一、前言
官网:https://kubernetes.io/
官方文档:https://kubernetes.io/zh-cn/docs/home/
二、基础环境部署
1)前期准备(所有节点)
1、修改主机名和配置 hosts
先部署 1master 和 2node 节点,后面再加一个 master 节点
# 在192.168.0.113执行
hostnamectl set-hostname k8s-master-168-0-113
# 在192.168.0.114执行
hostnamectl set-hostname k8s-node1-168-0-114
# 在192.168.0.115执行
hostnamectl set-hostname k8s-node2-168-0-115
配置 hosts
cat >> /etc/hosts<<EOF
192.168.0.113 k8s-master-168-0-113
192.168.0.114 k8s-node1-168-0-114
192.168.0.115 k8s-node2-168-0-115
EOF
2、配置 ssh 互信
# 直接一直回车就行
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-master-168-0-113
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node1-168-0-114
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node2-168-0-115
3、时间同步
yum install chrony -y
systemctl start chronyd
systemctl enable chronyd
chronyc sources
4、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
5、关闭 swap
# 临时关闭;关闭swap主要是为了性能考虑
swapoff -a
# 可以通过这个命令查看swap是否关闭了
free
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
6、禁用 SELinux
# 临时关闭
setenforce 0
# 永久禁用
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
7、允许 iptables 检查桥接流量(可选,所有节点)
若要显式加载此模块,请运行 sudo modprobe br_netfilter,通过运行 lsmod | grep br_netfilter 来验证 br_netfilter 模块是否已加载,
sudo modprobe br_netfilter
lsmod | grep br_netfilter
为了让 Linux 节点的 iptables 能够正确查看桥接流量,请确认 sysctl 配置中的 net.bridge.bridge-nf-call-iptables 设置为 1。例如:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
2)安装容器 docker(所有节点)
提示:v1.24 之前的 Kubernetes 版本包括与 Docker Engine 的直接集成,使用名为 dockershim 的组件。这种特殊的直接整合不再是 Kubernetes 的一部分 (这次删除被作为 v1.20 发行版本的一部分宣布)。你可以阅读检查 Dockershim 弃用是否会影响你 以了解此删除可能会如何影响你。要了解如何使用 dockershim 进行迁移,请参阅从 dockershim 迁移。
# 配置yum源
cd /etc/yum.repos.d ; mkdir bak; mv CentOS-Linux-* bak/
# centos7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# centos8
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 设置yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动
systemctl start docker
# 开机自启
systemctl enable docker
# 查看版本号
docker --version
# 查看版本具体信息
docker version
# Docker镜像源设置
# 修改文件 /etc/docker/daemon.json,没有这个文件就创建
# 添加以下内容后,重启docker服务:
cat >/etc/docker/daemon.json<<EOF
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
EOF
# 加载
systemctl reload docker
# 查看
systemctl status docker containerd
【温馨提示】dockerd 实际真实调用的还是 containerd 的 api 接口,containerd 是 dockerd 和 runC 之间的一个中间交流组件。所以启动 docker 服务的时候,也会启动 containerd 服务的。
3)配置 k8s yum 源(所有节点)
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
EOF
4)将 sandbox_image 镜像源设置为阿里云 google_containers 镜像源(所有节点)
# 导出默认配置,config.toml这个文件默认是不存在的
containerd config default > /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
sed -i "s#k8s.gcr.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml

5)配置 containerd cgroup 驱动程序 systemd(所有节点)
kubernets 自v 1.24.0 后,就不再使用 docker.shim,替换采用 containerd 作为容器运行时端点。因此需要安装 containerd(在 docker 的基础下安装),上面安装 docker 的时候就自动安装了 containerd 了。这里的 docker 只是作为客户端而已。容器引擎还是 containerd。
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
# 应用所有更改后,重新启动containerd
systemctl restart containerd
6)开始安装 kubeadm,kubelet 和 kubectl(master 节点)
# 不指定版本就是最新版本,当前最新版就是1.24.1
yum install -y kubelet-1.24.1 kubeadm-1.24.1 kubectl-1.24.1 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
# 查看状态,这里需要等待一段时间再查看服务状态,启动会有点慢
systemctl status kubelet
查看日志,发现有报错,报错如下:
kubelet.service: Main process exited, code=exited, status=1/FAILURE kubelet.service: Failed with result 'exit-code'.
