前情提要
当你看到此篇文章时,nacos目前最新稳定版本为:
2.2.2 (Apr 11, 2023)
Latest
版本不在于有多新,在于与当前场景环境匹配正常,稳中求快。万一你用了比较新的版本,遇到问题怎么办?有问题,那就找李元芳吧!开个玩笑。你可以去 nacos 的github仓库issues提问、追问选择解决方案,促进开源社区的和谐发展。
第一篇基础篇,可在博客园搜索:MySQL数据库与Nacos搭建监控服务。
本篇是个人nacos系列文章第二篇springboot项目集成微服务组件nacos。

整体思路,个人nacos系列博文一共分为三篇
:
- 基础篇:《MySQL数据库与Nacos搭建监控服务》,Nacos与MySQL基本介绍。
- 开发篇:《开发篇:springboot与微服务组件nacos》,从代码开始构建,集成微服务组件。
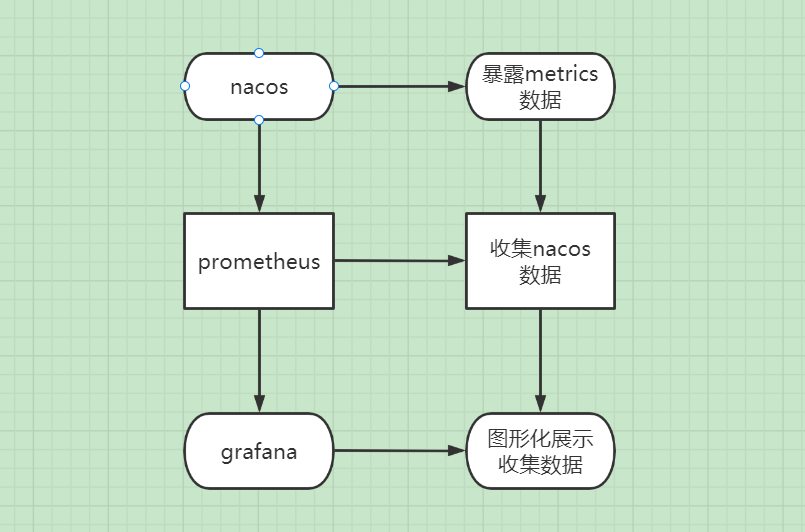
- 运维篇:《运维篇:nacos prometheus grafana》,服务监控篇,主要以Linux发行版为主。
骚话环节
一入编程深似海,从此节操是路人。脱发已是常态,致富还需绝顶。
那天我听说程序员之间还相互鄙视,其中不能忍的终极鄙视:有女朋友的程序员鄙视没有女朋友的程序员。这不能忍,打不过怎么办,问就是加入吧。
由于是测试环境,使用版本比较新,学当然要学新知识吸收精华,羽化成仙,做那万人敬仰韩天尊。啊,不好意思,扯远了。开个玩笑,我们依旧
使用稳定版本
。此次在Linux发行版操作系统中全程使用root用户进行测试避免权限问题带来的干扰,如果使用普通用户请自行测试提权赋予所有者或者所属组权限。
骚话不多说,
