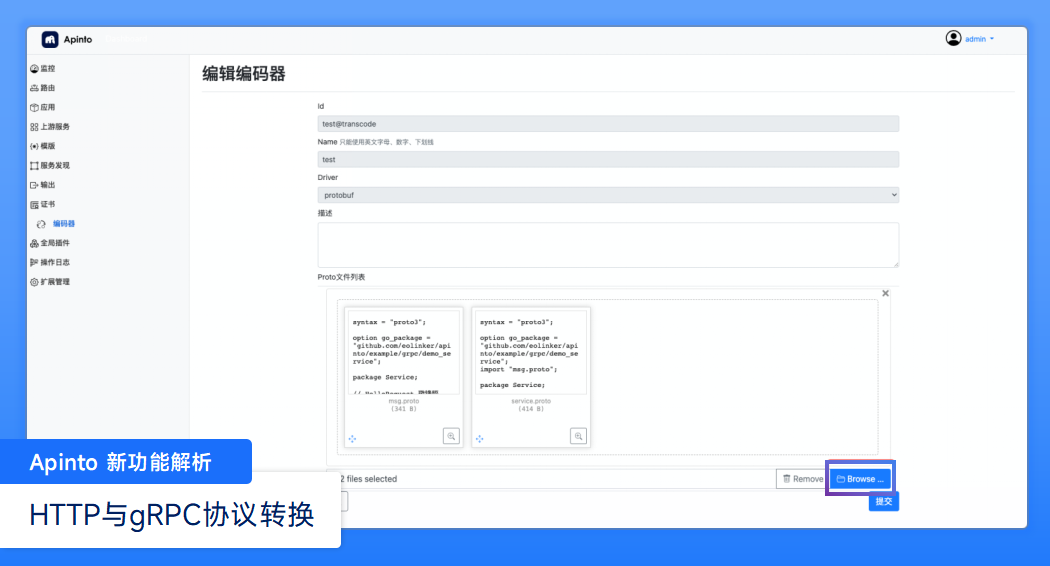
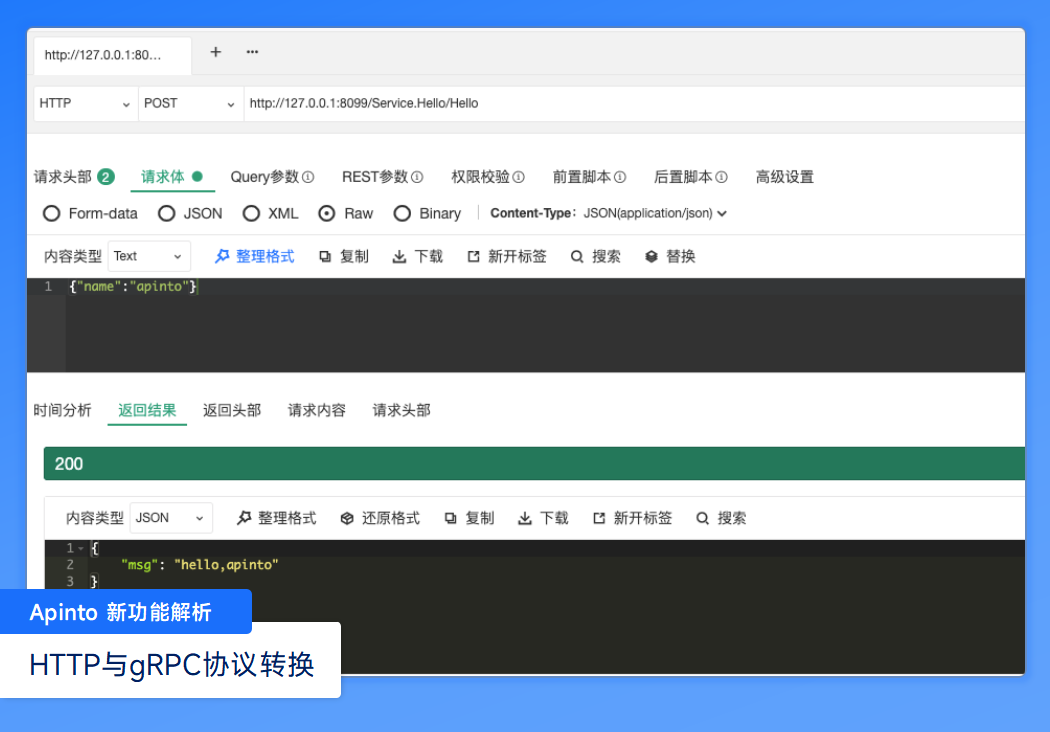
DES & 3DES 简介 以及 C# 和 js 实现【加密知多少系列】
〇、简介
1、DES 简介
DES 全称为 Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法,1977 年被美国联邦政府的国家标准局确定为联邦资料处理标准(FIPS),并授权在非密级政府通信中使用,随后该算法在国际上广泛流传开来。
在很长时间内,许多人心目中“密码生成”与 DES 一直是个同义词。直到 1997 年 NIST(美国国家标准与技术研究院)开始公开征集更安全的加密算法以替代 DES,并在 2001 年推出了更加安全的 AES(Advanced Encryption Standard)高级加密标准。
优点:
- Feistel 网络的轮数可以任意增加;
- 解密与轮函数 f 无关,轮函数f也不需要有逆函数;
- 轮函数可以设计得足够复杂;
- 加密和解密可以使用完全相同的结构来实现。
缺点:
- 分组比较短;
- 密钥太短;
- 密码生命周期短;
- 运算速度较慢。
2、3DES 简介
其实并不是直接由 DES 过渡到 AES,还有一个 3DES 统治时期。3DES 也称 Triple DES,它使用 3 条 56 位的密钥对数据进行三次加密。
3DES 算法通过对 DES 算法进行改进,增加 DES 的密钥长度来避免类似的攻击,针对每个数据块进行三次 DES 加密;因此,3DES 加密算法并非什么新的加密算法,是 DES 的一个更安全的变形,它以 DES 为基本模块,通过组合分组方法设计出分组加密算法。
相比 DES,
3DES 因密钥长度变长,安全性有所提高,但其处理速度不高
。因此又出现了 AES 加密算法,AES 较于 3DES 速度更快、安全性也更高。
加密:
- 为了兼容普通的 DES,3DES 并没有直接使用 加密->加密->加密 的方式,而是采用了
加密->解密->加密
的方式。 - 当三重密钥均相同时,前两步相互抵消,相当于仅实现了一次加密
,因此可实现对普通 DES 加密算法的兼容。
解密:
- 3DES 解密过程,与加密过程相反,即逆序使用密钥。是以密钥 3、密钥 2、密钥 1的顺序执行
解密->加密->解密
。
一、C# 代码实现
1、DES
// 测试(密钥需要是八位字符)
string jiamihou = DesEncrypt("TestString", "66666611222", false); // 57fe567eaa866373f851a526f07d9e26
string jiamiqian = DesDecrypt(jiamihou32, "66666611222");
/// <summary>
/// DES加密字符串
/// </summary>
/// <param name="deseninstr">待加密的字符串</param>
/// <param name="deskey">加密密钥,要求为8位</param>
/// <param name="isupper">返回大写密文,false:小写</param>
/// <returns>加密成功返回加密后的字符串,失败返回源串</returns>
public static string DesEncrypt(string deseninstr, string deskey, bool isupper = true)
{
StringBuilder stringBuilder = new StringBuilder();
try
{
DESCryptoServiceProvider des = new DESCryptoServiceProvider();
byte[] inputByteArray = Encoding.UTF8.GetBytes(deseninstr);
des.Key = Encoding.UTF8.GetBytes(deskey);
des.IV = Encoding.UTF8.GetBytes(deskey); // 当 mode 为 CBC 时,偏移量必传
des.Mode=CipherMode.ECB; // 为空默认 CBC
MemoryStream memoryStream = new MemoryStream();
CryptoStream cryptoStream = new CryptoStream(memoryStream, des.CreateEncryptor(), CryptoStreamMode.Write);
cryptoStream.Write(inputByteArray, 0, inputByteArray.Length);
cryptoStream.FlushFinalBlock();