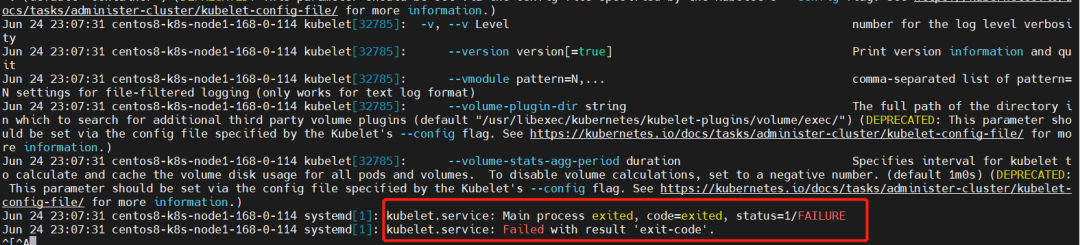
【解释】重新安装(或第一次安装)k8s,未经过 kubeadm init 或者 kubeadm join 后,kubelet 会不断重启,这个是正常现象……,执行 init 或 join 后问题会自动解决,对此官网有如下描述,也就是此时不用理会 kubelet.service。
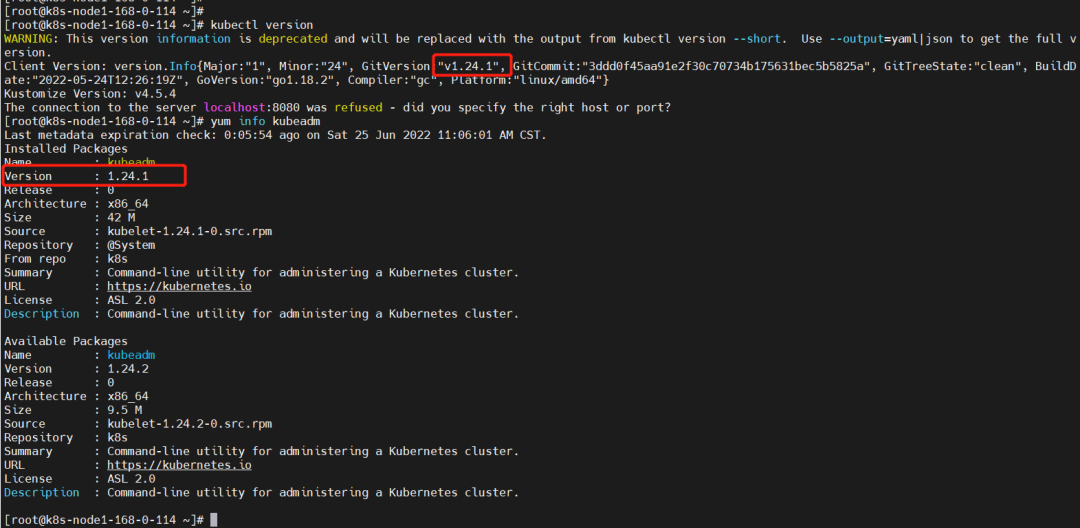
查看版本
kubectl version
yum info kubeadm
7)使用 kubeadm 初始化集群(master 节点)
最好提前把镜像下载好,这样安装快
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.24.1
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.24.1
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.24.1
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.24.1
docker pull registry.aliyuncs.com/google_containers/pause:3.7
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.3-0
docker pull registry.aliyuncs.com/google_containers/coredns:v1.8.6
集群初始化
kubeadm init \
--apiserver-advertise-address=192.168.0.113 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=cluster-endpoint \
--kubernetes-version v1.24.1 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--v=5
# –image-repository string: 这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
# –kubernetes-version string: 指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(v1.22.1)来跳过网络请求。
# –apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。这里的ip为master节点ip,记得更换。
# –pod-network-cidr 指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
# --control-plane-endpoint cluster-endpoint 是映射到该 IP 的自定义 DNS 名称,这里配置hosts映射:192.168.0.113 cluster-endpoint。 这将允许你将 --control-plane-endpoint=cluster-endpoint 传递给 kubeadm init,并将相同的 DNS 名称传递给 kubeadm join。 稍后你可以修改 cluster-endpoint 以指向高可用性方案中的负载均衡器的地址。
【温馨提示】kubeadm 不支持将没有 --control-plane-endpoint 参数的单个控制平面集群转换为高可用性集群。
