1
1 引 言软件规模 日趋庞大 , 软件调试 中 , 发现 、 定位、分析错误的工作量也相应增长 。 因此 , 人们 开发 了 C o d e iV e w 等调试工具以 深 入错 误发 生时的程序执行环 境 , 使效率大增 。 不过对于 下 面的循环结构 ( 以 C 语言为例 )仍有为难之处 :
 假定该循环共执行 1 0 0 0 0 遍 , 第 3 0 0 0 次执行死 机了 , 那么用调试工具判定死机发生在该循环 中很 容易 , 但再进一步分析则不可能 。 因为 , 若 设 断点 于 循 环 内 , 则 每 次循 环 皆被 中断 , 至 3 0 0 0 次运行才能发现错误所在 , 以 后欲 分析错 误也是每 3 0 0 0 次运行方可进入 出错环境一次 , 这绝对无法 容忍。 2 调试方法在这里笔者介绍一种在调试软件过程中改 进了的方法 , 可解决这个问题 。 对于上面的实例 只需增加几条语句即可 , 如下所示 。 其 中 fp 为 文件 指针 , n u m b e r 是 初 值 为零 的整 型 变 量 ,
d o o n h t in g 为一空 函数 , 它 们都为调试而 设立 。 具体的调试方法是将不设断点的程序先执行一 次 , 然后 阅读 r e c o r d . da t 找 出错 误发 生 时的n u m be r 值 , 再设 br e a k p o in t 为该 n u m be r 值 , 置断点于 d o n o t h i n g o 这 一行上 , 即可使 程序 非常方便地运行到 出错处停住 。
 这里文件先 用 “ w ” 方 式打开 , 就 自然清 除 了上次执行形成的 r e c o r d . da t 。 在循环中用“ a " 方式将每次循 环 中的 n u m h a r 值等关键参数逐 次记入文件尾 部 。 切记一定要在循环内打开文 件 , 写 入信息 , 再关 闭文件 , 这可保证切实形 成 文件 ; 否则 (在进入循环 前打开 , 结束循环后关 闭) , 一旦循环 内出现死机等严重间题 , 文件就 不能形成 。 对于复杂的循环 , 记录于文件 中的信 息应包含一些除 n u m b e r 外 的其 他重 要参 数 , 既 利于发现错误 ( 参数异常就是出错 , 不必非死 机等重大问题才知出错了 ) , 又有利于了解循环 执行过程 而分析错误 , 因此 , 这些参数选择的好 坏 直接 影响调试效率。 在这个例子 中设 do_mai n _ w o r k 为循环 中的实质所在 , 又 很复 杂 , 其余仅是简 . 单工作 , 则应记录它的参数 ( 假设参 数 1 为整型 , 参数 2 为双精度型 ) 。 n u m b e r 系一附加 变量 , 如循环 中有一 不 断 增大或不断减小的变量可用 , 则也可用该变 量代替 n u m b e r 的作用 。 不过本例适用于 任何 循环 , 则是标准的方法 。 另外 i f 语句中的相等 关系也可用适当的不等关 系取代 , 如本例中用 不小于关 系 , 则 n u m b e r 不小于 b r e a k p o i n t 后 的每一 次循环 中断点有效 。 b r e a k p i o n t 最好不 要用一常量 ( 以免常常修改 ) , 而采用一变量 , 它 可在进入循环 前读入或 由命令行参数传入 , 如 此则程序无须改 动而 可停在循环的任意次数 上 。 b r e a kp o in t 类型 自然与 n u m b e r 或其他替 代者相同 。 3 结 语这种方法有利于 发现错误 , 以 后 利用调试 工具又极易进入 出错时的环境 , 而且为调试而增加的程 序是固定不 变的 , 故大大提高了效率 。 不过除了死机 、 除零等中断程序运行的错 误一 定发生在 r e c o r d . d a t 的最后 一行记录写入 后外 , 其余错误往往 比较含蓄而要查找一番 , 如 关 键参 数出错 , 则可能需要认真 阅读 r e c o r .d
da t , 对于一些不影响关键参数的小错则可能需 要另 想办法 。 另外发现的可能是表面错误 , 如果 死机 由前面 某次循 环中的错误 埋下祸 根 , 则需 先 由 死 机 处 仔 细 分 析 , 发 现 疑 点 , 再 重 设
b r e a k p o f n t 去分析疑点 , 深挖根源 . 所 以使用该 法虽减小了工作量 , 但软件调试仍是一项艰 巨 的任务 .
