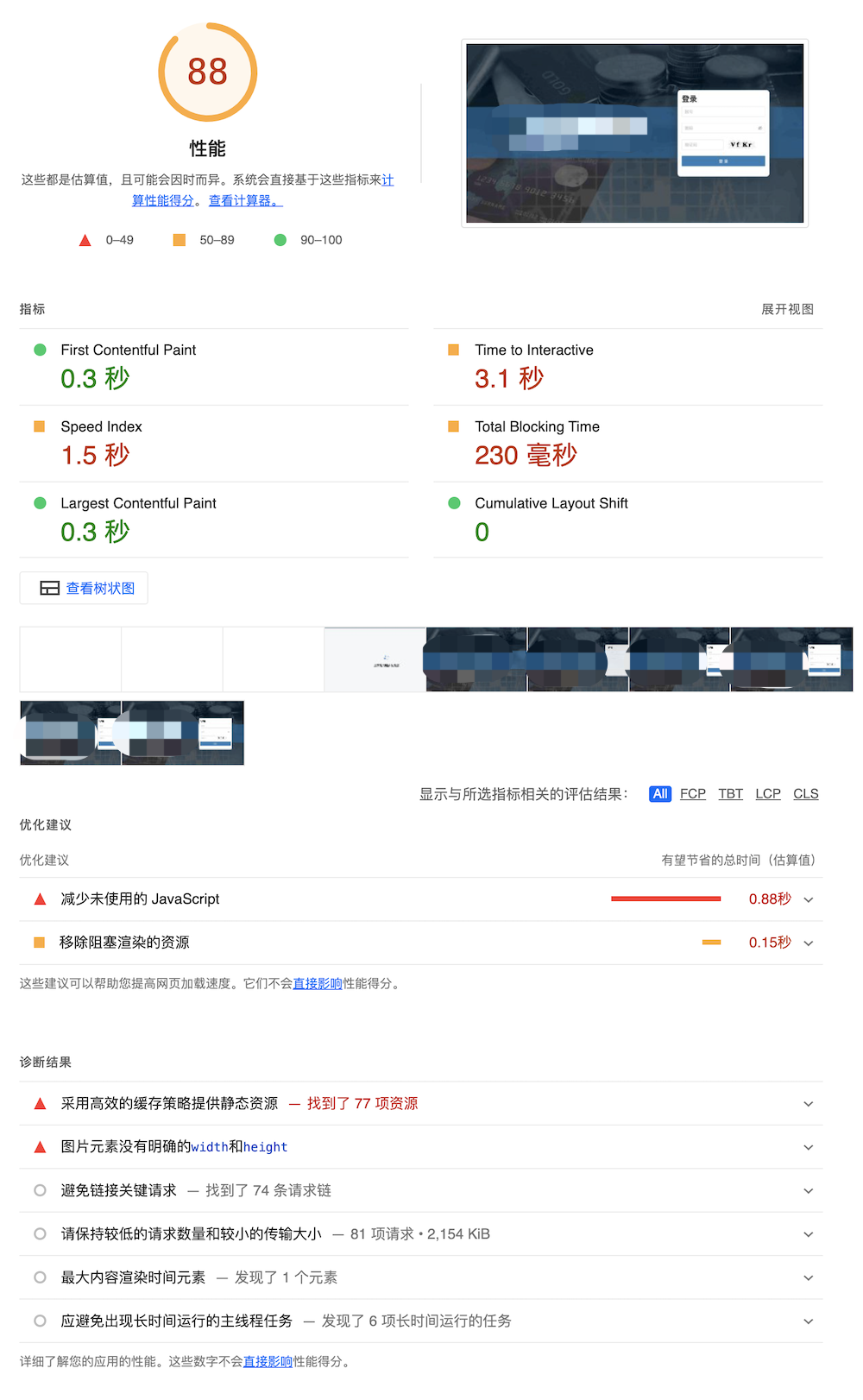
4、分析完成后如图所示:
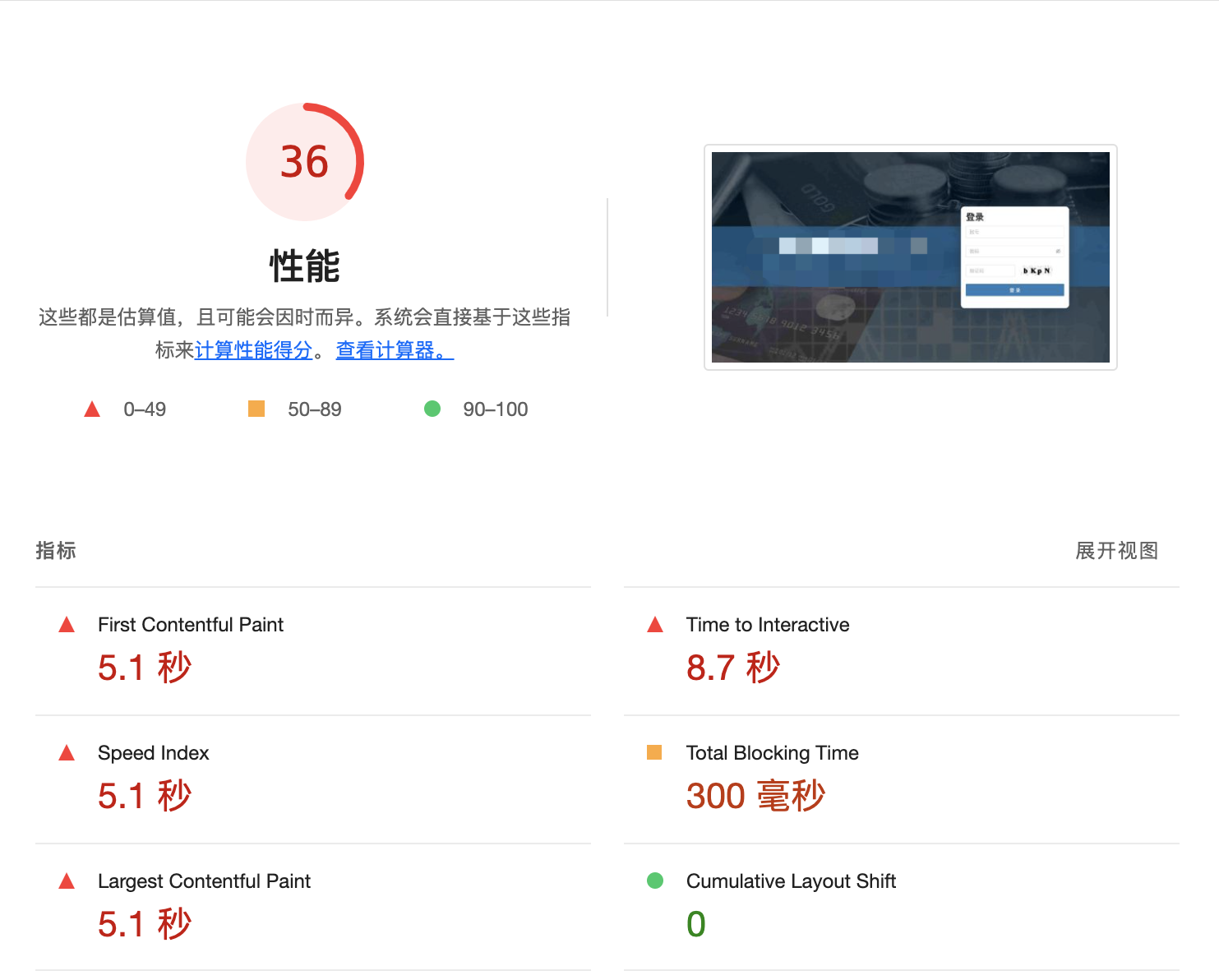
上图中展示了六个主要性能指标的数据,通过这些指标对页面的性能进行评分。上图中性能评分只有 36 分,因此该站点存在严重的性能问题。
六个主要指标的说明(可通过指标数据区域右上角的
展开视图
查看简要指标说明):
1、First Contentful Paint(FCP):首次内容渲染时间标记了渲染出首个文本或首张图片的时间。
FCP 得分说明:
FCP time(in seconds) Color-coding 0-1.8 Green(fast) 1.8-3 Orange(moderate) Over 3 Red(slow) 2、Time to Interactive(TTI):可交互时间是指网页需要多长时间才能提供完整交互功能。
TTI 得分说明:
TTI metric(in seconds) Color-coding 0-3.8 Green(fast) 3.9-7.3 Orange(moderate) Over 7.3 Red(slow) 3、Speed Index:速度指数表明了网页内容的可见填充速度。
移动端的 Speed Index 得分说明:
Speed Index(in seconds) Color-coding 0-3.4 Green(fast) 3.4-5.8 Orange(moderate) Over 5.8 Red(slow) 4、Total Blocking Time(TBT):首次内容渲染 (FCP) 和可交互时间之间的所有时间段的总和,当任务用时超过 50 毫秒时,该数值以毫秒表示。
TBT 得分说明:
TBT time(in milliseconds) Color-coding 0–200 Green(fast) 200-600 Orange(moderate) Over 600 Red(slow) 5、Largest Contentful Paint(LCP):Largest Contentful Paint 标记了渲染出最大文本或图片的时间。
LCP 得分说明:
LCP time(in seconds) Color-coding 0-2.5 Green(fast) 2.5-4 Orange(moderate) Over 4 Red(slow) 6、Cumulative Layout Shift(CLS):“累积布局偏移”旨在衡量可见元素在视口内的移动情况。
累积布局偏移 (CLS) 是测量视觉稳定性的一个以用户为中心的重要指标,因为该项指标有助于量化用户经历意外布局偏移的频率,较低的 CLS 有助于确保一个页面是令人愉悦的。
二、分析性能问题
Lighthouse 工具通过对页面的分析,影响页面性能的主要有存在未使用的 JavaScript、文本压缩未启用、网络负载过大、缓存策略等问题,如图所示:
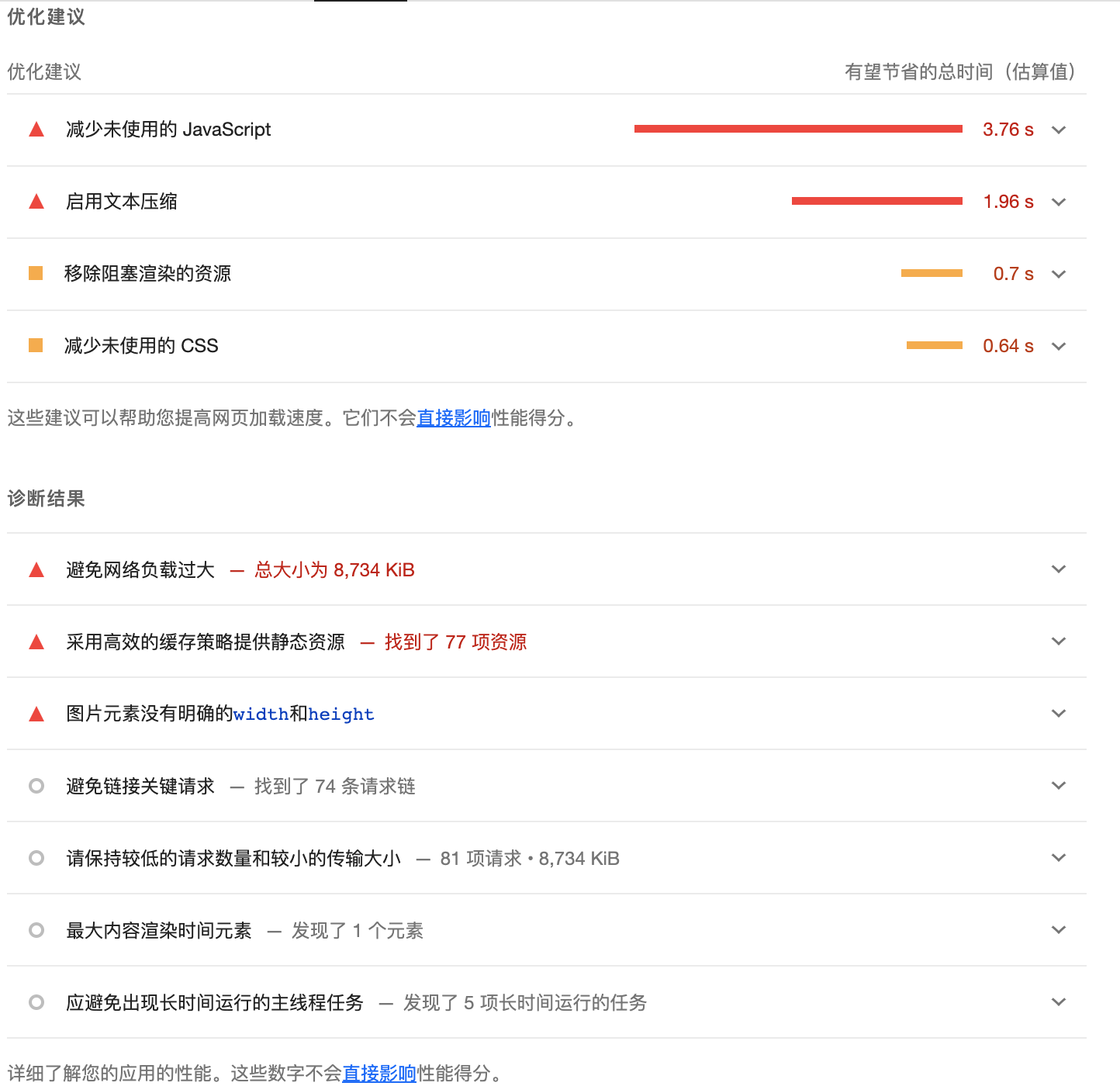
从上图可以看出,对站点性能影响最大的是存在未使用的 JavaScript,其次是文本压缩未启用,本文主要分析文本压缩问题对性能的影响。

如图可知,分析工具给出针对
未启用文本压缩
的具体优化建议是:对于文本资源,应先压缩(gzip、deflate 或 brotli),然后再提供,以最大限度地减少网络活动消耗的字节总数。
三、解决性能问题
通过启用文本压缩解决前端性能问题的主要措施有:
1、前端代码打包时启用预压缩静态文件功能