重置再初始化
kubeadm reset
rm -fr ~/.kube/ /etc/kubernetes/* var/lib/etcd/*
kubeadm init \
--apiserver-advertise-address=192.168.0.113 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=cluster-endpoint \
--kubernetes-version v1.24.1 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--v=5
# –image-repository string: 这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
# –kubernetes-version string: 指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(v1.22.1)来跳过网络请求。
# –apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。这里的ip为master节点ip,记得更换。
# –pod-network-cidr 指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
# --control-plane-endpoint cluster-endpoint 是映射到该 IP 的自定义 DNS 名称,这里配置hosts映射:192.168.0.113 cluster-endpoint。 这将允许你将 --control-plane-endpoint=cluster-endpoint 传递给 kubeadm init,并将相同的 DNS 名称传递给 kubeadm join。 稍后你可以修改 cluster-endpoint 以指向高可用性方案中的负载均衡器的地址。
配置环境变量
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 临时生效(退出当前窗口重连环境变量失效)
export KUBECONFIG=/etc/kubernetes/admin.conf
# 永久生效(推荐)
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
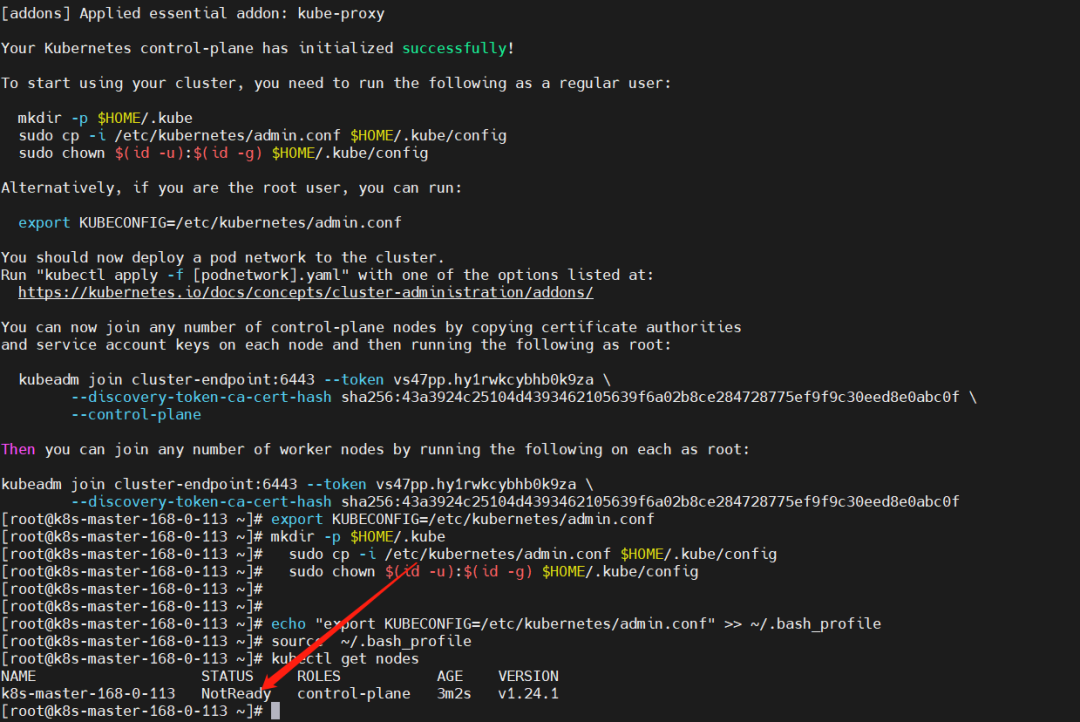
发现节点还是有问题,查看日志 /var/log/messages
"Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized"
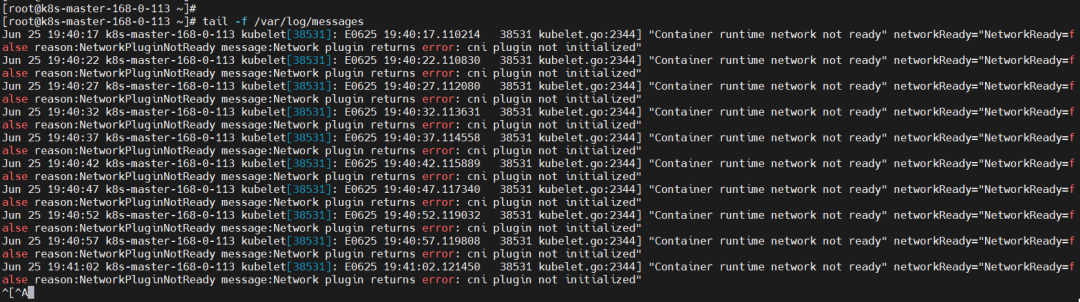
接下来就是安装 Pod 网络插件
8)安装 Pod 网络插件(CNI:Container Network Interface)(master)
你必须部署一个基于 Pod 网络插件的 容器网络接口 (CNI),以便你的 Pod 可以相互通信。
# 最好提前下载镜像(所有节点)
docker pull quay.io/coreos/flannel:v0.14.0
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果上面安装失败,则下载我百度里的,离线安装
链接:https://pan.baidu.com/s/1HB9xuO3bssAW7v5HzpXkeQ
提取码:8888
再查看 node 节点,就已经正常了
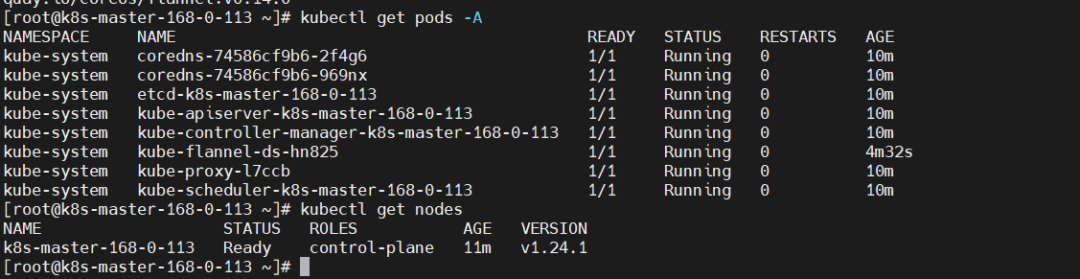
