一:硬盘存储
1、存储类型
根据存储的可以将存储分为内存和外存两类。
2、硬盘和磁盘:
磁盘是一个广泛的概念,是
一个总的称呼
,用来描述多种不同类型的存储介质,包括硬盘、软盘、光盘、闪存盘等等。
所以硬盘也可以被称为磁盘,因为硬盘也是一种磁性存储介质。
3、硬盘类型
根据存储原理的不同,可以将硬盘分为机械硬盘和固态硬盘两类。

4、接口类型
从整体的角度上,硬盘接口分为IDE、SCSI、STAT、USB、M.2等类型。
- IDE
:133MB/s,并行接口,早期家用电脑接口(淘汰了)
- SCSI
:640MB/s,并行接口,早期服务器用的接口
- SATA
:6Gbps,SATA数据端口与电源端口是分开的,即需要两条线,一条数据线,一条电源线, 一般的家用电脑的接口
- SAS
:6Gbps,SAS是一整条线,数据端口与电源端口是一体化的,SAS中是包含供电线的,而SATA中不包含供电线。SATA标准其实是SAS标准的一个子集,二者可兼容,SATA硬盘可以插入SAS主板上,反之不行。
- USB
:Universal Serial Bus,中文叫通用串行总线,480MB/s
- M.2
:M.2接口,是Intel推出的一种替代MSATA新的接口规范(
M.2就是从笔记本诞生的
)。可以兼容多种通信协议,如sata、PCIe、USB等。如果 M.2 插槽如果不支持特定的协议,相应的固态硬盘将无法识别和使用。


5、硬盘尺寸
服务器使用的硬盘尺寸只要有两种,LFF和SFF。

6、数据的存储方式
机械硬盘存储数据的时候,是将数据存储在其内部的盘面上。盘面类似于DVD光盘,每个盘面划分成了一圈一圈的磁道,最外圈是0磁盘。然后每个磁盘有划分为了N多个小块,这个小块叫做扇区。扇区大小固定,是512byte。
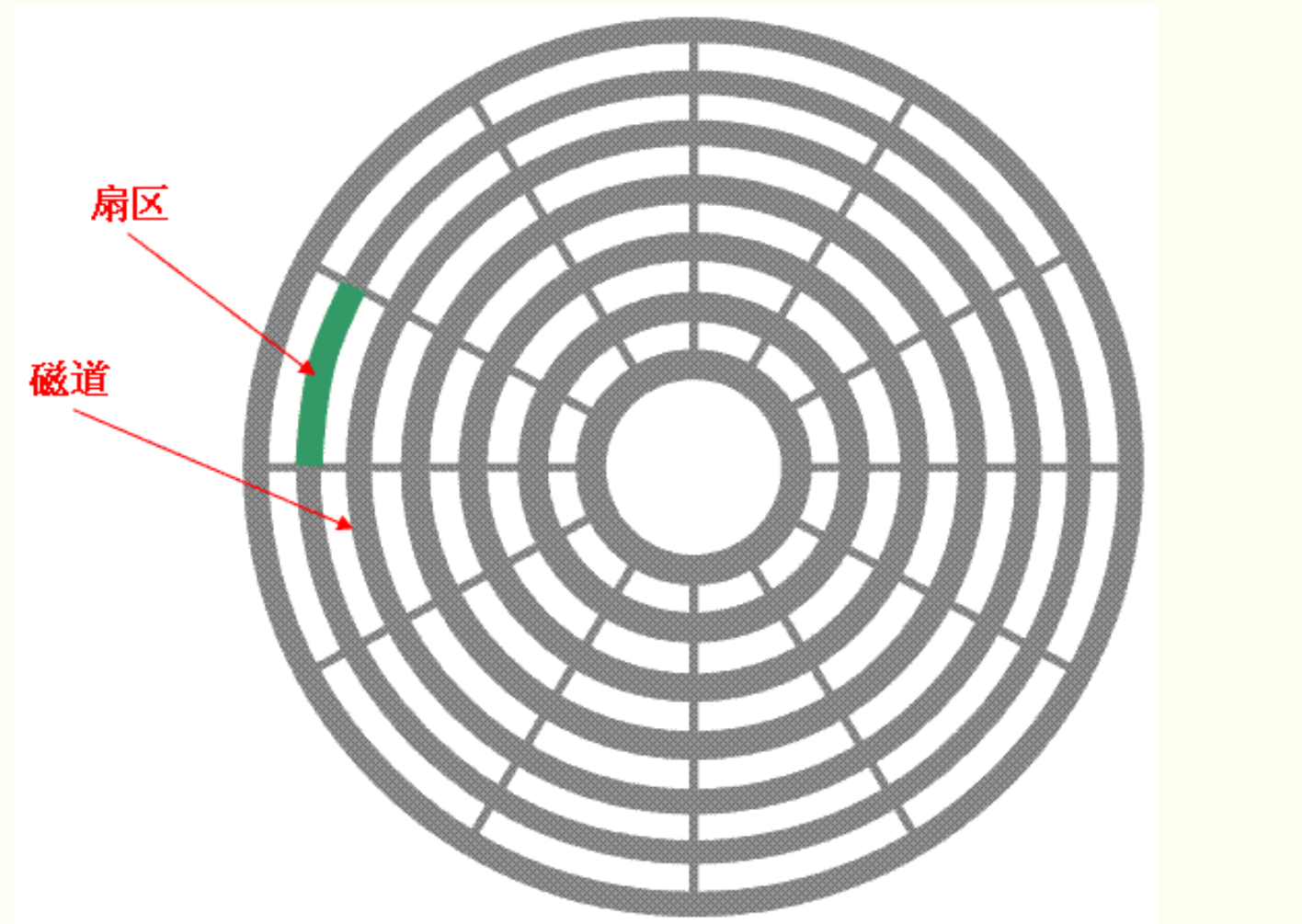
0磁道0扇区:
指的就是最外面那个磁盘的第一个扇区,大小是512字节。
7、硬盘空间的使用
在服务器上加入一块新的硬盘后,需要经过分区、格式化和挂载才能正常使用硬盘的空间。
- 硬盘分区:
将一个物理硬盘在逻辑上分为多个硬盘,每一个逻辑硬盘就叫做一个分区。
- 创建文件系统
:硬盘或分区格式化的过程就是创建文件系统的过程。
- 挂载新文件系统
:将额外文件系统与根文件系统某现存的目录建立起关联关系,进而使得此目录做为其它文件访问入口的行为
8、硬盘的分区说明
将硬盘进行分区具备以下优点:
- 便于数据管理,可以将操作系统、应用程序、用户数据等分别存储在不同的分区
- 可以安装多个操作系统和使用不同的文件系统,将不同的操作系统安装在不同的分区中,这样可以避免不同操作系统之间的冲突。
- 可以优化磁盘的性能,将操作系统、应用程序等放置在不同的分区中,可以避免数据碎片,提升硬盘读写速度。
对硬盘进行分区的时候有两种分区方式(MBR分区和GPT)分区,不同的分区方式具有不同的特点。
MBR分区:
Master Boot Record(主引导记录),1982年开发而来,使用32位表示扇区数,分区的大小不能超过2T,最多只能有四个主分区,如果需要使用更多的分区,可以将一个分区格式化为逻辑分区,再基于逻辑分区创建多个扩展分区。
硬盘使用MBR的分区类型方式后,会将整个硬盘的分区信息放在0磁道0扇区这个512字节大小的空间中,前446字节存放boot loader,中间64字节存放分区表信息。每16字节用来标识一个分区信息。最后2字节作为标志位。
