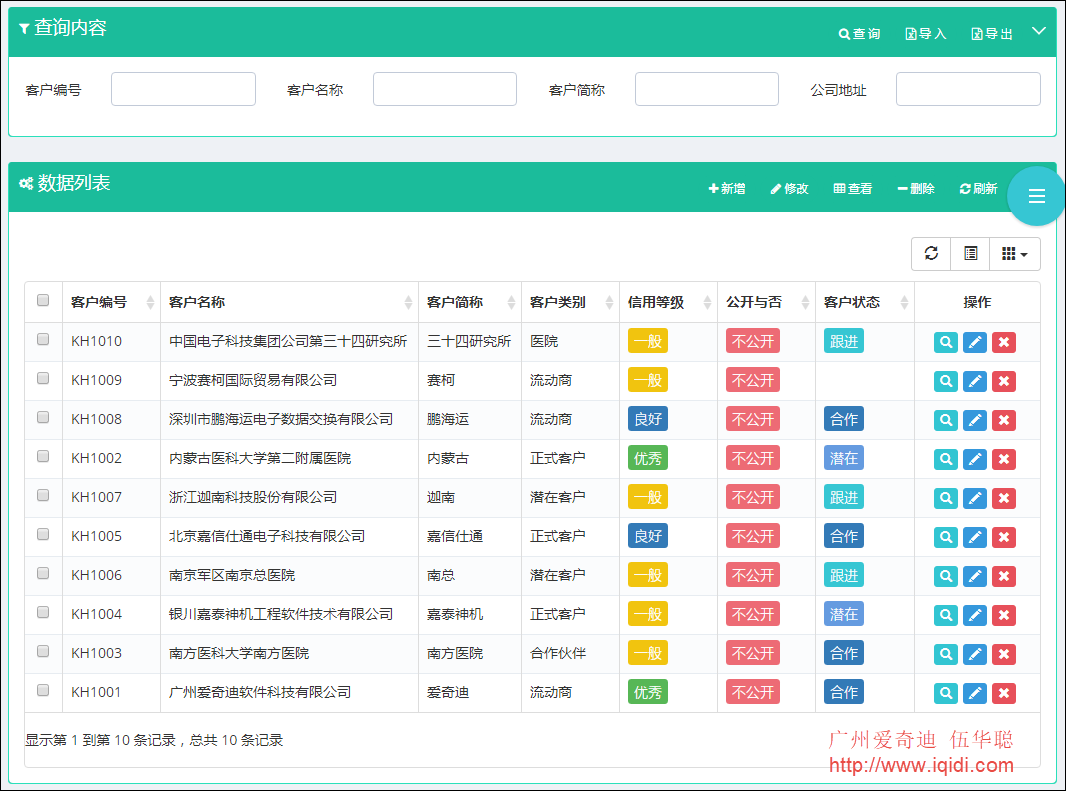
微信小程序豆瓣电影项目的改造过程经验分享
在学习微信小程序开发过程中,一部分的难点是前端逻辑的处理,也就是对前端JS的代码编辑;一部分的难点是前端界面的设计展示;本篇随笔基于一个豆瓣电影接口的小程序开源项目进行重新调整,把其中遇到的相关难点和改进的地方进行讨论介绍,希望给大家提供一个参考的思路,本篇随笔是基于前人小程序的项目基础上进行的改进,因此在开篇之前首先对原作者的辛劳致敬及感谢。
1、豆瓣电影接口的小程序项目情况
豆瓣电影接口提供了很多相关的接口给我们使用,豆瓣电影接口的API地址如下所示:
https://developers.douban.com/wiki/?title=movie_v2

在GitHub的开源库里面,可以搜索到很多关于豆瓣电影接口的小程序,我本篇随笔是基于
weapp-douban-movie
这个小程序进行的改造处理,后来找到了原作者的项目地址:
wechat-weapp-movie
,原作者对版本做了一次升级,后来我对照我的调整和作者最新版本的源码,发现有些地方改造的思路有些类似,如对于URL地址外放到统一的配置文件中的处理,不过还是有很多地方改造不同。
本篇随笔的改造方案是基于小程序项目
weapp-douban-movie
的,因此对比的代码也是和这个进行比较,不知道这个版本是不是原作者的旧版本,不过这个版本对文件目录的区分已经显得非常干净利落了,对电影信息的展示也统一到了模板里面,进行多次的重复利用,整体的布局和代码都做的比较好,看得出是花了不少功夫进行整理优化的了。
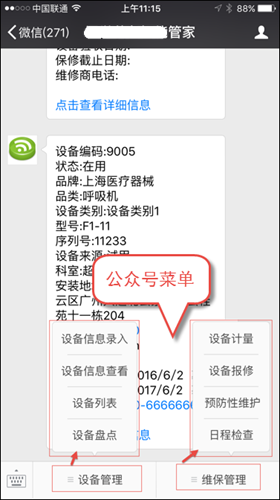
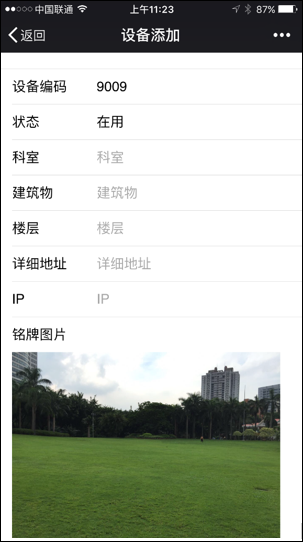
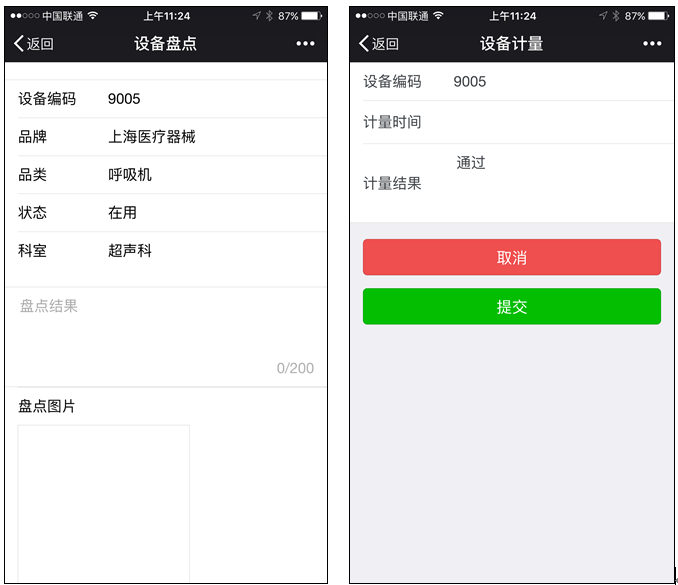
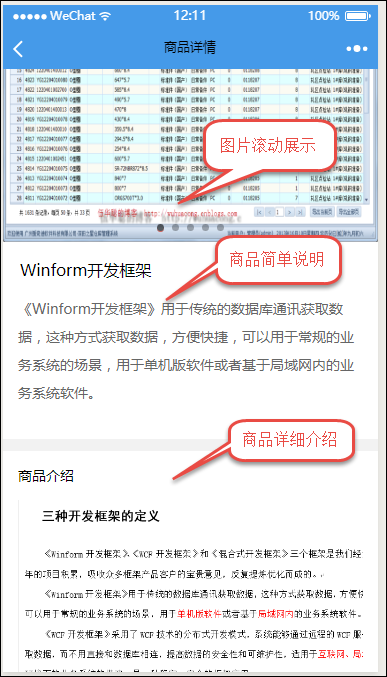
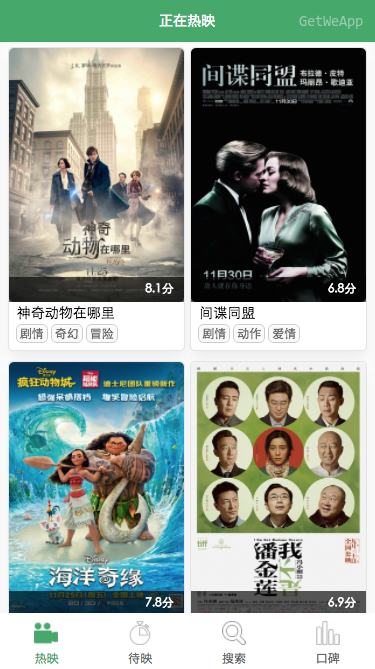
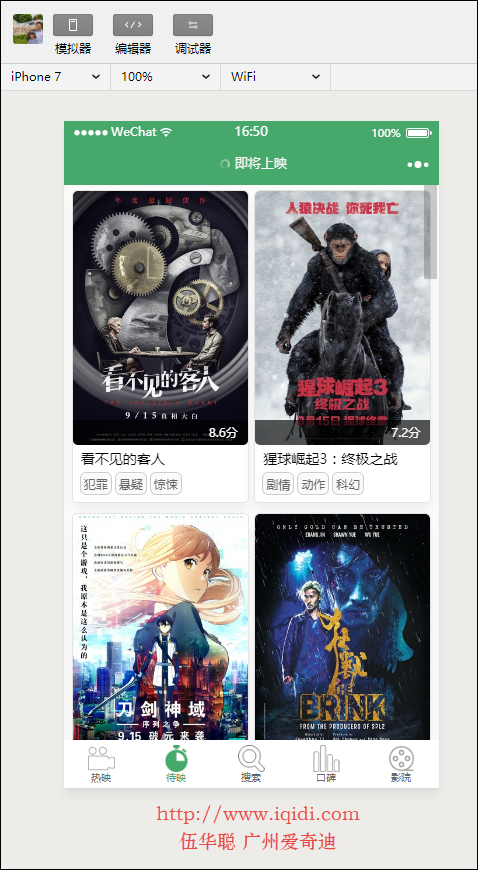
小程序主界面效果如下所示:
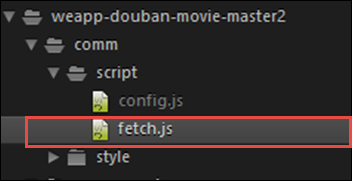
小程序源码目录结构如下所示:

不过每个人都有不同的经验和看法,对于开发小程序来说,我侧重于使用配置文件减少硬编码的常量,使用Promise来优化JS代码的使用,将获取和提交JSON数据的方法封装到辅助类,以及使用地理位置接口动态获取当前城市名称和坐标等等。
本篇随笔下面的部分就是介绍使用这些内容进行代码优化的处理过程。
1、使用配置文件定义常量内容
我们在使用任何代码开发程序的时候,我们都是非常注意一些变量或常量的使用,如果能够统一定义那就统一定义好了,这种在小程序的JS代码里面也是一样,我们尽可能抽取一些如URL,固定参数等信息到独立的配置文件中,这样在JS代码引入文件,使用变量来代替