foreach (byte bb in memoryStream.ToArray())
{
stringBuilder.AppendFormat(isupper ? "{0:X2}" : "{0:x2}", bb);
}
return stringBuilder.ToString();
}
catch (Exception ex)
{
return deseninstr;
}
}
/// <summary>
/// DES解密字符串
/// </summary>
/// <param name="desdeinstr">待解密的字符串</param>
/// <param name="deskey">解密密钥,要求为8位</param>
/// <returns>解密成功返回解密后的字符串,失败返源串</returns>
public static string DesDecrypt(string desdeinstr, string deskey)
{
MemoryStream memoryStream = new MemoryStream();
try
{
DESCryptoServiceProvider des = new DESCryptoServiceProvider();
byte[] inputByteArray = new byte[desdeinstr.Length / 2];
for (int ii = 0; ii < desdeinstr.Length / 2; ii++)
{
int intt = (Convert.ToInt32(desdeinstr.Substring(ii * 2, 2), 16));
inputByteArray[ii] = (byte)intt;
}
des.Key = Encoding.UTF8.GetBytes(deskey);
des.IV = Encoding.UTF8.GetBytes(deskey); // 当 mode 为 CBC 时,偏移量必传
des.Mode = CipherMode.ECB; // 为空默认 CBC
CryptoStream cs = new CryptoStream(memoryStream, des.CreateDecryptor(), CryptoStreamMode.Write);
cs.Write(inputByteArray, 0, inputByteArray.Length);
cs.FlushFinalBlock();
return Encoding.UTF8.GetString(memoryStream.ToArray());
}
catch
{
return desdeinstr;
}
}2、3DES
密文采用 Base64 格式输出。
疑问解答:三次加解密操作会运用三个不同的 Key,但是我们只传入了一个密钥,怎么回事?
3DES 密钥必须为 24 位,为 DES 的 3 倍,经测试得出结论:
- TripleDESCryptoServiceProvider 内部将密钥分成 3 份,进行了加密解密三重操作。
- 我们把 24 位字符串分成三部分,如果三部分均相等,或前两部分相等,就会报错:"Specified key is a known weak key for 'TripleDES' and cannot be used."--指定的密钥是'TripleDES'的已知弱密钥,不能使用。
// 测试
string jiamihou16 = SecurityDES.Des3Encrypt("TestString", "666666112222233333444446666665", "12345678"); // yJGf3qgWyoAQeaPY2S5Etg==
string jiamihou32 = SecurityDES.Des3Decrypt(jiamihou16, "666666112222233333444446666665", "12345678");
/// <summary>
/// 3DES 加密
/// </summary>
/// <param name="des3eninstr"></param>
/// <param name="des3key">24 位</param>
/// <param name="des3iv">8 位</param>
/// <returns></returns>
public static string Des3Encrypt(string des3eninstr, string des3key, string des3iv)
{
string encryptPassword = string.Empty;
SymmetricAlgorithm algorithm = new TripleDESCryptoServiceProvider();
algorithm.Key = Encoding.UTF8.GetBytes(des3key);// Convert.FromBase64String(des3key);
