zabbix搭建
简介
Zabbix 是一个开源的监控解决方案,用于监控各种网络服务、服务器和其他网络硬件。它能够采集各类监控数据,并提供强大的报警和报告功能。
1. 前置环境准备
我们采用编译安装的方式,需要提前准备好一个LNMP或者LAMP的环境
1.1 搭建LNMP
[root@oe01 ~]# yum install nginx php php-fpm -y
默认安装完之后php-fpm是采用socker通信的。我们将他修改为监听9000端口
[root@oe01 ~]# vim /etc/php-fpm.d/www.conf
38 listen = /run/php-fpm/www.sock
39 listen = 127.0.0.1:9000
[root@oe01 ~]# systemctl restart php-fpm
多添加一行即可,安装完php之后他会默认帮我们产生2个nginx的配置文件,我们不用他的。将他改名
[root@oe01 ~]# mv /etc/nginx/conf.d/php-fpm.conf /etc/nginx/conf.d/php-fpm.conf.bak
[root@oe01 ~]# mv /etc/nginx/default.d/php.conf /etc/nginx/default.d/php.conf.bak
然后我们重新编写一个nginx的配置文件
[root@oe01 ~]# cp /etc/nginx/nginx.conf.default /etc/nginx/nginx.conf
cp: overwrite '/etc/nginx/nginx.conf'? y
[root@oe01 ~]# vim /etc/nginx/nginx.conf
43 location / {
44 root /data/zabbix;
45 index index.php index.html index.htm;
46 }
65 location ~ \.php$ {
66 root /data/zabbix;
67 fastcgi_pass 127.0.0.1:9000;
68 fastcgi_index index.php;
69 fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
70 include fastcgi_params;
71 }
你的行号跟我的可能不太一样,大概是这些内容。然后重启nginx
[root@oe01 ~]# mkdir -p /data/zabbix
[root@oe01 ~]# systemctl restart nginx
接下来自行去测试php是否可以正常解析。如果可以那我们的LNMP环境就搭建完成了。接下来开始搭建监控。如果解析不了注意看网站根目录是在
/data/zabbix
,不要放错地方了
2. zabbix准备工作
现在我们开始安装php模块
2.1 安装php模块以及编译所需工具
root@oe01 ~]# yum install php-gd php-mbstring php-bcmath php-xml php-ldap php-mysqlnd mysql-devel pcre-devel openssl-devel zlib-devel libxml2-devel net-snmp-devel net-snmp libssh2-devel OpenIPMI-devel libevent-devel openldap-devel libcurl-devel gcc make -y
2.2 修改php配置
默认的php配置是无法让zabbix正常运行的,所以我们需要修改一下
[root@oe01 ~]# sed -i "s/post_max_size = 8M/post_max_size = 16M/g" /etc/php.ini
[root@oe01 ~]# sed -i "s/max_execution_time = 30/max_execution_time = 300/g" /etc/php.ini
[root@oe01 ~]# sed -i "s/max_input_time = 60/max_input_time = 300/g" /etc/php.ini
[root@oe01 ~]# systemctl restart php-rpm
这几个配置必须改,因为不改的话等会安装的时候会过不了环境检测的
2.3 编译安装zabbix
2.3.1 下载tar包
[root@oe01 opt]# wget https://cdn.zabbix.com/zabbix/sources/oldstable/6.2/zabbix-6.2.8.tar.gz
[root@oe01 opt]# ls zabbix-6.2.8.tar.gz
zabbix-6.2.8.tar.gz
2.3.2 解压
[root@oe01 opt]# tar -zxvf zabbix-6.2.8.tar.gz
2.3.3 创建用户/组
[root@oe01 opt]# groupadd --system zabbix
[root@oe01 opt]# useradd --system -g zabbix -d /usr/lib/zabbix -s /sbin/nologin -c "Zabbix User" zabbix
2.3.4 开始安装
[root@oe01 zabbix-6.2.8]# ./configure --sysconfdir=/etc/zabbix --enable-server --enable-agent --with-mysql --with-ssh2 --with-zlib --with-libpthread --with-libevent --with-libpcre --with-net-snmp --with-libcurl --with-libxml2 --with-openipmi --with-openssl --with-ldap
等待执行完成,如果有报错检查一下之前安装的东西是不是缺什么
正常执行完之后应该是这样的
***********************************************************
* Now run 'make install' *
* *
* Thank you for using Zabbix! *
* <http://www.zabbix.com> *
***********************************************************
然后我们执行
make install
[root@oe01 zabbix-6.2.8]# make install
Making install in misc
make[1]: Entering directory '/opt/zabbix-6.2.8/misc'
make[2]: Entering directory '/opt/zabbix-6.2.8/misc'
make[2]: Nothing to be done for 'install-exec-am'.
