计网学习笔记三 MAC与LAN
在上一讲中,我们学习了链路层可以提供的服务
在上一讲中,我们学习了链路层可以提供的服务
在本篇文章当中主要分析在 cpython 虚拟机当中 float 类型的实现原理以及与他相关的一些源代码。
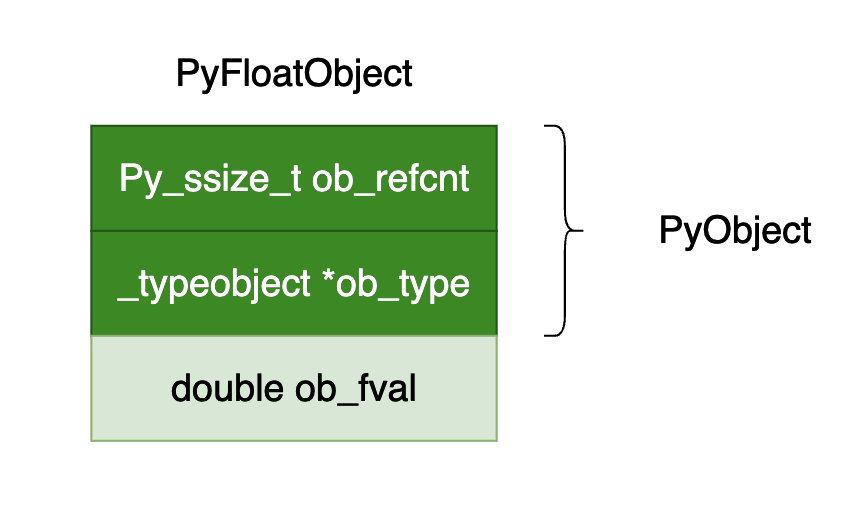
在 cpython 虚拟机当中浮点数类型的数据结构定义如下所示:
typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;
上面的数据结构定义图示如下:
和我们在前面所讨论到的元组和列表对象一样,在 cpython 内部实现 float 类型的时候也会给 float 对象做一层中间层以加快浮点数的内存分配,具体的相关代码如下所示:
#define PyFloat_MAXFREELIST 100
static int numfree = 0;
static PyFloatObject *free_list = NULL;
在 cpython 内部做多会缓存 100 个 float 对象的内存空间,如果超过 100 就会直接释放内存了,这里需要注意一点的是只用一个指针就可以将所有的 float 对象缓存起来,这一点是如何实现的。
这是使用在对象 PyFloatObject 当中的 struct _typeobject *ob_type; 这个字段实现的,用这个字段指向下一个 float 对象的内存空间,因为在 free_list 当中的数据并没有使用,因此可以利用这个特点节省一些内存空间。下面则是创建 float 对象的具体过程:
PyObject *
PyFloat_FromDouble(double fval)
{
// 首先查看 free_list 当中是否有空闲的 float 对象
PyFloatObject *op = free_list;
if (op != NULL) {
// 如果有 那么就将让 free_list 指向 free_list 当中的下一个 float 对象 并且将对应的个数减 1
free_list = (PyFloatObject *) Py_TYPE(op);
numfree--;
} else {
// 否则的话就需要申请内存空间
op = (PyFloatObject*) PyObject_MALLOC(sizeof(PyFloatObject));
if (!op)
return PyErr_NoMemory();
}
/* Inline PyObject_New */
(void)PyObject_INIT(op, &PyFloat_Type); // PyObject_INIT 这个宏的主要作用是将对象的引用计数设置成 1
op->ob_fval = fval;
return (PyObject *) op;
}
下面是在 cpython 当中浮点数的加法具体实现,整个过程比较简单就是得到新的值,并且创建一个新的 PyFloatObject 对象,并且将这个对象返回。
static PyObject *
float_add(PyObject *v, PyObject *w)
{
