2023年3月
创建镜像发布到镜像仓库【不依赖docker环境】
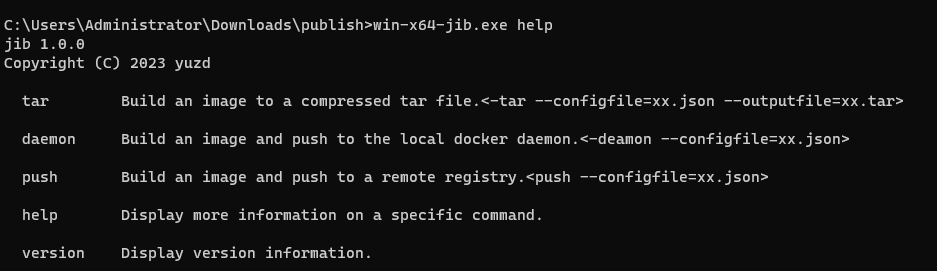
如今,docker镜像常用于工具的分发,demo的演示,第一步就是得创建docker镜像。 Google开发的jib 介于上述原因,来介绍我开发的这款工具,名字也叫jib,只不过它是一个纯粹构建镜像工具,支持win,linux,osx三个平台 我的口号是: 功能包含: 工具地址: 它是一个纯粹构建镜像命令行工具,根据不同的功能有不同的参数,如下图 作为一个纯粹的构建镜像工具,它不需要依赖docker环境,只需要读取一个json配置文件,根据配置生成镜像 推送到镜像仓库的配置示例(从阿里云镜像仓库拉取base镜像+我要加的目录=新的镜像并推送到私有仓库): 示例 json配置参数就少了推送相关的参数 本地tar文件的镜像,可以通过docker load命令在装载到docker环境中。 json配置和tar差不多 该工具支持多平台(linux、win、mac) 17M左右大小,不依赖docker环境,独立构建镜像速度很快,除了第一次基础镜像的拉取需要时间,有缓存的话只需要几秒搞定 适用于在CICD流水线中使用。 我也集成到了我的AntDeploy一键发布工具中, 开源地址: 微软最有价值专家(MVP),.NET 技术专家,热爱开源,关注并喜欢研究前沿技术,热衷于技术和经验分享,长期撰写技术博客,活跃于开源社区。
工具背景
一般入门都会安装docker,然后用dockerFile来创建镜像,除此以外你还想过有更高效的方式吗?
不依赖docker环境
也能
创建
docker或者OCI类型的
镜像
,但是可惜它只为java应用而生,其他类型的比如nodejs,.net应用都无法用,而且它是作为maven/gradle的插件形式来工作的,而不是一个纯粹独立构建镜像的工具。Build container images for your any applications.
https://github.com/yuzd/jib
工具使用
windows平台
macos平台
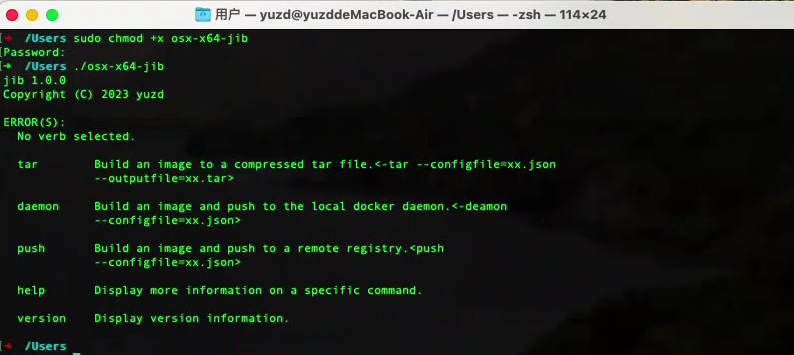
json配置文件
命令: jib.exe -push --configfile=demo.json
{
"BaseHttpProxy": "",
"BaseImage": "ccr.ccs.tencentyun.com/dotnet-core/aspnet:2.2",
"BaseImageCredential": {
"UserName": "aaaaaaaa",
"Password": "xxxxx"
},
"TargetHttpProxy": "",
"TargetImage": "http://127.0.0.1:5000/test1",
"TargetTags": [
"1.0.1"
],
"TargetImageCredential": {
"UserName": "aaaa",
"Password": "xxxx"
},
"ImageFormat": "Docker",
"ImageLayersFolder": "E:\\workspace\\demo\\publish",
"ImageWorkingDirectory": "/publish",
"Entrypoint": [
"dotnet"
],
"Cmd": [
"/publish/RazorTestProject.dll"
],
"ApplicationLayersCacheDirectory": "E:\\workspace\\cache",
"SkipExistingImages":true,
"IgnoreList":[
"支持正则"
]
"Env":{
"env1":"value1"
},
"Ports":[
{
"port":8080,
"protocol":"tcp"
}
],
"Volumes":[
"/var/log",
"/var/log2"
]
}
字段名
含义
备注
BaseHttpProxy
代理
拉取基础镜像的时候看你需要,格式 ip:port
BaseImage
基础镜像地址
完整地址,包含了版本,如果仓库地址没有https,请在最前面加上http://
BaseImageCredential
拉取基础镜像如果要登录
账户名+密码
TargetHttpProxy
代理
只有在推送到远程镜像且你有需要,才需要配置 格式ip:port
TargetImage
目标镜像
要推送的目标镜像仓库地址,不包含版本,如果仓库地址没有https,请在最前面加上http://
TargetTags
镜像标签
可以理解为版本号
TargetImageCredential
如果目标镜像仓库要登录
账户名+密码
ImageFormat
镜像仓库构建格式
Docker和OCI两种
ImageLayersFolder
要打包进镜像仓库的目录
通常这就是你的项目成果物
ImageWorkingDirectory
打包的目标仓库的工作目录
如果设置那你的文件们都会在这个目录下工作
Entrypoint
镜像启动的入口
比如dotnet
Cmd
镜像启动执行的参数
供Entrypoint使用
ApplicationLayersCacheDirectory
程序在运行时候会产生缓存目录来加快下次构建速度
可以不指定,会用temp目录
Env
环境变量
可以不指定,容器启动指定也行
Ports
端口
可以不指定,容器启动指定也行
Volumes
共享目录
可以不指定,容器启动指定也行
SkipExistingImages
如果目标仓库有一模一样的镜像就不会上传
比对的是镜像sha256
IgnoreList
要打包的目录里面可以排除某些文件
正则表达式
tar格式镜像文件本地生成
命令: jib.exe -tar --configfile=demo.json --outfile=demo.tar
{
"BaseHttpProxy": "",
"BaseImage": "ccr.ccs.tencentyun.com/dotnet-core/aspnet:2.2",
"BaseImageCredential": {
"UserName": "aaaaaaaa",
"Password": "xxxxx"
},
"ImageFormat": "Docker",
"ImageLayersFolder": "E:\\workspace\\demo\\publish",
"ImageWorkingDirectory": "/publish",
"Entrypoint": [
"dotnet"
],
"Cmd": [
"/publish/RazorTestProject.dll"
]
}推送镜像到本机的docker环境
命令: jib.exe -deamon --configfile=demo.json写到最后
https://github.com/yuzd/AntDeploy
.net应用可以下载AntDeploy Vs插件, 可以在vs中一键发布镜像推送到镜像仓库功能,还支持一键部署到iis,windows/linux服务 欢迎试用~关于我


如何设计一个微博系统?- 4招教你搞定系统设计

经常在面试的时候,会被问到系统设计类的题目,比如如何设计微信朋友圈、如何设计12306系统、如何设计一个抢票系统等等。如果是没有准备过,一般都会不知所措,难以找到切入点。今天这里码老思会介绍一个解决系统设计类问题的通用框架,无论什么问题,朝这几步走,一定能找到解决办法。
系统设计在考察什么?
