软件测试计划与测试方案
这是一份机票预订系统的软件测试报告,老师评分98分,希望能帮助各位园友。

一、 测试任务、目标
本次课程设计将对航班订票系统进行系统测试,验证系统是否满足登录注册以及订票退票等功能要求,同时测试系统的性能是否达标。
二、 进行测试工作量估计
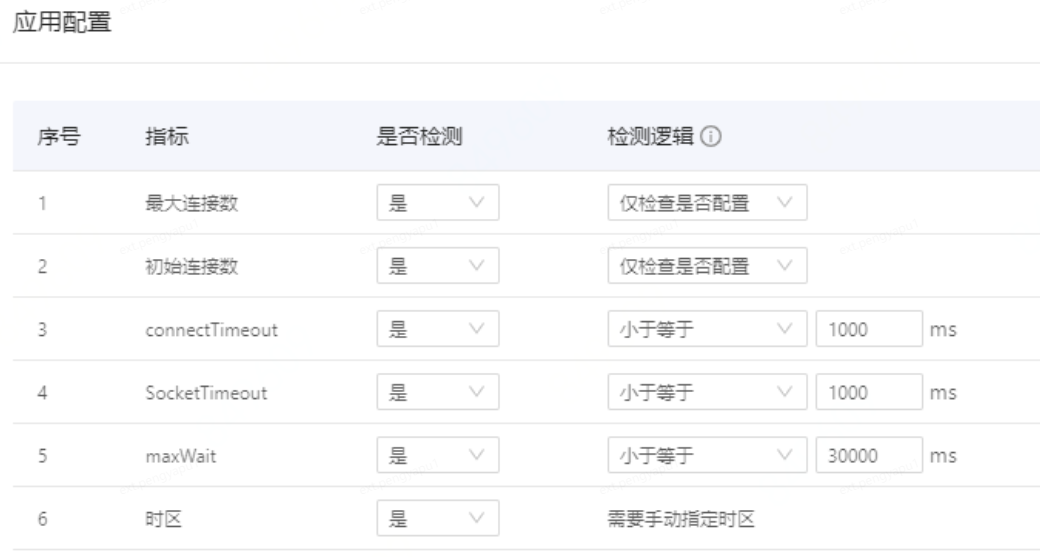
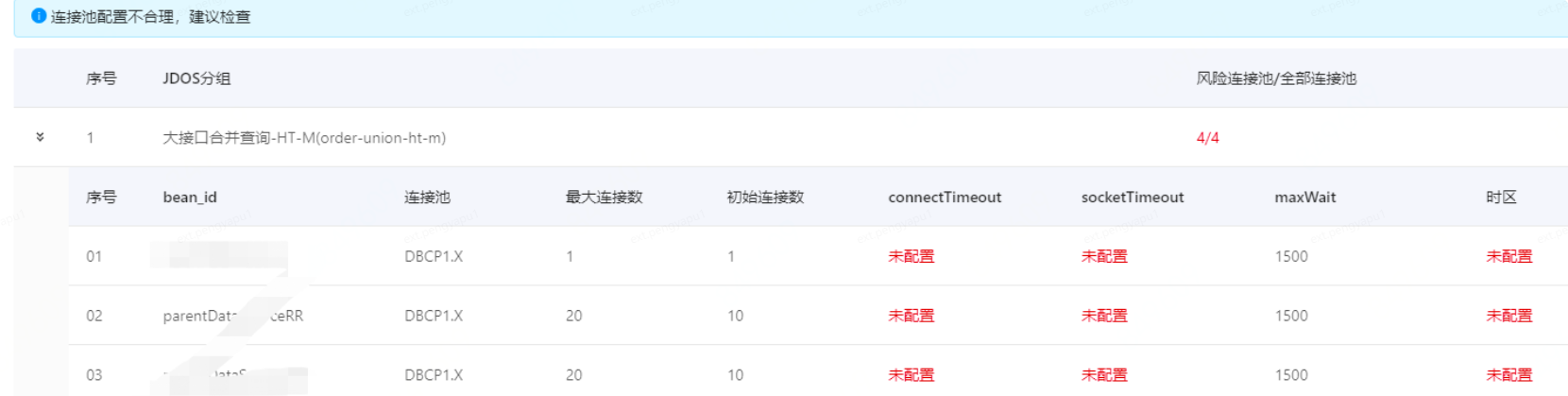
根据机票预定系统的需求规格说明书,可以看出这是一个规模比较小的系统,可以采用手工测试和自动化测试相结合的方式进行测试。可以采用场景法、成效价类划分法、边界类法和常见错误法来编写测试用例。本系统有8个功能点要测试,比较复杂的功能点是新增订票、查询订票和修改订票三个功能点,每个功能点大约需求10个测试用例,其它均为2-5个测试用例,初步估计有50个测试用例,约有3人/天的工作量,执行测试则有6人/天的工作量。
三、 人员资源和资源分配
人员资源分配:
小组成员每人各负责一部分进行开发测试:
测试员(一人)
软件工程需求分析(一人)
系统设计员(一人)
项目经理(一人)
架构师(一人)
资源分配:
初级设计不需要用到过多资金,只需保证人手一台电脑设备,以供成员使用即可。
四、明确任务的时间和进度安排
机票预订系统设计周期预计为一个月,一个月内完成模型的初步设计。其中具体时间安排如下:
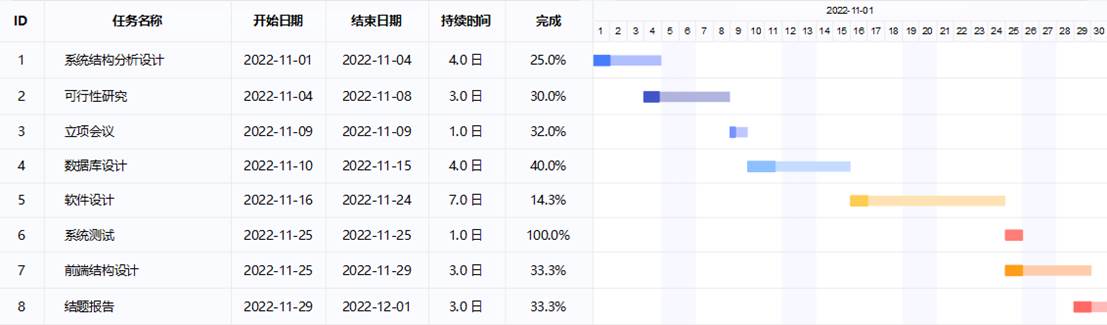
其中设计进度为期一个月,其中为确保工期按时完成,每个星期都会有一次阶段性验收。
五、风险估计和应急计划;
风险估计:
1.系统可侧性差
2.测试环境不符合测试要求
3.测试人手不够,时间不足
4.测试所需硬件、软件需求不满足
应急计划:
1.加强测试环境的管理和改进
2.在项目前期加强对人员的管理和培训,测试人员要尽早熟悉产品,做好人员分配工作。
3.测试前做好测试所需硬件配置,软件安装更新等工作。
六、测试失败/通过的标准
在功能测试中,系统中各功能能正常执行;在性能测试中,各类测试指标包括测试中应该达到的某些性能指标,这些性能指标均是来自应用系统设计开发时遵循的业务需求,当某个测试的某一类指标已经超出了业务需求的要求范围,则测试已经达到目的,即可终止压力测试。
应用软件级别的测试指标:
测试用例执行通过率,通过的测试用例个数/测例总数。该值>=95,
(1) 事务的执行情况
事务的平均响应时间(期望值:<15s)
事务的最大响应时间(期望值:<30s)
平均每秒处理数量(分别记录单位时间内成功、失败和停止的数量)
