一、需求
- 了解dumpsys原理,助于我们进一步了解Android系统的设计
- 帮助我们分析问题,定位系统状态
- 设计新功能的需要
二、环境
- 版本:Android 12
- 平台:SL8541E SPRD
三、相关概念
3.1 dumpsys
dumpsys 是一种在 Android 设备上运行的工具,可提供有关系统服务的信息。可以使用 Android 调试桥 (adb) 从命令行调用 dumpsys,获取在连接的设备上运行的所有系统服务的诊断输出。
3.2 Binder
Binder是Android提供的一套进程间相互通信框架。用来实现多进程间发送消息,同步和共享内存。

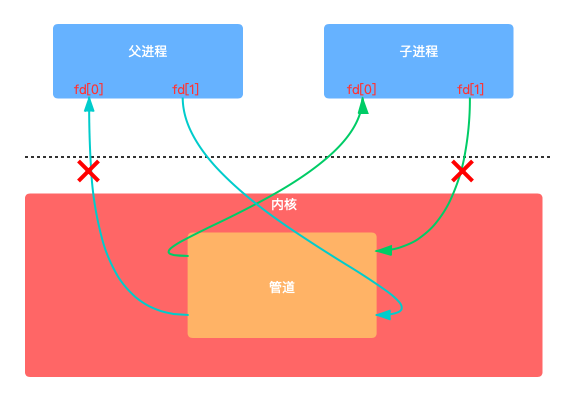
3.3 管道
管道是一种IPC通信方式,分为有名管道和无名管道,无论是有名管道还是无名管道其原理都是在内核开辟一块缓存空间,这段缓存空间的操作是通过文件读写方式进行的。
有名管道与无名管道:
有名管道:
有名管道的通信可以通过管道名进行通信,进程间不需要有关系。
无名管道:
无名管道就是匿名管道,匿名管道通信的进程必须是父子进程。
管道为分半双工和全双工:
半双工:
半双工管道是单向通信,进程1只能向管道写数据,进程2只能从管道读取数据。只有一个代表读或者写的FD(文件描述符)。
全双工:
全双工管道是双向通信,有两个文件描述符,代表读和写。
四、dumpsys指令的使用
4.1 dumpsys使用
如下为执行"adb shell dumpsys"指令,控制台打印的内容,其使用如下:
4.2 dumpsys指令语法
(1)使用 dumpsys 的一般语法如下:
adb shell dumpsys [-t timeout] [--help | -l | --skip services | service [arguments] | -c | -h]
(2)如需获取所连接设备的所有系统服务的诊断输出,请运行 adb shell dumpsys。不过,这样输出的信息比您通常想要的信息多得多。若要使输出更加可控,您可以通过在命令中添加相应服务来指定要检查的服务。例如,下面的命令会提供输入组件(如触摸屏或内置键盘)的系统数据:
adb shell dumpsys input
(3)如需查看可与 dumpsys 配合使用的系统服务的完整列表,请使用以下命令:
adb shell dumpsys -l
(4)命令行选项如下:
|
选项
|
说明
|
| -t timeout |
指定超时期限(秒)。如果未指定,默认值为 10 秒。 |
| --help |
输出 dumpsys 工具的帮助文本。 |
| -l |
输出可与 dumpsys 配合使用的系统服务的完整列表。 |
| --skip services |
指定您不希望包含在输出中的 services。 |
| service [arguments] |
指定您希望输出的 service。某些服务可能允许您传递可选 arguments。如需了解这些可选参数,请将 -h 选项与服务一起传递:
adb shell dumpsys procstats -h
|
| -c |
指定某些服务时,附加此选项能以计算机可读的格式输出数据。 |
| -h |
对于某些服务,附加此选项可查看该服务的帮助文本和其他选项。 |
五、详细设计
5.1 dumpsys流程图

5.2 dumpsys查看电池信息
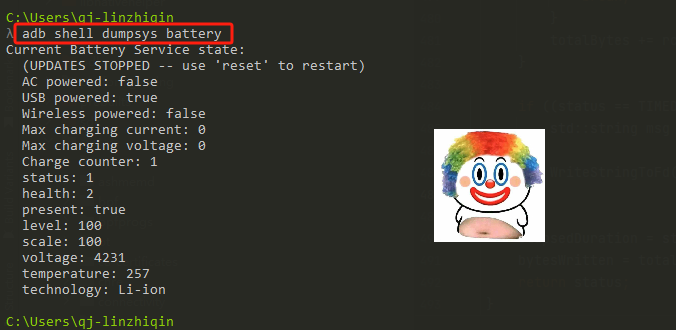
5.2.1 dumpsys battery指令
5.2.2 service->dump打印函数
@frameworks\base\services\core\java\com\android\server\BatteryService.java
private final class BinderService extends Binder {
@Override protected void dump(FileDescriptor fd, PrintWriter pw, String[] args) {
if (!DumpUtils.checkDumpPermission(mContext, TAG, pw)) return;
if (args.length > 0 && "--proto".equals(args[0])) {
dumpProto(fd);
} else {
dumpInternal(fd, pw, args);
}
}
...