系统设计面试中,经常会被问到如何设计微信、如何设计微博、如何设计百度……我们怎么能在如此短的时间内设计出来一个由成千上万的码农、PM,经年累月地迭代出来的如此优秀的产品?如果面试者这么优秀,那还面试啥?百度、谷歌也不可能只是一个搜索框而已,底下的东西复杂去了。
所以首先要明确,系统问题的答案一定不可能是全面的,面试官也不会期望我们给出一个满分答案。所谓的系统设计面试实际上是在模拟一个场景:两名同事在一起就一个模糊的问题,讨论一番,得出一个还不错的解决方案。
因此在这个过程中,我们需要与面试官进行充分的沟通,了解清楚需求,回应面试管的各种问题,阐述我们设计的方案。最终设计的结果是开放性的,没有标准答案;而面试官会在这个过程中,会充分挖掘我们的沟通、分析、解决问题的能力,最后给出通过与否的结论。
常见误区
没有方向,只提出各种关键词
在面试中,常见的错误是面试官给出问题后,候选人就开始怼各种关键词,什么Load Balancer,Memcache,NodeJS,MongoDB,MySQL.
不是说我们不能说这些技术词汇,但是系统设计首先我们需要搞清楚具体的需求,然后在大概确定系统架构,最后才根据场景进行技术选型,因为并不存在一个完全完美的系统设计,往往都是各方面之间的均衡,至于如何均衡,需要结合面试官的要求和具体实际来选择。
一开始直奔最优解
系统设计考察我们如何去解决一个具体的问题,在实际工作中,我们也是先实现功能之后,再在此基础上去进行针对性的优化;在面试中同样也十分重要,一方面,面试官希望看到你从一开始设计系统,到慢慢完善的过程,另外,系统设计其实没有最优解,往往都是各种因素之间权衡后的结果,就像CAP理论一样,无法同时满足,我们的系统只要能满足面试官提出来的要求,刚好够用就行。
闷头设计不沟通
很多人在听到问题之后,就开始闷头设计,丝毫不会和面试官进行沟通交流。这样不仅不利于自己理解题目意图,而且让面试官无法了解你是如何一步步去解决问题的过程。
这个时候可以把面试官当做一位同事,比如你对题目不理解,可以提出问题搞清楚题目意图;又比如你在哪个环节卡住了,也不要一直闷在那,可以大胆向面试官求助寻求提示,也能节省不少时间。
就像开始说的,系统设计没有最优解,你的思路和解决问题的过程很重要,而这些就是通过不断的沟通来传递给面试官的。
如何搞定系统设计 - 4步法
针对系统设计,这里给大家提供一个4步法解决方案,无论是任何系统设计的题目,都可以按照这几步去思考解决。
1. 确定问题需求
这一步主要是确定问题的需求和系统使用场景,为了搞清楚这个问题,需要和面试官你来我往地问问题。
在做设计的同时,问面试官的要求是什么,做出合理的假设、取舍,让面试官看出你的思考过程,最终综合所有的信息完成一个还不错的设计。不要害怕问问题。那并不会说明我们不懂,而是让面试官理解我们的思考过程。当我们问出问题后,面试官要么给出明确的回答;要么让我们自己做出假设。当需要做出假设时,我们需要把假设写下来备用。
这个举个例子,比如面试官让你设计weibo,因为weibo的功能较为庞大,例如发微博、微博时间线、关注、取消关注、微博热搜榜等等,我们无法在短短的面试时间内完成这么多功能设计,所以这时候可以询问面试官我们需要实现哪些功能。
比如需要实现微博时间线的功能,我们得进一步确认,整体用户量多大,系统的QPS多大,因为这涉及到我们后续的系统设计,而且如果对于QPS特别高的情况,在后续的设计中需要针对此进行专门的扩展性优化。
QPS有什么用?
- QPS = 100,那么用你的笔记本作Web服务器就好了;
- QPS = 1K,一台好点的Web 服务器也能应付,需要考虑Single Point Failure;
- QPS = 1m,则需要建设一个1000台Web服务器的集群,并且要考虑如何Maintainance(某一台挂了怎么办)。
QPS 和 服务器/数据库之间的关系:
- 一台Web Server承受量约为 1K的QPS(考虑到逻辑处理时间以及数据库查询的瓶颈);
- 一台SQL Database承受量约为 1K的QPS(如果JOIN和INDEX query比较多的话,这个值会更小);
- 一台 NoSQL Database (Cassandra) 约承受量是 10k 的 QPS;
- 一台 NoSQL Database (Memcached) 约承受量是 1M 的 QPS。
以下是一些通用的问题,可以通过询问系统相关的问题,搞清楚面试官的意图和系统的使用场景。
- 系统的功能是什么
- 系统的目标群体是什么
- 系统的用户量有多大
- 希望每秒钟处理多少请求?
- 希望处理多少数据?
- 希望的读写比率?