以 Vue 3 项目和 gzip 压缩为例:
# 是否启用 gzip 或 brotli 压缩
# 选项值: gzip | brotli | none
# 如果需要多个可以使用“,”分隔
VITE_BUILD_COMPRESS = 'gzip'
# 使用压缩时是否删除原始文件,默认为 false
VITE_BUILD_COMPRESS_DELETE_ORIGIN_FILE = false
2、Nginx 部署时启用 gzip 文本压缩功能
以 gzip 压缩为例:
http {
# 开启 gzip
gzip on;
# 开启 gzip_static。开启后可能会报错,需要安装相应的 gzip 压缩模块。只有开启 gzip_static,前端打包的 .gz 文件才会有效果
gzip_static on;
# 用于控制哪些响应需要进行 gzip 压缩
gzip_proxied any;
gzip_min_length 1k;
# 设置用于压缩响应的内存缓冲区的大小和数量
gzip_buffers 4 16k;
# 如果 nginx 中使用了多层代理,必须设置这个才可以开启 gzip
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
gzip_vary off;
gzip_disable "MSIE [1-6]\.";
}
gzip_static 指令用于启用预压缩静态文件功能。当启用 gzip_static 指令后,Nginx 会检查请求的文件是否存在与同名的 .gz 文件,如果存在,则直接返回 .gz 文件,否则才会进行压缩并返回压缩后的内容。
gzip_proxied 指令用于控制哪些响应需要进行 gzip 压缩。当响应满足指定条件时,将会进行 gzip 压缩,从而减小响应的大小,提高页面的加载速度,降低带宽消耗。