9)node 节点加入 k8s 集群
先安装 kubelet
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
systemctl status kubelet
如果没有令牌,可以通过在控制平面节点上运行以下命令来获取令牌:
kubeadm token list
默认情况下,令牌会在24小时后过期。如果要在当前令牌过期后将节点加入集群, 则可以通过在控制平面节点上运行以下命令来创建新令牌:
kubeadm token create
# 再查看
kubeadm token list
如果你没有 –discovery-token-ca-cert-hash 的值,则可以通过在控制平面节点上执行以下命令链来获取它:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
如果执行 kubeadm init 时没有记录下加入集群的命令,可以通过以下命令重新创建(推荐)一般不用上面的分别获取 token 和 ca-cert-hash 方式,执行以下命令一气呵成:
kubeadm token create --print-join-command
这里需要等待一段时间,再查看节点节点状态,因为需要安装 kube-proxy 和 flannel。另外,搜索公众号技术社区后台回复“Linux”,获取一份惊喜礼包。
kubectl get pods -A
kubectl get nodes
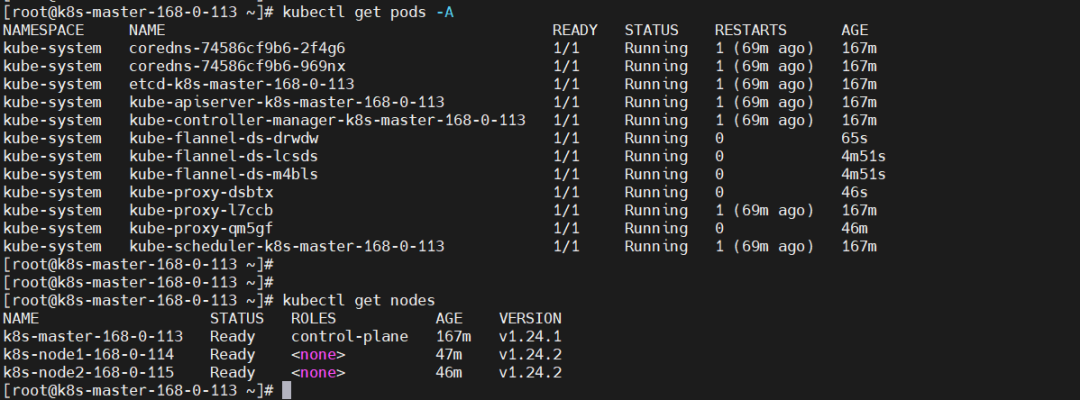
10)配置 IPVS
【问题】集群内无法 ping 通 ClusterIP(或 ServiceName)
1、加载 ip_vs 相关内核模块
modprobe -- ip_vs
modprobe -- ip_vs_sh
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
所有节点验证开启了 ipvs:
lsmod |grep ip_vs
2、安装 ipvsadm 工具
yum install ipset ipvsadm -y
3、编辑 kube-proxy 配置文件,mode 修改成 ipvs
kubectl edit configmap -n kube-system kube-proxy
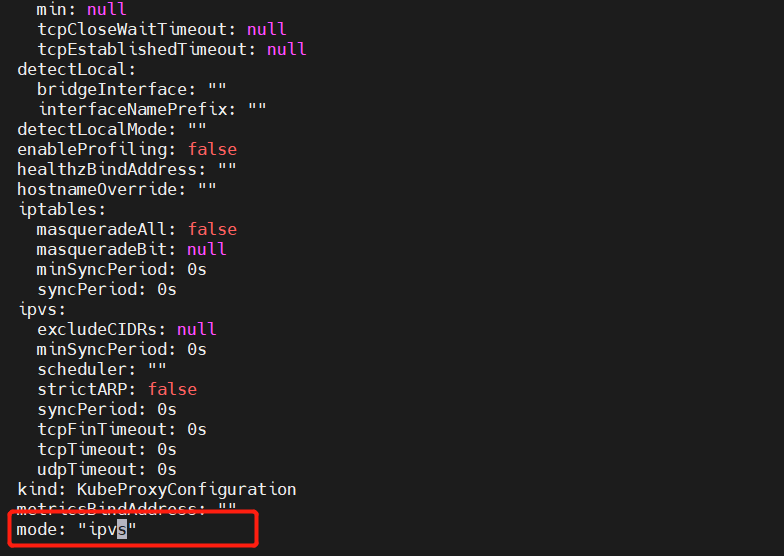
4、重启 kube-proxy
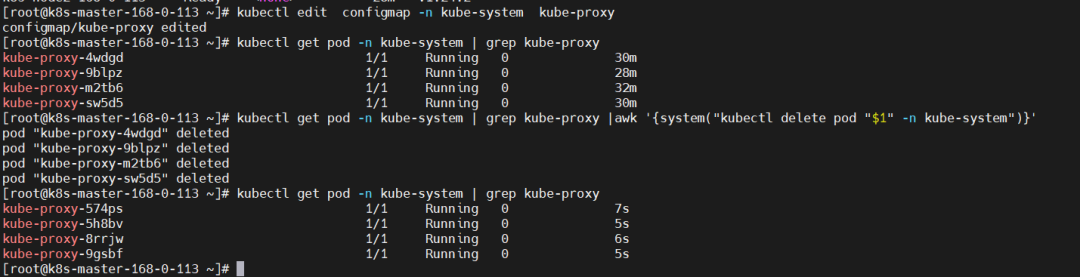
# 先查看
kubectl get pod -n kube-system | grep kube-proxy
# 再delete让它自拉起
kubectl get pod -n kube-system | grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}'
# 再查看
kubectl get pod -n kube-system | grep kube-proxy
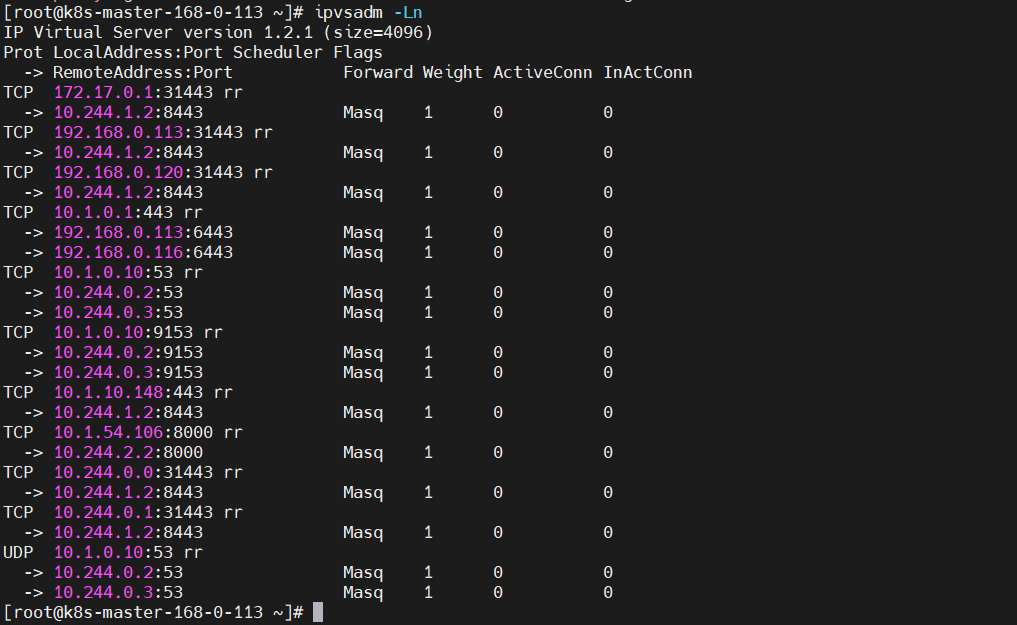
5、查看 ipvs 转发规则
ipvsadm -Ln
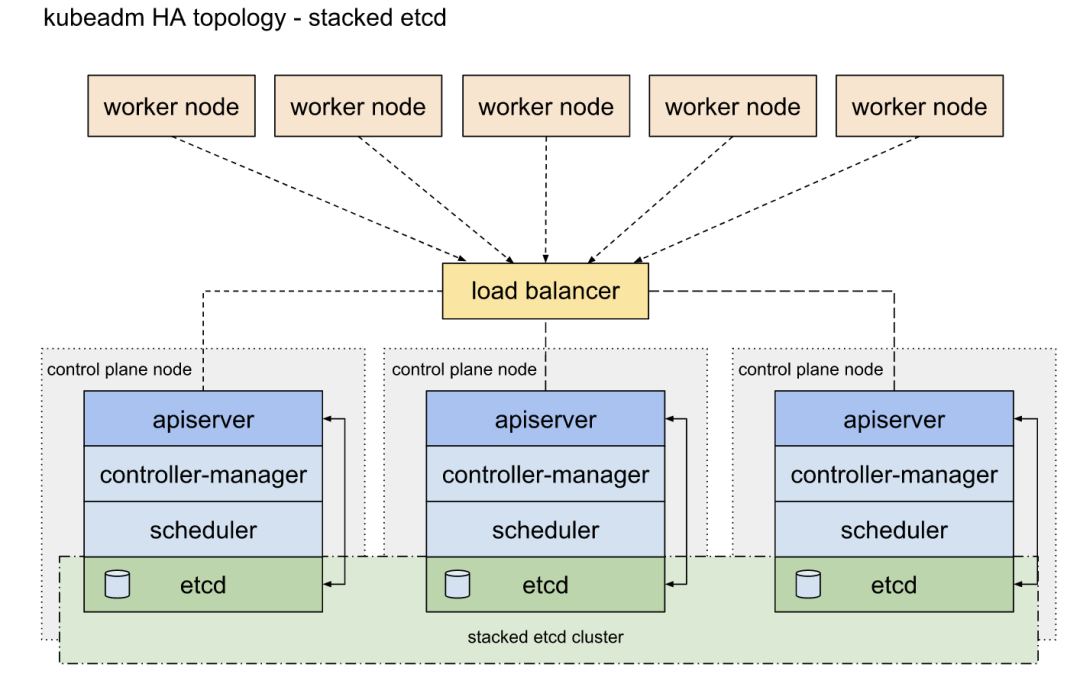
11)集群高可用配置
配置高可用(HA)Kubernetes 集群实现的两种方案:
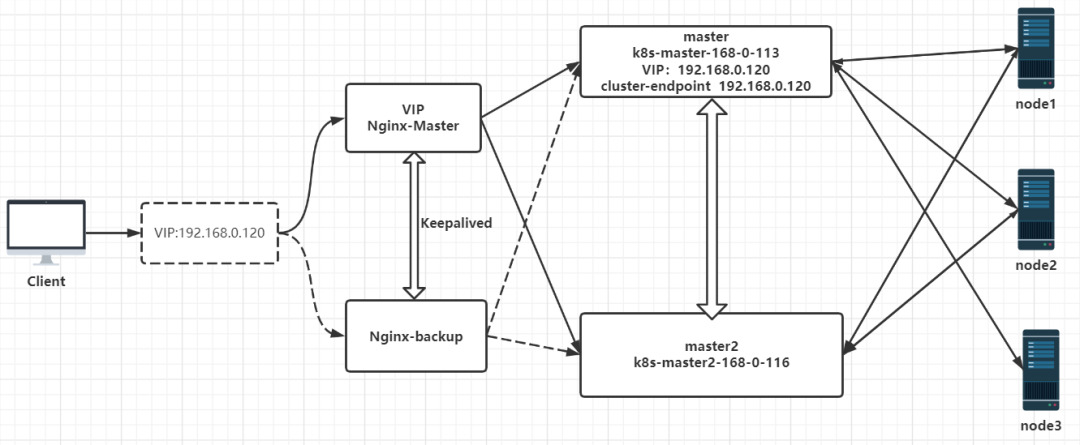
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存(本章使用),架构图如下:
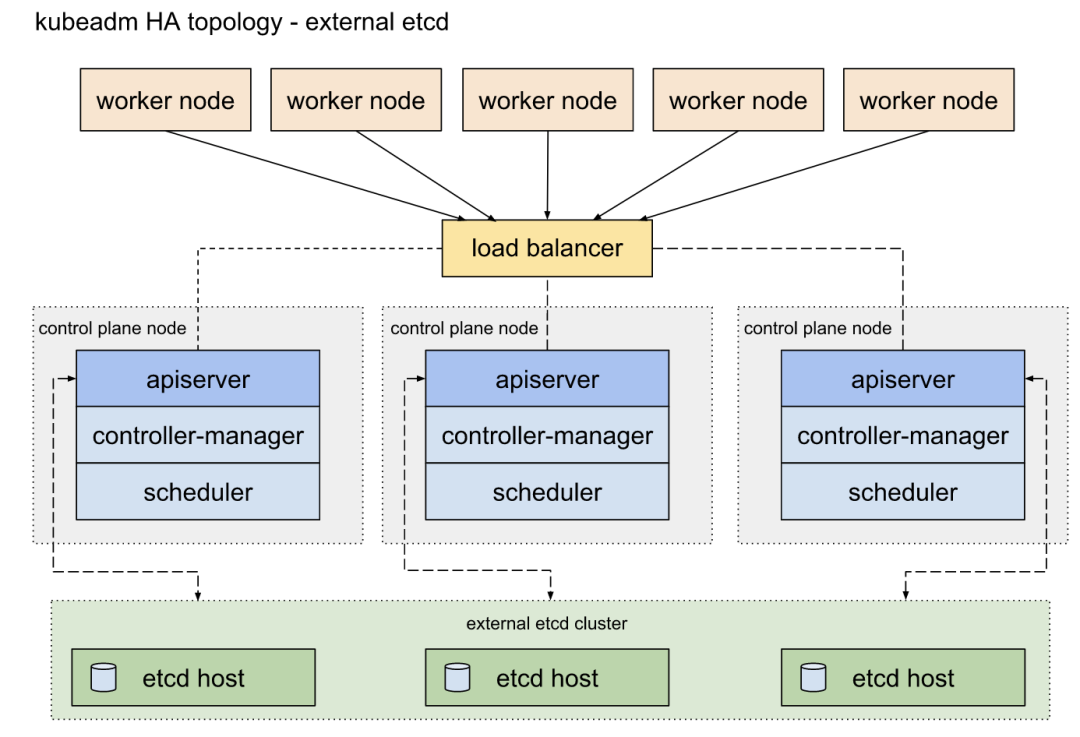
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行,架构图如下:
这里新增一台机器作为另外一个 master 节点:192.168.0.116 配置跟上面 master 节点一样。只是不需要最后一步初始化了。
1、修改主机名和配置 hosts
所有节点都统一如下配置:
# 在192.168.0.113执行
hostnamectl set-hostname k8s-master-168-0-113
# 在192.168.0.114执行
hostnamectl set-hostname k8s-node1-168-0-114
# 在192.168.0.115执行
hostnamectl set-hostname k8s-node2-168-0-115
# 在192.168.0.116执行
hostnamectl set-hostname k8s-master2-168-0-116
配置 hosts
cat >> /etc/hosts<<EOF
192.168.0.113 k8s-master-168-0-113 cluster-endpoint
192.168.0.114 k8s-node1-168-0-114
192.168.0.115 k8s-node2-168-0-115
192.168.0.116 k8s-master2-168-0-116
EOF
2、配置 ssh 互信
# 直接一直回车就行
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-master-168-0-113
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node1-168-0-114
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node2-168-0-115
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-master2-168-0-116
3、时间同步
yum install chrony -y
systemctl start chronyd
systemctl enable chronyd
chronyc sources
7、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
4、关闭 swap
# 临时关闭;关闭swap主要是为了性能考虑
swapoff -a
# 可以通过这个命令查看swap是否关闭了
free
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
5、禁用 SELinux
# 临时关闭
setenforce 0
# 永久禁用
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
6、允许 iptables 检查桥接流量(可选,所有节点)
若要显式加载此模块,请运行 sudo modprobe br_netfilter,通过运行 lsmod | grep br_netfilter 来验证 br_netfilter 模块是否已加载,
sudo modprobe br_netfilter
lsmod | grep br_netfilter
为了让 Linux 节点的 iptables 能够正确查看桥接流量,请确认 sysctl 配置中的 net.bridge.bridge-nf-call-iptables 设置为 1。例如:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