double a,b;
CONVERT_TO_DOUBLE(v, a); // CONVERT_TO_DOUBLE 这个宏的主要作用就是将对象的 ob_fval 这个字段的值保存到 a 当中
CONVERT_TO_DOUBLE(w, b); // 这个就是将 w 当中的 ob_fval 字段的值保存到 b 当中
a = a + b;
return PyFloat_FromDouble(a); // 创建一个新的 float 对象 并且将这个对象返回
}
同理减法也是一样的。
static PyObject *
float_sub(PyObject *v, PyObject *w)
{
double a,b;
CONVERT_TO_DOUBLE(v, a);
CONVERT_TO_DOUBLE(w, b);
a = a - b;
return PyFloat_FromDouble(a);
}
static PyObject *
float_mul(PyObject *v, PyObject *w)
{
double a,b;
CONVERT_TO_DOUBLE(v, a);
CONVERT_TO_DOUBLE(w, b);
PyFPE_START_PROTECT("multiply", return 0)
a = a * b;
PyFPE_END_PROTECT(a)
return PyFloat_FromDouble(a);
}
static PyObject *
float_div(PyObject *v, PyObject *w)
{
double a,b;
CONVERT_TO_DOUBLE(v, a);
CONVERT_TO_DOUBLE(w, b);
if (b == 0.0) {
PyErr_SetString(PyExc_ZeroDivisionError,
"float division by zero");
return NULL;
}
a = a / b;
return PyFloat_FromDouble(a);
}
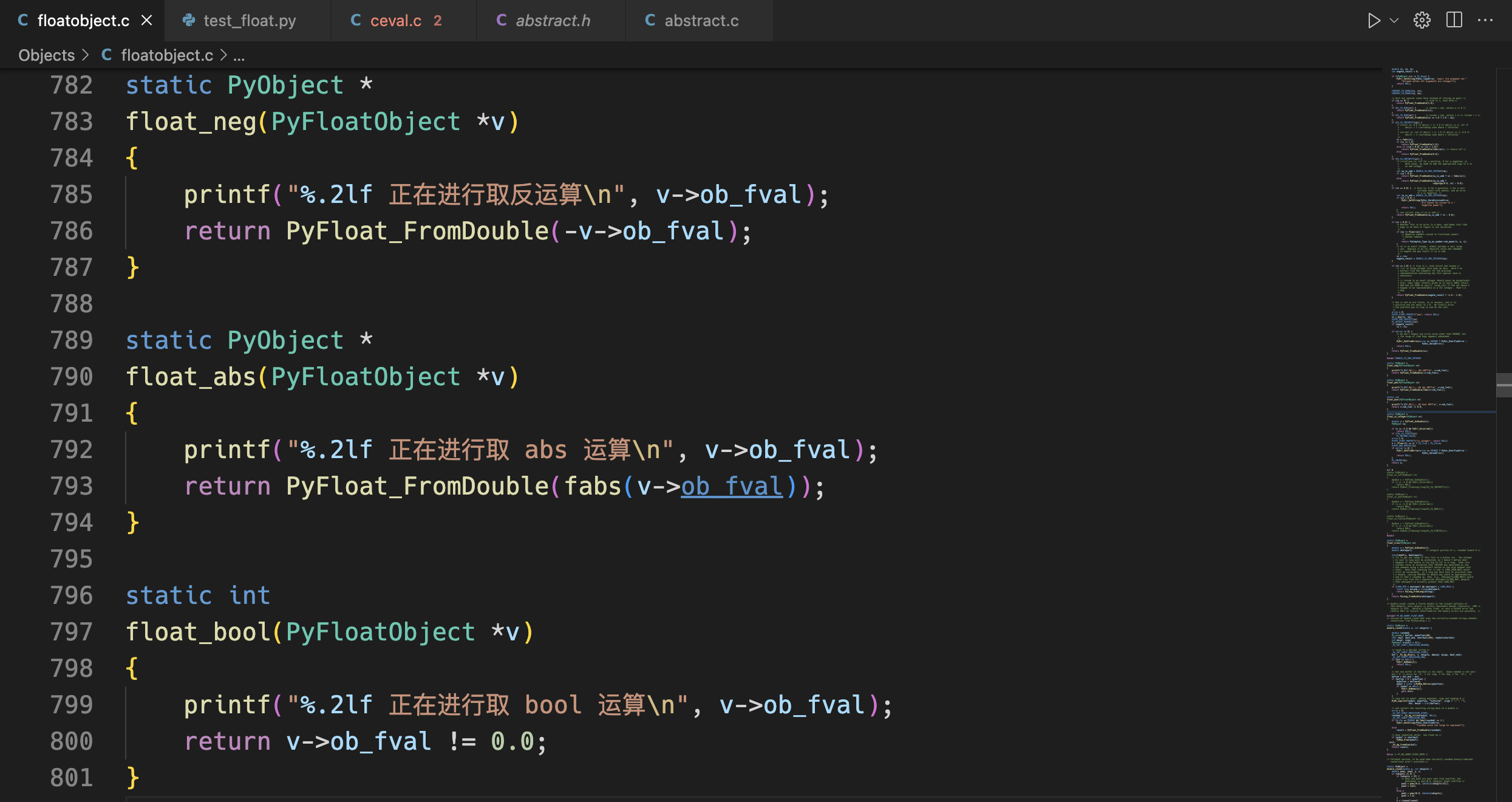
这里加入了一行输出语句,这个是为了后面方便我们进行测试的。
static PyObject *
float_neg(PyFloatObject *v)
{
printf("%.2lf 正在进行取反运算\n", v->ob_fval);
return PyFloat_FromDouble(-v->ob_fval);
}
static PyObject *
float_abs(PyFloatObject *v)
{
printf("%.2lf 正在进行取 abs 运算\n", v->ob_fval);
return PyFloat_FromDouble(fabs(v->ob_fval));
}
static int
float_bool(PyFloatObject *v)
{
printf("%.2lf 正在进行取 bool 运算\n", v->ob_fval);
return v->ob_fval != 0.0;
}
下图是我们对于 cpython 对程序的修改!