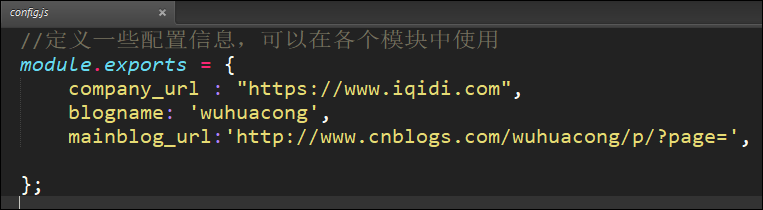
例如原来的config.js文件里面,只是定义了一个地址和页面数量的大小常量,如下所示
module.exports ={
city:'杭州',
count:20}
原来的小程序代码在获取待映的电影内容时候,部分源码如下所示
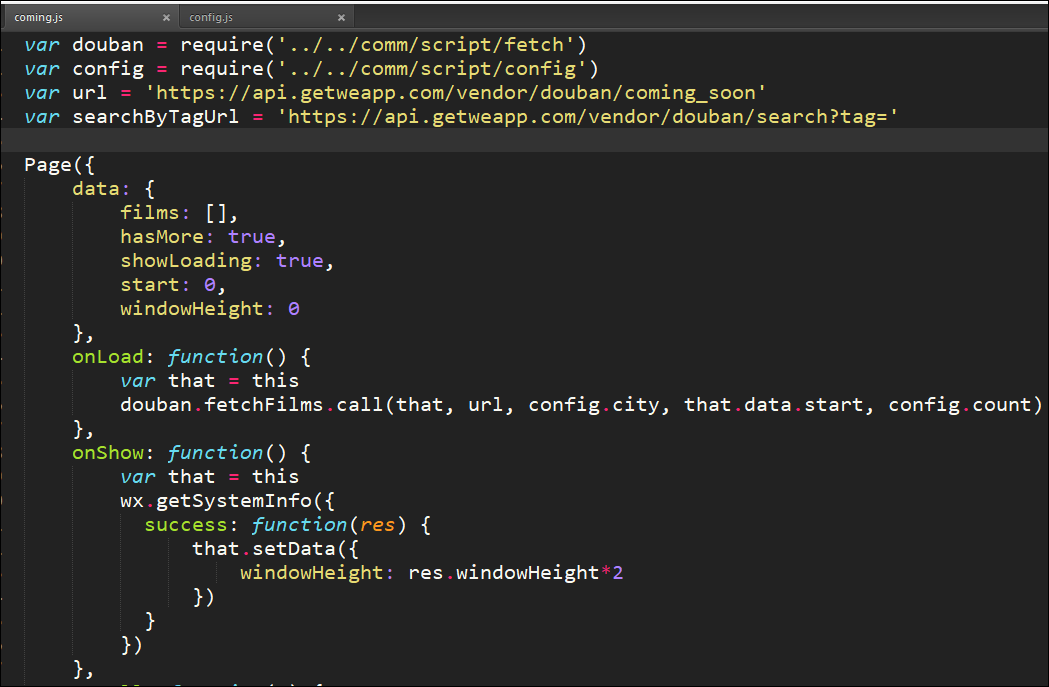
其他页面JS代码也和这个类似,头部依旧有很多类似这样URL地址,这个是我希望统一到config.js文件的地方,另外这个调用的函数是使用回调函数的处理方式,如下所示。
douban.fetchFilms.call(that, url, config.city, that.data.start, config.count)
其实我认为这里面既然是定义的外部函数,那么这里面的url, city, config.city, config.cout都不需要这里,在封装函数内部使用这些常量即可,因此可以对他们进行改造,如下我们统一抽取各个文件里面的URL,以及一些常见变量到config.js里面。
下面代码是我优化整理后的配置参数信息。
module.exports ={
city:'',
location:'0,0',
count:20,
coming_soon_url:'https://api.douban.com/v2/movie/coming_soon',
in_theaters_url:'https://api.douban.com/v2/movie/in_theaters',
top_url:'https://api.douban.com/v2/movie/top250',
search_url:'https://api.douban.com/v2/movie/search?tag=',
detail_url:'https://api.douban.com/v2/movie/subject/', //?id= celebrity_url: 'https://api.douban.com/v2/movie/celebrity/',
baidu_ak:'6473aa8cbc349933ed841467bf45e46b',
baidu_movie:'https://api.map.baidu.com/telematics/v3/movie',
hotKeyword: ['功夫熊猫', '烈日灼心', '摆渡人', '长城', '我不是潘金莲', '这个杀手不太冷', '驴得水', '海贼王之黄金城', '西游伏妖片', '我在故宫修文物', '你的名字'],
hotTag: ['动作', '喜剧', '爱情', '悬疑'],
}
上面的配置文件config.js里面,我统一抽取了各个页面的URL地址、关键词和标签(hotKeyword和hotTag)、城市及地址(city和location后面动态获取)、页面数量count等参数信息。
另外由于部分参数统一通过config.js获取,就不需要再次在调用的时候传入了,因此简化调用代码的参数传入,如下代码所示。
