初学J2V8
V8和J2V8
V8
V8是Google开源的JavaScript和WebAssembly引擎,被用于Chrome浏览器和Node.js等。和其它JavaScript引擎把JavaScript转换成字节码或解释执行不同的是,V8在运行JavaScript之前,会将JavaScript编译成原生机器码,并且使用内联缓存等方法来提高性能,V8引擎执行JavaScript的速度可以媲美二进制程序。V8采用 C++ 编写,可以独立运行,也可以嵌入到任何 C++ 程序中。
J2V8
J2V8
是对V8引擎的一层Java封装,即J2V8借助JNI来实现Java层对C++层的访问,通过Java将V8的一些关键API暴露出来供外部程序使用。J2V8旨在为Java世界带来更加高效的JavaScript运行时环境,同时J2V8也可以在Windows、Linux、Mac OS等平台上运行。
J2V8的使用
我们在Android工程中演示J2V8如何具体使用。
创建Android工程
首先,我们通过Android Studio创建一个Android工程。
依赖J2V8
创建好Android工程之后,需要依赖J2V8库,如下:
// j2v8
implementation "com.eclipsesource.j2v8:j2v8:6.2.1@aar"
创建V8运行时实例
要使用J2V8,我们首先需要创建一个V8运行时实例,通过这个V8运行时实例,我们可以执行js脚本、注入js变量、注入原生方法等。
com.eclipsesource.v8.V8
提供了一系列创建V8运行时实例的静态方法,如下:
public static V8 createV8Runtime() {
return createV8Runtime((String)null, (String)null);
}
public static V8 createV8Runtime(String globalAlias) {
return createV8Runtime(globalAlias, (String)null);
}
public static V8 createV8Runtime(String globalAlias, String tempDirectory) {
if (!nativeLibraryLoaded) {
synchronized(lock) {
if (!nativeLibraryLoaded) {
load(tempDirectory);
}
}
}
checkNativeLibraryLoaded();
if (!initialized) {
_setFlags(v8Flags);
initialized = true;
}
V8 runtime = new V8(globalAlias);
synchronized(lock) {
++runtimeCounter;
return runtime;
}
}
我们用最简单的方法创建一个V8运行时实例,如下:
val v8 = V8.createV8Runtime()
执行js脚本
com.eclipsesource.v8.V8
提供了一系列执行js脚本的方法,如下: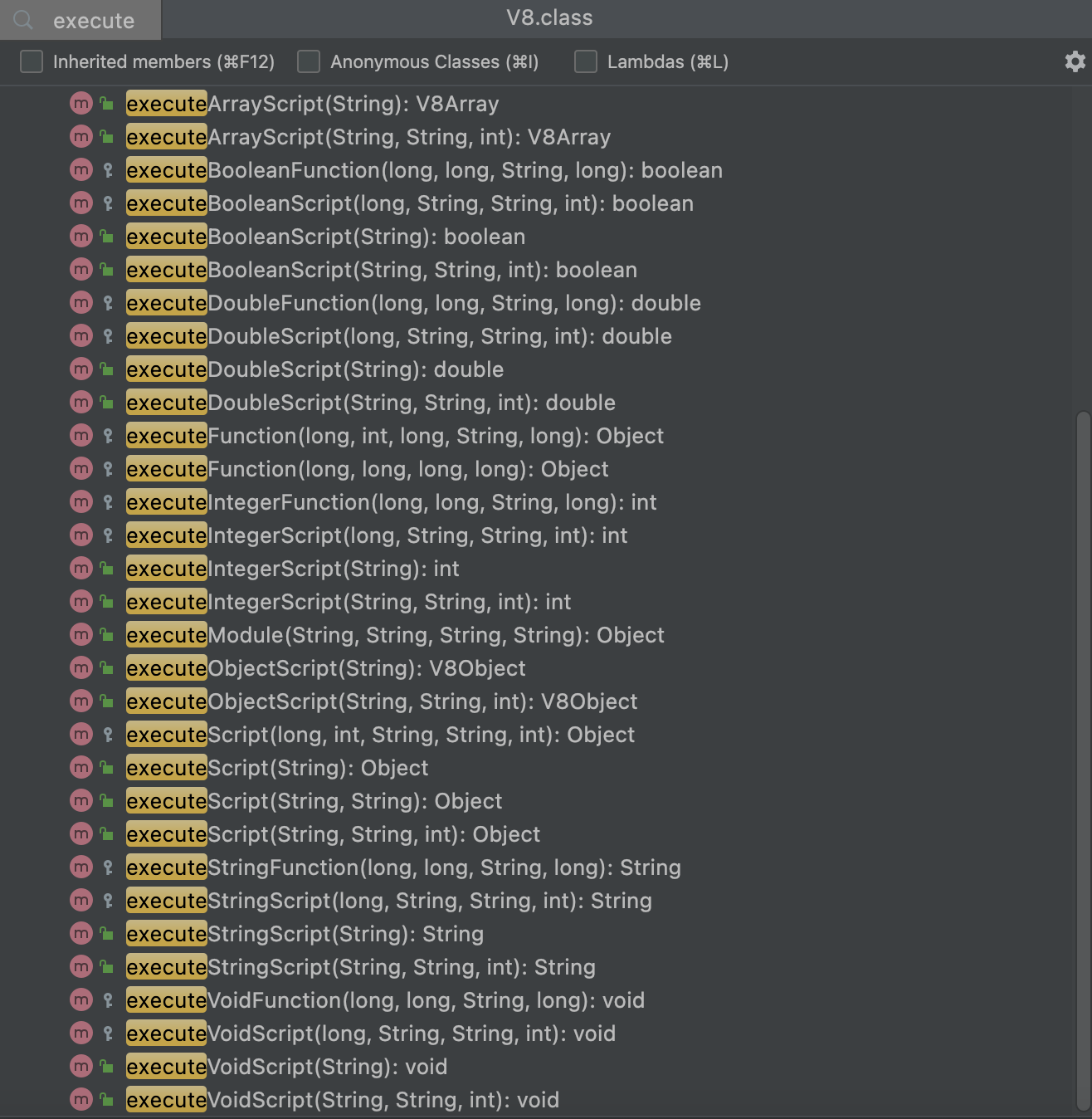
这些方法涵盖了多种不同的使用场景,例如返回不同的数据类型、执行某些具体的js函数等等,我们可以根据需要选择合适的方法来执行js脚本。
注入变量
通过
com.eclipsesource.v8.V8Object
提供的一系列
add
方法,可以给
V8Object
实例注入js变量,如下:
v8.add("key1", "value1")
v8.add("key2", "value2")
v8.add("key3", "value3")
变量注入之后,我们可以在js中直接使用这些变量。
注入原生对象
J2V8支持注入原生对象,向js注入原生对象之后,在js中可以访问原生对象以及原生对象内部的方法和属性。
如何注入原生对象呢?我们以在js中调用原生代码输出日志的场景为例。
首先,在原生代码中定义一个
Console
类,如下:
/**
* 输出日志的类
