程序员的自我修养-编译链接
常见场景
你是在工作中遇到如下问题或者疑问:
- undefined reference to “function”。链接过程中出现未定义引用。
- .a和.so文件分别是什么?什么情况下使用?
- extern "C"有什么作用?
等等...
编译过程
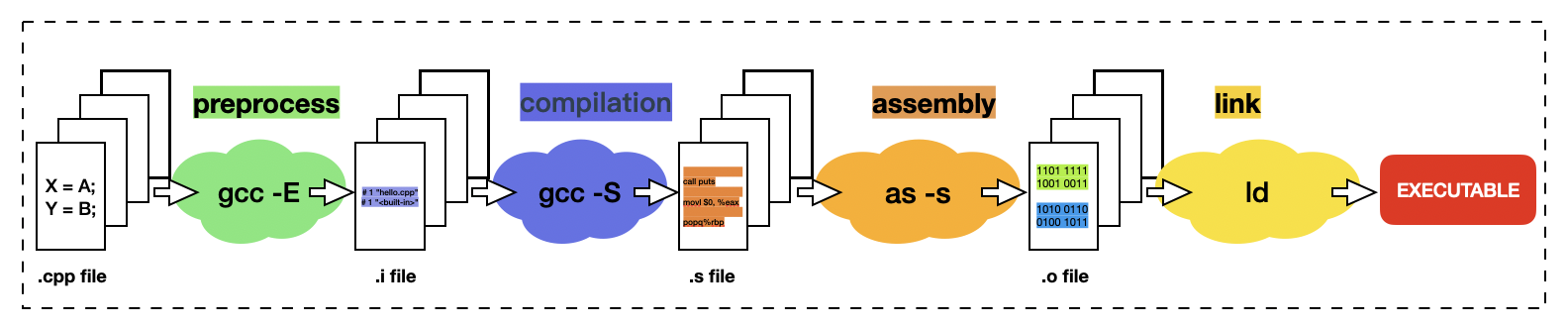
我们平时编译,如果没有加任何编译参数将默认执行预处理,编译,汇编,链接等步骤。
ELF文件格式
每一个cpp文件会生成一个.o文件。.o文件里面有什么信息?多个.o文件如何合并成一个可执行文件。可执行文件的文件里有都有什么信息?
看下下面的例子:
int global_init_var = 84;
int global_uninit_var;
void func1(int i) {
printf("%d\n", i);
}
int main() {
static int static_var = 85;
static int static_var2;
int a = 1;
int b;
func1(static_var + static_var2 + a + b);
return 0;
}
为了探究.o文件内容,只编译不链接
gcc -c whats_in_elf.c -o whats_in_elf.o
ELF可以用objdump,readelf等工具查看内容。这里用readelf -S whats_in_elf.o查看section headers:
# daihaonan link_load $ readelf -S whats_in_elf.o
There are 11 section headers, starting at offset 0x114:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 000051 00 AX 0 0 4
[ 2] .rel.text REL 00000000 000424 000028 08 9 1 4
[ 3] .data PROGBITS 00000000 000088 000008 00 WA 0 0 4
[ 4] .bss NOBITS 00000000 000090 000004 00 WA 0 0 4
[ 5] .rodata PROGBITS 00000000 000090 000004 00 A 0 0 1
[ 6] .comment PROGBITS 00000000 000094 00002d 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 00000000 0000c1 000000 00 0 0 1
[ 8] .shstrtab STRTAB 00000000 0000c1 000051 00 0 0 1
[ 9] .symtab SYMTAB 00000000 0002cc 0000f0 10 10 10 4
[10] .strtab STRTAB 00000000 0003bc 000065 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings)
I (info), L (link order), G (group), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