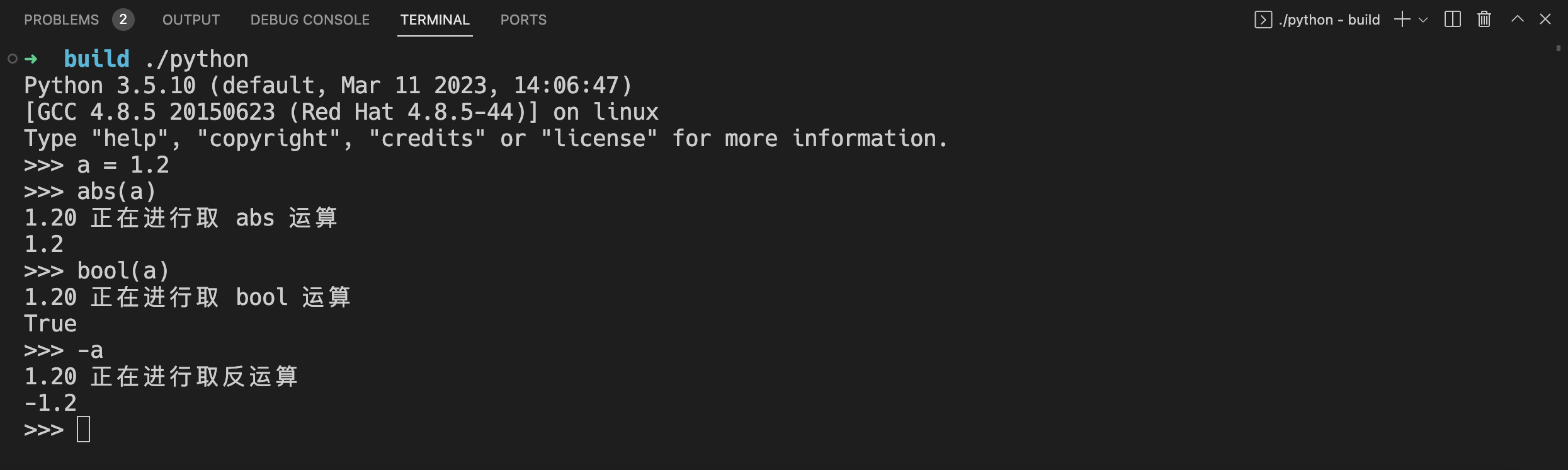
下面是修改之后我们再次对浮点数进行操作的时候的输出,可以看到的是输出了我们在上面的代码当中加入的语句。
在本篇文章当总主要介绍了一些 float 类型在 cpython 内部是如何实现的以及和他相关的加减乘除方法是如何实现的,以及和部分和关键字有关的函数实现。本篇文章主要是讨论 float 数据类型本身,不涉及其他的东西,其实关于类型还有非常大一块,就是 cpython 内部对象系统是如何实现的,这一点在后面深入讨论对象系统的时候再进行深入分析,在回头来看 float 类型会有更加深刻的理解。
本篇文章是深入理解 python 虚拟机系列文章之一,文章地址:
https://github.com/Chang-LeHung/dive-into-cpython
更多精彩内容合集可访问项目:
https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
转载请注明出处❤️
作者:
测试蔡坨坨
原文链接:
caituotuo.top/e8aa6c6f.html
你好,我是测试蔡坨坨。
前几天在使用Selenium进行元素拖拽操作时,发现Selenium自带的元素拖拽方法(dragAndDrop())不生效,网上的回答也是五花八门,比较混乱,尝试了
以下几种方法均无法解决
。
方案1:通过dragAndDrop()方法将元素拖放到特定区域上——无效
// 要拖拽的元素
WebElement draggable = driver.findElement(By.xpath(""));
// 目标元素/区域
WebElement droppable = driver.findElement(By.xpath(""));
new Actions(driver).dragAndDrop(draggable, droppable).build().perform();
方案2:通过dragAndDropBy()方法将元素进行指定像素位移,从而实现拖放到特定区域,该方法需要先找到元素的像素——无效
new Actions(driver).dragAndDropBy(draggable,135, 40).build().perform();
方案3:先通过clickAndHold()方法点击并按住元素,然后使用moveByOffset()方法将元素拖拽到目标区域,再使用release()方法将按住的元素释放——无效
new Actions(driver).clickAndHold(draggable).moveByOffset(400, 0).release().build().perform();
方案4:先通过clickAndHold()方法点击并按住元素,然后使用moveToElement()方法将元素拖拽到指定元素上,再使用release()方法将元素释放——无效
new Actions(driver).clickAndHold(draggable).moveToElement(droppable).release(droppable).build().perform();
方案5:借助Robot类实现拖拽——无效
Point coordinates1 = draggable.getLocation();
Point coordinates2 = droppable.getLocation();
Robot robot = new Robot();
robot.mouseMove(coordinates1.getX(), coordinates1.getY());
robot.mousePress(InputEvent.BUTTON1_MASK);
robot.mouseMove(coordinates2.getX(), coordinates2.getY());
robot.mouseRelease(InputEvent.BUTTON1_MASK);
……
以上方案均未生效,具体表现为运行均无任何报错,但在应用程序中未发生拖放。
经过一顿操作,最终在「
Selenium Drag and Drop Bug Workaround
」上找到了问题原因及解决方案。
经了解,Selenium的拖放功能在某些情况下无效的错误已经存在多年。
原因是拖放功能包含三个动作:单击并按住(click and hold)、将鼠标移动到其他元素或位置(move mouse to other element/location)、释放鼠标(release mouse),问题在于最后一步释放鼠标的操作,当Webdriver API发送释放鼠标的请求时,在某些情况下它会一直按住它,所以导致拖放功能无效。
解决方法就是通过Webdriver API将JavaScript代码发送到浏览器,利用JavaScript模拟拖放操作,而不使用Webdriver自带的拖放方法。
其工作原理是将浏览器实例和CSS选择器找到的两个Web元素作为参数,然后在浏览器端执行JavaScript代码。
如果你是使用Python+Selenium技术栈实现的Web UI自动化,可以直接下载
seletools
(Selenium Tools,作者:Dmitrii Bormotov)包,并将它导入到需要执行拖放的地方,然后简单地调用它的drag_and_drop()方法即可。
pip install seletools
from seletools.actions import drag_and_drop
source = driver.find_element(By.CSS_SELECTOR, "#column-a")
target = browser.find_element(By.CSS_SELECTOR, "#column-b")
drag_and_drop(driver, source, target)
如果使用的是Java+Selenium技术栈,则可以使用以下代码实现:
// 要拖拽的元素
WebElement draggable = driver.findElement(By.xpath(""));
// 目标元素
WebElement droppable = driver.findElement(By.xpath(""));
// 拖动前先点击并按住要拖拽的元素,避免在elementui,拖放前draggable属性才会变成true,目的是让draggable变成true,如果一开始就是true也可不加这句
new Actions(driver).clickAndHold(draggable).perform();
