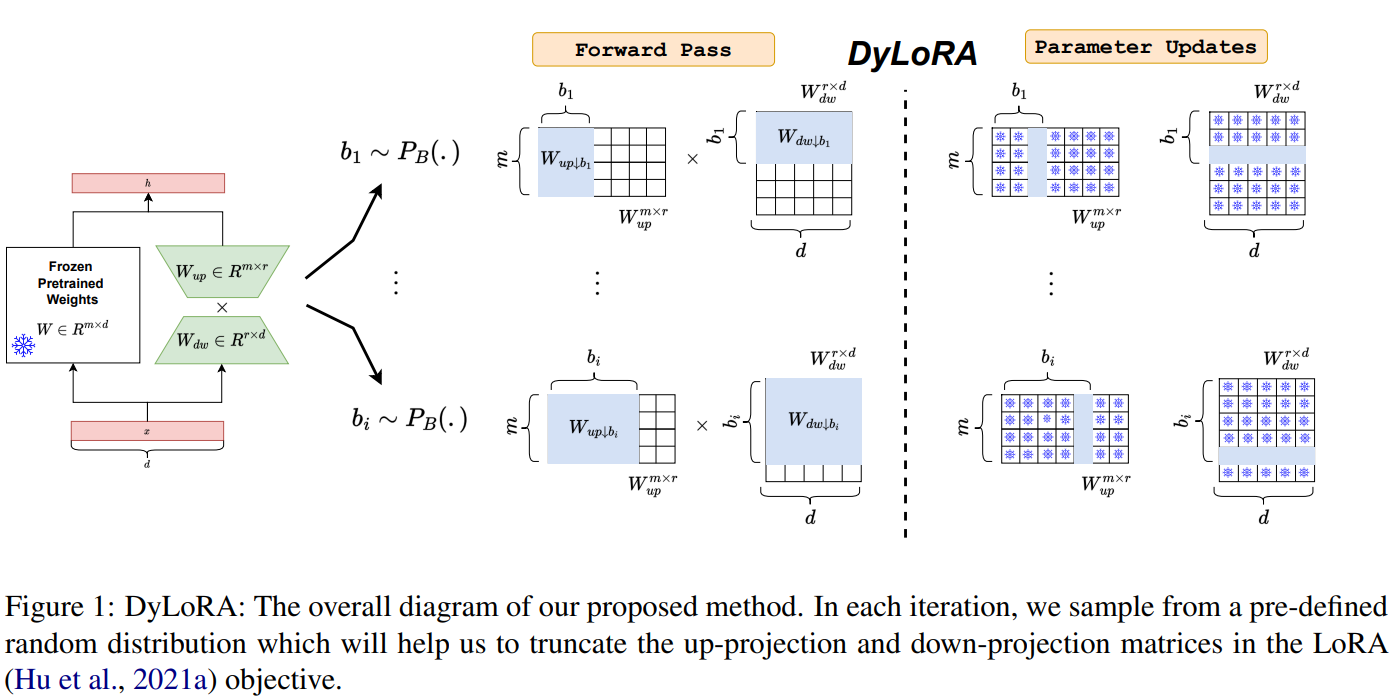
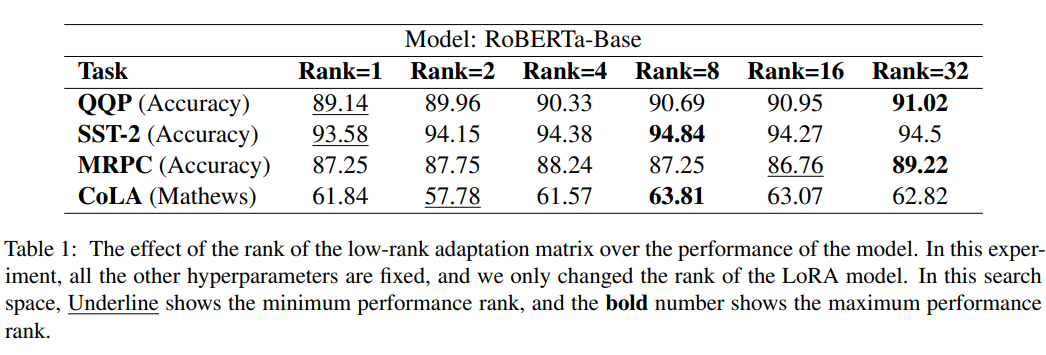
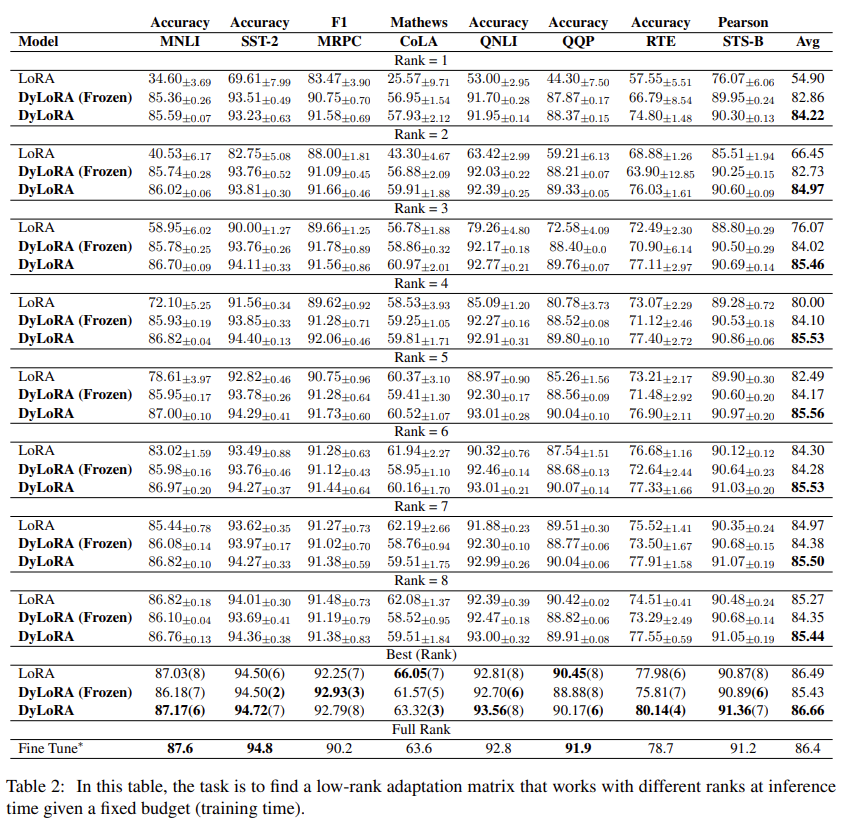
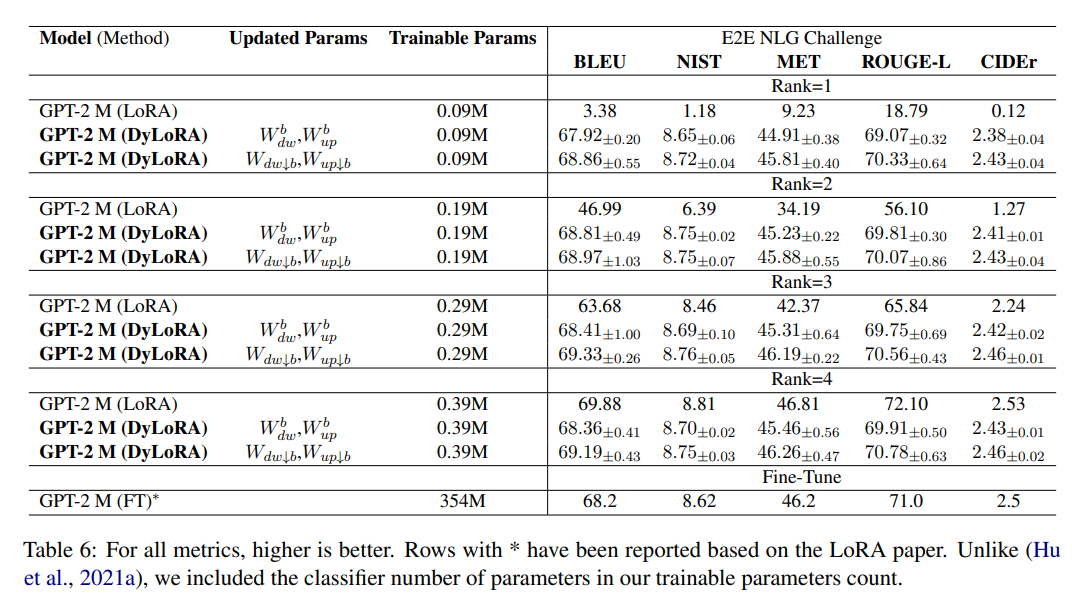
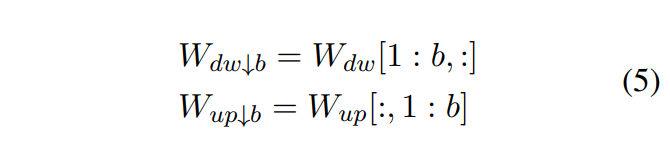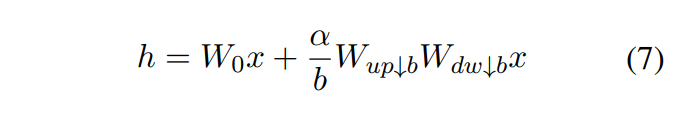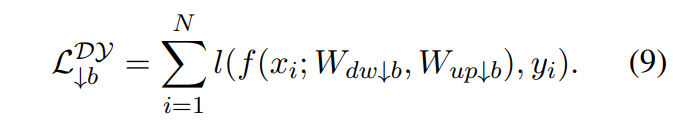作者:京东物流 李光新
1 Shell可以帮我们做什么
作为一名测试开发工程师,在与linux服务器交互过程中,大都遇到过以下这些问题:
