使用C#实现五行号码属性变化的万年历
五行是指“金木水火土”,我国古代认为,宇宙是由金、木、水、火、土五种元素构成的,五行运动即相生相克的结果构成了大千世界。五行有正五行和纳音五行之分。
按天干地支的自身属性所定的五行为正五行,甲木、子水等;
(十大天干和十二地支,十天干:甲、乙、丙、丁、戊、己、庚、辛、壬、癸;十二地支:子、丑、寅、卯、辰、巳、午、未、申、酉、戌、亥;
天干地支纪年法首先是天干在前,地支在后,比如今年2005就为-乙酉年)
按干支结合生出的五行为纳音五行。纳音来源:六十甲子纳音,实即六十律逆相为宫之法。一律合五音,十二律即纳六十音。纳音的基本方法是:同类娶妻,隔八生子。这也是律吕相生的法则。干为天,支为地,音为人。
六十甲子纳音表
甲子乙丑海中金 丙寅丁卯炉中火 戊辰己巳大林木 庚午辛未路旁土 壬申癸酉剑锋金
甲戌乙亥山头火 丙子丁丑涧下水 戊寅己卯城头土 庚辰辛巳白腊金 壬午癸未杨柳木
甲申乙酉泉中水 丙戌丁亥屋上土 戊子己丑劈雳火 庚寅辛卯松柏木 壬辰癸巳长流水
甲午乙未沙中金 丙申丁酉山下火 戊戌己亥平地木 庚子辛丑壁上土 壬寅癸卯金箔金
甲辰乙巳佛灯火 丙午丁未天河水 戊申己酉大驿土 庚戌辛亥插环金 壬子癸丑桑枝木
甲寅乙卯大溪水 丙辰丁巳沙中土 戊午己未天上火 庚申辛酉石榴木 壬戌癸亥大海水
另外上面纳音表结合具体年份详细如下:
甲子年:(
1924
,
1984
)五行属海中金,屋上之鼠。
★
乙丑年:(
1925
,
1985
)五行属海中金,海内之牛。
丙寅年:(
1926
,
1986
)五行属炉中火,山林之虎。
★
丁卯年:(
1927
,
1987
)五行属炉中火,望月之兔。
戊辰年:(
1928
,
1988
)五行属大林木,清温之龙。
★
已巳年:(
1929
,
1989
)五行属大林木,福气之蛇。
庚午年:(
1930
,
1990
)五行属路旁土,堂里之马。
★
辛未年:(
1931
,
1991
)五行属路旁土,得禄之羊。
壬申年:(
1932
,
1992
)五行属剑锋金,清秀之猴。
★
癸酉年:(
1933
,
1993
)五行属剑锋金,楼宿之鸡。
甲戌年:(
1934
,
1994
)五行属山头火,守身之狗。
★
乙亥年:(
1935
,
1995
)五行属山头火,过往之猪。
丙子年:(
1936
,
1996
)五行属涧下水,田内之鼠。
★
丁丑年:(
1937
,
1997
)五行属涧下水,湖内之牛。
戊寅年:(
1938
,
1998
)五行属城头土,过山之虎。
★
巳卯年:(
1939
,
1999
)五行属城头土,山林之兔。
庚辰年:(
1940
,
2000
)五行属白腊金,怒性之龙。
★
辛巳年:(
1941
,
2001
)五行属白腊金,冬藏之蛇。
壬午年:(
1942
,
2002
)五行属杨柳木,军中之马。
★
癸未年:(
1943
,
2003
)五行属杨柳木,群内之羊。
甲申年:(
1944
,
2004
)五行属井泉水,过树之猴。
★
乙酉年:(
1945
,
2005
)五行属井泉水,唱午之鸡。
丙戌年:(
1936
,
2006
)五行属屋上圭,自眠之狗。
★
丁亥年:(
1947
,
2007
)五行属屋上圭,过山之猪。
戌子年:(
1948
,
2008
)五行属霹雷火,仓内之鼠。
★
巳丑年:(
1949
,
2009
)五行属霹雷火,栏内之牛。
庚寅年:(