不同并发用户数的状况下的上述记录值
(2)测试结果分析情况
测试指标:
吞吐量:单位时间内网络传输数据量
七、测试范围
1.功能测试
注册和登录用户信息
订票办理
退票办理
查询购票信息
- 性能测试
本次测试是针对系统的性能特征和系统的性能调优而进行的,主要需要获得如下的性能测试指标。
1、系统的响应能力:即在各种负载压力情况下,系统的响应时间,也就是从客户端交易发起,到服务器端交易应答返回所需要的时间,包括网络传输时间和服务器处理时间。
2、应用系统的吞吐率:即应用系统在单位时间内完成的交易量,也就是在单位时间内,应用系统针对不同的负载压力,所能完成的交易数量。
3、应用系统的负载能力:即系统所能容忍的最大用户数量,也就是在正常的响应时间中,系统能够支持的最多的客户端的数量。
3.UI界面测试
1、导航、链接、 Cookie 、页面结构包括菜单、背景、颜色、字体、按钮名称、 TITLE 、提示信息的一致性等。
2、友好性、可操作性(易用性)
4.安全性测试
1、程序安全性
2、网络安全性
- 数据库测试
① 系统数据机密性
② 系统数据的完整性;
③ 系统数据可管理性;
④ 系统数据的独立性;
⑤ 系统数据可备份和恢复能力
八、测试策略
1.单元测试
人工静态检查:
主要是保证代码逻辑的正确性。包括检查机票预定系统中算法的逻辑正确性、模块接口的正确性、检查输入参数有没有作正确性检查、调用其他方接口的正确性、异常错误处理、保证表达式、SQL语句的正确性、检查常量或全局变量使用的正确性、程序风格的一致性、规范性、检查代码注释是否完整。
动态执行跟踪:
检查实际的运行结果和预期结果是否一致。保证机票预定系统的代码覆盖率,尽量做到代码的全覆盖。常见单元测试覆盖标准:语句覆盖、分支覆盖、条件覆盖、分支-条件覆盖、条件组合覆盖、路径覆盖。
2.集成测试
机票预定系统经过单元测试的模块一个接一个地组合,然后测试组合单元的功能。通常,集成测试是在单元测试之后进行的。一旦创建并测试了所有单个单元,我们便开始组合那些经过测试的模块并开始执行集成测试。这里的主要目标是测试单元/模块之间的接口。以下是一些进行集成测试的简单步骤:准备测试整合计划、确定集成测试方法的类型、相应地设计测试用例,测试场景和测试脚本、一起部署所选模块并运行集成测试、跟踪缺陷并记录测试结果、重复上述步骤,直到测试完成整个系统。
3.系统测试