final String java_script = "var args = arguments," + "callback = args[args.length - 1]," + "source = args[0]," + "target = args[1]," + "offsetX = (args.length > 2 && args[2]) || 0," + "offsetY = (args.length > 3 && args[3]) || 0," + "delay = (args.length > 4 && args[4]) || 1;" + "if (!source.draggable) throw new Error('Source element is not draggable.');" + "var doc = source.ownerDocument," + "win = doc.defaultView," + "rect1 = source.getBoundingClientRect()," + "rect2 = target ? target.getBoundingClientRect() : rect1," + "x = rect1.left + (rect1.width >> 1)," + "y = rect1.top + (rect1.height >> 1)," + "x2 = rect2.left + (rect2.width >> 1) + offsetX," + "y2 = rect2.top + (rect2.height >> 1) + offsetY," + "dataTransfer = Object.create(Object.prototype, {" + " _items: { value: { } }," + " effectAllowed: { value: 'all', writable: true }," + " dropEffect: { value: 'move', writable: true }," + " files: { get: function () { return undefined } }," + " types: { get: function () { return Object.keys(this._items) } }," + " setData: { value: function (format, data) { this._items[format] = data } }," + " getData: { value: function (format) { return this._items[format] } }," + " clearData: { value: function (format) { delete this._items[format] } }," + " setDragImage: { value: function () { } }" + "});" + "target = doc.elementFromPoint(x2, y2);" + "if(!target) throw new Error('The target element is not interactable and need to be scrolled into the view.');" + "rect2 = target.getBoundingClientRect();" + "emit(source, 'dragstart', delay, function () {" + "var rect3 = target.getBoundingClientRect();" + "x = rect3.left + x2 - rect2.left;" + "y = rect3.top + y2 - rect2.top;" + "emit(target, 'dragenter', 1, function () {" + " emit(target, 'dragover', delay, function () {" + "\ttarget = doc.elementFromPoint(x, y);" + "\temit(target, 'drop', 1, function () {" + "\t emit(source, 'dragend', 1, callback);" + "});});});});" + "function emit(element, type, delay, callback) {" + "var event = doc.createEvent('DragEvent');" + "event.initMouseEvent(type, true, true, win, 0, 0, 0, x, y, false, false, false, false, 0, null);" + "Object.defineProperty(event, 'dataTransfer', { get: function () { return dataTransfer } });" + "element.dispatchEvent(event);" + "win.setTimeout(callback, delay);" + "}";
// 默认拖拽到中心点位置,第3个参数是X坐标偏移量(左负右正),第4个参数为Y坐标偏移量(上负下正),第5个参数是延迟时间(单位为毫秒,表示当鼠标点下后,延迟指定时间后才开始激活拖拽动作,用来防止误点击)
((JavascriptExecutor) driver).executeScript(java_script, draggable, droppable, -200, -300, 500);
以上就是在Python和Java中的解决方案,至于为什么不在Selenium中直接修改程序,而是创建单独的包来处理,以下是Dmitrii Bormotov的说法:
The drag and drop bug is a webdriver issue, so all you can do on the Selenium side is to simply perform the same workaround that I did. I spoke with David Burnes (core Selenium committer) about pushing that workaround into Selenium, but he said that it is not a good idea to have any workarounds in Selenium itself. That is why I had to create a separate package to help the test automation community with this problem.