直接进入今天的主题springboot项目集成微服务组件nacos
。
springboot与微服务组件nacos
必备环境,前置条件尽量保持一致
:
- JDK版本: JDK17
- 开发工具和项目构建工具:STS4 & Maven3.6
- Springboot版本:Springboot2.7.x
- 服务监控三件套:Nacos2.x、Prometheus2.3.x、Grafana9.3.x
- 开发测试环境:Linux(centos-stream-9)云服务器或者VMware搭建环境
你可以了解到的知识:从项目开发构建到线上测试发布,不过,需要具备一点点Java或者其它编程语言基础知识。
tips
:做实验时请检查是否关安装防火墙管理工具,关闭防火墙服务或者开启相应端口,或者放通云服务器安全组。
企业中生产环境,唯稳,稳中求快
。
可以看到,我再次使用了这张流程图,在第三篇会总结使用过程。
Nacos服务快速启动
关于nacos2.2.0相关配置说明以及数据源说明,遇到问题总结,可以参考如下文章:
https://blog.cnwangk.top/2023/03/30/MySQL数据库与Nacos搭建监控服务/
使用hexo搭建静态博客网站,感兴趣可以自己搭建一个,利用github pages和cloudflare pages等进行同步。之所以给出上面的链接,因为一篇优质的教程,会持续更新迭代。当然,在个人公众号里面同样可以搜索到相关教程。
根据个人或者团队开发环境,可以选择框架开发环境:spring、springboot以及springcloud集成nacos
。
值得注意的地方
服务器部署nacos服务支持多种场景:
- Nacos原生形式部署。
- Nacos Docker形式部署。