douban.fetchComming(that, that.data.start)对于原先的代码
douban.fetchFilms.call(that, url, config.city, that.data.start, config.count)
简化的虽然不多,但是尽可能的保持干净简单的接口是我们的目标,而且这里把常规的URL等参数提取到函数里面,更加符合我们编码的习惯。
这里定义的
douban.fetchComming(that, that.data.start)
使用了Promise来简化代码,传入的that参数是因为需要在函数体里面设置该页面里面的Data等处理。
关于Promise的相关处理,我们在下面进行介绍。
2、使用Promise来优化JS代码
关于Promise的好处和如何使用Promise插件介绍,我在随笔《
在微信小程序的JS脚本中使用Promise来优化函数处理
》中已有介绍,我很喜欢使用这种Promise的风格代码,而且可以定义一些常用的辅助类来提高代码的重用。在我参考的这个豆瓣电影小程序还是使用常规回调的函数,对比原作者最新版本的
wechat-weapp-movie
小程序,也依旧使用回调函数模式来处理,有点奇怪为什么不引入Promise插件来开发。
原来的小程序,电影接口的相关处理,统一在fetch.js里面进行处理,这里封装对各种豆瓣API接口的调用。
这里我们来看看原来程序没有采用Promise的回调函数处理代码
var config = require('./config.js')var message = require('../../component/message/message')
module.exports={
fetchFilms:function(url, city, start, count, cb) {var that = this if(that.data.hasMore) {
wx.request({
url: url,
data: {
city: config.city,
start: start,
count: count
},
method:'GET',
header: {"Content-Type": "application/json,application/json"},
success:function(res){if(res.data.subjects.length === 0){
that.setData({
hasMore:false,
})
}else{
that.setData({
films: that.data.films.concat(res.data.subjects),
start: that.data.start+res.data.subjects.length,
showLoading:false})
}
wx.stopPullDownRefresh()typeof cb == 'function' &&cb(res.data)
},
fail:function() {