1950
,
2010
)五行属松柏木,出山之虎。
★
辛卯年:(
1951
,
2011
)五行属松柏木,蟾窟之兔。
壬辰年:(
1952
,
2012
)五行属长流水,行雨之龙。
★
癸巳年:(
1953
,
2003
)五行属长流水,草中之蛇。
甲午年:(
1954
,
2004
)五行属沙中金,云中之马。
★
乙未年:(
1955
,
2015
)五行属沙中金,敬重之羊。
丙申年:(
1956
,
2016
)五行属山下火,山上之猴。
★
丁酉年:(
1957
,
2017
)五行属山下火,独立之鸡。
戊戌年:(
1958
,
2018
)五行属平地木,进山之狗。
★
已亥年:(
1959
,
2019
)五行属平地木,道院之猪。
庚子年:(
1960
,
2020
)五行属壁上土,梁上之鼠。
★
辛丑年:(
1961
年)
五行属壁上土,路途之牛。
壬寅年:(
1962
年)
五行属金泊金,过林之虎。
★
癸卯年:(
1963
年)
五行属金泊金,山林之兔。
甲辰年:(
1964
年)
五行属覆灯火,伏潭之龙。
★
乙巳年:(
1965
年)
五行属覆灯火,出穴只蛇。
丙午年:(
1966
年)
五行属天河水,行路之马。
★
丁未年:(
1967
年)
五行属天河水,失群之羊。
戊申年:(
1968
年)
五行属大泽土,独立之猴。
★
已酉年:(
1969
年)
五行属大泽土,报晓之鸡。
庚戌年:(
1970
年)
五行属钗钏金,寺观之狗。
★
辛亥年:(
1971
年)
五行属钗钏金,圈养之猪。
壬子年:(
1972
年)
五行属桑柘木,山上之鼠。
★
癸丑年:(
1973
年)
五行属桑柘木,栏外之牛。
甲寅年:(
1974
年)
五行属大溪水,立定只虎。
★
乙卯年:(
1975
年)
五行属大溪水,得道之兔。
丙辰年:(
1976
年)
五行属沙中土,天上之龙。
★
丁已年:(
1977
年)
五行属沙中土,塘内之蛇。
戊午年:(
1978
年)
五行属天上火,厩内之马。
★
已未年:(
1979
年)
五行属天上火,草野之羊。
庚申年:(
1980
年)
五行属石榴木,食果之猴。
★
辛酉年:(
1981
年)
五行属石榴木,笼藏之鸡。
壬戌年:(
1982
年)
五行属大海水,顾家之犬。
★
癸亥年:(
1983
年)
五行属大海水,林下之猪。
六十甲子納音之說,術家多不能曉。原其所以得名,皆從五音所生,有條不紊,端如貫珠。蓋甲子為首,而五音始於宮,宮土生金,故甲子為金,而乙丑以陰從陽。商金生水,故丙子為水,而丁丑從之。角木生火,故戊子為火。徵火生土,故庚子為土。羽水生木,故壬子為木。而己丑、辛丑、癸丑各從之。至於甲寅,則納音起於商,商金生水,故甲寅為水。角木生火,故丙寅為火。徵火生土,故戊寅為土。羽水生木,故庚寅為木。宮土生金,故壬寅為金。而五卯各從之。至甲辰,則納音起於角,角木生火,故甲辰為火。徵火生土,故丙辰為土。羽水生木,故戊辰為木。宮土生金,故庚辰為金。商金生水,故壬辰為水。而五巳各從之。宮、商、角既然,惟徵、羽不得居首。於是甲午復如甲子,甲申如甲寅,甲戌如甲辰,而五未、五酉、五亥,亦各從其類。
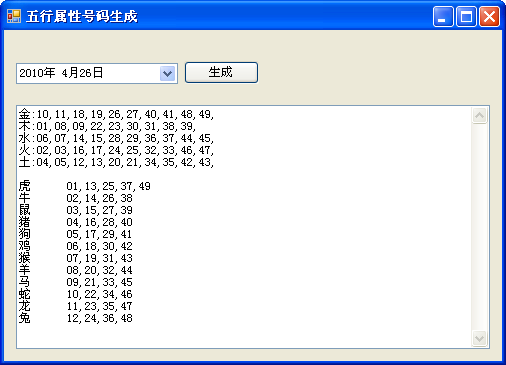
我们知道,六合一共有49个号码(1~49),由于五行号码是每年都会变化的,对应到六合里面, 如何获得该年的五行(金木水火土)对应的49个号码呢?
