利用异常实现反调试
0×01 介绍
一些文章已经介绍过通过检测异常来对抗调试器的技术。这个思想很简单:根据设计本意,调试器会处理特定的异常。如果一个异常包裹在try块中,只有当没有附加调试器的时候,异常处理程序才会执行。因此,可以得出结论,只要异常块没有执行,那么程序就正在被一个调试器调试。
0×02 一个字节的Interrupt 3中断(0xCC)
在所有会被调试器处理的异常中,interrupt 3中断算是一个,它会生成一个单字节的断点。
BOOL IsDebuggerPresent_Int3()
{
__try
{
__asm int 3
}
__except(1)
{
return FALSE;
}
return TRUE;
}
0×03 两个字节的Interrupt 3中断(0xCD 0×03)
使用Visual C++内联汇编器的_emit伪指令可以生成一个两字节的interrupt 3指令。在测试的所有调试器中,只有OnllyDbg调试器识别这个异常。
BOOL IsDebuggerPresent_Int3_2Byte()
{
__try
{
__asm
{
__emit 0xCD
__emit 0x03
}
}
__except(1)
{
return FALSE;
}
return TRUE;
}
0×04 Interrupt 0x2C中断
Interrupt 0x2C引起一个调试断言异常。WinDbg会响应这个异常,但是其它的调试器都不会处理它。这个指令可以使用_int 2c来生成。这个中断只在Vista以及之后的系统上有效。因为这一点,需要动态检查windows的版本,如果版本号小于6就返回false。
BOOL IsDebuggerPresent_Int2c()
{
OSVERSIONINFO osvi;
ZeroMemory(&osvi, sizeof(OSVERSIONINFO));
osvi.dwOSVersionInfoSize = sizeof(OSVERSIONINFO);
GetVersionEx(&osvi);
if (osvi.dwMajorVersion < 6)
return FALSE;
__try
{
__int2c();
}
__except(1)
{
return FALSE;
}
return TRUE;
}
0×05 Interrupt 0x2D
如果执行了interrupt 0x2D,Windows将抛出一个断点异常
BOOL IsDebuggerPresent_Int2d()
{
__try
{
__asm int 0x2d
}
__except(1)
{
return FALSE;
}
return TRUE;
}
0×06 ICEBP(0xF1)
ICEBP是一个没有文档化的指令,可以作为一个单字节的interrupt 1中断,产生一个单步异常。
BOOL IsDebuggerPresent_IceBp()
{
__try
{
__asm __emit 0xF1
}
__except(1)
{
return FALSE;
}
return TRUE;
}
0×07 陷阱标志位
EFLAGS寄存器的第八个比特位是陷阱标志位。如果设置了,就会产生一个单步异常。
BOOL IsDebuggerPresent_TrapFlag()
{
__try
{
__asm
{
pushfd
or word ptr[esp], 0x100
popfd
nop
}
}
__except(1)
{
return FALSE;
}
return TRUE;
}
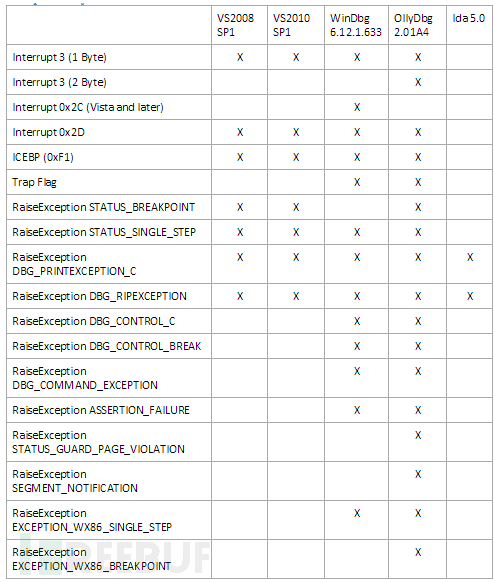
0×08 抛出异常
RaiseException函数产生的若干不同类型的异常可以被调试器捕获。在RaiseException的基础上,OutputDebugString,该函数常被用来检测附加的调试器。有效的异常码如下所示:
STATUS_BREAKPOINT (0x80000003)
STATUS_SINGLE_STEP (0x80000004)
DBG_PRINTEXCEPTION_C (0x40010006)
DBG_RIPEXCEPTION (0x40010007)
DBG_CONTROL_C (0x40010005)
DBG_CONTROL_BREAK (0x40010008)
DBG_COMMAND_EXCEPTION (0x40010009)
ASSERTION_FAILURE (0xC0000420)
STATUS_GUARD_PAGE_VIOLATION (0x80000001)
SEGMENT_NOTIFICATION (0x40000005)
EXCEPTION_WX86_SINGLE_STEP (0x4000001E)
EXCEPTION_WX86_BREAKPOINT (0x4000001F)BOOL TestExceptionCode(DWORD dwCode)
{
__try
{
RaiseException(dwCode, 0, 0, 0);
}
__except(1)
{
return FALSE;
}
return TRUE;
}
BOOL IsDebuggerPresent_RipException()
{
return TestExceptionCode(DBG_RIPEXCEPTION);
}
0×09 兼容性表