一、解决bug:Selenium with PhantomJS,重构SeleniumeDownloader底层浏览器驱动
0、小背景:
想爬取外网steam的数据,但是steam官网在海外,加上steam处于反爬考虑,对于异步数据-json数据进行处理,导致如果直接去拿人家的ajax接口作为请求url进行爬取就爬取得到一堆乱码的没用数据。---解决:使用Selenium 模拟用户使用浏览器(通过js渲染),然后再解析处理selenium下载器下载下来的数据。
但是一开始,项目中selenium底层是使用phantomjs 作为驱动器(浏览器),出现了如下的一系列:
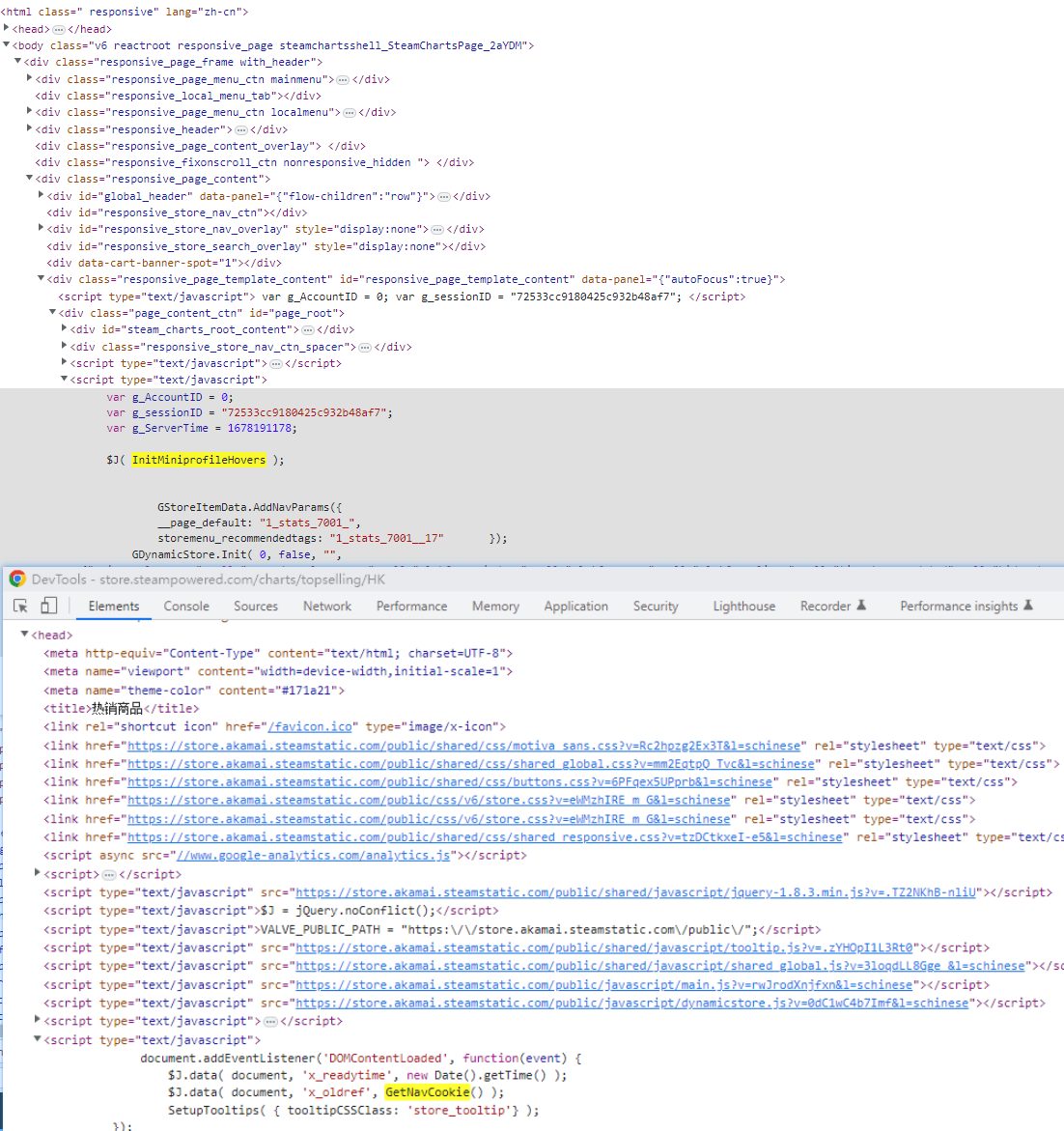
1、bug 截图

[ERROR - 2023-03-07T12:00:29.232Z] Session [258893b0-bcdf-11ed-9fc2-3f99c08d4ed8] - page.onError - msg: ReferenceError: Can't find variable: InitMiniprofileHovers
phantomjs://platform/console++.js:263 in error
[ERROR - 2023-03-07T12:00:29.233Z] Session [258893b0-bcdf-11ed-9fc2-3f99c08d4ed8] - page.onError - stack:
global code (https://store.steampowered.com/charts/topselling/SG:671)
phantomjs://platform/console++.js:263 in error
[ERROR - 2023-03-07T12:00:30.743Z] Session [258893b0-bcdf-11ed-9fc2-3f99c08d4ed8] - page.onError - msg: ReferenceError: Can't find variable: WebStorage
phantomjs://platform/console++.js:263 in error
[ERROR - 2023-03-07T12:00:30.744Z] Session [258893b0-bcdf-11ed-9fc2-3f99c08d4ed8] - page.onError - stack:
(anonymous function) (https://store.st.dl.eccdnx.com/public/shared/javascript/shared_responsive_adapter.js?v=TNYlyRmh1mUl&l=schinese&_cdn=china_eccdnx:43)