可以看到.o文件由很多section组成,每个section都有size, file off等描述其在文件内位置的属性。元信息记录在File header中,其中有e_shoff字段指向Section Header Table,Section Header Table是个数组结构保存每个Section信息。
查看Header: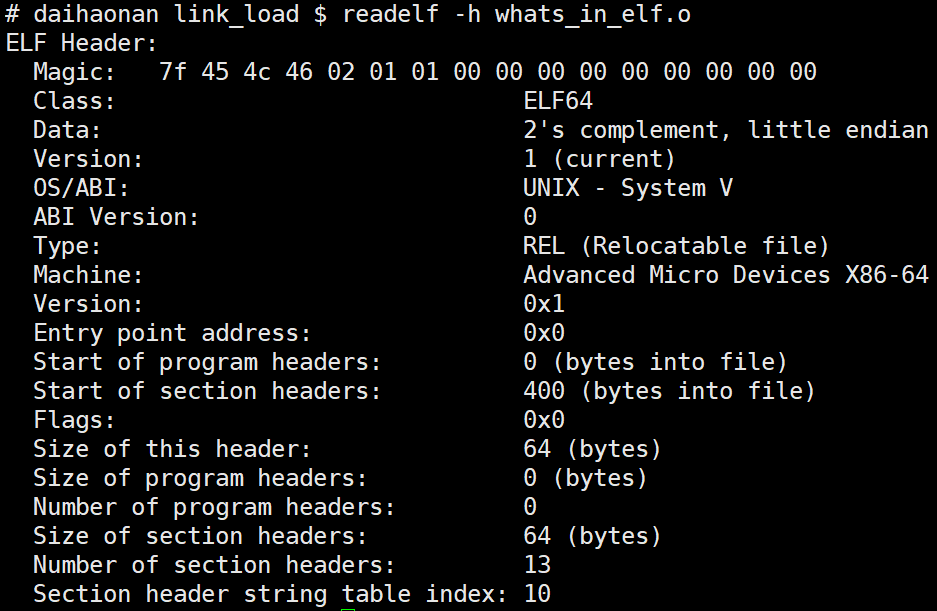
.o文件总体格式如下: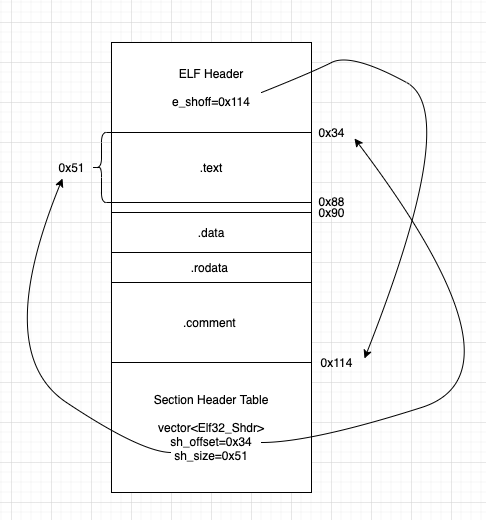
当然还有很多其它section,.text,.data,.rodata,.symtab,.rel.text段是最主要的段,分别保存代码信息,全局数据,全局只读数据,符号表,代码段重定位表。
.text Section
将代码反汇编
objdump -s -d whats_in_elf.o
# daihaonan link_load $ objdump -d whats_in_elf.o
whats_in_elf.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func1>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 89 c6 mov %eax,%esi
10: bf 00 00 00 00 mov $0x0,%edi
15: b8 00 00 00 00 mov $0x0,%eax
1a: e8 00 00 00 00 callq 1f <func1+0x1f>
1f: c9 leaveq
20: c3 retq
0000000000000021 <main>:
21: 55 push %rbp
22: 48 89 e5 mov %rsp,%rbp
25: 48 83 ec 10 sub $0x10,%rsp
29: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp)
30: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 36 <main+0x15>
36: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 3c <main+0x1b>
3c: 8d 04 02 lea (%rdx,%rax,1),%eax
3f: 03 45 f8 add -0x8(%rbp),%eax
42: 03 45 fc add -0x4(%rbp),%eax
45: 89 c7 mov %eax,%edi
47: e8 00 00 00 00 callq 4c <main+0x2b>
4c: b8 00 00 00 00 mov $0x0,%eax
51: c9 leaveq
52: c3 retq
可以看到func1和main两个函数的反汇编代码。
顺便可以了解下gcc函数调用约定。
规则如下:
- 执行call指令前,函数调用者将参数入栈,按照函数列表从右到左的顺序入栈。
- call指令会自动将当前eip入栈,ret指令将自动从栈中弹出该值到eip寄存器。
- 被调用函数负责:将ebp入栈,esp的值赋给ebp。所以反汇编一个函数会发现开头两个指令都是
push %ebp, mov %esp,%ebp
一个例子:
.data和.rodat Section
Contents of section .data:
0000 54000000 55000000 T...U...