7、安装容器 docker(所有节点)
提示:v1.24 之前的 Kubernetes 版本包括与 Docker Engine 的直接集成,使用名为 dockershim 的组件。这种特殊的直接整合不再是 Kubernetes 的一部分 (这次删除被作为 v1.20 发行版本的一部分宣布)。你可以阅读检查 Dockershim 弃用是否会影响你 以了解此删除可能会如何影响你。要了解如何使用 dockershim 进行迁移,请参阅从 dockershim 迁移。
# 配置yum源
cd /etc/yum.repos.d ; mkdir bak; mv CentOS-Linux-* bak/
# centos7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# centos8
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 设置yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动
systemctl start docker
# 开机自启
systemctl enable docker
# 查看版本号
docker --version
# 查看版本具体信息
docker version
# Docker镜像源设置
# 修改文件 /etc/docker/daemon.json,没有这个文件就创建
# 添加以下内容后,重启docker服务:
cat >/etc/docker/daemon.json<<EOF
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
EOF
# 加载
systemctl reload docker
# 查看
systemctl status docker containerd
【温馨提示】dockerd 实际真实调用的还是 containerd 的 api 接口,containerd 是 dockerd 和 runC 之间的一个中间交流组件。所以启动 docker 服务的时候,也会启动 containerd 服务的。
8、配置 k8s yum 源(所有节点)
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
EOF
9、将 sandbox_image 镜像源设置为阿里云 google_containers 镜像源(所有节点)
# 导出默认配置,config.toml这个文件默认是不存在的
containerd config default > /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
sed -i "s#k8s.gcr.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
10、配置 containerd cgroup 驱动程序 systemd
kubernets 自v 1.24.0 后,就不再使用 docker.shim,替换采用 containerd 作为容器运行时端点。因此需要安装 containerd(在 docker 的基础下安装),上面安装 docker 的时候就自动安装了 containerd 了。这里的 docker 只是作为客户端而已。容器引擎还是 containerd。
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
# 应用所有更改后,重新启动containerd
systemctl restart containerd