l (https://store.st.dl.eccdnx.com/public/shared/javascript/jquery-1.8.3.min.js?v=.TZ2NKhB-nliU&_cdn=china_eccdnx:2)
fireWith (https://store.st.dl.eccdnx.com/public/shared/javascript/jquery-1.8.3.min.js?v=.TZ2NKhB-nliU&_cdn=china_eccdnx:2)
ready (https://store.st.dl.eccdnx.com/public/shared/javascript/jquery-1.8.3.min.js?v=.TZ2NKhB-nliU&_cdn=china_eccdnx:2)
A (https://store.st.dl.eccdnx.com/public/shared/javascript/jquery-1.8.3.min.js?v=.TZ2NKhB-nliU&_cdn=china_eccdnx:2)
phantomjs://platform/console++.js:263 in error
[ERROR - 2023-03-07T12:00:30.746Z] Session [258893b0-bcdf-11ed-9fc2-3f99c08d4ed8] - page.onError - msg: ReferenceError: Can't find variable: GetNavCookie
2、待爬取的页面是存在该变量的:InitMiniprofileHovers、GetNavCookie
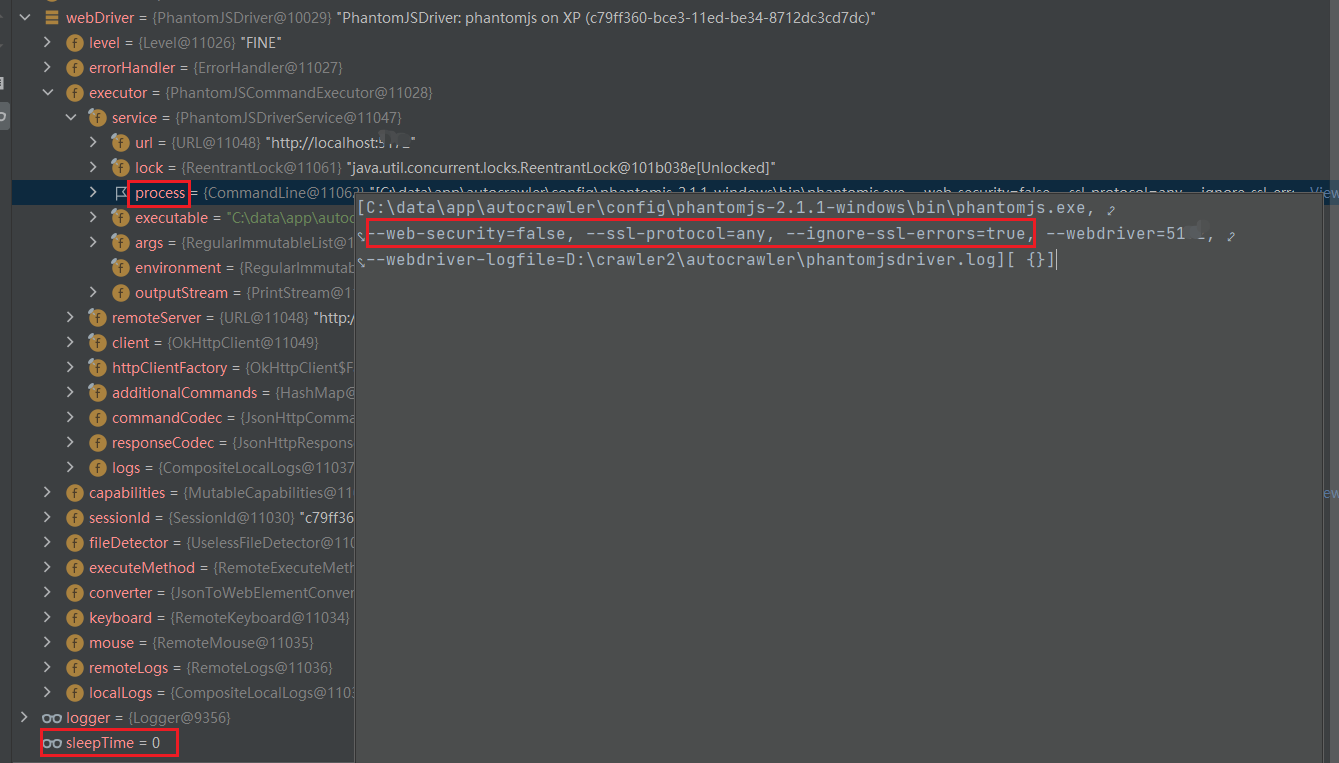
3、调试-核心步骤
Page page = downloader.download(request, this);//爬虫任务的下载器,开始下载页面
//获取到web驱动器
webDriver = webDriverPool.get();
//驱动器下载页面
webDriver.get(request.getUrl());//这里出错
▪ webDriver变量的情况:
this.execute("get", ImmutableMap.of("url", url));//执行下载命令
response = this.executor.execute(command);//响应体,即执行命令后的结果
//command 只是一个封装了sessionId, driverCommand-get, 请求参数url的对象
Response var2 = super.execute(command);
...
4、分析错误原因:
报错原因:是phantomis设计的不够合理: 在页面寻找不到dom元素的时候,合理设计应该返回nul,而不应该throw异常。
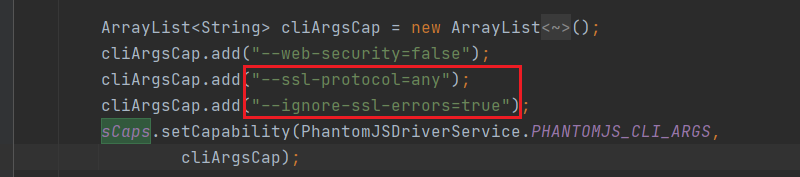
网友的错误原因--加密方式,理由:PhantomJS使用的加密方式是SSLv3,有些网站用的是TLS。
解决加密问题的方法:--ignore-ssl-errors=true 和 --ssl-protocol=any
▷ 自己的项目中的 web驱动器/浏览器(排除加密方式的原因):
5、小心得:
phantomjs在对ES6的支持上天生有坑,前端使用ES6的网站都不建议用phantomis去跑。
6、解决:使用 chrome 代替 PhantomJS
7、新的问题:chrome 解析外网的时候,不稳定
- 解决---vpn
- 现在思路就变成了Selenium 在调用浏览器 chrome 的时候,开vpn,默认集成到 Selenium中的浏览器,都是普通纯净的浏览器。
发现微软的浏览器Edge 打开steam 官网,不开vpn,也很流畅,不过要是steam的链接带上地理位置,例如香港,又打不开了,解决:vpn
二、改写Selenium的浏览器-目的为了添加代理
1、基本思路:先理清业务的逻辑
发现,在项目调用完爬虫框架的调度器后,下载器开始发挥作用。
case CHROME:
if (isWindows) {
System.setProperty("selenuim_config", "C:\\data\\config\\config-chrome.ini");
SeleniumDownloader seleniumDownloader = new SeleniumDownloader("C:\\data\\config\\chromedriver.exe");
// 浏览器打开10s后才开始爬取数据
seleniumDownloader.setSleepTime(10 * 1000);
autoSpider.setDownloader(seleniumDownloader);
}
业务中,我们是通过了创建了SeleniumDownloader的下载器来下载页面,但是确定就是底层的浏览器是纯净普通版的浏览器。
看到业务在创建SeleniumDownloader的下载器的时候,给它注入了一个配置文件config-chrome.ini,
2、个人解决思路1:考虑把代理的options 也通过这个配置文件注入
但是发现这个配置文件是一个启动文件,里面并没options的属性可以配置。
启动文件的配置,没法实现
3、个人解决思路2:看看SeleniumDownloader的下载器底层的浏览器驱动池WebDriverPool
是否有暴露给外界什么属性可以配置options,阅读源码后,发现它只暴露一个属性就是配置启动文件config-chrome.ini。
