在经过长时间对WxPython的深入研究,并对其构建项目有深入的了解,以及完成对基础框架的完整改写后,终于在代码生成工具完全整合了基于 Python 跨平台方案项目的代码快速生成了,包括基于FastApi 的后端Web API项目,以及前端的WxPython前端界面项目。本篇随笔主要介绍跨平台WxPython项目的前端代码生成内容。
1、代码生成工具的整合处理
在前面随笔《
基于SqlAlchemy+Pydantic+FastApi的Python开发框架
》中提到过,对于基于FastApi的项目我们已经使用自家的代码生成工具快速进行代码的生成,FastApi+SqlAlchemy+Python后端代码生成,可以生成模型、Schema对象、CRUD封装类、Endpoint路由类等。
本次在基于对WxPython的深入研究,并对我基础框架的内容进行全部的改写后,整理了基于WxPython的项目代码生成,其中包括生成列表界面、新增/编辑界面、WebApi调用类、实体信息等。对WxPython跨平台项目界面的有兴趣的可以参考随笔《
分享一个纯Python开发的系统程序,基于VSCode + WxPython开发的跨平台应用系统
》。
至此,整个Python的项目前后端串联起来,完成了一个完整的项目了。
代码生成工具可以到地址下载:
https://www.iqidi.com/database2sharp.htm
,使用代码生成工具来快速开发项目代码,有很多好处。
减少重复工作
:自动生成常用代码(如数据模型、CRUD 操作、API 接口等),减少手动编写的时间。
专注于核心逻辑
:开发者可以将时间集中在业务逻辑和复杂问题的解决上,而非基础代码的编写。
模块化和规范化
:生成代码一般遵循既定的架构和风格,便于后续维护和扩展。
初学者友好
