FlinkSQL自定义函数开发
本次需求场景主要为实现将flinksql中collect()函数输出的Mutiset(VARCHAR<100>)多行结果转换为字符串。
一、FlinkSQL自定义函数分类
Flink SQL 的自定义函数是用户可以自行编写的一种函数,用于扩展 Flink SQL 的功能。自定义函数可以在 SQL 查询中被调用,以完成用户自定义的数据处理逻辑。 在 Flink SQL 中,自定义函数分为标量函数、表函数和聚合函数三种类型。
1、标量函数(Scalar Function)
标量函数接受一行输入,返回一行输出。常见的标量函数有字符串函数、数学函数等。用户可以通过继承 ScalarFunction 类或实现 ScalarFunction 接口的方式来实现自定义的标量函数。
2、表函数(Table Function)
表函数接受一行输入,返回多行输出。在 Flink SQL 中,表函数可以使用 LATERAL TABLE 语法进行调用。用户可以通过继承 TableFunction 类或实现 TableFunction 接口的方式来实现自定义的表函数。
3、聚合函数(Aggregate Function)
聚合函数接受多行输入,返回一行输出。在 Flink SQL 中,聚合函数可以使用 GROUP BY 语法进行调用。用户可以通过继承 AggregateFunction 类或实现 AggregateFunction 接口的方式来实现自定义的聚合函数。 在使用自定义函数时,需要将对应的 Jar 包提交到 Flink 集群中,并在执行任务时将其加入到 Classpath 中。Flink SQL 还提供了 CREATE FUNCTION 语句来注册用户自定义的函数,以便在 SQL 查询中进行调用。 总的来说,自定义函数是 Flink SQL 中非常重要的一个功能,可以帮助用户扩展 Flink SQL 的功能,提高数据处理的灵活性和效率。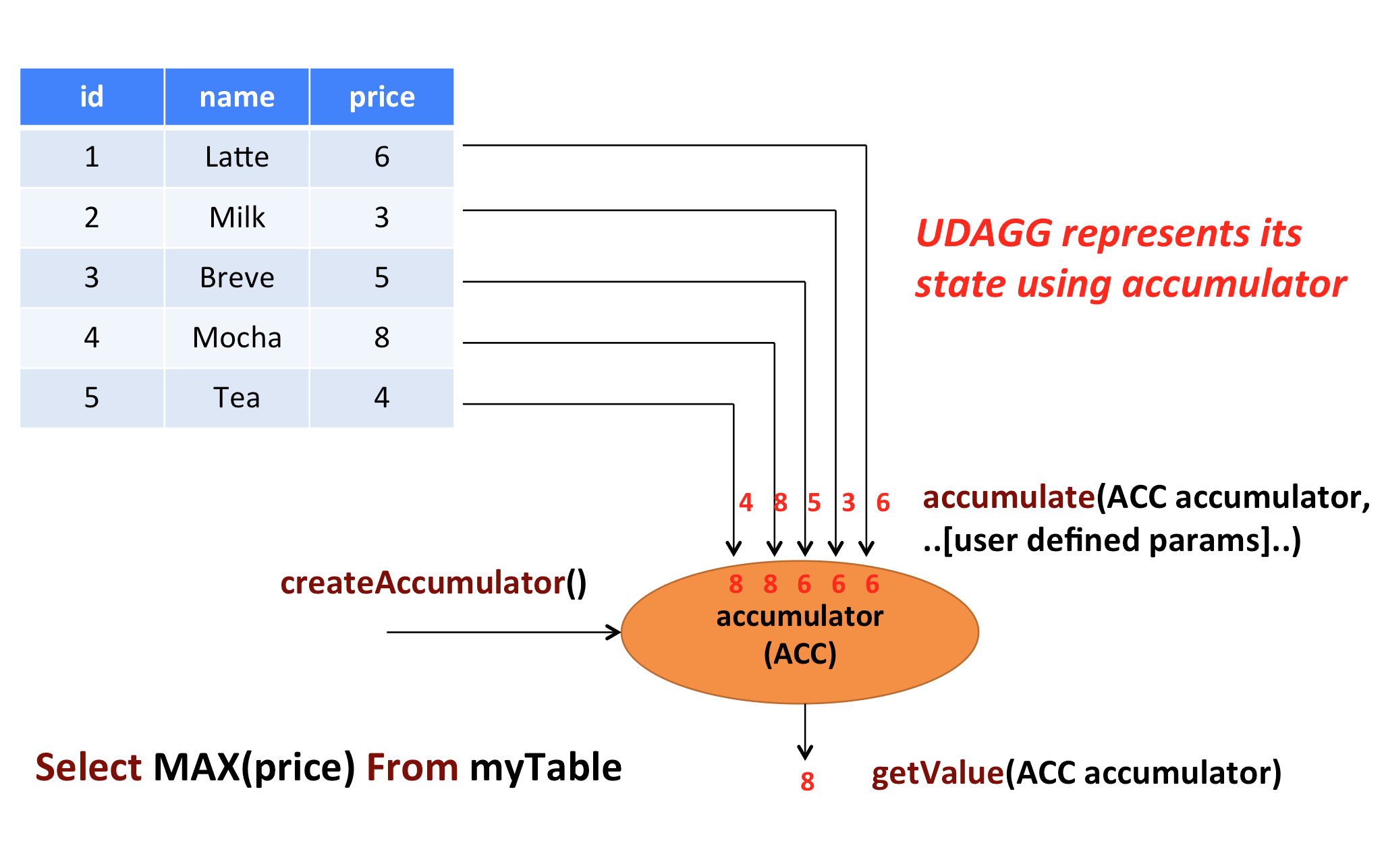
上面的图片展示了一个聚合的例子。假设你有一个关于饮料的表。表里面有三个字段,分别是 id、name、price,表里有 5 行数据。假设你需要找到所有饮料里最贵的饮料的价格,即执行一个 max() 聚合。你需要遍历所有 5 行数据,而结果就只有一个数值。
自定义聚合函数是通过扩展 AggregateFunction 来实现的。AggregateFunction 的工作过程如下。首先,它需要一个 accumulator,它是一个数据结构,存储了聚合的中间结果。通过调用 AggregateFunction 的 createAccumulator() 方法创建一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate() 方法来更新 accumulator。当所有的数据都处理完了之后,通过调用 getValue 方法来计算和返回最终的结果。
下面几个方法是每个 AggregateFunction 必须要实现的:
- createAccumulator()
- accumulate()
- getValue()
4、表值聚合函数
