从零开始自己动手写自旋锁
前言
我们在写并发程序的时候,一个非常常见的需求就是保证在某一个时刻只有一个线程执行某段代码,像这种代码叫做临界区,而通常保证一个时刻只有一个线程执行临界区的代码的方法就是锁。在本篇文章当中我们将会仔细分析和学习自旋锁,所谓自旋锁就是通过while循环实现的,让拿到锁的线程进入临界区执行代码,让没有拿到锁的线程一直进行while死循环,这其实就是线程自己“旋”在while循环了,因而这种锁就叫做自旋锁。
自旋锁
原子性
在谈自旋锁之前就不得不谈原子性了。所谓原子性简单说来就是一个一个操作要么不做要么全做,全做的意思就是在操作的过程当中不能够被中断,比如说对变量data进行加一操作,有以下三个步骤:
将
data从内存加载到寄存器。将
data这个值加一。将得到的结果写回内存。
原子性就表示一个线程在进行加一操作的时候,不能够被其他线程中断,只有这个线程执行完这三个过程的时候其他线程才能够操作数据data。
我们现在用代码体验一下,在Java当中我们可以使用AtomicInteger进行对整型数据的原子操作:
import java.util.concurrent.atomic.AtomicInteger;public class AtomicDemo {public static void main(String[] args) throws InterruptedException {AtomicInteger data = new AtomicInteger();data.set(0); // 将数据初始化位0Thread t1 = new Thread(() -> {for (int i = 0; i < 100000; i++) {data.addAndGet(1); // 对数据 data 进行原子加1操作}});Thread t2 = new Thread(() -> {for (int i = 0; i < 100000; i++) {data.addAndGet(1);// 对数据 data 进行原子加1操作}});// 启动两个线程t1.start();t2.start();// 等待两个线程执行完成t1.join();t2.join();// 打印最终的结果System.out.println(data); // 200000}}从上面的代码分析可以知道,如果是一般的整型变量如果两个线程同时进行操作的时候,最终的结果是会小于200000。
我们现在来模拟一下一般的整型变量出现问题的过程:
主内存
data的初始值等于0,两个线程得到的data初始值都等于0。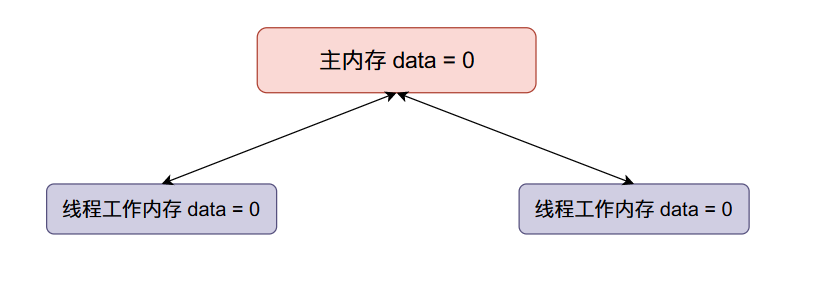
现在线程一将
data加一,然后线程一将data的值同步回主内存,整个内存的数据变化如下: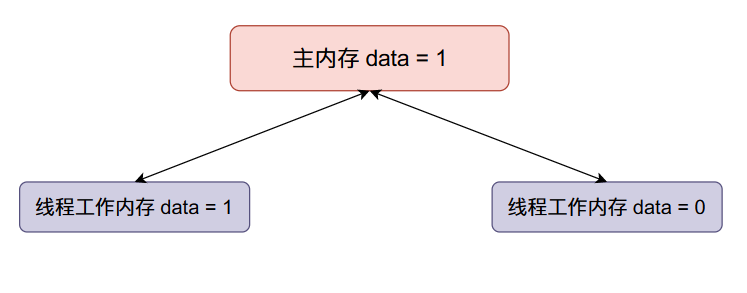
现在线程二
data加一,然后将data的值同步回主内存(将原来主内存的值覆盖掉了):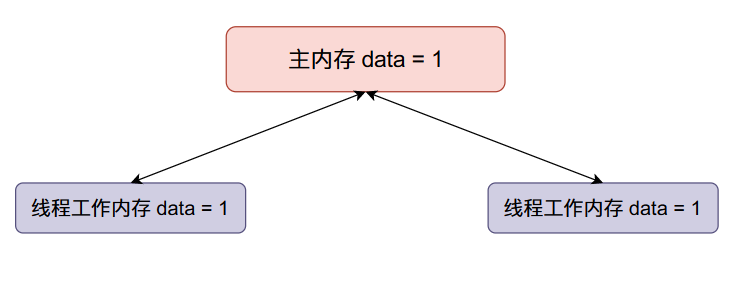
我们本来希望data的值在经过上面的变化之后变成2,但是线程二覆盖了我们的值,因此在多线程情况下,会使得我们最终的结果变小。
但是在上面的程序当中我们最终的输出结果是等于20000的,这是因为给data进行+1的操作是原子的不可分的,在操作的过程当中其他线程是不能对data进行操作的。这就是原子性带来的优势。
自己动手写自旋锁
AtomicInteger类
现在我们已经了解了原子性的作用了,我们现在来了解AtomicInteger类的另外一个原子性的操作——compareAndSet,这个操作叫做比较并交换(CAS),他具有原子性。
public static void main(String[] args) {AtomicInteger atomicInteger = new AtomicInteger();atomicInteger.set(0);atomicInteger.compareAndSet(0, 1);}compareAndSet函数的意义:首先会比较第一个参数(对应上面的代码就是0)和atomicInteger的值,如果相等则进行交换,也就是将atomicInteger的值设置为第二个参数(对应上面的代码就是1),如果这些操作成功,那么compareAndSet函数就返回true,如果操作失败则返回false,操作失败可能是因为第一个参数的值(期望值)和atomicInteger不相等,如果相等也可能因为在更改atomicInteger的值的时候失败(因为可能有多个线程在操作,因为原子性的存在,只能有一个线程操作成功)。
自旋锁实现原理
我们可以使用AtomicInteger类实现自旋锁,我们可以用0这个值表示未上锁,1这个值表示已经上锁了。
AtomicInteger类的初始值为0。
在上锁时,我们可以使用代码
atomicInteger.compareAndSet(0, 1)进行实现,我们在前面已经提到了只能够有一个线程完成这个操作,也就是说只能有一个线程调用这行代码然后返回true其余线程都返回false,这些返回false的线程不能够进入临界区,因此我们需要这些线程停在atomicInteger.compareAndSet(0, 1)这行代码不能够往下执行,我们可以使用while循环让这些线程一直停在这里while (!value.compareAndSet(0, 1));,只有返回true的线程才能够跳出循环,其余线程都会一直在这里循环,我们称这种行为叫做自旋,这种锁因而也被叫做自旋锁。线程在出临界区的时候需要重新将锁的状态调整为未上锁的上状态,我们使用代码