that.setData({
showLoading:false})
message.show.call(that,{
content:'网络开小差了',
icon:'warning',
duration:3000})
}
})
}
},
这个函数是一个通用的函数,用来获取待映、热映、top250口碑的记录信息,不过它把参数抛给调用者传入,因此显得调用比较复杂一些,我们经过使用Promise优化代码处理,并对接口的参数进行简化,代码改造如下所示。
var config = require('./config.js')var message = require('../../component/message/message')var app = getApp()//获取应用实例 module.exports={//待映 fetchComming : function(page, start) {return this.fetchFilms(page, config.coming_soon_url, config.city, start, config.count);
},//热映 fetchPopular : function(page, start) {return this.fetchFilms(page, config.in_theaters_url, config.city, start, config.count);
},//top250口碑 fetchTop : function(page, start) {return this.fetchFilms(page, config.top_url, config.city, start, config.count);
},//通用的热映、待映的获取方式 fetchFilms: function(page, url, city, start, count) {return new Promise((resolve, reject) =>{var that =page;var json ={city: city, start: start, count: count };var type = "json";//特殊设置,默认是application/json if(that.data.hasMore) {
app.utils.get(url, json, type).then(res=>{if(res.subjects.length === 0){
that.setData({
hasMore:false,
})
}else{
that.setData({
films: that.data.films.concat(res.subjects),
start: that.data.start+res.subjects.length,
showLoading:false})
}
wx.stopPullDownRefresh();
resolve(res);
})
}
})
},
最终的请求接口参数只有两个,一个是页面对象,一个是请求的起始位置,如下代码所示
