软件调试的技术和方法
调试的关键在于推断程序内部的错误位置及原因,可以采用以下方法:
1、分析和推理
设计人员和开发人员根据软件缺陷问题的信息, 分析和推理调试软件。
(1)根据软件程序架构自顶向下缩小定位范围, 确定可能发生问题的软件组件。
(2)根据软件功能,软件运行时序定位软件问题。
(3)根据算法原理,分析和确定缺陷问题发生的 根源。
2、归纳类比法
归纳法是一种从特殊推断一般的系统化思考方法,归纳法调试的基本思想是:从一些线索(错误征兆)着手,通过分析它们之间的关系来找出错误。该方法主要是根据积累的工作经验和案例处理调试工作。
(1)根据工作经验和比对程序设计中类似问题的 处理方式进行调试工作。
(2)咨询相关部门和有经验的相关人员。
(3)查找相关文档和案例,为处理问题提供思路 和方法。 在软件开发过程中,通常对每个缺陷问 题进行跟踪管理,将解决问题的方案和过程详细记录。
(4)收集出错的信息,列出数据,包括输入,输出,归纳整理,发现规律,从线索除法,寻找线索之间的联系。也就意味着:从特殊到一般。归纳调试的步骤可以概括为以下一个图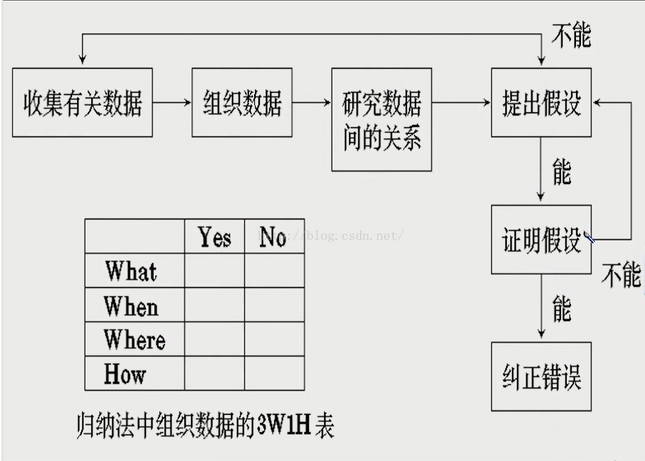
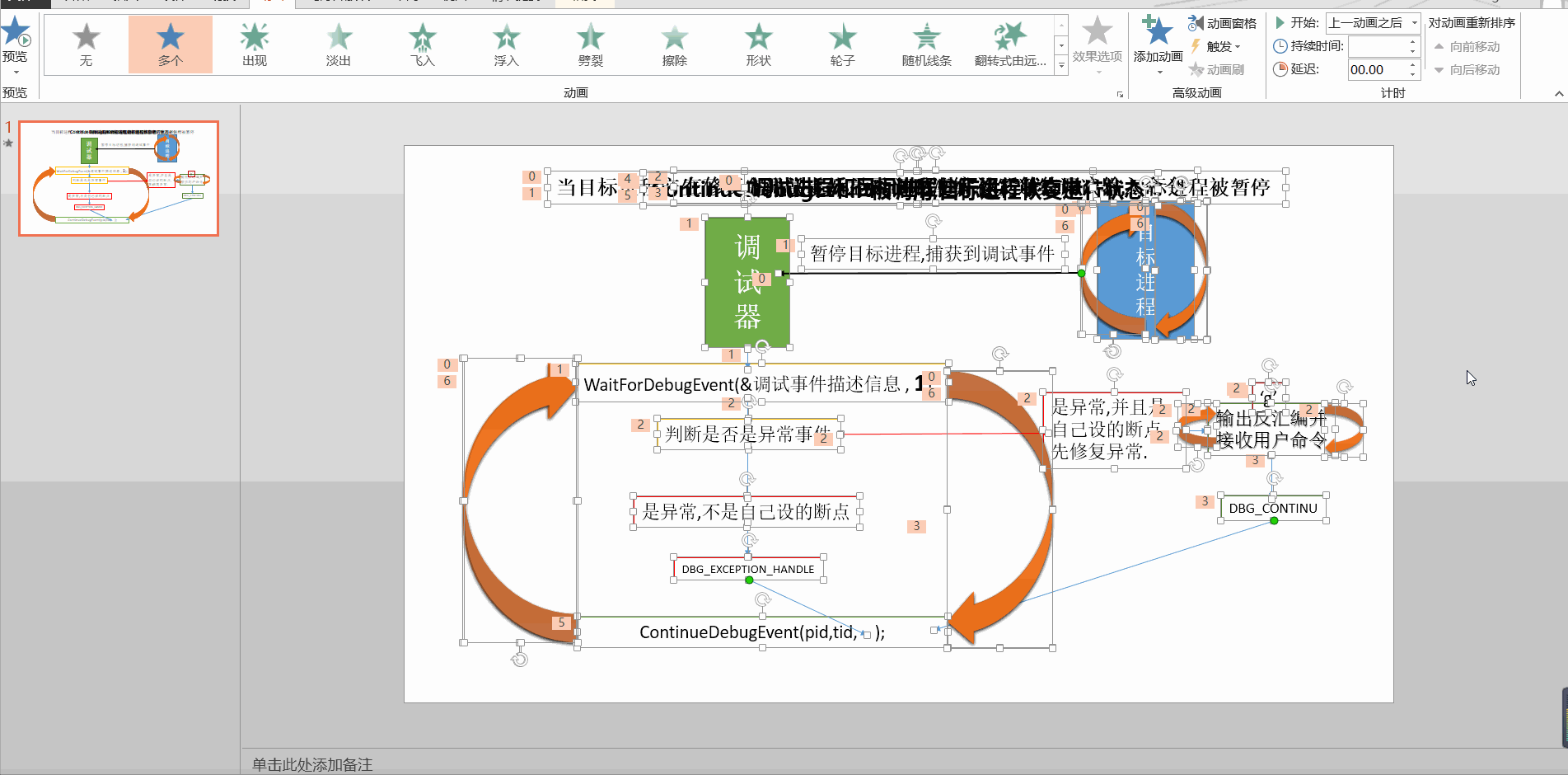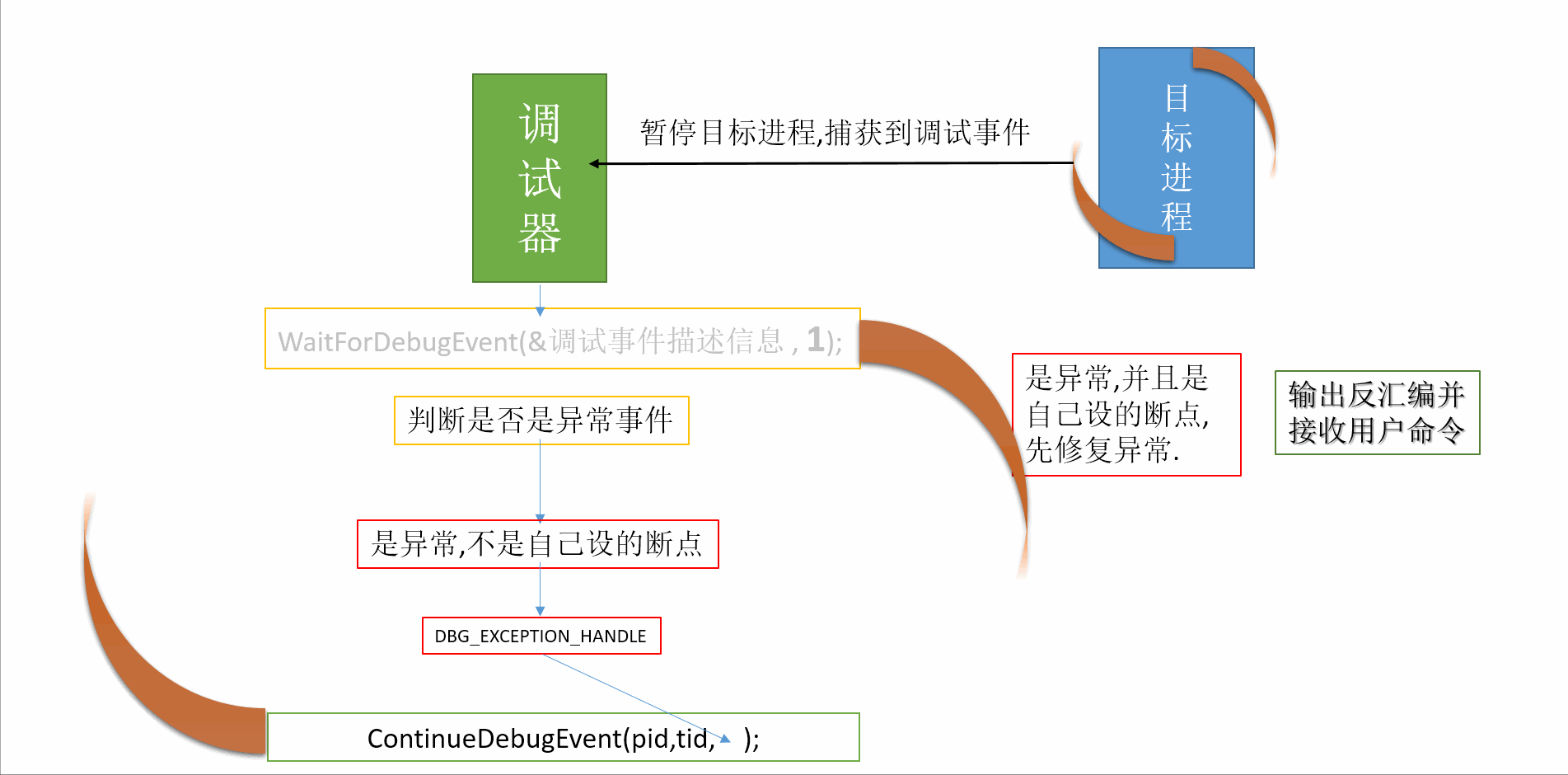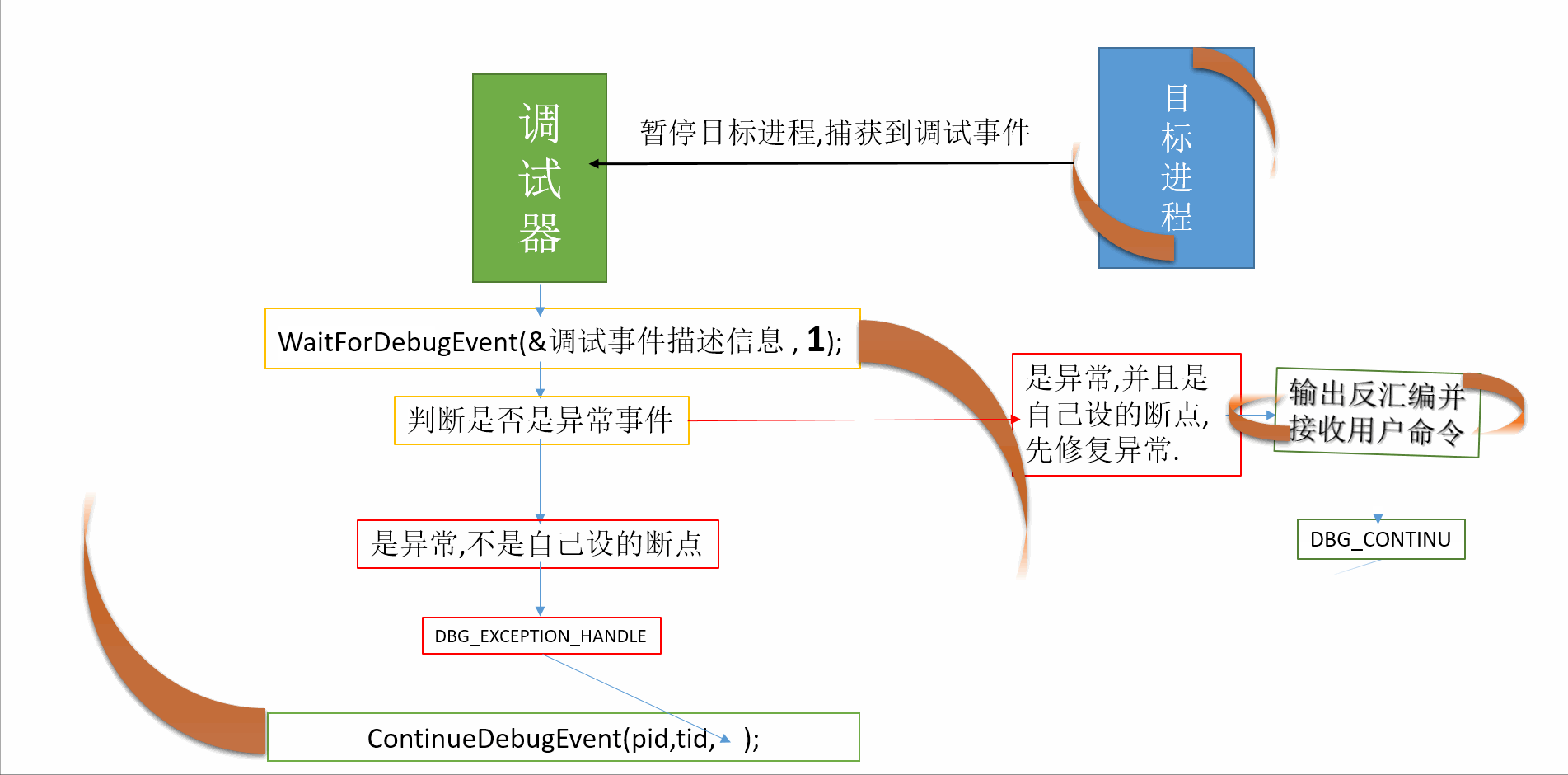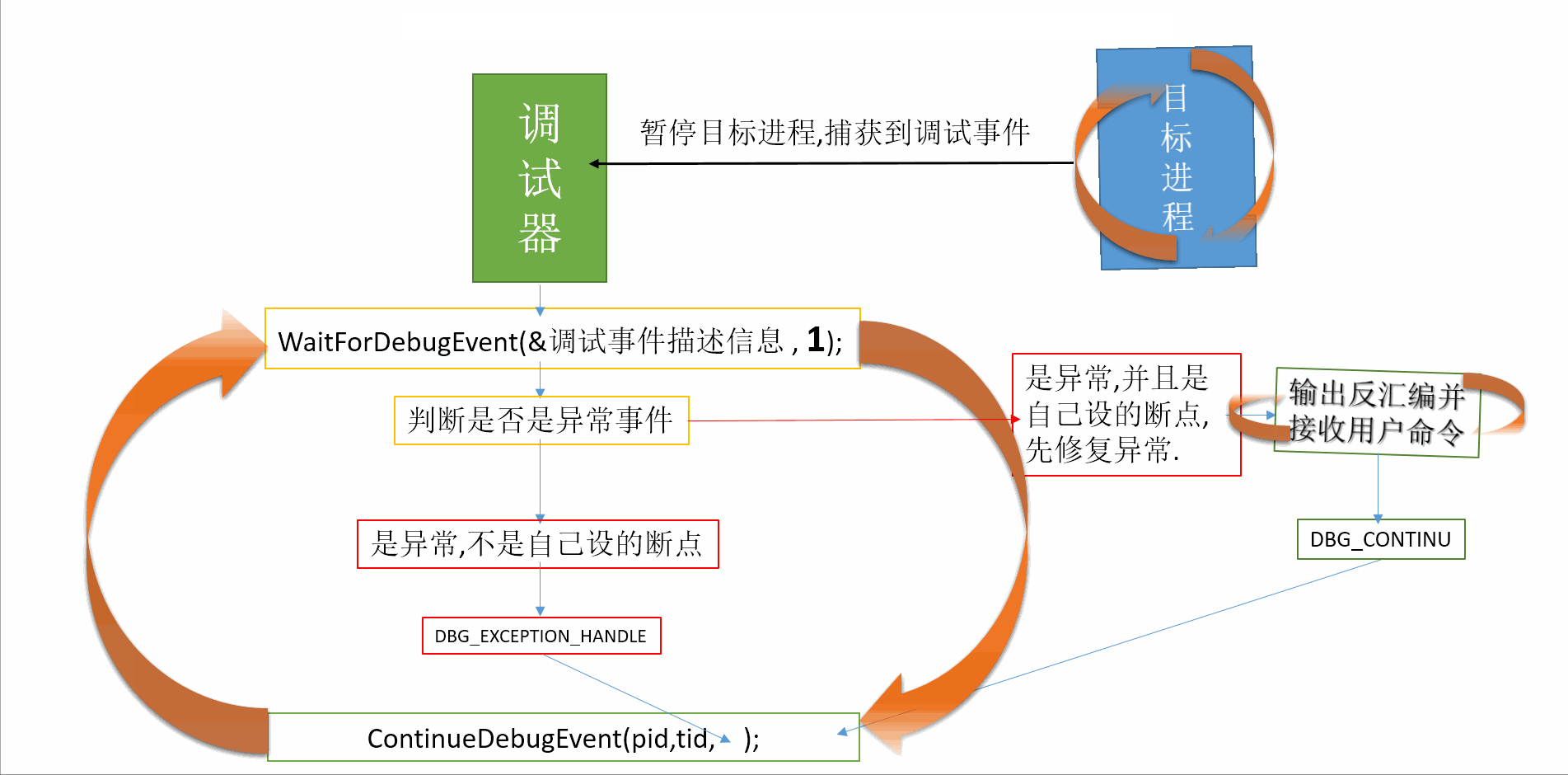
3、跟踪回朔
在小程序中常用的一种有效的调试方法,一旦发现了错误,人们先分析错误的征兆,确定最先发现“症状“的位置然后,人工沿程序的控制流程,向回追踪源程序代码,直到找到错误根源或确定错误产生的范围,例如,程序中发现错误处是某个打印语句,通过输出值可推断程序在这一点上变量的值,再从这一点出发,回溯程序的执行过程,反复思考:“如果程序在这一点上的状态(变量的值)是这样,那么程序在上一点的状态一定是这样···“直到找到错误所在。