MBR的三种分区类型
- 主分区
:primary。可以存放数据也可以装系统
- 扩展分区
:extended。不能直接存数据,需要在里面划分逻辑分区才能存放数据(相当于一个容器)
- 逻辑分区
:logical。作用和主分区一样
GPT分区:
GUID(Globals Unique Identifiers) partition table,最多支持128个分区,其中没有扩展分区的概念。每个分区都可以是主分区.每个分区的最大空间理论上可以达到9.4ZB。
BIOS和UEFI:
作用:BIOS和UEFI都是负责计算机硬件初始化、开机自检和引导操作系统。
- BIOS:
是只读内存(ROM)中的一段程序,这段程序叫做"基本输入输出系統"(BasicInput/Output System),简称为BIOS,计算机通电后,第一件事就是读取ROM芯片中的程序。
- EFI:
(Extensible Firmware Interface)可扩展固件接口,最初由Intel开发,是Intel的专有技术。是BIOS的升级版。
- UEFI:
(Unified Extensible Firmware Interface)统一的可扩展固件接口,是基于EFI标准的一个具体实现,并由多个公司共同推动和支持,现在UEFI是一个开放的标准,UEFI不再是intel的专有技术。
BIOS和UEFI的区别
- BIOS只能引导传统的MBR分区,UEFI支持MBR、GPT等分区。
- UEFI提供了Secure Boot(安全启动)功能,在启动过程中只加载由受信任的制造商签名的软件和驱动程序。
- UEFI支持的硬件设备和接口更多,例如USB 3.0、NVMe、网络堆栈等
- UFEI提供了图形界面,可以用鼠标操作,BIOS只能用键盘操作。
windows:只能安装 BIOS + MBR 或是 UEFI + GPT组合。
linux:可以实现 BIOS + GPT + GRUB 组合
Linux中的设备文件:
在linux中,一切及皆文件,包括硬件设备。硬件设备会被映射为
/dev
下面的一个文件设备文件。
设备文件根据存储单位的不同分为两种
:
- 块设备文件:存储单位是block,例如硬盘。
- 字符设备文件:存储单位是char,例如键盘。
设备文件的命令规则:
# SAS,SATA,SCSI,IDE,USB: /dev/sdX
# nvme协议: /dev/nvme0n#
# 虚拟磁盘: /dev/vd 或/dev/xvd
查看块设备文件:lsblk
tom@ubuntu1604:~$ lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 ext4 8a39188a-59cd-4899-b4c1-22aec246c18f /
├─sda2
└─sda5 swap 4442a597-37c1-4639-bc25-881505c12d98 [SWAP]
sdb
├─sdb1 ntfs 老毛桃U盘 1C98D9A698D97EA8
└─sdb2 vfat EFI 0BE8-0ECB
sr0 iso9660 Ubuntu-Server 16.04.6 LTS amd64 2019-02-27-00-06-32-00
二:文件系统
1、文件系统的概念