•一次申请多台服务器,多台服务器需要安装相同软件,配置相同的环境,同样的操作需要重复多次;
•工作中经常会使用命令行命令来完成我们的一些操作,但是有些命令使用率很高,而且很长,每次都全部敲进去势必会浪费很多时间(比如查日志)
长此以往,以上两个问题可能会导致:重复性工作,个人能力得不到任何提高,浪费时间,而且还容易出错,作为一名技术人员,当同一个操作重复了三次,我们就应该考虑是否可以通过工具来帮我们实现。
而shell脚本正好擅长,
把复杂问题分解成简单的小问题,然后再把各个部分功能组合起来解决复杂问题
。 当然,有些命令我们只能节省三五秒的时间,短期看不到时间的节省,但是从长期来看这个价值将是巨大的。我们可以将这些时间专注于更有意义,更重要的事情 - 提高生命质量。
2 功能介绍
Shell脚本语言的优势在于处理偏操作系统底层的业务,例如,Linux系统内部很多应用是用shell脚本语言开发的,因为有众多的Linux系统命令为它作支撑,特别是Linux正则表达式和三剑客grep、awk、sed等命令。
对于一些常见的系统脚本,使用shell开发会更简单、更快速。就像让软件一键自动化安装、优化,监控报警脚本,软件启动脚本,日志分析脚本等,虽然PHP和Python语言也能做到这些,但是由于掌握难度、开发效率和开发习惯等,可能就不如shell脚本语言流行及有优势了。
shell是一个C语言编写的脚本语言,它是用户与linux的桥梁,用户输入命令交给shell来处理,shell将相应的操作传递给内核,内核把处理的结果输出给用户。
可参考如下流程示意图:

简单来说:shell就是一个用户跟操作系统之间交互的命令解释器
3 基本用法
下面首先来介绍下日常使用较多的基本指令:
3.1 文件拷贝

3.2 文件合并
有时候,要遇到将多个文件合并成一个的需求,除了重复的复制和粘贴,还可以通过简单指令来辅助实现。
cat命令
默认地,cat命令可以直接接收多个参数,这样,通过重定向可以很方便地合并文件:
效果如下:


4 案例分享
4.1 自动添加注释
下面我们从日常工作入手,和大家一起来看下,shell有哪些提高工作效率的应用场景~
首先,我们编写的脚本有时候并不仅仅是我们个人使用,可能是团队内部使用,所以通常在脚本正式编写前,通常需要添加部分注释,注明脚本的作用,创建日期,创建人等信息;
而如果编写脚本比较多的话,这些重复性工作就会成为我们的负担,所以,我们又可以将这些交给shell来帮我们实现,
用shell脚本来解决创建shell脚本的重复性工作
;
下面给大家分享一个shell脚本的模板文件,把它拷贝到用户的根目录下并命名成 .vimrc 名称,这样我们以后再次打开以 .sh结尾的文件时就会成自动生成一些注释信息,只要稍稍修改一下即可如图所示:
vimrc文件是vim的环境设置文件,在启动vim时,当前用户根目录下的.vimrc文件会被自动读取,该文件可以包含一些设置甚至脚本,所以,一般会在.vimrc文件中根据个人喜好进行一些自定义设置;
下面脚本我都注释了具体含义,可参考:

实现效果展示:

4.2 内存使用率监控预警
日常工作中,经常会遇到由于服务器被日志打满而不得不重启的场景,而对于一些必要的单据,就需要时常注意日志的备份,所以可以编写如下一个脚本,来做提醒;
如下脚本实现了,当服务器内存使用率超过90%时,提示保存日志操作,如果未超过90%,则不作任何处理;

实现效果展示:

4.3 后台服务启动/停止/重启脚本
对于一些小范围使用,暂未接入j-one部署的服务器,每次后台服务代码更新,代码部署都是一项比较繁琐的工作,而这就到了shell发挥威力的时候了。
实现原理就是,将停止服务和启动服务需要执行的命令写进脚本,通过shell交互来实现,外加一些必要的判断逻辑,比如:
1.执行启动服务时判断服务是否正在启动中;
2.执行停止服务时判断根据交互条件筛选出的服务是否只有一个;
3.执行重启服务时判断服务是否正在启动中;
4.保证中间所有交互过程中的唯一性,避免失误将其他人的服务停止
实现脚本如下:

实现效果展示:
该脚本可在团队内部通用,只需要输入任务类型编号和对应任务关键字两步即可,脚本在执行过程中会自动提示你确认执行任务对象是否正确,以免误伤;
1)停止服务

2)启动服务:

3)重启服务

大大减少了团队服务部署的工作量~
4.4 函数化封装
对于一些比较复杂的功能,或者需要多次执行的功能,shell也支持将功能封装为函数,直接执行函数即可;
比如服务器的部署基本可以分为以下几个步骤:
•服务部署目录创建
•服务配置部署
•服务应用部署
•服务应用启动
则该四个步骤可以通过shell脚本封装为四个函数,如下:

将每个模块编写为函数,最后,只需要调用main函数,即可执行上述一系列操作;
以此类推,安装nginx,Java,jenkins等各种软件操作,也可以封装成多个函数,实现自动化一键完成~
5 结语
综上,linux服务器上,所有的重复性工作都可以交给shell来打理,日常工作中增加一个万能助手,何乐而不为呢
shell脚本小巧且功能强大,以上只是给大家分享了些日常使用到的脚本,其他功能大家也可以举一反三,通过各种流程控制组合来实现,让shell来帮我们做工具人,我们就可以腾出更多的时间来做更重要且更有意义的事情了,与君共勉。