Contents of section .rodata:
0000 25640a00 %d..
可以看到.data Section有8个字节,分别是0x54和0x55对应全局变量static_var和global_init_var。
.rodata Section只有4个字节保存%d\n三个字符。
从这里可以直观看到全局有初值的变量是会在ELF文件中分配空间的,而a,b这种栈上分配的变量不会ELF文件中分配空间,只会在运行到该函数的是在栈上动态分配。
.symtab Section
可以用
readelf -s whats_in_elf.o
查看符号表
# daihaonan link_load $ readelf -s whats_in_elf.o
Symbol table '.symtab' contains 16 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS whats_in_elf.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000004 4 OBJECT LOCAL DEFAULT 3 static_var.1600
7: 0000000000000000 4 OBJECT LOCAL DEFAULT 4 static_var2.1601
8: 0000000000000000 0 SECTION LOCAL DEFAULT 7
9: 0000000000000000 0 SECTION LOCAL DEFAULT 8
10: 0000000000000000 0 SECTION LOCAL DEFAULT 6
11: 0000000000000000 4 OBJECT GLOBAL DEFAULT 3 global_init_var
12: 0000000000000004 4 OBJECT GLOBAL DEFAULT COM global_uninit_var
13: 0000000000000000 33 FUNC GLOBAL DEFAULT 1 func1
14: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND printf
15: 0000000000000021 50 FUNC GLOBAL DEFAULT 1 main
从上面可以得到如下信息:
- 该.o文件中有static_var.1600,static_var2.1601,global_init_var,global_uninit_var,func1,printf,main等符号
- 每个符号在.o文件中的位置,比如func1,Ndx是1,对应.text Section,Value为0,Size为33,说明func1从.text Section起始字节开始,占了33个字节。
- printf这个符号在.o文件中并没有定义,所以它的Ndx是UND
用
g++ whats_in_elf.c -o whats_in_elf2.o
重新编译,会发现
# daihaonan link_load $ readelf -s whats_in_elf2.o
Symbol table '.symtab' contains 17 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS whats_in_elf.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000004 4 OBJECT LOCAL DEFAULT 3 _ZZ4mainE10static_var
7: 0000000000000004 4 OBJECT LOCAL DEFAULT 4 _ZZ4mainE11static_var2
8: 0000000000000000 0 SECTION LOCAL DEFAULT 7
9: 0000000000000000 0 SECTION LOCAL DEFAULT 8
10: 0000000000000000 0 SECTION LOCAL DEFAULT 6
11: 0000000000000000 4 OBJECT GLOBAL DEFAULT 3 global_init_var
12: 0000000000000000 4 OBJECT GLOBAL DEFAULT 4 global_uninit_var
13: 0000000000000000 33 FUNC GLOBAL DEFAULT 1 _Z5func1i
14: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND __gxx_personality_v0
15: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _Z6printfPKcz
16: 0000000000000021 50 FUNC GLOBAL DEFAULT 1 main
原来的func1变成了_Z5func1i,为了防止符号冲突,C++引入了符号修饰的概念。
所以在C++里如果希望动态库中某个函数能被正确加载,需要加上
extern "C"
方式符号被修饰,比如:
extern "C"
{
ProcessorBase* create_processor(const std::string& processor_name)
{
...
}
}
加载该符号的地方才能正确找到create_processor这个符号。
(PFUNC_CREATE_PROCESSOR_CALL)dlsym(handle,"create_processor");
.rel.text Section
对于可重定位的ELF文件,必须包含重定位Section,一个ELF文件中可能有多个重定位Section,比如.text有需要重定位的地方,那么会有一个.rel.text表,详细见下文。
静态链接
为什么需要链接?