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。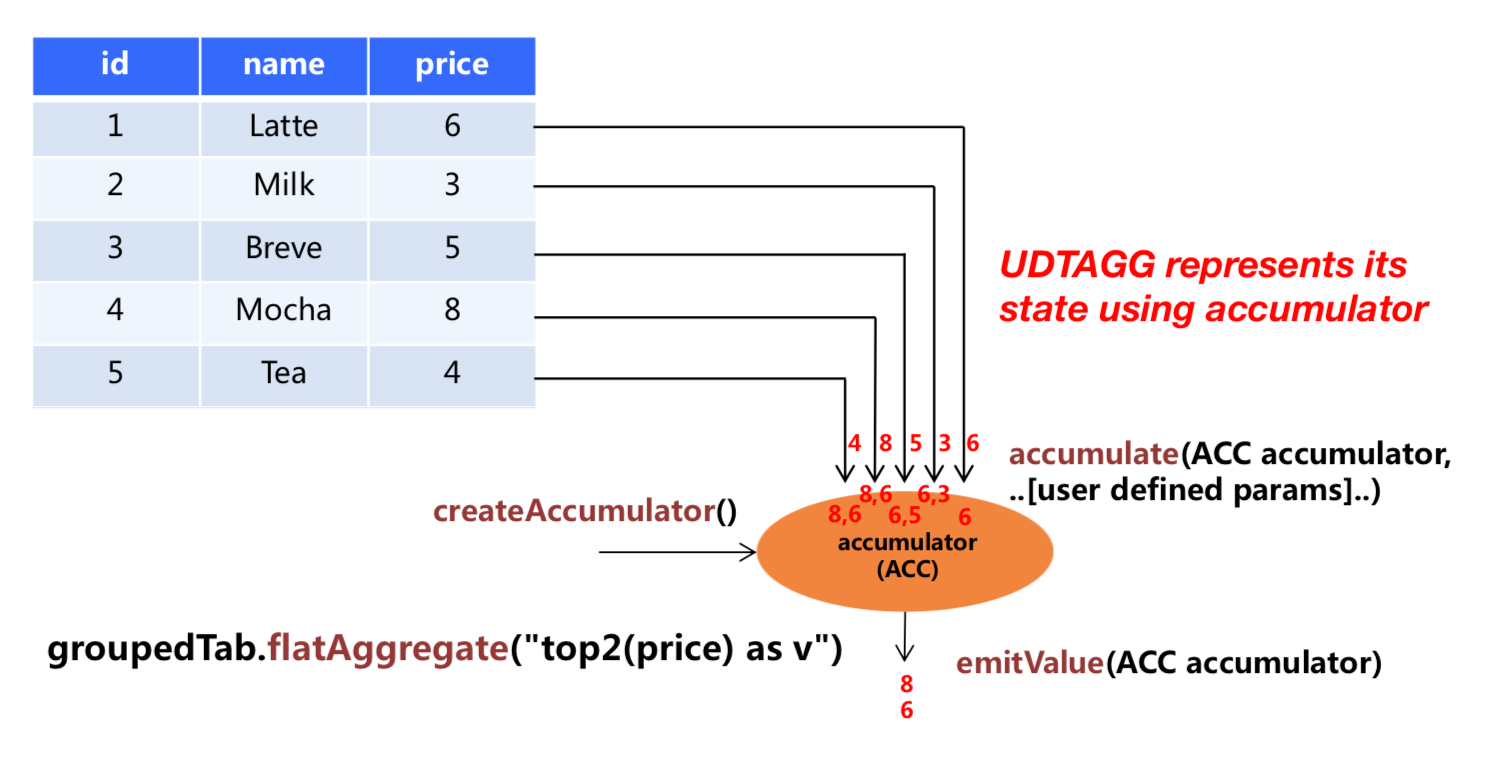
上图展示了一个表值聚合函数的例子。假设你有一个饮料的表,这个表有 3 列,分别是 id、name 和 price,一共有 5 行。假设你需要找到价格最高的两个饮料,类似于 top2() 表值聚合函数。你需要遍历所有 5 行数据,结果是有 2 行数据的一个表。
用户自定义表值聚合函数是通过扩展 TableAggregateFunction 类来实现的。一个 TableAggregateFunction 的工作过程如下。首先,它需要一个 accumulator,这个 accumulator 负责存储聚合的中间结果。 通过调用 TableAggregateFunction 的 createAccumulator 方法来构造一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate 方法来更新 accumulator。当所有数据都处理完之后,调用 emitValue 方法来计算和返回最终的结果。
下面几个 TableAggregateFunction 的方法是必须要实现的:
- createAccumulator()
- accumulate()
5、异步表值函数
异步表值函数是异步查询外部数据系统的特殊函数。
二、需求场景
1、需求描述
基于Flink1.14.4集群,有一批基于某个主键生成的collect函数结果数据,需要转换为字符串传到下游Kafka。由于collect()函数生成的结果是一个多行的集合MutiSet<varchar(100)>,FlinkSQL中暂未支持concat_ws或者concat函数,因此无法将collect生成的多行结果直接通过现有SQL函数转换为一行字符串。基于以上原因,需要开发一个自定义函数实现。
2、数据样例
CREATE TABLE "air_data_source_result" (
"id" int NOT NULL DEFAULT '0' COMMENT '主键',
"airlineLogo" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"airlineShortCompany" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrActCross" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrActTime" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrAirport" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrCode" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrOntimeRate" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrPlanCross" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrPlanTime" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"arrTerminal" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"checkInTable" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"checkInTableWidth" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"depActCross" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"depActTime" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"depAirport" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"depCode" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"depPlanCross" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"depPlanTime" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"depTerminal" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"flightNo" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"flightState" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"localDate" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"mainFlightNo" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"shareFlag" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
"stateColor" varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (1, 'https://cdn1.133.cn/ticket/airline/image_ca_cca.png', '中国国航', '', '11:11\n', '广州白云', 'CAN', '89.65%', '', '11:25', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '08:15\n', '北京首都', 'PEK', '', '08:00', 'T3', 'CA1351', '到达', '2023-02-27', '', '0', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (2, 'https://cdn1.133.cn/ticket/airline/image_zh_csz.png', '深圳航空', '', '11:11\n', '广州白云', 'CAN', '89.65%', '', '11:25', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '08:15\n', '北京首都', 'PEK', '', '08:00', 'T3', 'ZH1351', '到达', '2023-02-27', 'CA1351', '1', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (3, 'https://cdn1.133.cn/ticket/airline/image_hu_chh.png', '海南航空', '', '11:57\n', '广州白云', 'CAN', '75.86%', '', '11:50', 'T1B', 'https://api.133.cn/third/textImg?code=IfLOkkFeJagwbNuqYtoqNg==', '140', '', '08:51\n', '北京首都', 'PEK', '', '08:30', 'T2', 'HU7805', '到达', '2023-02-27', '', '0', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (4, 'https://cdn1.133.cn/ticket/airline/image_ca_cca.png', '中国国航', '', '12:14\n', '广州白云', 'CAN', '79.31%', '', '12:20', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '09:19\n', '北京首都', 'PEK', '', '09:00', 'T3', 'CA1321', '到达', '2023-02-27', '', '0', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (5, 'https://cdn1.133.cn/ticket/airline/image_zh_csz.png', '深圳航空', '', '12:14\n', '广州白云', 'CAN', '79.31%', '', '12:20', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '09:19\n', '北京首都', 'PEK', '', '09:00', 'T3', 'ZH1321', '到达', '2023-02-27', 'CA1321', '1', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (6, 'https://cdn1.133.cn/ticket/airline/image_hu_chh.png', '海南航空', '', '13:12\n', '广州白云', 'CAN', '96.55%', '', '13:40', 