在上篇文章
别再用 float 布局了,flex 才是未来!
中,我们聊到 Flex 布局才是目前主流的布局方式。在文章最后,我们还贴了一个案例,并且还浅浅地讲解了一下。
有些小伙伴说,这讲解得太粗了,要是能够再深入讲解一下,顺便把代码分享分享就好了。那么,今天我们就继续来扒一扒这个项目的布局实现。
大体框架实现
这个项目是我在 CodePen 上找到的一个项目,地址是:
Glassmorphism Creative Cloud App Redesign
,其页面如下图所示。
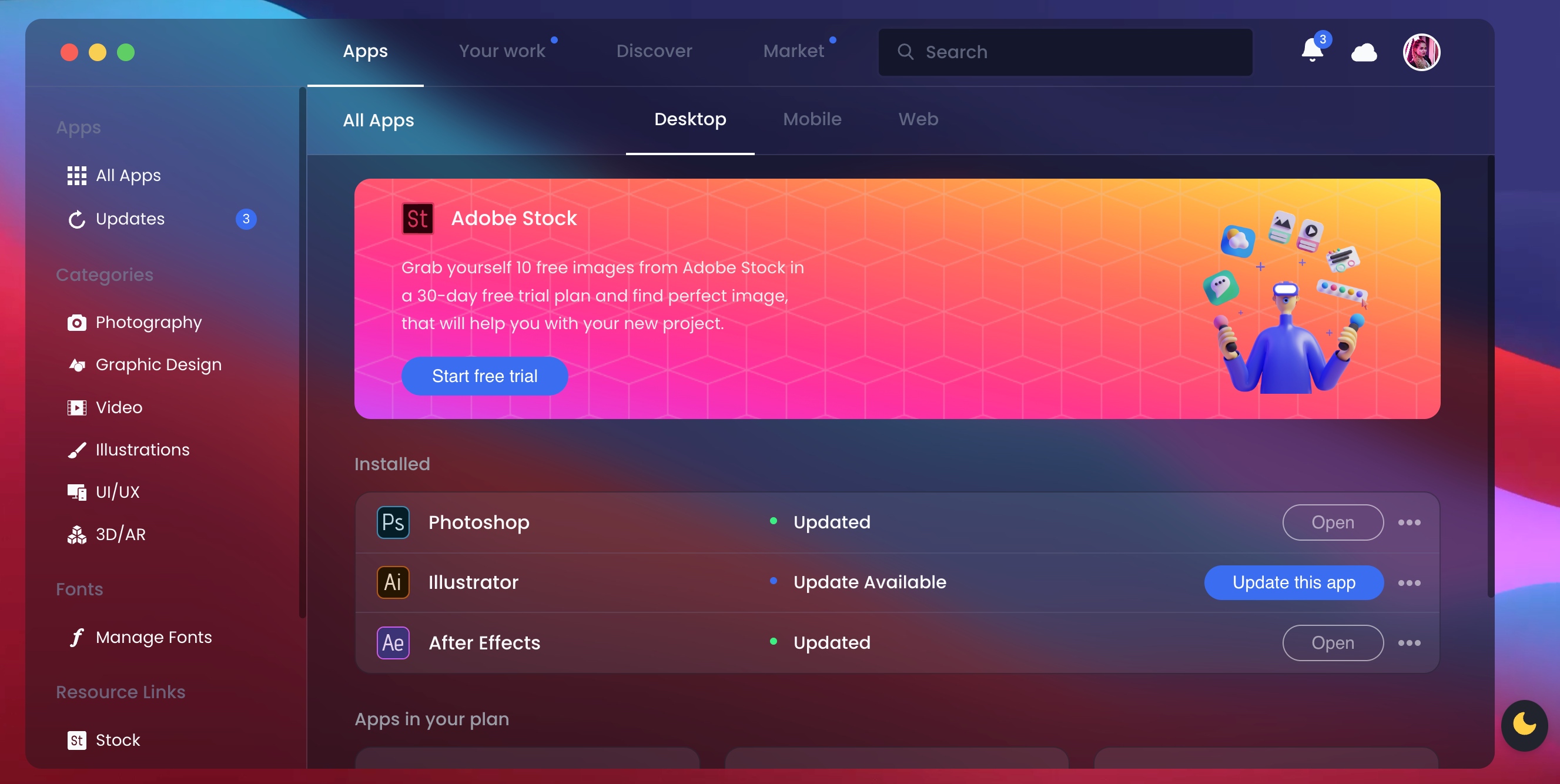
从上图可以看得出来,其布局还是非常清晰明了的。其最外层包括一个顶部的导航栏和一个下面的内容区域,用 html 描述大致是下面的代码。
<div class="app">
<div class="header"</div>
<div class="wrapper">/div>
</div>
如上面代码所示的布局,我们用 Flex 布局来写,大致就是如下代码所示。
.app {
display: flex;
flex-direction: column;
background-color: var(--theme-bg-color);
max-width: 1250px;
max-height: 860px;
width: 100%;
height: 90vh;
overflow: hidden;
position: relative;
font-size: 15px;
font-weight: 500;
border-radius: 14px;
backdrop-filter: blur(20px);
-webkit-backdrop-filter: blur(20px);
}
.header {
display: flex;
height: 58px;
padding: 0 30px;
background-color: black;
}
.wrapper {
display: flex;
flex: 1;
background-color: red;
overflow: hidden;
}
加了上面的样式代码之后,整体的效果就变成了如下图的样式。