*/
class Console {
fun log(tag: String, message: V8Array) {
Log.d(tag, message.toString())
}
}
Console
类实现了一个
log
方法,用于打印日志内容。
然后,创建
Console
类对象,如下:
val console = Console()
接下来,我们创建一个
V8Object
对象,并向V8运行时对象注入这个对象,对象名命名为
console
,如下:
val consoleObject = V8Object(v8)
v8.add("console", consoleObject)
再接下来,我们通过
consoleObject
注册原生方法。
这里,我们选择通过如下方法实现原生方法的注册:
public V8Object registerJavaMethod(Object object, String methodName, String jsFunctionName, Class<?>[] parameterTypes) {
return this.registerJavaMethod(object, methodName, jsFunctionName, parameterTypes, false);
}
public V8Object registerJavaMethod(Object object, String methodName, String jsFunctionName, Class<?>[] parameterTypes, boolean includeReceiver) {
this.v8.checkThread();
this.checkReleased();
try {
Method method = object.getClass().getMethod(methodName, parameterTypes);
method.setAccessible(true);
this.v8.registerCallback(object, method, this.getHandle(), jsFunctionName, includeReceiver);
return this;
} catch (NoSuchMethodException var7) {
throw new IllegalStateException(var7);
} catch (SecurityException var8) {
throw new IllegalStateException(var8);
}
}
这是一种基于反射的方法,其中,第一个参数传原生对象即
console
,第二个参数传原生方法名称即
log
,第三个参数传js方法的名称,这里和原生方法名称保持一致(当然也可以不一致),最后一个参数传
Class
类型的数组,表示方法参数的类型,数组元素和方法参数类型必须一一对应。如下:
consoleObject.registerJavaMethod(
console, "log", "log", arrayOf(
String::class.java, V8Array::class.java
)
)
最后,一定要记得关闭手动创建的
V8Object
对象,释放native层的内存,否则会报内存泄露方面的错误。如下:
consoleObject.close()
以上步骤完成之后,我们就可以在js中愉快地打印日志了,我们使用V8运行时对象执行打印日志的js脚本,将此前注入的js变量打印出来,如下:
v8.executeScript("console.log('myConsole', [key1, key2, key3]);")
在Android Studio的Logcat中将会输出如下信息:
2022-12-25 13:21:48.932 4556-4556 myConsole com.xy.j2v8 D value1,value2,value3
注入原生方法
上面在讲注入原生对象的过程当中,其实也包含了原生方法的注入,在注入原生方法的时候,除了上面讲到的方法,还有更简单的方法。