大概的意思就是拖放错误是一个webdriver网络驱动问题,David Burnes(核心 Selenium 提交者)认为在Selenium中提供任何暂时避开网络的方法并不是一个好主意。
对于简单的模型,可以采用直接遍历子模块的方法,取出相应name模块的输出,不对模型做任何改动。该方法的缺点在于,
只能得到其子模块的输出
,而对于使用nn.Sequensial()中包含很多层的模型,
无法获得其指定层的输出
。
示例 resnet18取出layer1的输出
from torchvision.models import resnet18
import torch
model = resnet18(pretrained=True)
print("model:", model)
out = []
x = torch.randn(1, 3, 224, 224)
return_layer = "layer1"
for name, module in model.named_children():
x = module(x)
if name == return_layer:
out.append(x.data)
break
print(out[0].shape) # torch.Size([1, 64, 56, 56])torchvison中提供了IntermediateLayerGetter类,该方法同样
只能得到其子模块的输出
,而对于使用nn.Sequensial()中包含很多层的模型,
无法获得其指定层的输出
。
from torchvision.models._utils import IntermediateLayerGetter
IntermediateLayerGetter类的pytorch源码
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Args:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
"""
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()}
# 重新构建backbone,将没有使用到的模块全部删掉
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x: Tensor) -> Dict[str, Tensor]:
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out示例 使用
IntermediateLayerGetter类 改
resnet34+unet 完整代码见
gitee
import torch
from torchvision.models import resnet18, vgg16_bn, resnet34
from torchvision.models._utils import IntermediateLayerGetter
model = resnet34()
stage_indices = ['relu', 'layer1', 'layer2', 'layer3', 'layer4']
return_layers = dict([(str(j), f"stage{i}") for i, j in enumerate(stage_indices)])
model= IntermediateLayerGetter(model, return_layers=return_layers)
input = torch.randn(1, 3, 224, 224)
output = model(input)
print([(k, v.shape) for k, v in output.items()])使用create_feature_extractor方法,创建一个新的模块,该模块将给定模型中的中间节点作为字典返回,用户指定的键作为字符串,请求的输出作为值。该方法比 IntermediateLayerGetter方法更通用,
不局限于获得模型第一层子模块的输出
。比如下面的vgg,池化层都在子模块feature中,上面的方法无法取出,因此推荐使用create_feature_extractor方法。
示例 FCN论文中以vgg为backbone,分别取出三个池化层的输出
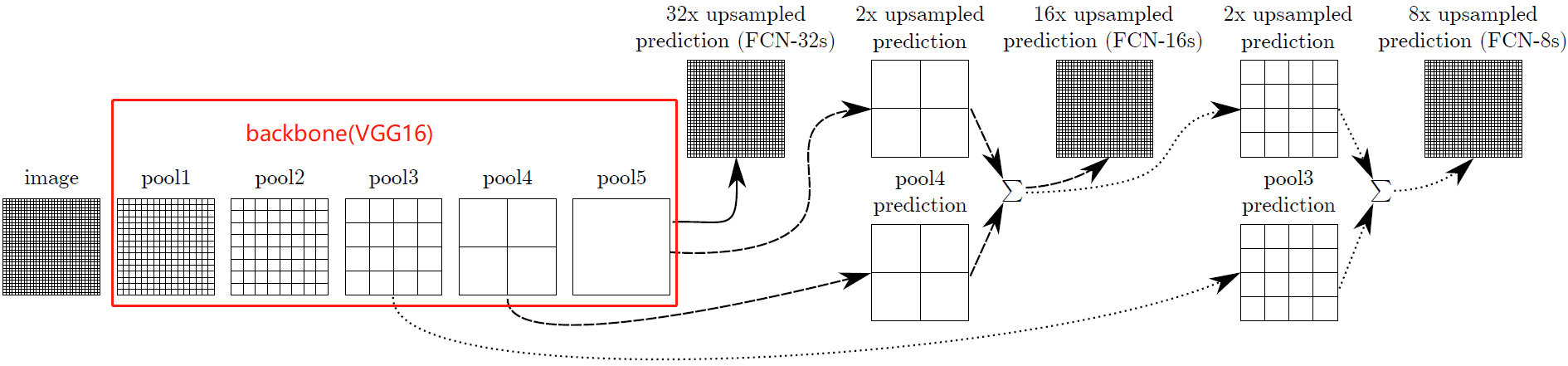
import torch
from torchvision.models import vgg16_bn
from torchvision.models.feature_extraction import create_feature_extractor
model = vgg16_bn()
model = create_feature_extractor(model, {"features.43": "pool5", "features.33": "pool4", "features.23": "pool3"})
input = torch.randn(1, 3, 224, 224)
output = model(input)
print([(k, v.shape) for k, v in output.items()])hook函数
是程序中预定义好的函数,这个函数处于原有程序流程当中(暴露一个钩子出来)。我们需要再在有流程中钩子定义的函数块中实现某个具体的细节,需要把我们的实现,挂接或者注册(register)到钩子里,使得hook函数对目标可用。hook 是一种编程机制,和具体的语言没有直接的关系。
Pytorch的hook编程可以在
不改变网络结构
的基础上有效获取、改变模型中间变量以及梯度等信息。在pytorch中,Module对象有register_forward_hook(hook) 和 register_backward_hook(hook) 两种方法,两个的操作对象都是nn.Module类,如神经网络中的卷积层(nn.Conv2d),全连接层(nn.Linear),池化层(nn.MaxPool2d, nn.AvgPool2d),激活层(nn.ReLU)或者nn.Sequential定义的小模块等。
register_forward_hook
是获取前向传播的输出的,即特征图或激活值
;
register_backward_hook
是获取反向传播的输出的,即梯度值
。(这边只讲register_forward_hook,其余见
链接
)
示例 获取resnet18的avgpool层的输入输出
import torch
from torchvision.models import resnet18
model = resnet18()
fmap_block = dict() # 装feature map
def forward_hook(module, input, output):
fmap_block['input'] = input
fmap_block['output'] = output
layer_name = 'avgpool'
for (name, module) in model.named_modules():
if name == layer_name:
module.register_forward_hook(hook=forward_hook)
input = torch.randn(64, 3, 224, 224)
output = model(input)
print(fmap_block['input'][0].shape)
print(fmap_block['output'].shape)
参考
2.