此时去拖动窗口大小,会发现红色背景的内容部分是会自动改变高度的。
接下来,我们继续分析剩下的内容。
对于导航栏而言,我们也可以把它看成是一个 Flex 容器,其内部划分为 4 个元素。我加上这部分的代码内容之后,整体的 html 代码如下所示。
<div class="app">
<div class="header">
<div class="menu-circle"></div>
<div class="header-menu"></div>
<div class="search-bar"></div>
<div class="header-profile"></div>
</div>
<div class="wrapper">
</div>
</div>
</div>
此时,我们再加上导航栏这部分的 CSS 样式,如下代码所示。
.menu-circle {
flex-shrink: 0;
width: 100px;
margin-right: 50px;
background-color: gray;
}
.header-menu {
flex-shrink: 0;
width: 400px;
margin-right: 50px;
background-color: gray;
}
.search-bar {
flex-shrink: 0;
width: 200px;
margin-right: 50px;
background-color: gray;
}
.header-profile {
flex-shrink: 0;
width: 100px;
margin-right: 50px;
background-color: gray;
}
加上之后,其效果图如下图所示。

到这里,我想你应该会发现,使用 Flex 布局其实就是一层层把内容划分,然后设置好合适的 flex 属性,布局变得非常简单了。这里我就不继续讲解其他区域的布局代码了,我直接将我最终完成的一个布局草稿图给出来,如下图所示。
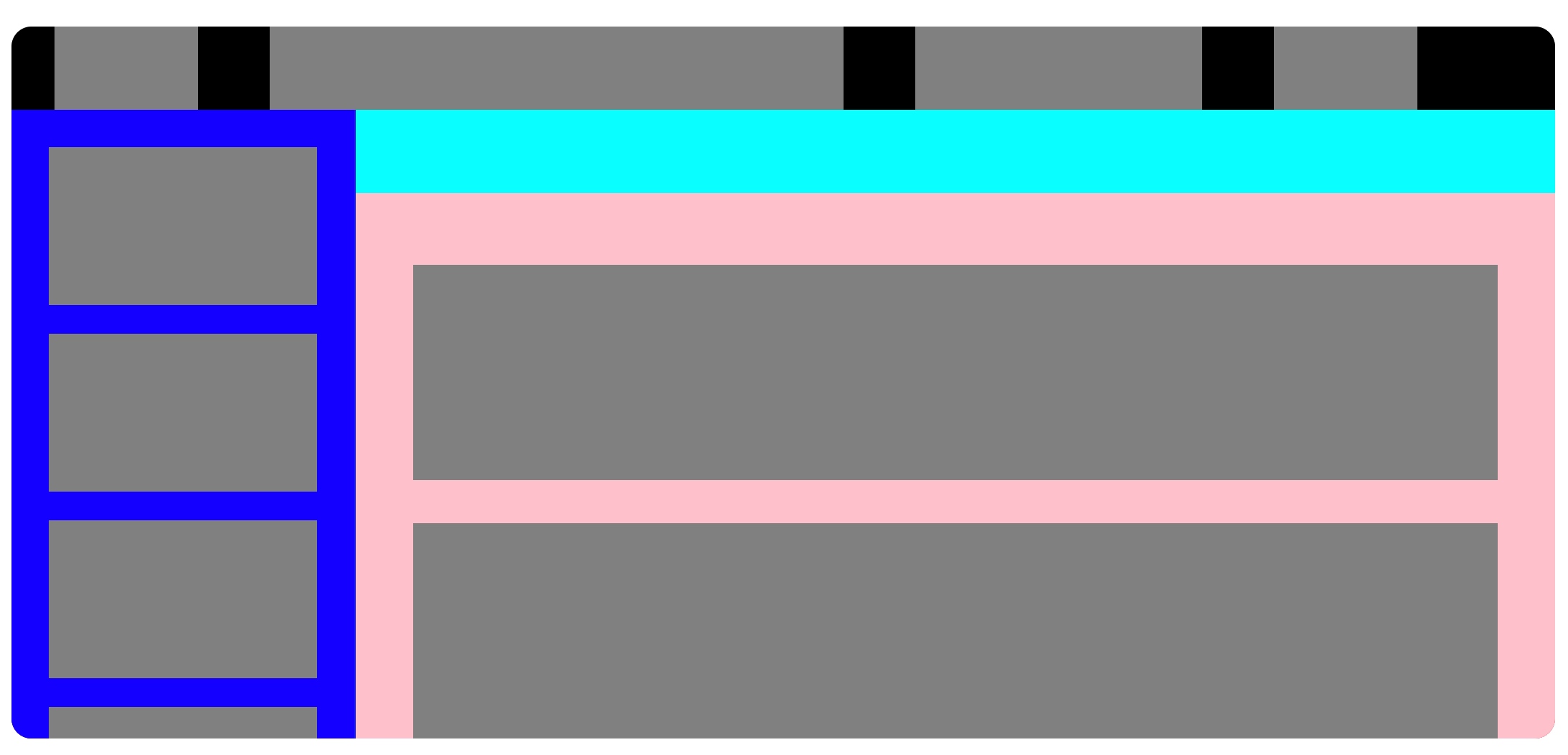
我们在实际要做的时候,就是这样一点点去将需要弄的区域做出来,接下来就是填上所需要的内容,包括文字、图标、颜色等等信息。上面我自己练习布局的 HTML 和 CSS 代码都在 CodePen 上,有兴趣的可以参考下:
CodePen Home Flex 布局项目实战
。
纸上得来终觉浅,虽然 Flex 布局简单,但也有非常多的实现细节需要去琢磨。这里我就不事无巨细地讲解所有的样式实现了,我将摘取 5 个比较常见的样式实现来一步步讲解如何实现它们。这 5 个例子的代码都放在了 CodePen 上,感兴趣的可以自己看看:
CSS最佳实践 - CodePen
。
细节实现
扁平化按钮
首先,我们将上面的例子整理一下,作为我们的第一个 CSS 最佳实践。
要实现如下图所示的扁平化按钮,应该怎么写呢?