value.compareAndSet(1, 0);就可以实现,将锁的状态还原为未上锁的状态,这样其他的自旋的线程就可以拿到锁,然后进入临界区了。
自旋锁代码实现
import java.util.concurrent.atomic.AtomicInteger;public class SpinLock {// 0 表示未上锁状态// 1 表示上锁状态protected AtomicInteger value;public SpinLock() {this.value = new AtomicInteger();// 设置 value 的初始值为0 表示未上锁的状态this.value.set(0);}public void lock() {// 进行自旋操作while (!value.compareAndSet(0, 1));}public void unlock() {// 将锁的状态设置为未上锁状态value.compareAndSet(1, 0);}}上面就是我们自己实现的自旋锁的代码,这看起来实在太简单了,但是它确实帮助我们实现了一个锁,而且能够在真实场景进行使用的,我们现在用代码对上面我们写的锁进行测试。
测试程序:
public class SpinLockTest {public static int data;public static SpinLock lock = new SpinLock();public static void add() {for (int i = 0; i < 100000; i++) {// 上锁 只能有一个线程执行 data++ 操作 其余线程都只能进行while循环lock.lock();data++;lock.unlock();}}public static void main(String[] args) throws InterruptedException {Thread[] threads = new Thread[100];// 设置100个线程for (int i = 0; i < 100; i ++) {threads[i] = new Thread(SpinLockTest::add);}// 启动一百个线程for (int i = 0; i < 100; i++) {threads[i].start();}// 等待这100个线程执行完成for (int i = 0; i < 100; i++) {threads[i].join();}System.out.println(data); // 10000000}}在上面的代码单中,我们使用100个线程,然后每个线程循环执行100000data++操作,上面的代码最后输出的结果是10000000,和我们期待的结果是相等的,这就说明我们实现的自旋锁是正确的。
自己动手写可重入自旋锁
可重入自旋锁
在上面实现的自旋锁当中已经可以满足一些我们的基本需求了,就是一个时刻只能够有一个线程执行临界区的代码。但是上面的的代码并不能够满足重入的需求,也就是说上面写的自旋锁并不是一个可重入的自旋锁,事实上在上面实现的自旋锁当中重入的话就会产生死锁。
我们通过一份代码来模拟上面重入产生死锁的情况:
public static void add(int state) throws InterruptedException {TimeUnit.SECONDS.sleep(1);if (state <= 3) {lock.lock();System.out.println(Thread.currentThread().getName() + "\t进入临界区 state = " + state);for (int i = 0; i < 10; i++)data++;add(state + 1); // 进行递归重入 重入之前锁状态已经是1了 因为这个线程进入了临界区lock.unlock();}}在上面的代码当中加入我们传入的参数
state的值为1,那么在线程执行for循环之后再次递归调用add函数的话,那么state的值就变成了2。if条件仍然满足,这个线程也需要重新获得锁,但是此时锁的状态是1,这个线程已经获得过一次锁了,但是自旋锁期待的锁的状态是0,因为只有这样他才能够再次获得锁,进入临界区,但是现在锁的状态是1,也就是说虽然这个线程获得过一次锁,但是它也会一直进行while循环而且永远都出不来了,这样就形成了死锁了。
可重入自旋锁思想
针对上面这种情况我们需要实现一个可重入的自旋锁,我们的思想大致如下:
在我们实现的自旋锁当中,我们可以增加两个变量,
owner一个用于存当前拥有锁的线程,count一个记录当前线程进入锁的次数。如果线程获得锁,
owner = Thread.currentThread()并且count = 1。当线程下次再想获取锁的时候,首先先看
owner是不是指向自己,则一直进行循环操作,如果是则直接进行count++操作,然后就可以进入临界区了。我们在出临界区的时候,如果
count大于一的话,说明这个线程重入了这把锁,因此不能够直接将锁设置为0也就是未上锁的状态,这种情况直接进行count--操作,如果count等于1的话,说明线程当前的状态不是重入状态(可能是重入之后递归返回了),因此在出临界区之前需要将锁的状态设置为0,也就是没上锁的状态,好让其他线程能够获取锁。
可重入锁代码实现:
实现的可重入锁代码如下:
