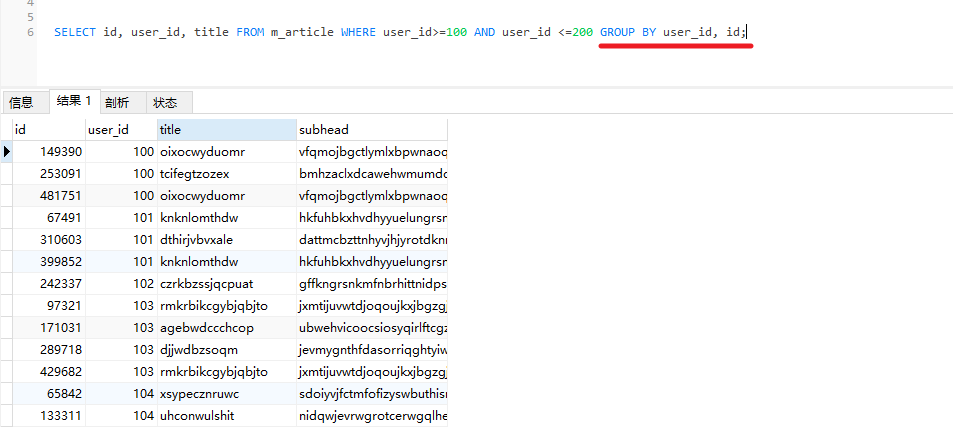
鸿蒙NEXT应用上架与分发步骤详解
大家好,我是 V 哥。今天的文章来聊一聊HarmonyOS NEXT应用上架。当你开发、调试完HarmonyOS应用/元服务,就可以前往AppGallery Connect申请上架,华为审核通过后,用户即可在华为应用市场获取您的HarmonyOS应用/元服务。
HarmonyOS会通过数字证书与Profile文件等签名信息来保证应用的完整性,需要上架的HarmonyOS应用/元服务都必须通过签名校验,所以上架前,您需要先完成签名操作。

1.生成密钥和证书请求文件
- 打开DevEco Studio,菜单选择“Build > Generate Key and CSR”。
- Key Store File可以点击“Choose Existing”选择已有的密钥库文件(存储有密钥的.p12文件),跳转至步骤4继续配置;如果没有密钥库文件,点击“New”,跳转至步骤3进行创建。
- 在“Create Key Store”界面,填写密钥库信息后,点击“OK”。
- Key Store File:设置密钥库文件存储路径,并填写p12文件名。
- Password:设置密钥库密码,必须由大写字母、小写字母、数字和特殊符号中的两种以上字符的组合,长度至少为8位。请记住该密码,后续签名配置需要使用。
- Confirm Password:再次输入密钥库密码。
- 在“Generate Key and CSR”界面继续填写密钥信息后,点击“Next”。
- Alias:密钥的别名信息,用于标识密钥名称。请记住该别名,后续签名配置需要使用。
- Password:密钥对应的密码,与密钥库密码保持一致,无需手动输入。
- Validity:证书有效期,建议设置为25年及以上,覆盖元服务的完整生命周期。
