利用代码生成工具Database2Sharp生成ABP VNext框架项目代码
我们在做某件事情的时候,一般需要详细了解它的特点,以及内在的逻辑关系,一旦我们详细了解了整个事物后,就可以通过一些辅助手段来提高我们的做事情的效率了。本篇随笔介绍ABP VNext框架各分层项目的规则,以及结合代码生成工具Database2Sharp来实现项目类代码,项目文件等内容的快速生成。
ABP VNext框架在官方下载项目的时候,会生成一个标准的空白项目框架,本代码工具不是替代这个项目代码生成,而是基于这个基础上进行基于数据表的增量式开发模块的需求(毕竟官方没有针对数据表的项目代码生成),最终所有的子模块可以集成在主模块上,形成一个完整的系统。
1、ABP VNext框架的项目关系
目前框架代码生成包括:应用服务层:Application.Contracts和Application项目,领域层:Domain.Shared和Domain项目,基础设施层:EntityFrameworkCore项目,HTTP 层:HttpApi和HttpApi.Client项目。生成代码集成相关的基类代码,简化项目文件的类代码。
应用服务层:
Application.Contracts,包含应用服务接口和相关的数据传输对象(DTO)。
Application,包含应用服务实现,依赖于 Domain 包和 Application.Contracts 包。
领域层:
Domain.Shared,包含常量,枚举和其他类型.
Domain 包含实体, 仓储接口,领域服务接口及其实现和其他领域对象,依赖于 Domain.Shared 包.
基础设施层:
EntityFrameworkCore,包含EF的ORM处理,使用仓储模式,实现数据的存储功能。
HTTP 层
HttpApi项目, 为模块开发REST风格的HTTP API。
HttpApi.Client项目,它将应用服务接口实现远程端点的客户端调用,提供的动态代理HTTP C#客户端的功能。
各个层的依赖关系如下图所示。
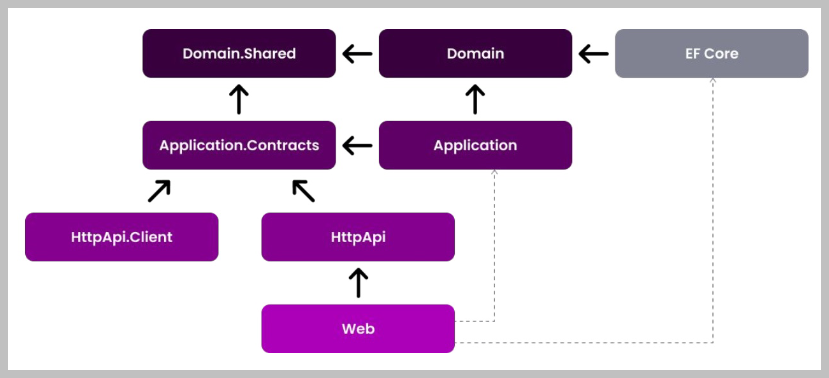
2、ABP VNext框架各层的项目代码
我在上篇随笔《
在ABP VNext框架中对HttpApi模块的控制器进行基类封装
》中介绍了为了简化子类一些繁复代码的重复出现,使用自定义基类方式,封装了一些常用的函数,通过泛型参数的方式,可以完美的实现强类型接口的各种处理。
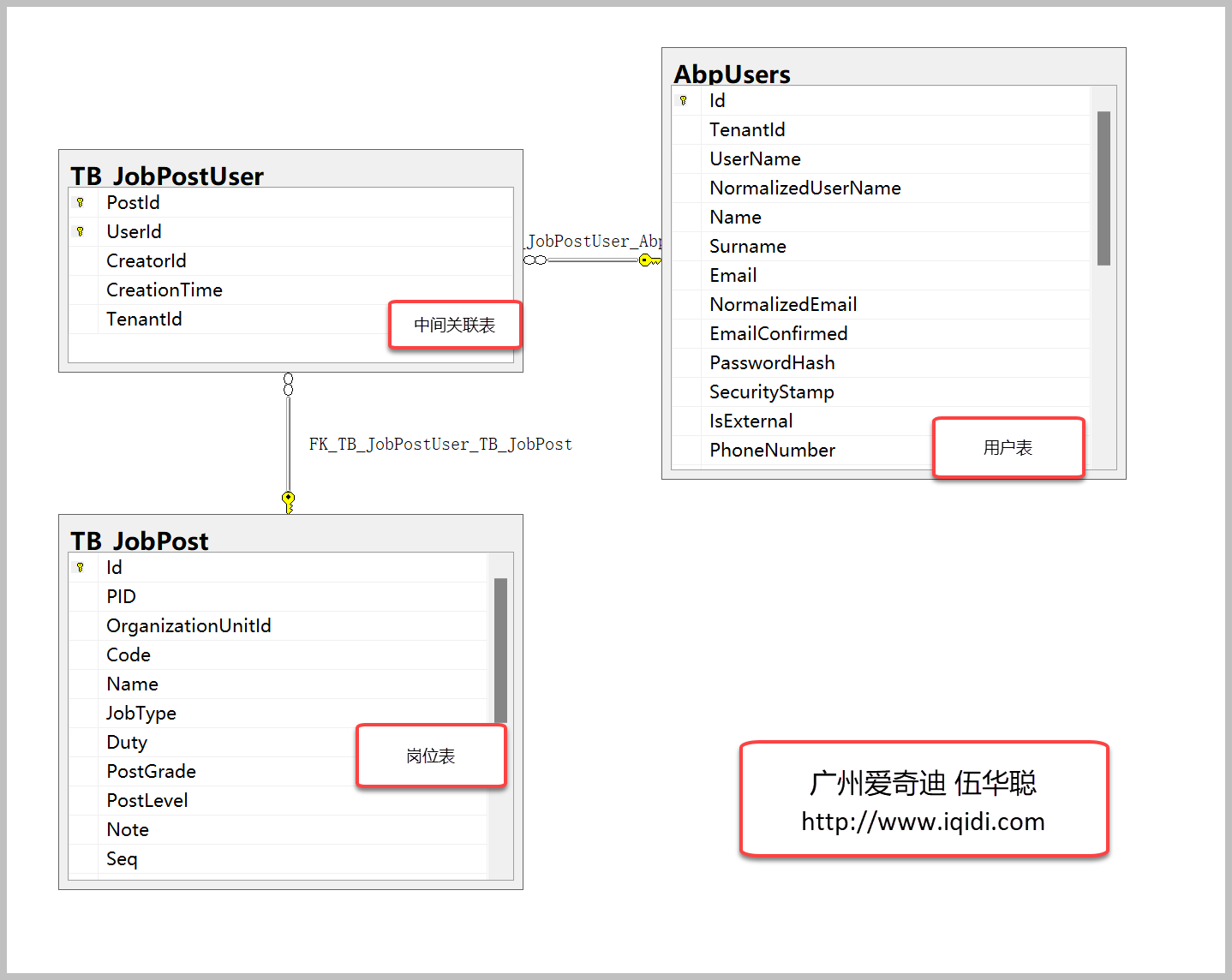
对于ABP VNext个项目的内容,我们继续推演到它的项目组织上来。为了简便,我们以简单的客户表T_Customer表来介绍框架项目的分层和关系。

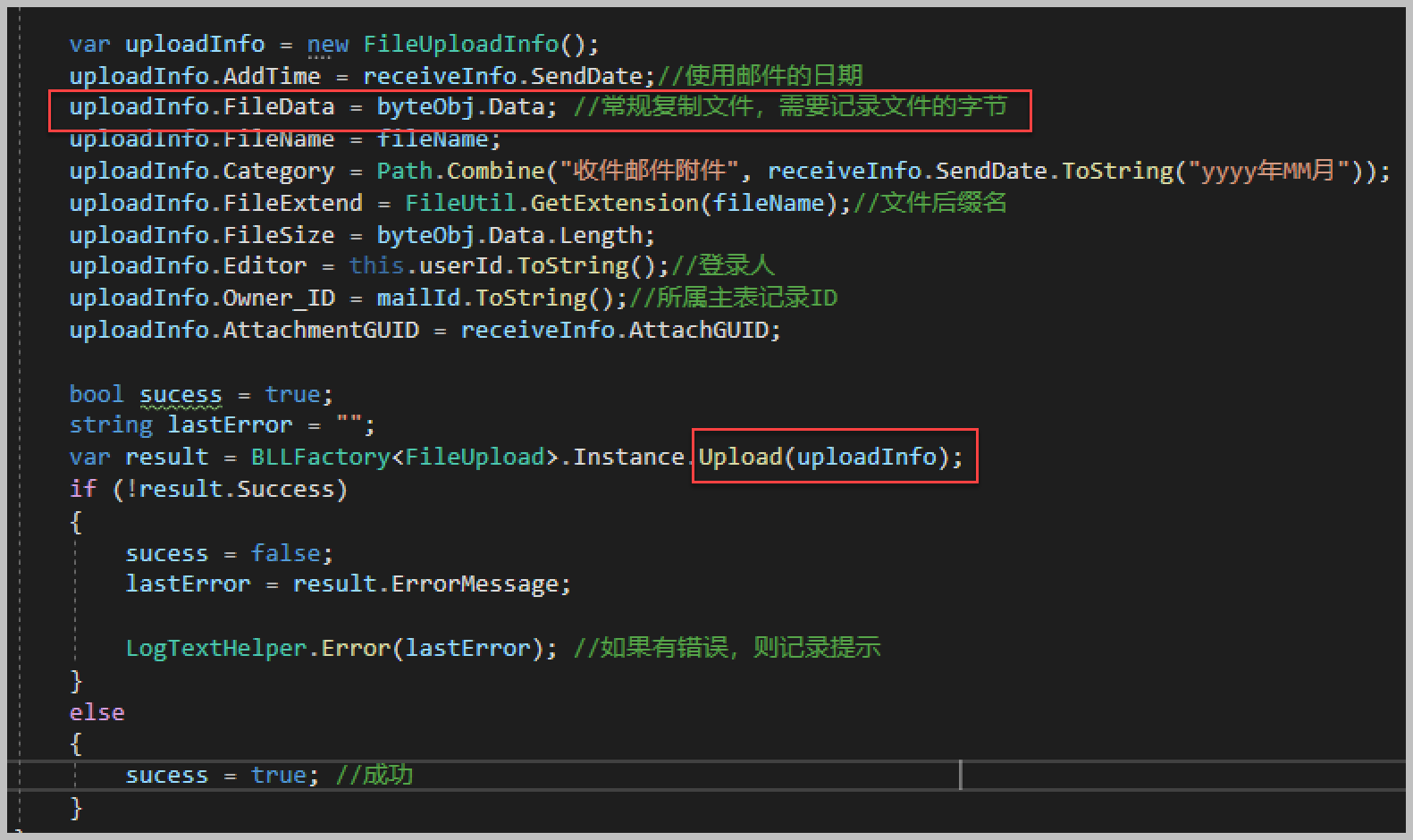
对于这个额外添加的表,首先我们来看看应用服务层的Application.Contracts项目文件,如下所示。
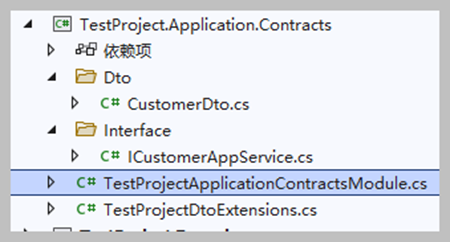
其中映射DTO放在DTO目录中,而应用服务的接口定义则放在Interface目录中,使用目录的好处是利于查看和管理,特别是在业务表比较多的情况下。
DTO类的定义如下所示。
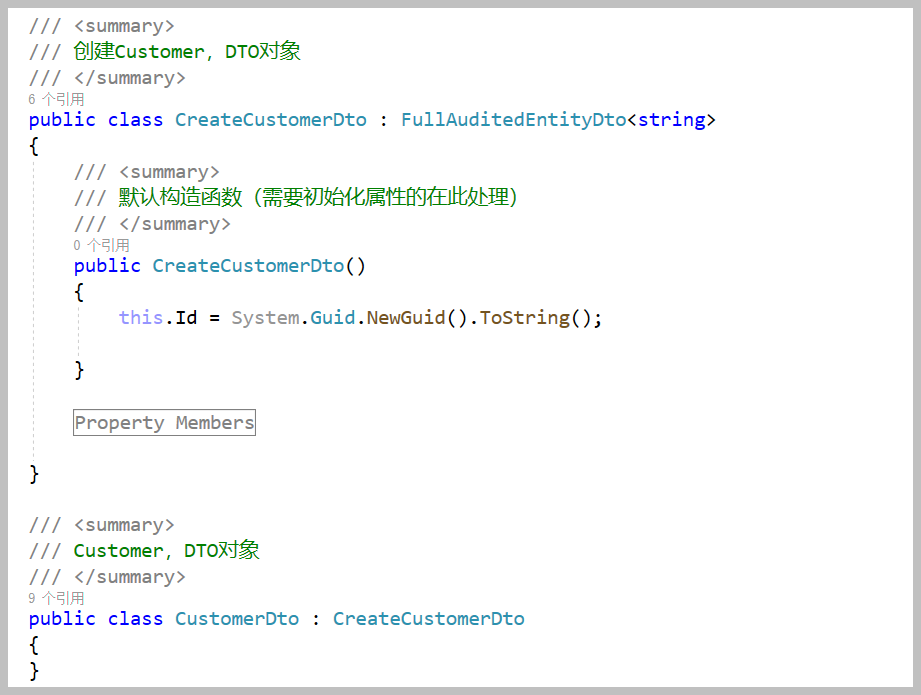