在软件开发通常采用基线与版本管理。 基线为 程序代码开发提供统一的开发基点,基线的建立有助 于分清楚各个阶段存在的问题,便于对缺陷问题定位。 软件版本在软件产品的开发过程中生成了一个版本 树。 软件产品实际上是某个软件版本,新产品的开发 通常是在某个软件版本的基础上进行开发。
(1)开发过程中发现有问题,可以回退至版本树上的稳定版本,查找问题根源。
(2)通过基线版本序列可以追踪产品的各种问 题,可以重新建立基于某个版本的配置,可以重现软件 开发过程中的软件缺陷和各种问题,进行定位并查找 问题根源。
4、增量调试
软件开发大多采用软件配置管理和持续集成 技术。 开发人员每天将评代码提交到版本库。 持续集 成人员完成集成构建工作。 可以通过控制持续集成的 粒度(构建时间间隔),控制开发人员提交到版本库的 程序代码量,从而便于对缺陷问题定位。 通常每天晚 上进行持续集成工作,发现问题时,开发人员实际上只需要调试处理当天编写的代码。
5、写出能重现问题的最短代码
采用程序切片和插桩技术写出能重现问题的最短 代码调试软件模块。
(1)程序切片
程序切片是通过在特定位置消除那些不影响表达 式计算的所有语句,把程序减少到最小化形式,并仍能 产生给定的行为。 使用切片技术,可以把一个规模较 大并且较复杂的软件模块转换成多个切片程序。 这些 切片程序相对原来的程序,简单并且易于调试和测试。
(2)程序插桩
程序插桩方法是在被测程序中插入某些语句或者 程序段来获取各种信息。 通过这些信息进一步了解执 行过程中程序的一些动态特性。 一个软件组件的独立 调试和测试需要采用插桩技术,该组件调用或运行需 要桩模块。 在软件模块的调试过程中程序切片和程序插桩可 以结合起来使用。
6、日志追踪技术
日志是一种记录机制,软件模块持续集成构建过 程中,日志文件记录了有用信息。 若构建失败,通过查 看日志文件,将信息反馈给相关人员进行软件调试。
7、调试和测试融合的技术
(1)测试驱动开发
测试驱动开发是一种不同于传统软件开发流程的 开发方法。 在编写某个功能的代码之前先编写测试代 码,然后编写测试通过的功能代码,这有助于编写简洁 可用和高质量的代码。