public class ReentrantSpinLock extends SpinLock {private Thread owner;private int count;@Overridepublic void lock() {if (owner == null || owner != Thread.currentThread()) {while (!value.compareAndSet(0, 1));owner = Thread.currentThread();count = 1;}else {count++;}}@Overridepublic void unlock() {if (count == 1) {count = 0;value.compareAndSet(1, 0);}elsecount--;}}下面我们通过一个递归程序去验证我们写的可重入的自旋锁是否能够成功工作。
测试程序:
import java.util.concurrent.TimeUnit;public class ReentrantSpinLockTest {public static int data;public static ReentrantSpinLock lock = new ReentrantSpinLock();public static void add(int state) throws InterruptedException {TimeUnit.SECONDS.sleep(1);if (state <= 3) {lock.lock();System.out.println(Thread.currentThread().getName() + "\t进入临界区 state = " + state);for (int i = 0; i < 10; i++)data++;add(state + 1);lock.unlock();}}public static void main(String[] args) throws InterruptedException {Thread[] threads = new Thread[10];for (int i = 0; i < 10; i++) {threads[i] = new Thread(new Thread(() -> {try {ReentrantSpinLockTest.add(1);} catch (InterruptedException e) {e.printStackTrace();}}, String.valueOf(i)));}for (int i = 0; i < 10; i++) {threads[i].start();}for (int i = 0; i < 10; i++) {threads[i].join();}System.out.println(data);}}上面程序的输出:
Thread-3 进入临界区 state = 1Thread-3 进入临界区 state = 2Thread-3 进入临界区 state = 3Thread-0 进入临界区 state = 1Thread-0 进入临界区 state = 2Thread-0 进入临界区 state = 3Thread-9 进入临界区 state = 1Thread-9 进入临界区 state = 2Thread-9 进入临界区 state = 3Thread-4 进入临界区 state = 1Thread-4 进入临界区 state = 2Thread-4 进入临界区 state = 3Thread-7 进入临界区 state = 1Thread-7 进入临界区 state = 2Thread-7 进入临界区 state = 3Thread-8 进入临界区 state = 1Thread-8 进入临界区 state = 2Thread-8 进入临界区 state = 3Thread-5 进入临界区 state = 1Thread-5 进入临界区 state = 2Thread-5 进入临界区 state = 3Thread-2 进入临界区 state = 1Thread-2 进入临界区 state = 2Thread-2 进入临界区 state = 3Thread-6 进入临界区 state = 1Thread-6 进入临界区 state = 2Thread-6 进入临界区 state = 3Thread-1 进入临界区 state = 1Thread-1 进入临界区 state = 2Thread-1 进入临界区 state = 3300
从上面的输出结果我们就可以知道,当一个线程能够获取锁的时候他能够进行重入,而且最终输出的结果也是正确的,因此验证了我们写了可重入自旋锁是有效的!
总结
在本篇文章当中主要给大家介绍了自旋锁和可重入自旋锁的原理,并且实现了一遍,其实代码还是比较简单关键需要大家将这其中的逻辑理清楚:
所谓自旋锁就是通过while循环实现的,让拿到锁的线程进入临界区执行代码,让没有拿到锁的线程一直进行while死循环。
可重入的含义就是一个线程已经竞争到了一个锁,在竞争到这个锁之后又一次有重入临界区代码的需求,如果能够保证这个线程能够重新进入临界区,这就叫可重入。
我们在实现自旋锁的时候使用的是
AtomicInteger类,并且我们使用0和1这两个数值用于表示无锁和锁被占用两个状态,在获取锁的时候使用while循环不断进行CAS操作,直到操作成功返回true,在释放锁的时候使用CAS将锁的状态从1变成0。实现可重入锁最重要的一点就是需要记录是那个线程获得了锁,同时还需要记录获取了几次锁,因为我们在解锁的时候需要进行判断,之后
count = 1的情况才能将锁的状态从1设置成0。
以上就是本篇文章的所有内容了,我是LeHung,我们下期再见!!!更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore