循环神经网络设计同样可以使用预训练词“嵌入”

序言:重新训练人工智能大型模型是一项复杂且高成本的任务,尤其对于当前的LLM(大型语言模型)来说,全球99.99%的企业难以承担。这是因为模型训练需要巨大的资源投入、复杂的技术流程以及大量的人力支持。因此,无论在科学研究还是实际应用中,人们通常依赖开源的预训练模型及其已经学习到的各种特征信息,就像使用开源的Linux一样。本节将讲解如何利用这些预训练模型中的“嵌入”信息来解决实际问题。
使用预训练嵌入与RNN
在之前的所有示例中,我们收集了训练集中要使用的完整单词集,然后用它们训练了嵌入。这些嵌入最初是聚合在一起的,然后输入到密集网络中,而在最近的章节中,我们探讨了如何使用RNN来改进结果。在此过程中,我们被限制在数据集中已经存在的单词,以及如何使用该数据集中的标签来学习它们的嵌入。回想一下在前面有一章,我们讨论了迁移学习。如果,您可以不自己学习嵌入,而是使用已经预先学习的嵌入,研究人员已经完成了将单词转化为向量的艰苦工作,并且这些向量是经过验证的呢?其中一个例子是Stanford大学的Jeffrey Pennington、Richard Socher和Christopher Manning开发的GloVe(Global Vectors for Word Representation)模型。
在这种情况下,研究人员分享了他们为各种数据集预训练的单词向量:
• 一个包含60亿个标记、40万个单词的词汇集,维度有50、100、200和300,单词来自维基百科和Gigaword
• 一个包含420亿个标记、190万个单词的词汇集,维度为300,来自通用爬虫
• 一个包含8400亿个标记、220万个单词的词汇集,维度为300,来自通用爬虫
• 一个包含270亿个标记、120万个单词的词汇集,维度为25、50、100和200,来自对20亿条推文的Twitter爬虫
考虑到这些向量已经预训练,我们可以轻松地在TensorFlow代码中重复使用它们,而不必从头开始学习。首先,我们需要下载GloVe数据。这里选择使用Twitter数据集,包含270亿个标记和120万个单词的词汇集。下载的是一个包含25、50、100和200维度的归档文件。
为了让整个过程稍微方便一些,我已经托管了25维版本,您可以像这样将其下载到Colab笔记本中:
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/glove.twitter.27B.25d.zip
\
-O /tmp/glove.zip
这是一个ZIP文件,您可以像这样解压缩,得到一个名为glove.twitter.27B.25d.txt的文件:
解压GloVe嵌入
import os
import zipfile
local_zip = '/tmp/glove.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/glove')
zip_ref.close()
文件中的每一行都是一个单词,后面跟着为其学习到的维度系数。最简单的使用方式是创建一个字典,其中键是单词,值是嵌入。您可以这样设置这个字典:
glove_embeddings = dict()
f = open('/tmp/glove/glove.twitter.27B.25d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
glove_embeddings[word] = coefs
f.close()
此时,您可以简单地通过使用单词作为键来查找任何单词的系数集。例如,要查看“frog”的嵌入,您可以使用:
glove_embeddings['frog']
有了这个资源,您可以像以前一样使用分词器获取语料库的单词索引——但现在,您可以创建一个新的矩阵,我称之为嵌入矩阵。这个矩阵将使用GloVe集中的嵌入(从glove_embeddings获取)作为其值。因此,如果您检查数据集中单词索引中的单词,如下所示:
{'
那么嵌入矩阵的第一行应该是GloVe中“
您可以使用以下代码创建该矩阵:
embedding_matrix = np.zeros((vocab_size, embedding_dim))
for word, index in tokenizer.word_index.items():
if index > vocab_size - 1:
break
else:
embedding_vector = glove_embeddings.get(word)
if embedding_vector is not None:
embedding_matrix[index] = embedding_vector
这只是创建了一个矩阵,矩阵的维度是您所需的词汇大小和嵌入维度。然后,对于分词器的每个词汇索引项,您会查找GloVe中的系数(从glove_embeddings中获取),并将这些值添加到矩阵中。
接着,您需要修改嵌入层,使用预训练的嵌入,通过设置weights参数,并指定不希望该层被训练,通过设置trainable=False:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix], trainable=False),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
现在,您可以像之前一样进行训练。然而,您需要考虑您的词汇大小。在上一章中,您为了避免过拟合,做了一些优化,目的是防止嵌入过多地学习低频单词;您通过使用更小的词汇表、仅包含常用单词来避免过拟合。在这种情况下,由于单词嵌入已经通过GloVe为您学习过,您可以扩展词汇表——但扩展多少呢?