}
private void dumpInternal(FileDescriptor fd, PrintWriter pw, String[] args) {
synchronized (mLock) {
if (args == null || args.length == 0 || "-a".equals(args[0])) {
pw.println("Current Battery Service state:");
if (mUpdatesStopped) {
pw.println(" (UPDATES STOPPED -- use 'reset' to restart)");
}
pw.println(" AC powered: " + mHealthInfo.chargerAcOnline);
pw.println(" USB powered: " + mHealthInfo.chargerUsbOnline);
pw.println(" Wireless powered: " + mHealthInfo.chargerWirelessOnline);
pw.println(" Max charging current: " + mHealthInfo.maxChargingCurrent);
pw.println(" Max charging voltage: " + mHealthInfo.maxChargingVoltage);
pw.println(" Charge counter: " + mHealthInfo.batteryChargeCounter);
pw.println(" status: " + mHealthInfo.batteryStatus);
pw.println(" health: " + mHealthInfo.batteryHealth);
pw.println(" present: " + mHealthInfo.batteryPresent);
pw.println(" level: " + mHealthInfo.batteryLevel);
pw.println(" scale: " + BATTERY_SCALE);
pw.println(" voltage: " + mHealthInfo.batteryVoltage);
pw.println(" temperature: " + mHealthInfo.batteryTemperature);
pw.println(" technology: " + mHealthInfo.batteryTechnology);
} else {
Shell shell = new Shell();
shell.exec(mBinderService, null, fd, null, args, null, new ResultReceiver(null));
}
}
}
5.3 dumpsys源码分析
5.3.1 dumpsys服务编译
dumpsys是个二进制可执行程序,其通过bp进行编译,并最终打包到system分区(system/bin/dumpsys)。
@frameworks\native\cmds\dumpsys\android.bp
cc_binary {
name: "dumpsys",
defaults: ["dumpsys_defaults"],
srcs: [
"main.cpp",
],
}
5.3.2 dumpsys入口函数
我们通过执行adb指令
"adb shell dumpsys"
,可以启动dumpsys服务,其对应的入口函数如下:
@frameworks\native\cmds\dumpsys\main.cpp
int main(int argc, char* const argv[]) {
signal(SIGPIPE, SIG_IGN);
sp<IServiceManager> sm = defaultServiceManager();//获取SM对象
fflush(stdout);
if (sm == nullptr) {
ALOGE("Unable to get default service manager!");
std::cerr << "dumpsys: Unable to get default service manager!" << std::endl;
return 20;
}
Dumpsys dumpsys(sm.get());
return dumpsys.main(argc, argv);//进入dumpsys服务
}
这边比较关键的点是获取
ServiceManager对象
。
大家通过打印可以发现,dumpsys指令打印的数据是java进程的dump函数,而dumpsys也是独立的一个进程,那么dumpsys进程又是怎么和多个java进程通信的呢?没错,就是通过ServiceManager对象。
那么,ServiceManager对象是什么呢?ServiceManager是
Binder IPC通信
的管家,本身也是一个Binder服务,他相当于 “DNS服务器”,内部存储了serviceName与其Binder Service的对应关系,管理Java层和native层的service,支持addService()、getService()、checkService、listServices()等功能。(Binder机制此处就不展开细说)
5.3.3 dumpsys服务打印
5.3.3.1 dumpsys解析参数
当我们使用dumpsys指令,打印的数据太过冗长,一般会配合相关参数进行使用,例如:"dumpsys -l"、"dumpsys -t 100 battery"、"dumpsys --help",第一步我们会先解析目标参数。
@frameworks\native\cmds\dumpsys\dumpsys.cpp
int Dumpsys::main(int argc, char* const argv[]) {
...
while (1) {
...
c = getopt_long(argc, argv, "+t:T:l", longOptions, &optionIndex);//获取指令参数
...
switch (c) {
case 0://长参数
if (!strcmp(longOptions[optionIndex].name, "skip")) {//跳过某些服务打印
skipServices = true;
} else if (!strcmp(longOptions[optionIndex].name, "proto")) {
asProto = true;
} else if (!strcmp(longOptions[optionIndex].name, "help")) {//指令帮助
usage();
return 0;
} else if (!strcmp(longOptions[optionIndex].name, "priority")) {
...