:新手开发者可以通过代码生成工具快速上手,了解项目结构和基础代码。
代码生成工具在提升开发效率、降低出错率、标准化代码方面具有显著优势,尤其在重复性工作较多或团队合作时尤为适用。
1)后端项目代码的生成
Python + FastAPI项目是一个Web API的项目,为各个前端提供接口的后端项目,其界面自动整合Swagger的文档界面,如下所示。
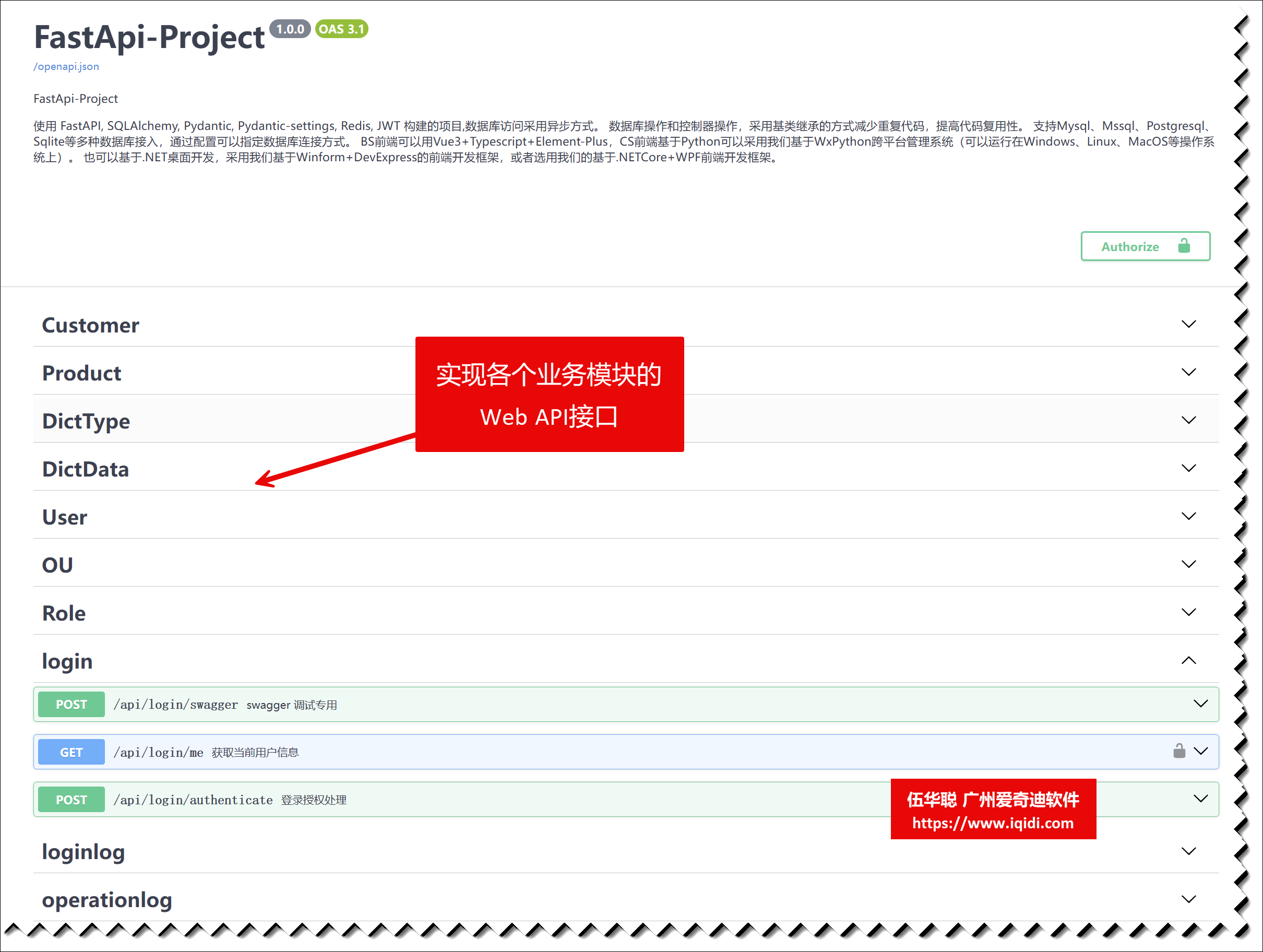
在代码生成工具打开数据库列表后,右键菜单可以选择生成对应的Python+FastApi后端项目,如下界面所示。
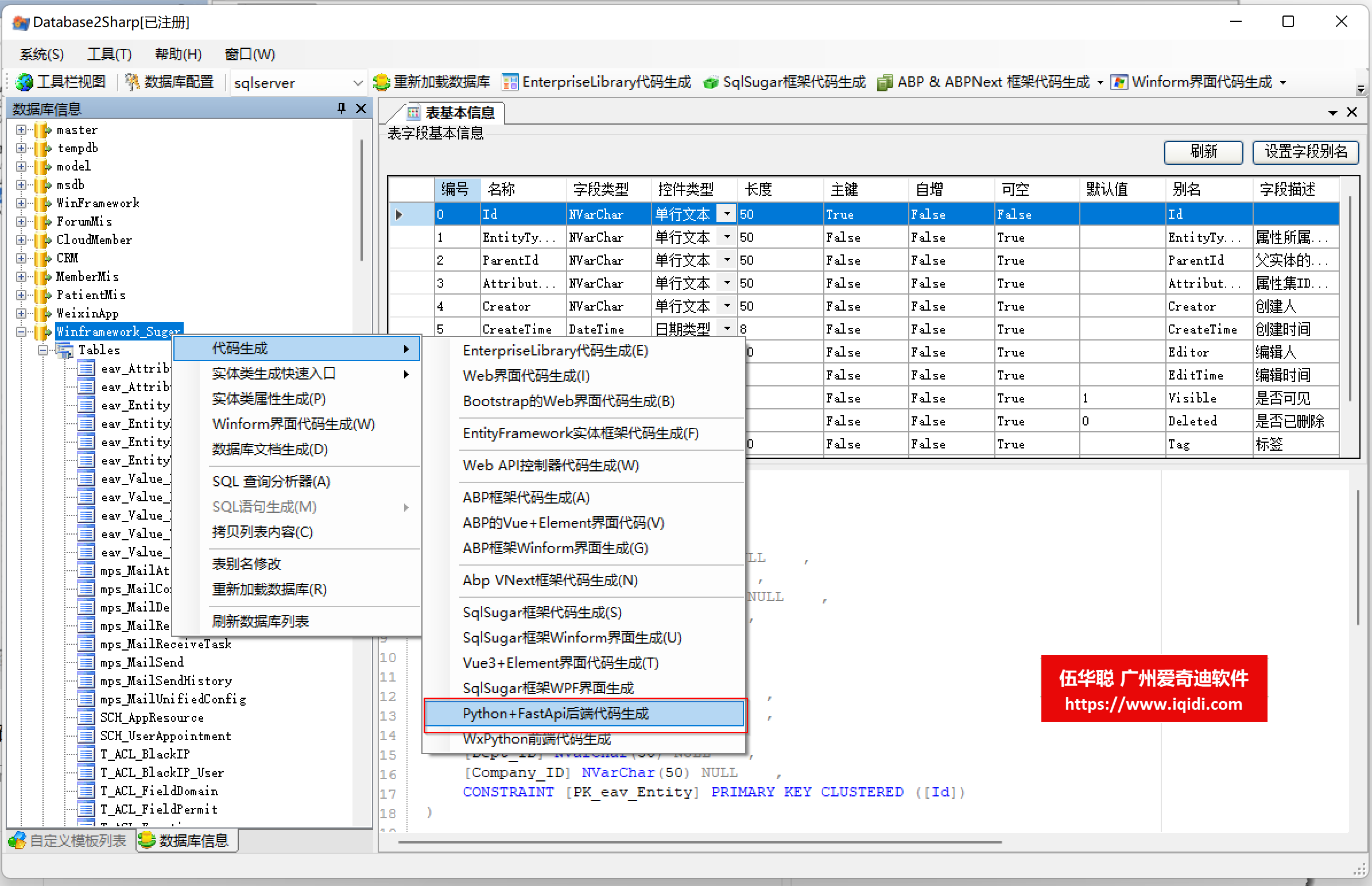
选中相关的表后,一键可以生成各层的类文件,其中包括最为繁琐的Model映射类信息。如下是生成的相关类的界面效果。

2) WxPython前端项目代码生成
在经过对WxPython的深入研究后,并依据改造过的项目结构,整合在代码生成工具中,对项目的代码,包括列表界面,编辑界面、API调用类、DTO实体信息等进行统一的生成。
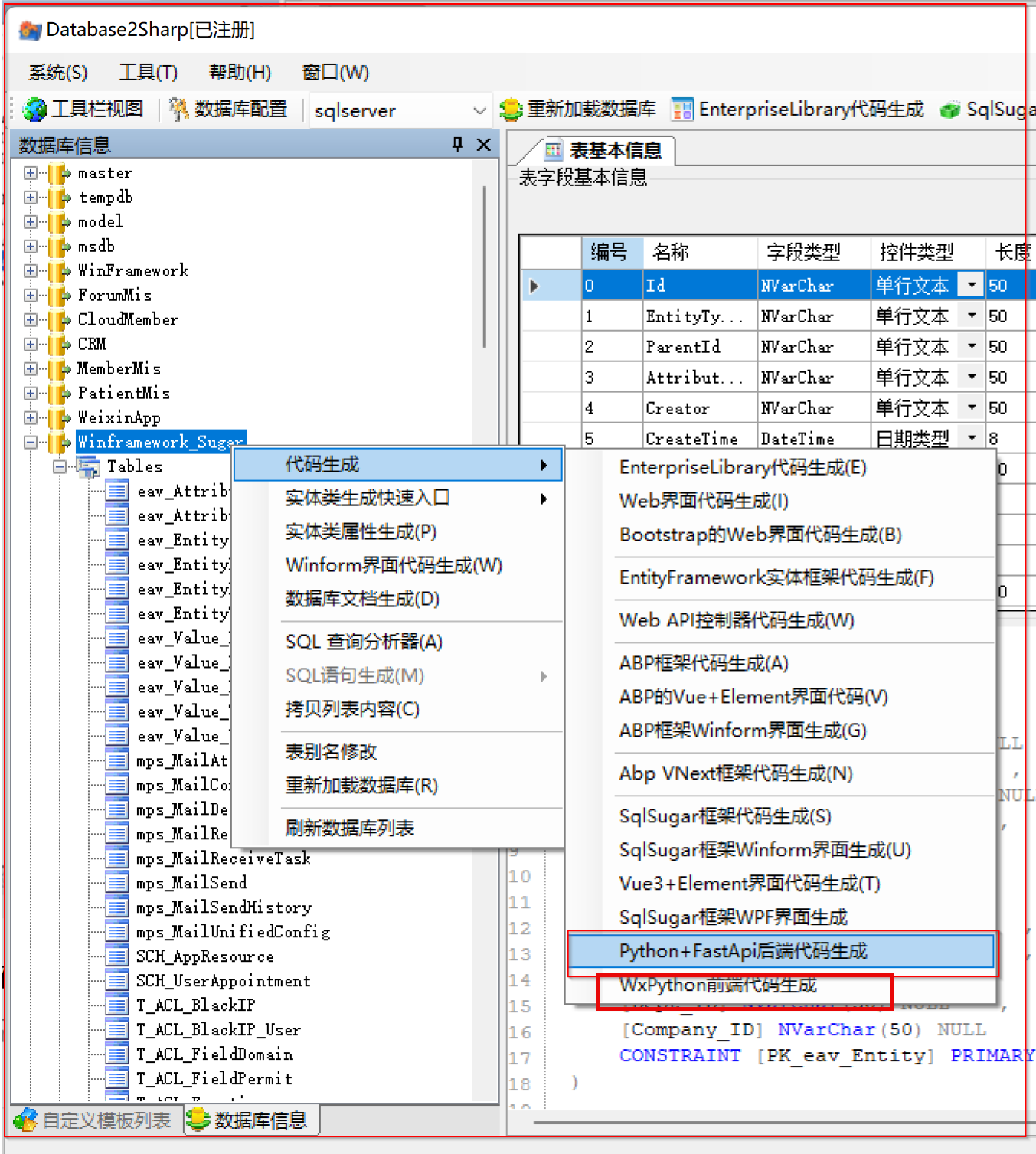
选择相关的数据表后,一键生成相关的代码,如下所示。
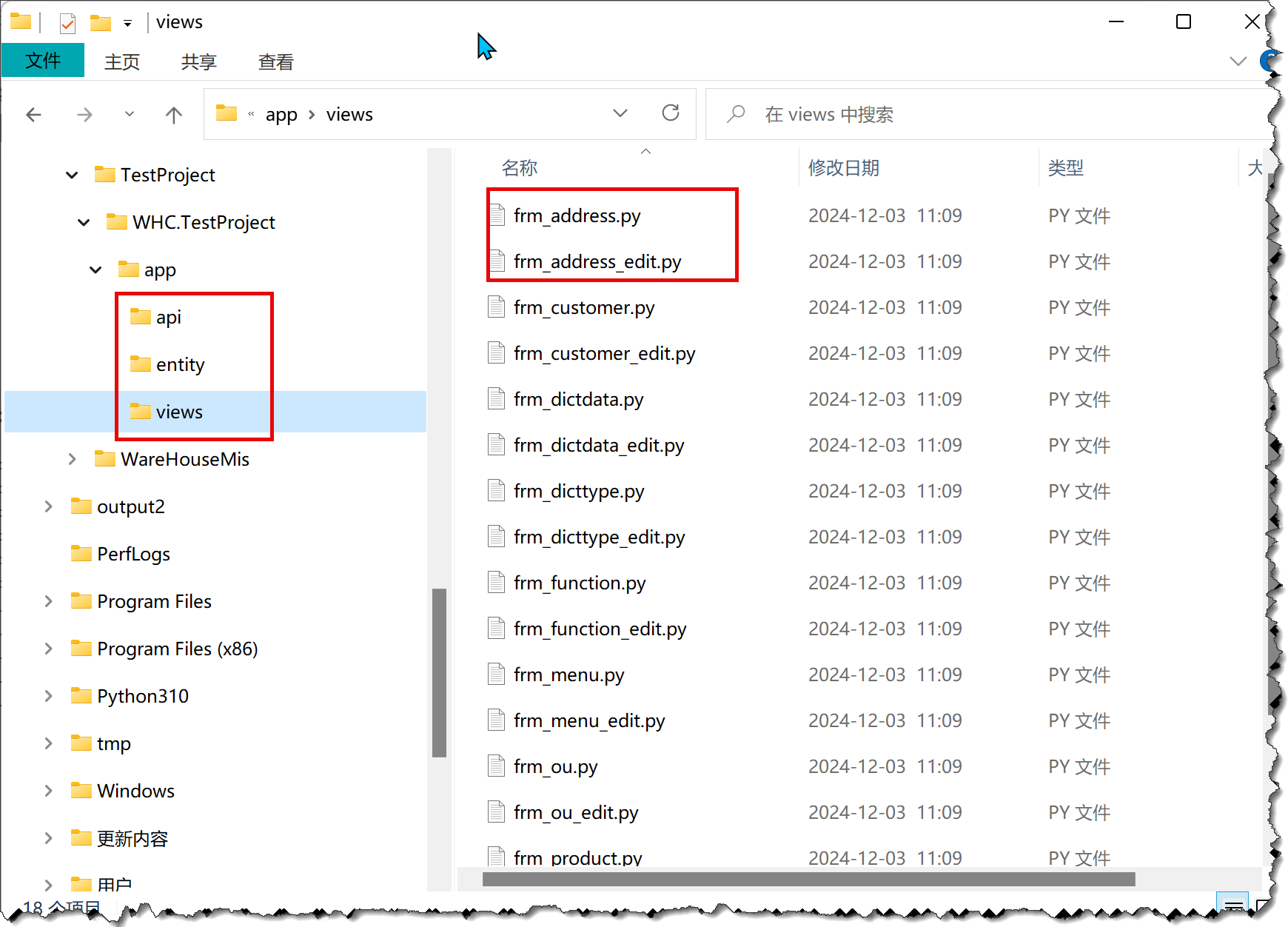
1)列表界面和继承关系
列表界面继承基类,从而可以大幅度的利用相应的规则和实现。

如对于两个例子窗体:系统类型定义,客户信息,其中传如对应的DTO信息和参数即可。

因为常规的列表界面一般分为查询区、列表界面展示区和分页信息区,我们把它分为两个主要的部分,如下界面所示。

当然如果有树形列表的,也整合在基类窗体中实现控制逻辑,具体实现放在子类处理即可。
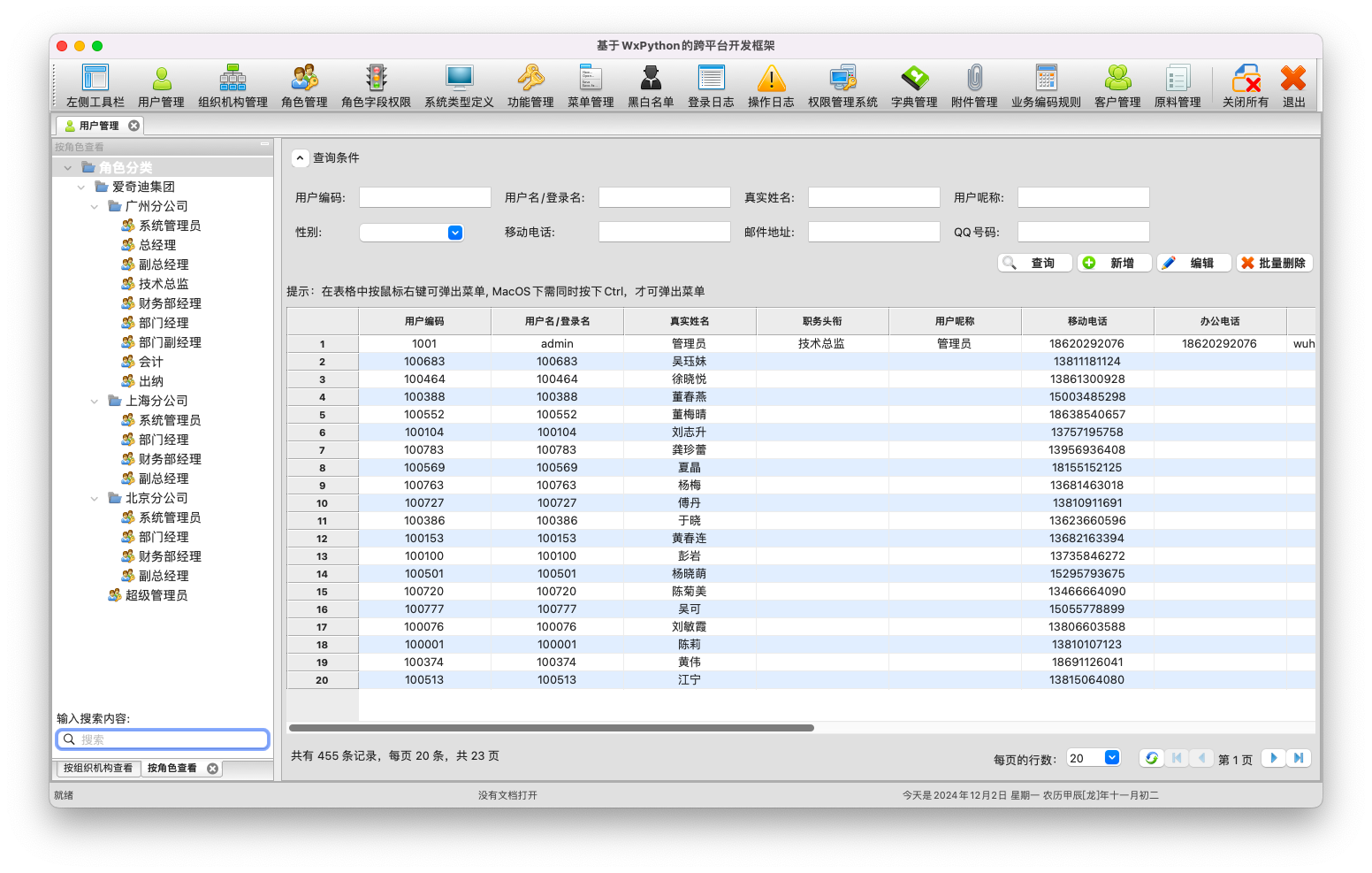