首先要探索的是,您的语料库中有多少单词实际上在GloVe集中。GloVe有120万个单词,但不能保证它包含您的所有单词。所以,这里有一些代码,可以快速对比,让您探索您的词汇表应该多大。
首先,整理数据。创建一个包含Xs和Ys的列表,其中X是词汇索引,Y=1表示该单词在嵌入中,0则表示不在。此外,您可以创建一个累计集,在每个时间步计算单词的比例。例如,索引为0的单词“OOV”不在GloVe中,所以它的累计Y值为0。下一个索引的单词“new”在GloVe中,所以它的累计Y值为0.5(即,到目前为止看到的单词中有一半在GloVe中),然后您会继续这样计算整个数据集:
xs = []
ys = []
cumulative_x = []
cumulative_y = []
total_y = 0
for word, index in tokenizer.word_index.items():
xs.append(index)
cumulative_x.append(index)
if glove_embeddings.get(word) is not None:
total_y = total_y + 1
ys.append(1)
else:
ys.append(0)
cumulative_y.append(total_y / index)
然后,您可以使用以下代码绘制Xs与Ys的关系图:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12, 2))
ax.spines['top'].set_visible(False)
plt.margins(x=0, y=None, tight=True)
plt.axis([13000, 14000, 0, 1])
plt.fill(ys)
这将给您一个单词频率图,看起来像图7-17。
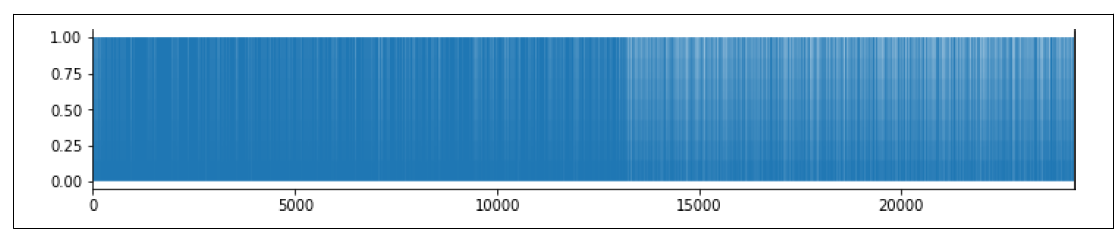
图7-17. 单词频率图
如图表所示,密度在10,000到15,000之间发生变化。这让您直观地看到,大约在13,000标记的位置,未在GloVe嵌入中的单词的频率开始超过那些已经在GloVe嵌入中的单词。
如果您再绘制累计的cumulative_x与cumulative_y的关系,您将能更好地理解这个变化。以下是代码:
import matplotlib.pyplot as plt
plt.plot(cumulative_x, cumulative_y)
plt.axis([0, 25000, .915, .985])
您可以看到图7-18中的结果。
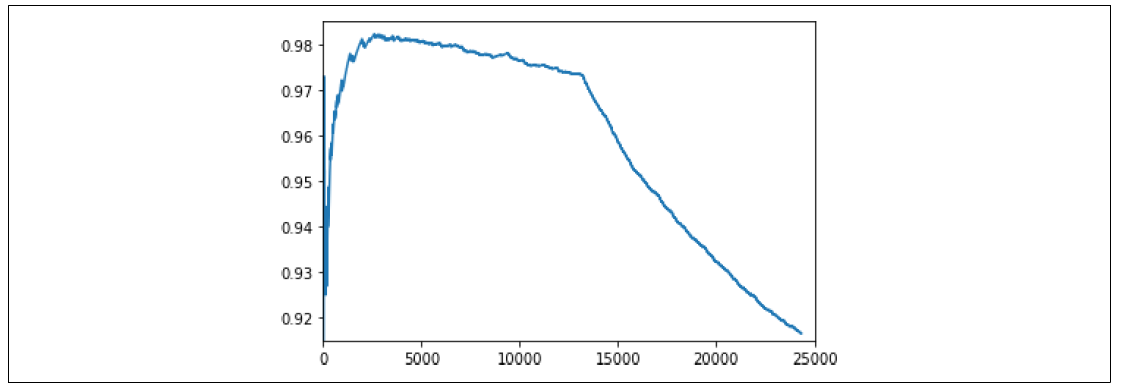
图7-18. 绘制单词索引频率与GloVe的关系
现在,您可以调整plt.axis中的参数,放大查看拐点,看看未出现在GloVe中的单词是如何开始超过那些在GloVe中的单词的。这是设置词汇大小的一个不错起点。
使用这种方法,我选择了一个词汇大小为13,200(而不是之前为了避免过拟合而使用的2,000),并使用了以下模型架构,其中embedding_dim是25,因为我使用的是GloVe集:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix], trainable=False),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
然后,使用Adam优化器:
adam = tf.keras.optimizers.Adam(learning_rate=0.00001, beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
训练30个epoch后,得到了很好的结果。准确率如图7-19所示。验证准确率与训练准确率非常接近,表明我们不再过拟合。
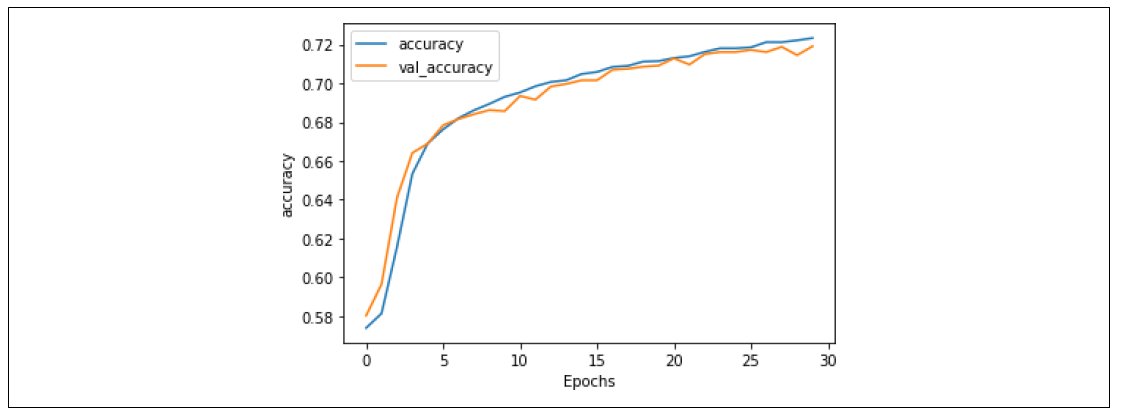
图7-19. 使用GloVe嵌入的堆叠LSTM准确率
这一点通过损失曲线得到进一步验证,如图7-20所示。验证损失不再发散,这表明尽管我们的准确率只有大约73%,我们可以有信心认为模型的准确性达到了这个程度。
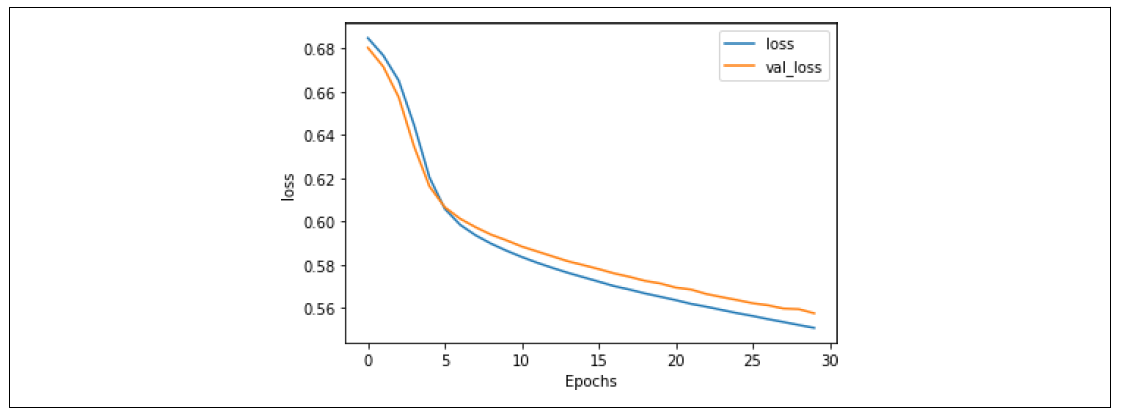
图7-20. 使用GloVe嵌入的堆叠LSTM损失
训练模型更长时间会得到非常相似的结果,并且表明,尽管大约在第80个epoch左右开始出现过拟合,模型仍然非常稳定。
准确率指标(图7-21)显示模型训练得很好。
损失指标(图7-22)显示大约在第80个epoch左右开始出现发散,但模型仍然拟合得很好。

