iptables的使用
iptables的使用
iptables介绍
iptables是基于内核提供的netfilter框架实现的,网络协议栈是分层的,在tcp ip网络模型里,tcp传输层下面的一层就是ip网络层,而netfilter就是工作在ip网络层,通过定义钩子函数,允许用户代码干预数据在协议栈中的过滤逻辑。
在进出ip路由前后,都定义了相关的钩子函数,可以在钩子函数内部加上过滤数据包的逻辑,但直接使用netfilter还是比较麻烦,需要写代码。
而iptables则是基于netfilter提供的功能,让使用者能用配置的方式替代之前直接写代码的操作。可以说它简化了netfilter的使用。
规则定义
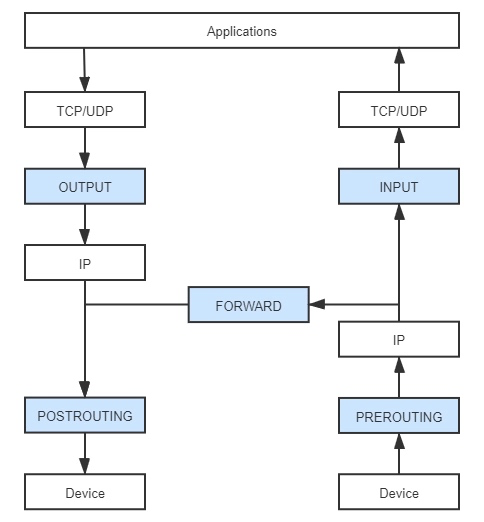
在看iptables使用规则前,得先明白这5个钩子函数的触发规则。
钩子函数
PREROUTING
:
在进入 IP 路由之前触发,就意味着只要接收到的数据包,无论是否真的发往本机,也都会触发这个钩子。它一般是用于目标网络地址转换(Destination NAT,DNAT)。
INPUT
:
报文经过 IP 路由后,如果确定是发往本机的,将会触发这个钩子,它一般用于加工发往本地进程的数据包。
FORWARD
:
报文经过 IP 路由后,如果确定不是发往本机的,将会触发这个钩子,它一般用于处理转发到其他机器的数据包。
OUTPUT
:
从本机程序发出的数据包,在经过 IP 路由前,将会触发这个钩子,它一般用于加工本地进程的输出数据包。
POSTROUTIN
:
从本机网卡出去的数据包,无论是本机的程序所发出的,还是由本机转发给其他机器的,都会触发这个钩子,它一般是用于源网络地址转换(Source NAT,SNAT)
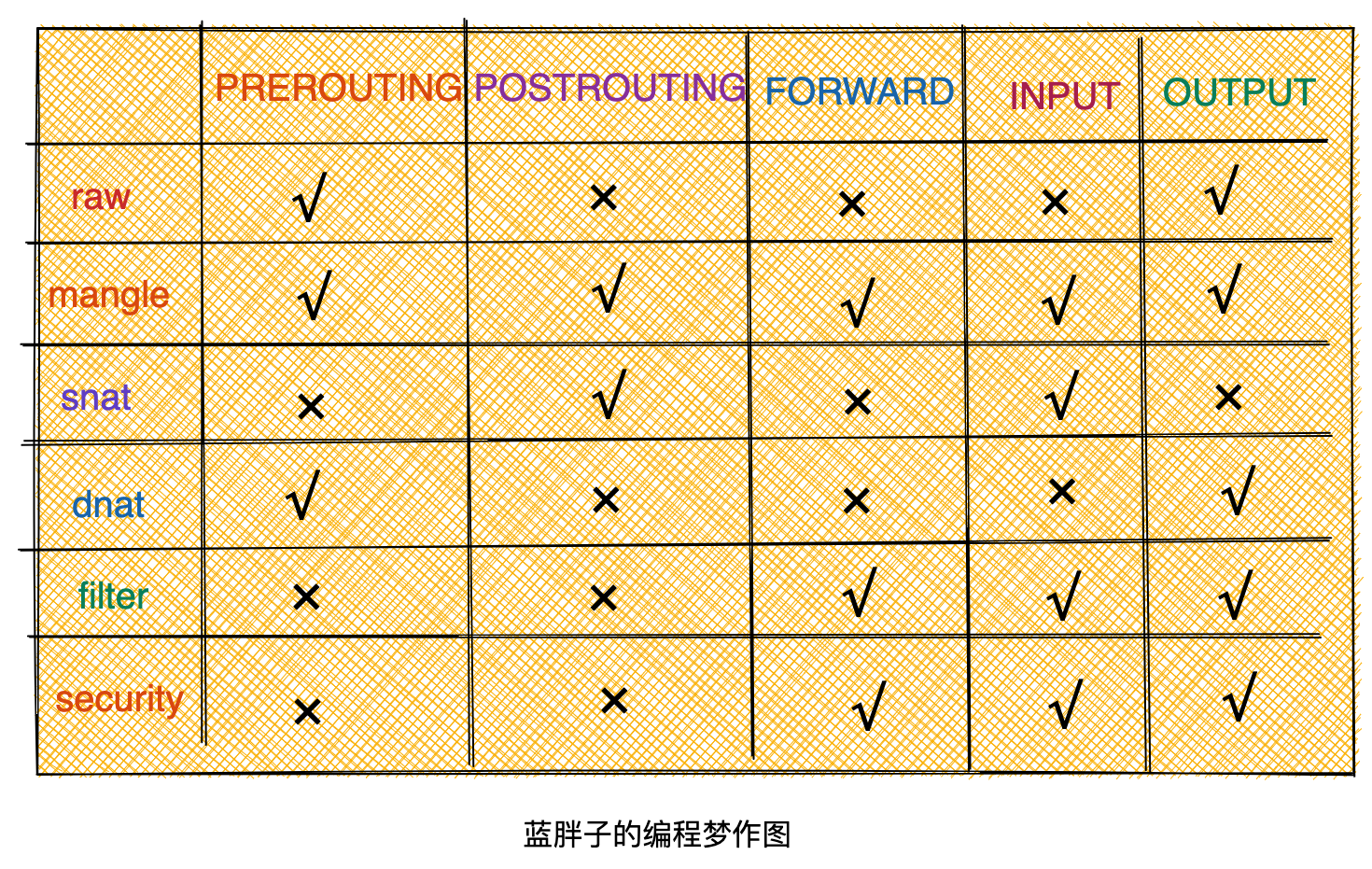
在使用iptables时,能够在特定的钩子函数上定义一条条规则,而为了更好的管理这些规则,iptables将这些规则按功能进行分类,这样相同目的的规则就形成了规则表。
规则表
我们来看看:
raw 表
:
用于去除数据包上的连接追踪机制(Connection Tracking)。
mangle 表
:
用于修改数据包的报文头信息,比如服务类型(Type Of Service,ToS)、生存周期(Time to Live,TTL)。
nat 表
:
用于修改数据包的源或者目的地址等信息,典型的应用是网络地址转换(Network Address Translation)。
filter 表
:
用于对数据包进行过滤,控制到达某条链上的数据包是继续放行、直接丢弃或拒绝(ACCEPT、DROP、REJECT),典型的应用是防火墙。
security 表
:
用于在数据包上应用SELinux,这张表并不常用。
nat和filter表用的很频繁,这也是今天分析的重点。
五张表能够在相应的钩子函数上设定规则,而如果碰到不同表在相同的钩子函数上设定规则,那么规则谁先谁后呢,这就需要知道表的优先级顺序。
表优先级:raw→mangle→nat→filter→security。