algorithm.IV = Encoding.UTF8.GetBytes(des3iv);
algorithm.Mode = CipherMode.ECB;
algorithm.Padding = PaddingMode.PKCS7;
ICryptoTransform transform = algorithm.CreateEncryptor();
byte[] data = Encoding.UTF8.GetBytes(des3eninstr);
MemoryStream memoryStream = new MemoryStream();
CryptoStream cryptoStream = new CryptoStream(memoryStream, transform, CryptoStreamMode.Write);
cryptoStream.Write(data, 0, data.Length);
cryptoStream.FlushFinalBlock();
encryptPassword = Convert.ToBase64String(memoryStream.ToArray());
memoryStream.Close();
cryptoStream.Close();
return encryptPassword;
}
/// <summary>
/// 3DES 解密
/// </summary>
/// <param name="des3deinstr">密文 Base64</param>
/// <param name="des3key">24 位</param>
/// <param name="des3iv">8 位</param>
/// <returns></returns>
public static string Des3Decrypt(string des3deinstr, string des3key, string des3iv)
{
string decryptPassword = string.Empty;
SymmetricAlgorithm algorithm = new TripleDESCryptoServiceProvider();
algorithm.Key = Encoding.UTF8.GetBytes(des3key);
algorithm.IV = Encoding.UTF8.GetBytes(des3iv);
algorithm.Mode = CipherMode.ECB;
algorithm.Padding = PaddingMode.PKCS7;
ICryptoTransform transform = algorithm.CreateDecryptor(algorithm.Key, algorithm.IV);
byte[] buffer = Convert.FromBase64String(des3deinstr);
MemoryStream memoryStream = new MemoryStream(buffer);
CryptoStream cryptoStream = new CryptoStream(memoryStream, transform, CryptoStreamMode.Read);
StreamReader reader = new StreamReader(cryptoStream, System.Text.Encoding.ASCII);
decryptPassword = reader.ReadToEnd();
reader.Close();
cryptoStream.Close();
memoryStream.Close();
return decryptPassword;
}二、js 语言实现
以下是通过 crypto-js.js 实现。
1、DES
注意:mode 为空默认 CBC,此时偏移量 iv 不可为空。
注意:密钥可用位数为 8,如果超过 8 位以后的对加密结果无影响,且不会报错。
// 先引入 js 文件
<script src="http://cdn.bootcdn.net/ajax/libs/crypto-js/4.0.0/crypto-js.js"></script>
// npm(Node.js package manager)方式
> npm install crypto-js
// 调用方法 message() 查看测试结果
function message(){
var outdata_value = encryptByDES("TestString", "66666611222");
alert(outdata_value) // 57fe567eaa866373f851a526f07d9e26
console.log("outdata_value-aes_encrypt:", outdata_value);
