2023年10月
多线程指南:探究多线程在Node.js中的广泛应用
前言
最初,JavaScript是用于设计执行简单的web任务的,比如表单验证。直到2009年,Node.js的创建者Ryan Dahl让开发人员认识到了通过JavaScript 进行后端开发已成为可能,在后端开发中,用到最多的就是多线程以及线程之间的同步功能,今天小编就为大家介绍一下如何使用Node.js实现多线程的应用。
Node.js的内部工作原理
在介绍之前,先给大家介绍一下Node.js的工作原理,Node.js基于单线程事件循环的范例进行操作。为了充分掌握Node.js的功能,理解Node中线程(构成Node.js核心的事件循环)的概念至关重要。
Node.js中的线程
在Node.js中,线程是指单个进程内的独立执行上下文,它是一个轻量级的处理单元,可以与同一进程中的其他线程并发操作。每个线程都有自己的执行指针和堆栈,并共享进程堆。
Node.js使用两种类型的线程:由事件循环管理的主线程和工作池中的多个辅助线程。(在本文中”辅助线程“和"线程"可互换使用来指代工作线程)
Node.js中的主线程是Node.js启动时的初始执行线程,它负责执行JavaScript代码并处理传入的请求,工作线程是与主线程并行运行的单独执行线程。
Node.js 以多线程还是单线程方式运行?
“单线程”是指只有一个执行线程的程序,允许它顺序执行任务,“多线程”意味着具有多个执行线程的程序可以同时执行任务。
通常情况下,Node.js 被认为是单线程,因为它只有一个处理 JavaScript 操作和 I/O 的主事件循环。然而,Node.js单线程架构中的主要元素是事件循环,这使得 Node.js 尽管是单线程运行,却有着强大的性能。
事件循环
事件循环是一种注册将要执行的回调(函数)的机制,并与 JavaScript 代码在同一线程中运行。当 JavaScript 操作阻塞线程时,事件循环也会被阻塞。
工作池
工作池是一种执行模型,它生成并管理单独的线程,这些线程同步执行任务并将结果返回到事件循环。然后,事件循环使用结果执行提供的回调。工作池主要用于异步 I/O 操作,例如与系统磁盘和网络的交互,并在libuv中实现。尽管当 Node.js 需要在 JavaScript 和 C++ 之间进行内部通信时可能会出现轻微的延迟,但几乎不会被注意到。
使用事件循环和工作池实现异步操作
借助事件循环和工作池机制,能够在 Node.js 中编写有效处理异步操作的代码。
fs.readFile(path.join(__dirname, './package.json'), (err, content) => {
if (err) {
return null;
}
console.log(content.toString());
});
介绍worker_threads模块
worker_threads模块是一个包,它允许在单核上创建多个线程,下面是worker_threads的使用方法:
type WorkerCallback = (err: any, result?: any) => any;
export function runWorker(path: string, cb: WorkerCallback, workerData: object | null = null) {
const worker = new Worker(path, { workerData });
worker.on('message', cb.bind(null, null));
worker.on('error', cb);
worker.on('exit', (exitCode) => {
if (exitCode === 0) {
return null;
}
return cb(new Error(`Worker has stopped with code ${exitCode}`));
});
return worker;
}
先创建一个Worker类的实例,第一个参数包含worker代码的文件路径,第二个参数应该是一个包含名为workerData的属性的对象,并在开始执行时能够访问的数据。
需要注意的是,无论是使用 JavaScript 还是TypeScript,文件路径都应始终指向扩展名为 .js 或.mjs的文件。
下面是一些常见的事件:
/*每当工作线程中发生未处理的异常时,会触发错误事件。随后,工作线程被终止,
并且可以将错误作为提供的回调函数中的第一个参数进行访问。这种设置可以实现及时捕获和处理异常情况。
*/
worker.on('error', (error) => {});
/*
当工作线程退出时,会发出exit事件。如果调用process.exit(),exitCode将提供给回调函数。
如果使用worker.terminate()终止worker ,退出代码将被设置为1:
*/
worker.on('exit', (exitCode) => {});
/*
当工作线程向父线程发送数据时,会发出消息事件。现在,来看看数据是如何在线程之间共享的。
*/
worker.on('online', () => {});
使用工作线程的两种方法:
工作程序
第一种方法是生成一个工作程序,执行其代码,并将结果发送回父级。然而,这种方法具有显着的开销成本,包括创建新的工作线程、管理每个线程的内存开销以及启动和管理线程所需的资源。虽然可以使用这种方法完成任务,但它可能效率不高,尤其是在大规模基于节点的系统中。为了解决与此方法相关的挑战,通常采用第二种更常用的行业实践。
工作线程池
第二种方法是实现工作线程池,它通过创建可重用于多个任务的工作线程池来减轻第一种方法的缺点。不是为每个任务创建一个新的工作线程,而是创建一个工作线程池,并将任务分配给它们。
用技术术语来说,工作池可以被视为管理工作线程池的抽象数据类型。池中的每个工作线程都被分配一个任务,并且该线程与其他线程并行执行该任务。
在工作池中分配任务的方式有多种,池充当管理器,将任务分配给工作线程,收集它们的结果,并促进池中线程之间的通信。
实现工作池可能涉及使用不同的数据结构和算法,例如任务队列和消息传递系统。具体数据结构的选择取决于多种因素,包括所需的工作线程数量、任务的性质以及线程之间所需的通信级别。
Node.js实现工作池
在 Node 中,可以使用内置功能或第三方工具来实现工作池。节点的内置工作线程模块提供对工作线程的支持,可用于创建工作池。此外,还有多个库可以通过为工作线程提供高级 API 以及对任务调度和线程管理的额外支持来补充工作池。
这些库自动执行任务调度和线程管理过程,从而更容易实现工作池。
为了说明这一点,下面是一个利用Node内置工作线程功能的示例代码:
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
// Main thread code
// Create an array to store worker threads
const workerThreads = [];
// Create a number of worker threads and add them to the array
for (let i = 0; i < 4; i++) {
workerThreads.push(new Worker(__filename));
}
// Send a message to each worker thread with a task to perform
workerThreads.forEach((worker, index) => {
worker.postMessage({ task: index });
});
} else {
// Worker thread code
// Listen for messages from the main thread
parentPort.on('message', message => {
console.log(`Worker ${process.pid}: Received task ${message.task}`);
// Perform the task
performTask(message.task);
});
function performTask(task) {
// … operations to be performed to execute the task
}
}
上面的代码由两部分组成:一部分用于主线程,另一部分用于工作线程。在主线程部分,从模块中导入必要的成员,如果当前执行上下文在主线程中,则创建一个数组来存储四个worker。随后,带有要执行的任务的新消息被发送到每个工作线程。
在工作线程部分,使用属性方法来监听来自主线程的消息parentPort。一旦收到消息,记录下进程ID和任务,并将任务传递给应用程序中适当的方法来执行。这样就能够更加智能地处理任务,并提供高效的函数执行。
使用线程的主要优点是什么?
线程是一个强大的工具,可以极大地影响程序的性能、响应能力和整体效率。在 Node.js 中,线程对于开发人员来说是一项很有价值的功能,因为它可以将进程拆分为多个独立的执行流。如果正确使用,线程可以提高程序的速度、效率和响应能力。
线程的优势:
- 提高性能:线程允许并发执行多个任务,与顺序运行任务相比,整体程序执行速度更快。
- 响应性:线程可以防止计算量大的任务阻塞或延迟其他操作的执行,确保程序保持对用户输入和其他任务的响应。
- 资源共享:Node.js 中的线程可以共享变量等资源,从而实现并发处理并加快程序执行速度。
- 易于编程:线程消除了 Node.js 中单线程架构的限制,使编程更加高效和可扩展。
- 提高可扩展性:线程可以轻松扩展,从而可以更轻松地构建高性能且可扩展的 Node.js 应用程序,这些应用程序可以轻松处理增加的负载。
结论
通过worker_threads模块,可以轻松地将多线程支持集成到应用程序中。将密集的CPU计算卸载到单独的线程中,可以大幅提高服务器的吞吐量。这种设计可以吸引更多来自人工智能、机器学习和大数据等领域的开发人员和工程师开始在他们的项目中使用Node.js。因此,使用worker_threads模块是一种高效、便捷的方式来实现多线程编程。
Redis从入门到实践
一节课带你搞懂数据库事务!
Chrome开发者工具使用教程
扩展链接:
Lora升级!ReLoRa!最新论文 High-Rank Training Through Low-Rank Updates
关注公众号TechLead,分享AI与云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