同时,在树列表或者表格数据控件支持右键弹出菜单处理,包括常规的新增、编辑、删除、复制、刷新等常规功能,如果需要更多业务模块的功能,整合在右键菜单中,在窗体子类中重写某些只定义函数即可实现。
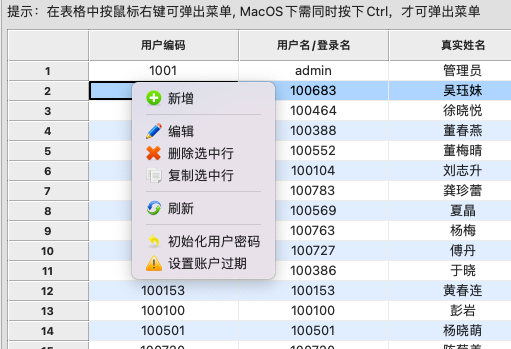
对于列表界面,生成的代码如下所示(以客户信息表为例):
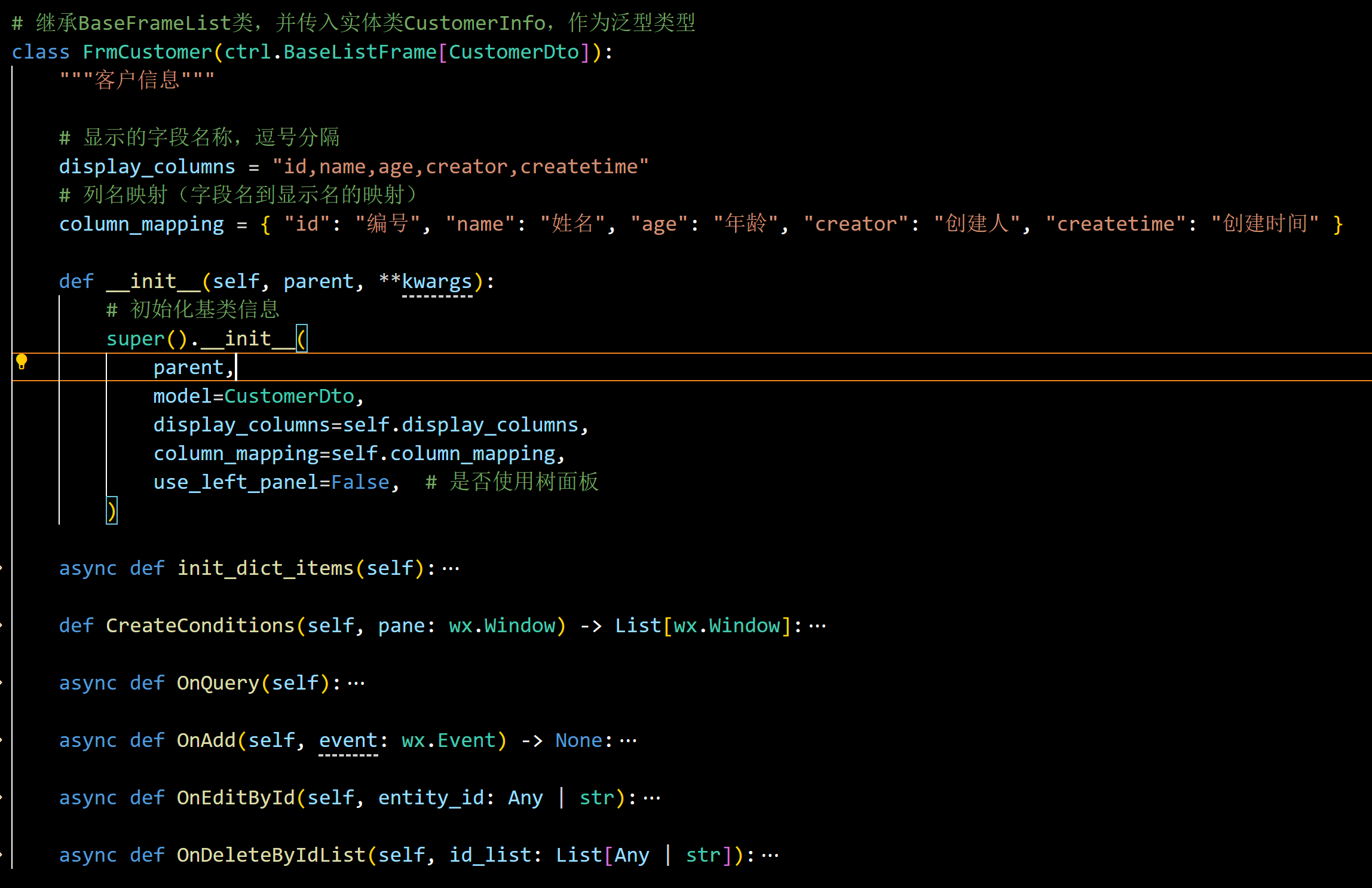
代码工具最大程度的提供常规方法的处理,如果需要特殊的操作,如在查询框中的条件,那么需要根据需要修改一下即可。
def CreateConditions(self, pane: wx.Window) ->List[wx.Window]:"""创建折叠面板中的查询条件输入框控件"""
#创建控件,不用管布局,交给CreateConditionsWithSizer控制逻辑
#默认的FlexGridSizer为4*2=8列,每列间隔5pxself.txtName=ctrl.MyTextCtrl(pane)
self.txtAge=ctrl.MyNumericRange(pane)
self.txtCustomerType= ctrl.MyComboBox(pane, style=wx.CB_READONLY)
util=ControlUtil(pane)
util.add_control("姓名:", self.txtName)
util.add_control("年龄:", self.txtAge)
util.add_control("客户类型:", self.txtCustomerType) #测试数据类型绑定