- Nacos Kubernetes形式部署。
至于用哪种方式,根据实际业务场景分析,选择符合个人或者公司业务场景的最佳方式。
Nacos支持三种部署模式
- 单机模式:用于测试和单机试用。
- 集群模式:用于生产环境,确保高可用。
- 多集群模式:用于多数据中心场景。
高可用环境准备
- 建议支撑环境:部署JDK,需要 1.8 及其以上版本
- 建议硬件配置:2核 CPU / 4G 内存 及其以上
- 建议软件配置:生产环境 3 个节点 及其以上
Nacos 依赖 Java 环境来运行。如果您是从代码开始构建并运行Nacos,还需要为此配置 Maven环境,请确保是在以下版本环境中安装使用:
1、预备环境准备
2、下载源码或者安装包
你可以通过
源码
和
发行包
两种方式来获取 Nacos。
个人推荐
:下载发行包。关于版本,使用稳定版本(
通常有GA标识
),个人习惯使用官方推荐的上一个小版本。有特殊需求可以下载源码包,修改源码重新编译。
从 Github 获取源码方式,使用
git clone
命令,
值得注意的是你需要部署Git环境
:
git clone https://github.com/alibaba/nacos.git
cd nacos/
mvn -Prelease-nacos -Dmaven.test.skip=true clean install -U
ls -al distribution/target/
// change the $version to your actual path
cd distribution/target/nacos-server-$version/nacos/bin
nacos发行包下载地址
:
下载编译后压缩包方式,您可以从 最新稳定版本 下载 nacos-server-$version.zip 包。
unzip nacos-server-$version.zip 或者 tar -zxvf nacos-server-$version.tar.gz
cd nacos/bin
$version指具体nacos版本号,比如具体版本:nacos-server-2.1.1。
Windows平台建议下载以 .zip结尾的压缩包:nacos-server-2.1.1.zip。
Linux平台建议下载以 .tar.gz 结尾的压缩包:nacos-server-2.1.1.tar.gz。
3、修改配置文件
注意
:修改
conf
目录下的
application.properties
文件。设置其中的
nacos.core.auth.plugin.nacos.token.secret.key
值,详情可查看鉴权-自定义密钥:
https://nacos.io/zh-cn/docs/v2/plugin/auth-plugin.html
注意,文档中的默认值
SecretKey012345678901234567890123456789012345678901234567890123456789
和
VGhpc0lzTXlDdXN0b21TZWNyZXRLZXkwMTIzNDU2Nzg=
为公开默认值,可用于临时测试,实际使用时请
务必
更换为自定义的其他有效值。
4、启动服务器
Linux/Unix/Mac:执行startup.sh脚本
启动命令(standalone代表着单机模式运行,非集群模式):
sh startup.sh -m standalone