- 系统的扩张规模怎么样,这涉及到后续的扩展
总结,在这一步,不要设计具体的系统,把问题搞清楚就行。不要害怕问问题,那并不会说明我们不懂,而是让面试官理解我们的思考过程。
2. 完成整体设计
这一步根据系统的具体要求,我们将其划分为几个功能独立的模块,然后做出一张整体的架构图,并依据此架构图,看是否能实现上一步所提出来的需求。
如果可能的话,设想几个具体的例子,对着图演练一遍。这让我们能更坚定当前的设计,有时候还能发现一些未考虑到的边界case。
这里说的比较抽象,具体可以参考下面的实战环节,来理解如何完成整体设计。
3. 深入模块设计
至此,我们已经完成了系统的整体设计,接下来需要根据面试官的要求对模块进行具体设计。
比如需要设计一个短网址的系统,上一步中可能已经把系统分为了如下三个模块:
- 生成完整网址的hash值,并进行存储。
- 短网址转换为完整url。
- 短网址转换的API。
这一步中我们需要对上面三个模块进行具体设计,这里面就涉及到实际的技术选型了。下面举个简单的例子。
比如说生成网址的hash值,假设别名是http://tinyurl.com/<alias_hash>,alias_hash是固定长度的字符串。
如果长度为 7,包含[A-Z, a-z, 0-9],则可以提供62 ^ 7 ~= 3500 亿个 URL。至于3500亿的网址数目是否能满足要求,目前世界上总共有2亿多个网站,平均每个网站1000个网址来计算,也是够用的。而且后续可以引入网址过期的策略。
首先,我们将所有的映射存储在一个数据库中。 一个简单的方法是使用alias_hash作为每个映射的 ID,可以生成一个长度为 7 的随机字符串。
所以我们可以先存储<ID,URL>。 当用户输入一个长 URL
http://www.lfeng.tech时
,系统创建一个随机的 7 个字符的字符串,如abcd123作为 ID,并插入条目<"abcd123", "
http://www.lfeng.tech
">进入数据库。在运行期间,当有人访问http://tinyurl.com/abcd123时,我们通过 ID abcd123查找并重定向到相应的 URL
http://www.lfeng.tech
。
当然,上面的例子中只解决了生成网址的问题,还有网址的存储、网址生成hash值之后产生碰撞如何解决等等,都需要在这个阶段解决。这里面涉及到各种存储方案的选择、数据库的设计等等,后面会有专门的文章进行介绍。
4. 可扩展性设计
这是最后一步,面试官可能会针对系统中的某个模块,给出扩展性相关的问题,这块的问题可以分为两类:
- 当前系统的优化
。因为没有完美的系统,我们的设计的也不例外,因此这类问题需要我们认真反思系统的设计,找出其中可能的缺陷,提出具体的解决方案。 - 扩展当前系统
。例如我们当前的设计能够支撑100w 用户,那么当用户数达到 1000w 时,需要如何应对等等。
这里面可能涉及到水平扩展、垂直扩展、缓存、负载均衡、数据库的拆分的同步等等话题,后续会有专门的文章进行讲解。
实战 - 4步法解决Weibo设计
这部分我以Weibo的设计为例,带大家过一遍如何用4步法解决实际的系统设计。
确定weibo的使用场景
因为weibo功能较多,这里没有面试官的提示,我们假定需要实现
微博的时间线以及搜索
的功能。
基于这个设定,我们需要解决如下几个问题:
- 用户发微博:服务能够将微博推送给对应的关注者,同时可能需要相应的提醒。
- 用户浏览自己的微博时间线。
- 用户浏览主页微博,也就是需要将用户关注对象的微博呈现出来。
- 用户能够搜索微博。
- 整个系统具有高可用性。
初步估算
基于上面的需求,我们进一步做出一些假设,然后计算出大概的储存需求和QPS,因为后续的技术选型依赖于当前系统的规模。这里我做出如下假定:
- 假设有1亿活跃用户,每人平均每天5条微博,也就是每天5亿条微博,每月150亿条。
- 每条微博的平均阅读量是20,也就是每月3000亿阅读量。
- 对于搜索,假定每人每天搜索5次,一个月也就是150亿次搜索请求。
下面进一步对存储和QPS进行估算,
首先是储存,每条微博至少包含如下几个内容:
微博id
:8 bytes用户id
:32 bytes微博正文
:140 bytes媒体文件
:10 KB (这里只考虑媒体文件对应的链接)
总共10KB左右。
每月150亿条微博,也就是0.14PB,每年1.68PB。
其次是QPS,这里涉及到3个接口:
- 发微博接口:每天5亿条微博,也就是大约6000QPS
- 阅读微博接口:每天100亿阅读,也就是大约12万QPS
- 搜索微博接口:每天每人搜索5次,那也大约6000QPS。
这里估算出来的数据为后续技术选型做参考。
完成weibo整体设计
根据上面的分析,这一步将主要服务拆分出来,可以分为读微博服务、发微博服务、搜索服务;同时还有相关的时间线服务、微博信息服务,用户信息服务、用户关系图服务、消息推送服务等等。考虑到服务高可用,这里也引入了缓存。
拆分好了之后,根据用户使用场景,可以设计出如下图所示的系统架构图,注意到目前为止,都是粗略设计,我们只需要将服务抽象出来,完成具体的功能即可。后续步骤会对主要服务进行详细设计。
下图的架构中,主要实现了用户发微博、浏览微博时间线和搜索的场景。
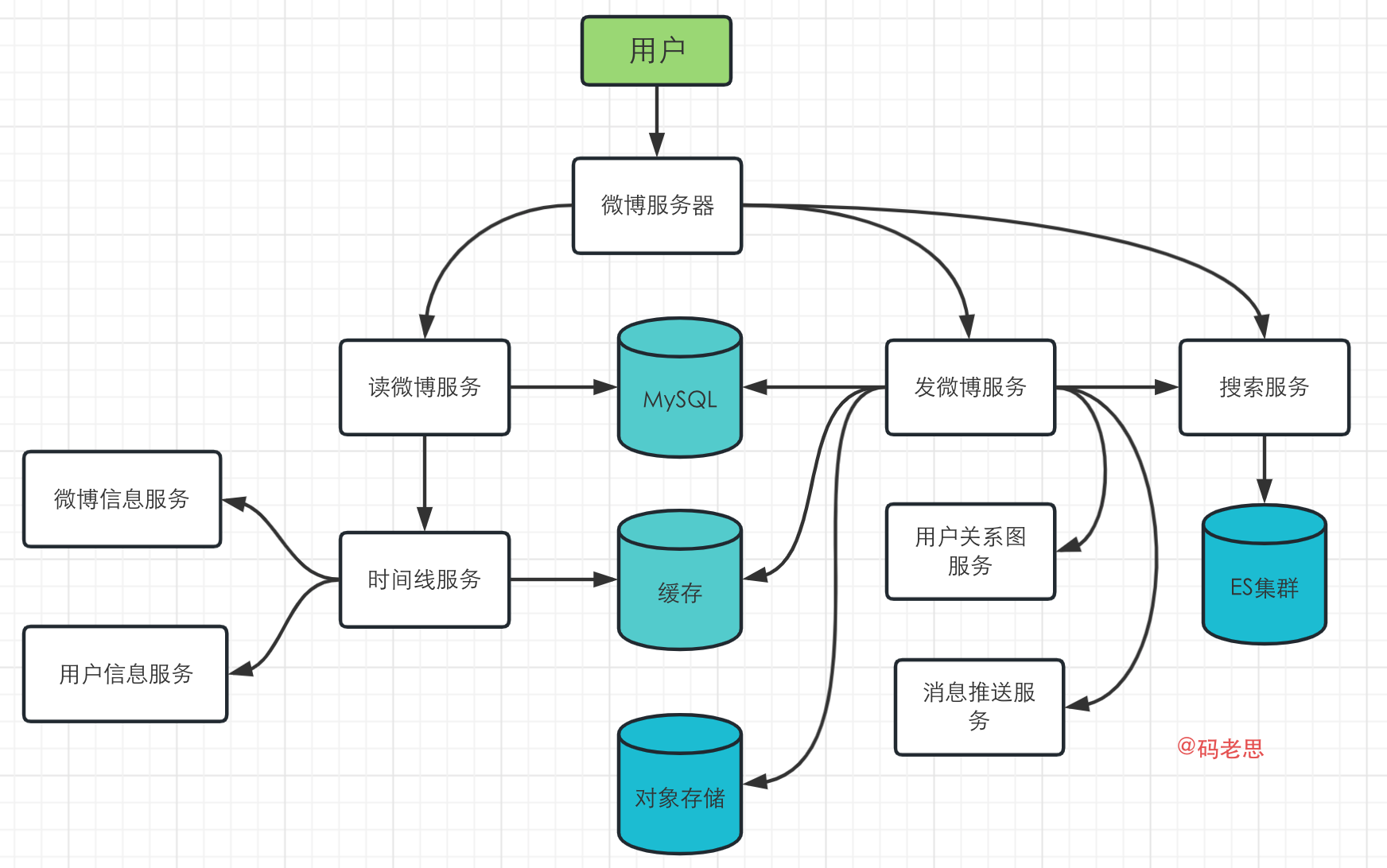
设计核心模块
上一步我们完成了微博的架构设计,这一步从用户场景入手,详细设计核心模块。
用户发微博
用户发微博的时候,发微博服务需要完成如下几项工作:
- 将微博写入到MySQL等关系型数据库,考虑到流量较大,这里可以引入Kafka等MQ来进行削峰。
- 查询用户关系图服务,找到该用户的所有follower,然后把微博插入到所有follower的时间线上,注意到这里时间线的信息都是存放在缓存中的。
- 将微博数据导入到搜索集群中,提供给后续搜索使用。
- 将微博的媒体文件存放到对象储存中。
- 调用消息推送服务,将消息推送到所有的followers。这里同样可以采用一个MQ来进行异步消息推送。
对于每个用户,我们可以用一个Redis的list,来存放所有该用户关注对象的微博信息,类似如下:
| 第N条微博 | 第N+1条微博 | 第N+2条微博 |
|---|---|---|
| 8 bytes 8 bytes 1 byte | 8 bytes 8 bytes 1 byte | 8 bytes 8 bytes 1 byte |
| weibo_id user_id meta | weibo_id user_id meta | weibo_id user_id meta |
后续的时间线服务,可以根据这个列表生成用户的时间线微博。
用户浏览微博时间线
当用户浏览主页时间线时,微博时间线服务会完成如下的工作:
- 从上面设计的Redis list中拿到时间线上所有的微博id和用户id,可以在O(1)时间内完成。
- 查询微博信息服务,来获取这些微博的详细信息,这些信息可以存放在缓存中,O(N)时间内可以完成。
- 查询用户信息服务,来获取每条微博对应用户的详细信息,同样也是O(N)时间完成。
注意到这里有一个特殊的情形,就是用户浏览自己的微博列表,对于这种情况,如果频率不是很高的情况,可以直接从MySQL中取出用户所有的微博即可。
用户搜索微博
当用户搜索微博时,会发生下面的事情:
- 搜索服务首先会进行预处理,包括对输入文本的分词、正则化、词语纠错等等处理。
- 接着将处理好的结果组装成查询语句,在集群中完成对应的查询,获取搜索结果。
- 最后根据用户的设置,可能需要对结果进行排序、聚合等等,最后将处理好的结果返回给用户。
系统扩展设计
在做系统扩展设计之前,我们可以依据下面几个步骤,找出系统中可能存在的瓶颈,然后进行针对性优化。
(1)对各个模块进行benckmark测试,并记录对应的响应时间等重要数据;
(2)综合各种数据,找到系统的瓶颈所在;
(3)解决瓶颈问题,并在各种可选方案之间的做权衡,就像开头所说,没有完美的系统。
下面针对我们刚才设计的微博系统,可能的瓶颈存在于下面几个地方:
- 微博服务器的入口。这里承受了最大的流量,因此可以引入负载均衡进缓解。
- 发微博服务。可以看到这里需要和大量的服务进行交互,在流量很大的情况下,很容易成为整个系统的瓶颈,因此可以考虑将其进行水平扩展,或者将发微博服务进行进一步拆分,拆成各个小组件之后,再进行单独优化。
- MySQL服务器。这里存储着用户信息、微博信息等,也承载了很大的流量,可以考虑将读写进行分离,同时引入主从服务器来保证高可用。
- 读微博服务。在某些热点事件时,读微博服务会接收巨大的流量,可以引入相应的手段对读服务进行自动扩展,比如K8s的水平扩展等,方便应对各种突发情况。
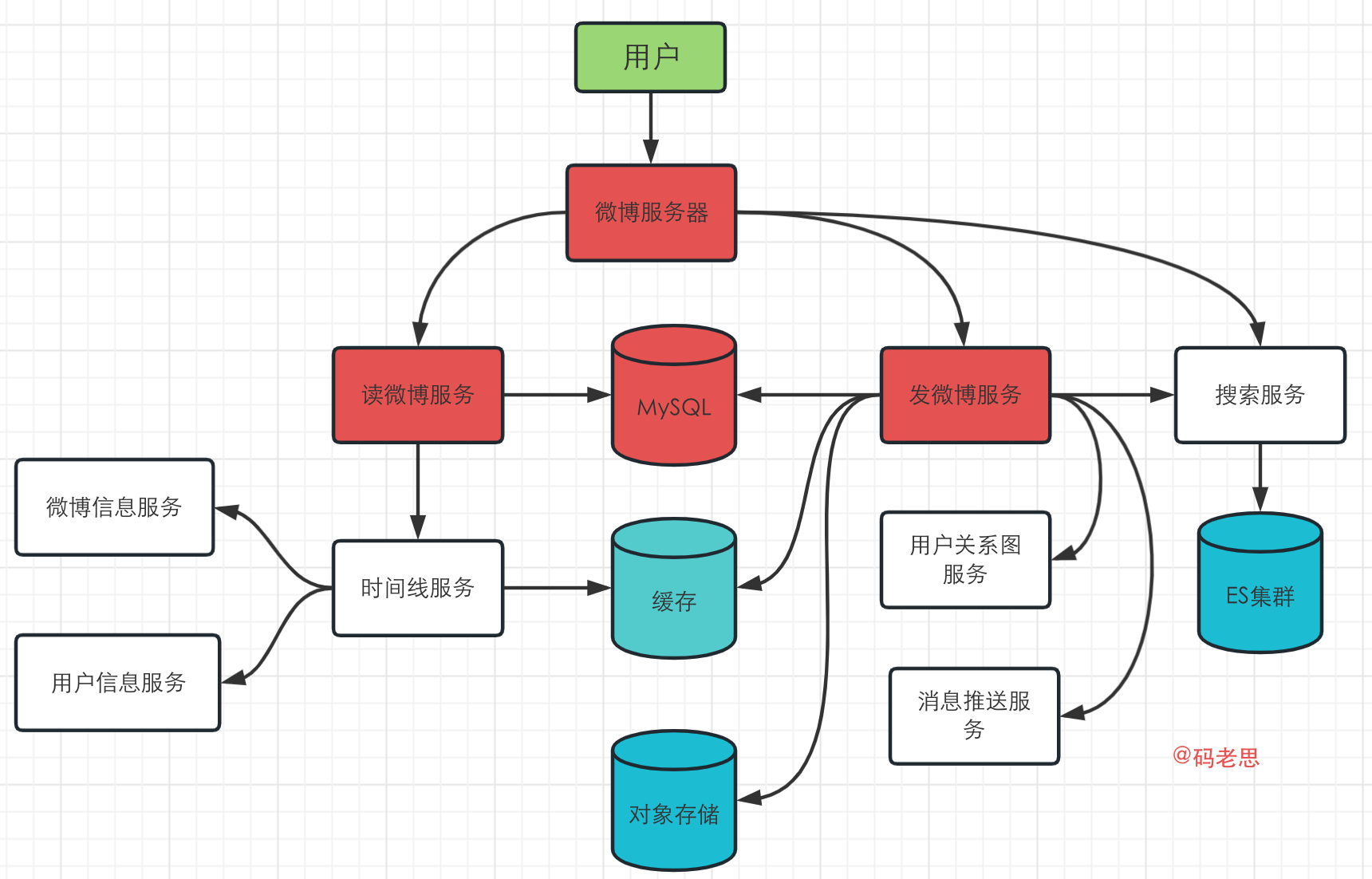
下面是进一步优化之后的系统架构图:
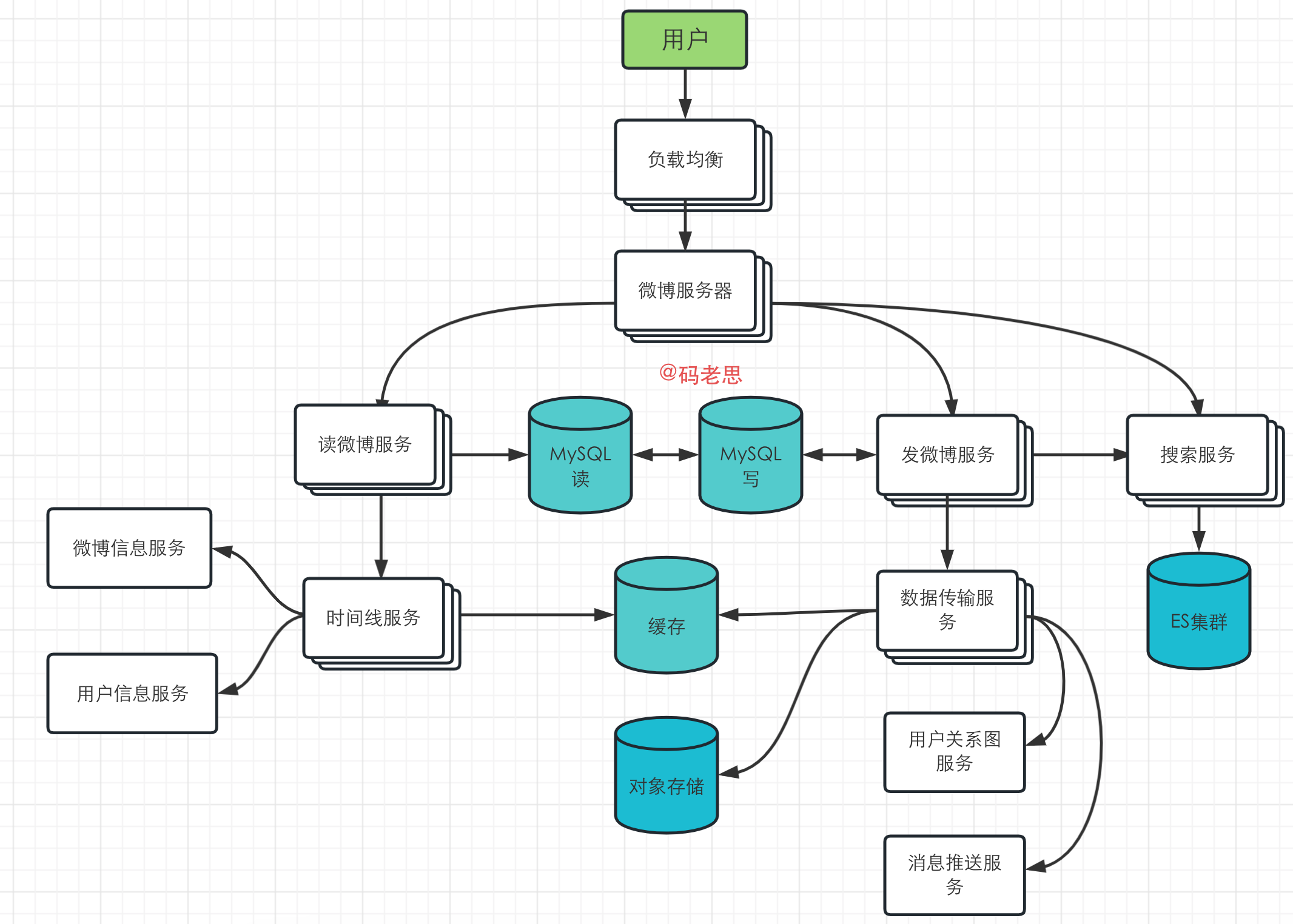
针对这个系统,我们还可以进一步优化,以下是几个思路,也可以自己思考看看,
- 对于有大量粉丝的用户,比如很多明星;在现有架构上明星每次都会将微博利用数据传输服务,发到每个粉丝的时间线上去,这样其实会造成大量的流量,针对这种情况,可以将这些明星用户单独处理,每当粉丝在刷新主页的时候,会根据这些粉丝的时间线以及明星的微博信息,合并来生成粉丝的主页时间线,避免了不必要的流量浪费。
- 只保存最近一段时间的微博数据在缓存中, 这主要是为了节省集群空间,并且一般热点微博都是最近的微博。
- 只保存活跃用户的主页时间线在缓存中,对于过去一段时间内,比如30天内未活跃的用户,我们只有在该用户首次浏览的时候,从DB中将数据load出来组成时间线。
扩展的方向不止上面说的这几点,大家可以从缓存(CDN,用户缓存、服务器缓存)、异步(MQ、微服务等等)、数据库调优等方向去思考,看如何提升整体性能。这些相关内容我会在后续文章中仔细讲述,欢迎关注【码老思】,后续文章敬请期待。
参考:
- https://github.com/donnemartin/system-design-primer/blob/master/solutions/system_design/twitter/README.md
- https://cloud.tencent.com/developer/article/1899760
- https://www.zhihu.com/question/26312148
可以关注公众号【码老思】,一时间获取最通俗易懂的原创技术干货。
【LeetCode动态规划#05】背包问题的理论分析(基于代码随想录的个人理解,多图)
背包问题
问题描述
背包问题是一系列问题的统称,具体包括:
01背包
、
完全背包
、多重背包、分组背包等(仅需掌握前两种,后面的为竞赛级题目)
下面来研究
01背包
实际上即使是最经典的01背包,也不会直接出现在题目中,一般是融入到其他的题目背景中再考察
因为是学习原理,所以先跳过最原始的问题模板来学。
01背包的原始题意是:(标准的背包问题)
有n件物品和一个最多能背重量为
w
的背包。第
i
件物品的重量是
weight[i]
,得到的价值是
value[i]
。
每件物品只能用一次
,求解将哪些物品装入背包里物品
价值总和最大
。
(01背包问题
可以使用暴力解法
,每一件物品其实只有两个状态,
取
或者
不取
,所以可以使用
回溯法
搜索出所有的情况,那么
时间复杂度就是O(2^n)
,这里的n表示物品数量。因为暴力搜索的时间复杂度是指数级别的,所以才需要通过dp来进行优化)
根据上面的描述可以举出以下例子
二维dp数组01背包
背包最大重量为4。
物品为:
| 重量 | 价值 | |
|---|---|---|
| 物品0 | 1 | 15 |
| 物品1 | 3 | 20 |
| 物品2 | 4 | 30 |
问背包能背的物品最大价值是多少?