机票预定系统的系统测试是针对整个产品系统进行的测试,目的是验证系统是否满足了需求规格的定义,找出与需求规格不符或与之矛盾的地方,从而提出更加完善的方案。系统测试发现问题之后要经过调试找出错误原因和位置,然后进行改正,是基于系统整体需求说明书的黑盒类测试,应覆盖系统所有联合的部件。对象不仅仅包括需测试的软件,还要包含软件所依赖的硬件、外设甚至包括某些数据、某些支持软件及其接口等。
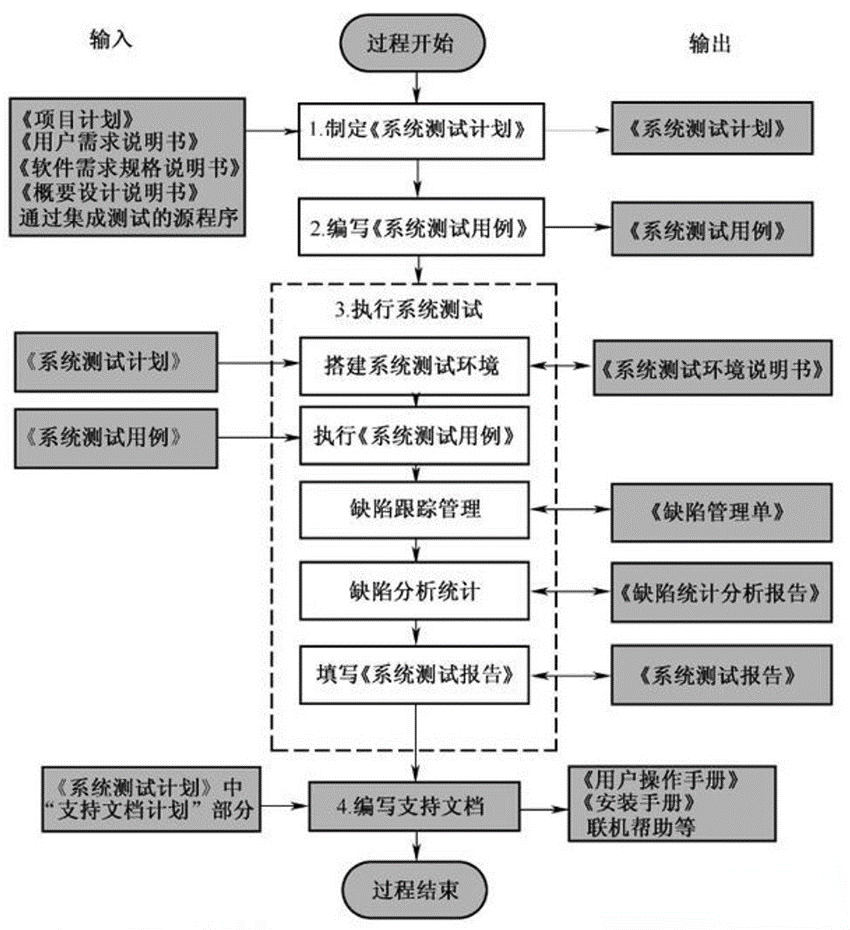
4.验收测试
在此阶段下,机票预定系统已通过三个测试级别(单元测试,集成测试,系统测试)但仍可能有一些小错误,当最终用户在实际场景中使用系统时,可以识别这些错误。验收测试是对先前完成的所有测试过程的挤压。需求分析:测试团队分析需求文档以找出所开发软件的目标。通过使用需求文档,流程图,系统需求规范,业务用例,业务需求文档和项目章程完成测试计划。测试计划创建:概述测试过程的整个策略。测试用例设计:能够涵盖大多数验收测试场景。测试用例执行:包括使用适当的输入值执行测试用例。测试团队从最终用户收集输入值,然后测试用例和最终用户执行所有测试用例,以确保软件在实际场景中正常工作。确认目标:成功完成所有测试过程后,测试团队确认软件应用程序没有错误,可以将其交付给客户端。
九、测试用例的设计与规划
| 所属产品 | 所属模块 | 相关需求 | 用例标题 | 前置条件 | 步骤 | 预期 | 用例类型 | 用例状态 |
|---|---|---|---|---|---|---|---|---|
| 机票预定系统 | 登录 | 正确登录 | 登录 | 无 | 使用已经注册的账号和密码 | 登录成功 | 功能测试 | 正常 |
| 机票预定系统 | 登录 | 账号不存在,无法登录 | 无法登录1 | 无 | 没有注册的用户名进行登录 | 登录失败,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 登录 | 密码不正确,登录失败 | 无法登录2 | 无 | 输入错误的密码进行登录 | 登录失败,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 查询机票 | 输入不存在的地点进行查询 | 查询航班1 | 已经登录 | 输入不存在的地点,点击查询 | 查询失败,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 查询机票 | 输入正确的地点进行查询 | 查询航班2 | 已经登录 | 输入正确的地点,点击查询 | 查询成功,显示航班信息 | 功能测试 | 正常 |