文件系统就是在操作系统中
负责管理和存储文件信息的软件结构
称为文件管理系统。
文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索。
文件系统的创建:
硬盘或分区在进行格式化的过程,就是创建文件系统的过程。
windows 常用文件系统
- FAT32
:最多只能支持16TB的文件系统和4GB的文件
- NTFS
:New Technology File System。windows独有的文件系统,linux不支持。最多只能支持16EB的文件系统和16EB的文件
- exFAT
:Linux和windows都支持,时为了解决FAT32等不支持4G及其更大的文件而推出de1,适合于闪存的文件系统,例如U盘。
Linux 常用文件系统
- ext系列:
最新版本的时ext4,Ext4的文件系统容量达到1EB,而支持单个文件则达到16TB,理论上支持无限数量的子目录。
- xfs:
最大可以支持8EB的文件系统,而支持单个文件则达到8EB,能以接近裸设备I/O的性能存储数据。
- swap:
用于Linux的交换分区,在Linux中,使用整个交换分区来提供虚拟内存。
- iso9660:
光盘的文件系统类型
裸文件系统
- raw:
裸文件系统是指未经过格式化的磁盘分区或映像文件,因此它没有文件系统结构和元数据,也没有任何文件或目录可见。
裸文件系统是一个块设备,它可以像其他块设备一样进行读写操作,因此裸文件系统通常用于虚拟化环境中,作为虚拟机磁盘镜像的基础。
网络文件系统
- NFS:
(Network File System)网络文件系统,一般使用在局域网中。
- CIFS:
(Common Internet File System)通用过internet文件系统。
虚拟文件系统
- VFS:
为用户程序提供文件和文件系统操作的统一接口,屏蔽不同文件系统的差异和操作细节。
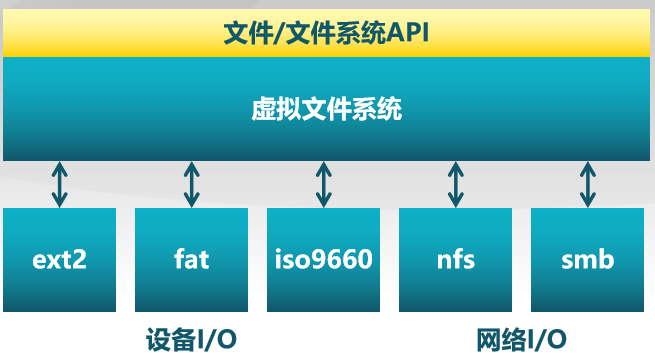
例如:
使用ls查看磁盘上的文件,因为文件系统的功能是由操作系统的内核提供,应用程序是通过访问文件系统,然后文件系统再去访问具体的文件,但是不同文件系统底层是实现和区别差别可能非常大。所以程序的系统调用可能会不同,为了方便程序的统一调用,就就使用了虚拟文件系统提供统一的接口。
文件系统的组成
由三部分组成,分别是内核中的模块,虚拟文件系统和用户空间的管理工具。
- 内核中的模块
:提供对应文件系统的功能。例如ext4, xfs, vfat
- Linux的虚拟文件系统
:提供统一的接口。例如VFS
- 用户空间的管理工具
:提供对内核文件系统管理的工具。例如mkfs.ext4, mkfs.xfs,mkfs.vfat
查看当前系统支持的文件系统:
# 方法一:
ls -l /lib/modules/`uname -r`/kernel/fs
# 方法二:
cat /proc/filesystems

2、Inode 和 Block
当某个存储设备被格式化为EXT系列的文件系统后,文件系统会将磁盘空间分为两部分:inode区域和数据区域(也称为块区域)。
Inode区域:
存放文件的元数据信息
包含了若干了Inode,每个inode存放一个文件的元数据信息(文件大小、类型、权限、UID、GID、所有者、所属组等信息)和唯一的Inode编号,以及指向文件数据块的指针。