五部曲分析一波
五步走
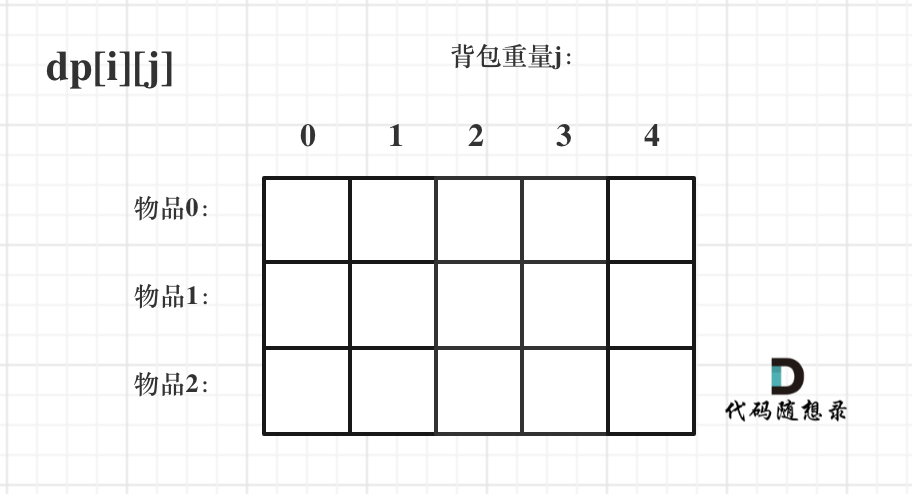
1、确定dp数组含义
该问题中的dp数组应该是二维的,所以先定义一个
dp[i][j]
该数组的含义是什么?
含义:
任取编号(下标)为[0, i]之间的物品放进容量为j的背包里
2、确定递推公式
确定递推公式之前,要明确
dp[i][j]
可以由哪几个方向推导出
当前背包的状态取决于放不放物品i,下面分别讨论
(1)不放物品i
dp[i - 1][j]
(2)放物品i
dp[i - 1][j - weight[i]] + value[i] (物品i的价值)
我来解释一下上面的式子是什么意思
先回顾一下
dp[i][j]
的含义:从下标为[0, i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
那么可以有上述两个方向推出来
dp[i][j]
情况1:不放物品i。此时我们已经认为
物品i不会被放到背包中
,那么根据
dp[i][j]
的定义,任取物品的范围应该变成[0, i-1]
也就是从下标为[0, i-1]的物品里任意取,放进容量为j的背包,价值总和最大是多少,即
dp[i - 1][j]
再看情况2:放物品i。因为要放物品i,那就
不需要再遍历到i了
(相当于已经放入背包的东西下次就不遍历了)
根据
dp[i][j]
的定义,任取物品的范围也应该变成[0, i-1]
但是,因为情况2是要将物品i放入背包,此时
背包的容量也要发生变化
根据
dp[i][j]
的定义,背包的容量应该要减去物品i的重量
weight[i]
,即
dp[i - 1][j - weight[i]]
此时
dp[i - 1][j - weight[i]]
只是做好了准备放入物品i的工作,实际上物品i并没有放入,因此该式子的含义是:
背包容量为j - weight[i]的时候不放物品i的最大价值
所以要再加上物品i本身的价值
value[i]
,才能求出
背包放物品i得到的最大价值
即:
dp[i - 1][j - weight[i]] + value[i]
根据
dp[i][j]
的定义,我们最后要求价值总和最大物品放入方式
因此递推公式应该是:
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
从不放物品i和放物品i两个方向往
dp[i][j]
推,取最后结果最大的那种方式(即最优的方式)
3、确定dp数组初始化方式
可以把dp数组试着画出来,然后假设要求其中一个位置,思考可以从哪个方向将其推出,而这些方向最开始又是由哪些方向推得的,进而确定dp数组中需要初始化的部分
将本题的dp数组画出来如下:
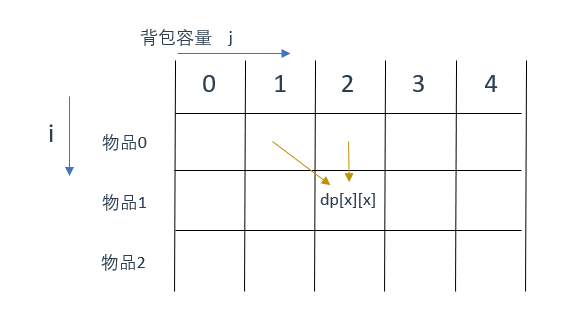
假设有一个要求的元素
dp[x][x]
,根据前面对递推公式的讨论可知,该元素一定是由两个方向推过来求得的。
也就是情况1、情况2,那么对应到图中就是从上到下推过来的,是情况1(
dp[i - 1][j]
)
情况2(
dp[i - 1][j - weight[i]]
)在图中体现得不是十分确定,但是大致方向是从左上角往下推过来的
这两个方向的源头分别指向
绿色区域
和
橙色区域
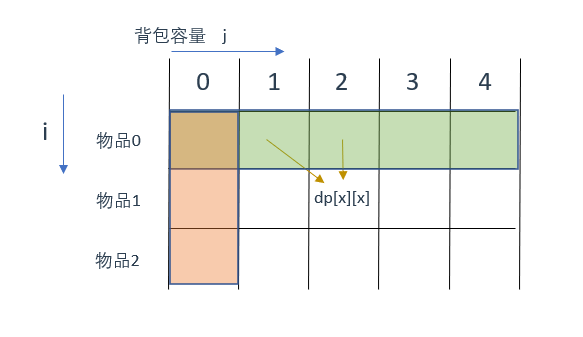
那么这两个区域就是要初始化的区域,怎么初始化呢?