'T1B', 'https://api.133.cn/third/textImg?code=IfLOkkFeJagwbNuqYtoqNg==', '140', '', '10:07\n', '北京首都', 'PEK', '', '10:00', 'T2', 'HU7813', '到达', '2023-02-27', '', '0', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (7, 'https://cdn1.133.cn/ticket/airline/image_zh_csz.png', '深圳航空', '', '14:22\n', '广州白云', 'CAN', '82.75%', '', '14:25', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '11:22\n', '北京首都', 'PEK', '', '11:00', 'T3', 'ZH1315', '到达', '2023-02-27', 'CA1315', '1', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (8, 'https://cdn1.133.cn/ticket/airline/image_ca_cca.png', '中国国航', '', '14:22\n', '广州白云', 'CAN', '82.75%', '', '14:25', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '11:22\n', '北京首都', 'PEK', '', '11:00', 'T3', 'CA1315', '到达', '2023-02-27', '', '0', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (9, 'https://cdn1.133.cn/ticket/airline/image_zh_csz.png', '深圳航空', '', '15:13\n', '广州白云', 'CAN', '78.57%', '', '15:25', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '12:19\n', '北京首都', 'PEK', '', '12:00', 'T3', 'ZH1339', '到达', '2023-02-27', 'CA1339', '1', '#4273FE');
INSERT INTO `air_data`.`air_data_source_result` (`id`, `airlineLogo`, `airlineShortCompany`, `arrActCross`, `arrActTime`, `arrAirport`, `arrCode`, `arrOntimeRate`, `arrPlanCross`, `arrPlanTime`, `arrTerminal`, `checkInTable`, `checkInTableWidth`, `depActCross`, `depActTime`, `depAirport`, `depCode`, `depPlanCross`, `depPlanTime`, `depTerminal`, `flightNo`, `flightState`, `localDate`, `mainFlightNo`, `shareFlag`, `stateColor`) VALUES (10, 'https://cdn1.133.cn/ticket/airline/image_ca_cca.png', '中国国航', '', '15:13\n', '广州白云', 'CAN', '78.57%', '', '15:25', 'T1B', 'https://api.133.cn/third/textImg?code=FvOGTb%2Bgbgxpgw9zPNG2Qw==', '30', '', '12:19\n', '北京首都', 'PEK', '', '12:00', 'T3', 'CA1339', '到达', '2023-02-27', '', '0', '#4273FE');
3、FlinkSQL表连接
create table air_data_source(
id int COMMENT '主键',
airlineLogo varchar(100) ,
airlineShortCompany varchar(100) ,
arrActCross varchar(100) ,
arrActTime varchar(100) ,
arrAirport varchar(100) ,
arrCode varchar(100) ,
arrOntimeRate varchar(100) ,
arrPlanCross varchar(100) ,
arrPlanTime varchar(100) ,
arrTerminal varchar(100) ,
checkInTable varchar(100) ,
checkInTableWidth varchar(100) ,
depActCross varchar(100) ,
depActTime varchar(100) ,
depAirport varchar(100) ,
depCode varchar(100) ,
depPlanCross varchar(100) ,
depPlanTime varchar(100) ,
depTerminal varchar(100) ,
flightNo varchar(100) ,
flightState varchar(100) ,
localDate varchar(100) ,
mainFlightNo varchar(100) ,
shareFlag varchar(100) ,
stateColor varchar(100)
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/air_data?serverTimezone=GMT%2B8',
'username' = 'root',
'password' = 'root',
'table-name' = 'air_data_source'
)
;
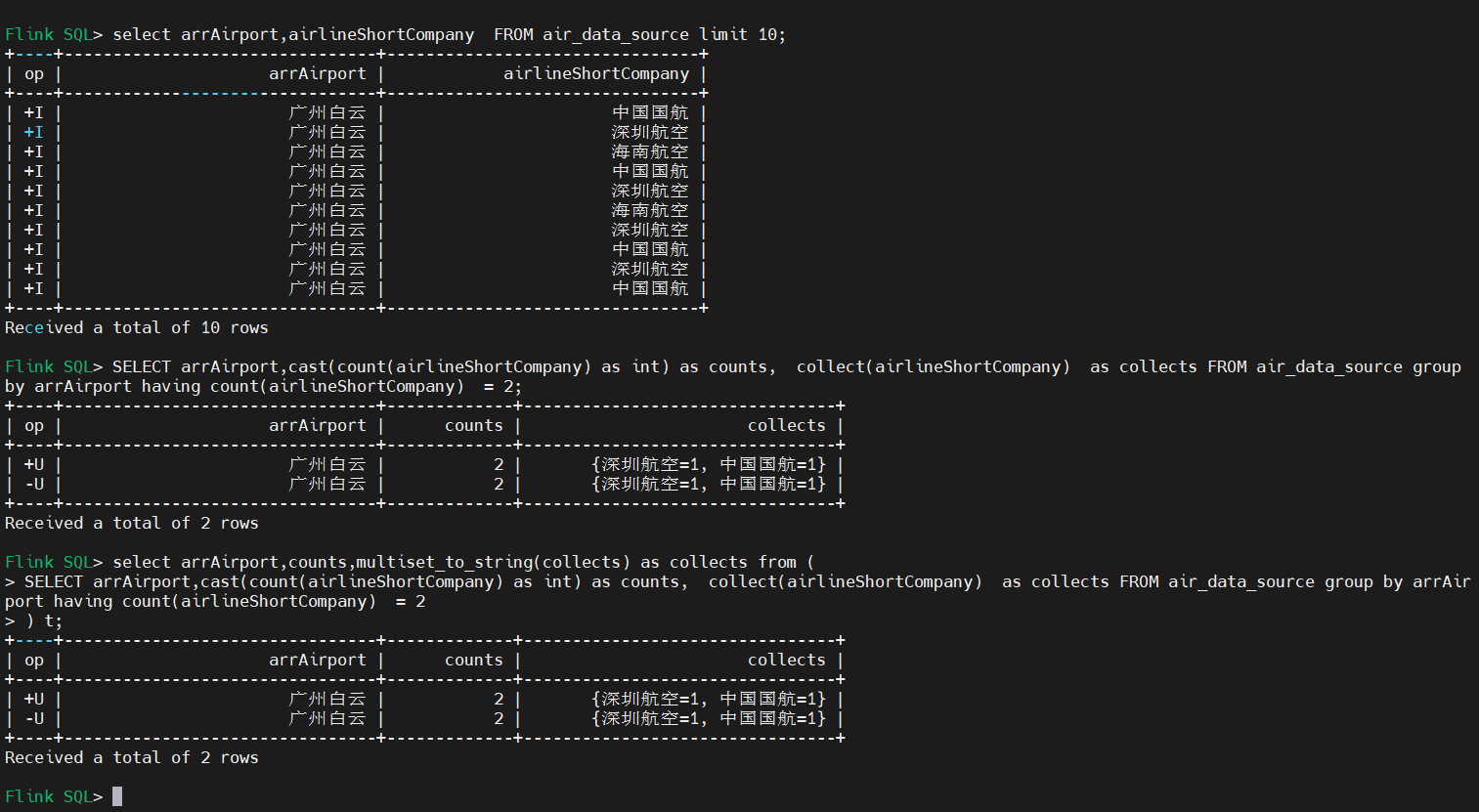
4、collect()函数结果