软件 的调试 也称纠错或排错 , 它是孤立并纠正错误的一种技巧性过程 。 软件错误的外部表现形式与内部 原 因之间往往没有 明显 的联系 , 所 出现的差错并非直接就能找 出原 因 。 因此 , 调试 既要对 错误 的性 质及 程序 本身进 行系统的研 究 , 在某种程 度上也要靠直觉与经验 。 到 目前为止 , 调试还 没有 一套经 得起检验 的完 整而 系统 的理论方法 , 排错时所采用的方法和时 间都不能事先确定 . 这样 , 通常认为调试是 困难的 , 是软件开发过 程 中最为艰 巨 的一种脑力劳动 。 本文拟就 调试的方法 、 技术与技 巧进行探讨 . 调试的步骤诊断错误或是 系统报 错 , 或是输 出结果与设 想的不 同 , 或是 陷入死循环等 , 都认为程序存在错误 . 确定错误的源发点发现错 误的地方不一定是错误的源发点 , 应寻找所有与错误有关 的地方 , 从而确定错误的源发点 。 例如程序 :
1 0 F O R I= 1 T O 1 0
20 R E A D A ( I )
30 N E X T I
4 0 D A T A 15 , 1 6 , 2 5 , 27 , 2 8
R U N
O U T O F D A T A 1 N 2 0
错误发生于 2 0 行 , 但与第 4 0 行有关。 改正错误确定错误及 位置后 , 针对错误 的具 体类 型进行改正 。 在纠错过程 的两方面即确定错误及位置和改 正错误 中 , 第一方面 的工作大 约相当于整个工作的 9 5 % , 为 排 错的关键 。 故本文重点探讨错误的诊断方法与技巧 。 诊断 错误的实验方法静态调试静态调试指对程序进行人工书面检查。 静态调试时要仔细阅读程序及其文档 , 经过结构分析 、 功能分析 、 逻辑 分析 、 接 口 分析 、 语 法分析以 及逐行检查 , 以 便找出并改正错误 。 通常 有下 面两种方法 。
- 检查语法错误
产生语 法错误 的原因 主要有两 个 , 一个是 键入错误 , 此错误如 同写文章 时的“ 笔误” ; 二是 由于对语法规则 不熟悉 , 如书后的错误 信息 、 各种限制 、 全局变量与局 部变量 、 先左后右 的原则等 , 这些 虽不是 系统的规定 , 但也是语法的一部分 , 应作为专项予 以检 查。
- 跟踪程序流程
此时的跟踪程序 流程 , 即将 自己 当做计算机 , 给 定一 组输 入数据后 , 顺序执行每 条语句 , 考察所得结果 . 寻 找错误 . 此方法需 花一定时间 , 但这是 最基本的方法 , 用 其它方法难 以查 出问题时 . 可以试 用此法 。 顺便说一句 , 学习编 程技术的主要途径是读 别人的 程序 , 对 较难懂的地方 , 也只 有跟踪程序才能读懂 , 也 就是常说的阅读能力提高 的途径 。 对程序 的流程图也可采取此方法检查 。 一般提倡应尽可能将 各种错误 消灭在静 态调试 阶段 。
动态调试动态调试 , 是指实际 上机运行程序进行调试 . 经过静态调试 后 , 仍 留在程序中的错误便都十分隐蔽。 为找 到这些错误 , 首先需捕 获一些与错误有关的线索 . 即进行错误侦察 , 此时需充分利 用计算机系统提供的调试手段。
- 试通
源程序上机 运行 , 语 言系统及操 作系统会在程序有故 障时给出信息 , 这些 信息反映 了如下几种故障情况 :
①没 有通过 编译 对解释型的高级语言来说 , 如 B A S I C 语言 , 程 序出现语法错误 , 系统便使程序在出错点 中断 , 并指 出错误 的类型 和 位置。 对 编译 型的高能 语言 , 如 P A S C A L 语言程序 , 编 译系统把程序检查一遍后 , 对语法错误会打 印 出一系列的出错 信息 , 根据这些语法出错信息号 , 可在“ 用 户手册 ” 中查 出原因 。
②没有通过连 接编辑 连接编 辑阶段的 错误有 : 公 共数据块长度不一致 , 系统 自动按最长 处理 , 但给 出警 告 ; 某个模块名找不到 所需要 的模块 , 如 数据说 明遗漏 , 连接数组元素引用 当函数引用 , 库函数引用 不符合规格说 明; 内存容量 不够 而需要分节等 。 这些 错误 可参照 “ 用 户手 册 ” 予以改正 。
③程序的运行过 程因故障而停止 程序因故障而 停止运 行 , 在多数情 况下会给出出错信 息 , 这类信息在“ 用户手册 ” 中都有解释 。
④程序只 输出部 分结果 对这 部分结果进行分析 , 可大致 了解程序被执行的逻辑 , 或程序在什么地方被中断 。
⑤程序执行 了很 长时间没有结果 这种情况可能 由三个原因造成 : 一是程序本来执行 时间就 很长 ; 二是程序 内有死循环 ; 三是程序运行时使 硬 件系统“ 死锁” 。
- 调试工具
错误的位置可以 通 过在程序 中插入调试 语句 , 也可 以使用机 器提供的调试工 具在程序 中的某一点将有 关数据单元的内容或程序 的执 行路径输 出。 不 同的操 作系统或编译程序提供 不同的调 试工 具 。 调试软件一般 有两 种 , 一种是 交互式调 试程序 , 它 使得 程序员和 执行 中的用 户软件 在联 机方式下相 互作用 , 提 供了中断程 序 、 在程序中设置断点 、 显示并改变符 号项 中的变量 、 逐语句的执行程序等特性 。 如 B I M 公司为 P L l / 的 C C ; D E C 公司为 CO B O L 配的 C ID 等 。 另一种是 程序 语言所提 供 的调 试特性 对语言 的 扩充 。 如 P L l / 提 供了 c H E c K 语句 , F O R T R A N 提供 了作为注释或在编译时 作为正 式语 句解释 的特性等 。 此外 , 为了调 试程序 , 常 常使用操 作系统提供的某些实用软件 , 例如文件或 内存 的转储 , 两个文件的比 较程序 等 , 或是利用测试得到 的 信息 。 然而 , 最有效 的调 试工具 似乎是写程序时写到程序中的调试语 句 , 这 样 , 出错区域可 由程序员定位。 调 试语句是一些不影响程序的功能 , 仅 给调试人员提供如下 信息的语 句:
✦活动路径
✦统计活动次数
✦其它有关信息
常用的调试 语句有 以下几种 :
①利用系统 提供的调试命令和语句 如在 A P P L E S O F T 中以下命令与语句常 用 , S T O P 语 句使程序暂 停 , 设置断点 ; C O N T 语句使程序从断 点继续执行下去 ; T R A C E 逐个行跟踪 , 即逐 次显示计算机执行的语句行号 , 给 定一 组调试 数据后可以检查程 序是否按预想的路径执行及执行的结果是否 正确 ; N O T R A C E 命令取消逐行跟 踪。 在 F O X B A s E 中 , 程序执 行到 S U S P E N D 时能把正在执行的程序挂起 , R E S U M E 能使被 挂起的程序 从断点处继 续恢复运行 ; S E T E C H O O F F / O N , 默认值 为 O F F , 若设置为 O N , 则将 每一条执行过的命令在屏幕上显示 , 由此可确切地掌握当 前程 序运行 的进程 , 帮助 查 出产 生 间题的 位置 , S E T S T E P O F F /O N , 默认为 O F F , 当为 O N 时 , 程序会以单 步形式进 行等。
②设 置状 态变 量 例 如 , 在 每个 模块中设置一个状态变 量 , 程序进入该 模块时 , 便给该 状态变量一 个特殊值 , 根 据各状态变 量 的值 , 可以判定程序活动的大致路径 。
③设置计数器 在每个模块或基本 结构中 , 设置 一个计数器 , 程序 每进入该结构一次 , 便计数一 次。 这样 , 不仅 可以判断 出程序活动的路径 , 而且 当程序中有死循环时 , 用此方法便能很快确定 .
④插入打印语句
打印语句是最 常用的一种调试语句。 它用起来非常 敏捷 , 能产生许多 有用的信息 . 特 别适用于人机对话 或 调试过程 。 关键是断点的位置和打印哪些变量 的值 。 下面介绍打印语句的几种用法 。
A.回声打印 ( E C H O P R IN T IN G ) “ 回声 ” 打印的特点是“ 读 了就写” 。 它把打印语句放在紧靠读语句之 (或输入语句 )之后 , 或模块入 口 处 , 及 调 用语句之前后 . 可以帮助调试人员检查数据有没有被 正确地翰入或接 口 处信息传递是否正确 。
B. 追踪打印
追踪打印是为提供程序执行的路径信息而设置的打印语 句。 这些打印语句通常设置在下述 位置 : . 模块首部或尾部 . 调用语句前后 . 循环结构 内的第一个语句或最后一个语句 . 紧靠循环结构后面第一个语 句 . 分支点之前 . 分支中的第一个语句
C.抽点打印
抽点打印就是选择一些可疑点设置打印语句 , 以便打印有关变量的值 。
D.成组打印子程序
即集中一组打 印语句写成一个 专用子程序 , 凡是需 要了解情况处就可调用此子程序。 例 : 考 虑到 层、 块结构 的需要 , 可在一层中编写一个打印子程 序。
8 9 9 9 R E M C 层成组打 印子程序
90 0 0 P R I N T “ C $ = ” ; C $ ; “ C C $ = ” ; C C $
9 0 1 0 P R IN T “ C = ” ; C ; “ C C 一 ” ; C C ; “ C l = ” ; C l ; “ C Z = " ; C Z
9 0 20 R E T U R N
可在若干地方调用 此子程序 :
31 4 5 P R IN T “ 检索部分打印” : G O S U B 90 0 0
3 5 6 5 P R IN T “ 分类部分打印” : G O S U B 9 0 0 0
36 7 5 P R I N T “ 求和部分打印” : G O S U B 9 0 0 0
此方法很有用 , 能动态地 了解程序运行情况 。
预埋技术预埋技术是在程序 中加入“ 潜伏” 的调试语 句。 前面介绍的打印语句和成组打 印子程序 , 在程序完 成后要将 其删去 . 而预埋技术将调试 语句永久地编入程序 , 其是否起作用 由逻辑软 件开头控制 。
例如: 10 IN P U T “ X = ” ; X 20 IF X ( 1 O R X ) = 1 0 T H E N P R IN T “ N O D E F IN I T IO N ” 30 IF X ) = 1 A N D X ( 3 T 圣IE N P R I N T “ Y = ” ; 5一 CO S ( 8 * X ) 4 0 IF X ) = 3 A N D X ( 6 T H E N P R I N T “ Y = " ; E X P ( X )
5 0 IF X >= 6 A N D X ( 1 0 T } {E N P R IN T “ Y = ” ; 1+ S Q R ( X 二 1)
60 E N D 在此例中 , 我们只处理了 X e 〔1 , 10 ) 的正常情况 , 但估计到使用 中出现 的变动可能导致 x ( 1 或 x ) 1 0, 提 前将调试语句放 在程序 中。 这样 , 对于任何情况的输入程序都能 适应。 人是健忘 的 , 如果没有这个调试语句 , 将会花费很多时间去查错 。 错误诊断的推理技术归纳法排错 ( D E B U G G I N G B Y I N D U C T IO N )其 荃本思想是 逐步减少和改进 假定的过程 。 在查 出错误后 , 要把一切可 能的原 因和假定都提出来 , 利用 错误数据 排除一部分 , 假 定再从其余 假定中估计可能性最大的一个 。 使确 定错误原 因的范围更集 中 , 下一步 或 许就可证明这一改进后的假定 , 或再作其他选择 . 