return util.get_controls()基本上就是不变的内容和规则,由基类处理,变化的内容,由子类来具体化即可。对于新增、编辑、删除的操作,我们根据表的不同,生成子类实现代码,一般不用修改。
async def OnAdd(self, event: wx.Event) ->None:"""子类重写-打开新增对话框"""dlg=FrmCustomerEdit(self)if await AsyncShowDialogModal(dlg) ==wx.ID_OK:#新增成功,刷新表格
await self.update_grid()
dlg.Destroy()
如果需要再查询框中初始化下拉列表的内容,我们重写初始化字典函数即可。
async definit_dict_items(self):"""初始化字典数据-子类重写"""await self.txtCustomerType.bind_dictType("客户类型")通过上面我们构建的基类处理,以及提供一个界面辅助类来处理,可简化很多不必要的代码,而且还很灵活的控制布局处理,非常方便。
2)编辑/新增界面继承关系
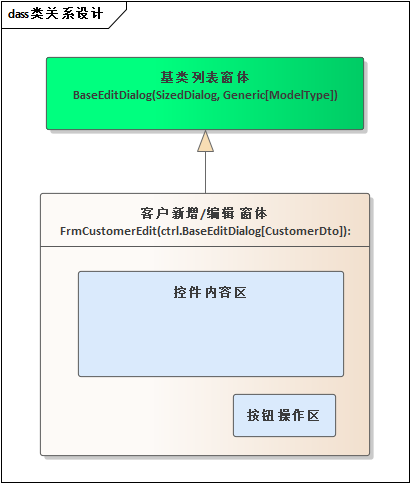
继承基类编辑对话框(通常用于创建模态对话框或自定义窗口的基类)有以下优点:
- 共享通用功能
:将所有对话框的共同行为(如按钮布局、事件处理、数据校验逻辑等)封装在基类中,子类可以直接继承使用,无需重复实现。
- 减少冗余代码
:对话框的通用结构只需在基类中实现一次,后续的功能扩展只需通过继承来实现,减少代码重复。
- 统一界面风格
:基类可以预定义窗口的样式和布局,确保项目中所有对话框的界面一致。
- 快速定制功能
:子类仅需实现或覆盖特定方法,即可快速实现自定义对话框的功能。
继承基类编辑对话框能够提高代码复用性、开发效率和维护性,特别适合在复杂系统中管理多个相似对话框。通过合理设计基类,开发者可以显著减少重复代码,实现更灵活的功能扩展。