Block区域:
存放文件真正的数据部分
- 存放文件的真正数据部分,数据区域被分割成一个个大小相等的块,每个块通常为4KB或8KB。
- 目录块也是存储在数据区域中的一种特殊的数据块,它存储了一组目录项,每个目录项存放一个文件的文件名和Inode编号。
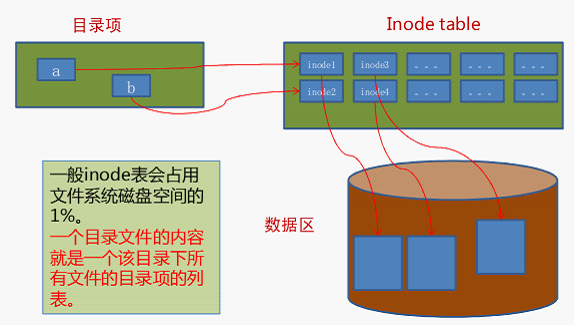
例如:
当需要访问一个文件时,文件系统会通过目录项找到对应的inode,然后根据inode中的信息来读取或写入文件的内容。因此,目录项在文件系统中扮演了非常重要的角色,它们充当了文件和文件系统之间的桥梁。
删除某个目录就是把目录文件的数据块部分的文件列表和文件的节点编号的映射关系删除的过程
在EXT系列文件系统中创建文件流程:
- 首先,文件系统会找到一个未使用的inode号码,并分配给新文件。inode包含文件的元数据,如权限、所有者、创建时间、修改时间等信息。
- 然后,文件系统会找到一个或多个未使用的数据块,这些数据块将用于存储文件的实际内容。
- 接着文件系统会将inode与数据块的信息记录在文件系统的元数据区域中,以便以后可以找到并访问它们。
- 最后文件系统会将文件的名称和与该文件相关联的inode号码存储在目录中。目录是一个特殊的文件,它包含文件系统中所有文件和目录的列表。
3、软链接和硬链接
软链接:
类似于windows的快捷方式
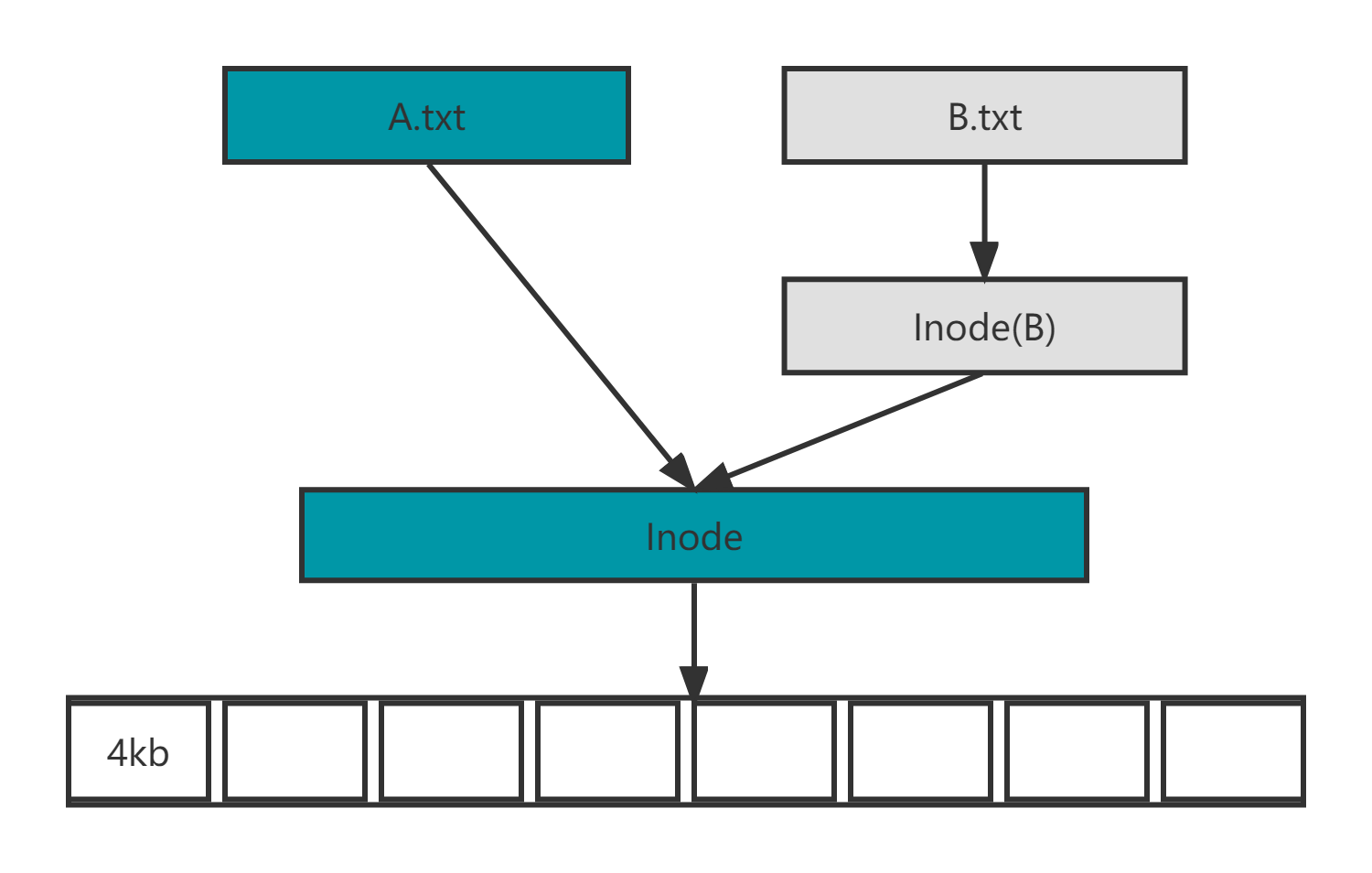
特点:
硬链接:
一个文件多个文件名
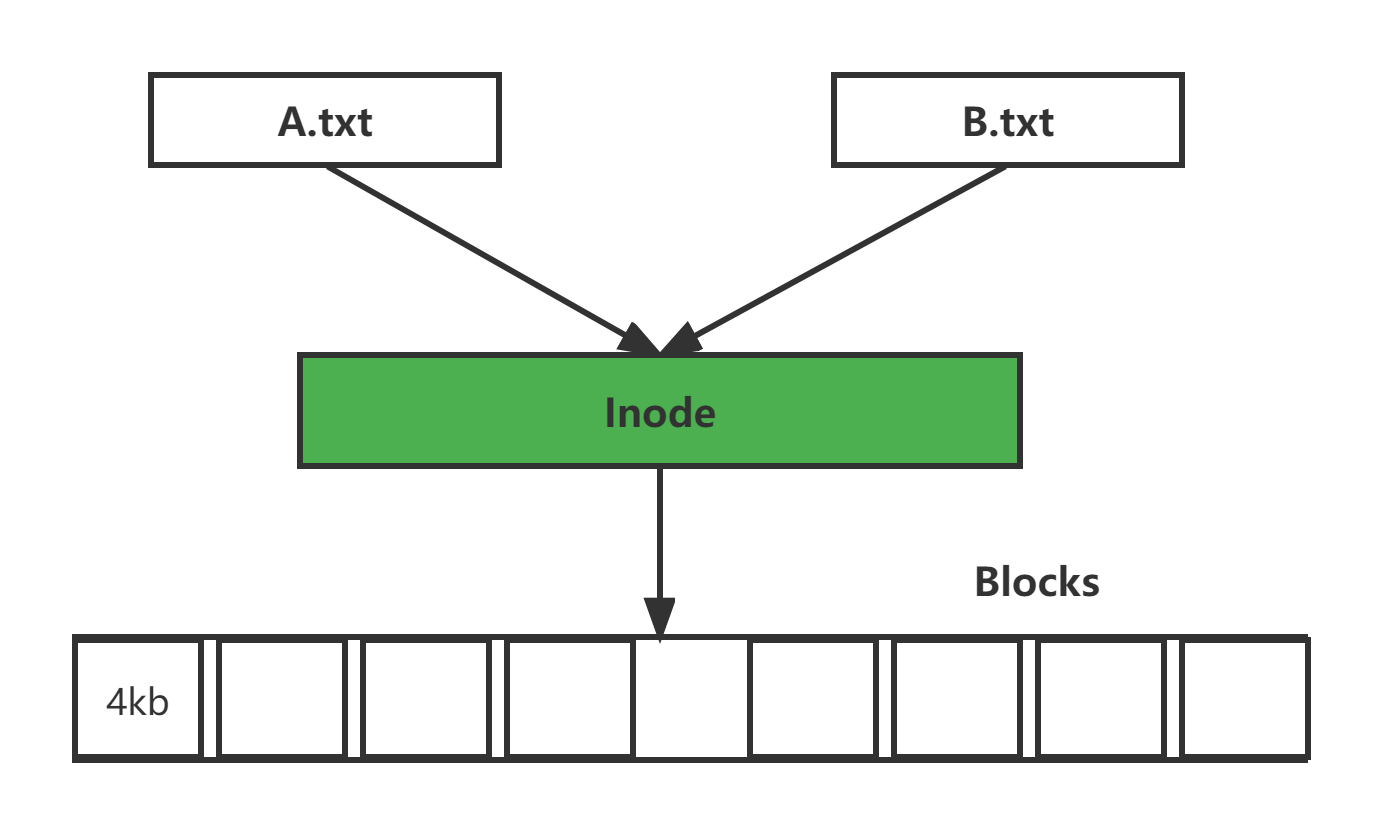
特点:
- 不允许对目录文件创建硬链接
- 不能跨设备、跨分区,例如sda1的文件不能硬链接到sda2上面。
4、硬盘的分区工具
fdisk
使用fdisk创建硬盘分区的时候,默认会将硬盘的分区类型格式化为MBR格式的分区类型。
例如:
# 创建分区表
root@ubuntu1804:~# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.31.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n # 创建一个分区表
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p # 创建主分区
Partition number (1-4, default 1): # 分区编号,
First sector (2048-41943039, default 2048): # 不输入表示从当前位置开始
Last sector, +sectors or +size{K,M,G,T,P} (2048-41943039, default 41943039): +10G # 分区的大小
Created a new partition 1 of type 'Linux' and of size 10 GiB.
Command (m for help): p # 查看分区表的信息
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x3ea7c314
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 20973567 20971520 10G 83 Linux
Command (m for help): w # 保存设置并退出
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
# 删除分区表
root@ubuntu1804:~# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.31.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): p
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x3ea7c314
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 20973567 20971520 10G 83 Linux
/dev/sdb2 20973568 31459327 10485760 5G 83 Linux
Command (m for help): d # 删除分区表
Partition number (1,2, default 2): 2 # 删除的分区表编号 表示删除第二个分区
Partition 2 has been deleted.
Command (m for help): p
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x3ea7c314
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 20973567 20971520 10G 83 Linux
Command (m for help): w #保存退出
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
gdisk
gdisk工具是默认会把硬盘的分区类型格式化为GPT类型。如果分区类型非gpt格式,会默认转换为gpt格式。
例如:
# 新建分区表
root@ubuntu1804:~# gdisk /dev/sdb
GPT fdisk (gdisk) version 1.0.3
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): n
Partition number (1-128, default 1):
First sector (34-41943006, default = 2048) or {+-}size{KMGTP}:
Last sector (2048-41943006, default = 41943006) or {+-}size{KMGTP}: +2G
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300):
Changed type of partition to 'Linux filesystem'
Command (? for help): w
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): Y
OK; writing new GUID partition table (GPT) to /dev/sdb.
The operation has completed successfully.
# 删除分区表
root@ubuntu1804:~# gdisk /dev/sdb
GPT fdisk (gdisk) version 1.0.3
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present # 当前硬盘的分区类型
Found valid GPT with protective MBR; using GPT.
Command (? for help): p
Disk /dev/sdb: 41943040 sectors, 20.0 GiB
Model: VMware Virtual S
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): E0199E20-EDB2-43D1-B653-3E8080E547EA
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 41943006
Partitions will be aligned on 2048-sector boundaries
Total free space is 37748669 sectors (18.0 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 4196351 2.0 GiB 8300 Linux filesystem
Command (? for help): d 1 # 删除标号为1的分区表
Using 1
Command (? for help): w # 保存退出
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): Y # 确认更改
OK; writing new GUID partition table (GPT) to /dev/sdb.
The operation has completed successfully.
parted
parted工具可以管理gpt和mbr类型的分区表,其它的分区类型也可以管理,例如sun、bsd等。
注意:parted的操作都是实时生效的,需要小心使用。
例如:
# 新建分区表
root@ubuntu1804:~# parted /dev/sdb
GNU Parted 3.2
Using /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p # 将硬盘分区类型改为gpt
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
(parted) mklabel gpt
Warning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? yes # 确认更改
(parted) mkpart primary ext4 0% 20% # mkpart 分区类型 文件系统类型 分区的开始位置 分区的结束位置 -1:表示磁盘的最后
(parted) mkpart primary ext4 20% 40%
(parted) mkpart primary ext4 40% 70%
(parted) p # 查看分区表信息
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 4295MB 4294MB ext4 primary
2 4295MB 8590MB 4295MB ext4 primary
3 8590MB 15.0GB 6442MB ext4 primary
(parted) quit
Information: You may need to update /etc/fstab.
# 删除分区表 # 退出
root@ubuntu1804:~# parted /dev/sdb
GNU Parted 3.2
Using /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 10.7GB 10.7GB primary
(parted) rm 1 # rm 1 表示删除编号为1的分区表
(parted) quit
Information: You may need to update /etc/fstab.
查看分区类型:
PTTYPE="dos" # MBR类型
PTTYPE="gpt" # GPT类型
Partition Table: msdos # MBR类型
Partition Table: gpt # GPT类型
Disklabel type: dos # MBR类型
Disklabel type: gpt # GPT类型
修改分区类型
parted /dev/sdb
(parted) mklabel gpt
parted /dev/sdb
(parted) mklabel msdos
5、硬盘格式化工具
mkfs工具
mkfs是一个Linux/Unix操作系统中用于创建文件系统的命令行工具,它可以用于格式化磁盘或分区,以便在上面创建新的文件系统。
例如:
# 格式化硬盘为ext4文件系统
sudo mkfs.ext4 /dev/sdb 或 sudo mkfs -t ext4 /dev/sdb
# 指定Inode的数量
sudo mkfs -t ext4 -M 2000000 /dev/sdb
常用选项:
-t {ext2|ext3|ext4|xfs} 指定文件系统类型
-b {1024|2048|4096} 指定块 block 大小,默认4kb
-L ‘LABEL’ 设置卷标,便于在系统中识别。
-i # 指定一个inode节点的大小;默认256字节,即一个block可以存放16个inode
-N # 指定分区中创建多少个inode,默认inode空间占总空间的1%
硬盘挂载工具
硬盘挂载是将硬盘驱动器(例如硬盘、SSD等)连接到操作系统文件系统的过程,将某个硬盘驱动器挂载到文件系统后就可以对硬盘进行读写等操作。
mount工具
例如:
# 将/dev/sdb1挂载到/mnt/data 不指定文件系统类型,会自动进行检测
sudo mount /dev/sdb1 /mnt/data
# 挂载的时候手动指定文件系统的类型
sudo mount -t ntfs /dev/sdb1 /mnt/data
说明:
使用mount进行挂载的时候,如果确定了要挂载的文件系统的类型,使用-t参数指定文件系统类型可以确保系统以正确的方式挂载文件系统,避免可能的错误和问题。
如果挂载的时候不确定文件系统的类型,系统会对文件系统进行自动检测,但是当存在多个可能的文件系统类型时,系统可能会选择错误的类型导致挂载失败。
mount命令的常用参数:
-t fstype:指定文件系统类型,如果不指定会自动进行检测
-o <挂载选项>:指定挂载选项,多个选项用逗号隔开。
# 挂载选项
# ro 以只读方式挂载文件系统。
# remount 重新挂载文件系统,相当于先umount再mount
# defaults 使用默认的挂载选项,相当于rw, suid, dev, exec, auto, nouser, async
# async 异步模式,内存更改时,写入缓存区buffer,过一段时间再写到磁盘中,效率高,但不安全
# sync 同步模式,内存更改时,同时写磁盘,安全,但效率低下
# noatime 指定文件系统不更新最后访问时间
# _netdev 当网络可用时才对网络资源进行挂载,如:NFS文件系统,如果网络不可达不加该选项会导致系统无法启动。
-r:以只读方式挂载文件系统。
-w:以可读写方式挂载文件系统,默认就是以可读可写的方式挂载
-a 自动挂载所有支持自动挂载的设备(定义在了/etc/fstab文件中,且挂载选项中有auto功能)
noatime选项说明:
使用