| 机票预定系统 | 订票 | 选择已经售完的机票,给出提示信息 | 订票失败1 | 已经登录,查询到对应的机票 | 点击已经售完的机票 | 无法订票,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 订票 | 选择有余票的机票,没有选择支付方式 | 订票失败2 | 已经登录,查询到对应的机票信息 | 点击未售完的机票,点击支付按钮 | 提示选择支付方式 | 功能测试 | 正常 |
| 机票预定系统 | 订票 | 选择有余票的机票,选择支付方式,但是余额不足 | 订票失败3 | 已经登录,查询到对应的机票信息 | 点击未售完的机票,选择支付方式,点击支付按钮 | 支付失败,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 订票 | 选择有余票的机票,选择支付方式,余额充足 | 订票成功 | 已经登录,查询到对应的机票信息 | 点击未售完的机票,选择支付方式,点击支付按钮 | 支付成功 | 功能测试 | 正常 |
| 机票预定系统 | 退票 | 退票时间在航班规定退票时间点之后,退票失败 | 退票失败 | 已经登录,购买相应的机票 | 选择购买的机票,点击退票按钮 | 退票失败,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 退票 | 退票时间在航班规定退票时间点之前,退票成功 | 退票成功 | 已经登录,购买相应的机票 | 选择购买的机票,点击退票按钮 | 退票成功,机票的金额返还给用户 | 功能测试 | 正常 |
| 机票预定系统 | 用户充值 | 用户往系统充值一定数量的金额,没有选择支付方式 | 充值失败1 | 已经登录 | 进入个人中心,点击充值按钮,直接点击支付 | 充值失败,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 用户充值 | 用户往系统充值一定数量的金额,选择支付方式,但是金额不足 | 充值失败2 | 已经登录 | 进入个人中心,点击充值按钮,选择支付方式,点击支付 | 充值失败,给出提示信息 | 功能测试 | 正常 |
| 机票预定系统 | 用户充值 | 用户往系统充值一定数量的金额,选择支付方式,金额充足 | 充值成功 | 已经登录 | 进入个人中心,点击充值按钮,选择支付方式,点击支付 | 充值成功 | 功能测试 | 正常 |
| 机票预定系统 | 用户投诉 | 用户点击投诉按钮,投诉理由不合理 | 投诉失败 | 已经登录 | 点击投诉按钮,填写投诉理由,点击提交按钮 | 投诉失败 | 功能测试 | 正常 |