Pytorch的hook技术——获取预训练/已训练好模型的特定中间层输出
在平时的业务中,我们很多使用都会有文件上传这个功能。
今天分享一下使用 node+element-ui实现一下文件上传。
请个人大佬指点一番~~~。批评的时候稍微轻一点。
毕竟我心里承受能力弱地一批,一不高兴就喜欢....
前端上传文件的时候,我们通常file对象。
较小的图片的当然也可以使用base64的方式进行上传。
等会我们将会将file转化为base64。
file对象传参的时候是这样的 file:file(二进制对象)
并且'Content-type': 'multipart/form-data'
下面我们使用 element-ui 的el-upload 组件进行文件上传.
我们会使用 http-request 自定义事件覆盖原来的事件。
请看下面的代码
<template>
<div>
<h2>文件上传</h2>
<el-upload class="upload-demo" action="https"
:http-request="uploadFile">
<el-button size="small" type="primary">点击上传</el-button>
</el-upload>
</div>
</template>
<script>
import axios from 'axios'
export default {
methods: {
uploadFile(file) {
console.log('file对象', file)
axios.post('http://127.0.0.1:666/upload/upload',
{
file:file
}, {
'Content-type': 'multipart/form-data'
}
).then(function (response) {
console.log(response);
}).catch(function (error) {
console.log(error);
});
}
}
}
</script>
写过很多文件上传的的小伙伴。
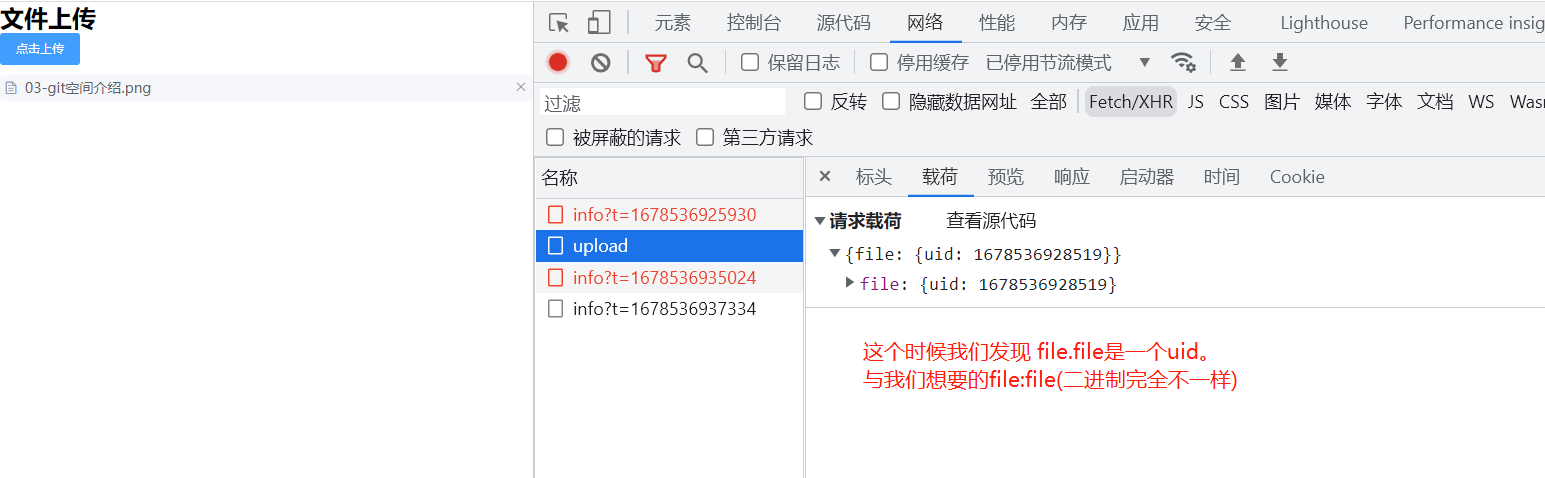
你们觉得可以上传成功吗?