gzip_proxied 的可选配置项有:
- off:禁用 gzip 压缩。
- expired:对过期的响应进行 gzip 压缩。
- no-cache:对不缓存的响应进行 gzip 压缩。
- no-store:对不存储的响应进行 gzip 压缩。
- private:对私有响应进行 gzip 压缩。
- no_last_modified:不检查响应的 Last-Modified 头,仅检查 Expires 头。
- no_etag:不检查响应的 ETag 头。
- any:对所有响应进行 gzip 压缩。
这些选项可以单独使用,也可以组合使用,以逗号分隔。例如,"no-cache, no-store" 表示对不缓存和不存储的响应进行 gzip 压缩。
需要注意的是,开启 gzip 压缩会消耗一定的 CPU 资源,对于 CPU 负载较高的服务器,应谨慎使用 gzip_proxied 配置项。同时,开启 gzip 压缩还可能会导致一些浏览器和代理服务器出现兼容性问题,因此应该进行充分的测试和评估。
gzip_buffers 指令用于设置用于压缩响应的内存缓冲区的大小和数量。当启用 gzip 压缩时,Nginx 会将响应内容压缩后发送给客户端,而这个过程需要使用内存缓冲区来存储压缩后的内容,以及压缩过程中的临时数据。
gzip_comp_level 指令用于设置压缩级别(1 ~ 9)。数字越大,压缩比越高,但是压缩速度越慢。通常情况下,建议将压缩级别设置为 5 或 6,以在保证压缩比的同时,保持较快的压缩速度。
通过
前端代码打包时启用预压缩静态文件功能
和
Nginx 部署时启用 gzip 文本压缩功能
的共同处理下,页面访问性能得到明显的提升,如图所示: