他山之石:软件调试的方法与技巧
软件 的调试 也称纠错或排错 , 它是孤立并纠正错误的一种技巧性过程 。 软件错误的外部表现形式与内部 原 因之间往往没有 明显 的联系 , 所 出现的差错并非直接就能找 出原 因 。 因此 , 调试 既要对 错误 的性 质及 程序 本身进 行系统的研 究 , 在某种程 度上也要靠直觉与经验 。 到 目前为止 , 调试还 没有 一套经 得起检验 的完 整而 系统 的理论方法 , 排错时所采用的方法和时 间都不能事先确定 . 这样 , 通常认为调试是 困难的 , 是软件开发过 程 中最为艰 巨 的一种脑力劳动 。 本文拟就 调试的方法 、 技术与技 巧进行探讨 .
调试的步骤
诊断错误
或是 系统报 错 , 或是输 出结果与设 想的不 同 , 或是 陷入死循环等 , 都认为程序存在错误 .
确定错误的源发点
发现错 误的地方不一定是错误的源发点 , 应寻找所有与错误有关 的地方 , 从而确定错误的源发点 。 例如程序 :
1 0 F O R I= 1 T O 1 0
20 R E A D A ( I )
30 N E X T I
4 0 D A T A 15 , 1 6 , 2 5 , 27 , 2 8
R U N
O U T O F D A T A 1 N 2 0
错误发生于 2 0 行 , 但与第 4 0 行有关。
改正错误
确定错误及 位置后 , 针对错误 的具 体类 型进行改正 。 在纠错过程 的两方面即确定错误及位置和改 正错误 中 , 第一方面 的工作大 约相当于整个工作的 9 5 % , 为 排 错的关键 。 故本文重点探讨错误的诊断方法与技巧 。
诊断 错误的实验方法
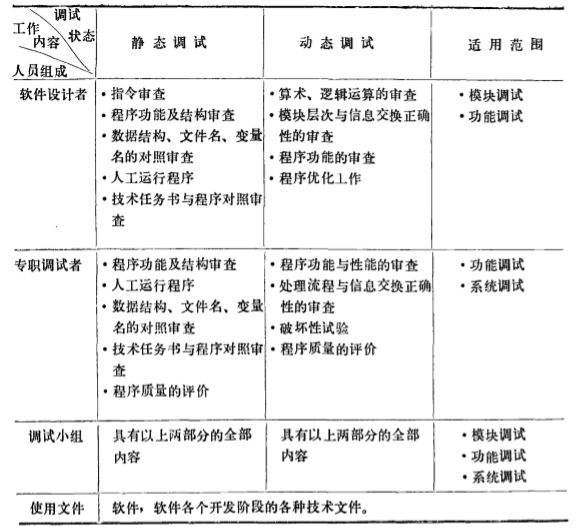
静态调试
静态调试指对程序进行人工书面检查。 静态调试时要仔细阅读程序及其文档 , 经过结构分析 、 功能分析 、 逻辑 分析 、 接 口 分析 、 语 法分析以 及逐行检查 , 以 便找出并改正错误 。 通常 有下 面两种方法 。
- 检查语法错误
产生语 法错误 的原因 主要有两 个 , 一个是 键入错误 , 此错误如 同写文章 时的“ 笔误” ; 二是 由于对语法规则 不熟悉 , 如书后的错误 信息 、 各种限制 、 全局变量与局 部变量 、 先左后右 的原则等 , 这些 虽不是 系统的规定 , 但也是语法的一部分 , 应作为专项予 以检 查。 - 跟踪程序流程
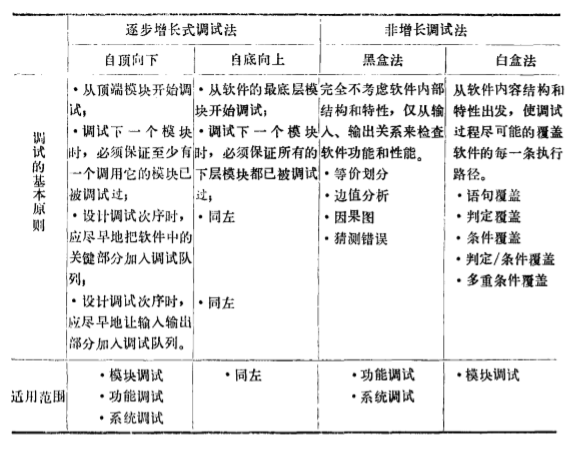
此时的跟踪程序 流程 , 即将 自己 当做计算机 , 给 定一 组输 入数据后 , 顺序执行每 条语句 , 考察所得结果 . 寻 找错误 . 此方法需 花一定时间 , 但这是 最基本的方法 , 用 其它方法难 以查 出问题时 . 可以试 用此法 。 顺便说一句 , 学习编 程技术的主要途径是读 别人的 程序 , 对 较难懂的地方 , 也只 有跟踪程序才能读懂 , 也 就是常说的阅读能力提高 的途径 。 对程序 的流程图也可采取此方法检查 。 一般提倡应尽可能将 各种错误 消灭在静 态调试 阶段 。
动态调试
动态调试 , 是指实际 上机运行程序进行调试 . 经过静态调试 后 , 仍 留在程序中的错误便都十分隐蔽。 为找 到这些错误 , 首先需捕 获一些与错误有关的线索 . 即进行错误侦察 , 此时需充分利 用计算机系统提供的调试手段。
- 试通