如果您使用的是ubuntu系统,或者运行脚本报错提示[[符号找不到,可尝试如下运行:
bash startup.sh -m standalone
Windows平台:执行startup.cmd脚本
启动命令(standalone代表着单机模式运行,非集群模式):
startup.cmd -m standalone
5、关闭服务器
Linux/Unix/Mac:执行shutdown.sh脚本
sh shutdown.sh
Windows平台:执行shutdown.cmd脚本
shutdown.cmd
可以在Windows中使用terminal或者cmd命令行运行shutdown.cmd命令,也可以双击shutdown.cmd运行文件。
以下为个人实战总结,仅供参考
个人开发以及测试环境
:
- Spring Tool Suite4
- JDK17
- Maven3.6
- Springboot2.7.6
- VMware16 & Linux(Centos-9-Stream)
关于IDE的选择
:
有人喜欢使用 IntelliJ IDEA ,有人喜欢用 Vim,有人喜欢用VSCode,还有人就偏爱 eclipse 。开发工具 IDE 的选择,不一定非要和我保持一致。个人开发者可以根据自己的喜好选择,怎么顺手怎么来,主打一个用的舒心。如果是团队开发,最优质的方案是与团队保持一致。
可能是入坑最开始接触的 IDE 是eclipse,习惯了。个人小项目偶尔会用VSCode,大型项目更趋向于 eclipse 或者 IntelliJ IDEA。
STS4 开发工具
支持OS版本,彼时最新版本是4.17.1
- Linux X86_64、Linux ARM_64
- MACOS X86_64、MACOS ARM_64