先说橙色区域,从
dp[i][j]
的定义出发,如果背包容量j为0的话,即
dp[i][0]
,无论是选取哪些物品,背包价值总和一定为0。
所以橙色区域区域需要初始化为0

再说绿色区域,状态转移方程
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
可以看出 i 是由 i-1 推导出来,那么 i 为 0 的时候就一定要初始化
dp[0][j]
,即:i 为0,存放 编号0 的物品的时候,各个容量的背包所能存放的最大价值。
很明显当
j < weight[0]
的时候,
dp[0][j]
应该是 0,因为背包容量比编号0的物品重量还小。
当
j >= weight[0]
时,
dp[0][j]
应该是
value[0]
,因为背包容量放足够放编号0物品。

两个区域的初始化情况对应到图中如下:

初始化代码:
for (int j = 0 ; j < weight[0]; j++) { //橙色区域
dp[0][j] = 0;
}
// 正序遍历
for (int j = weight[0]; j <= bagweight; j++) {//绿色区域
dp[0][j] = value[0];
}
以上两个区域实际上属于“含0下标区域”,其他的“非0下标区域”也需要初始化(没想清楚为什么有时要初始化完整个dp数组,有时又不用)
“非0下标区域”初始化为任何值都可以
还是拿前面的图来看
以
dp[x][x]
这个位置为例,其初始化成100、200都无所谓,因为这个位置的dp值是由其上面和左上两个方向上的情况推导出来的,只取决于这里个方向最开始的初始化值。
(例如
dp[x][x]
这里初始化为100,我从上面推导下来之后会用推导值将100覆盖)
4、确定遍历方式
该问题中dp数组有两个维度:物品、背包容量,先遍历哪个呢?
直接说结论,
都行
,但是
先遍历物品更好理解
(具体看
代码随想录解释
)
两种过程的图如下:
(这里需要重申一下背包问题的条件:
每个物品只能用一次
,要求的是怎么装背包里的
价值最大
)
先遍历物品再遍历背包容量(
固定物品编号,遍历背包容量
)
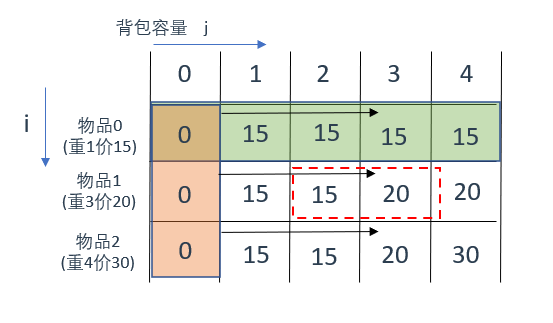
挑一个节点来说一下(图中的红框部分),此时的遍历顺序是先物后包,
物品1
(重3价20)
在0~4种容量中放置的结果
如图所示
因为固定了物品1,此时背包容量为0、1、2的情况都是放不下物品1的(又也放不下物品3),所以只能放物品0(此为最佳选择)
当遍历到背包容量为3时,可以放下物品1了,那此处的最佳选择就是放一个物品1,所以此处的dp数组值变为20
其余位置分析方法同理
先遍历背包容量再遍历物品(
固定背包容量,遍历物品编号
)
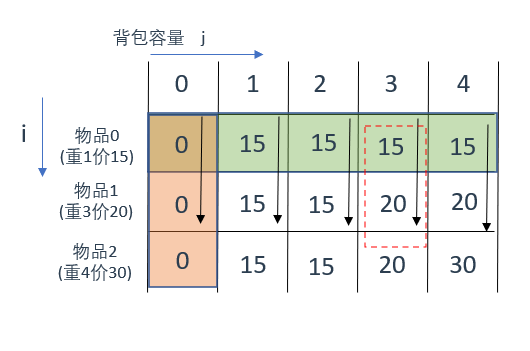
有了前面的例子,这里就很好理解了,就是从上往下遍历,固定住当前背包的容量,遍历物品,看看能不能放入,能放的话最优选择应该放哪个
还是拿红框部分来说,此时背包容量固定为3
第一次遍历,物品0可以装下,此时最优选择就是放物品0,背包总价是15;
第二次遍历,物品1可以装下,此时最优选择就是放物品1,背包总价是20;
第二次遍历,物品2
装不下
,此时最优选择就是放物品1,背包总价还是20;
其余位置分析方法同理
完整c++测试代码(卡哥)
void test_2_wei_bag_problem1() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagweight = 4;
// 二维数组
vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));
// 初始化
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
cout << dp[weight.size() - 1][bagweight] << endl;
}
int main() {
test_2_wei_bag_problem1();
}
仓库管理、dockerfile
Docker仓库管理
仓库(Repository)是集中存放镜像的地方。
Docker Dockerfile
什么是Dockerfile?
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
使用Dockerfile定制镜像
1、下面以定制一个 nginx 镜像(构建好的镜像内会有一个 /usr/share/nginx/html/index.html 文件)
# 在一个空目录下,新建一个名为 Dockerfile 文件,并在文件内添加以下内容:
[root@docker Dockerfile]# pwd
/root/project/docker/Dockerfile
[root@docker Dockerfile]# cat Dockerfile
FROM nginx
RUN echo '这是一个本地构建的nginx镜像' > /usr/share/nginx/html/index.html
2、FROM 和 RUN 指令的作用
FROM
:定制的镜像都是基于 FROM 的镜像,这里的 nginx 就是定制需要的基础镜像。
RUN
:用于执行后面跟着的命令行命令。有以下俩种格式:
# shell 格式:
RUN <命令行命令>
# <命令行命令> 等同于,在终端操作的 shell 命令。
# exec格式
RUN ["可执行文件", "参数1", "参数2"]
# 例如:
# RUN ["./test.php", "dev", "offline"] 等价于 RUN ./test.php dev offline
注意
:Dockerfile 的指令每执行一次都会在 docker 上新建一层。所以过多无意义的层,会造成镜像膨胀过大。例如:
FROM centos
RUN yum -y install wget
RUN wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz"
RUN tar -xvf redis.tar.gz
# 以上执行会创建 3 层镜像。可简化为以下格式:
FROM centos
RUN yum -y install wget \
&& wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" \
&& tar -xvf redis.tar.gz
# 如上,以 && 符号连接命令,这样执行后,只会创建 1 层镜像。
开始构建镜像
在 Dockerfile 文件的存放目录下,执行构建动作。以下示例,通过目录下的 Dockerfile 构建一个 nginx:v3(镜像名称:镜像标签)。
注
:最后的 . 代表本次执行的上下文路径。
[root@docker Dockerfile]# docker build -t nginx:v3 .
[+] Building 51.5s (4/5) ......