考虑如下程序:
a.c
extern int shared;
int main() {
int a = 100;
swap(&a, &shared);
}
b.c
int shared = 1;
void swap(int* a, int* b) {
*a ^= *b ^= *a ^= *b;
}
分别将a.c和b.c进行编译,然后查看代码段反汇编。
# daihaonan link_load $ objdump -d a.o
a.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
f: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 15 <main+0x15>
15: 8b 45 fc mov -0x4(%rbp),%eax
18: 89 d6 mov %edx,%esi
1a: 89 c7 mov %eax,%edi
1c: b8 00 00 00 00 mov $0x0,%eax
21: e8 00 00 00 00 callq 26 <main+0x26>
26: c9 leaveq
27: c3 retq
main中会引用全局变量shared,调用swap函数,但是shared和swap都不是定义在a.o中的,而是定义在b.o中。所以a.o中对shared的引用为0x0(%rip),%rip寄存器中保存的是当前执行指令的地址,对swap调用为e8 00 00 00 00,这是一条
近址相对位移调用指令
,e8是指令码,00 00 00 00是操作数,也就是被调用函数相对于
调用指令的下一条指令
的偏移量。这里因为不知道swap函数在哪,所以暂时用00 00 00 00来代替。
所以我们可以得出链接的一个主要作用是对一些全局变量,函数引用指令进行修正。
链接后达到什么效果?
将a.o和b.o链接在一起。ld a.o b.o -e main -o ab
然后再来看下ab中main的反汇编代码
# daihaonan link_load $ objdump -S ab
ab: file format elf64-x86-64
Disassembly of section .text:
00000000004000e8 <main>:
4000e8: 55 push %rbp
4000e9: 48 89 e5 mov %rsp,%rbp
4000ec: 48 83 ec 10 sub $0x10,%rsp
4000f0: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
4000f7: 8b 15 bb 00 20 00 mov 0x2000bb(%rip),%edx # 6001b8 <shared>
4000fd: 8b 45 fc mov -0x4(%rbp),%eax
400100: 89 d6 mov %edx,%esi
400102: 89 c7 mov %eax,%edi
400104: b8 00 00 00 00 mov $0x0,%eax
400109: e8 02 00 00 00 callq 400110 <swap>
40010e: c9 leaveq
40010f: c3 retq
