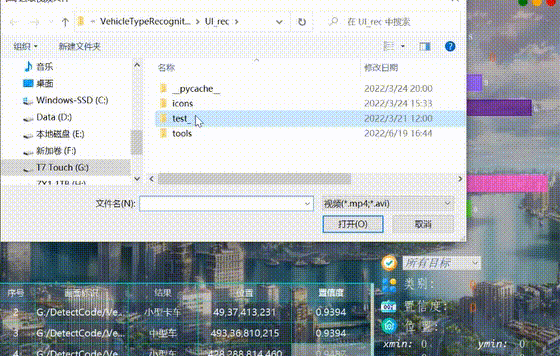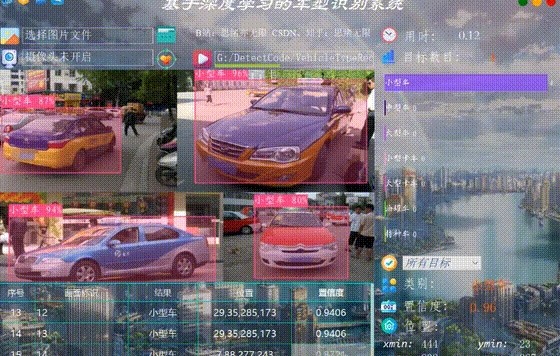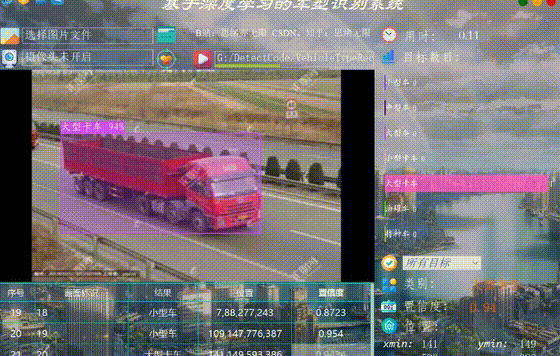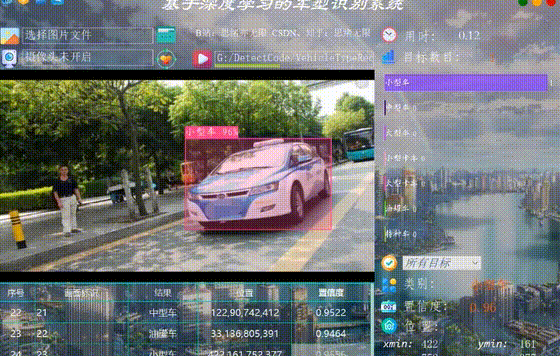
监控二叉树
力扣题目链接(opens new window)
给定一个二叉树,我们在树的节点上安装摄像头。
节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。
计算监控树的所有节点所需的最小摄像头数量。
示例 1:

- 输入:[0,0,null,0,0]
- 输出:1
- 解释:如图所示,一台摄像头足以监控所有节点。
示例 2:
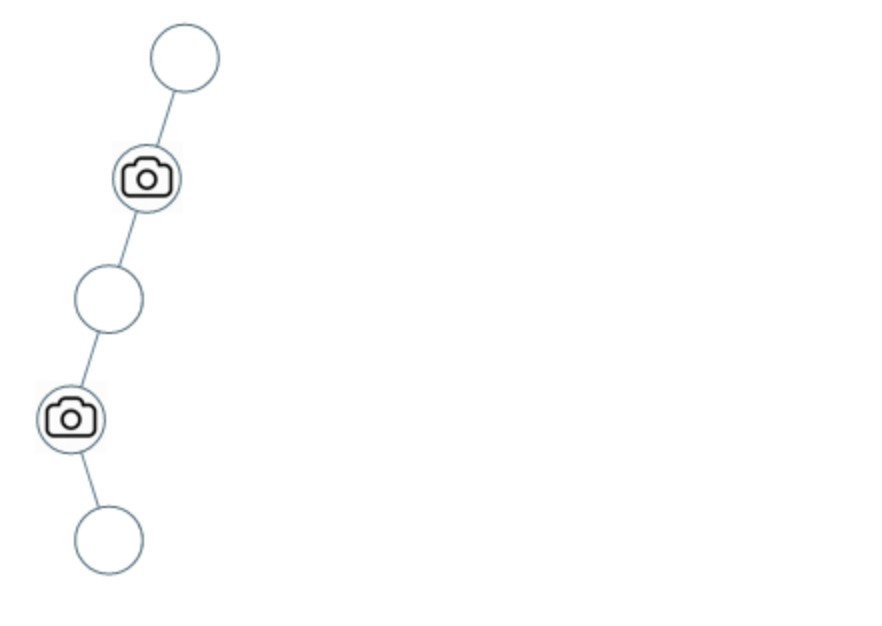
- 输入:[0,0,null,0,null,0,null,null,0]
- 输出:2
- 解释:需要至少两个摄像头来监视树的所有节点。 上图显示了摄像头放置的有效位置之一。
提示:
- 给定树的节点数的范围是 [1, 1000]。
- 每个节点的值都是 0。
思路
❗
难题警告
❗
题意解读
由题目和示例可知,本题的目标是
在二叉树的合适的节点上"装摄像头"
,那么装了摄像头的节点
可以覆盖的范围是本层加上其两个子节点(如果有的话)和一个父节点
,即一共可以覆盖三层
由此可以推知,我们