public void configure() throws IOException {
// Read config file
sConfig = new Properties();
String configFile = DEFAULT_CONFIG_FILE;
if (System.getProperty("selenuim_config")!=null){
configFile = System.getProperty("selenuim_config");
}
sConfig.load(new FileReader(configFile));
// Prepare capabilities
sCaps = new DesiredCapabilities();
sCaps.setJavascriptEnabled(true);
sCaps.setCapability("takesScreenshot", false);
String driver = sConfig.getProperty("driver", DRIVER_PHANTOMJS);
// Fetch PhantomJS-specific configuration parameters
......
}
4、个人解决思路3:重写底层的浏览器驱动池WebDriverPool,然后再重写一个调用该WebDriverPool的下载器
下载器和驱动器管理池都是在官网提供的源码的基础进行修改;
SeleniumDownloader2:在SeleniumDownloader基础上新增了代理枚举属性proxyEnum,并使用了自己重写的浏览器驱动池WebDriverPool2
WebDriverPool2:改写了 WebDriverPool的构造器,以及改写了初始化 WebDriver实例的configure方法(目的,就是为了增加上像代理等的options选项)
- 当然,还增加了一个轮询方法incrForLoop,目的就是为了获得代理列表的索引
■ WebDriverPool2:
public class WebDriverPool2 {
......
/** 代理枚举参数 */
private final ProxyEnum proxyEnum;
/** 代理列表 */
private List<String> proxies;
/** ip代理列表的索引 */
private final AtomicInteger pointer = new AtomicInteger(-1);
......
/**
* 初始化一个 WebDriver 实例
* @throws IOException 异常
*/
public void configure() throws IOException {
......