链接后再来看main函数的反汇编代码。有三个地方变动了
mov 0x0(%rip),%edx
变成了
mov 0x2000bb(%rip),%edx
,
e8 00 00 00 00
变成了
e8 02 00 00 00
。最左侧的地址变成了全局的虚拟地址,这说明链接还会分配虚拟地址空间,链接结束,每个函数,每个全局变量在虚拟地址空间内的地址就确定了。
callq下一条指令地址为0x40010e再加上0x02,等于0x400110。所以swap函数代码起始地址应该是0x400110。用objdump -S ab来验证下。
0000000000400110 <swap>:
400110: 55 push %rbp
400666666: 48 89 e5 mov %rsp,%rbp
400114: 53 push %rbx
400115: 48 89 7d f0 mov %rdi,-0x10(%rbp)
400119: 48 89 75 e8 mov %rsi,-0x18(%rbp)
40011d: 48 8b 45 f0 mov -0x10(%rbp),%rax
400121: 8b 10 mov (%rax),%edx
400123: 48 8b 45 e8 mov -0x18(%rbp),%rax
400127: 8b 08 mov (%rax),%ecx
400129: 48 8b 45 f0 mov -0x10(%rbp),%rax
40012d: 8b 18 mov (%rax),%ebx
40012f: 48 8b 45 e8 mov -0x18(%rbp),%rax
400133: 8b 00 mov (%rax),%eax
400135: 31 c3 xor %eax,%ebx
400137: 48 8b 45 f0 mov -0x10(%rbp),%rax
40013b: 89 18 mov %ebx,(%rax)
40013d: 48 8b 45 f0 mov -0x10(%rbp),%rax
400141: 8b 00 mov (%rax),%eax
400143: 31 c1 xor %eax,%ecx
400145: 48 8b 45 e8 mov -0x18(%rbp),%rax
400149: 89 08 mov %ecx,(%rax)
40014b: 48 8b 45 e8 mov -0x18(%rbp),%rax
40014f: 8b 00 mov (%rax),%eax
400151: 31 c2 xor %eax,%edx
400153: 48 8b 45 f0 mov -0x10(%rbp),%rax
400157: 89 10 mov %edx,(%rax)
400159: 5b pop %rbx
40015a: c9 leaveq
40015b: c3 retq
果然swap起始地址是0x400110。
a.o+b.o到ab的过程大致如下图: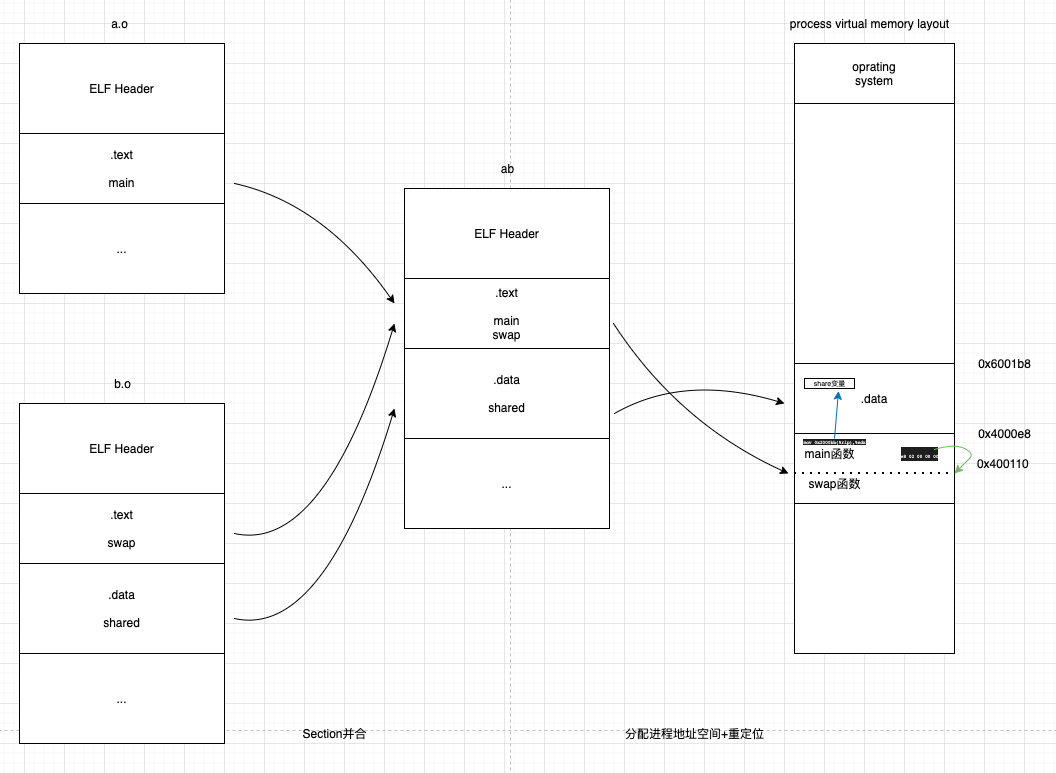
第一步对a.o和b.o相同的Section进行并合。
第二步将ab映射到进行虚拟地址空间,并确定各符号在进行虚拟地址空间中的地址。
第三步修正各符号引用,使其指向符号最终的地址。
怎么链接?