实现思路
使用 padding 属性控制按钮文字与边框的距离。
实现步骤
1、首先,使用 button 元素来作为按钮的 html 元素。
2、接着,使用 padding 属性来控制按钮文字与上下左右的距离。
3、最后,设置按钮文字、背景颜色、背景圆角、边框、鼠标手势属性。
整体实现代码:
<div>
<h1>1. 扁平化图标的实现</h1>
<div>
<button class="content-btn">Start free trial</button>
</div>
</div>
.content-btn {
padding: 8px 26px;
border: none;
border-radius: 20px;
color: #fff;
background-color: #3a6df0;
cursor: pointer;
}
带图标的菜单
一个菜单,左边有一个图标,如下图所示,如何实现?

核心思路
使用 flex 布局设置菜单项。将图标与文字放在同一个层级,使用 flex 布局对齐图标和文字,设置 svg 图标的大小。
实现步骤
首先,使用 a 属性表示一个菜单,外层包一个 div 容器,如下代码所示。
<div class="side-menu">
<a href=""></a>
<a href=""></a>
</div>
接着,每一个 a 元素表示一个菜单。在菜单里面,图标与菜单文字在同一层,如下代码所示。
<div class="side-menu">
<a href="">
<svg></svg>带图标的菜单1
</a>
<a href="">
<svg></svg>带图标的菜单2
</a>
</div>
接着,构造好 html 层次之后,可以构思 CSS 布局。菜单项(.side-menu)所在容器使用 flex 布局。
.side-menu {
display: flex;
flex-direction: column;
white-space: no-wrap;
}
最后,单个菜单(.side-menu a)内部则也使用 flex 布局,同时设置垂直居中对齐,让图标和文字对齐。此外,还为图标设置大小、悬浮显示背景颜色等。相关 CSS 代码如下所示。
.side-menu a {
display: flex;
align-items: center;
font-weight: 400;
font-size: 14px;
text-decoration: none;
padding: 10px;
color: #000;
/* 设置宽度 */
width: 150px;
}
.side-menu a:hover {
background-color: rgba(12 15 25 / 30%);
border-radius: 6px;
}
.side-menu svg {
width: 16px;
margin-right: 8px;
}
完整代码见:
CSS最佳实践 - 3、 带图标的菜单 - CodePen
图标上的红点提醒
对于许多应用来说,会通过红点或者未读数量来提醒用户,那么如何实现类似于下图的提醒呢?