function(page, start)另外我们使用了代码
app.utils.get(url, json, type)
来对wx.request方法的统一封装,直接使用工具类里面的方法即可获取结果,不需要反复的、臃肿的处理代码。这就是我们使用Promise来优化JS,并抽取常用代码到工具类里面的做法。
我们再来对比一下获取电影详细信息的接口函数封装,原来代码如下所示。
fetchFilmDetail: function(url, id, cb) {var that = this;
wx.request({
url: url+id,
method:'GET',
header: {"Content-Type": "application/json,application/json"},
success:function(res){
that.setData({
filmDetail: res.data,
showLoading:false,
showContent:true})
wx.setNavigationBarTitle({
title: res.data.title
})
wx.stopPullDownRefresh()typeof cb == 'function' &&cb(res.data)
},
fail:function() {
that.setData({
showLoading:false})
message.show.call(that,{
content:'网络开小差了',
icon:'warning',
duration:3000})
}
})
},
我改造后的函数代码如下所示。
//获取电影详细信息 fetchFilmDetail: function(page, id) {return new Promise((resolve, reject) =>{var that =page;var url = config.detail_url +id;var type = "json";//特殊设置,默认是application/json app.utils.get(url, {}, type).then(res =>{
that.setData({
filmDetail: res,
showLoading:false,
showContent:true});
wx.setNavigationBarTitle({
title: res.title
});
wx.stopPullDownRefresh();
resolve(res);
});
})
},
通过对fetch.js函数代码的改造处理,可以看到调用的JS代码参数减少了很多,而且页面也不用保留那么多连接等参数常量信息了。
onLoad: function() {var that = thisdouban.fetchComming(that, that.data.start)
},
3、使用地理位置接口动态获取当前城市名称和坐标
原来程序使用硬编码的方式设置当前城市,如下脚本所示
module.exports ={