这里你要注意,在 iptables 中新增规则时,需要按照规则的意图指定要存入到哪张表中,如果没有指定,就默认会存入 filter 表。此外,每张表能够使用到的钩子函数也有所不同。
命令格式
有了这些基础之后,我们再来看看iptables的命令格式:
iptables -t nat 命令 规则链 规则
在使用iptables的时候,我们用-t 指定定义的规则是属于哪张规则表的,如果不指定,则默认是指filter表。 而命令则是说明需要对规则表所进行的操作,比如查看添加删除规则链。
iptables命令 -L 代表查看 -A 代表插入到尾部, -D 删除规则 -F 清空规则
规则链则是具体的定义按什么规则去匹配数据包,如筛选出源ip是10.1.0.1的数据包,或者目的端口是8080的数据包。 规则即是对匹配的数据包所做的操作,比如是丢弃还是接受。
这里我列几个比较常用的规则;
DROP:直接将数据包丢弃。
REJECT:给客户端返回 Connection Refused 或 Destination Unreachable 报文。
RETURN:跳出当前链,该链里后续的规则不再执行。
ACCEPT:同意数据包通过,继续执行后续的规则。
JUMP:跳转到其他用户自定义的链继续执行。
REDIRECT:在本机做端口映射。
MASQUERADE:地址伪装,自动用修改源或目标的 IP 地址来做 NAT。
来看一个实际的iptables的实际使用例子。
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j MASQUERADE
这条命令就代表往nat规则表中添加一条规则,规则在POSTROUTING钩子函数处触发,规则是将源ip是192.168.10.0/24网段的数据包都做一次snat操作。 -s 指定源ip地址或ip网段
iptables -A INPUT -p tcp -s 192.168.10.0/24 -j DROP
上面这条命令没有用-t参数则说明默认是往filter规则表中添加,规则是在INPUT钩子函数处被触发,-p 指定匹配的协议,这里将源ip是192.168.10.0/24网段的tcp协议的数据包都丢掉了。-j 指定的就是规则链之后的动作。
除了添加内置的规则表中添加规则 ,iptables还允许用户自定义规则链表,这里将不再深入分析,本文目的仅是简单的了解下iptables的使用,以及能看懂iptables的输出即可,为后续分析容器网络环境做准备。
iptables 输出结果分析
知道iptables命令是如何使用之后,我们再来看看iptables是如何查看主机上的规则,以及如何对规则输出的结果进行分析。
iptables -nvL
这个命令能直接输出主机上的filter表的规则链,-n 代表不解析ip地址的域名,-v则是能输出更多的信息,-L则是查看命令了。
关于iptables 的命令参数有很多,更多详细的规则都可以通过man iptables去查看。
看看输出结果。
root@master:/home/parallels# iptables -nvL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