摘要
尽管通过扩展导致具有数千亿参数的大型网络在统治和效率方面表现突出,但训练过参数化模型的必要性仍然难以理解,且替代方法不一定能使训练高性能模型的成本降低。在本文中,我们探索了低秩训练技术作为训练大型神经网络的替代方法。我们引入了一种名为 ReLoRA 的新方法,该方法利用低秩更新来训练高秩网络。我们将 ReLoRA 应用于预训练最多达 350M 参数的变换器语言模型,并展示了与常规神经网络训练相当的性能。此外,我们观察到 ReLoRA 的效率随着模型大小的增加而提高,使其成为训练多十亿参数网络的有效方法。我们的研究发现揭示了低秩训练技术的潜力及其对扩展规律的影响。代码已在 GitHub 上提供。
1 引言
在过去的十年中,机器学习领域一直被训练越来越多参数化的网络或采取“叠加更多层”的方法所主导。大型网络的定义已经从具有1亿个参数的模型演变到数百亿个参数,这使得与训练这样的网络相关的计算成本对大多数研究团队来说变得过于昂贵。尽管如此,与训练样本相比,需要训练数量级更多的参数的模型的必要性在理论上仍然理解不足。
例如更有效的计算扩展最优化、检索增强模型、以及通过更长时间训练较小模型的简单方法等替代扩展方法,都提供了新的权衡。然而,它们并没有让我们更接近理解为什么我们需要过参数化的模型,也很少使这些模型的训练民主化。例如,训练RETRO需要一套复杂的训练设置和基础设施,能够快速搜索数万亿的标记,而训练LLaMA-6B仍然需要数百个GPU。
相比之下,像零冗余优化器、16位训练、8位推断和参数有效微调(PEFT)等方法在使大型模型更易访问方面发挥了关键作用。具体来说,PEFT方法使得在消费者硬件上微调十亿规模的语言或扩散模型成为可能。这引发了一个问题:这些方法是否也能惠及预训练?
一方面,预训练正是允许对网络进行微小修改以使其适应新任务的步骤。Aghajanyan等人已经证明,预训练网络越多,学习任务所需的更改的秩就越小。另一方面,多项研究已经证明了语言和视觉模型提取和利用的特征的简单性,以及它们的低固有维度。例如,变换器中的注意力模式通常呈现小秩,这已经被成功用于开发更高效的注意力变体。此外,训练过程中也并不需要过参数化。彩票票据假说从经验上证明,在初始化(或训练早期)时,存在子网络 - 获胜票据,当单独训练时可以达到整个网络的性能。
在本研究中,我们专注于低秩训练技术,并介绍了ReLoRA,它使用低秩更新来训练高秩网络。我们凭经验证明ReLoRA执行高秩更新,并实现与常规神经网络训练相似的性能。ReLoRA的组成部分包括神经网络的初始完全秩训练(类似于Frankle等人),LoRA训练,重新开始,锯齿状学习速率计划,以及部分优化器重置。我们对ReLoRA在高达350M参数的变换器语言模型上的效果进行评估。我们选择专注于自回归语言建模,因为这种方法在神经网络的大多数应用中已经展示了其通用性。最后,我们观察到ReLoRA的效率随着模型大小的增加而增加,使其成为有效训练多十亿参数网络的可行选择。
本研究中的每个实验均未使用超过8个GPU天的计算。

2 相关工作
缩放与效率 过参数化与神经网络的可训练性和泛化之间的关系已经得到了广泛的研究,但仍然是一个谜。此外,缩放法则展示了网络大小与其在各种模态之间的性能之间存在简单而强烈的幂律依赖关系。这一发现不仅支持过参数化,而且还鼓励对非常消耗资源的神经网络进行训练。然而,彩票假设表明原则上可以最小化过参数化。具体来说,它表明在训练初期存在可以训练以达到整个网络性能的子网络(中奖彩票)。
参数高效微调 Aghajanyan等人发现预训练减少了网络的变化量或其固有维数,以通过微调学习新任务。即,更大的网络或在更多数据上预训练的网络在学习新任务时需要较小的修改,就其范围的秩而言。这解释了参数高效微调方法的成功,并且还激发了像LoRA和Compacter这样的低秩微调方法的发展。
低秩神经网络训练 在CNN压缩、正则化和高效训练的背景下已经探讨了训练低秩表示。然而,这些方法中的大多数要么特定于CNN,要么不具备良好的可扩展性,要么没有在具有数亿参数的大型转换器上进行评估,而这些转换器可以从高效训练中大大受益。虽然转换器已被证明具有低秩的内部维数和表示,但Bhojanapalli等人的研究表明,在多头注意力中关键和查询投影的低秩限制了转换器的性能。我们自己的实验(第3节)也表明,与完整秩基线和ReLoRA相比,低秩转换器的性能明显较差。