make[2]: Nothing to be done for 'install-data-am'.
make[2]: Leaving directory '/opt/zabbix-6.2.8/misc'
make[1]: Leaving directory '/opt/zabbix-6.2.8/misc'
make[1]: Entering directory '/opt/zabbix-6.2.8'
make[2]: Entering directory '/opt/zabbix-6.2.8'
make[2]: Nothing to be done for 'install-exec-am'.
make[2]: Nothing to be done for 'install-data-am'.
make[2]: Leaving directory '/opt/zabbix-6.2.8'
make[1]: Leaving directory '/opt/zabbix-6.2.8'
执行完成是这样的
2.3.5 配置数据库
前面我们没有提到数据库的安装,因为LNMP里面的M就是MySQL/Mariadb,所以你自行安装就可以了,我还是安装一下吧
[root@oe01 zabbix-6.2.8]# yum remove mariadb-server # 这一步不用执行,我是为了还原数据库
[root@oe01 zabbix-6.2.8]# yum install mariadb-server
[root@oe01 zabbix-6.2.8]# systemctl restart mariadb
[root@oe01 zabbix-6.2.8]# mysql_secure_installation
完成初始化之后登录数据库
[root@oe01 zabbix-6.2.8]# mysql -uroot -p
MariaDB [(none)]> create database zabbix charset utf8 collate utf8_bin;
Query OK, 1 row affected (0.000 sec)
MariaDB [(none)]> create user 'zabbix'@'%' identified by '123';
Query OK, 0 rows affected (0.001 sec)
MariaDB [(none)]> grant all on zabbix.* to 'zabbix'@'%';
Query OK, 0 rows affected (0.001 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.000 sec)
接下来导入数据到数据库
[root@oe01 zabbix-6.2.8]# cd database/mysql/
[root@oe01 mysql]# mysql -uroot -p123 zabbix < schema.sql
[root@oe01 mysql]# mysql -uroot -p123 zabbix < images.sql
[root@oe01 mysql]# mysql -uroot -p123 zabbix < data.sql
[root@oe01 mysql]# mysql -uroot -p123 zabbix < double.sql
[root@oe01 mysql]# mysql -uroot -p123 zabbix < history_pk_prepare.sql
注意顺序不要错。错了会导入失败报错的
到这里,zabbix的准备工作全部完成
3. 配置zabbix
3.1 修改配置文件
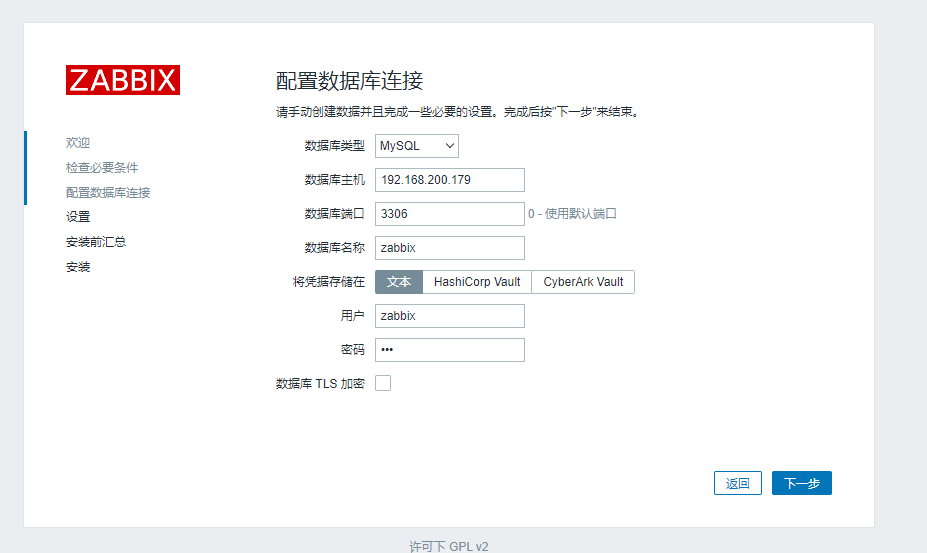
[root@oe01 ~]# vim /etc/zabbix/zabbix_server.conf
DBHost=192.168.200.179 # 改为数据库地址
DBPassword=123 # 改为数据库的密码
DBPort=3306 # 数据库的端口
ListenPort=10051 # 将这一行取消注释即可
然后我们启动zabbix
[root@oe01 ~]# zabbix_server -c /etc/zabbix/zabbix_server.conf
3.2 Web界面部署
[root@oe01 ~]# cd /data/zabbix/
[root@oe01 zabbix]# cp -r /opt/zabbix-6.2.8/ui/* .