常规的对话框中,业务表编码规则的新增、编辑界面如下所示。
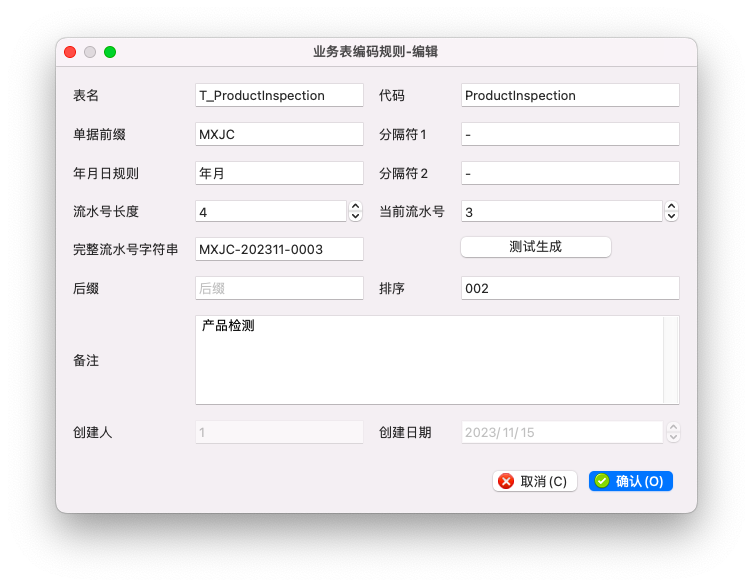
当然,我们也可以增加更多的定制功能,稍作调整可以增加多页的功能。
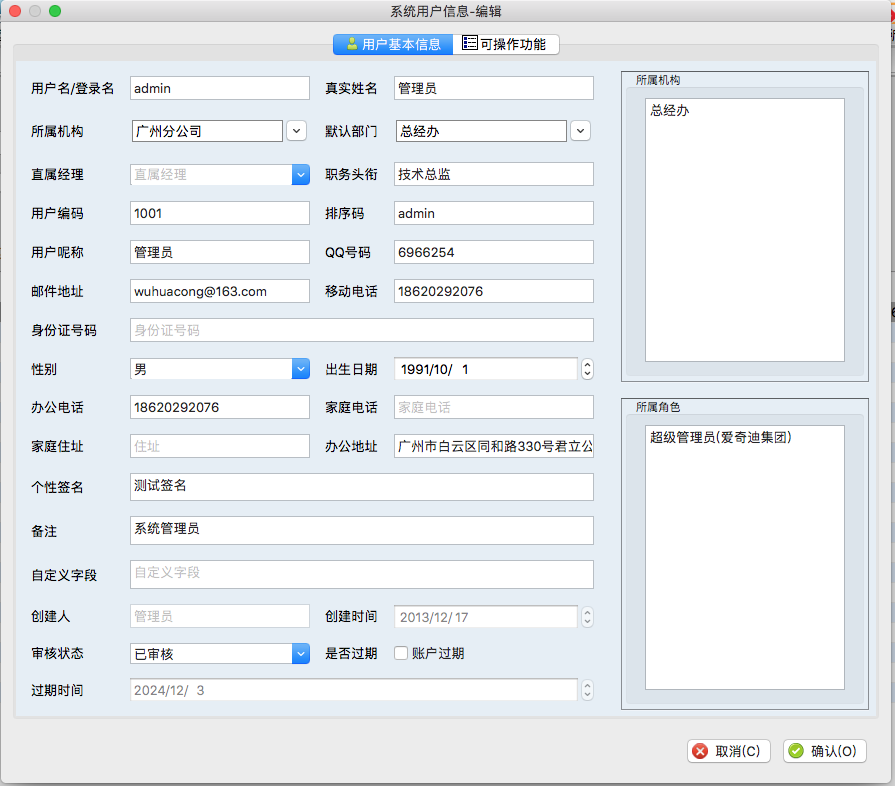
一般我们在编辑框中,或者列表窗体中,我们都可能有树形列表的情况,我们提供标准的处理方法,用于对这些内容进行修改。
对于编辑界面来说,我们继承父类后,子类重写一些实现函数即可实现弹性化的处理了。
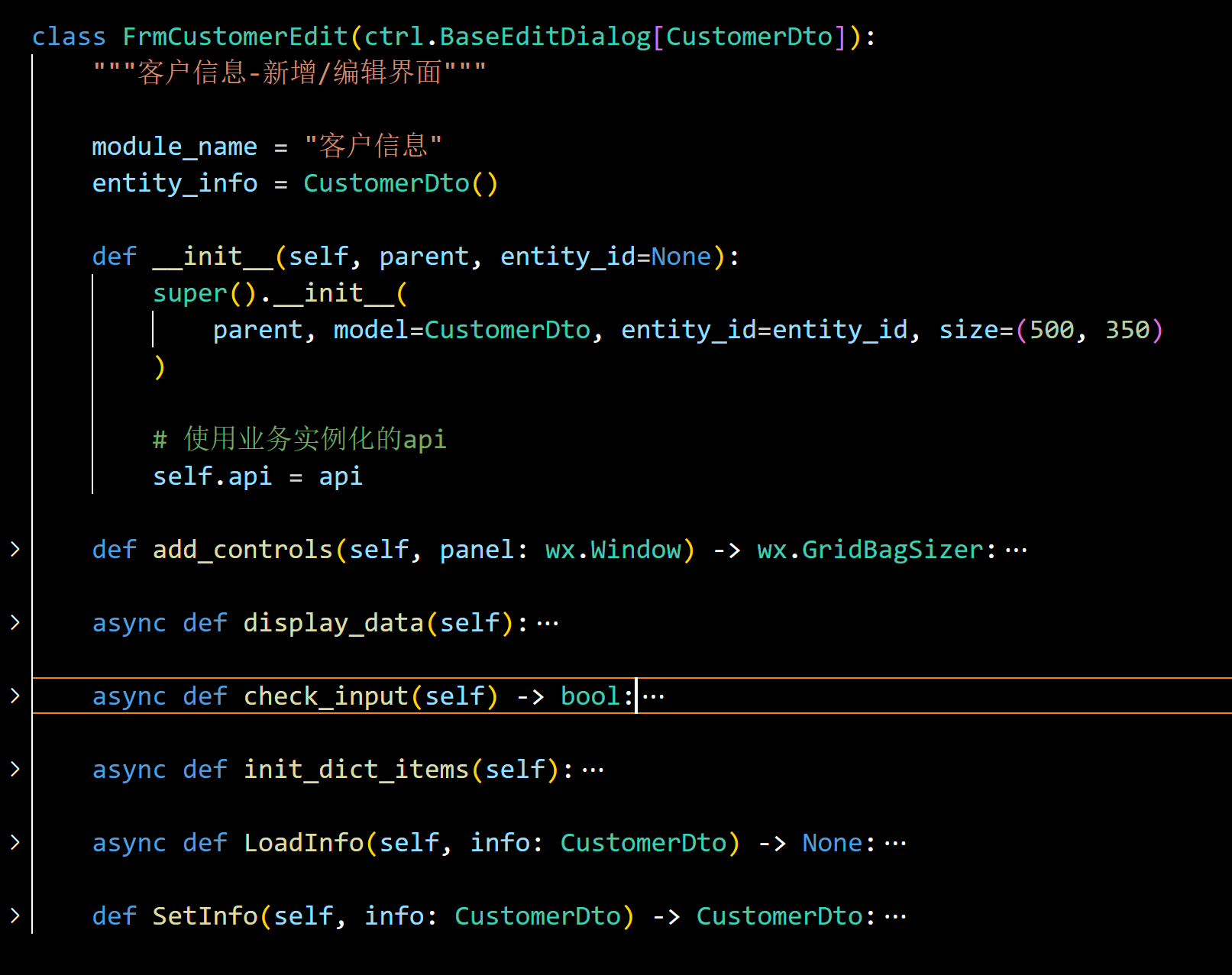
上面这些函数就是各司其职,对界面的内容处理,显示编辑数据,校验输入,初始化字典、加载信息,保存对象信息,都是我们在编辑框中需要处理到的内容,我们根据不同的需求进行修改即可。
生成的界面代码中,对于输入控件的显示放在add_controls函数里面,如下代码所示。
def add_controls(self, panel: wx.Window) ->wx.GridBagSizer:#创建一个 GridBagSizer
grid_sizer = wx.GridBagSizer(5, 5) #行间距和列间距为 5
util = GridBagUtil(panel, grid_sizer, 2) #构建工具类,布局为2列
self.txtName= ctrl.MyTextCtrl(panel, placeholder="客户姓名")
self.txtAge=wx.SpinCtrl(panel)
self.txtCreateTime=ctrl.MyDatePickerCtrl(panel)
self.txtCreateTime.Disable()