- WINDOWS X86_64
官网:
https://spring.io/tools
下载地址:
https://download.springsource.com/release/STS4/4.16.1.RELEASE/dist/e4.25/spring-tool-suite-4-4.16.1.RELEASE-e4.25.0-win32.win32.x86_64.self-extracting.jar
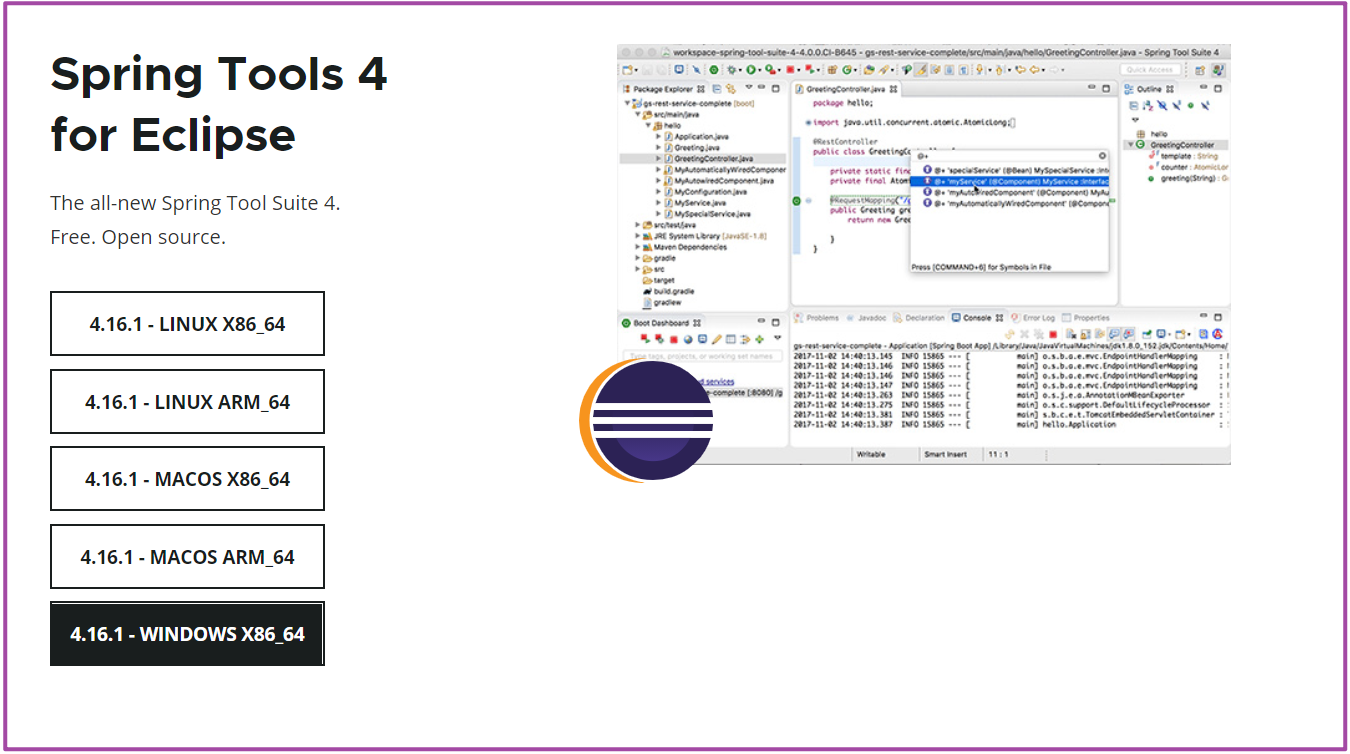
Maven 环境配置
STS4开发工具引入Maven配置
依次找到顶部菜单栏:Window---> Preferences---> Maven--->User Settings--->Global Settings & User Settings--->Apply
配置完记得点击Apply或者Apply and Close
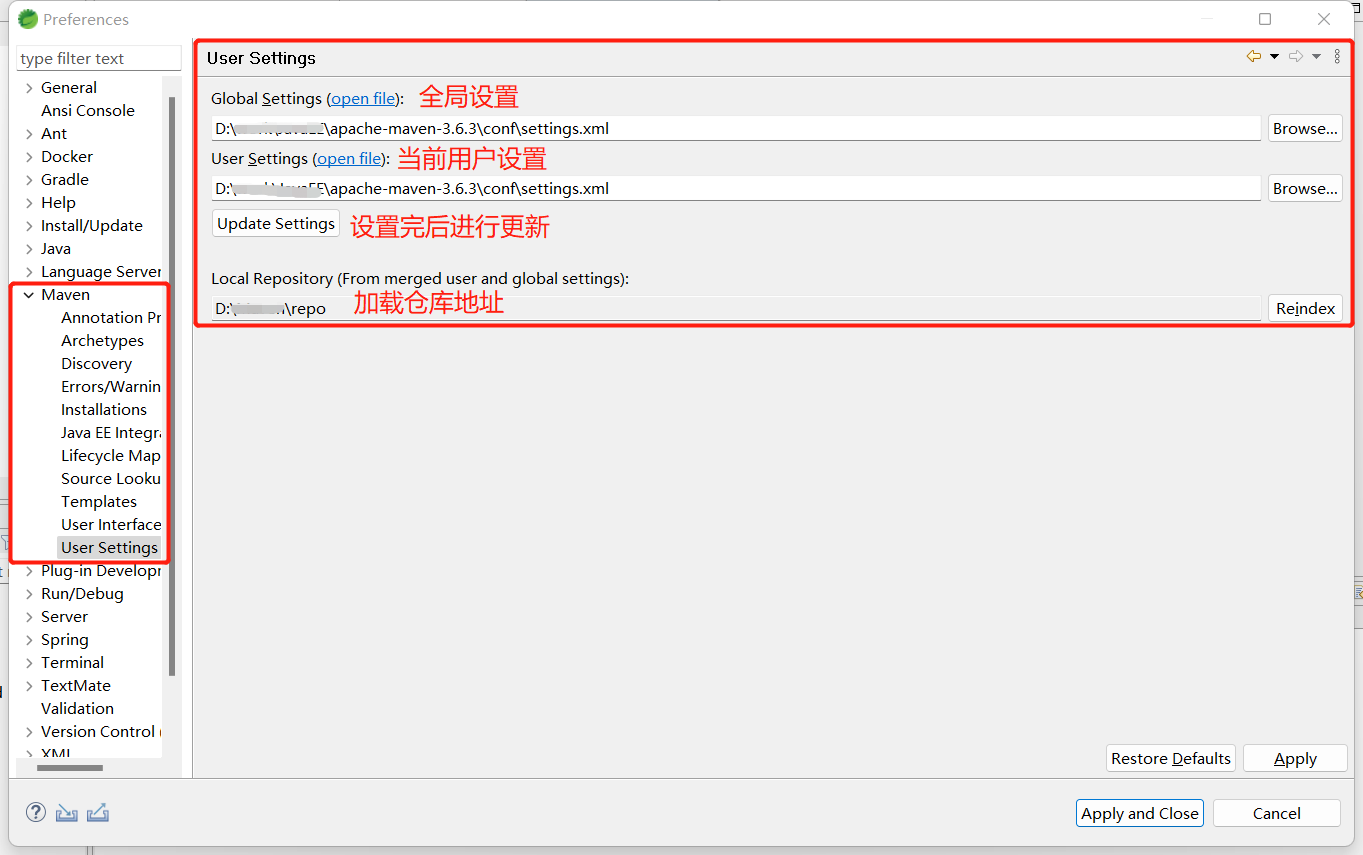
Maven Repo配置阿里云镜像源
本地maven环境配置conf\settings.xml(使用阿里云镜像地址),
maven版本
:apache-maven-3.6.3
配置本地repo仓库存储目录
<localRepository>D:\Maven\repo</localRepository>
配置mirrors
<mirrors>
<mirror>
<id>aliyunmaven</id>
<name>aliyun maven</name>
<!-- 老版本url -->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<!-- 新版本url -->