} else if (!strcmp(longOptions[optionIndex].name, "pid")) {//只显示服务的pid
type = Type::PID;
} else if (!strcmp(longOptions[optionIndex].name, "thread")) {//仅显示进程使用情况
type = Type::THREAD;
}
break;
case 't'://超时时间设置,默认10秒
...
break;
case 'T'://超时时间设置,默认10秒
...
break;
case 'l'://显示支持的服务列表
showListOnly = true;
break;
default://其他参数
fprintf(stderr, "\n");
usage();
return -1;
}
}
...
}
5.3.3.2 skippedServices列表构造
dumpsys内部构造了skippedServices集合,用于记录需要忽略的服务。
@frameworks\native\cmds\dumpsys\dumpsys.cpp
int Dumpsys::main(int argc, char* const argv[]) {
...
for (int i = optind; i < argc; i++) {
if (skipServices) {
skippedServices.add(String16(argv[i]));//配置待忽略的服务
} else {
...
}
...
}
5.3.3.3 获取支持服务列表
dumpsys通过ServiceManager获取支持的服务集合,并排序。
@frameworks\native\cmds\dumpsys\dumpsys.cpp
int Dumpsys::main(int argc, char* const argv[]) {
...
if (services.empty() || showListOnly) {
services = listServices(priorityFlags, asProto);
setServiceArgs(args, asProto, priorityFlags);
}
...
}
Vector<String16> Dumpsys::listServices(int priorityFilterFlags, bool filterByProto) const {
Vector<String16> services = sm_->listServices(priorityFilterFlags);//通过sm获取服务集合
services.sort(sort_func);//集合排序
...
return services;
}
5.3.3.4 打印支持服务列表
在获取了服务集合后,会先检查服务是否存在,接着打印服务的名称,且如果当前指令设置了"-l"参数,仅打印服务集合,即流程结束。
@frameworks\native\cmds\dumpsys\dumpsys.cpp
int Dumpsys::main(int argc, char* const argv[]) {
...
const size_t N = services.size();//获取支持的服务个数
if (N > 1 || showListOnly) {
// first print a list of the current services
std::cout << "Currently running services:" << std::endl;
for (size_t i=0; i<N; i++) {
sp<IBinder> service = sm_->checkService(services[i]);//检查服务状态
if (service != nullptr) {
bool skipped = IsSkipped(skippedServices, services[i]);
std::cout << " " << services[i] << (skipped ? " (skipped)" : "") << std::endl;//打印服务名称
}
}
}
if (showListOnly) {//如果指令仅需要打印服务集合,则结束。
return 0;
}
...
}
5.3.3.5 打印目标服务
先遍历所有需要打印的服务,如果参数有指定服务名,即N为对应服务的数量,否则N为所有支持的服务数量。接着,开启线程,通过servicemanager调用远端的dump函数,利用管道和poll机制监听远端数据。最后如果超时或者dump结束,则关闭线程,释放相关资源。
@frameworks\native\cmds\dumpsys\dumpsys.cpp
int Dumpsys::main(int argc, char* const argv[]) {
...
for (size_t i = 0; i < N; i++) {
const String16& serviceName = services[i];
if (IsSkipped(skippedServices, serviceName)) continue;//跳过部分服务
if (startDumpThread(type, serviceName, args) == OK) {//step 1.创建dump打印的线程
...
std::chrono::duration<double> elapsedDuration;
size_t bytesWritten = 0;
status_t status =
writeDump(STDOUT_FILENO, serviceName, std::chrono::milliseconds(timeoutArgMs),
asProto, elapsedDuration, bytesWritten);//step 2.dump执行打印操作
if (status == TIMED_OUT) {//打印超时
std::cout << std::endl
<< "*** SERVICE '" << serviceName << "' DUMP TIMEOUT (" << timeoutArgMs
<< "ms) EXPIRED ***" << std::endl
<< std::endl;
}
...
bool dumpComplete = (status == OK);
stopDumpThread(dumpComplete);//step 3.结束dump打印线程
}
}
...