noatime
选项可以禁止系统更新文件或目录的访问时间戳,即
atime
属性。当文件或目录被访问时,系统不会更新
atime
属性,而是保留原来的值,可以较少磁盘IO,提高文件系统的性能。
使用noatime的场景:
在某些高并发的应用中,可能会有大量的读取操作,如果每次读取都更新
atime
属性,会对系统的性能造成很大的影响。这种情况下可以考虑加noatime选项。
不能使用noatime的场景:
如果应用程序需要用到文件的访问时间,就不能使用
noatime
选项。因为使用
noatime
选项会禁止系统更新文件或目录的访问时间戳,即
atime
属性,这会导致应用程序无法获取文件的最后访问时间,从而影响应用程序的功能。
挂载规则说明:
- 一个挂载点同一时间只能挂载一个设备,如果挂载了多个设备就只显示最后一个设备
- 一个设备可以挂载到多个挂载点
- 挂载点通常是空的目录文件
umount工具
umount用于卸载挂载的文件系统。
例如:
umount device 或 umount mountpoint
# 例如:
umount /dev/sda1
查看挂载的设备
# 方法一:使用mount命令,会列出所有已挂载的设备及其挂载点
root@ubuntu1804:~# mount
/dev/sda5 on / type ext4 (rw,relatime,errors=remount-ro,data=ordered)
# 方法二:查看内核参数
root@ubuntu1804:~# cat /proc/mounts
/dev/sda1 /boot ext4 rw,relatime,data=ordered 0 0
# 方法三:df命令
root@ubuntu1804:~# df -hT
Filesystem Type Size Used Avail Use% Mounted on
udev devtmpfs 954M 0 954M 0% /dev
tmpfs tmpfs 198M 11M 187M 6% /run
/dev/sda5 ext4 58G 4.2G 51G 8% /
tmpfs tmpfs 986M 0 986M 0% /dev/shm
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs tmpfs 986M 0 986M 0% /sys/fs/cgroup
/dev/sda1 ext4 922M 80M 780M 10% /boot
tmpfs tmpfs 198M 0 198M 0% /run/user/0
持久挂载:
将挂载保存到
/etc/fstab
中可以下次开机时,自动启用挂载
#使用`man 5 fstab `查看/etc/fstab配置文件格式
# 格式
device mountpoint fs_type options 0 0
# 例如:
/dev/sdb1 /data ext4 defaults,noatime 0 0
# 表示将/dev/sdb1这个分区挂载到/data这个目录,并且使用默认的挂载选项,不进行本分和文件系统检查。
# 说明
# 备份频率(一般用不上):0:不做备份 1:每天转储 2:每隔一天转储
# 文件系统检查的次序:开机检测文件系统的过程。其中允许的数字是0 1 2
# 0:不自检 ,1:首先自检;一般只有rootfs才用 2:非rootfs使用
6、移动设备的管理
当把u盘设备插入linux系统后,会被内核探测为SCSI设备,会被映射到/dev下作为一个设备文件。例如:/dev/sdaX、/dev/sdbX等。

说明:
ubuntu默认支持识别 NTFS 文件系统格式的 U 盘,CentOS 默认情况下不支持识别 NTFS 文件系统格式的 U 盘。
如果不识别需要安装
ntfs-3g
软件包来支持 NTFS 格式的 U 盘。
插入u盘后可以通过系统日志看到相关信息:
root@ubuntu1804:~# tail -f /var/log/syslog
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.106369] usb 1-1: new high-speed USB device number 8 using ehci-pci
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.455825] usb 1-1: New USB device found, idVendor=0930, idProduct=6544
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.455827] usb 1-1: New USB device strings: Mfr=1, Product=2, SerialNumber=3
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.455828] usb 1-1: Product: DataTraveler 2.0
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.455829] usb 1-1: Manufacturer: Kingston
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.455829] usb 1-1: SerialNumber: 001BFC3653BCC341E91386F4
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.458677] usb-storage 1-1:1.0: USB Mass Storage device detected
Mar 19 17:14:51 ubuntu1804 kernel: [ 5822.458909] scsi host33: usb-storage 1-1:1.0
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.499865] scsi 33:0:0:0: Direct-Access Kingston DataTraveler 2.0 1.00 PQ: 0 ANSI: 4
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.500256] sd 33:0:0:0: Attached scsi generic sg3 type 0
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.504780] sd 33:0:0:0: [sdc] 60549120 512-byte logical blocks: (31.0 GB/28.9 GiB)
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.507219] sd 33:0:0:0: [sdc] Write Protect is off
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.507220] sd 33:0:0:0: [sdc] Mode Sense: 45 00 00 00
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.509773] sd 33:0:0:0: [sdc] Write cache: disabled, read cache: enabled, doesn't support DPO or FUA
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.523647] sdc: sdc1 sdc2