if (isUrl(driver)) {
sCaps.setBrowserName("phantomjs");
mDriver = new RemoteWebDriver(new URL(driver), sCaps);
} else if (driver.equals(DRIVER_FIREFOX)) {
mDriver = new FirefoxDriver(sCaps);
} else if (driver.equals(DRIVER_CHROME)) {
if(proxyEnum == ProxyEnum.VPN_ENABLE || proxyEnum == ProxyEnum.PROXY_ENABLE){
//给谷歌浏览器,添加上ip代理或vpn等options
ChromeOptions options = new ChromeOptions();
//禁止加载图片
options.addArguments("blink-settings=imagesEnabled=false");
Proxy proxy = new Proxy();
String httpProxy = proxies.get(incrForLoop());
// 需要设置ssl协议
proxy.setHttpProxy(httpProxy).setSslProxy(httpProxy);
options.setCapability("proxy",proxy);
sCaps.setCapability(ChromeOptions.CAPABILITY, options);
logger.info("chrome webDriver proxy is : " + proxy);
}
mDriver = new ChromeDriver(sCaps);
} else if (driver.equals(DRIVER_PHANTOMJS)) {
mDriver = new PhantomJSDriver(sCaps);
}
}
/**
* 轮询:从代理列表选出一个代理的索引
* @return 索引
*/
private int incrForLoop() {
int p = pointer.incrementAndGet();
int size = proxies.size();
if (p < size) {
return p;
}
while (!pointer.compareAndSet(p, p % size)) {
p = pointer.get();
}
return p % size;
}
public WebDriverPool2(int capacity, ProxyEnum proxyEnum, MasterWebservice masterWebservice) {
this.capacity = capacity;
//设置代理的情况
this.proxyEnum = proxyEnum;
//vpn的情况
if(proxyEnum == ProxyEnum.VPN_ENABLE){
this.proxies = masterWebservice.getVpn();
//ip代理的情况
}else if(proxyEnum == ProxyEnum.PROXY_ENABLE){
//获取动态生成的ip列表,带有端口的,参数形式举例 42.177.155.5:75114
this.proxies = masterWebservice.getProxyIps();
}
}
}
■ SeleniumDownloader2:
/**
* 在SeleniumDownloader基础上新增了代理枚举属性proxyEnum
* 并且要把官网SeleniumDownloader代码中使用WebDriverPool(实际是使用上咱改写的WebDriverPool2)的方法引入,还有使用到WebDriverPool的方法
* 中,需要的属性,要注意父类中被设置私有,需要重写一下(从父类copy到子类就行啦)
*/
public class SeleniumDownloader2 extends SeleniumDownloader {
private volatile WebDriverPool2 webDriverPool;
/** 代理枚举参数 */
private ProxyEnum proxyEnum;
/** 通过masterWebservice获得远程的动态ip列表 */
private MasterWebservice masterWebservice;
public SeleniumDownloader2(String chromeDriverPath, ProxyEnum proxyEnum, MasterWebservice masterWebservice) {
System.getProperties().setProperty("webdriver.chrome.driver",
chromeDriverPath);
this.proxyEnum = proxyEnum;
this.masterWebservice = masterWebservice;
}
......
}
■ seleniume 包下的下载器和浏览器如下:
■ 官网提供的WebDriverPool:
package us.codecraft.webmagic.downloader.selenium;
import org.apache.log4j.Logger;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import java.io.FileReader;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author code4crafter@gmail.com <br>
* Date: 13-7-26 <br>
* Time: 下午1:41 <br>
*/
class WebDriverPool {
private Logger logger = Logger.getLogger(getClass());
private final static int DEFAULT_CAPACITY = 5;
private final int capacity;
private final static int STAT_RUNNING = 1;
private final static int STAT_CLODED = 2;
private AtomicInteger stat = new AtomicInteger(STAT_RUNNING);
/*
* new fields for configuring phantomJS
*/
private WebDriver mDriver = null;
private boolean mAutoQuitDriver = true;
private static final String DEFAULT_CONFIG_FILE = "/data/webmagic/webmagic-selenium/config.ini";
private static final String DRIVER_FIREFOX = "firefox";
private static final String DRIVER_CHROME = "chrome";
private static final String DRIVER_PHANTOMJS = "phantomjs";
protected static Properties sConfig;
protected static DesiredCapabilities sCaps;
/**
* Configure the GhostDriver, and initialize a WebDriver instance. This part
* of code comes from GhostDriver.