- Certificate:输入证书基本信息,如组织、城市或地区、国家码等。
- 在“Generate Key and CSR”界面设置CSR文件存储路径和CSR文件名,点击“Finish”。
- CSR文件创建成功后,将在存储路径下获取生成密钥库文件(.p12)和证书请求文件(.csr)。
2.申请发布证书
- 登录
AppGallery Connect
,选择“用户与访问”。 - 左侧导航栏选择“证书管理”,进入“证书管理”页面,点击“新增证书”。
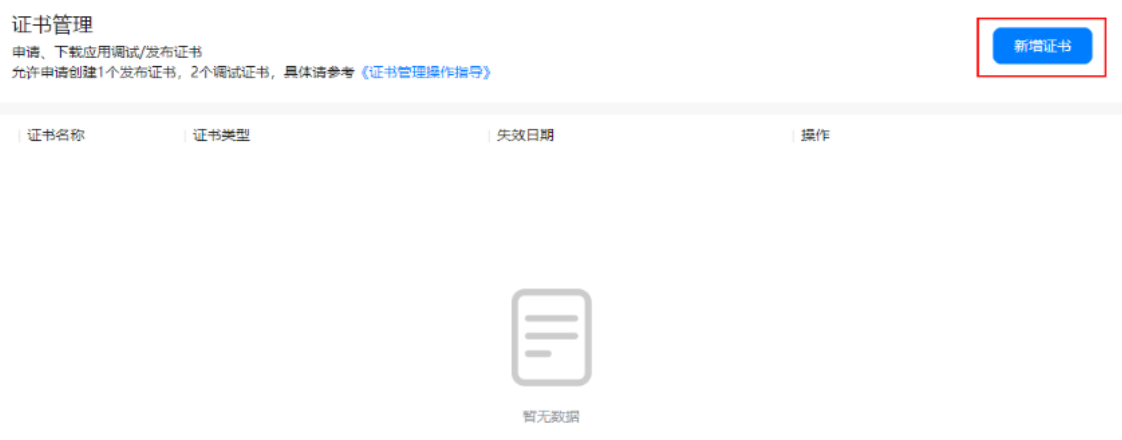
- 在弹出“新增证书”界面填写相关信息后,点击“提交”。
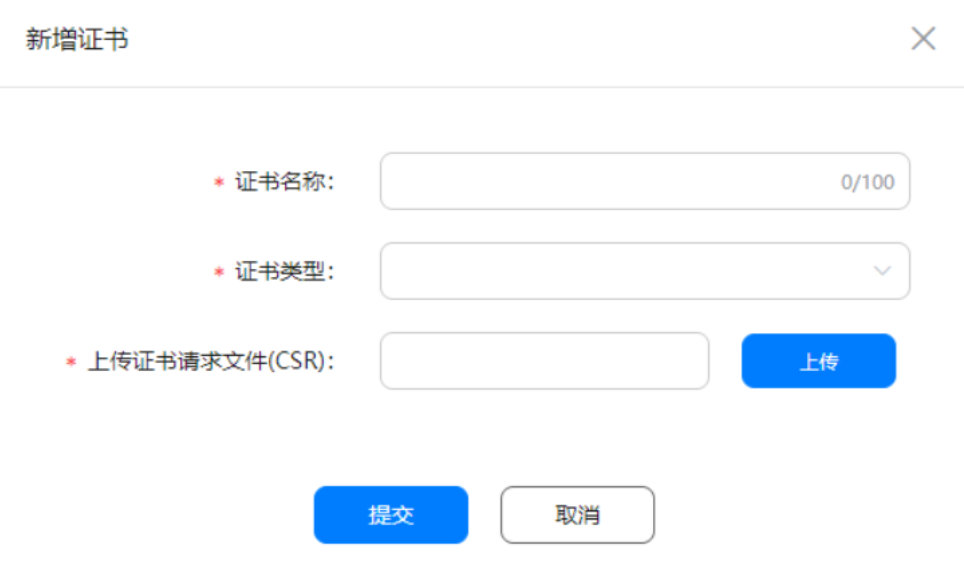
- 证书申请成功后,“证书管理”页面展示生成的证书内容。
- 点击“下载”将生成的证书保存至本地。
- 每个帐号最多申请1个发布证书,如果证书已过期或者无需使用,点击“废除”即可删除证书。
3.申请发布Profile
- 登录
AppGallery Connect
,选择“我的项目”。 - 找到对应项目,点击项目卡片中需要发布的元服务。
- 导航选择“HarmonyOS应用 > HAP Provision Profile管理”,进入“管理HAP Provision Profile”页面,点击“添加”。
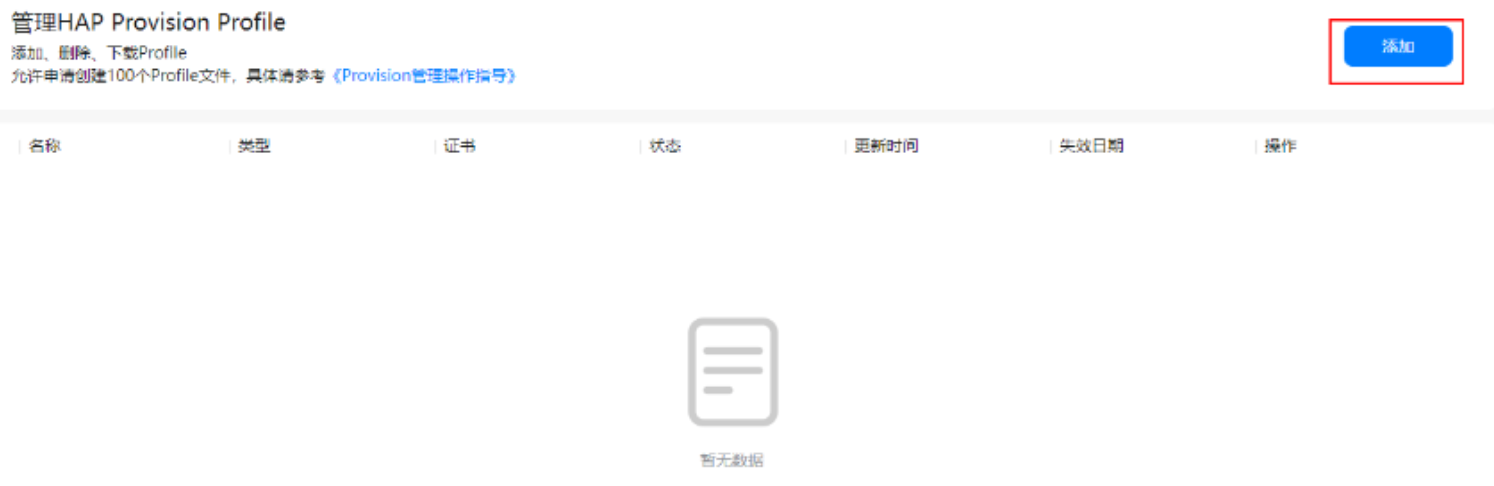
- 在“HarmonyAppProvision信息”界面填写相关信息,点击“提交”。
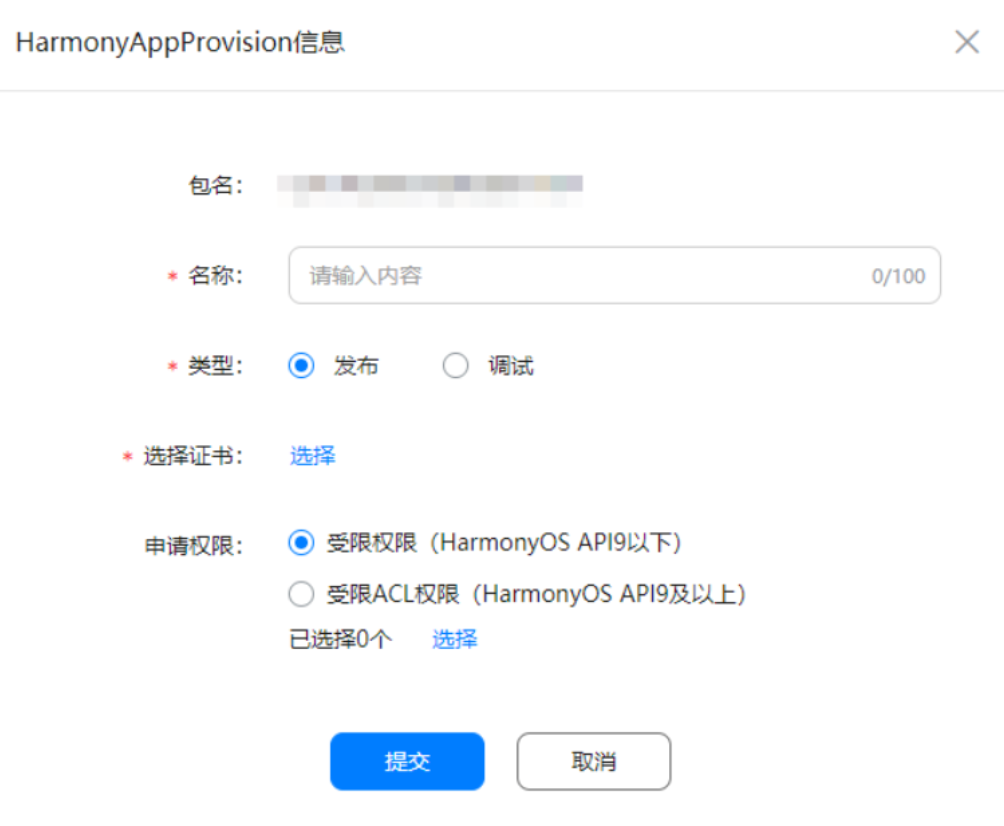
- 申请成功,即可在“管理HAP Provision Profile”页面查看Profile信息。点击“下载”,将文件下载到本地。
4.配置签名信息