其中用到了基类对象EntityDto、CreationAuditedEntityDto、AuditEntityDto、FullAuditedEntityDto几个基类DTO对象,具体采用哪个基类DTO,依赖于我们表的包含哪些系统字段。如只包含CreationTime、CreatorId那么就采用CreationAuditedEntityDto,其他的依次类推。
领域层的实体类关系和前面DTO关系类似,如下所示。
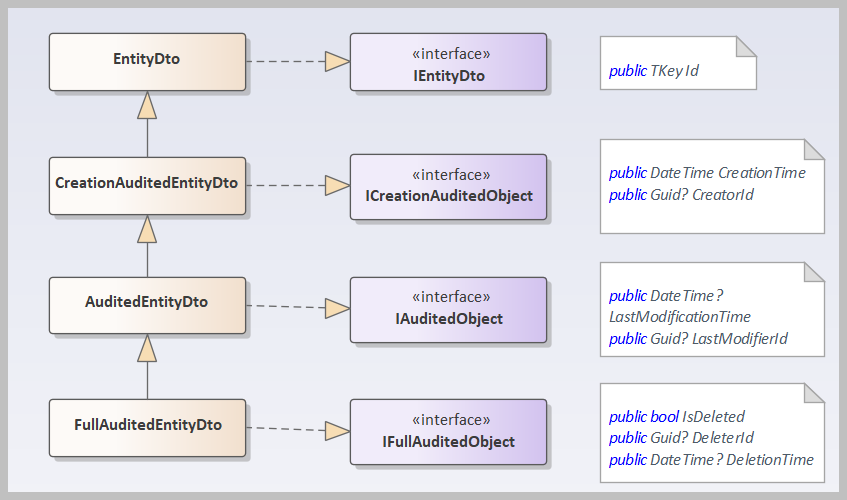
这样我们利用代码生成工具生成代码的时候,就需要判断表的系统字段有哪些来使用不同的系统DTO基类了。
而应用服务层的接口定义文件如下所示,它使用了我们前面随笔介绍过的自定义基类或接口。
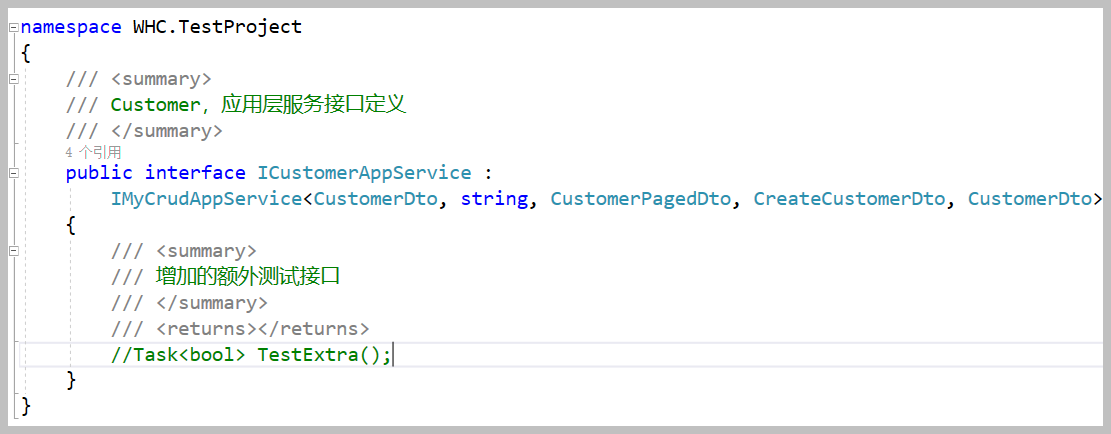
通过传入泛型类型,我们可以构建强类型化的接口定义。
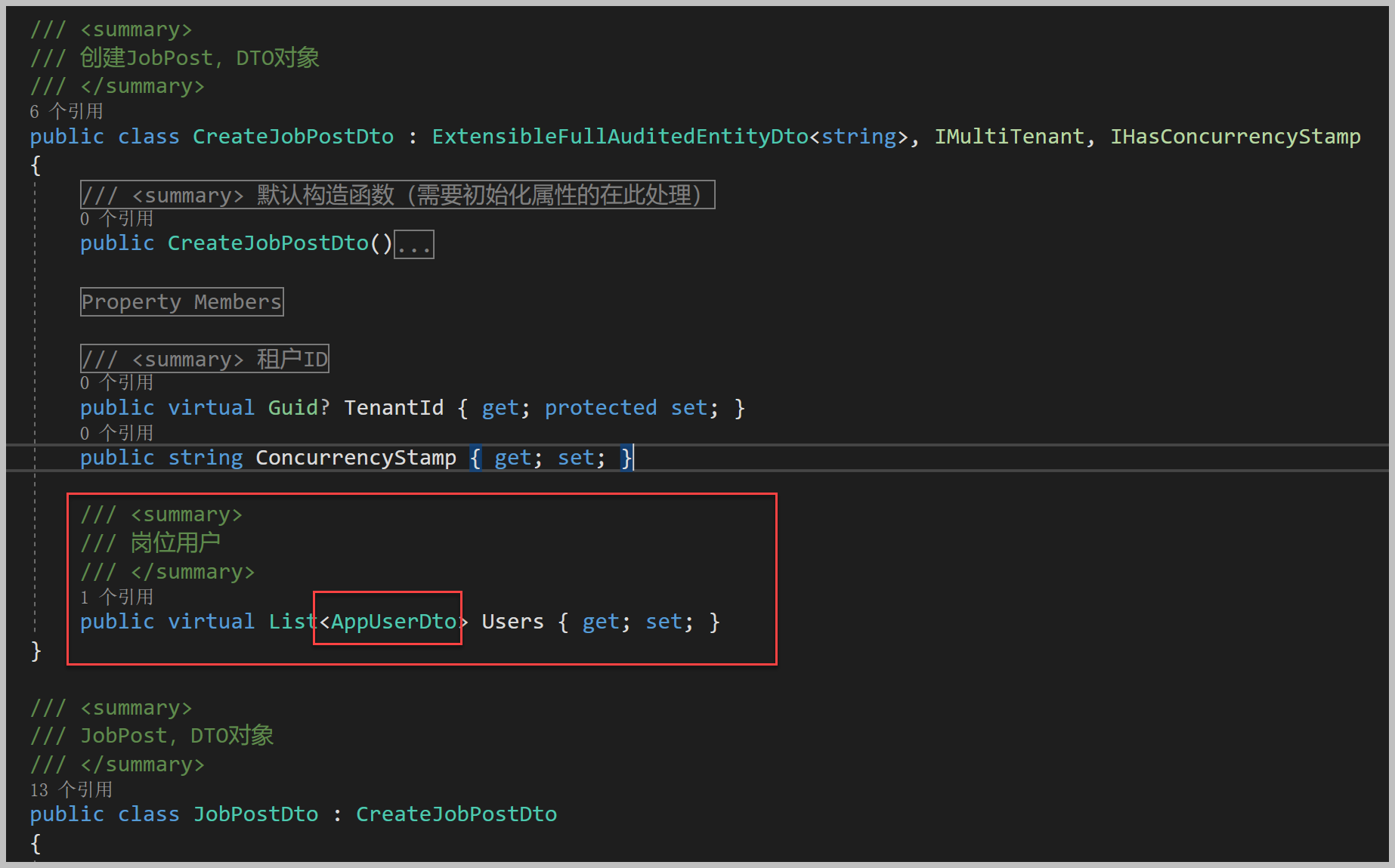
应用服务层的Application项目包含DTO映射文件和应用服务层接口实现类,如下所示。

其中映射DTO、Domain Entity(领域实体)关系的Automapper文件放在MapProfile文件夹中,而接口实现类文件则放在Service目录中,也是方便管理。
映射类文件,主要定义DTO和Domain Entity(领域实体)关系,如下所示。
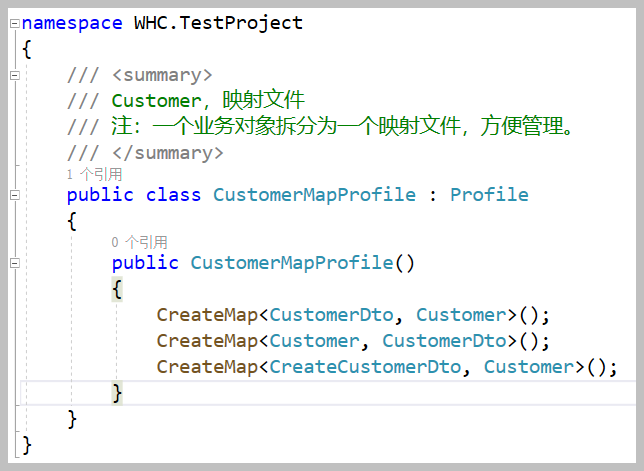
这样文件单独定义,在模块中会统一加载整个程序集的映射文件,比较方便。
public classTestProjectApplicationModule : AbpModule
{public override voidConfigureServices(ServiceConfigurationContext context)
{
Configure<AbpAutoMapperOptions>(options =>{
options.AddMaps<TestProjectApplicationModule>();
});
}
}
应用服务层的接口实现如下定义所示。
/// <summary> ///Customer,应用层服务接口实现/// </summary> public classCustomerAppService :
MyCrudAppService<Customer, CustomerDto, string, CustomerPagedDto, CreateCustomerDto, CustomerDto>,
ICustomerAppService
通过继承相关的自定义基类,可以统一封装一些常见的接口实现,传入对应的泛型类型,可以构建强类型的接口实现。
另外实现类还需要包含一些方法的重载,以重写某些规则,如排序、查询处理、以及一些通用的信息转义等,详细的应用服务层接口实现代码如下所示。
/// <summary> ///Customer,应用层服务接口实现/// </summary> public classCustomerAppService :
MyCrudAppService<Customer, CustomerDto, string, CustomerPagedDto, CreateCustomerDto, CustomerDto>,
ICustomerAppService