如2010年六合中的五行号码如下:
金:10,11,18,19,26,27,40,41,48,49,
木:01,08,09,22,23,30,31,38,39,
水:06,07,14,15,28,29,36,37,44,45,
火:02,03,16,17,24,25,32,33,46,47,
土:04,05,12,13,20,21,34,35,42,43,
在介绍使用C#来自动生成每年的五行号码前,我们先来看看使用易语言的实现逻辑。
.版本 2
.支持库 CnCalendar
.计次循环首 (49, 计次)
.如果真 (六十甲子纳音数组 [农历日期框1.农历年 - 1922 - 计次] = “金”)
金行文本 = 金行文本 + 取文本右边 (“0” + 到文本 (计次), 2) + “,”
.如果真结束
.如果真 (六十甲子纳音数组 [农历日期框1.农历年 - 1922 - 计次] = “木”)
木行文本 = 木行文本 + 取文本右边 (“0” + 到文本 (计次), 2) + “,”
.如果真结束
.如果真 (六十甲子纳音数组 [农历日期框1.农历年 - 1922 - 计次] = “水”)
水行文本 = 水行文本 + 取文本右边 (“0” + 到文本 (计次), 2) + “,”
.如果真结束
.如果真 (六十甲子纳音数组 [农历日期框1.农历年 - 1922 - 计次] = “火”)
火行文本 = 火行文本 + 取文本右边 (“0” + 到文本 (计次), 2) + “,”
.如果真结束
.如果真 (六十甲子纳音数组 [农历日期框1.农历年 - 1922 - 计次] = “土”)
土行文本 = 土行文本 + 取文本右边 (“0” + 到文本 (计次), 2) + “,”
.如果真结束
.计次循环尾 ()
C#生成逻辑中,我们首先生成一个六十甲子字符列表,并能根据六十甲子字符串,从六十甲子纳音表中获取主五行,代码如下所示:


代码
///
<summary>
///
获取六十甲子字符列表
///
</summary>
///
<returns></returns>
private
List
<
string
>
GetJiazhi()
{
string
str
=
@"
甲子 乙丑 丙寅 丁卯 戊辰 己巳 庚午 辛未 壬申 癸酉
甲戌 乙亥 丙子 丁丑 戊寅 己卯 庚辰 辛巳 壬午 癸未
甲申 乙酉 丙戌 丁亥 戊子 己丑 庚寅 辛卯 壬辰 癸巳
甲午 乙未 丙申 丁酉 戊戌 己亥 庚子 辛丑 壬寅 癸卯
甲辰 乙巳 丙午 丁未 戊申 己酉 庚戌 辛亥 壬子 癸丑
甲寅 乙卯 丙辰 丁巳 戊午 己未 庚申 辛酉 壬戌 癸亥
"
;
List
<
string
>
list
=
new
List
<
string
>
();
foreach
(
string
item
in
str.Split(
'
'
))
{
if
(
!