链接一般分为两步:
- 空间和地址分配。扫码所有输入目标文件,搜集符号定义和引用,放到全局符号表,并对Section进行并合。
- 符号解析和重定位。
符号重定位依赖重定位表+符号表
# daihaonan link_load $ objdump -r a.o
a.o: file format elf64-x86-64
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000011 R_X86_64_PC32 shared-0x0000000000000004
0000000000000022 R_X86_64_PC32 swap-0x0000000000000004
重定位表中记录了哪些地方需要修正,这里可以看到.text的0x11偏移处引用了shared变量,所以需要修正,.text的0x22偏移处引用了swap函数,也需要修正,
而.symtab Section记录了符号所在的位置。
# daihaonan link_load $ readelf -s b.o
Symbol table '.symtab' contains 10 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS b.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 2
4: 0000000000000000 0 SECTION LOCAL DEFAULT 3
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000000 0 SECTION LOCAL DEFAULT 6
7: 0000000000000000 0 SECTION LOCAL DEFAULT 4
8: 0000000000000000 4 OBJECT GLOBAL DEFAULT 2 shared
9: 0000000000000000 76 FUNC GLOBAL DEFAULT 1 swap
链接器有了这俩信息,可以轻而易举完成符号重定位。
动态链接
静态链接VS动态链接
动态链接优点:
- 方便发布。模块A依赖模块B,如果模块B实现发生了改变,在静态链接的情况下,模块A需要重新编译。
- 内存占用。模块A和模块B都依赖模块C中的某个函数func,在果静态链接的情况下,模块A/B同时运行时,func需要在内存中存在两份。
动态链接缺点:
- 执行效率不如静态链接高。
动态链接效果
静态共享库
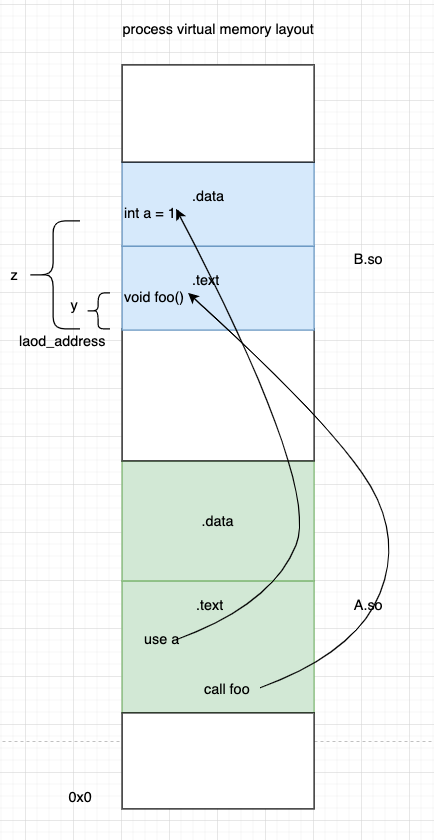
如图假设A.so又依赖B.so中的a变量和foo函数,当调用foo的时候,动态链接器会将B.so加载到内存load_address处,foo在B.so内是固定的y字节偏移出。所以foo在进程内的虚拟地址就是load_address+y。然后动态链接器修改A.so中call foo指令出代码,将foo地址修改为load_address+y。至此动态链接完成。和静态链接的区别在于动态链接将地址重定位推迟到了运行时。
动态共享库
上面这种静态共享库有个问题,就是指令部分没法在多个进程之间共享,从而失去了节省内存的优点。
假设有两个进程,做的事情都是A.so中调用B.so中的foo函数和引用a变量。
进程1A.so被加载到a0虚拟地址,进程2中A.so被动态加载到a1虚拟地址,静态共享库的虚拟内存分布如下:
A.so中的代码会被重定位,并且重定位值不一样,进程1中a变量在虚拟地址load_address1+x处,而在进程2中a变量在虚拟地址load_address2+x处。所以A.so的代码在内存中需要保存多份。
如果我们把需要重定位的地方单独抽出来放到数据区,这样a变量被加载到哪个地址,代码部分都不需要变动,那么两个进程可以只在物理内存中加载一份代码。使用这种机制的共享库叫做动态共享库。
相同的动态共享库的虚拟内存分布如下:
这种模式下,代码中需要被重定位的地方被放到了GOT中,动态加载重定位的时候只需要修改GOT就可以了,代码部分不需要被修改。缺点也很明显就是多了一层索引。
这就是-fPIC链接选项的作用。该链接选项指定生成的动态库为动态共享库。