* https://github.com/detro/ghostdriver/tree/master/test/java/src/test/java/ghostdriver
*
* @author bob.li.0718@gmail.com
* @throws IOException
*/
public void configure() throws IOException {
// Read config file
sConfig = new Properties();
String configFile = DEFAULT_CONFIG_FILE;
if (System.getProperty("selenuim_config")!=null){
configFile = System.getProperty("selenuim_config");
}
sConfig.load(new FileReader(configFile));
// Prepare capabilities
sCaps = new DesiredCapabilities();
sCaps.setJavascriptEnabled(true);
sCaps.setCapability("takesScreenshot", false);
String driver = sConfig.getProperty("driver", DRIVER_PHANTOMJS);
// Fetch PhantomJS-specific configuration parameters
if (driver.equals(DRIVER_PHANTOMJS)) {
// "phantomjs_exec_path"
if (sConfig.getProperty("phantomjs_exec_path") != null) {
sCaps.setCapability(
PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
sConfig.getProperty("phantomjs_exec_path"));
} else {
throw new IOException(
String.format(
"Property '%s' not set!",
PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY));
}
// "phantomjs_driver_path"
if (sConfig.getProperty("phantomjs_driver_path") != null) {
System.out.println("Test will use an external GhostDriver");
sCaps.setCapability(
PhantomJSDriverService.PHANTOMJS_GHOSTDRIVER_PATH_PROPERTY,
sConfig.getProperty("phantomjs_driver_path"));
} else {
System.out
.println("Test will use PhantomJS internal GhostDriver");
}
}
// Disable "web-security", enable all possible "ssl-protocols" and
// "ignore-ssl-errors" for PhantomJSDriver
// sCaps.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, new
// String[] {
// "--web-security=false",
// "--ssl-protocol=any",
// "--ignore-ssl-errors=true"
// });
ArrayList<String> cliArgsCap = new ArrayList<String>();
cliArgsCap.add("--web-security=false");
cliArgsCap.add("--ssl-protocol=any");
cliArgsCap.add("--ignore-ssl-errors=true");
sCaps.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS,
cliArgsCap);
// Control LogLevel for GhostDriver, via CLI arguments
sCaps.setCapability(
PhantomJSDriverService.PHANTOMJS_GHOSTDRIVER_CLI_ARGS,
new String[] { "--logLevel="
+ (sConfig.getProperty("phantomjs_driver_loglevel") != null ? sConfig
.getProperty("phantomjs_driver_loglevel")
: "INFO") });
// String driver = sConfig.getProperty("driver", DRIVER_PHANTOMJS);
// Start appropriate Driver
if (isUrl(driver)) {
sCaps.setBrowserName("phantomjs");
mDriver = new RemoteWebDriver(new URL(driver), sCaps);
} else if (driver.equals(DRIVER_FIREFOX)) {
mDriver = new FirefoxDriver(sCaps);
} else if (driver.equals(DRIVER_CHROME)) {
mDriver = new ChromeDriver(sCaps);
} else if (driver.equals(DRIVER_PHANTOMJS)) {
mDriver = new PhantomJSDriver(sCaps);
}
}
/**
* check whether input is a valid URL
*
* @author bob.li.0718@gmail.com
* @param urlString urlString
* @return true means yes, otherwise no.