源程序上机 运行 , 语 言系统及操 作系统会在程序有故 障时给出信息 , 这些 信息反映 了如下几种故障情况 :
①没 有通过 编译 对解释型的高级语言来说 , 如 B A S I C 语言 , 程 序出现语法错误 , 系统便使程序在出错点 中断 , 并指 出错误 的类型 和 位置。 对 编译 型的高能 语言 , 如 P A S C A L 语言程序 , 编 译系统把程序检查一遍后 , 对语法错误会打 印 出一系列的出错 信息 , 根据这些语法出错信息号 , 可在“ 用 户手册 ” 中查 出原因 。
②没有通过连 接编辑 连接编 辑阶段的 错误有 : 公 共数据块长度不一致 , 系统 自动按最长 处理 , 但给 出警 告 ; 某个模块名找不到 所需要 的模块 , 如 数据说 明遗漏 , 连接数组元素引用 当函数引用 , 库函数引用 不符合规格说 明; 内存容量 不够 而需要分节等 。 这些 错误 可参照 “ 用 户手 册 ” 予以改正 。
③程序的运行过 程因故障而停止 程序因故障而 停止运 行 , 在多数情 况下会给出出错信 息 , 这类信息在“ 用户手册 ” 中都有解释 。
④程序只 输出部 分结果 对这 部分结果进行分析 , 可大致 了解程序被执行的逻辑 , 或程序在什么地方被中断 。
⑤程序执行 了很 长时间没有结果 这种情况可能 由三个原因造成 : 一是程序本来执行 时间就 很长 ; 二是程序 内有死循环 ; 三是程序运行时使 硬 件系统“ 死锁” 。 - 调试工具
错误的位置可以 通 过在程序 中插入调试 语句 , 也可 以使用机 器提供的调试工 具在程序 中的某一点将有 关数据单元的内容或程序 的执 行路径输 出。 不 同的操 作系统或编译程序提供 不同的调 试工 具 。 调试软件一般 有两 种 , 一种是 交互式调 试程序 , 它 使得 程序员和 执行 中的用 户软件 在联 机方式下相 互作用 , 提 供了中断程 序 、 在程序中设置断点 、 显示并改变符 号项 中的变量 、 逐语句的执行程序等特性 。 如 B I M 公司为 P L l / 的 C C ; D E C 公司为 CO B O L 配的 C ID 等 。 另一种是 程序 语言所提 供 的调 试特性 对语言 的 扩充 。 如 P L l / 提 供了 c H E c K 语句 , F O R T R A N 提供 了作为注释或在编译时 作为正 式语 句解释 的特性等 。 此外 , 为了调 试程序 , 常 常使用操 作系统提供的某些实用软件 , 例如文件或 内存 的转储 , 两个文件的比 较程序 等 , 或是利用测试得到 的 信息 。 然而 , 最有效 的调 试工具 似乎是写程序时写到程序中的调试语 句 , 这 样 , 出错区域可 由程序员定位。 调 试语句是一些不影响程序的功能 , 仅 给调试人员提供如下 信息的语 句:
✦活动路径
✦统计活动次数
✦其它有关信息
常用的调试 语句有 以下几种 :