11、开始安装 kubeadm,kubelet 和 kubectl(master 节点)
# 不指定版本就是最新版本,当前最新版就是1.24.1
yum install -y kubelet-1.24.1 kubeadm-1.24.1 kubectl-1.24.1 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
# 查看状态,这里需要等待一段时间再查看服务状态,启动会有点慢
systemctl status kubelet
# 查看版本
kubectl version
yum info kubeadm
12、加入 k8s 集群
# 证如果过期了,可以使用下面命令生成新证书上传,这里会打印出certificate key,后面会用到
kubeadm init phase upload-certs --upload-certs
# 你还可以在 【init】期间指定自定义的 --certificate-key,以后可以由 join 使用。 要生成这样的密钥,可以使用以下命令(这里不执行,就用上面那个自命令就可以了):
kubeadm certs certificate-key
kubeadm token create --print-join-command
kubeadm join cluster-endpoint:6443 --token wswrfw.fc81au4yvy6ovmhh --discovery-token-ca-cert-hash sha256:43a3924c25104d4393462105639f6a02b8ce284728775ef9f9c30eed8e0abc0f --control-plane --certificate-key 8d2709697403b74e35d05a420bd2c19fd8c11914eb45f2ff22937b245bed5b68
# --control-plane 标志通知 kubeadm join 创建一个新的控制平面。加入master必须加这个标记
# --certificate-key ... 将导致从集群中的 kubeadm-certs Secret 下载控制平面证书并使用给定的密钥进行解密。这里的值就是上面这个命令(kubeadm init phase upload-certs --upload-certs)打印出的key。
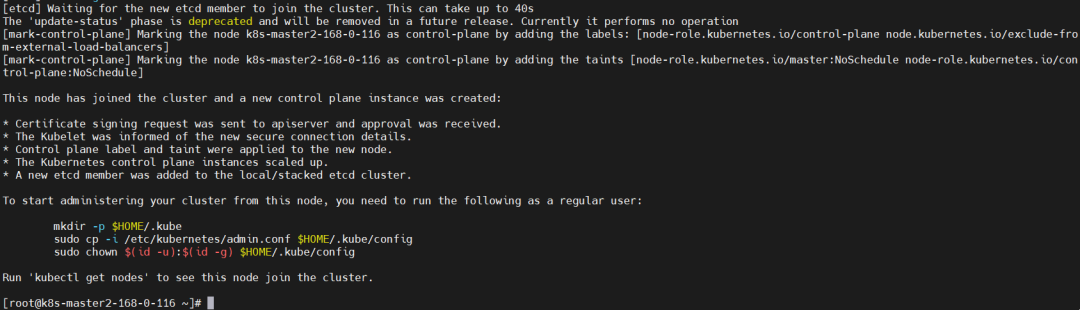
根据提示执行如下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
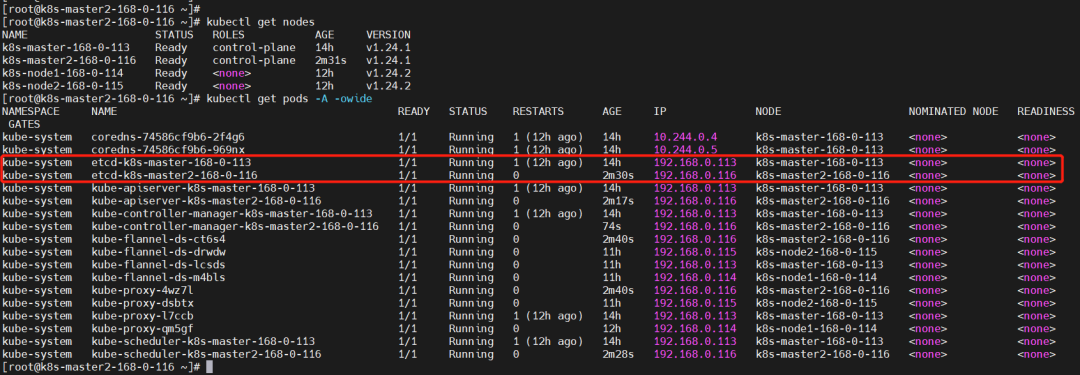
查看
kubectl get nodes
kubectl get pods -A -owide
虽然现在已经有两个 master 了,但是对外还是只能有一个入口的,所以还得要一个负载均衡器,如果一个 master 挂了,会自动切到另外一个 master 节点。
12)部署 Nginx+Keepalived 高可用负载均衡器
1、安装 Nginx 和 Keepalived
# 在两个master节点上执行
yum install nginx keepalived -y
2、Nginx 配置
在两个 master 节点配置
cat > /etc/nginx/nginx.conf << "EOF"
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
# Master APISERVER IP:PORT
server 192.168.0.113:6443;