city:'杭州',
count:20}
不过我们不同地方的人员使用的时候,这个城市名称肯定需要变化的,因此可以使用微信的地理位置接口动态获取当前位置信息,然后写入到配置文件里面即可。
//获取当前位置信息 functiongetLocation (type) {return new Promise((resolve, reject) =>{
wx.getLocation({ type: type, success: resolve, fail: reject })
})
}//根据坐标获取城市名称 function getCityName (latitude = 39.90403, longitude = 116.407526) {var data = { location: `${latitude},${longitude}`, output: 'json', ak: '6473aa8cbc349933ed841467bf45e46b'};var url = 'https://api.map.baidu.com/' + 'geocoder/v2/';var type = 'json';return this.get(url, data, type).then(res =>res.result.addressComponent.city);
}
然后我们在app.js里面编写代码,在app启动的时候,动态获取城市名称、坐标信息然后写入配置文件即可,这里使用的还是Promise的函数调用实现。
const utils = require('./comm/script/util.js')
const config= require('./comm/script/config.js')
App({
onLaunch:function() {
utils.getLocation()
.then(res=>{
const { latitude, longitude }=res;
config.location= `${longitude},${latitude}`;//当前坐标
console.log(`currentLocation : ${config.location}`);returnutils.getCityName(latitude, longitude)
})
.then(name=>{
config.city= name.replace('市', ''); //当前城市名称
console.log(`currentCity : ${config.city}`)
})
.catch(err =>{
config.city= '广州'console.error(err)
})
},
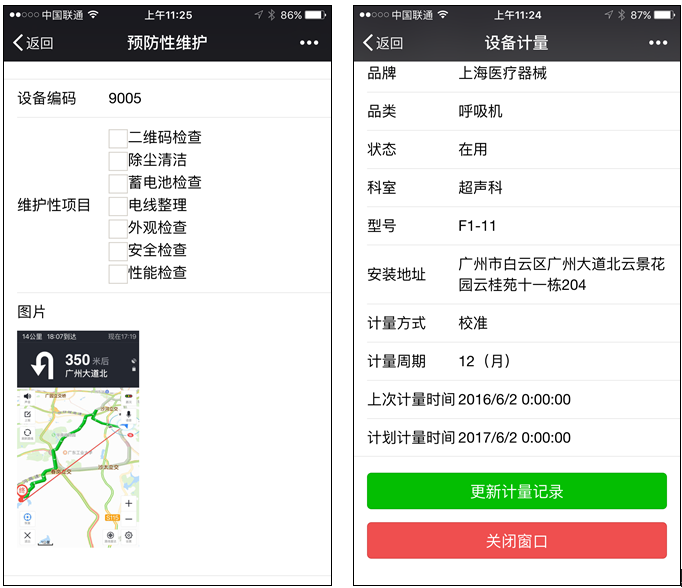
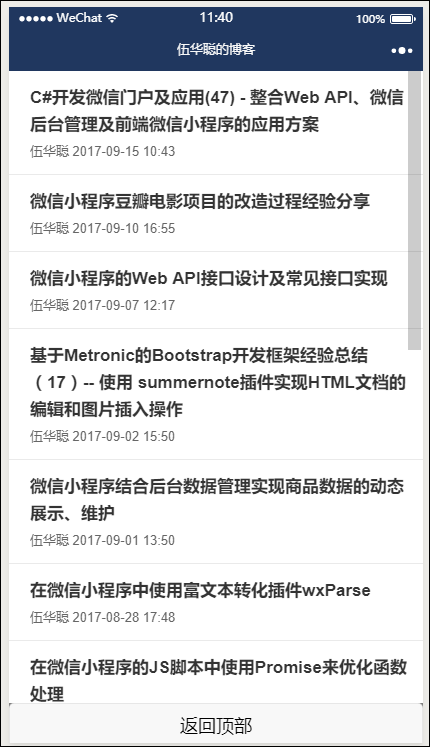
...最后呈上改造过代码的运行界面,还是保留原来的功能正常使用。
以上就是我对这个小程序进行不同方面的调整思路和经验总结,希望大家有所收益或者建议,感谢阅读支持。