会是file:file(二进制)对象吗?
凭借自己的感觉想一分钟,然后下滑
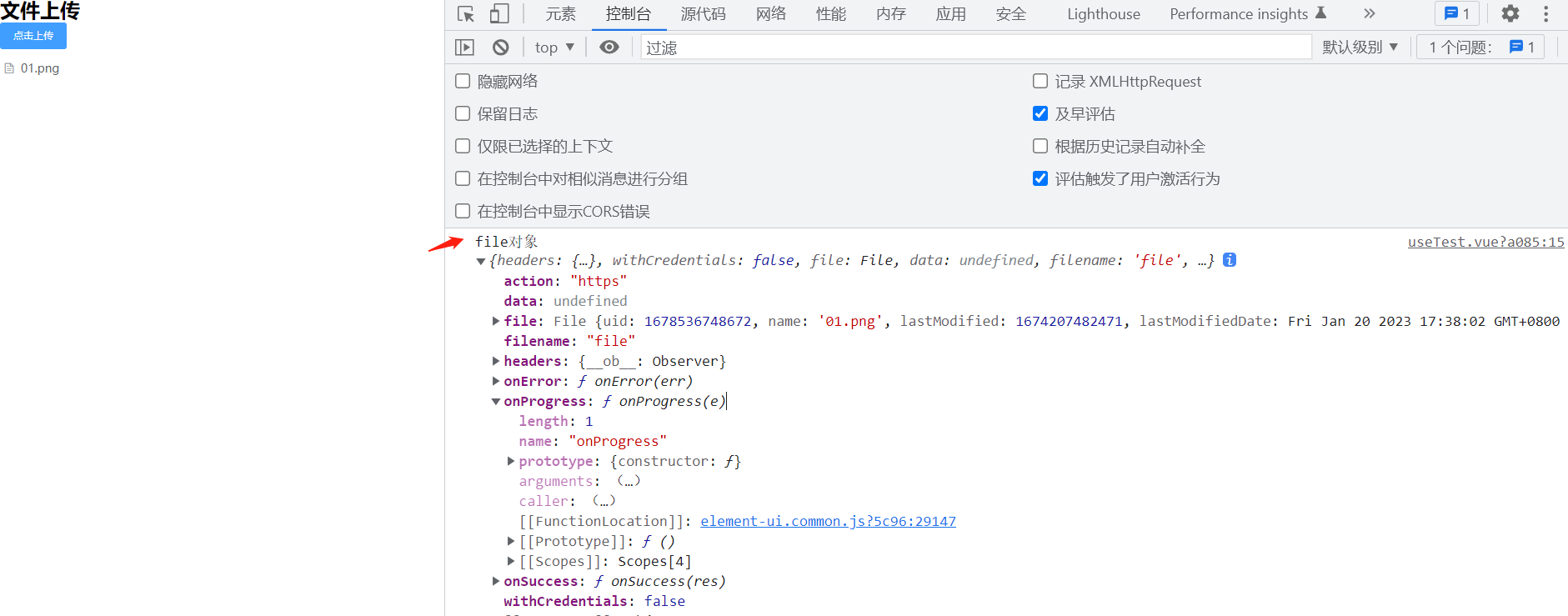

有的小伙伴会说 你传的时候不应该是file,应该是file.file
因为从你刚刚的截图来看应该是:file.file才是我们需要的。
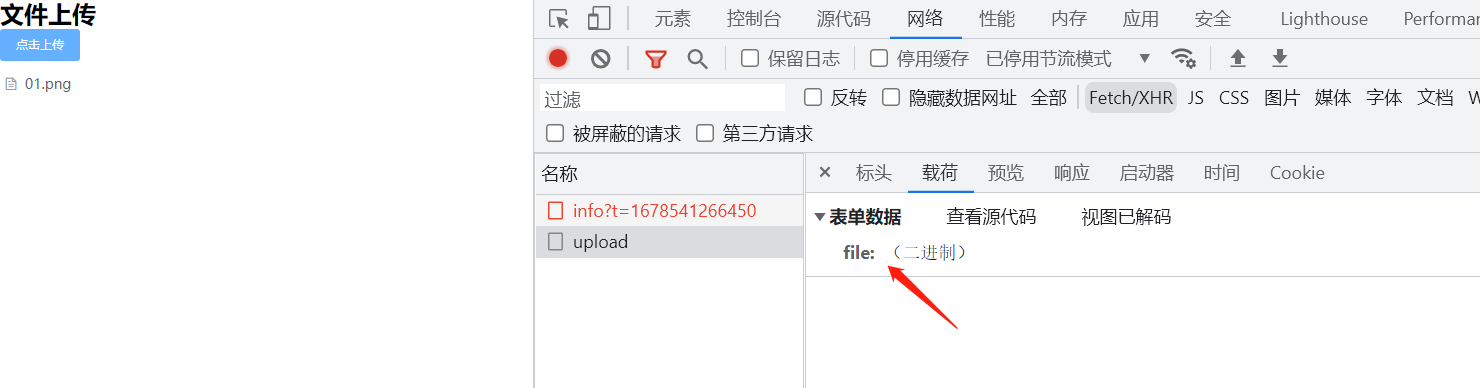
感觉说的有道理,我们尝试一下。
FormData是XMLHttpRequest提供的一个接口对象,
用以将数据编译成键值对,以便于XMLHttpRequest来发送数据。
创建一个 FormData对象,并添加属性。
FormData 可以通过 append(key, value)来添加数据。
上面说了 FormData的简单介绍。
并没有说为啥FormData可以使用解决这个这个问题?