3 方法
让我们从重新审视线性代数101开始。特别是,我们对两个矩阵之和的秩感兴趣:
rank(A + B) ≤ rank(A) + rank(B)。(1)
对和的秩的这个界限是紧的:对于矩阵A,有rank(A) < dim(A),存在B,使得rank(B) < dim(B),并且矩阵之和的秩高于A或B。我们想要利用这个属性来制造一种灵活的参数高效的训练方法。我们从LoRA开始,它是一种基于低秩更新思想的参数高效微调方法。LoRA可以应用于任何通过W ∈ R^m×n参数化的线性操作。具体来说,LoRA将权重更新δW分解为低秩乘积WAWB,如方程2所示,其中s ∈ R是通常等于1/r的固定缩放因子。
δW = sWAWB
WA ∈ R^in×r
, WB ∈ R^r×out(2)
在实践中,LoRA通常是通过添加新的可训练参数WA和WB来实现的,这些参数可以在训练后合并回原始参数。因此,即使方程1允许在训练时间P_t δWt内的总更新具有高于任何单个矩阵的更高的秩,LoRA实现也受到秩r = maxWA,WB rank(WAWB)的限制。
如果我们可以重新启动LoRA,即在训练期间合并WA和WB并重置这些矩阵的值,我们可以增加更新的总秩。多次这样做将整个神经网络更新带到
∆W = ΣT1_t=0 δWt + ΣT2_t=T1 δWt + · · · + ΣTN_t=TN−1 δWt = sW1_AW1_B + sW2_AW2_B + · · · + sWN_AWN_B(3)
其中,总和是独立的,意味着rank(Wi_AWi_B) + rank(Wj_AWj_B) ≥ r。然而,在实践中实现重新启动并不是微不足道的,需要对优化过程进行一些修改。天真的实现会导致模型在重新启动后立即发散。与仅依赖于当前优化时间步的梯度值的普通随机梯度下降不同,Adam更新主要由之前步骤累积的梯度的第一和第二时刻指导。在实践中,梯度矩滑参数β1和β2通常非常高,即0.9 - 0.999。假设在重新初始化边界W1_A和相应的梯度矩mA和vA处是全秩的(r)。那么,在合并和重新初始化后,继续使用W2_A的旧梯度矩将引导它沿着W1_A的相同方向,并优化相同的子空间。
为了解决这个问题,我们提出了ReLoRA。ReLoRA在合并和重新初始化期间对优化器状态进行部分重置,并将学习率设置为0,并随后进行热启动。具体来说,我们将99%的低幅度优化器状态值设置为零,并使用锯齿状余弦学习率计划(图2)。我们的消融研究(表3)表明,这两项修改都是提高LoRA性能的必要条件。
重申一下,ReLoRA是一种受LoRA启发的低秩训练方法,通过重新启动来增加更新的有效秩,使用部分优化器重置和锯齿调度器来稳定训练和热启动。所有这些都使ReLoRA能够通过一次仅训练一小部分参数实现与全秩训练相当的性能,特别是在大型变换器网络中。ReLoRA在算法1中描述。
提高计算效率 与其他低秩训练技术不同,ReLoRA通过保持原始网络的冻结权重并添加新的可训练参数来遵循LoRA方法。乍一看,这似乎在计算上是低效的;然而,冻结和可训练参数之间的区别在参数高效微调中起到了关键作用。
这些方法通过减小梯度和优化器状态的大小,显著提高了训练时间和内存效率。值得注意的是,Adam状态消耗的内存是模型权重的两倍。此外,对于大型网络,通常的做法是以32位精度保持梯度累积缓冲区,从而增加了梯度的内存消耗的重要开销。
通过大幅减少可训练参数的数量,ReLoRA使得能够使用更大的批次大小,最大化硬件效率。此外,它还减少了分布式设置中的带宽要求,这通常是大规模训练的限制因素。
此外,由于冻结参数在重新启动之间没有被更新,所以它们可以保持在低精度量化格式中,进一步减少它们的内存和计算影响。
这一额外的优化有助于整体提高ReLoRA在内存利用和计算资源方面的效率,并在规模上增加。

4 实验
为了评估ReLoRA的有效性,我们将其应用于使用各种模型大小:60M、130M、250M和350M,在C4数据集上训练变换器语言模型。语言建模已被证明是机器学习的基本任务,它能够实现文本和图像分类、翻译、编程、上下文学习、逐步推理等许多其他新兴能力。鉴于其重要性,本文的目的仅关注语言建模。
架构和训练超参数 我们的架构基于变换器,并与LLaMA非常相似。具体来说,我们使用预归一化、RMSNorm、SwiGLU激活、全连接隐藏状态大小,以及旋转嵌入。对于所有LoRA和ReLoRA实验,我们使用秩r = 128,因为我们的初步实验显示它具有最佳的困惑度/内存权衡。所有超参数均在表1中呈现。
我们对所有浮点操作使用bfloat16,并使用Flash注意力进行有效的注意力计算。与LLaMA中使用float32进行softmax计算的注意力相比,这增加了50-100%的训练吞吐量,而没有任何训练稳定性问题。
我们大部分模型在8个RTX 4090上训练了一天或更短的时间。由于计算限制,我们训练的模型要比LLaMA小得多,最大的模型拥有350M个参数,与BERT Large相同。我们根据Chinchilla缩放定律为所有模型选择预训练令牌的数量,除了最大的一个,我们为其训练了6.8B个令牌,而9.5B个令牌是Chinchilla最优的。
ReLoRA和基线设置 在我们的低秩训练实验中,ReLoRA替换了所有注意力和全连接网络参数,同时保持嵌入全秩。RMSNorm参数化保持不变。由于ReLoRA封装的模型比全秩训练具有更少的可训练参数,因此我们包括了一个控制基线,即具有与ReLoRA相同数量可训练参数的全秩变换器。
我们从全秩训练的5,000次更新步骤的检查点开始初始化ReLoRA,并在此后的每5,000步重置一次,总共3次。每次重置后,基于大小修剪99%的优化器状态,并在接下来的100次迭代中预热损失。ReLoRA参数按照LoRA的最佳实践重新初始化,A矩阵使用Kaiming初始化,B矩阵使用零。如果不使用重新启动,B矩阵也使用Kaiming初始化以避免梯度对称性问题。