=> => writing image sha256:f07b477bd5e4866873def66ebf441fc71b282f8dbd9dce22b1ceeaa81356da 0.0s
=> => naming to docker.io/library/nginx:v3 [root@docker Dockerfile]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx v3 f07b477bd5e4 2 minutes ago 141MB
上下文路径
上下文路径,是指 docker 在构建镜像,有时候想要使用到本机的文件(比如复制),docker build 命令得知这个路径后,会将路径下的所有内容打包。
解析
:由于 docker 的运行模式是 C/S。我们本机是 C,docker 引擎是 S。实际的构建过程是在 docker 引擎下完成的,所以这个时候无法用到我们本机的文件。这就需要把我们本机的指定目录下的文件一起打包提供给 docker 引擎使用。
如果未说明最后一个参数,那么默认上下文路径就是 Dockerfile 所在的位置。
注意
:上下文路径下不要放无用的文件,因为会一起打包发送给 docker 引擎,如果文件过多会造成过程缓慢。
指令详解
COPY
复制指令,从上下文目录中复制文件或者目录到容器里指定路径。
# 格式:
COPY [--chown=<user>:<group>] <源路径1>... <目标路径>
COPY [--chown=<user>:<group>] ["<源路径1>",... "<目标路径>"]
[--chown=<user>:<group>]:可选参数,用户改变复制到容器内文件的拥有者和属组。
<源路径>:源文件或者源目录,这里可以是通配符表达式,其通配符规则要满足 Go 的 filepath.Match 规则。例如:
COPY hom* /mydir/
COPY hom?.txt /mydir/
<目标路径>:容器内的指定路径,该路径不用事先建好,路径不存在的话,会自动创建。
ADD
ADD 指令和 COPY 的使用格类似(同样需求下,推荐使用 COPY)。功能也类似,不同之处如下:
- ADD 的优点:在执行 <源文件> 为 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,会自动复制并解压到 <目标路径>。
- ADD 的缺点:在不解压的前提下,无法复制 tar 压缩文件。会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。具体是否使用,可以根据是否需要自动解压来决定。
CMD
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
- CMD 在docker run 时运行。
- RUN 是在 docker build。(推荐,执行过程比较明确)
作用
:为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
注意
:如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。
CMD <shell 命令>
CMD ["<可执行文件或命令>","<param1>","<param2>",...]
CMD ["<param1>","<param2>",...] # 该写法是为 ENTRYPOINT 指令指定的程序提供默认参数
ENTRYPOINT
类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
但是, 如果运行 docker run 时使用了 --entrypoint 选项,将覆盖 ENTRYPOINT 指令指定的程序。
优点
:在执行 docker run 的时候可以指定 ENTRYPOINT 运行所需的参数。
注意
:如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
# 格式
ENTRYPOINT ["<executeable>","<param1>","<param2>",...]
可以搭配 CMD 命令使用:一般是变参才会使用 CMD ,这里的 CMD 等于是在给 ENTRYPOINT 传参
# 假设已通过 Dockerfile 构建了 nginx:test 镜像:
FROM nginx
ENTRYPOINT ["nginx", "-c"] # 定参
CMD ["/etc/nginx/nginx.conf"] # 变参
ENV
设置环境变量,定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。
# 格式
ENV <key> <value>
ENV <key1>=<value1> <key2>=<value2>...
# 以下示例设置 NODE_VERSION = 7.2.0 , 在后续的指令中可以通过 $NODE_VERSION 引用:
ENV NODE_VERSION 7.2.0
RUN curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-x64.tar.xz" \
&& curl -SLO "https://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc"
ARG
构建参数,与 ENV 作用一致。不过作用域不一样。ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只有 docker build 的过程中有效,构建好的镜像内不存在此环境变量。
构建命令 docker build 中可以用 --build-arg <参数名>=<值> 来覆盖。
# 格式
ARG <参数名>[=<默认值>]
VOLUME
定义匿名数据卷。在启动容器时忘记挂载数据卷,会自动挂载到匿名卷。
作用:
- 避免重要的数据,因容器重启而丢失,这是非常致命的。
- 避免容器不断变大。
# 格式
VOLUME ["<路径1>", "<路径2>"...]
VOLUME <路径>
# 在启动容器 docker run 的时候,我们可以通过 -v 参数修改挂载点
EXPOSE
仅仅只是声明端口。
作用:
- 帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射。
- 在运行时使用随机端口映射时,也就是 docker run -P 时,会自动随机映射 EXPOSE 的端口。
# 格式
EXPOSE <端口1> [<端口2>...]
WORKDIR
指定工作目录。用 WORKDIR 指定的工作目录,会在构建镜像的每一层中都存在。以后各层的当前目录就被改为指定的目录,如该目录不存在,WORKDIR 会帮你建立目录。
docker build 构建镜像过程中的,每一个 RUN 命令都是新建的一层。只有通过 WORKDIR 创建的目录才会一直存在。
# 格式
WORKDIR <工作目录路径>
USER
用于指定执行后续命令的用户和用户组,这边只是切换后续命令执行的用户(用户和用户组必须提前已经存在)。
# 格式
USER <用户名>[:<用户组>]
HEALTHCHECK
用于指定某个程序或者指令来监控 docker 容器服务的运行状态。
# 格式
HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令
HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK [选项] CMD <命令> : 这边 CMD 后面跟随的命令使用,可以参考 CMD 的用法。
ONBUILD
用于延迟构建命令的执行。简单的说,就是 Dockerfile 里用 ONBUILD 指定的命令,在本次构建镜像的过程中不会执行(假设镜像为 test-build)。当有新的 Dockerfile 使用了之前构建的镜像 FROM test-build ,这时执行新镜像的 Dockerfile 构建时候,会执行 test-build 的 Dockerfile 里的 ONBUILD 指定的命令。
# 格式
ONBUILD <其它指令>
LABEL
LABEL 指令用来给镜像添加一些元数据(metadata),以键值对的形式
# 格式
LABEL <key>=<value> <key>=<value> <key>=<value> ...
# 比如我们可以添加镜像的作者:
LABEL org.opencontainers.image.authors="runoob"
Docker的命令摘要:
| FROM | 镜像从那里来 |
|---|---|
| MAINTAINER | 镜像维护者信息 |
| RUN | 构建镜像执行的命令,每一次RUN都会构建一层 |
| CMD | 容器启动的命令,如果有多个则以最后一个为准,也可以为ENTRYPOINT提供参数 |
| VOLUME | 定义数据卷,如果没有定义则使用默认 |
| USER | 指定后续执行的用户组和用户 |
| WORKDIR | 切换当前执行的工作目录 |
| HEALTHCHECH | 健康检测指令 |
| ARG | 变量属性值,但不在容器内部起作用 |
| EXPOSE | 暴露端口 |
| ENV | 变量属性值,容器内部也会起作用 |
| ADD | 添加文件,如果是压缩文件也解压 |
| COPY | 添加文件,以复制的形式 |
| ENTRYPOINT | 容器进入时执行的命令 |