| 机票预定系统 | 用户投诉 | 用户点击投诉按钮,投诉理由合理 | 投诉成功 | 已经登录 | 点击投诉按钮,填写投诉理由,点击提交按钮 | 投诉成功 | 功能测试 | 正常 |
| 机票预定系统 | 机票信息 | 从航空公司的数据库获取机票信息,显示在系统里 | 显示机票信息 | 无 | 1. 创建GET请求 2. 设置请求Param 3. 设置断言 4. 运行请求 | 显示成功 | 接口测试 | 正常 |
| 机票预定系统 | 购买的机票信息 | 从数据库获取用户已经购买的机票,显示在系统里 | 显示购买机票信息 | 已经登录和购买机票 | 1. 创建GET请求 2. 设置请求Param 3. 设置断言 4. 运行请求 | 显示成功 | 接口测试 | 正常 |
十、测试环境和测试条件的规划
操作系统:window10
数据库:mySQL8.0
服务器:tomcat1.0
CPU:8核
内存:16G
硬盘:1T
网络:百兆宽带
测试前置条件:将网站进行本地搭建,数据完整,功能正常
十一、 测试工具的设计和选择
Jmeter:不依赖于界面,如果服务正常启动,传递参数明确就可以添加测试用例,执行测试。
测试脚本不需要编程,熟悉http请求,熟悉业务流程,就可以根据页面中input对象来编写测试用例。
测试脚本维护方便,可以将测试脚本复制,并且可以将某一部分单独保存。
可以跳过页面限制,向后台程序添加非法数据,这样可以测试后台程序的健壮性。
利用badboy录制测试脚本,可以快速的形成测试脚本。
Jmeter断言可以验证代码中是否有需要得到的值。
使用参数化以及Jmeter提供的函数功能,可以快速完成测试数据的添加修改等。
selenium:Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。而且它开源、多浏览器、多平台、api齐全(自带很多方法)、浏览器内运行
loadrunner:LoadRunner 是一种预测系统行为和性能的工业标准级负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner 能够对整个企业架构进行测试。通过使用LoadRunner , 企业能最大限度地缩短测试时间, 优化性能和加速应用系统的发布周期。目前企业的网络应用环境都必须支持大量用户,网络体系架构中含各类应用环境且由不同供应商提供软件和硬件产品。难以预知的用户负载和愈来愈复杂的应用环境使公司时时担心会发生用户响应速度过慢, 系统崩溃等问题。这些都不可避免地导致公司收益的损失。