5 结果
参数高效的预训练 我们的主要结果在表2中展示。ReLoRA显著优于低秩LoRA训练,展示了我们所提出修改的有效性(在第3节中剖析)。此外,ReLoRA的表现与全秩训练相似,且随着网络大小的增加,性能差距逐渐减小。
通过低秩更新进行高秩训练 为了确定ReLoRA是否执行比LoRA更高的秩更新,我们绘制了ReLoRA、LoRA和全秩训练的热启动权重与最终权重之间差异的奇异值谱图。图3描绘了LoRA和ReLoRA在WQ、WK、WV和Wdown的奇异值之间的显著定性差异。
虽然LoRA的大部分奇异值为零(图4),且有显著数量的异常高值超过1.5,但ReLoRA在0.1和1.0之间呈现更高的分布质量,让人联想到全秩训练。这一观察强调了高秩更新的重要性,并展示了ReLoRA的定性功效,其通过执行多个低秩更新实现高秩更新。
5.1 剖析研究
我们对ReLoRA的四个关键组件:重启、锯齿状调度、优化器重置和温暖启动进行剖析研究,使用130M大小的模型。结果展示在表3中。在本节中,我们将重点关注和分析这些组件的某些组合。
LoRA ReLoRA,没有上述组件,本质上等同于通过LoRA参数化训练低秩网络。这种方法产生了极高的困惑度,表明简单的矩阵分解与全秩训练有显著不同的训练动态。
添加重启和优化器重置 ReLoRA,没有锯齿状调度和优化器重置,表现与LoRA相似,因为旧的优化器状态将新初始化的参数强制进入与先前权重相同的子空间,限制了模型的容量。然而,用ReLoRA进行天真的优化器重置会导致模型发散。锯齿状调度有助于稳定训练,并对混合物产生积极影响。在我们的初步实验中,我们还观察到,部分优化器重置和锯齿状调度器的组合允许更快的预热,低至50步,而不是从头开始初始化优化器时所需的数百步。
温暖启动 温暖启动显示了最显著的改进,使困惑度降低了近10点。为了调查预热后训练是否有助于损失,我们测量了预热网络的困惑度,等于27.03。它优于所有低秩方法,除了我们最终的ReLoRA配方,但仍然显示出与最终网络的显著差异。这展示了早期训练的重要性,类似于彩票假说与倒带的概念。