outdata_value = decryptByDES(outdata_value, "66666611222");
alert(outdata_value)
console.log("outdata_value-aes_decrypt:", outdata_value);
}
//DES 加密
function encryptByDES(deseninstr, keystr, ivstr = keystr) {
var keybyte = CryptoJS.enc.Utf8.parse(keystr);
var ivbyte = CryptoJS.enc.Utf8.parse(ivstr);
let afterEncrypt = CryptoJS.DES.encrypt(deseninstr, keybyte, {
iv: ivbyte, // 当 mode 为 CBC 时,偏移量必传
mode: CryptoJS.mode.ECB, // 为空默认 CBC
padding: CryptoJS.pad.Pkcs7
}).ciphertext.toString()
console.log(afterEncrypt)
return afterEncrypt
}
//DES 解密
function decryptByDES(desdeinstr, keystr, ivstr = keystr) {
var keybyte = CryptoJS.enc.Utf8.parse(keystr);
var ivbyte = CryptoJS.enc.Utf8.parse(ivstr);
var decrypted = CryptoJS.DES.decrypt(
{ ciphertext: CryptoJS.enc.Hex.parse(desdeinstr) },
keybyte,
{
iv: ivbyte, // 当 mode 为 CBC 时,偏移量必传
mode: CryptoJS.mode.ECB, // 为空默认 CBC
padding: CryptoJS.pad.Pkcs7
}
);
console.log(decrypted);
var result_value = decrypted.toString(CryptoJS.enc.Utf8);
return result_value;
}2、3DES
// 调用方法 message() 查看测试结果
function message() {
var outdata_value = encryptByDES("TestString", "666666112222233333444446666665");
alert(outdata_value) // yJGf3qgWyoAQeaPY2S5Etg==
console.log("outdata_value-3des_encrypt:", outdata_value);
outdata_value = decryptByDES(outdata_value, "666666112222233333444446666665");
alert(outdata_value)
console.log("outdata_value-3des_decrypt:", outdata_value);
}
// 加密 密钥需为 24 位,偏移量需为 8 位
function encryptByDES(deseninstr, keystr) {
var keybyte = CryptoJS.enc.Utf8.parse(keystr);
//var ivbyte = CryptoJS.enc.Utf8.parse(ivstr);
var encrypted = CryptoJS.TripleDES.encrypt(deseninstr, keybyte, {
// iv: ivbyte, // 当 mode 为 CBC 时,偏移量必传
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
return encrypted.toString();
}
// 解密 密钥需为 24 位,偏移量需为 8 位
function decryptByDES(desdeinstr, keystr) {
var keybyte = CryptoJS.enc.Utf8.parse(keystr);
//var ivbyte = CryptoJS.enc.Utf8.parse(ivstr);
var decrypted = CryptoJS.TripleDES.decrypt(desdeinstr, keybyte, {
// iv: ivbyte, // 当 mode 为 CBC 时,偏移量必传
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
return decrypted.toString(CryptoJS.enc.Utf8);
}