- 打开DevEco Studio,菜单选择“File > Project Structure”,进入“Project Structure”界面。
- 导航选择“Project”,点击“Signing Configs”页签,填写相关信息后,点击“OK”。
- Store File:密钥库文件,选择生成密钥和证书请求文件时生成的.p12文件。
- Store Password:密钥库密码,需要与生成密钥和证书请求文件时设置的密钥库密码保持一致。
- Key alias:密钥的别名信息,需要与生成密钥和证书请求文件时设置的别名保持一致。
- Key password:密钥的密码,需要与生成密钥和证书请求文件时设置的密码保持一致。
- Sign alg:固定设置为“SHA256withECDSA”。
- Profile file:选择申请发布Profile时下载的.p7b文件。
- Certpath file:选择申请发布Profile时下载的.cer文件。
5.编译打包
- 打开DevEco Studio,菜单选择“Build > Build Hap(s)/APP(s) > Build APP(s)”。
- 等待编译构建签名的HarmonyOS应用/元服务,编译完成后,可在工程目录build > outputs > default目录下获取用于上架的软件包。
6.上架HarmonyOS应用/元服务
登录
AppGallery Connect
,选择“我的应用”。在应用列表首页中点击“HarmonyOS”页签。
点击待发布的应用/元服务,在左侧导航栏选择“应用信息”菜单。
填写应用的基本信息,如语言,应用名称,应用介绍等,上传应用图标,所有配置完成后点击“保存”。
填写版本信息,如发布国家或地区、上传软件包、提交资质材料等,所有配置完成后点击右上角“提交审核”。等待审核结果就可以了。