*/
private boolean isUrl(String urlString) {
try {
new URL(urlString);
return true;
} catch (MalformedURLException mue) {
return false;
}
}
/**
* store webDrivers created
*/
private List<WebDriver> webDriverList = Collections
.synchronizedList(new ArrayList<WebDriver>());
/**
* store webDrivers available
*/
private BlockingDeque<WebDriver> innerQueue = new LinkedBlockingDeque<WebDriver>();
public WebDriverPool(int capacity) {
this.capacity = capacity;
}
public WebDriverPool() {
this(DEFAULT_CAPACITY);
}
/**
*
* @return
* @throws InterruptedException
*/
public WebDriver get() throws InterruptedException {
checkRunning();
WebDriver poll = innerQueue.poll();
if (poll != null) {
return poll;
}
if (webDriverList.size() < capacity) {
synchronized (webDriverList) {
if (webDriverList.size() < capacity) {
// add new WebDriver instance into pool
try {
configure();
innerQueue.add(mDriver);
webDriverList.add(mDriver);
} catch (IOException e) {
e.printStackTrace();
}
// ChromeDriver e = new ChromeDriver();
// WebDriver e = getWebDriver();
// innerQueue.add(e);
// webDriverList.add(e);
}
}
}
return innerQueue.take();
}
public void returnToPool(WebDriver webDriver) {
checkRunning();
innerQueue.add(webDriver);
}
protected void checkRunning() {
if (!stat.compareAndSet(STAT_RUNNING, STAT_RUNNING)) {
throw new IllegalStateException("Already closed!");
}
}
public void closeAll() {
boolean b = stat.compareAndSet(STAT_RUNNING, STAT_CLODED);
if (!b) {
throw new IllegalStateException("Already closed!");
}
for (WebDriver webDriver : webDriverList) {
logger.info("Quit webDriver" + webDriver);
webDriver.quit();
webDriver = null;
}
}
}
■ 官网提供的SeleniumDownloader:
package us.codecraft.webmagic.downloader.selenium;
import org.apache.log4j.Logger;
import org.openqa.selenium.By;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.downloader.Downloader;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.PlainText;
import java.io.Closeable;
import java.io.IOException;
import java.util.Map;
/**
* 使用Selenium调用浏览器进行渲染。目前仅支持chrome。<br>
* 需要下载Selenium driver支持。<br>
*
* @author code4crafter@gmail.com <br>
* Date: 13-7-26 <br>
* Time: 下午1:37 <br>
*/
public class SeleniumDownloader implements Downloader, Closeable {
private volatile WebDriverPool webDriverPool;
private Logger logger = Logger.getLogger(getClass());
private int sleepTime = 0;
private int poolSize = 1;
private static final String DRIVER_PHANTOMJS = "phantomjs";
/**
* 新建
*
* @param chromeDriverPath chromeDriverPath
*/
public SeleniumDownloader(String chromeDriverPath) {
System.getProperties().setProperty("webdriver.chrome.driver",
chromeDriverPath);
}
/**
* Constructor without any filed. Construct PhantomJS browser
*
* @author bob.li.0718@gmail.com
*/
public SeleniumDownloader() {
// System.setProperty("phantomjs.binary.path",
// "/Users/Bingo/Downloads/phantomjs-1.9.7-macosx/bin/phantomjs");
}
/**
* set sleep time to wait until load success
*
* @param sleepTime sleepTime
* @return this
*/
public SeleniumDownloader setSleepTime(int sleepTime) {
this.sleepTime = sleepTime;
return this;
}
@Override
public Page download(Request request, Task task) {
checkInit();
WebDriver webDriver;
try {
webDriver = webDriverPool.get();
} catch (InterruptedException e) {
logger.warn("interrupted", e);
return null;
}
logger.info("downloading page " + request.getUrl());
webDriver.get(request.getUrl());
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebDriver.Options manage = webDriver.manage();
Site site = task.getSite();
if (site.getCookies() != null) {
for (Map.Entry<String, String> cookieEntry : site.getCookies()
.entrySet()) {
Cookie cookie = new Cookie(cookieEntry.getKey(),
cookieEntry.getValue());
manage.addCookie(cookie);
}
}
/*
* TODO You can add mouse event or other processes
*
* @author: bob.li.0718@gmail.com
*/
WebElement webElement = webDriver.findElement(By.xpath("/html"));
String content = webElement.getAttribute("outerHTML");
Page page = new Page();
page.setRawText(content);
page.setHtml(new Html(content, request.getUrl()));
page.setUrl(new PlainText(request.getUrl()));
page.setRequest(request);
webDriverPool.returnToPool(webDriver);
return page;
}
private void checkInit() {
if (webDriverPool == null) {
synchronized (this) {
webDriverPool = new WebDriverPool(poolSize);
}
}
}
@Override
public void setThread(int thread) {
this.poolSize = thread;
}
@Override
public void close() throws IOException {
webDriverPool.closeAll();
}
}
三、关于Selenium 的介绍
0、官网参考资料:
1、Selenium 是什么
Selenium 是
Web的自动化测试工具,可以模拟用户与浏览器交互,进行访问网站。
Selenium是一个浏览器自动化的大型项目。
它提供用于
模拟用户与浏览器交互
的扩展、用于扩展浏览器分配的分发服务器,以及用于实现W3C WebDriver 规范的基础结构,使您可以为所有主要 Web 浏览器编写可互换的代码。Selenium 的核心是
WebDriver
,它是一个编写指令集的接口,可以在许多浏览器中互换运行。
2、Selenium 作用:
自动化测试:自动化测试工具,可以模拟用户与浏览器交互,进行访问网站。
爬虫:因为Selenium可以控制浏览器发送请求,并获取网页数据,因此可以应用于爬虫领域。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
3、Selenium 实际情况
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。
■ 主流的浏览器驱动WebDriver:PhantomJS、chromedriver
▪ PhantomJS:
PhantomJS 是一个基于Webkit的“
无界面
”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
▪ chromedriver:
注意 :chromedriver的版本要与你使用的chrome版本对应!