[root@oe01 zabbix]# chown nginx:nginx -R /data/zabbix/
进入浏览器进行后续操作

语言选择简体中文
时间选择北京时间
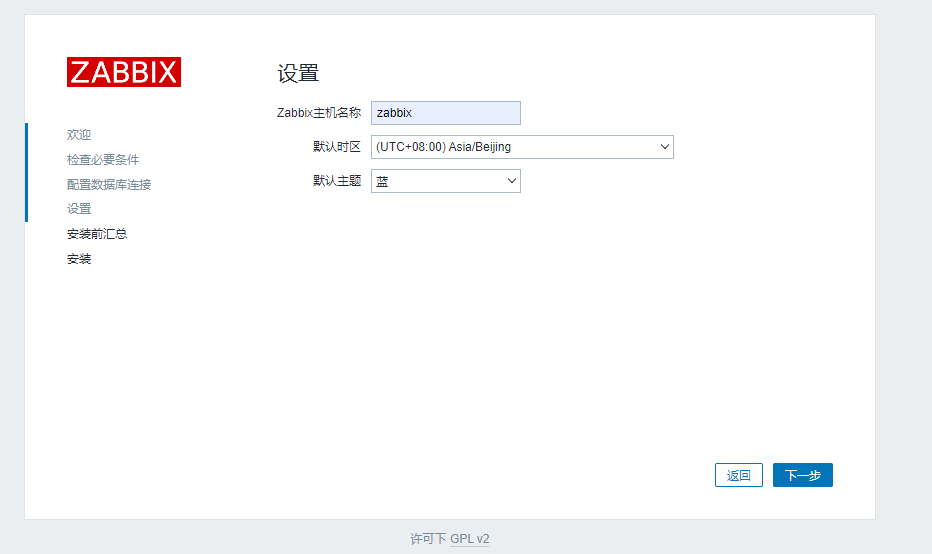
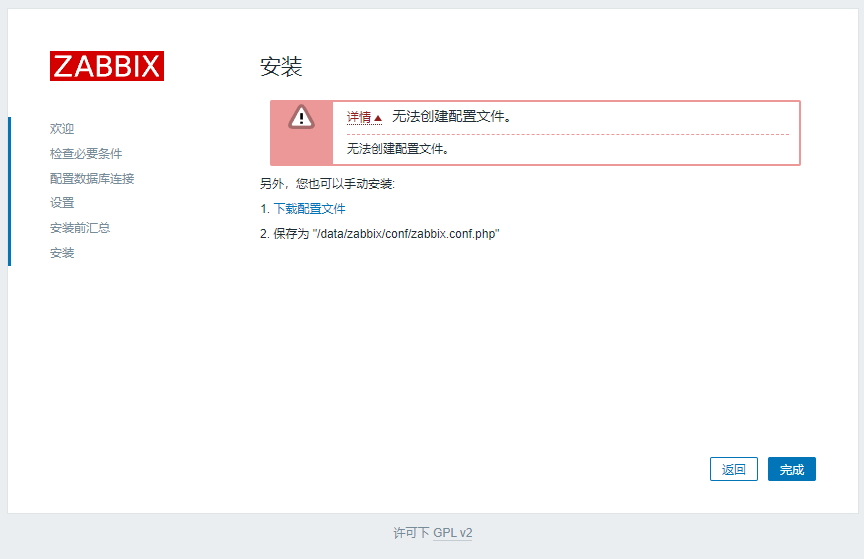
这里有这个报错我们可以点击下载配置文件,然后传到服务器上去
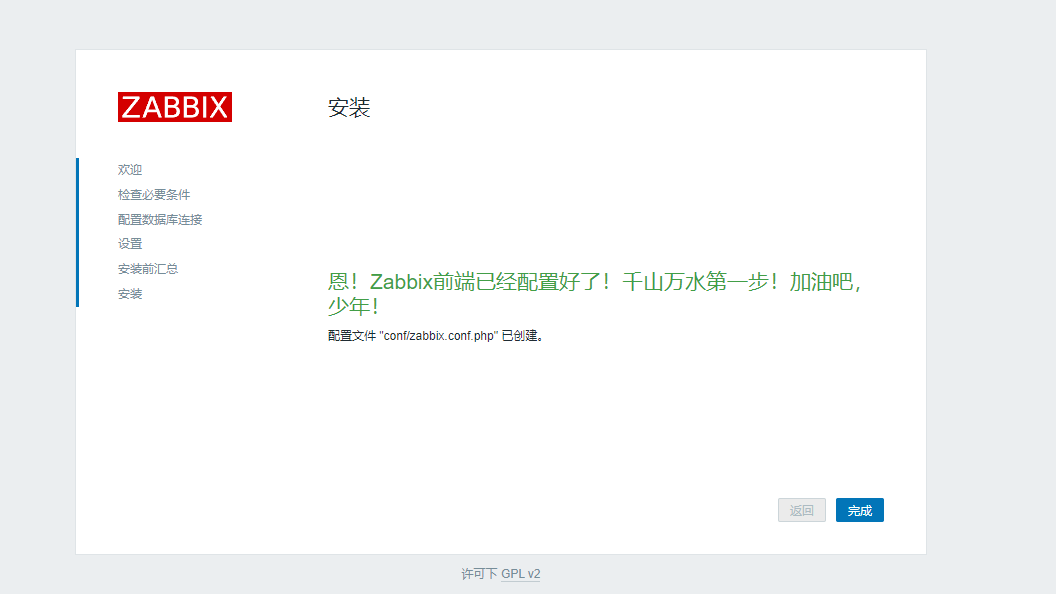
传好之后点击完成,就会提示你zabbix已经配置好了
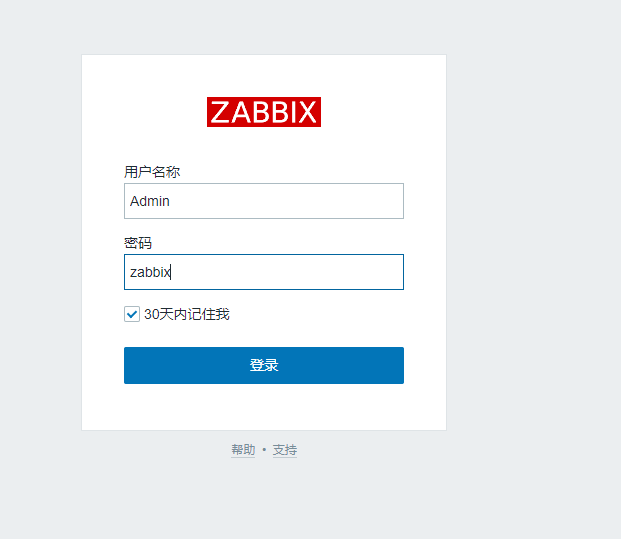
默认的登录用户名是
Admin
密码是
zabbix
服务端就已经搞定了
4. 安装agent