核心思路
使用 relative 或 absolute 布局让红点飘到右上角。其他的样式思路包括:使用 border-radius 画一个圆;使用 flex 布局使数字上下左右居中。
实现步骤
首先,在菜单后面加上 span 标签,填入对应的内容,如下代码所示。
带图标的菜单<span class="notification-number updates">3</span>
接着,画出圆圈以及背景颜色,以及字体大小颜色,如下代码所示。
.notification-number {
width: 16px;
height:16px;
background-color: #3a6df0;
border-radius: 50%;
font-size:10px;
color: #fff;
}
接着,使用 flex 布局设置圆圈和字体的上下左右居中对齐。
.notification-number {
display: flex;
align-items: center;
justify-content: center;
}
最后,使用相对布局调整图形图标位置。
.notification-number {
position: relative;
top: -6px;
right: -6px;
}
到这里,图标上的红点提示就完成了。上面这种实现方式是使用 relative 来实现的,完整代码见:
CSS最佳实践 - 4、图标上的红点提醒(relative实现) - CodePen
实际上,我们也可以使用 absolute 对齐的方式来实现,其完整代码见:
CSS最佳实践 - 5、图标上的红点提醒(absolute实现) - CodePen
。
这两种的区别在于:它们偏移的参考对象不同。对于 relative 而言,其相对于其父级容器偏移。但是 absolute 则是相对于最近的非 static 定位祖先元素的偏移。
搜索表单
如下图所示的搜索框,如何实现?

核心思路
使用背景图以及位置偏移设置搜索放大镜图标。
实现步骤
首先,整理出 html 元素层级。
<div class="search-bar">
<input type="text" placeholder="Search">
</div>
接着,设置搜索框大小以及背景,还有文字字体颜色。
.search-bar input {
height: 40px;
width: 150px;
padding: 0 20px 0 40px;
background-color: #14162b;
border-radius: 5px;
border: none;
font-family: "Poppins", sans-serif;
font-size: 15px;
font-weight: 500;
color: #fff;
}
最后,设置背景图以及位置。
.search-bar input {
background-image: url("data:image/svg+xml;charset=UTF-8,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 56.966 56.966' fill='%23717790c7'%3e%3cpath d='M55.146 51.887L41.588 37.786A22.926 22.926 0 0046.984 23c0-12.682-10.318-23-23-23s-23 10.318-23 23 10.318 23 23 23c4.761 0 9.298-1.436 13.177-4.162l13.661 14.208c.571.593 1.339.92 2.162.92.779 0 1.518-.297 2.079-.837a3.004 3.004 0 00.083-4.242zM23.984 6c9.374 0 17 7.626 17 17s-7.626 17-17 17-17-7.626-17-17 7.626-17 17-17z'/%3e%3c/svg%3e");
background-size: 14px;
background-repeat: no-repeat;
background-position: 16px 48%;
}
完整代码见:
CSS最佳实践 - 6. 搜索表单 - CodePen
顶部菜单
要实现如下图所示的顶部菜单效果,应该如何实现呢?

核心思路
使用 padding 设置菜单项带下,使用 flex 布局排列菜单项。
实现步骤
首先,写好 html 结构,使用 a 元素来实现,如下代码所示。
<div class="menu">
<a class="is-active" href="#">首页</a>
<a href="#">投资者关系</a>
<a href="#">企业社会责任</a>
<a href="#">加入我们</a>
</div>
接着,设置菜单项的样式,用 padding 撑开并设置字体大小,如下代码所示。
.menu a {
display: inline-block;
padding: 20px 30px;
text-decoration: none;
color: gray;
}
接着,设置激活状态下的菜单项以及鼠标悬浮下的菜单项效果。
.menu a.is-active,
.menu a:hover {
color: black;
border-bottom: 2px solid black;
}
最后,在顶层容器设置 flex 布局,这样每个菜单项之间就不会有间隙。
.menu {
display: flex;
align-items: center;
flex-shrink: 0;
}
完整代码见:
CSS最佳实践 - 7. 顶部菜单 - CodePen
关于 Flex 布局实战的分享就到此为止。希望这篇文章也能给你带来收获,让你更好掌握 CSS 布局技能。
如果这篇文章对你有帮助,记得一键三连支持我!
参考资料