20M 4214M KUBE-NODEPORTS all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes health check service ports */
293K 23M KUBE-EXTERNAL-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate NEW /* kubernetes externally-visible service portals */
20M 4220M KUBE-FIREWALL all -- * * 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 FLANNEL-FWD all -- * * 0.0.0.0/0 0.0.0.0/0 /* flanneld forward */
0 0 KUBE-FORWARD all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes forwarding rules */
.......
Chain KUBE-KUBELET-CANARY (0 references)
pkts bytes target prot opt in out source destination
Chain KUBE-NODEPORTS (1 references)
pkts bytes target prot opt in out source destination
输出的规则按不同规则链进行了归类,除了之前提到的iptables内置的5个规则链表,还有一些是自定义的规则链,自定义的规则链只能通过内置的规则链去进行跳转。
比如这里的第一行输出:
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
20M 4214M KUBE-NODEPORTS all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes health check service ports */
则表示,匹配所有经过INPUT链的数据包(source 为0.0.0.0/0 表示任意源ip地址,destination为0.0.0.0/0 表示任意目的ip地址,prot 为all表示任意协议,in out皆为all 表示输入输出可以是任意网络设备,opt则是一些定义规则链时候的扩展参数,这里为空) 都将跳转到KUBE-NODEPORTS这条自定义规则链。
pkts 表示经过此规则的包数量,bytes则是经过此规则的包大小,都是累加值。
然后
Chain KUBE-NODEPORTS (1 references)
pkts bytes target prot opt in out source destination
看到KUBE-NODEPORTS 没有定义规则,则回到上层规则链处,继续执行下一条规则。
通过上面的分析,应该能够看懂iptables的输出了,后续我将会结合iptables命令,看看容器环境下,对主机的iptables规则做了哪些改动,敬请期待。