string
.IsNullOrEmpty(item))
{
list.Add(item.Replace(
"
\r\n
"
,
""
));
}
}
return
list;
}
///
<summary>
///
根据甲子获取纳音
///
</summary>
///
<param name="jiazhi"></param>
///
<returns></returns>
private
string
GetNayin(
string
jiazhi)
{
string
str
=
@"
甲子乙丑海中金 丙寅丁卯炉中火 戊辰己巳大林木 庚午辛未路旁土 壬申癸酉剑锋金
甲戌乙亥山头火 丙子丁丑涧下水 戊寅己卯城头土 庚辰辛巳白腊金 壬午癸未杨柳木
甲申乙酉泉中水 丙戌丁亥屋上土 戊子己丑劈雳火 庚寅辛卯松柏木 壬辰癸巳长流水
甲午乙未沙中金 丙申丁酉山下火 戊戌己亥平地木 庚子辛丑壁上土 壬寅癸卯金箔金
甲辰乙巳佛灯火 丙午丁未天河水 戊申己酉大驿土 庚戌辛亥插环金 壬子癸丑桑枝木
甲寅乙卯大溪水 丙辰丁巳沙中土 戊午己未天上火 庚申辛酉石榴木 壬戌癸亥大海水
"
;
int
iStart
=
str.IndexOf(jiazhi);
string
leftStr
=
str.Substring(iStart);
int
iSpace
=
leftStr.IndexOf(
'
'
);
leftStr
=
leftStr.Substring(
0
, iSpace);
leftStr
=
leftStr.Substring(leftStr.Length
-
1
,
1
);
return
leftStr;
}
继而我们把六十甲子列表、五行列表(金木水火土)、以及根据每一个六十甲子字符得到的五行列表放到变量中待用。如下所示
代码
//
甲子列表
List
<
string
>
jiazhiList
=
GetJiazhi();
//
纳音列表
List
<
string
>
nayinList
=
new
List
<
string
>
();
//
初始化五行数字字符串列表
Dictionary
<
string
,
string
>
wuhanStrList
=
new
Dictionary
<
string
,
string
>
() { };
wuhanStrList.Add(
"
金
"
,
""
);
wuhanStrList.Add(
"
木
"
,
""
);
wuhanStrList.Add(
"
水
"
,
""
);
wuhanStrList.Add(
"
火
"
,
""
);
wuhanStrList.Add(
"
土
"
,
""
);
{
string jiazhi = jiazhiList[i - 1];
string nayin = GetNayin(jiazhi);
nayinList.Add(nayin);
//this.textBox1.AppendText(nayin + Environment.NewLine);
}
最后我们根据1~49号码和当年的农历年数字,根据规则生成各五行的数字字符串,放到对应的五行数字字符串列表中,如下所示
代码
=
new
ChineseLunisolarCalendar();
for
(
int
i
=
1
; i
<=
49
; i
++
)
{
int
currentYear
=
chineseDate.GetYear(
this
.dateTimePicker1.Value);
int
index
=
currentYear
-
1922
-
i
-
1
;
string
itemName
=
nayinList[index
%
60
];
if
(itemName
==
"
金
"
)
{
wuhanStrList[
"
金
"
]
+=
i.ToString(
"
D2
"
)
+
"
,
"
;
}
else
if
(itemName
==
"
木
"
)
{
wuhanStrList[
"
木
"
]
+=
i.ToString(
"
D2
"
)
+
"
,
"
;
}
else
if
(itemName
==
"
水
"
)
{
wuhanStrList[
"
水
"
]
+=
i.ToString(
"
D2
"
)
+
"
,
"
;
}
else
if
(itemName
==
"
火
"
)
{
wuhanStrList[
"
火
"
]
+=
i.ToString(
"
D2
"
)
+
"
,
"
;
}
else
if
(itemName
==
"
土
"
)
{
wuhanStrList[
"
土
"
]
+=
i.ToString(
"
D2
"
)
+
"
,
"
;
}
}
foreach
(
string
key
in
wuhanStrList.Keys)
{
this
.textBox1.AppendText(
string
.Format(
"
{0}:{1}\r\n
"
, key, wuhanStrList[key]));
}
最后给出一个实例截图(
程序文件下载地址
):