self.txtNote= ctrl.MyTextCtrl(panel, placeholder="备注", style=wx.TE_MULTILINE)
util.add_control("客户姓名", self.txtName, is_expand=True)
util.add_control("年龄", self.txtAge, is_expand=True)
util.add_control("创建日期", self.txtCreateTime, is_expand=True)
util.add_control("备注", self.txtNote, is_expand=True, is_span=True)#让控件跟随窗口拉伸
grid_sizer.AddGrowableCol(1) #允许第n列拉伸
return grid_sizer我们通过代码
util = GridBagUtil(panel, grid_sizer, 2) # 构建工具类,布局为2列
构建了一个辅助类来处理布局的,添加的时候不用管布局,大概知道是几列的即可。
在Windows下,客户信息的编辑界面如下所示。
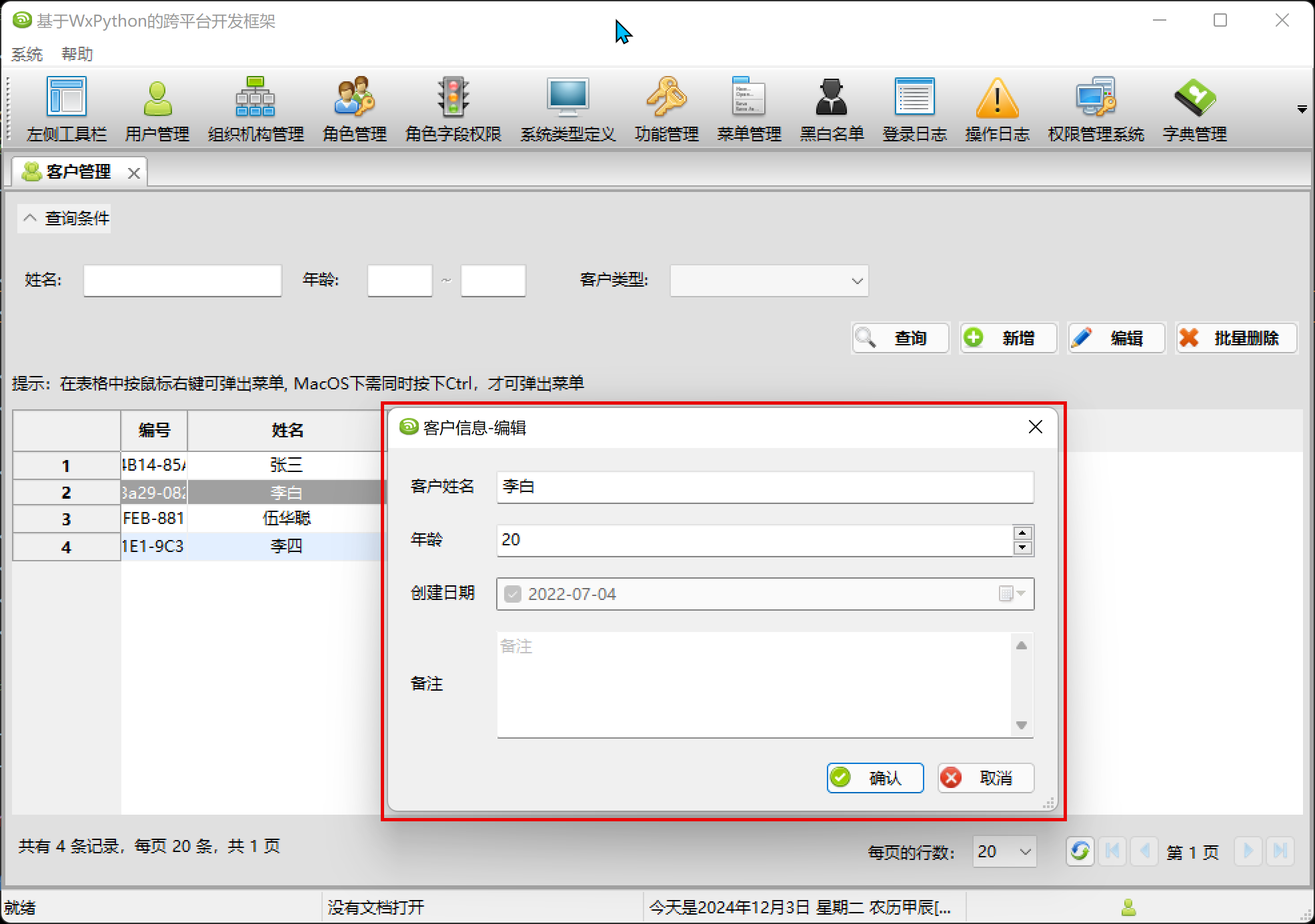
如果我们需要修改为双排的,那么修改下:
def add_controls(self, panel: wx.Window) ->wx.GridBagSizer:#创建一个 GridBagSizer
grid_sizer = wx.GridBagSizer(5, 5) #行间距和列间距为 5
util = GridBagUtil(panel, grid_sizer, 4) #构建工具类,布局为4列
self.txtName= ctrl.MyTextCtrl(panel, placeholder="客户姓名")