{private readonly IRepository<Customer, string> _repository;//业务对象仓储对象 public CustomerAppService(IRepository<Customer, string> repository) : base(repository)
{
_repository=repository; }/// <summary> ///自定义条件处理/// </summary> /// <param name="input">查询条件Dto</param> /// <returns></returns> protected override async Task<IQueryable<Customer>>CreateFilteredQueryAsync(CustomerPagedDto input)
{var query = await base.CreateFilteredQueryAsync(input);
query=query
.WhereIf(!input.ExcludeId.IsNullOrWhiteSpace(), t=>t.Id != input.ExcludeId) //不包含排除ID .WhereIf(!input.Name.IsNullOrWhiteSpace(), t => t.Name.Contains(input.Name)) //如需要精确匹配则用Equals//区间查询 .WhereIf(input.AgeStart.HasValue, s => s.Age >=input.AgeStart.Value)
.WhereIf(input.AgeEnd.HasValue, s=> s.Age <=input.AgeEnd.Value)//创建日期区间查询 .WhereIf(input.CreationTimeStart.HasValue, s => s.CreationTime >=input.CreationTimeStart.Value)
.WhereIf(input.CreationTimeEnd.HasValue, s=> s.CreationTime <=input.CreationTimeEnd.Value)
;returnquery;
}/// <summary> ///自定义排序处理/// </summary> /// <param name="query">可查询LINQ</param> /// <param name="input">查询条件Dto</param> /// <returns></returns> protected override IQueryable<Customer> ApplySorting(IQueryable<Customer>query, CustomerPagedDto input)
{//按创建时间倒序排序 return base.ApplySorting(query, input).OrderByDescending(s => s.CreationTime);//时间降序//先按第一个字段排序,然后再按第二字段排序//return base.ApplySorting(query, input).OrderBy(s=>s.DictType_ID).ThenBy(s => s.Seq); }/// <summary> ///获取字段中文别名(用于界面显示)的字典集合/// </summary> /// <returns></returns> public override Task<Dictionary<string, string>>GetColumnNameAlias()