# Master2 APISERVER IP:PORT
server 192.168.0.116:6443;
}
server {
listen 16443;
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}
EOF
【温馨提示】如果只保证高可用,不配置 k8s-apiserver 负载均衡的话,可以不装 nginx,但是最好还是配置一下 k8s-apiserver 负载均衡。
3、Keepalived 配置(master)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from fage@qq.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.0.120/24
}
track_script {
check_nginx
}
}
EOF
vrrp_script:指定检查 nginx 工作状态脚本(根据 nginx 状态判断是否故障转移)virtual_ipaddress:虚拟 IP(VIP)
检查 nginx 状态脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
4、Keepalived 配置(backup)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from fage@qq.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.120/24
}
track_script {
check_nginx
}
}
EOF
检查 nginx 状态脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
5、启动并设置开机启动
systemctl daemon-reload
systemctl restart nginx && systemctl enable nginx && systemctl status nginx
systemctl restart keepalived && systemctl enable keepalived && systemctl status keepalived
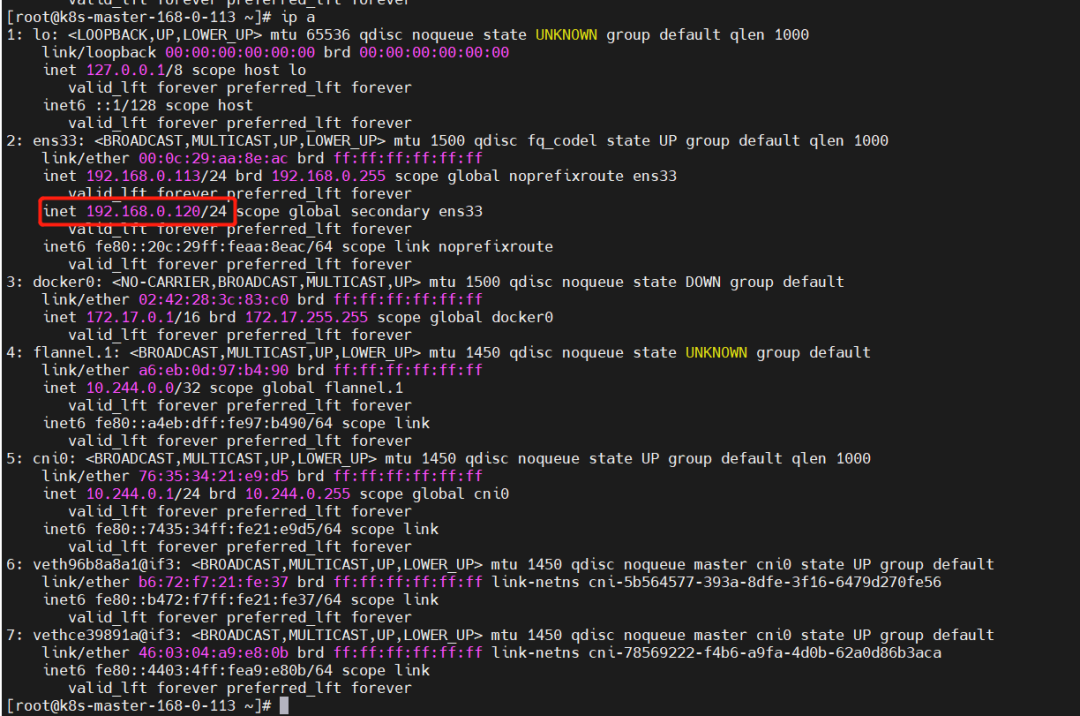
查看 VIP
ip a
6、修改 hosts(所有节点)
将 cluster-endpoint 之前执行的 ip 修改执行现在的 VIP
192.168.0.113 k8s-master-168-0-113
192.168.0.114 k8s-node1-168-0-114
192.168.0.115 k8s-node2-168-0-115
192.168.0.116 k8s-master2-168-0-116
192.168.0.120 cluster-endpoint
7、测试验证
查看版本(负载均衡测试验证)
curl -k https://cluster-endpoint:16443/version
高可用测试验证,将 k8s-master-168-0-113 节点关机
shutdown -h now
curl -k https://cluster-endpoint:16443/version
kubectl get nodes -A
kubectl get pods -A
【温馨提示】堆叠集群存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和控制平面实例都将丢失, 并且冗余会受到影响。你可以通过添加更多控制平面节点来降低此风险。