<!--<url>https://maven.aliyun.com/repository/public/</url>-->
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
阿里云Maven中央仓库为
阿里云云效
提供的公共代理仓库,帮助研发人员提高研发生产效率,使用阿里云Maven中央仓库作为下载源,速度更快更稳定。
在线搜索jar包依赖
:
https://developer.aliyun.com/mvn/search
Springboot集成nacos服务
主要介绍Springboot项目以微服务形式集成nacos,如果使用springmvc或者是普通springboot项目集成nacos服务,可以参考官方文档。
关于版本问题
,我将官方部分(个人感觉初次使用可能用得上,并非全部)文档引入到本次教程。
tips
:sts个性化注解设置,Window---> Preferences--->Java--->Code Style--->Code Templates--->Comments:Types method
在集成nacos服务之前,一步一步来,从构建第一个springboot项目开始。
springboot项目构建
可能你有疑问,springboot版本如何选择,下图支持最后维护时间可供参考:
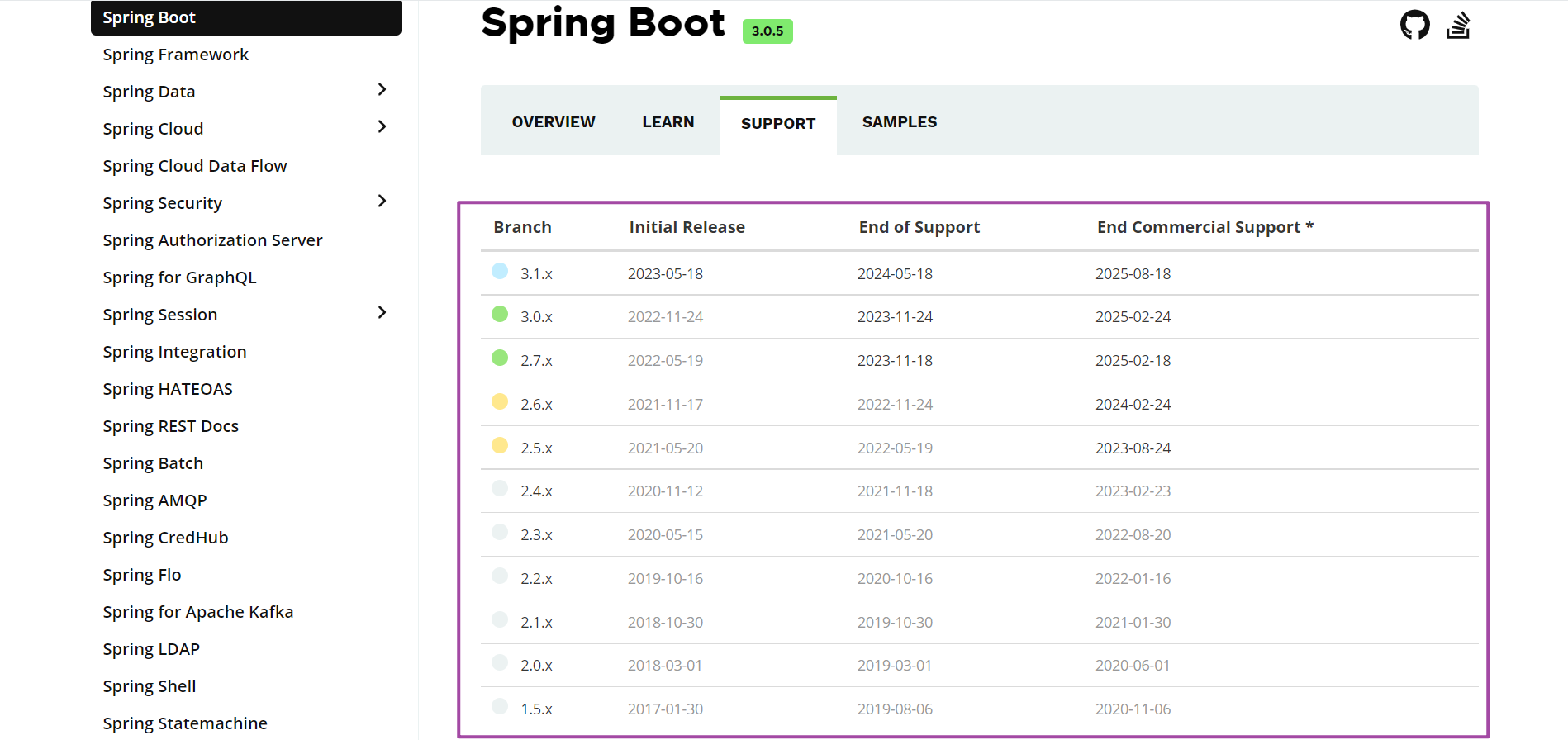
目前Springboot官网最新稳定版本是Springboot3.0.5,实际工作中个人使用2.7.x版本,未来主流可能是3.X版本。目前主流依旧是Springboot2.x,更倾向于2.6.x或者2.7.x作为开发构建版本,当然也是以spring官网显示维护时间作为参考。