{
Dictionary<string, string> dict = new Dictionary<string, string>();#region 添加别名解析 //系统部分字段 dict.Add("Id", "编号");
dict.Add("UserName", "用户名");
dict.Add("Creator", "创建人");
dict.Add("CreatorUserName", "创建人");
dict.Add("CreationTime", "创建时间");//其他字段 dict.Add("Name", "姓名");
dict.Add("Age", "");#endregion returnTask.FromResult(dict);
}/// <summary> ///对记录进行转义/// </summary> /// <param name="item">dto数据对象</param> /// <returns></returns> protected override voidConvertDto(CustomerDto item)
{//如需要转义,则进行重写 #region 参考代码 //用户名称转义//if (item.Creator.HasValue)//{// //需在CustomerDto中增加CreatorUserName属性//var user = _userRepository.FirstOrDefault(item.Creator.Value);//if (user != null)//{//item.CreatorUserName = user.UserName;//}//}//if (item.UserId.HasValue)//{//item.UserName = _userRepository.Get(item.UserId.Value).UserName;//}//IP地址转义//if (!string.IsNullOrEmpty(item.ClientIpAddress))//{//item.ClientIpAddress = item.ClientIpAddress.Replace("::1", "127.0.0.1");//} #endregion}/// <summary> ///用于测试的额外接口/// </summary> public Task<bool>TestExtra()
{return Task.FromResult(true);
}
}
这些与T_Customer 表相关的信息,如表信息,字段信息等相关的内容,可以通过代码生成工具元数据进行统一处理即可。
领域层的内容,包含Domain、Domain.Share两个项目,内容和Applicaiton.Contracts项目类似,主要定义一些实体相关的内容,这部分也是根据表和表的字段进行按规则生成。而其中一些类则根据命名控件和项目名称构建即可。
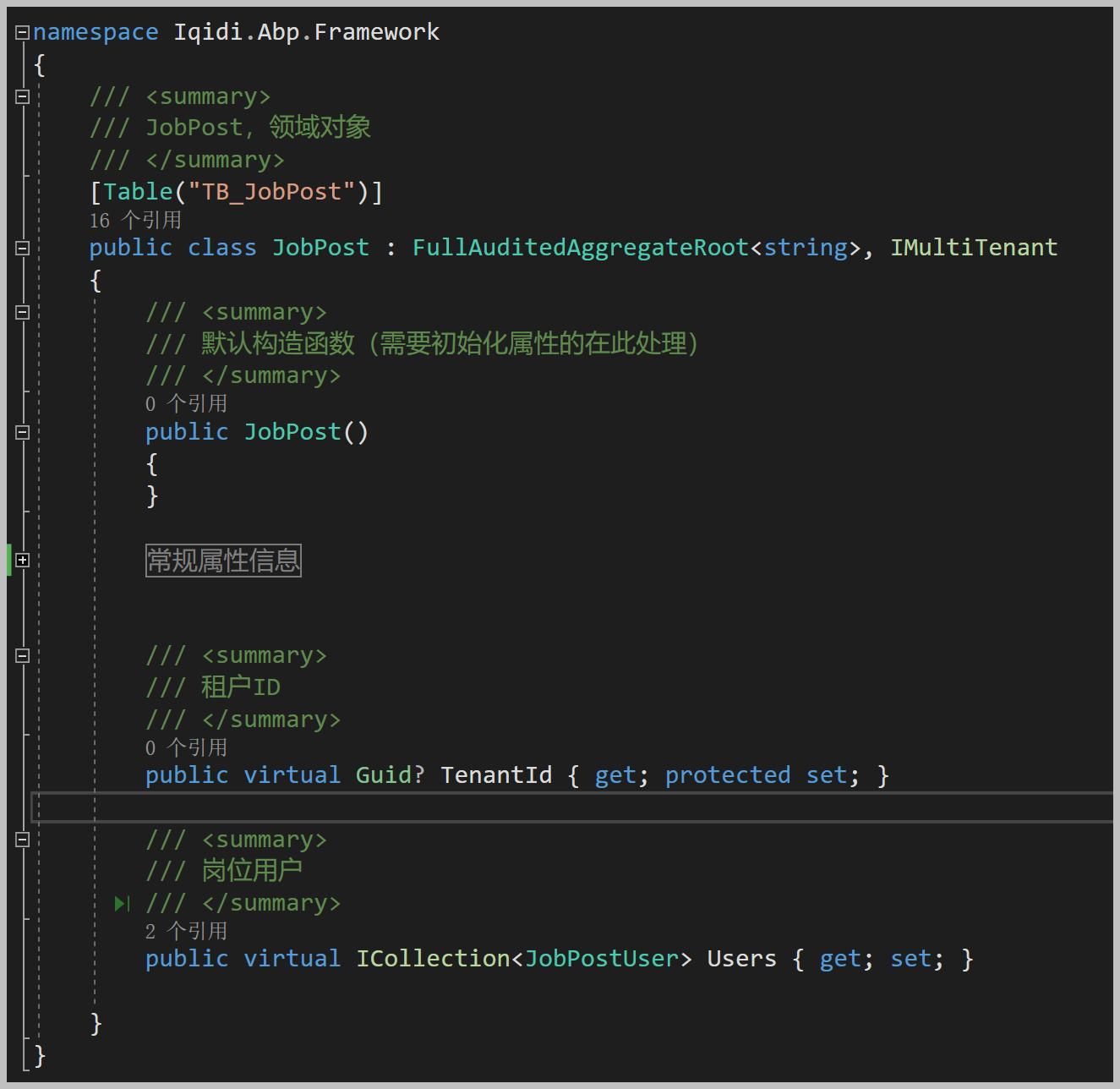
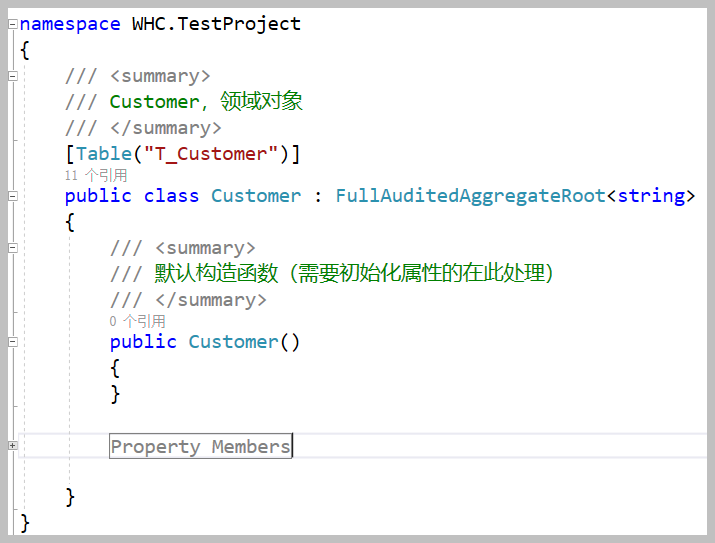
而Domain项目中的Customer领域实体定义代码如下所示。
而领域实体和聚合根的基类关系如下所示。