chromedriver版本 支持的Chrome版本
v2.46 v71-73
v2.45 v70-72
v2.44 v69-71
v2.43 v69-71
v2.42 v68-70
v2.41 v67-69
v2.40 v66-68
v2.39 v66-68
v2.38 v65-67
v2.37 v64-66
v2.36 v63-65
v2.35 v62-64
v2.34 v61-63
v2.33 v60-62
v2.32 v59-61
v2.31 v58-60
v2.30 v58-60
v2.29 v56-58
v2.28 v55-57
v2.27 v54-56
v2.26 v53-55
v2.25 v53-55
v2.24 v52-54
v2.23 v51-53
v2.22 v49-52
v2.21 v46-50
v2.20 v43-48
v2.19 v43-47
v2.18 v43-46
v2.17 v42-43
v2.13 v42-45
v2.15 v40-43
v2.14 v39-42
v2.13 v38-41
v2.12 v36-40
v2.11 v36-40
v2.10 v33-36
v2.9 v31-34
v2.8 v30-33
v2.7 v30-33
v2.6 v29-32
v2.5 v29-32
v2.4 v29-32
4、Selenium+chromedriver 的使用:
(1) 准备工作:
Selenium:导入依赖包
chromedriver:看着你电脑的谷歌浏览器版本,下载对应的chromedriver 驱动包
(2) 使用:
public class FirstScriptTest {
@Test
public void eightComponents() {
//通过DesiredCapabilities、options 可以给driver 配置一个选项,例如代理,禁止加载图片、去掉界面模式等
//参考:ChromeDriver:https://sites.google.com/a/chromium.org/chromedriver/capabilities
String downloadsPath = "d:\\data\\downloads";
HashMap<String, Object> chromePrefs = new HashMap<String, Object>();
chromePrefs.put("download.default_directory", downloadsPath);
ChromeOptions options = new ChromeOptions();
Proxy proxy = new Proxy();
// 需要增加设置ssl协议
proxy.setHttpProxy(VpnServerUtils.getVpnServer()).setSslProxy(VpnServerUtils.getVpnServer());
// proxy.setHttpProxy(VpnServerUtils.getVpnServer());
options.setCapability("proxy",proxy);
System.out.println("~~~~~~~~~~~~~~~~~proxy: " + proxy.getHttpProxy());
options.setExperimentalOption("prefs", chromePrefs);
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(ChromeOptions.CAPABILITY, options);
WebDriver driver = new ChromeDriver(caps);
//浏览器驱动器请求加载页面
driver.get("https://www.selenium.dev/selenium/web/web-form.html");
//查找元素
String title = driver.getTitle();
assertEquals("Web form", title);
driver.manage().timeouts().implicitlyWait(Duration.ofMillis(500));
WebElement textBox = driver.findElement(By.name("my-text"));
WebElement submitButton = driver.findElement(By.cssSelector("button"));
textBox.sendKeys("Selenium");
submitButton.click();//点击事件
WebElement message = driver.findElement(By.id("message"));
String value = message.getText();
assertEquals("Received!", value);
//结束会话
driver.quit();
}
}
如果本文对你有帮助的话记得给一乐点个赞哦,感谢!

