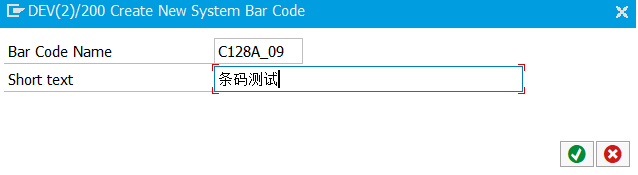
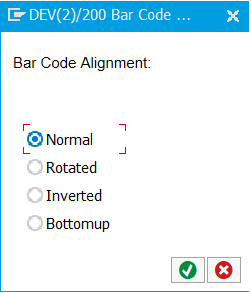
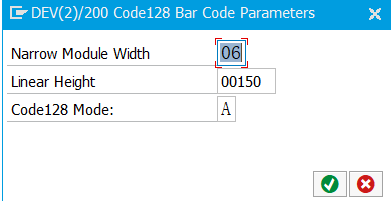
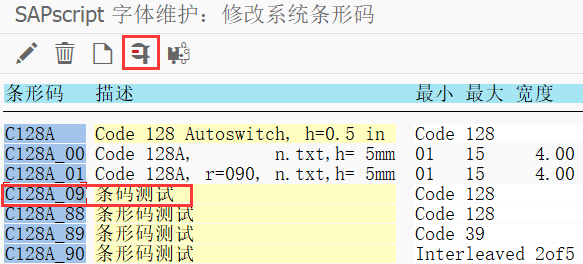
字符串中包含单引号:单引号前面再加一个单引号
例:jest~stat = 'E0002'
jest~stat = 'E0003' OR jest~stat = 'E0004'
IF z_stat IS INITIAL.
z_stat = 'jest~stat = ''E0002'''.
ELSE.
z_stat = 'jest~stat = ''E0003'' OR jest~stat = ''E0004'''.
ENDIF.
1、连接字符串
CONCATENATE {dobj1 dobj2 ...}|{LINES OF itab}
INTO result
[IN {BYTE|CHARACTER} MODE]
[SEPARATED BY sep]
[RESPECTING BLANKS].
2、拆分字符串:
SPLIT dobj AT sep INTO
{ {result1 result2 ...} | {TABLE result_tab} }
[IN {BYTE|CHARACTER} MODE].
例:
DATA: str TYPE string VALUE '字符串一 字符串二 字符串三 字符串四',
str1 TYPE string,
str2 TYPE string,
str3 TYPE string.
SPLIT str AT space INTO str1 str2 str3.
WRITE: / str1, / str2, / str3.
字符串一
字符串二
字符串三 字符串四
注意:没有足够的目标字段,则用str的剩余部分填充最后目标字段。
可以用一个内表来接收拆分后的子串,可以自动增长,就不用担心目标字段不够用了。例子如下:
DATA: str TYPE string VALUE '字符串一 字符串二 字符串三 字符串四'.
DATA: it_str TYPE TABLE OF string,
wa_str LIKE LINE OF it_str.
SPLIT str AT space INTO TABLE it_str.
LOOP AT it_str INTO wa_str.
WRITE: / wa_str.
ENDLOOP.
字符串一
字符串二
字符串三
字符串四
segment()函数
segment( val = text index = idx [sep|space = sep] )
根据指定的字符串sep或者指定的字符sapce来将text拆分,并返回第idx(从1开始)个片断
3、截断字符串:
SHIFT {c} [BY {n} PLACES] [{mode}].:
字符串移动
字符串替换
替换指定的字符串(老式的,已过时的)
REPLACE sub_string WITH new INTO dobj
[IN {BYTE|CHARACTER} MODE]
[LENGTH len].
替换某个区间上的字符串
REPLACE SECTION [OFFSET off] [LENGTH len] OF dobj WITH new
[IN {BYTE|CHARACTER} MODE].
OFFSET or LENGTH必须要指定一个,如果指定了OFFSET,但未指定LENGTH时,替换的内容从OFFSET到dobj的最后;如果指定了LENGTH,但未指定OFFSET时,OFFSET将隐含为0。OFFSET与LENGTH需要大于或等于0,通过OFFSET与LENGTH定位到的子字符串段必须要位于dobj里。
replace
返回码:
0 ——替换成功,并且结果未被截断
2 ——替换成功,但结果右边被截断
4 ——未找到要替换的字符串
replace()函数regex
replace( val = text [off = off] [len = len] with = new )
replace( val = text {sub = substring}|{regex = regex} with = new [case = case] [occ = occ] )
使用new替换指定的子符串,返回String类型。
搜索字符串
SEARCH <c> FOR <str> <options>.
contains()函数regex
matches()函数regex
count()函数regex