6 结论
在本文中,我们研究了大型变换器语言模型的低秩训练技术。我们首先检查了简单低秩矩阵分解(LoRA)方法的局限性,并观察到它在有效训练高性能变换器模型方面存在困难。为解决这个问题,我们提出了一种名为ReLoRA的新方法,它利用秩的和性质通过多个低秩更新来训练高秩网络。与彩票假说和倒带相似,ReLoRA在转变为ReLoRA之前采用全秩训练的温暖启动。此外,ReLoRA引入了合并和重新初始化(重启)策略、锯齿状学习速率调度器和部分优化器重置,这些共同增强了ReLoRA的效率,并使其更接近全秩训练,特别是在大型网络中。随着网络大小的增加,ReLoRA的效率提高,使其成为多十亿规模训练的可行候选方案。
我们坚信,低秩训练方法的发展对于提高训练大型语言模型和一般神经网络的效率具有很大的潜力。此外,低秩训练还有潜力为深度学习理论的进步提供有价值的见解,有助于我们通过梯度下降理解神经网络的可训练性以及在过参数化体系中的卓越泛化能力。
7 局限性和未来工作
超越350M的扩展 由于计算资源有限,我们的实验仅限于训练多达350M参数的语言模型。然而,ReLoRA已经在此规模上展示了有希望的结果。不过,我们预计其真正的潜力将在1B+参数区域实现。此外,虽然350M模型胜过控制基线,但并未继续缩小ReLoRA和全秩训练之间的差距的趋势。我们将这一现象归因于次优的超参数选择,这需要进一步研究。
此外,在60-350M的实验中,尽管ReLoRA显著减少了可训练参数的数量,但我们并未观察到对这种大小的网络在内存和计算方面的实质改进。为了评估我们当前实现在更大规模上的效率,我们训练了1.3B参数的模型进行少量迭代,以估计ReLoRA的内存和计算改进。在这个规模下,我们观察到30%的内存消耗减少和52%的训练吞吐量增加。我们期望在更大的网络中观察到相对全训练基线的更大改进,因为ReLoRA的可训练参数数量(与LoRA类似)相较于冻结参数的数量增加得要慢得多。ReLoRA的实现可以通过有效利用ReLoRA层的梯度检查点、自定义反向函数和将冻结模型权重转换为int8或int4量化格式[14]来进一步改进。
与其他低秩训练方法的比较 早期的工作已经探索了许多低秩训练方法与其他模型架构的组合[44,49,55]。我们的工作与这些早期努力有两个方面的不同。首先,我们提出的方法通过低秩训练执行高秩更新。其次,我们的工作展示了在具有100M+参数的大规模变换器语言模型中,低秩训练方法的竞争力。
关注公众号TechLead,分享AI与云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
LLM在text2sql上的应用
一、前言:
目前,大模型的一个热门应用方向text2sql它可以帮助用户快速生成想要查询的SQL语句。那对于用户来说,大部分简单的sql都是正确的,但对于一些复杂逻辑来说,需要用户在产出SQL的基础上进行简单修改,Text2SQL应用主要还是帮助用户去解决开发时间,减少开发成本。
Text to SQL: 简称Text2SQl,是将自然语言文本(Text)转换成结构化查询语言SQL的过程,属于自然语言处理-语义分析(Semantic Parsing)领域中的子任务。
它的目的可以简单概括为:
“打破人与结构化数据之间的壁垒”
,即普通用户可以通过
自然语言描述
完成复杂数据库的查询工作,得到想要的结果。
二、背景应用:
目前大家对T2S的做法大致分为两种,
- 一种是用现有的大模型来直接生成,例如ChatGPT、GPT-4模型,但是对于一些公司来说,数据是属于保密资产,这种方式相当于将自己公司的数据信息透漏给大模型,属于数据泄露行为;
- 另一种方式是利用开源的大模型做finetune,比如chatglm2-6b来做微调,这个也是目前我们在做的,同时开源的数据集也有很多,简单罗列如下:
| 数据集 | 数据集介绍 |
|---|---|
| WikiSQL | WikiSQL是一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。 WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。 虽然数据规模大,SQL语法却非常简单;适合做NL2SQL任务入门。 |
| Spider | 耶鲁大学在2018年新提出的一个大规模的NL2SQL(Text-to-SQL)数据集。 该数据集包含了10,181条自然语言问句、分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。 涉及的SQL语法最全面,是目前难度最大的NL2SQL数据集。 |
| Cspider | CSpider是Spider的中文版,西湖大学出品。 |
| Sparc | 耶鲁大学在2019年提出的基于对话的Text-to-SQL数据集。 SParC是一个跨域上下文语义分析的数据集,是Spider任务的上下文交互版本。SParC由4298个对话(12k+个单独的问题,每个对话平均4-5个子问题,由14个耶鲁学生标注)组成,这些问题通过用户与138个领域的200个复杂数据库进行交互获得。 |
| CHASE | 微软亚研院和北航、西安交大联合提出的首个大规模上下文依赖的Text-to-SQL中文数据集。 内容分为CHASE-C和CHASE-T两部分,CHASE-C从头标注实现,CHASE-T将Sparc从英文翻译为中; 相比以往数据集,CHASE大幅增加了hard类型的数据规模,减少了上下文独立样本的数据量,弥补了Text2SQL多轮交互任务中文数据集的空白。 |
三、Text2SQL使用:
我们在Text2SQL上面的应用主要包括两个阶段,第一阶段是利用LLM理解你的请求,通过请求去生成
结构化的SQL
;下一个阶段是在生成的SQL上自动化的查询数据库,返回结果,然后利用LLM对结果
生成总结,提供分析
。
3.1 第一阶段:
利用LLM理解文本信息,生成SQL,目前通过spider数据集来评测,GPT家族还是笑傲群雄。但是这里我们如果只借助GPT来做的话,就会出现之前说的数据隐私问题。
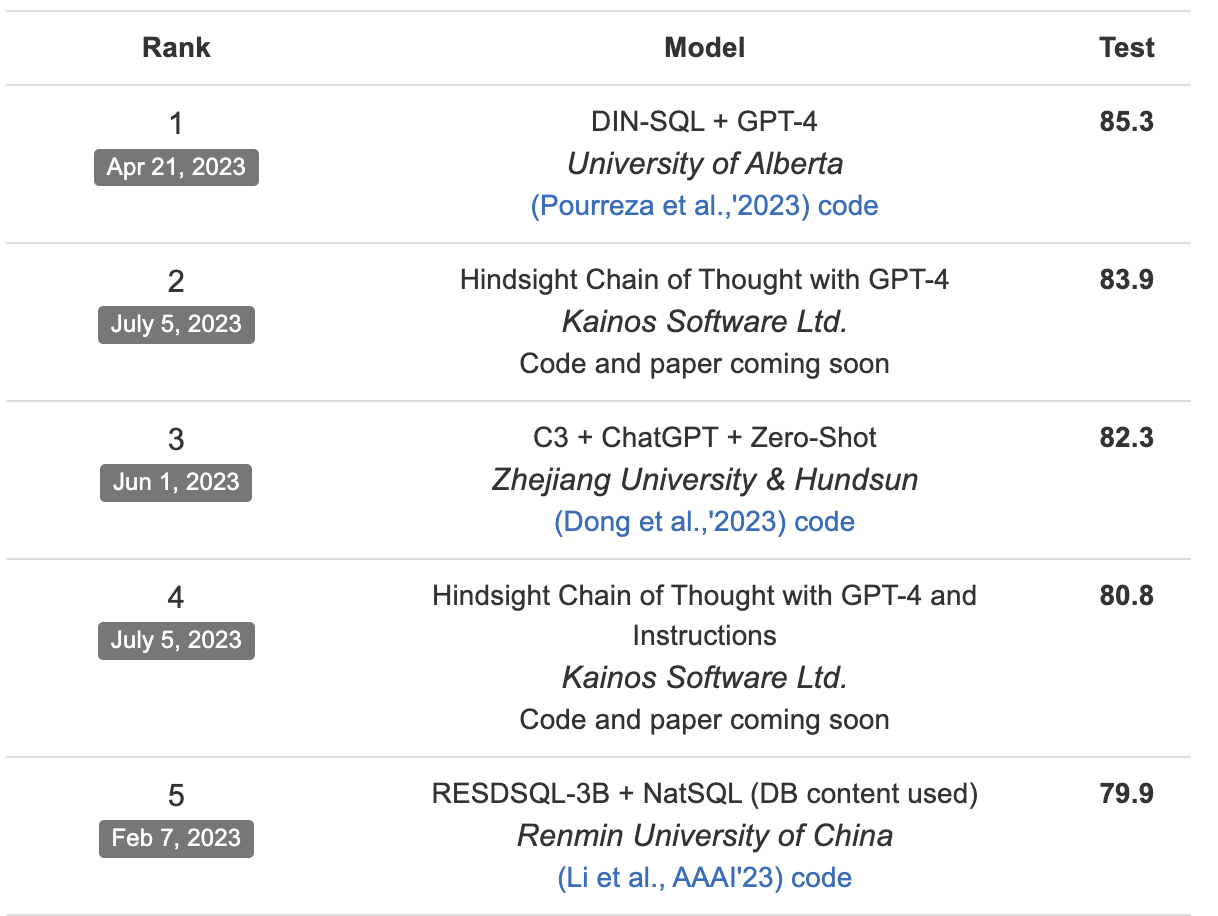
这里我们通过两部分来提升LLM对文本的理解,生成更符合我们要求的结果。
1. 构建数据信息表的schema,利用LLM生成embedding
由于我们从离线评测效果来看,开源模型chatglm2-6b直接生成的SQL和GPT对比,还是有比较大的差距,所以无法直接使用。这里我们根据用户描述的text,让预训练的chatglm2-6b生成embedding,通过embedding检索的方式,选出top1数据表,这个过程属于先验过滤阶段。
数据表的schema设计非常重要,需要描述清楚这个表它的主体信息以及表中重要字段和字段含义。
例:
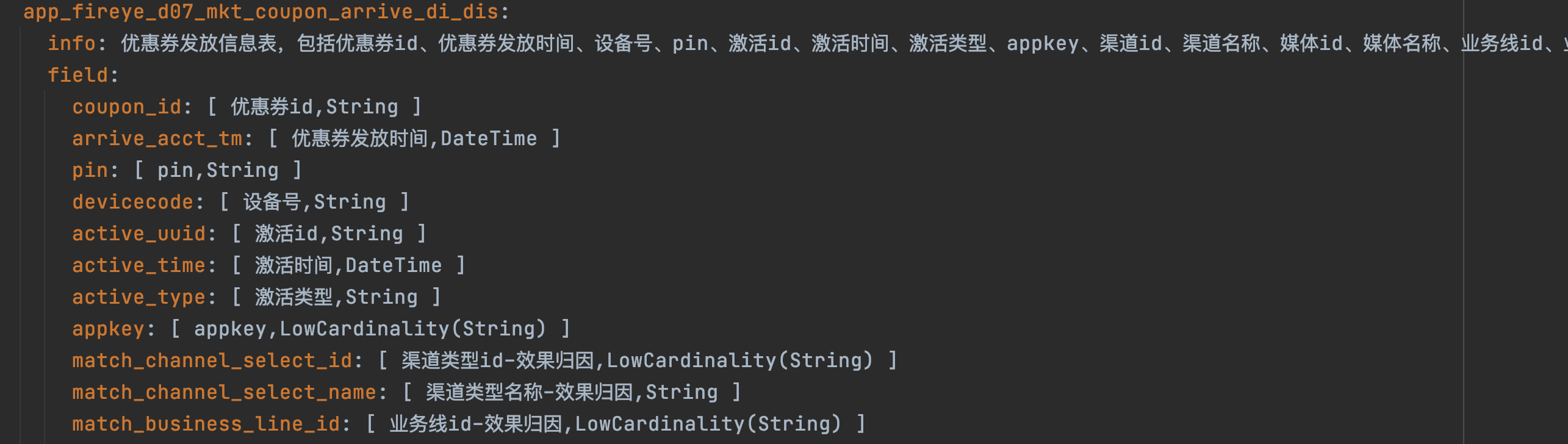
数据表的embedding可以提前计算保存,这样利用后期检索效率。
2. prompt构建,生成SQL
这部分我认为最重要的还是如何去合理构建prompt,让LLM去理解你的真实意图,生成标准的SQL。
一是prompt的开头需要定义构建,二是prompt整体结构以及结构中数据表的信息也需要涵盖进去,这里我们prompt的开头首先定义LLM的工作目的是生成SQL,通过我们根据第一部分返回的top1数据表,解析数据表中的信息,加入到prompt中,以此来构建完成的prompt。
1)开头prompt定义:

2
)数据表prompt定义:

3)In-context-prompt:如果想强化prompt,可以增加一些正样本“问答”式的结构,让LLM去学习理解,最终生成更理想的结果

prompt的构建对最终结果的影响非常重要,构建一个完美的prompt可能已经成功了一半。
通过以上的prompt构建,我们就可以给LLM让模型生成最终的SQL结果。

3.2 第二阶段:
其实很多场景上一阶段生成SQL就已经达到我们想要的结果,但这里我们还想进一步根据SQL生成最终的数据,所以需要连接数据库,SQL运行返回结果。这里我们通过连接集团CK数据库,以接口的形式进行部署,我们在运行SQL的时候,其实就是调用接口,这样方便简洁,对接口返回的结果进行结构化的输出就可以。
通过接口访问结构化输出:

四、结果:
以上就是目前我们根据LLM来生成SQL,同时让SQL自动运行产生结果。前期我们利用GPT模型去跑通整个pipeline,同时生成一些训练数据集,来提供chatglm2-6b微调,后期我们还会对产出的结果进行数据分析,这个阶段也是利用LLM来完成,通过这种方式给用户一些指导性的意见或总结。
以下是整个pipeline的流程:
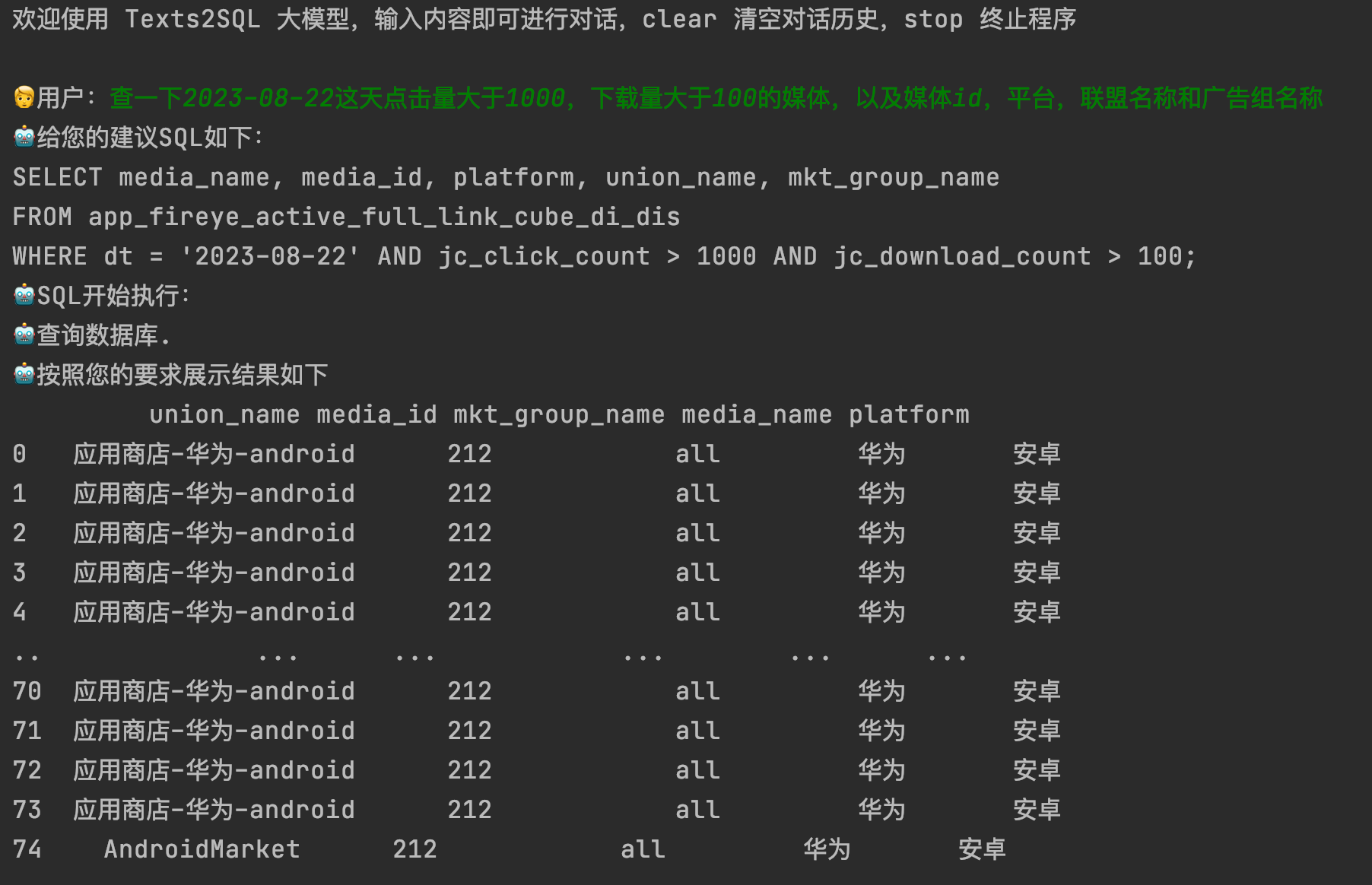
作者:京东零售 郑少强
来源:京东云开发者社区 转载请注明来源
Chromium GPU资源共享
资源共享指的是在一个 Context 中的创建的 Texture 资源可以被其他 Context 所使用。一般来讲只有相同
share group
Context 创建的 Texture 才可以被共享,而 Chromium 设计了一套允许不同
share group
并且跨进程的 Texture 共享机制。
Chromium 中有新旧两套共享 Texture 的机制,一套是 Mailbox 机制,一套是 SharedImage 机制。
1. Mailbox 机制
Mailbox 机制由
CHROMIUM_texture_mailbox
扩展提供,它定义了一种在不同Context之间共享 Texture 对象中的图片数据的方式,不管这些Context是否处于相同的
share group
。
它定义了2个方法:

glProduceTextureDirectCHROMIUM
方法传入一个当前Context中已经存在的
texture
对象,然后返回一个指向该texture的
mailbox
。后续可以在其他的Context中使用
glCreateAndConsumeTextureCHROMIUM
方法通过这个
mailbox
创建一个新的
texture
对象,新对象存在于新的 Context 中。结合 Command Buffer,可以实现跨进程共享Texture的效果。
Mailbox
类本身是一个定长的字节数组,作为资源的唯一标识符,默认是16字节,系统全局唯一,可以跨进程。
Mailbox 机制使用起来非常方便,但是它对 service 端的运行环境依赖非常严重,比如要求 service 端的所有 Context 都必须属于相同 share group,这导致service端在某些平台上需要使用Virtual Context或者很多的同步机制才能实现,而这些会导致性能损失。再加上这种机制基于GL,无法很好的支持Vulkan,因此 Mailbox 机制已经被标记为
deprecated
,在当前的 Chromium 中只有 media 模块还在使用。新代码应该使用
SharedImage
机制。
2. SharedImage 机制
ShareImage 机制从2018年开始引入,设计用来取代 Mailbox 机制并且支持 Vulkan。它引入了一套 client 端的 SharedImage 接口以及一个新的GL扩展
CHROMIUM_shared_image
。
主要接口为
SharedImageInterface
,用来创建 shared images,定义如下:

这是一个 client 端的接口,可以通过
gpu::GpuChannelHost
来获取到。对它的调用会通过 IPC 接口发送到 service 端,service 端会使用合适的机制来存储 SharedImage 的数据,比如GL Texture,GMB(GpuMemoryBuffer)等。
CreateSharedImage
方法创建一个新的 SharedImage 并返回一个 mailbox 指向它。
UpdateSharedImage
方法更新指定的 SharedImage 的属性。
DestroySharedImage
销毁指定的 SharedImage,释放相关内存。
在client端,通过
CHROMIUM_shared_image
扩展提供的方法来读写 SharedImage 数据。
Mailbox
机制中
CHROMIUM_texture_mailbox
扩展提供的方法也可以用来访问
SharedImage
,因为
SharedImage
机制兼容了
Mailbox
机制。但应该尽量比避免这样使用,因为 Mailbox 机制已经过时了。在 service 端也可以用这种方法来访问 ShareImage。
在servcie端,
SharedImage
实现了大概3类存储机制,分别为 GLTexture/EGLImage,GMB 和 VulkanImage,这三大类又被抽象为了很多种小类。下面这些都是
SharedImage
可能的存储后端:

其中
gpu::SharedImageBackingGLTexture
使用 GL Texture 来存储 SharedImage 数据。
gpu::SharedImageBackingEglImage
使用 EGLImage 来存储数据。
gpu::SharedImageBackingAHB
仅用于 Android 平台,使用 Android 提供的 AHardwareBuffer 来存储数据。
gpu::ExternalVkImageBacking
对接 Vulkan。
gpu::SharedImageBackingGLImage
比较特殊,它表示使用
gpu::GLImage
类来进行存储,
gpu::GLImage
又抽象了不同的存储后端,最终也可能使用 GL Texture。
SharedImage 机制本质上抽象了 GPU 的数据存储能力。即允许应用直接把数据存储到 GPU (GPU 能访问到的内存)中,以及直接从 GPU 中读取数据,并且允许跨过
shared group
边界。理解了这一点,应该比较容易想到哪些场景可以使用 SharedImage 机制,下面这些是 Chromium 中使用 SharedImage 机制的一些场景:
- CC模块: 先将画面 Raster 到 SharedImage,然后再发送给 Viz 进行合成。
- OffscreenCanvas: 先将 Canvas 的内容 Raster 到 SharedImage,然后再发送给 Viz 进行合成。
- 图片处理/渲染: 一个线程将图片解码到 GPU 中,另一个线程使用 GPU 来修改或者渲染图片。
- 视频播放: 一个线程将视频解码到 GPU 中,另一个线程来渲染。
下面介绍2个操作 ShareImage 的扩展。需要注意的是在使用这些扩展方法之前都先要有一个指向 SharedImage 的 mailbox,可以使用
SharedImageInterface
接口创建,也可以是从其他地方传过来。
4. CHROMIUM_shared_image 扩展
CHROMIUM_SHARED_IMAGE 扩展定义了以下4个方法:

glCreateAndTexStorage2DSharedImageCHROMIUM*
方法根据传入的
mailbox
创建一个新的 Texture 对象。然后应用可以使用
glBeginSharedImageAccessDirectCHROMIUM
方法获取读/写
texture
对象的权限,然后使用常规的读写texture的GL命令访问texture的内容,比如
glGetTexImage
,
glReadPixels
,
glTexImage2D
等或者使用skia来间接访问texture的内容。操作结束之后,调用
glEndSharedImageAccessDirectCHROMIUM
方法释放权限。
这些接口用于
GPU-R
机制下的 Raster,这种 Raster 机制已经被
OOP-R
Raster 机制替代,并且在2022年2月份被移除,这里只用于演示旧版本
GPU-R
方式的 Raster:

5. CHROMIUM_raster_transport

glBeginRasterCHROMIUM
方法表示要开始执行 Raster 操作了,Raster的结果存放到传入的
mailbox
对应的 SharedImage 中。
glRasterCHROMIUM
将
cc::DisplayItemList
序列化后发送到service端。参数
raster_shm_id
指向存储
cc::DisplayItemList
序列化数据的共享内存。
glEndRasterCHROMIUM
结束 Raster 操作。
这些接口用于
OOP-R(Out-Of-Process Raster)
机制下的 Raster。关于 OOP-R 见后续文档, 下面的代码演示使用 OOP-R 接口创建 SharedImage:

6. SharedImage 架构设计
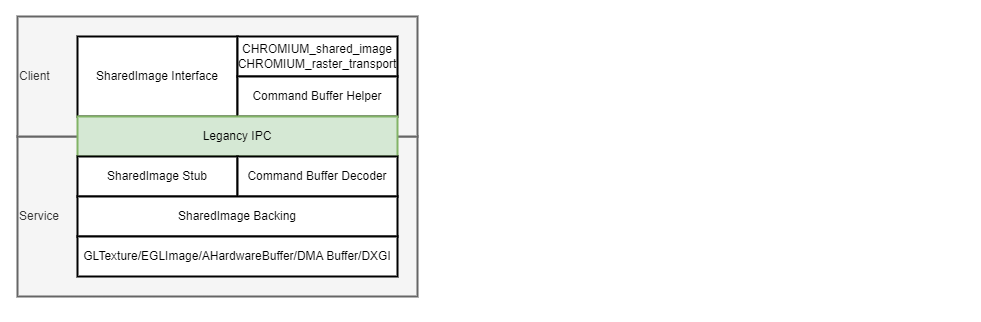
SharedImage 被设计用于多进程架构,Client 端可以有多个,比如 Browser/Render/Gpu 进程都可以作为 Client 端,Service 端只能有一个,它运行在 Gpu 进程中。Client 和 Servcie 通过 IPC 进行通信。Client 端的接口主要包括 SharedImageInterface 和 2 个扩展。Service 端将数据存储在基于不同技术实现的 SharedImageBacking 中。
7. SharedImage 实现原理
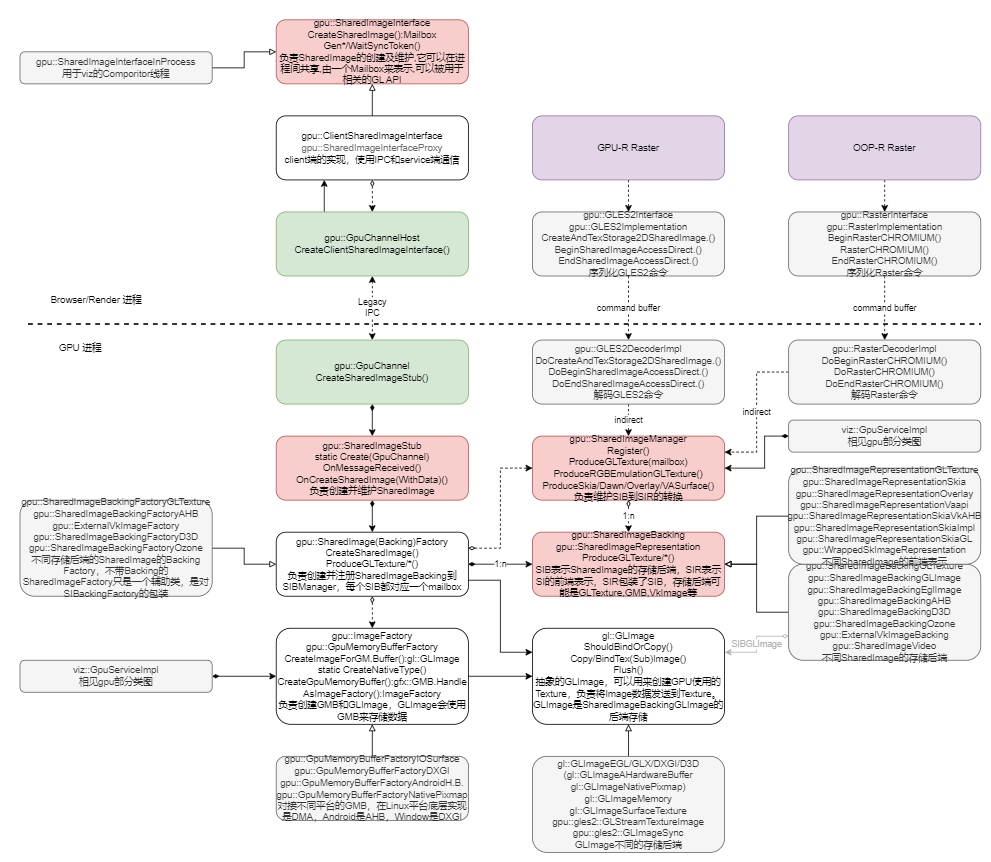
8. 总结
在当前的 Chromium 中,Mailbox 机制是建立在 SharedImage 机制之上的。旧的 Mailbox 机制的接口正在被废弃(Mailbox 类本身并不会被废弃),在新的代码中应该使用新的 SharedImage 接口。
在所有需要“分阶段”渲染的场合都可以使用 SharedImage 机制,在需要从 GPU 读取数据的场合也可以使用 SharedImage 机制。SharedImage 机制只提供内存的管理,应用可以使用常规的读写GPU数据的方式来读写SharedImage中的数据。
9. 参考文献