那为什么FormData可以解决这个问题了?
因为:
File 接口基于 Blob,继承 blob 功能并将其扩展为支持用户系统上的文件。
你可以通过 Blob() 构造函数创建一个 Blob 对象。
而 FormData 对象附加 File 或 Blob 类型的文件,所以我们可以添加。
<script>
import axios from 'axios'
export default {
methods: {
uploadFile(file) {
let formdata = new FormData();
console.log(file);
formdata.append("file", file.file);
axios.post('http://127.0.0.1:666/upload/upload',
formdata, {
'Content-type': 'multipart/form-data'
}
).then(function (response) {
console.log(response);
}).catch(function (error) {
console.log(error);
});
}
}
}
</script>
<template>
<div>
<!-- accept 接收图片格式 -->
<input type="file" title="" ref="inputRef"
accept=".jpeg,.png, .gif,.jpg" @change="Upload">
</div>
</template>
<script>
import axios from 'axios'
export default {
methods: {
// 文件上传被触发
Upload(event) {
const flie = event.target.files[0]; //直接获取的就是file对象
this.fileChangeBase64(flie).then(backres => {
console.log('base64', backres)
// 上传成功后的处理,清除input中value值,否则只相同文件只能够上传一次
// this.$refs.inputRef.value = ""; 在合适的时候使用
}).catch(err => {
console.log('err', err )
})
},
// 将file对象转化为base64
fileChangeBase64(file) {
return new Promise((resolve, reject) => {
//FileReader类就是专门用来读文件的,我们现在创建一个
const reader = new FileReader()
// 它的本质就是图片的二进制数据, 进行base64加密后形成的一个字符串.
reader.readAsDataURL(file)
// 成功返回对应的信息,reader.result一个base64
reader.onload = () => resolve(reader.result)
// 失败返回失败的信息
reader.onerror = error => reject(error)
})
}
}
}
</script>
需要注意的一点,我这里是将file转为base64哈。
base64将不会不能被multer处理的哈~或者说不能够处理
前端代码已经写好了,现在我们开始写后端的代码,后端我们使用node+express
multer 是一个 node.js 中间件。
它用于处理 multipart/form-data 类型的表单数据,它主要用于上传文件。
需要注意的是: multer 不会处理任何非 multipart/form-data 类型的表单数据。
换一句换说:前端必须这样设置类型 'Content-type': 'multipart/form-data'
guthub官方解释链接
https://github.com/expressjs/multer/blob/master/doc/README-zh-cn.md
前端代码写好了,现在我们开始借助node来实现后端的代码
我们使用 multer 来进行文件传
第一步:先下载 multer 模块
npm i express multer -S
我下载的时候是1.4.5版本
// 引入express
var express = require('express')
//添加路由模块
var router = express.Router()
// 文件上传需要的模块
var multer=require('multer')
// 配置路径和文件名
var storage = multer.diskStorage({
//上传文件到服务器的存储位置
destination: 'public/upload',
filename: function (req, file, callback) {
//上传的文件信息
console.log('file', file)
/**
* file {
fieldname: 'file',
originalname: 'JRMW5Y~E5B%UO4$EZ)[)XLR.png',
encoding: '7bit',
mimetype: 'image/png'
}
*/
// 将字符串分割成为数组,以点.的形式进行分割。返回的是一个数组
var fileFormat = (file.originalname).split('.')
// 获取时间戳
var filename = new Date().getTime()
// 文件的命名为:时间戳 + 点 + 文件的后缀名
callback(null, filename + "." + fileFormat[fileFormat.length-1])
}
})
var upload = multer({
storage
})
router.post('/upload', upload.single('file'), (req, res) => {
res.send({ code:'0', msg:'上传成功'})
})
module.exports = router;
// 引入
var uploadRouter = require('./routes/fileupload');
// ... 其他代码....
//注册接口前缀/upload
app.use('/upload', uploadRouter);
//这个时候接口就是 /upload/upload

1. 需要注意的点:upload.single('key') 必须要与前端中
formData.append("file", flie)key键名保持一致。
2. 为什么不直接使用前端传递传来的名称?
因为有可能名称会重复,这样不好。
3. 因为前端上传文件的时候使用change事件进行监听的。
注意在合适的时候清除它的value值,否者上传相同的文件change事件不会被触发