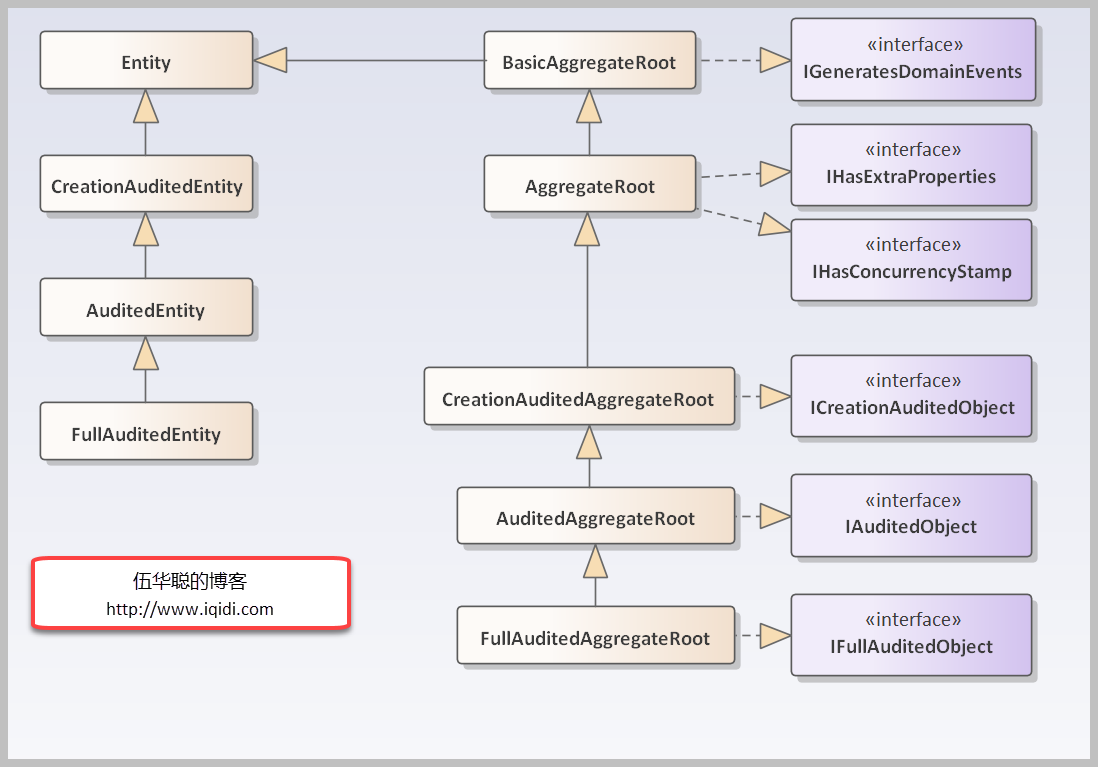
具体使用***
Entity
(如FullAuditedEntity基类)还是使用聚合根***
AggregateRoot
(如FullAuditedAggregateRoot)作为领域实体的基类,生成的时候,我们需要判断表的字段关系即可,如果表包含ExtraProperties和ConcurrencyStamp,则使用聚合根相关的基类。
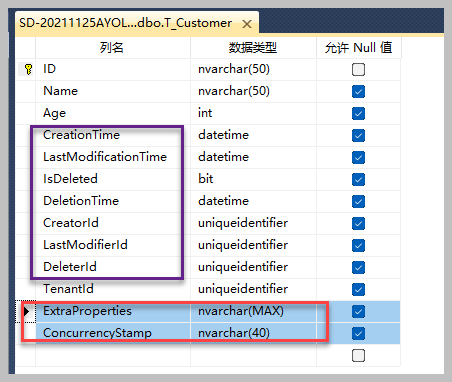
我们的T_Customer包含聚合根基类所需要的字段,代码生成的时候,则基类应该使用
FullAuditedAggregateRoot<T>
基类。
对于EntityFrameworkCore项目文件,它主要就是生成对应表的DbSet然后用于操作即可。
其中DbContext文件如下所示
namespaceWHC.TestProject.EntityFrameworkCore
{
[ConnectionStringName("Default")]public class TestProjectDbContext : AbpDbContext<TestProjectDbContext>{/// <summary> ///T_Customer,数据表对象/// </summary> public virtual DbSet<Customer> Customers { get; set; }public TestProjectDbContext(DbContextOptions<TestProjectDbContext>options)
:base(options)
{
}protected override voidOnModelCreating(ModelBuilder builder)
{base.OnModelCreating(builder);
builder.ConfigureTestProject();
}
}
}
按照规则生成即可,其他的可以不管了。
我们注意一下EntityFrameworkCoreModule中的内容处理,如果不是采用聚合根作为领域实体的基类,而是采用**Entity标准实体(如FullAuditedEntity基类)作为基类,那么需要在该文件中默认设置为true处理,因为ABP VNext框架默认只是加入聚合根的领域实体处理。
namespaceWHC.TestProject.EntityFrameworkCore
{
[DependsOn(typeof(TestProjectDomainModule),typeof(AbpEntityFrameworkCoreModule)
)]public classTestProjectEntityFrameworkCoreModule : AbpModule
{public override voidConfigureServices(ServiceConfigurationContext context)
{