com.eclipsesource.v8.V8Object
还提供了如下方法:
public V8Object registerJavaMethod(JavaCallback callback, String jsFunctionName) {
this.v8.checkThread();
this.checkReleased();
this.v8.registerCallback(callback, this.getHandle(), jsFunctionName);
return this;
}
public V8Object registerJavaMethod(JavaVoidCallback callback, String jsFunctionName) {
this.v8.checkThread();
this.checkReleased();
this.v8.registerVoidCallback(callback, this.getHandle(), jsFunctionName);
return this;
}
两个方法只有第一个参数不一样,
com.eclipsesource.v8.JavaVoidCallback
表示原生方法无返回值,
com.eclipsesource.v8.JavaCallback
表示原生方法有返回值,返回类型是
java.lang.Object
类型的。
两个方法的第二个参数表示要注入的方法的名称。
我们使用第一个方法,来注入一个在js中弹Toast的方法,代码如下:
v8.registerJavaMethod({ v8Object, v8Array ->
Toast.makeText(this, "$v8Object, $v8Array", Toast.LENGTH_SHORT).show()
}, "toast")
接下来,我们执行调用toast的js脚本:
v8.executeJSFunction("toast", "Hello, I am a toast!")
脚本执行之后,屏幕中将弹出文本内容为"Hello, I am a toast!"的toast。
线程模型
JavaScript本身是单线程的,J2V8也严格遵循这一点,即对单个V8运行时的所有访问必须来自同一线程,换句话说就是:V8运行时实例在哪个线程被创建,就只能在哪个线程被使用。
如果在一个线程创建了V8运行时实例,在另外一个线程中直接访问这个实例,会抛异常,如下:
Process: com.xy.j2v8, PID: 27274
java.lang.Error: Invalid V8 thread access: current thread is Thread[Thread-3,5,main] while the locker has thread Thread[main,5,main]
at com.eclipsesource.v8.V8Locker.checkThread(V8Locker.java:99)
at com.eclipsesource.v8.V8.checkThread(V8.java:840)
at com.eclipsesource.v8.V8.executeScript(V8.java:715)
at com.eclipsesource.v8.V8.executeScript(V8.java:685)
at com.xy.j2v8.MainActivity.onCreate$lambda$1$lambda$0(MainActivity.kt:27)
at com.xy.j2v8.MainActivity.$r8$lambda$jWdwVCxaGZnvyZS9q138fD71tFk(Unknown Source:0)
at com.xy.j2v8.MainActivity$$ExternalSyntheticLambda2.run(Unknown Source:2)
at java.lang.Thread.run(Thread.java:929)
J2V8单线程模型确保了在使用单个V8运行时时不存在多线程问题,例如线程之间资源竞争,出现死锁等。
GitHub
尊重原创,转载请注明出处
初学J2V8