搭建Soap webservice api接口测试案例系统
Eclipse下创建WebService项目,主要目的是作为Postman、soapUI等工具进行soap webservice 接口测试的案例。
本文基于Axis2框架,在eclipse环境下搭建webservice项目,以用于后期使用SoapUI进行webservice接口测试。
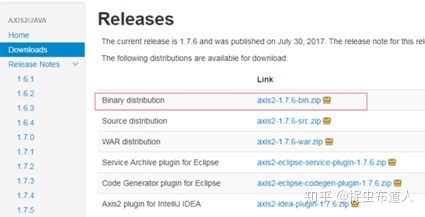
1、下载Axis2框架
在官网http://axis.apache.org/axis2/java/core/download.html下载web service框架Axis2,这是Apache的一个子项目,注意下载的版本,最好和jdk版本匹配,JDK1.8需要下载1.7.x版本的。
2、在eclipse中集成Axis2框架
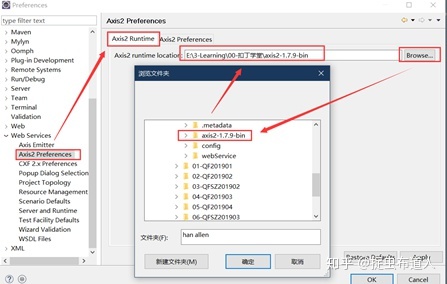
打开eclipse软件,选择一个工程目录:webservice,然后window->preferences->Web Services->Axis2 Preferences,在其中加载解压后的axis文件夹。
3、创建web项目,并提供对外访问的java类和方法
File->New->Project->web,选择Dynamic Web Project,点击下一步:
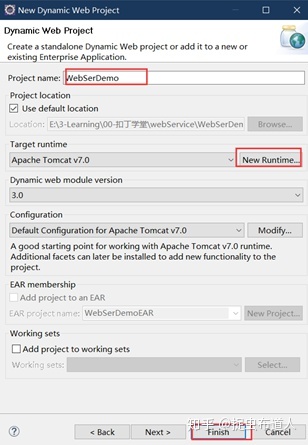
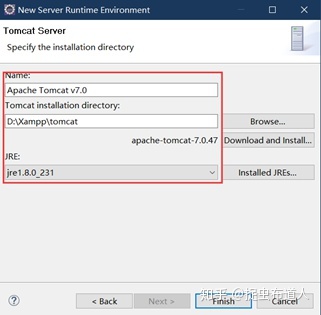
其中NewRuntime,需要配置Tomcat,如果已经安装过,只需要在此处设置安装目录即可,如果jre是1.8_xxx,选择tomcat7版本。
完成上面配置,直接点击Finish按钮,完成项目创建。生成的工程目录如下:
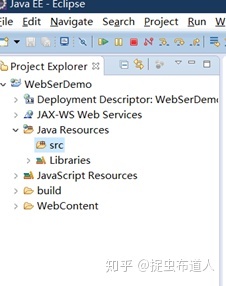
再在Java Resources->src下创建包:com.qf,在包下创建一个类:FirstDemo.java
其中实现如下类和方法的创建:
package com.qf;
import java.util.ArrayList;
public FirstDemo {
//创建第一个对外开放的接口方法
//获取姓名接口
public String getName(String name){
if(name == null || name.equals("null") || name.equals("")){
name = "there is no this name!!";
return name;
}
System.out.println("姓名是:"+name);
return "welcome "+name+" , to QIANFENG testing.";
}
//获取姓名列表接口
public String getNameList(){
ArrayList al = new ArrayList();
al.add("allen");
al.add("petter");
al.add("Lucy");
System.out.println(al.toString());
return al.toString();
}
//获取加法运算结果接口
public int sum(int a, int b){
return a+b;
}
}4、选择项目的web service
鼠标右键New->Other->Web Service->Web Service选中,点击next。