演绎法排错其基本思 想是枚举所有可能引起 出错的原 因作为假设 , 然后利用数据逐一排除不可能发 生的原 因与假设 , 将 余下的原 因作为主攻方向。 演绎法过程如下 图所示 :
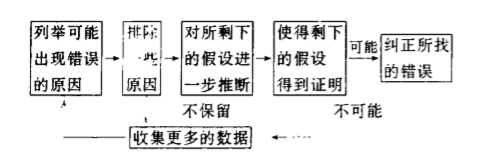 回溯法 ( B A C K T R A C KING)对于小程序 , 这 种技术极为有用 。 从错误 出现之处 出发 , 沿反 向路径进行检查 , 直到找出错误的原因 。 推理是在取得一 定的实验数据的基础 上进行 的 , 推理 得出的假设 , 要靠实验证 明 并取得 新的数据 , 把搜索 范围缩 小。故错误诊断的 实验方法与推理技术应结合使用 , 互相补充 。 错误修改的原则不要试着改不要当只 查到 了一些征兆 , 原 因还没有 查清 , 便想试 着改 动某个语句 。 这 种盲 目行 为成功 的概率很 小 。 因 某些错误征兆 的修改并没有治本 。 有时会把 某些新的错 误掺加到程序 中 , 造 成调试 的混乱 。 修改 了一个错误 , 可能还 会有别的错误一般错误 是密集 的 , 修改了一个错 误后 , 还应检查它的近邻还有没有别的错误或者在程序 中还有无类似 的错误 。 改变源程序代码 , 不要改变目标代码当调试一个大 系统 , 特别是用 汇编语 言写的系统纠错时 , 不要直接修改目标代码。 否则 , 当程 序重新编译 或重新汇编时 , 错误 还会再现 修改错误的过程将迫使人们暂时回到设计阶段修改错误是 程序设计的一个重要 内容和形式 。 一般 说来 , 在设计过程中所使用 的各种方法应 能应 用于错 误修改过程 。 修改完毕 . 需进行 回溯测试因为 :
- 纠正错 误的概率 不是 10 0 %
- 纠正错误 时产生新错误 的可能性
- 修改代 码比 原有的代码更 易出错
由于软件调试是软件质量鉴定工 作必须 具备的前提条件 , 而且软件调试 过程关系到 软件质量的优 劣 , 所以 , 专门讨论软件调试技未的有关内容。 目前 , 软件设计人员中存在着一种错误 的认识 , 即认为软件调试只 是为了证明 自己 设计的软件或怪序的正 确性。 在这种思想指 导下 , 软件设计人 员往往会选择简单的调试 方法 和简单的数据情况 , 往往仅完成主 要 功 能的调试 , 这就造成了调试过程不 全面、 不 完整 , 使软件在投 入实际运行 后无法长期可 靠的工 作。 正确的软件调试作用为: 软件调试是为 了发现 错误而执行软件的过程 。 结果通 过软 件调试发现 了错误 , 并不 是证 明了软件设计 的 失败 , 而 恰好是增加了软件的可靠性和应 用 价值。 所以 , 软件调试是软件开发 中地 位 十 分重要 的一 个工 作阶段。 软件调试工作应遵循的原则
- 根据软件所具有的功能 、 结构和 数据 类 型来选择调试方案和调试的重 点。
- 从心理学和调试有效性而论 , 软件设 计者不应调 试 自己 的软件。 如 果没有条件做 到这 一点 , 可以采用 一些集体工作的措施来 弥补 。
- 在软件调试 中, 不 但 要 对 那些合法的、 正常的情况进 行调试 , 而且要对那些 非 法的 、 异 常的情况进行调试。 调试应 对软件 具有一定的破坏力。
- 在软件调试 中, 不但要 检查软件是否 完成了应完成的功能 , 而且要 检查软件是否 完成了不 应有的功 能。
- 任何调试数据、 调试结果和错误 内容 都是极有价值的资料 , 应 认 真 地 分析、 保 存 。 某些 情况可能需要反复调试 、 纠错。
- 国 外的有关统计资料表明: 已发现较 多错误 的软件与已发现较少错误 的软件相比 较 , 前者仍存在错误 的概率较大 。
- 国外的 研究资料表明: 要结束一个软 件的调试过程是有条件的 , 是根据诸多因素( 如已发现的错误率 、 查错效率、 调试覆盖 率等 ) 综合分 沂后做出的 。