Mar 19 17:14:52 ubuntu1804 kernel: [ 5823.535055] sd 33:0:0:0: [sdc] Attached SCSI removable disk
lsusb工具
lsusb工具用于显示 USB 总线上连接的设备列表。使用
lsusb
可以查看连接到计算机上的 USB 设备列表。从而判断u盘设备是否插入了系统中。
例如:查看usb设备信息:
# usbutils工具包
root@ubuntu1804:~# lsusb
Bus 001 Device 008: ID 0930:6544 Toshiba Corp. TransMemory-Mini / Kingston DataTraveler 2.0 Stick (2GB)
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 003: ID 0e0f:0002 VMware, Inc. Virtual USB Hub
Bus 002 Device 002: ID 0e0f:0003 VMware, Inc. Virtual Mouse
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub

7、du和df使用说明
du
:disk usage。
一般是用来查看目录或指定文件的大小
选项:
-h # 自动使用合适的单位进行显示,默认单位是kb
-s # 显示指定目录或文件的总大小
--exclude=/path # 用于排除指定的文件或目录
例如:
# 查看整个系统的大小,但不统计/sys和/proc这连个虚拟文件系统
root@ecs-1746-0001:~# du -sh --exclude='/proc' --exclude='/sys' /
23G /
# 统计某个目录下目录文件的大小
# 需要进入待统计的目录
root@ecs-1746-0001:~# cd DeploySystem-Ubuntu-20.04/
root@ecs-1746-0001:~/DeploySystem-Ubuntu-20.04# du -sh */ | sort -rh
2.1G packages/
5.6M lib/
3.1M phplib/
156K conf/
48K include/
16K job/
4.0K SourceCode/
# */通配符表示所有子目录
# 统计某个目录下每个文件的大小
# 1. 进入该目录
root@ecs-1746-0001:~# cd DeploySystem-Ubuntu-20.04/
# 2. 进行统计
root@ecs-1746-0001:~/DeploySystem-Ubuntu-20.04# du -ah --exclude='{'.','..'}' */ | sort -rh | more
# --exclude='{'.','..'}'表示不统计.和..文件
# */通配符表示所有子目录
df:
disk free,主要用来查看挂载了的文件系统情况。
注意:
df看到的文件系统中真实占用的空间大小,而非表面上的空间大小。因为文件系统本身就有元数据,所以即使是刚创建的干净文件系统,也会占用一定的空间
选项:
-h:自动使用合适的单位进行数据的显示
-T:显示文件系统的类型
例如:
root@ubuntu1804:~# df -hT
Filesystem Type Size Used Avail Use% Mounted on
udev devtmpfs 954M 0 954M 0% /dev
tmpfs tmpfs 198M 11M 187M 6% /run
/dev/sda5 ext4 58G 4.2G 51G 8% /
tmpfs tmpfs 986M 0 986M 0% /dev/shm
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs tmpfs 986M 0 986M 0% /sys/fs/cgroup
/dev/sda1 ext4 922M 80M 780M 10% /boot
tmpfs tmpfs 198M 0 198M 0% /run/user/1000
tmpfs tmpfs 198M 0 198M 0% /run/user/0
df和du统计信息不相同的情况:
当把文件删除了,但是空间并没有被释放(有进程再使用这个文件,删除了这个文件不会马上释放空间)时候,使用df看到的数据比du统计的大。即:
df>du
例如:
# 创建要给1G大小的文件
root@ubuntu1804:~# dd if=/dev/zero of=./a.txt bs=1G count=1
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 1.23766 s, 868 MB/s
#
root@ubuntu1804:~# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda5 ext4 58G 5.2G 50G 10% /
/dev/sda1 ext4 922M 80M 780M 10% /boot
root@ubuntu1804:~# du -sh /
5.2G /
# 在另一个窗口使用vim打开这个文件
root@ubuntu1804:~# vim a.txt
# 在本窗口删除该文件
root@ubuntu1804:~# rm -rf a.txt
# 使用lsof查看,发现a.txt这个文件被vim进程使用,所以删除了文件没有释放空间
root@ubuntu1804:~# lsof | grep delete
vim 22197 root 3r REG 8,5 1073741824 3673208 /root/a.txt (deleted)
# 再次统计大小
root@ubuntu1804:~# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda5 ext4 58G 5.2G 50G 10% /
/dev/sda1 ext4 922M 80M 780M 10% /boot
root@ubuntu1804:~# du -sh /
4.2G /
当某个目录文件挂载到其他设备了的时候(多个设备空间的组合),这就是所说的文件系统重叠时候。即
df < du
例如:
# /dev/sda5分区挂载到/根目录下,显示已经用了4.2G空间
root@ubuntu1804:~# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda5 ext4 58G 4.2G 51G 8% /
/dev/sda1 ext4 922M 80M 780M 10% /boot
# 使用du工具统计根目录大小也是4.2G
root@ubuntu1804:~# du -sh /
4.2G /
# 将sdb1分区挂载到/xx下
root@ubuntu1804:~# mount /dev/sdb1 /xx
# 创建要给1G大小的文件
root@ubuntu1804:~# dd if=/dev/zero of=/xx/a.txt bs=1G count=1
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 10.6664 s, 101 MB/s
# 再次使用du统计/的大小已经变为了5.2G
root@ubuntu1804:~# du -sh /
5.2G
# 使用df查看 仍然是4.2G
root@ubuntu1804:~# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda5 ext4 58G 4.2G 51G 8% /
/dev/sda1 ext4 922M 80M 780M 10% /boot
/dev/sdb1 ext4 3.9G 1.1G 2.7G 28% /xx