(2)开发与测试融合
程序开发人员除了进行程序代码的编写,白盒测 试,也要完成基本的功能测试设计和执行。 这样有助 于程序开发人员更好地开展调试工作。 程序开发人员 可以通过交叉测试来解决测试心理学的问题(不能自 己测试自己)。 采用这种模式测试人员的数量会减少,专业的测 试人员去做其他复杂的测试工作。 研发中的很多低级 缺陷会尽早在开发过程中被发现,从而减少缺陷后期 发现的成本。
8、强行排错
这种调试方法目前使用较多,效率较低,它不需要过多的思考,比较省脑筋。例如:
(1)通过内存全部打印来调试,在这大量的数据中寻找出错的位置。
(2)在程序特定位置设置打印语句,把打印语句插在出错的源程序的各个关键变量改变部位,重要分支部位,子程序调用部位,跟踪程序的执行,监视重要变量的变化
(3)自动调用工具,利用某些程序语言的调试功能或专门的交互式调试工具,分析程序的动态过程,而不必修改程序。
应用以上任一种方法之前,都应当对错误的征兆进行全面彻底的分析,得出对出错位置及错误性质的推测,再使用一种适当的调试方法来检验推测的正确性。
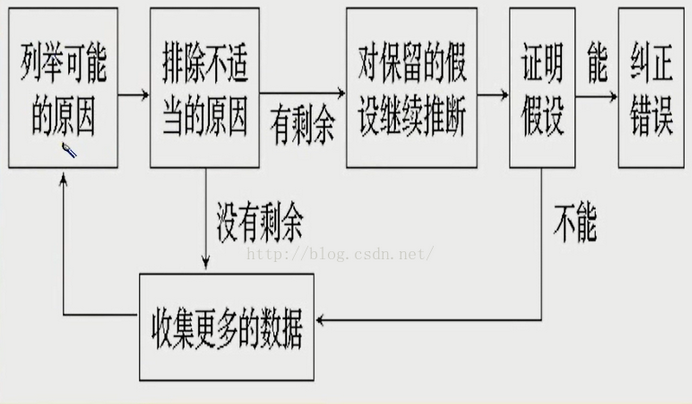
9、演绎法调试
演绎法是一种从一般原理或前提出发,经过排除和精华的过程来推导出结论的思考方法,演绎法排错是测试人员首先根据已有的测试用例,设想及枚举出所有可能出错的原因作为假设,然后再用原始测试数据或新的测试,从中逐个排除不可能正确的假设,最后,再用测试数据验证余下的假设确是出错的原因。
(1) 列举所有可能出错原因的假设,把所有可能的错误原因列成表,通过它们,可以组织,分析现有数据
(2) 利用已有的测试数据,排除不正确的假设
仔细分析已有的数据,寻找矛盾,力求排除前一步列出所有原因,如果所有原因都被排除了,则需要补充一些数据(测试用例),以建立新的假设。
(3)改进余下的假设
利用已知的线索,进一步改进余下的假设,使之更具体化,以便可以精确地确定出错位置
(4)证明余下的假设