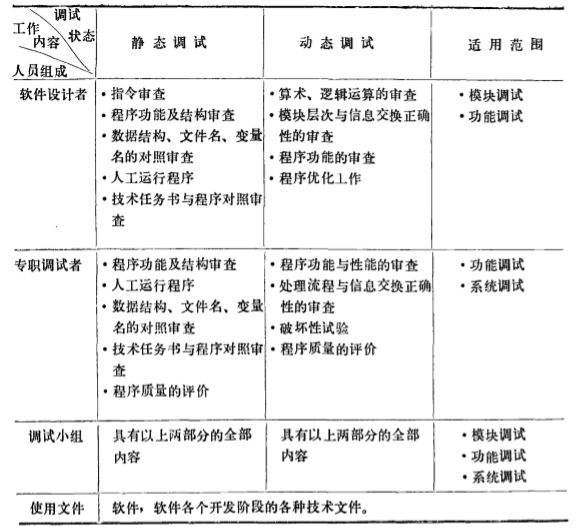
软件调试的几种工作方式软件调 试中常见的 几种工作方式 和工作 内容见表 l 。 在适用 范围 一栏中, 根据调试 的规模分了三个等级: 模块级 、 功 能级、 系 统级 。 各等级的任 务如下:
- 模块调试: 对相互独立的各个模块 在 各种条件下进行运行 , 检查模块内部的运算 和逻 辑关系 、 控制关系的正确性。
- 程序功 能调试: 对于组成某一功能 的 各个模块进行联调 , 检查 在各种条件下的执 行过 程 和执行结果 , 特别是模块之 间的层次 关系和信息 交换 的正确性 。
- 系统调试: 将各个功能的程序汇合 , 在实际或模拟的工作 环 境中, 检查输入 、 输 出是否符合要求 , 测定并评价软件的各项性 能 , 提出改进意见。
由于三个等级的调 试内容与规模不同 , 所采用的工 作 方式和工 作方法也不相同。 一 般 地说 , 由数人 组成的 软件调 试小组 可以 达 到相互 启发 , 集思 广议 , 相互检查 , 认真高 效的工 作目的 。 但这要求 软件调 试小组的每 个成员在软件设计与调试技术方面 , 在微机 使用 方面 , 在对整个系统功 能与性能的理解 方面 , 具有较高的水平与深刻的认识 。
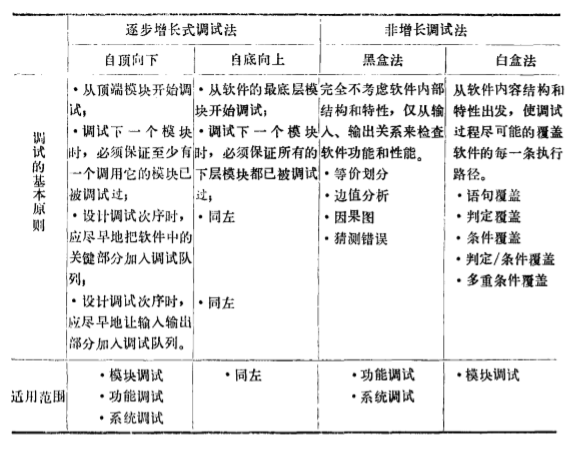
 软件调试方法软件调 试中经常采用 的方法见表 2 。 逐 步增长和非增长式两种调 试方法 , 各有优缺 点 , 列举如下:
- 非增长式调试需 要 完 成 更大的 工作量。
- 逐步增长式调试 中 , 由于 及时地完成 了模块的组合调试, 模块之间的接 口错误和 由多个模块运行产生的功能错误 , 能及早地发现。
- 利用逐步增长式调试 , 寻错纠错比较容易。
- 逐步增长式调试可以 更 彻底 地对软件 进行调试 。
- 非增长式调试需用的机器时间较少 。
- 用非增长式调试 , 在整个调试阶段有 可 能并行工作。
- 在逐步增长式调试法中 , 自顶向下调 试的缺点是很难产生调试条件, 调试的 相当 时间内无法考察结果输出。 而自底 向上调试 的缺点是必须给 出调 用模块 , 在加人最后一个模块之前 , 程序不能作为一个整体存在。
- 在非增长式调试法中, 黑盒 法的缺点 是寻错纠错极困难 , 白盒法的缺点是工作量 太大 。 综合比较起来 , 逐步增长式调试法是一 种比较好的方法 , 适用于工程应用类 软件 , 建议推广实施。 如果数人同时采用逐步增长 法对同一个软件进行调试 , 就可以 达到相互 补充 、 完整调试的 目的 。
调试工 作中应注意的几点
- 调 试前应认真地查阅有关设计资料 , 避免 出现对软件设计任务 书的理解不准确 、 不完整而造成的软件设计中的缺陷。
- 调 试中应认真地检查程序结构 ( 是否 采用模块结构 ) 和指令使用 ( 如运算指令使 用不 当 , 转移指令使用 太多等 ) 。
- 调试中一定要 对 程 序 进行破坏性试 验 , 考核程序的可 靠性。
- 调试结束前 , 应 把以 前完成的各个调 试情况复现一遍 , 避免由于 纠正某个程序错 误而出现 了其他的错误 或缺陷。
- 调试完 成后 , 应尽 可能的对程序进行 优化 , 提高程序质量。
软件调试技术中几 个研究专题为了更有效 、 更经济地开 展软件调试工 作 , 有必要 在以 下两 个方面进行研究 :
- 应重视软件调试数据与结果的收集、 分析工作。 目的 有两 个: 第一 , 统计软件出 错类型和产生错误 的原因 , 以 便于 在今后的 软件开发 中加以克服 , 第二 , 分析各种调试 措施或数据条件对各类错误的有效性 , 建立 起一套高效的调试原则。
- 利用 积累的调试经验 , 建立软件可靠 性分析 , 软件错误预测的模型 , 为寻找结束 调试的最佳时机提供参考或依据。