①利用系统 提供的调试命令和语句 如在 A P P L E S O F T 中以下命令与语句常 用 , S T O P 语 句使程序暂 停 , 设置断点 ; C O N T 语句使程序从断 点继续执行下去 ; T R A C E 逐个行跟踪 , 即逐 次显示计算机执行的语句行号 , 给 定一 组调试 数据后可以检查程 序是否按预想的路径执行及执行的结果是否 正确 ; N O T R A C E 命令取消逐行跟 踪。 在 F O X B A s E 中 , 程序执 行到 S U S P E N D 时能把正在执行的程序挂起 , R E S U M E 能使被 挂起的程序 从断点处继 续恢复运行 ; S E T E C H O O F F / O N , 默认值 为 O F F , 若设置为 O N , 则将 每一条执行过的命令在屏幕上显示 , 由此可确切地掌握当 前程 序运行 的进程 , 帮助 查 出产 生 间题的 位置 , S E T S T E P O F F /O N , 默认为 O F F , 当为 O N 时 , 程序会以单 步形式进 行等。
②设 置状 态变 量 例 如 , 在 每个 模块中设置一个状态变 量 , 程序进入该 模块时 , 便给该 状态变量一 个特殊值 , 根 据各状态变 量 的值 , 可以判定程序活动的大致路径 。
③设置计数器 在每个模块或基本 结构中 , 设置 一个计数器 , 程序 每进入该结构一次 , 便计数一 次。 这样 , 不仅 可以判断 出程序活动的路径 , 而且 当程序中有死循环时 , 用此方法便能很快确定 .
④插入打印语句
打印语句是最 常用的一种调试语句。 它用起来非常 敏捷 , 能产生许多 有用的信息 . 特 别适用于人机对话 或 调试过程 。 关键是断点的位置和打印哪些变量 的值 。 下面介绍打印语句的几种用法 。
A.回声打印 ( E C H O P R IN T IN G ) “ 回声 ” 打印的特点是“ 读 了就写” 。 它把打印语句放在紧靠读语句之 (或输入语句 )之后 , 或模块入 口 处 , 及 调 用语句之前后 . 可以帮助调试人员检查数据有没有被 正确地翰入或接 口 处信息传递是否正确 。
B. 追踪打印
追踪打印是为提供程序执行的路径信息而设置的打印语 句。 这些打印语句通常设置在下述 位置 : . 模块首部或尾部 . 调用语句前后 . 循环结构 内的第一个语句或最后一个语句 . 紧靠循环结构后面第一个语 句 . 分支点之前 . 分支中的第一个语句
C.抽点打印
抽点打印就是选择一些可疑点设置打印语句 , 以便打印有关变量的值 。
D.成组打印子程序
即集中一组打 印语句写成一个 专用子程序 , 凡是需 要了解情况处就可调用此子程序。 例 : 考 虑到 层、 块结构 的需要 , 可在一层中编写一个打印子程 序。
8 9 9 9 R E M C 层成组打 印子程序
90 0 0 P R I N T “ C $ = ” ; C $ ; “ C C $ = ” ; C C $
9 0 1 0 P R IN T “ C = ” ; C ; “ C C 一 ” ; C C ; “ C l = ” ; C l ; “ C Z = " ; C Z
9 0 20 R E T U R N
可在若干地方调用 此子程序 :
31 4 5 P R IN T “ 检索部分打印” : G O S U B 90 0 0
3 5 6 5 P R IN T “ 分类部分打印” : G O S U B 9 0 0 0
36 7 5 P R I N T “ 求和部分打印” : G O S U B 9 0 0 0
此方法很有用 , 能动态地 了解程序运行情况 。
预埋技术
预埋技术是在程序 中加入“ 潜伏” 的调试语 句。 前面介绍的打印语句和成组打 印子程序 , 在程序完 成后要将 其删去 . 而预埋技术将调试 语句永久地编入程序 , 其是否起作用 由逻辑软 件开头控制 。