context.Services.AddAbpDbContext<TestProjectDbContext>(options =>{//options.AddDefaultRepositories();//默认情况下,这将为每个聚合根实体(从派生的类AggregateRoot)创建一个存储库。//如果您也想为其他实体创建存储库,请设置includeAllEntities为true://参考https://docs.abp.io/en/abp/latest/Entity-Framework-Core#add-default-repositories options.AddDefaultRepositories(includeAllEntities: true);
});
}
}
}
上面的处理,即使是采用**Entity标准实体(如FullAuditedEntity基类)作为基类,也没问题了,可以顺利反射Repository对象出来了。
而对于Http项目分层,包含的HttpApi项目和HttpApi.Client,前者是重从应用服务层的服务接口,使用知道自定义的API规则,虽然默认可以使用应用服务层ApplicationService的自动API发布,不过为了更强的控制规则,建议重写(也是官方的做法)。两个项目文件如下所示。
其中HttpApi项目控制器,也是采用了此前介绍过的自定义基类,可以减少重复代码的处理。
namespaceWHC.TestProject.Controllers
{/// <summary> ///Customer,控制器对象/// </summary> //[RemoteService]//[Area("crm")] [ControllerName("Customer")]
[Route("api/Customer")]public classCustomerController :
MyAbpControllerBase<CustomerDto, string, CustomerPagedDto,CreateCustomerDto, CustomerDto>,
ICustomerAppService
{private readonlyICustomerAppService _appService;public CustomerController(ICustomerAppService appService) : base(appService)
{
_appService=appService;
}
}
}
其中MyAbpControllerBase控制器基类,封装了很多常见的CRUD方法(Create/Update/Delete/GetList/Get),以及一些BatchDelete、Count、GetColumnNameAlias等基础方法。
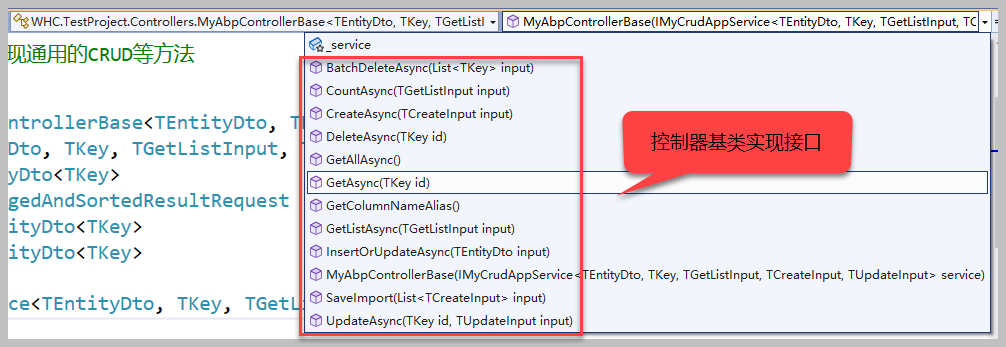
对于ABP VNext各个项目的项目文件的生成,我们这里顺便说说,其实这个文件很简单,没有太多的内容,包含命名空间,项目名称,以及一些常见的引用而已,它本身也是一个XML文件,填入相关信息生成文件即可。

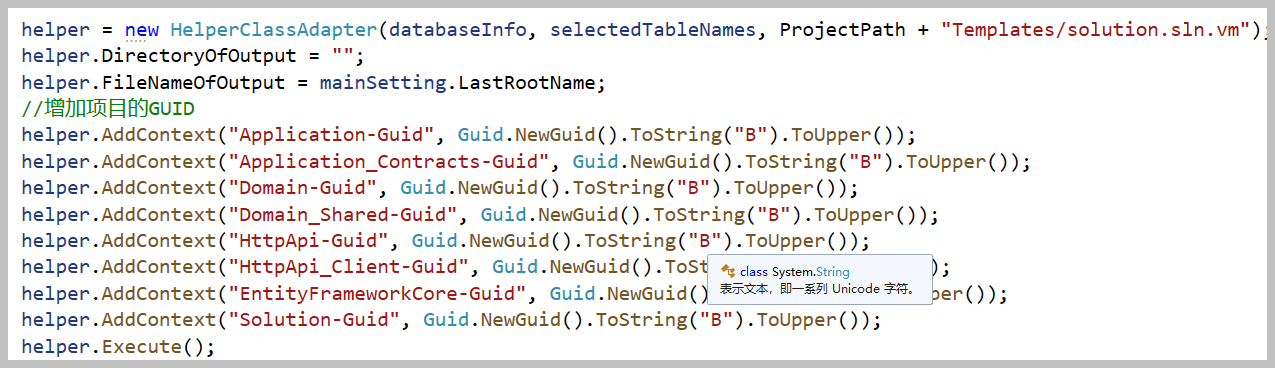
而对于解决方案,它就是包含不同的项目文件,以及各个项目文件有一个独立的GUID,因此我们动态构建对应的GUID值,然后绑定在模板上即可。
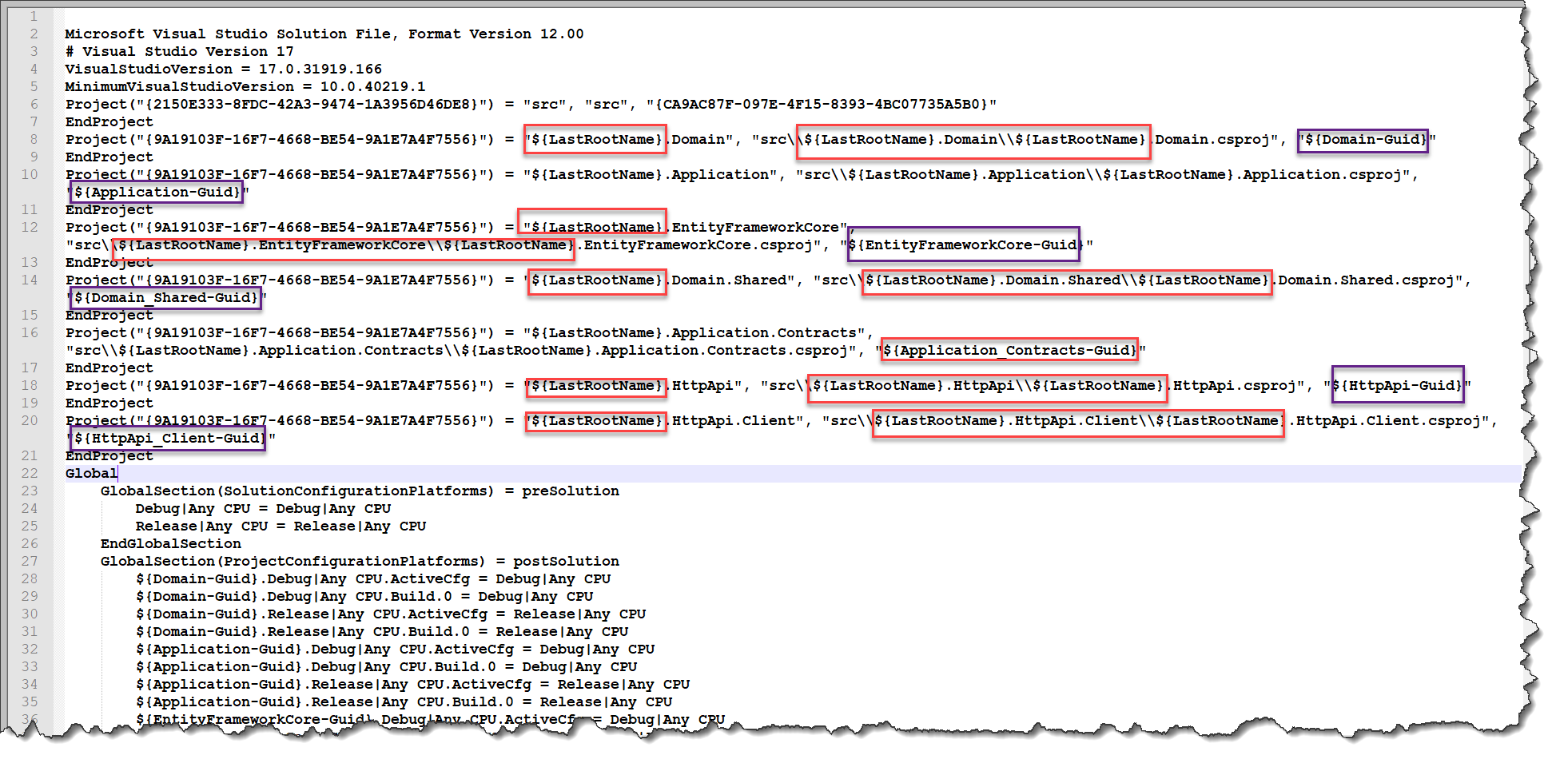
代码工具中,后端提供数据绑定到前端模板即可实现内容的动态化了。
3、使用代码生成工具Database2Sharp生成ABP VNext框架项目
上面介绍了ABP VNext框架的各个项目层的代码生成,以及一些代码生成处理的规则,那么实际的代码生成工具生成是如何的呢?