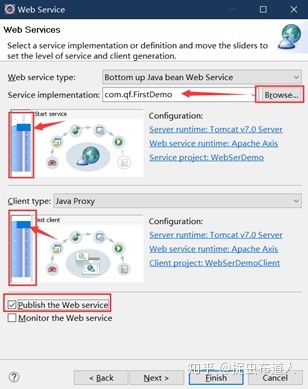
按照下面页面进行设置,其中需要点击Browser选择刚创建的java文件,点击下一步。
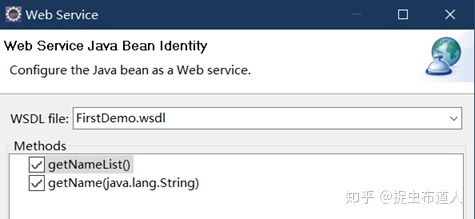
选择对外开放的接口方法,点击下一步:
点击页面的Start server,启动Tomcat服务(注意端口问题,默认是8080端口,若有占用此端口的需要关闭其再试)
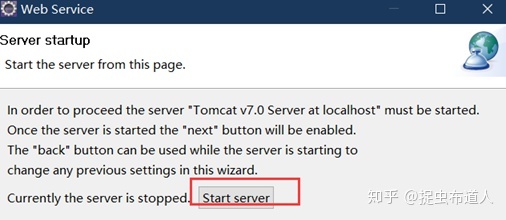
启动Tomcat服务成功后,改按钮会置灰,Eclipse控制台会显示tomcat启动日志,并处于服务状态,点击该页面的Finish完成配置。
在弹出的页面中如图设置,验证通过,则web service服务搭建成功。
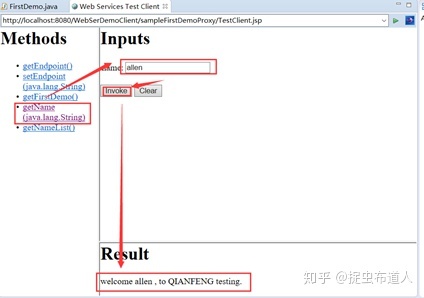
5、查看wsdl文件
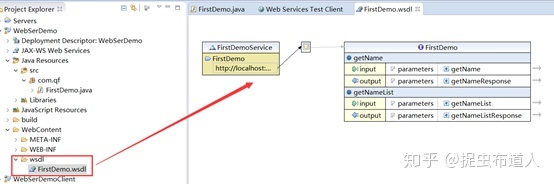
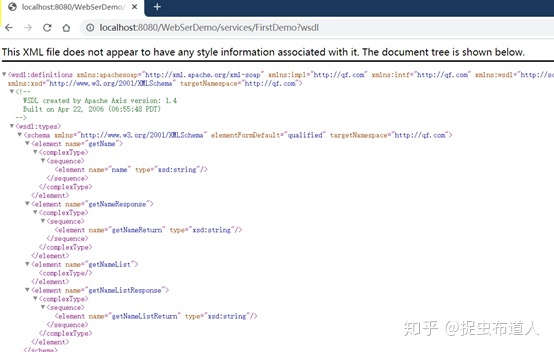
通过xml文件打开,可以找到该服务提供的接口地址,末尾拼接wsdl :http://localhost:8080/WebSerDemo/services/FirstDemo?wsdl

复制该地址到浏览器中,可以查看xml格式的内容:
在浏览器中输入:http://localhost:8080/WebSerDemo/services,点击图示按钮,也可以打开上文的wsdl文件。
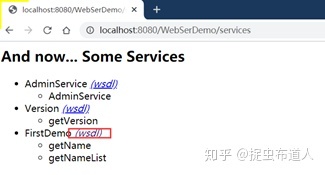
记住这个地址:http://localhost:8080/WebSerDemo/services/FirstDemo?wsdl





![20160408_uOmp[1].jpg](http://images.wenmo8.com/blog/typecho/20160408_uOmp[1].jpg)
![20160408_L3I4[1].jpg](http://images.wenmo8.com/blog/typecho/20160408_L3I4[1].jpg)
![20160408_wJFl[1].jpg](http://images.wenmo8.com/blog/typecho/20160408_wJFl[1].jpg)
![20160408_gHuN[1].jpg](http://images.wenmo8.com/blog/typecho/20160408_gHuN[1].jpg)