SELECT arrAirport,cast(count(airlineShortCompany) as int) as counts, collect(airlineShortCompany) as collects FROM air_data_source group by arrAirport having count(airlineShortCompany) = 2
三、FlinkSQL UDF 代码开发
1、pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xxxxx.tech</groupId>
<artifactId>alarmCollectPlatform</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<flink.version>1.14.4</flink.version>
</properties>
<dependencies>
<!-- flink依赖引入-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
2、java代码实现
package com.xxxxx.tech.udf;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction;
import java.util.Map;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.ResultTypeQueryable;
public class MultisetToString extends ScalarFunction implements ResultTypeQueryable<String> {
public String eval(@DataTypeHint("MULTISET<STRING>") Map<String, Integer> multiset) {
return multiset.toString();
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
}
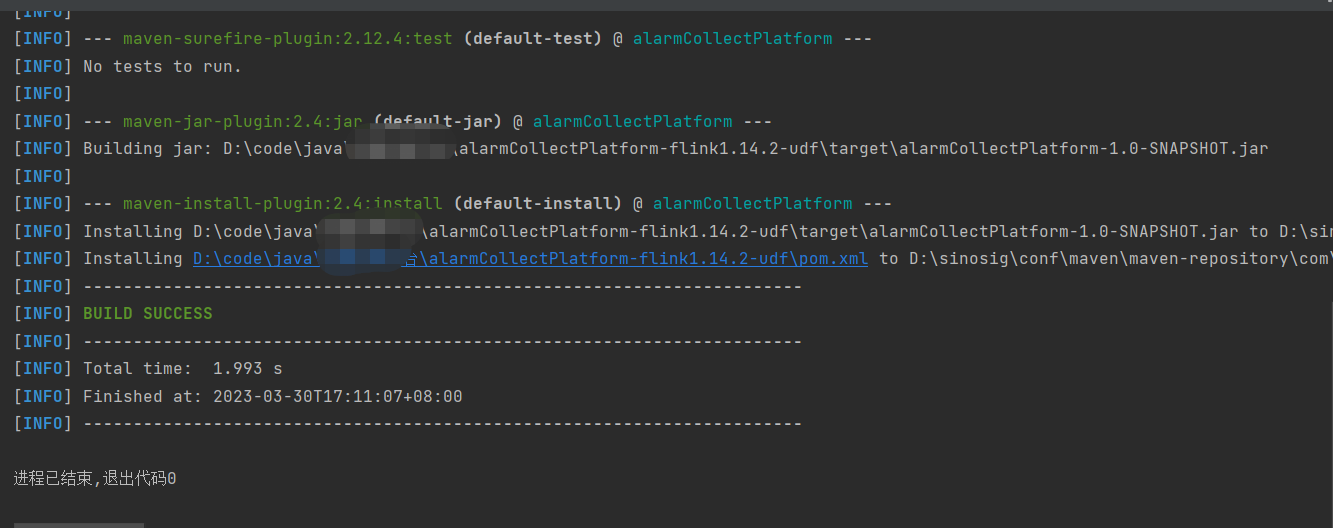
3、打包
mvn clean install
4、上传
将打好的jar包上传到Flink_HOME的lib目录下,并重启集群
5、注册函数
进入bin目录启动sql-client,注册函数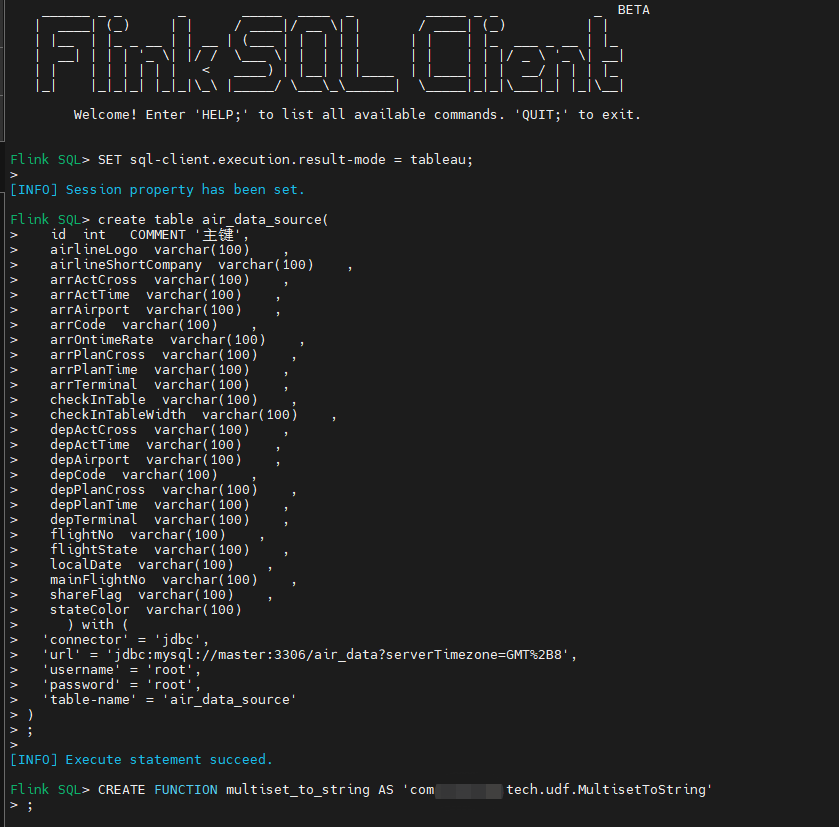
6、使用函数进行转换
select arrAirport,counts,multiset_to_string(collects) as collects from (
SELECT arrAirport,cast(count(airlineShortCompany) as int) as counts, collect(airlineShortCompany) as collects FROM air_data_source group by arrAirport having count(airlineShortCompany) = 2
) t