代码生成工具下载地址:
http://www.iqidi.com/database2sharp.htm
。
首先单击左侧节点展开ABP VNext项目的数据库,让数据库的元数据读取出来,便于后面的代码生成。
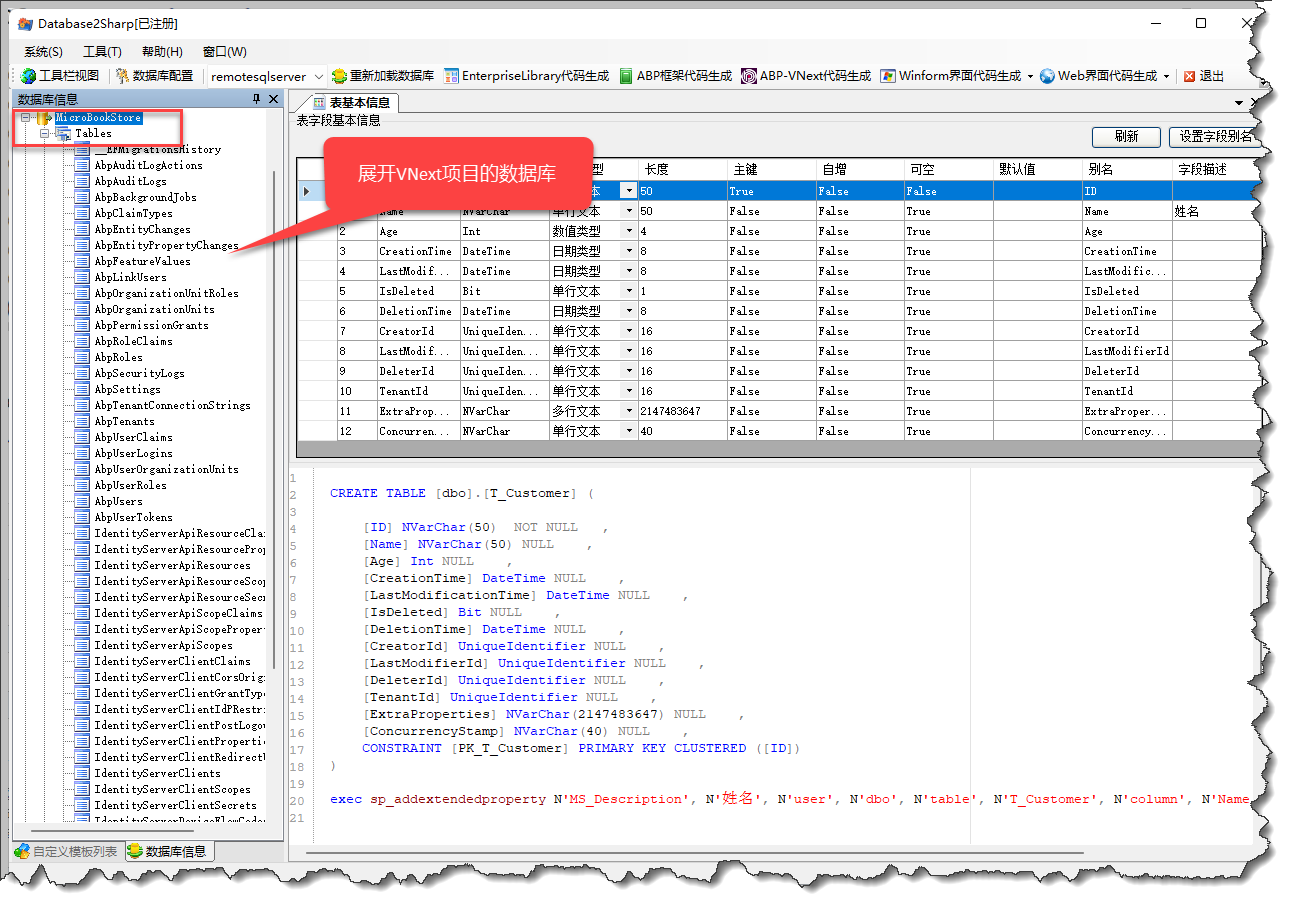
然后从右键菜单中选择【代码生成】【ABP VNext框架代码生成】或者工具栏中选择快速入口,一样的效果。
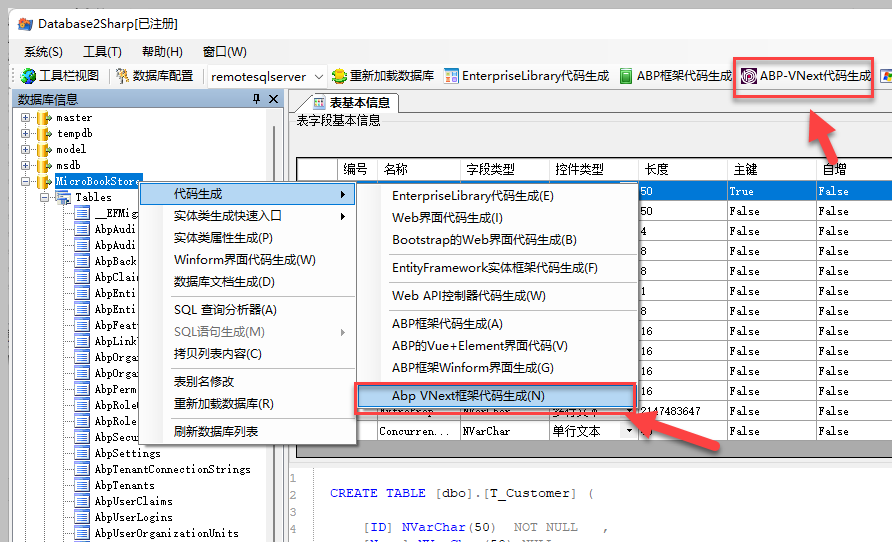
在弹出的对话框中选择相关的数据表,用于生成框架代码即可,注意修改合适的主命名空间,可以是TestProject或者WHC.Project等类似的名称。
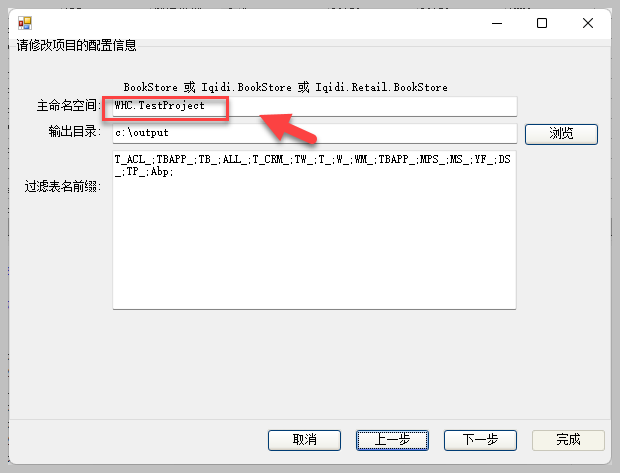
最后下一步生成确认即可生成相关的解决方案代码。

生成后所有项目关系已经完善,可以直接打开解决方案查看到整个项目情况如下所示。
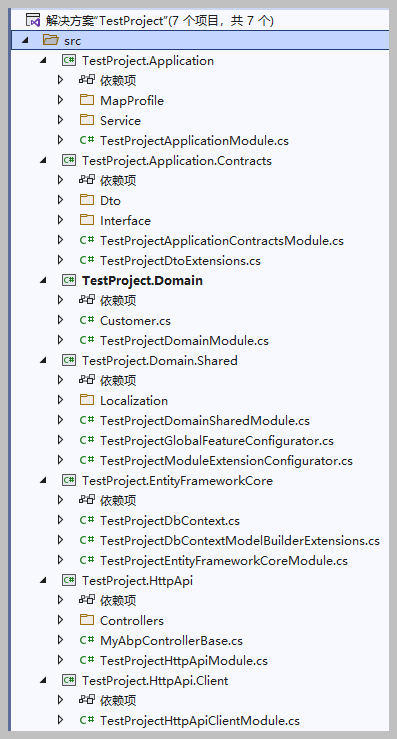