软件调试工作是软件开 发 中最 复杂、 最 具有技术性和技巧性的工作 , 所以 , 应大力地并展研究和提高工 作 , 保 证软件具有优 良 的质量与性能。
随软件向大型化和复杂化方向发展 . 软件调试的难度 也在不断增大。 对于一 些小的软件 我们可 以不讲究什么方法 . 只要通过插入print语句等简单手段就可 以解决问题 但是如果是要调试一个比较大的系统 . 不讲究必要的调试 技巧就会多花费很多时间甚至根本行不通了。
那么如何掌握调试技巧 , 提高调试效率呢 ?学习基本的调试原理是第一步 . 试想如果我们不 了解调试工具的工 作机制 , 那么怎么可能最大限度地发挥其功能呢。 如果我们根本没听说过硬件断点 . 那么我们怎么能利用它解决普通软件断点无法完成的任务呢 ?
从 宏观来看 . 软件调试是调试工具 、 系统软件 (操作系统)和C P U 这三者密切 配合、 相互协作的一个复杂过程。 简单来说CP U 为软件调试提供了硬件一级的支持 , 是很多调试功能的根 本基础: 操作系统负资协调管理 CPU 所提供的硬件支持 ,并为各种调试工具提供服务;调试工具与调试人 员直接交互 ,使操作系统和CPU所提供的调试支持真正 可用。 下面 , 便以 IA 一3 2 处理器 《CP U ) 为例介绍 CP U 对软件调 试的支持。 IA 一 3 2 处理器是指英特尔3 2 位架构 ( l n t e l ? rA c h i一tc e t u r e 3 2一b it ) 处理器 . 即从 38 6 开始的 x 8 6 处理器 . 包括i3 86 、i4 86、奔腾、p 6 系列和奔腾 4 系列处理器。 可以将 lA 一 3 2 处理器 的调试支持简单概括如下:
- INT3 指令— 又叫断点指令 . 是软件断点的实现基础 。
- 标志寄存器 F L A G S 的 TF 标志— 陷阱标志位 . 是单 步执行的实现基础
- 断点地址寄存器 D R0一 D R 3— 用于设置断点地址 (线性 内存地址或 l /O 地址 ), 是硬件断点的实现基础 。
- 断点控制寄存器 DR 7— 用来控制和进一步描述四个调 试地址寄存器 (D R O一D R 3 ) 的断点条件
- 断点状态寄存器 DR 6— 当断点发生 时 . 向调试器报告该断点的具体情况, 以便调试器区分发生的是哪个断点。
- 断点异常 (# BP) 一 当 INT3 指令执行时 , 会导致此异常.CPU 转到该异常的处理 程序 。
- 调试异常 (# DB ) 一 当除 INT 3 指令以外的调试事件 发生时 会导致此异常。
- 任务状态段 (T S )S 的T 标志 任务陷阱标志 , 当切换到设置了 T 标志的任务时 , 中断到调试器 。
- 分支记录机制 用来记录上一个分支 、 中断和异常的地址等信息 。
下面我们分几块对以上 内容做进一步讨论: 软件断点X8 6 系列处理器从其第一代 产品英特尔 8 0 8 6 开始就提供 了一条专门用来支持调试的指令INT 3。 简单来说 , 这条指令的目的就是使 CP U 中断 (陷入 ) 到调试器 . 以供调试者对执行 现场进行各种分析 。
下面通过一 个小实验来感受一下INT 3 指令的工作原理 。
在 V is u a l C + + S tu d io 6.0 ( 以下简称 v C 6 ) 中创建一个简单的He l l o w o r l d 控制台程序HIn t 3 然后在m a i n () 函数的开头通过嵌 入式汇编插入 对INT3指令的调用 :
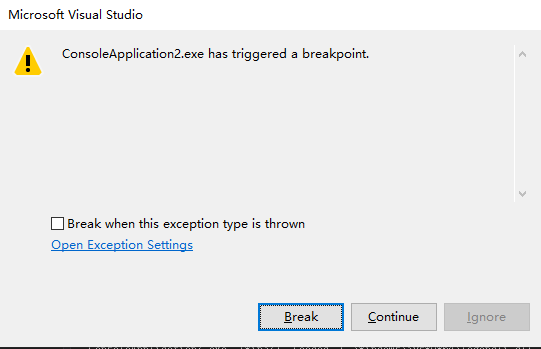
 当在 V C 环境中执行以上程序时 . 会得到以下对话框 , 点O K 按钮后程序便 会停在 N I T 3 指令所在的位t 。 由此看来我们 刚刚插入的一行 (asm INT 3 ) 相当于在那里设 了一个断点 .