应该尽量在叶子节点的父节点处放置摄像头
,这样可以
充分利用其三层覆盖范围
所以我们可以从下往上推,在叶子节点的父节点放摄像头,然后其父节点的上一个节点(即父节点的父节点)再隔一个节点放置摄像头
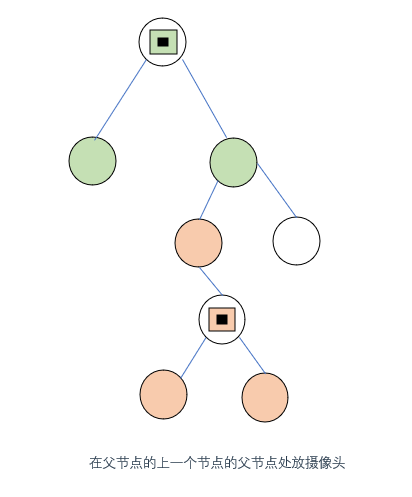
对应颜色的摄像头的覆盖范围如图所示,我们在橙色的节点处放置了摄像头,其有两个叶子节点,因此这是符合我们的推断的
该摄像头节点的覆盖范围包含了其父节点,因此我们无需在其父节点的父节点处放置摄像头,因为这
会导致覆盖范围重叠,进而浪费一个覆盖范围
,这不符合我们设置最少摄像头的目标
贪心点
这里还会出现一个问题,就是在根节点处放摄像头其实也浪费了一个覆盖范围(就是其父节点的范围)
所以如果严格按照设置最少摄像头的目标来做的话,此时我们应该将摄像头设置在根节点的父节点
但是,
实际上这么做只是在局部上满足了最优解,在全局上并不是最优的
因为叶子节点的数量远大于根节点的数量,如果按照“在根节点的父节点设置摄像头”的规则来做的话,那么会影响到叶子节点设置摄像头的方法,进而影响最后总摄像头的数量
因此,
不能为了节省根节点浪费的一个范围牺牲其他更多更合理的摄像头设置位置
总结一下摄像头安放原则:
优先在叶子节点的父节点安放摄像头,然后从下往上推,每隔两个节点再放一个摄像头,直到遍历至根节点
状态设定
(仅用于模拟,无需选择最优状态)
通过上面的分析,我们遍历二叉树的顺序自然的应该选择
后序遍历
问题又来了,怎么控制每隔两个节点放一个摄像头呢?
这里可以设置几个状态,然后
记录每个节点的状态
,根据左右子节点的状态去确定父节点的状态
通过节点间的状态关系,来确定某处是否应该安放摄像头
根据分析,可以得出以下三种节点状态:
这里要么节点是被覆盖,要么是没被覆盖,没必要设置一个没有摄像头的状态(有摄像头其实也是被覆盖的)
然后这里需要讨论二叉树中
空节点的状态设置问题
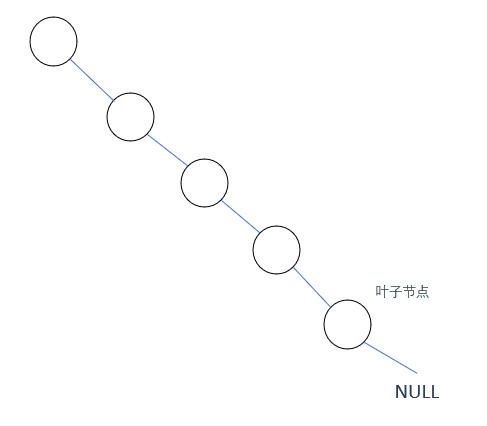
以上述二叉树为例,因为就三种状态嘛,那这个NULL就有三种情况,看看哪种情况符合我们的要求
情况1: NULL节点没被覆盖(0)
因为这个NULL节点被设置为无覆盖状态,那按题意一定要有一个摄像头去覆盖它,因此NULL的父节点,也就是
叶子节点就需要放置摄像头
而这与我们前面设计的放置原则(优先在叶子节点的父节点安放摄像头)有冲突,且推到后面,根节点处会没有摄像头(反正就是不合适)
因此情况1否了
情况2: NULL节点有摄像头(1)
这种情况也不行,因为如果NULL节点有摄像头,就意味着叶子节点已经被覆盖了
那么下一步需要隔两个节点再放置摄像头,那叶子节点的父节点就又没有摄像头了,即又不满足设计初衷
否了
情况3: NULL节点被覆盖(2)
前两种都不行,那这个肯定行了,简单推一下就知道这种情况是满足条件的
因此,
空节点应该被设置为有覆盖状态(2)
状态转移
规定好状态之后,如何在遍历过程中对每个节点的状态进行转换并统计摄像头个数呢?
这里又有几种情况需要讨论:(后序遍历)
情况1:左右子节点都有覆盖
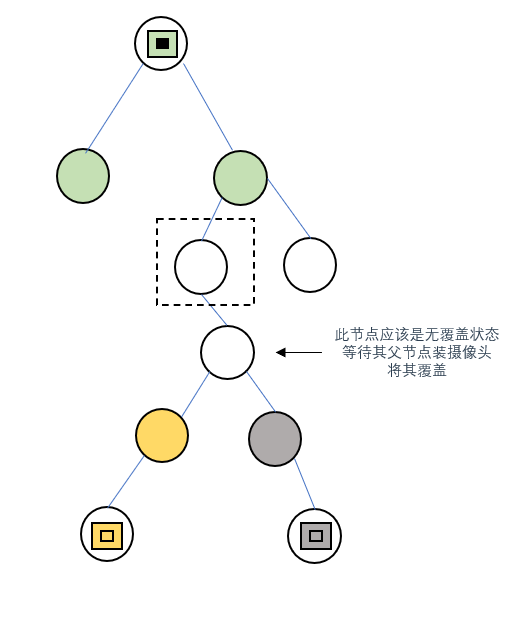
某个节点的左右子节点均被覆盖时,覆盖它们的摄像头肯定是不同的,因此当前节点应该设置为
无覆盖(0)
,等待之后遍历到父节点设置摄像头将其覆盖
情况2:左右子节点至少有一个无覆盖
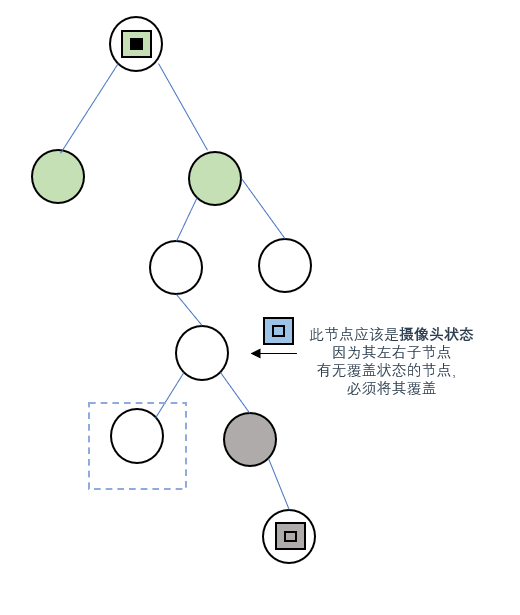
不论左右,当某个节点的子节点出现无覆盖状态时,当前节点都应该设置为
摄像头状态(1)
,这样才能不漏掉这个没被覆盖的节点
情况3: 左右子节点至少有一个有摄像头
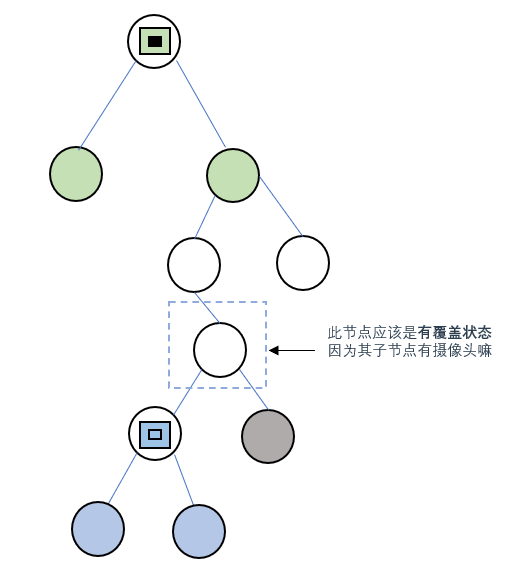
因为摄像头的覆盖范围是三层,某个节点的子节点有摄像头,那该节点肯定是被覆盖到了的,因此节点状态设为
有覆盖(2)
情况4:遍历完毕根节点还是没被覆盖
确实是有这种情况,此时需要对根节点进行单独修改,放置一个
摄像头(1)
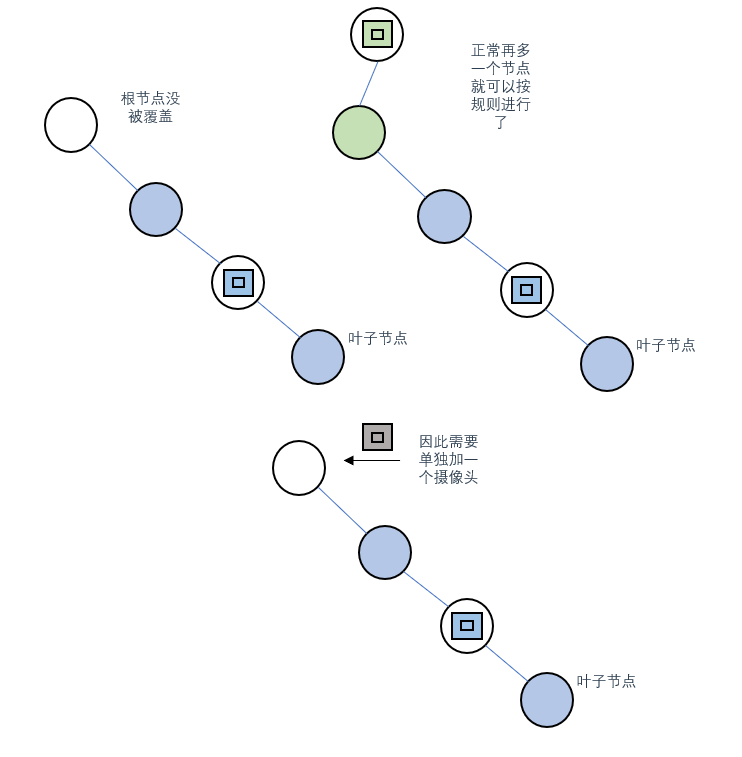
虽然这样会浪费一个覆盖范围,但是也没办法
至此,所有状态转移的情况分析完毕(够复杂够阴间了吧...)
代码
要使用后序遍历,因此可以直接使用二叉树后序递归遍历的模板(
详见
)
为了复习之前的知识,这里还是使用递归三部曲的方式写一下代码
递归三部曲
1、确定递归函数的参数和返回值
根据分析,我们在遍历二叉树的过程中是通过判断当前节点的状态(依据是左右子节点的状态)来决定是否要设置摄像头的
因此递归的返回值应该是一个节点的状态(0、1、2其中之一),因此
递归函数有返回值int
输入参数肯定是
待判断状态的节点
class Solution {
private:
int res = 0;//记录摄像头数量
int traversal(TreeNode* cur){//确定递归函数参数与返回值
}
public:
int minCameraCover(TreeNode* root) {
}
};
2、确定终止条件
遇到叶子节点就终止,和遍历模板中一致
class Solution {
private:
int res = 0;//记录摄像头数量
int traversal(TreeNode* cur){//确定递归函数参数与返回值
if(cur == NULL) return 2;//空节点按规则返回2状态
}
public:
int minCameraCover(TreeNode* root) {
}
};
3、确定单层处理逻辑
这里就是完成左右中的后序遍历逻辑就行
需要在中的位置处理我们的3中左右子节点的情况,来给当前节点返回一个状态(第四种状态在主函数中处理)
class Solution {
private:
int res = 0;//记录摄像头数量
int traversal(TreeNode* cur){//确定递归函数参数与返回值
//确定终止条件,遇到叶子节点终止,该节点有覆盖(因为是空节点)
if(cur == NULL) return 2;
//确定单层处理逻辑,即左右中
int left = traversal(cur->left);//左
int right = traversal(cur->right);//右
//中,处理4种左右节点的情况
if(left == 2 && right == 2) return 0;//左右子节点都有覆盖(2)
if(left == 0 || right == 0){//左右子节点至少有一个无覆盖
res++;
return 1;
}
if(left == 1 || right == 1) return 2;//左右子节点至少有一个有摄像头(1)
return -1;//需要一个返回值,但代码不会运行到这
}
public:
int minCameraCover(TreeNode* root) {
}
};
注意,递归函数有返回值,需要用变量接一下,并且最后需要给一个返回值-1(尽管不会执行到此处)
完整代码
剩下的一种情况是遍历结束根节点没被摄像头覆盖,我们可以在主函数中处理该情况
只要在调用递归函数后判断一下最终返回值是否为0即可(注意返回值不是res)
如果是0表示当前二叉树在遍历结束后,根节点的状态没有变为被覆盖(2),要多设置一个摄像头(就让res再加1即可)
class Solution {
private:
int res = 0;//记录摄像头数量
int traversal(TreeNode* cur){//确定递归函数参数与返回值
//确定终止条件,遇到叶子节点终止,该节点有覆盖(因为是空节点)
if(cur == NULL) return 2;
//确定单层处理逻辑,即左右中
int left = traversal(cur->left);//左
int right = traversal(cur->right);//右
//中,处理4种左右节点的情况
if(left == 2 && right == 2) return 0;//左右子节点都有覆盖(2)
if(left == 0 || right == 0){//左右子节点至少有一个无覆盖
res++;
return 1;
}
if(left == 1 || right == 1) return 2;//左右子节点至少有一个有摄像头(1)
return -1;//需要一个返回值,但代码不会运行到这
}
public:
int minCameraCover(TreeNode* root) {
//在这里处理root无覆盖的情况
if(traversal(root) == 0){//调用递归进行后序遍历,如果根节点没被覆盖,额外加个摄像头
res++;
return res;
}
return res;
}
};