self.txtAge=wx.SpinCtrl(panel)
self.txtCreateTime=ctrl.MyDatePickerCtrl(panel)
self.txtCreateTime.Disable()
self.txtNote= ctrl.MyTextCtrl(panel, placeholder="备注", style=wx.TE_MULTILINE)
util.add_control("客户姓名", self.txtName, is_expand=True)
util.add_control("年龄", self.txtAge, is_expand=True)
util.add_control("创建日期", self.txtCreateTime, is_span=True)
util.add_control("备注", self.txtNote, is_expand=True, is_span=True, is_stretch=True)#让控件跟随窗口拉伸
grid_sizer.AddGrowableCol(1) #允许第n列拉伸
grid_sizer.AddGrowableCol(3) #允许第n列拉伸
return grid_sizer界面效果如下所示。
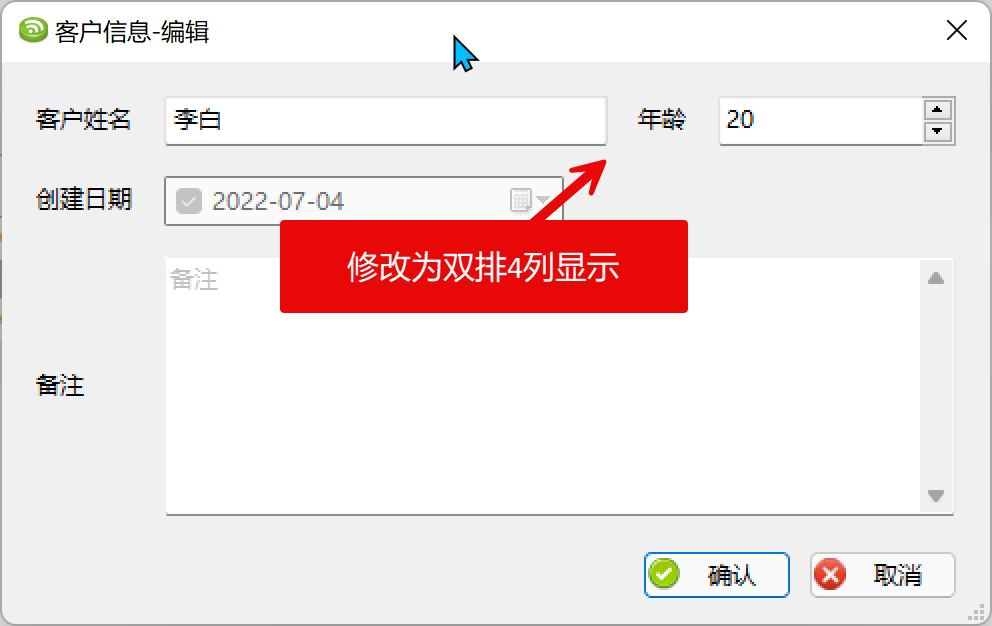
稍作修改即可重新布局,非常方便。
利用代码生成工具,可以很好的利用现有基类的关系生成相关的代码,包括界面代码,对Web API的调用代码也是一样,我们只需要做好继承关系,就具有基类一些的CRUD接口了。
例如对于客户信息的API接口封装类,我们只需要增加一些个性化的自定义函数即可,默认对应基类有相关的CRUD接口。
classCustomer(BaseApi[CustomerDto]):"""客户信息--API接口类"""api_name= "customer"
def __init__(self):
super().__init__(self.api_name, CustomerDto)
asyncdef exist(self, name: str = None, id: str = None) ->bool:"""判断记录是否存在,如果指定ID,则判断ID不等于当前ID的记录是否存在"""url= f"{self.base_url}/exist"params= {"name": name, "id": id}
data= await self.client.get(url, params=params)
res=AjaxResponse[bool].model_validate(data)return res.result if res.success elseFalse
asyncdef get_by_name(self, name: str) ->CustomerDto:"""根据名称获取客户信息"""url= f"{self.base_url}/by-name"params= {"name": name}
data= await self.client.get(url, params=params)
res=AjaxResponse[CustomerDto].model_validate(data)return res.result if res.success elseNone#构建一个业务逻辑实例,方便调用
api_customer = Customer()
这个基类的函数,和后端的控制器接口一一对应。
利用代码生成工具,开发项目事半功倍,这就是工具的力量和魅力。