}
step 1. 创建dumpsys打印线程
创建了一条管道,接着开启了一个线程,通过ServiceManager对象读取目标服务的dump函数,即dump打印数据。
@frameworks\native\cmds\dumpsys\dumpsys.cpp
status_t Dumpsys::startDumpThread(Type type, const String16& serviceName,
const Vector<String16>& args) {
sp<IBinder> service = sm_->checkService(serviceName);//通过SM获取service对象
int sfd[2];
if (pipe(sfd) != 0) {//创建管道,用于读取service端数据
...
}
...
redirectFd_ = unique_fd(sfd[0]);
unique_fd remote_end(sfd[1]);
sfd[0] = sfd[1] = -1;
// dump blocks until completion, so spawn a thread..
activeThread_ = std::thread([=, remote_end{std::move(remote_end)}]() mutable {//创建线程
status_t err = 0;
switch (type) {
case Type::DUMP:
err = service->dump(remote_end.get(), args);//调用dump函数
break;
...
}
...
});
return OK;
}
step 2. dumpsys打印到终端
通过poll机制用来监听管道的数据,并将读取到的dump数据,打印至控制台。同时,通过计算剩余的时间,来判断当前是否读取超时。
@frameworks\native\cmds\dumpsys\dumpsys.cpp
status_t Dumpsys::writeDump(int fd, const String16& serviceName, std::chrono::milliseconds timeout,
bool asProto, std::chrono::duration<double>& elapsedDuration,
size_t& bytesWritten) const {
...
int serviceDumpFd = redirectFd_.get();
struct pollfd pfd = {.fd = serviceDumpFd, .events = POLLIN};
while (true) {
...
int rc = TEMP_FAILURE_RETRY(poll(&pfd, 1, time_left_ms()));//poll机制检测管道数据
if (rc < 0) {
...
} else if (rc == 0 || time_left_ms() == 0) {
status = TIMED_OUT;//计算剩余时间,来决定是否超时
break;
}
char buf[4096];
rc = TEMP_FAILURE_RETRY(read(redirectFd_.get(), buf, sizeof(buf)));//读取远端的数据
...
if (!WriteFully(fd, buf, rc)) {//打印至控制台
...
break;
}
totalBytes += rc;
}
...
return status;
}
step 3. 关闭dumpsys打印线程
将dumpsys打印的线程detach掉,相关的fd句柄reset掉,释放资源。
六、dumpsys的应用
如后续有什么应用dumpsys,或者有助于日常开发调试的场景,再补充,未完待续。
6.1 dumpsys常用指令
|
服务名
|
类名
|
指令
|
功能
|
| activity |
ActivityManagerService |
获取某个应用的Activity信息:
adb shell dumpsys activity a packagename
获取某个应用的Service信息:
adb shell dumpsys activity s packagename
获取某个应用的Broadcast信息:
adb shell dumpsys activity b packagename
获取某个应用的Provider信息:
adb shell dumpsys activity prov packagename
获取某个应用的进程状态:
adb shell dumpsys activity p packagename
获取当前界面的Activity信息:
adb shell dumpsys activity top | grep ACTIVITY
|
AMS相关信息 |
| package |
PackageManagerService |
adb shell dumpsys package
|
PMS相关信息 |
| window |
WindowManagerService |
adb shell dumpsys window
|
WMS相关信息 |
| input |
InputManagerService |
adb shell dumpsys input
|
IMS相关信息 |
| power |
PowerManagerService |
adb shell dumpsys power
|
PMS相关信息 |
| batterystats |
BatterystatsService |
adb shell dumpsys batterystats
|
电池统计信息 |
| battery |
BatteryService |
adb shell dumpsys battery
|
电池信息 |
| alarm |
AlarmManagerService |
adb shell dumpsys alarm
|
闹钟信息 |
| dropbox |
DropboxManagerService |
adb shell dumpsys dropbox
|
调试相关 |
| procstats |
ProcessStatsService |
adb shell dumpsys procstats
|
进程统计 |
| cpuinfo |
CpuBinder |
adb shell dumpsys cpuinfo
|
CPU |
| meminfo |
MemBinder |
adb shell dumpsys meminfo
|
内存 |
| gfxinfo |
GraphicsBinder |
adb shell dumpsys gfxinfo
|
图像 |
| dbinfo |
DbBinder |
adb shell dumpsys dbinfo
|
数据库 |
七、参考资料
dumpsys指令介绍:
https://developer.android.google.cn/studio/command-line/dumpsys?hl=zh-cn
管道:
https://www.cnblogs.com/naray/p/15365954.html
Binder:
https://blog.csdn.net/shenxiaolinil/article/details/128972302