例如:
10 IN P U T “ X = ” ; X
20 IF X ( 1 O R X ) = 1 0 T H E N P R IN T “ N O D E F IN I T IO N ”
30 IF X ) = 1 A N D X ( 3 T 圣IE N P R I N T “ Y = ” ; 5一 CO S ( 8 * X )
4 0 IF X ) = 3 A N D X ( 6 T H E N P R I N T “ Y = " ; E X P ( X )
5 0 IF X >= 6 A N D X ( 1 0 T } {E N P R IN T “ Y = ” ; 1+ S Q R ( X 二 1)
60 E N D
在此例中 , 我们只处理了 X e 〔1 , 10 ) 的正常情况 , 但估计到使用 中出现 的变动可能导致 x ( 1 或 x ) 1 0, 提 前将调试语句放 在程序 中。 这样 , 对于任何情况的输入程序都能 适应。 人是健忘 的 , 如果没有这个调试语句 , 将会花费很多时间去查错 。
错误诊断的推理技术
归纳法排错 ( D E B U G G I N G B Y I N D U C T IO N )
其 荃本思想是 逐步减少和改进 假定的过程 。 在查 出错误后 , 要把一切可 能的原 因和假定都提出来 , 利用 错误数据 排除一部分 , 假 定再从其余 假定中估计可能性最大的一个 。 使确 定错误原 因的范围更集 中 , 下一步 或 许就可证明这一改进后的假定 , 或再作其他选择 .

演绎法排错
其基本思 想是枚举所有可能引起 出错的原 因作为假设 , 然后利用数据逐一排除不可能发 生的原 因与假设 , 将 余下的原 因作为主攻方向。 演绎法过程如下 图所示 :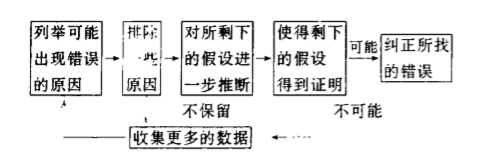
回溯法 ( B A C K T R A C KING)
对于小程序 , 这 种技术极为有用 。 从错误 出现之处 出发 , 沿反 向路径进行检查 , 直到找出错误的原因 。 推理是在取得一 定的实验数据的基础 上进行 的 , 推理 得出的假设 , 要靠实验证 明 并取得 新的数据 , 把搜索 范围缩 小。故错误诊断的 实验方法与推理技术应结合使用 , 互相补充 。
错误修改的原则
不要试着改
不要当只 查到 了一些征兆 , 原 因还没有 查清 , 便想试 着改 动某个语句 。 这 种盲 目行 为成功 的概率很 小 。 因 某些错误征兆 的修改并没有治本 。 有时会把 某些新的错 误掺加到程序 中 , 造 成调试 的混乱 。
修改 了一个错误 , 可能还 会有别的错误
一般错误 是密集 的 , 修改了一个错 误后 , 还应检查它的近邻还有没有别的错误或者在程序 中还有无类似 的错误 。
改变源程序代码 , 不要改变目标代码
当调试一个大 系统 , 特别是用 汇编语 言写的系统纠错时 , 不要直接修改目标代码。 否则 , 当程 序重新编译 或重新汇编时 , 错误 还会再现
修改错误的过程将迫使人们暂时回到设计阶段
修改错误是 程序设计的一个重要 内容和形式 。 一般 说来 , 在设计过程中所使用 的各种方法应 能应 用于错 误修改过程 。
修改完毕 . 需进行 回溯测试
因为 :
- 纠正错 误的概率 不是 10 0 %
- 纠正错误 时产生新错误 的可能性
- 修改代 码比 原有的代码更 易出错