 这正是通过注入代码手工 设盆断点的方法 , 这种方法在调试某些特殊的程序时还 非常有用。
w id n o w s 操作系统还提供了相应的 A P I 用于手 工断点 . 例 如用户模式T 的De bu g B re a k ( ) 和内核模式下的DbgBreakPoint(),DbgBreakPointWithStatus()。 把刚才的小程序中的对 INT 3 的直接调 用改 为调用 Win do w s A PI De bug B r e a k ( ) (需要在开头 Include< w id n o w s.h> ) . 然后执行可 以看到产生 的效果是一样的。 通过反汇编很容易看出这些 AIP 在x 8 6 平台上其实都只是对INT 3指 令的简单调 用。
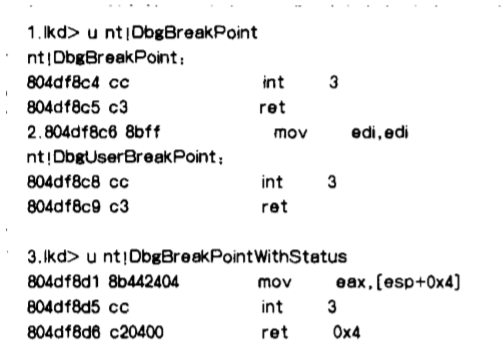
- 在 windbg 中启动本地内核调试 (参见 w in d b g 帮助文档 ) 然后使用u命令进行反汇编。 提示符 Ikd> 的含义是 “ Lo c a l ke r n e l d “ 。 本地内核调试需要Wind o w s XP或 以上操作系统才支持。
- 用来对齐的,没有实际意义。3 2 位 C户 U 通常需要 内存和可执行文件 以 4 字节对齐。
- DbgBreakPointWithStatus()允许向调试器 传递一个整型 参数 。
那么C PU是如何从被调试程序调到调试器 的呢 , 这一机制的全部工作过程因操作系统和被调试程序的执行模式 (用户模式还是 内核模式 ) 的不同而有所不同 。目前我们可 以作出如下简单理解 :
C p U 把 INT 3 指令处理 为一种软件异常 . 当执行INT 3指令 时 C PU 会把当时的程 序指针 ( C S 和 EIP) 压入堆栈保存起来,然后通过 中断向量表调 用 lNT 3 所对应 的中断例程。 当我们在调试器 中运行程序时 . 调试器会直接 ( DOS 时代 ) 或间接(通过操作系统的 A P I ) 注册这个中断服务 因此 当 INT 3 中断发生时 . 调试器的代码会被调用而执行 。在实模式下CPU 的执行逻辑如下 :

- 这是针对实模式的情况 保护模式下会更复杂 . 但 原理 ’类似。
- 对于INT 3指令 ,v e c t o r _ n um b e r 为 3.这个操作过程本适用于所有软件 中断和异常。
- # G P 即 Ge n e r a l Protection Exception , 常规保护性错误。也就是说 当中断向量表 的长度 (Lim i t ) 不足 以包 含本向量时,C P U便会产生常规保护异常。
- IF语句的结束语句
- 当堆栈不足以容纳接下来要压入的6字节内容时,便产生堆栈异常
下面考虑一下调试器是如何设置断点的。当我们在调试器中对代码的某一行设断点时,调试器会先把这里的本来的指令的第一个字节保存起来。然后写入一条INT 3指令。因为INT 3指令的机器码为0xCC,仅有一个字节,所以设置和取消断点时也只需要保存和恢复一个字节。这是设计这条指令时便考虑好的。顺便说一下,虽然VC6是把断点的设置信息(断点所在的文件和行位置)保存在和项目文件相同位置且相同主名称的一个.opt文件中。但注意,该文件并不保存每个断点处应该被INT 3指令替换掉的那个字节。因为这种替换是在启动调试和调试过程中动态进行的。这可以解释有时我们在VC6中,在非调试状态下,我们甚至可以在注释行设置缎带你。当开始调试时,会得到一个图2所示的警告信息。这是因为当用户在非调试状态下设置断点时,VC6只是简单的记录下该断点的设置信息。当开始调试时,VC会一个一个的取出OPT文件中的断点记录 . 并真正将这些断点设置到目标代码的内存映像中。 也就 是要将断点位置对应的指令的第一个字节先保存起来 , 再替换为C C . 即 INT 3 指令 . 这是如果 VC 6 发现某个断点的位置根本 对应不到目标映像的代码段 , 那么便会发出图 2 所示的警告 。