agent安装在被监控的节点上
[root@oe01 ~]# rpm -Uvh https://repo.zabbix.com/zabbix/6.2/rhel/8/x86_64/zabbix-release-6.2-3.el8.noarch.rpm
[root@oe01 ~]# yum install zabbix-agent2 -y
然后我们修改相关的配置文件
[root@oe01 ~]# vim /etc/zabbix/zabbix_agent2.conf
Server=192.168.200.179
[root@oe01 ~]# systemctl restart zabbix-agent2.service
将server这里改为zabbix-server的地址
5. 添加主机
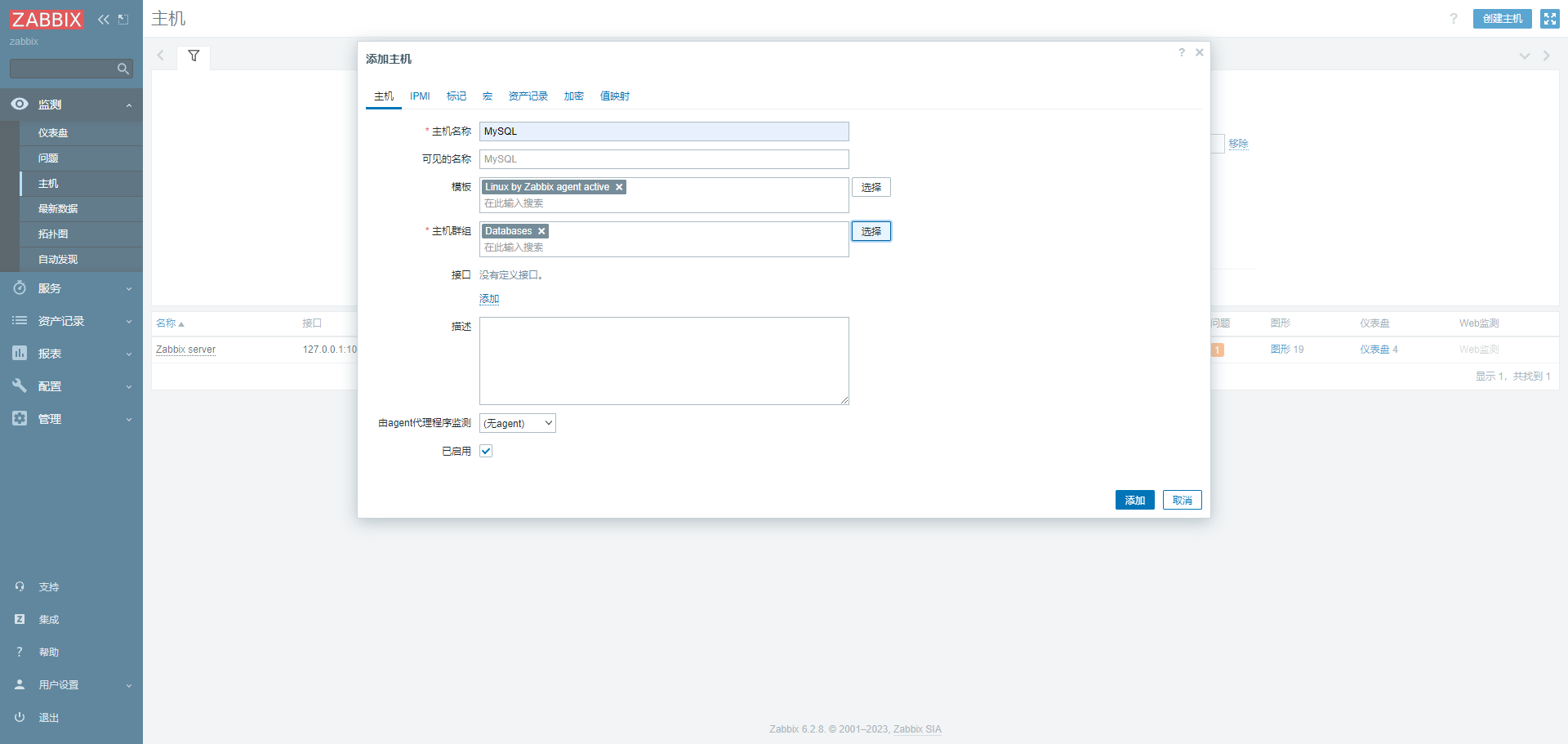

点进主机这里的时候会发现这里没有显示中文,我们需要将windows上的字体上传到服务器上
windows字体路径
C:\Windows\Fonts\msyh.ttc
[root@oe01 fonts]# pwd
/data/zabbix/assets/fonts
将字体上传到这个目录
[root@oe01 fonts]# ls
DejaVuSans.ttf MSYH.TTC
[root@oe01 fonts]# mv DejaVuSans.ttf DejaVuSans.ttf.bak
[root@oe01 fonts]# mv MSYH.TTC DejaVuSans.ttf
将原有的字体文件备份,再将我们上传的字体改为之前的那个文件名即可,回到网页刷新
字体就已经出来了