图7-21. 使用GloVe的堆叠LSTM在150个epoch上的准确率
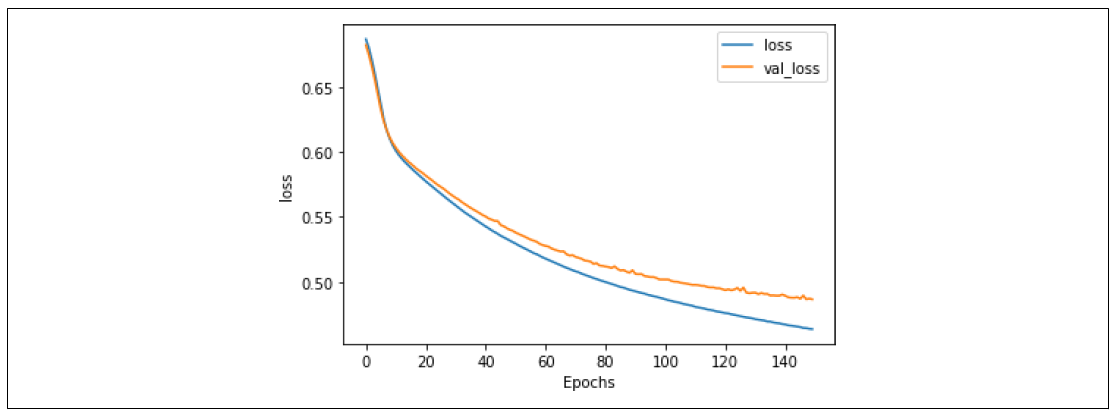
图7-22. 使用GloVe的堆叠LSTM在150个epoch上的损失
这告诉我们,这个模型是早停的好候选者,您只需要训练它75到80个epoch,就能得到最佳结果。
我用来自《洋葱报》的标题(《洋葱报》是讽刺性标题的来源,也是讽刺数据集的来源),与其他句子进行了测试,测试代码如下:
test_sentences = [
"It Was, For, Uh, Medical Reasons, Says Doctor To Boris Johnson, Explaining Why They Had To Give Him Haircut",
"It's a beautiful sunny day",
"I lived in Ireland, so in high school they made me learn to speak and write in Gaelic",
"Census Foot Soldiers Swarm Neighborhoods, Kick Down Doors To Tally Household Sizes"
]
这些标题的结果如下——记住,接近50%(0.5)的值被认为是中立的,接近0的是非讽刺的,接近1的是讽刺的:
[[0.8170955 ]
[0.08711044]
[0.61809343]
[0.8015281 ]]
来自《洋葱报》的第一句和第四句显示了80%以上的讽刺概率。关于天气的陈述则显得非常非讽刺(9%),而关于在爱尔兰上高中这句话被认为可能是讽刺的,但信心不高(62%)。
总结
本节中我们介绍了循环(递归)神经网络(RNN),它们在设计中使用面向序列的逻辑,可以帮助您理解句子的情感,不仅基于其中的单词,还基于它们出现的顺序。了解了基本的RNN如何工作,以及LSTM如何在此基础上改进,保留长期上下文。您使用这些技术改进了您一直在做的情感分析模型。接着,您研究了RNN的过拟合问题以及改善它们的技术,包括使用从预训练嵌入中进行迁移学习。在接下来的章节中,我们将使用前面全部所学内容探索如何预测单词,进而创建一个能够生成文本的模型,甚至为您写诗!