 下面说说INT 3 断点被触发时的悄形 . 我们仍以V C 6 为例 .也就是使用 VC 6 调试一 个普通的 3 2 位 W in d o w s 应用程序 。 当Cp U 执行到 INT 3 指令时 . 由于 INT 3指令的设计目的就是 中 断到调试器 . 因此CPU 执行该指令的过程也就是准备产生断点异常 (Breakpoint exception简称# B P)并转去执行异常处理例 程的过程。 W in d o w s下所有异常和中断都是先由内核例程处理的. 因此应用程序中的 INT 3会导致 C U P 从用户模式转入内核模式并执行nt!KiTrap03例程。 接下来经过几个内核函数的处理 .因为这个异常是来自内核模式的. 而且该异常的拥有进程正在 被调试 (内核函数可以得到这些信息 ) . 所以内核例程会把这 个异常分发给用户模式的调试器 . 这里也就是VC 6 。 接下来V C 6会根据异常的发生位置 (记录在每个异常的附属数据结构中) 试图寻 找一个与其匹配 的断点记录。 如果找不到 . 那么就说明
导致这个异常的INT 3 指令不是 v C6 动态替换进去的 , 因此会 显示一个图 1 所示的对话框. 意思是说一个 “ 用户 “ 插入的断 点被触发了。 另外值得说明的是 . V C 6 在每次中断到调试器 时 .会先将所有断点处替换为 INT 3的指令恢复成原来的指令 , 然 后再把控制权交给用户 。 所以在调试器下 . 我们是看不到动态插入的 INT 3指令的. 
还想介绍一个有趣现象 。当我们用 VC 6 进行调试时 , 常常会观察到一块刚分配 的内存或字符串数组里 面被坟充满了CC。如果是在中文环境下 . 因为x o C CC C 恰好是汉字 ` 烫 ` 字 的简码 . 所以会观察到很多 ` 烫烫烫烫烫烫… ’ . CC 正好是 INT 3 指令的机器码 . 这是偶然的么? 答案是否定的 . 因为这是有意为之 . 为了辅助试 调试版本的运行库会用0xCC 来填充 刚刚分配的缓冲区 . 这样如果 因为缓冲区或堆栈溢出时程序指针意外指向了这些 区域 . 那么便会因 为遇到这些 自动填充的 INT 3指令而马上 中断到调试器 。 另一方面 . 编译器也经常用 INT 3指令来填充函数或代码段末尾的空 闲区域。 这也可以解释 为什么有时我们没有手工插入任何对 INT 3的调用 . 但是也会遇到图 1 所示的对话框。因为使用 INT 3 指令产生 的断点是依靠插入指令和软件中 断机制工作的 . 因此人们习惯把这类断点成为软件断点 . 软件断点具有如下局限性 :
- 属于代码类断点 , 即可 以让 C PU 执行到代码段内的某个地址时停下来 . 不适用于数据段和 1 / 0 空 间。
- 对于在RO M ( 只读存储器 ) 中执行的程序 ( 比如 B I O S 或其它固件程序) . 无法动态增加软件断点 。 因为目标内存是 只读的 . 不能动态写入断点指令 。 这时就要使用我们后面介绍 的硬件断点。
- 当中断向量表或中断描述表 (IDT) 没有准备好或遭到破 坏的情况下这类断点无法或不能正常工作的。 比如系统刚刚启动时或者IDT被病毒窜改后 。 这时只能使用硬件级的调试工具。
虽然软件断点存在以上不足 . 但因为它使用方便 , 而且没 有数量限制 (硬 件断点需要寄存器记录断点地址 . 有数量限制 ),所以目前仍被广泛应用。
关于 INT 3指令还有一点要说明的是 . IN T 3 指令与当n=3时的 INT n 指令 (通常所说的软件中断) 并不同. INT n 指令对 应的机器码是CD后跟 1字节n 值 . 比如INT 23H 会被编译为CD23 。 与此不同 INT 3 指令具有独特的单字节机器码 CC 。 也就是当编译器看见 IN T 3 时会特别的将其编译为 CC . 而不是 CD 0 3。尽 管没有那个编译器会将 INT 3 编译成 CD 0 3. 但是可以通过某些方 法直接在程序中插入 CD 0 3 。 但是这样做会失去IN T 3 指令所具有的 特殊待遇 (例如在虚拟 8086模式下免受IOPL检查).
- « 前一页
- 1
- ...
- 1269
- 1270
- 1271
- 1272
- 1273
- 1274
- 1275
- ...
- 1376
- 后一页 »
|