这样生成的解决方案,可以编译为一单独的模块,需要的时候,直接在主项目中引用并添加依赖即可。
例如我们在一个ABP VNext的标准项目MicroBookStore.Web中引入刚才代码生成工具生成的模块,那么在MicroBookStoreWebModule.cs 中添加依赖即可,如下所示。
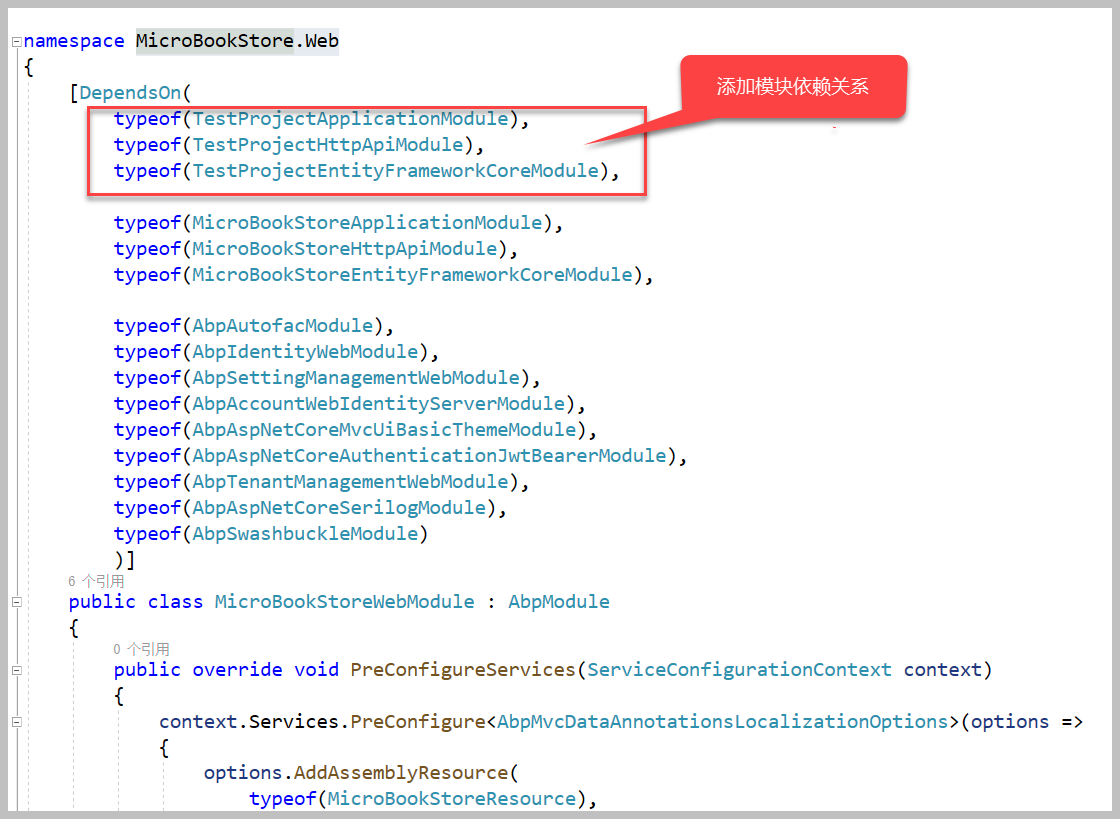
由于我们是采用DLL的引用方式,那么在项目添加对应的引用关系才可以使用。
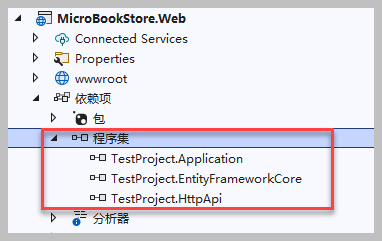
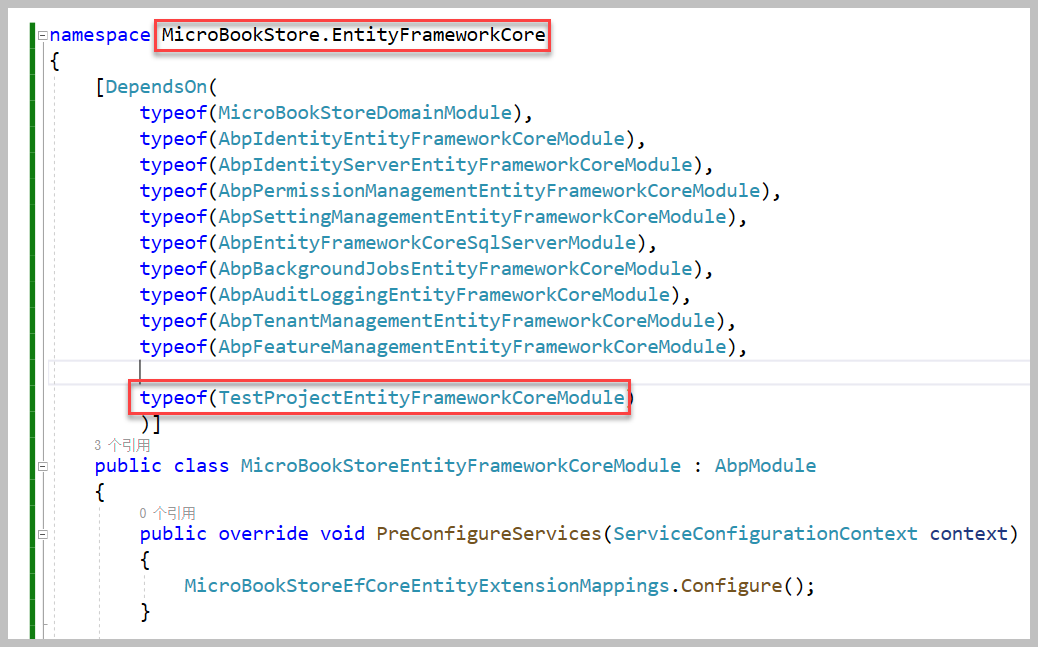
同时在EFCore项目中添加项目的TestProject项目的EF依赖关系如下所示。
这样跑动起来项目,就可以有Swagger的接口可以查看并统一调用了。

以上就是对于ABP VNext框架项目的分析和项目关系的介绍,并重要介绍利用代码生成工具来辅助增量式模块化开发的操作处理,这样我们在开发ABP VNext项目的时候,更加方便高效了。