项目构建方式有多种,总体上分官网脚手架构建和开发工具构建,此处以官网和STS4为示例。不必纠结,怎么顺手怎么来。
如果官网访问速度缓慢,你还可以通过阿里云脚手架网站构建
:
https://start.aliyun.com/
springboot项目之官网构建
访问:
https://start.spring.io/
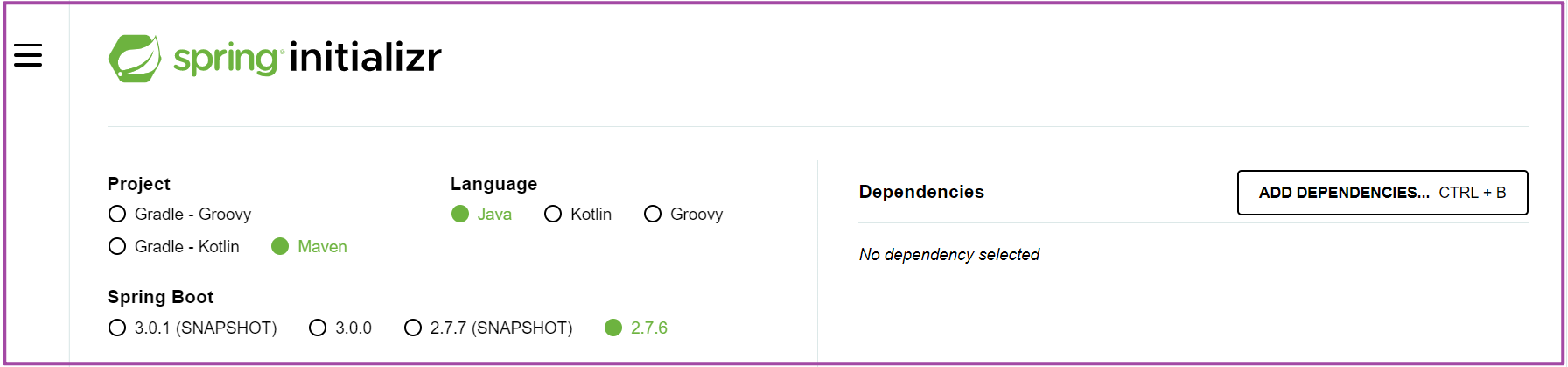
第一步
- Project:选择Maven作为项目构建方式
- Language:选择Java作为开发语言
- Spring Boot:选择springboot2.7.6稳定版本作为构建版本
- Dependencies:选择pom依赖的jar包
第二步
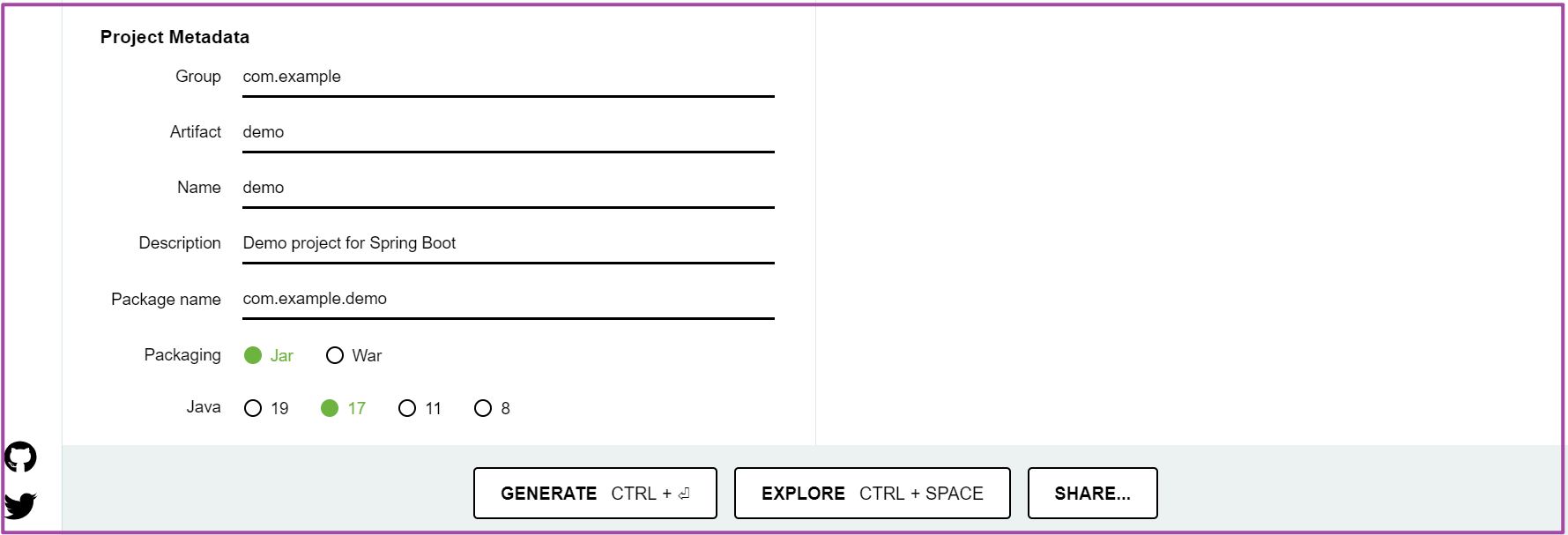
- Project Metadata:项目元数据,Group组名、Artifact工程名、Name项目名称、Description项目描述、Package name包名。
- Packaging:选择Jar作为默认打包方式。
- Java:选择JDK17作为Java项目默认构建版本。
- GENERATE:生成构建项目demo并下载。
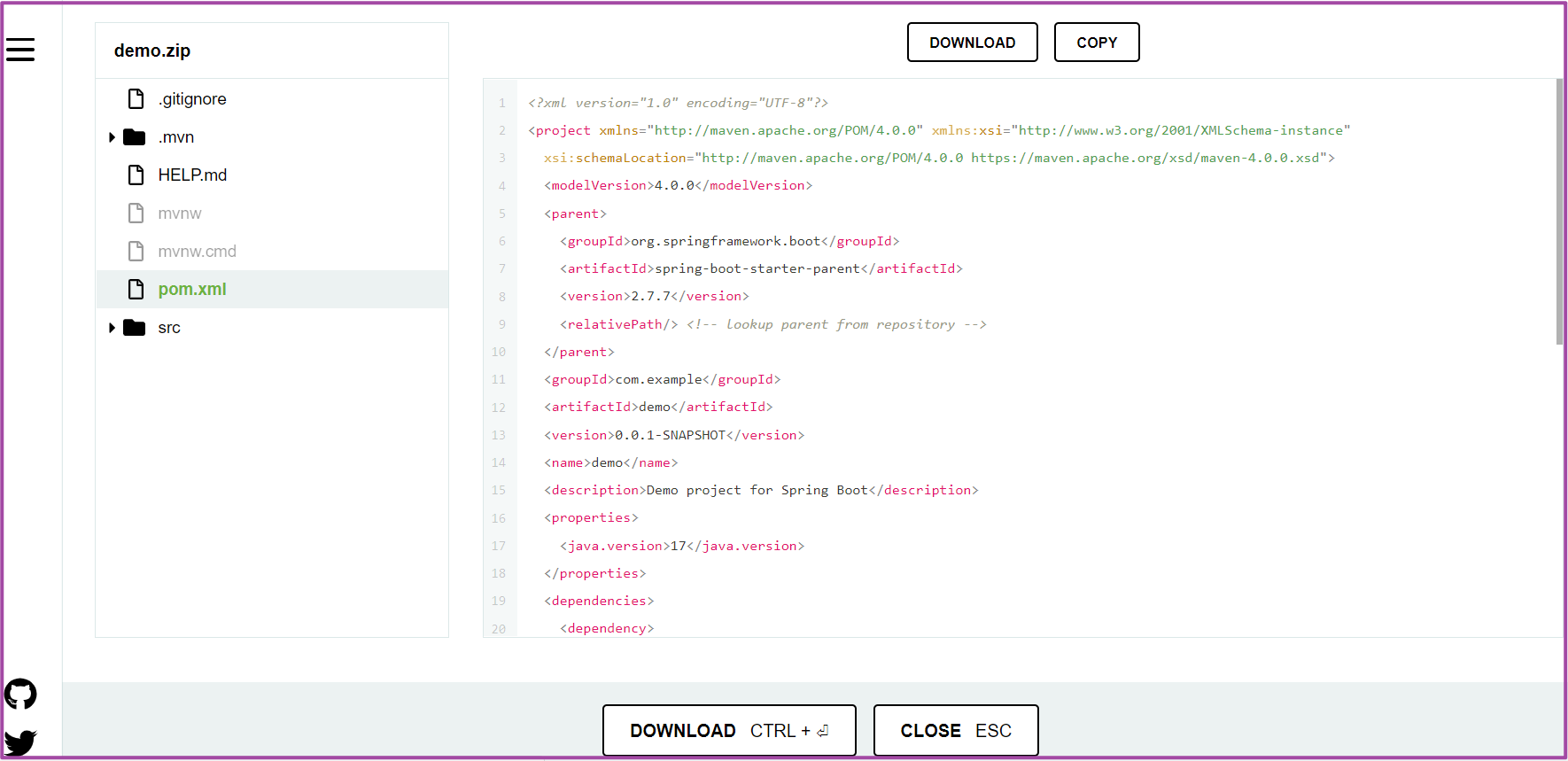
- EXPLORE:展示出构建项目结构清单以及文件具体内容。
以下展示Project Metadata截图以及EXPLORE截图。
EXPLORE:展示项目层次结构
springboot项目之STS4工具构建
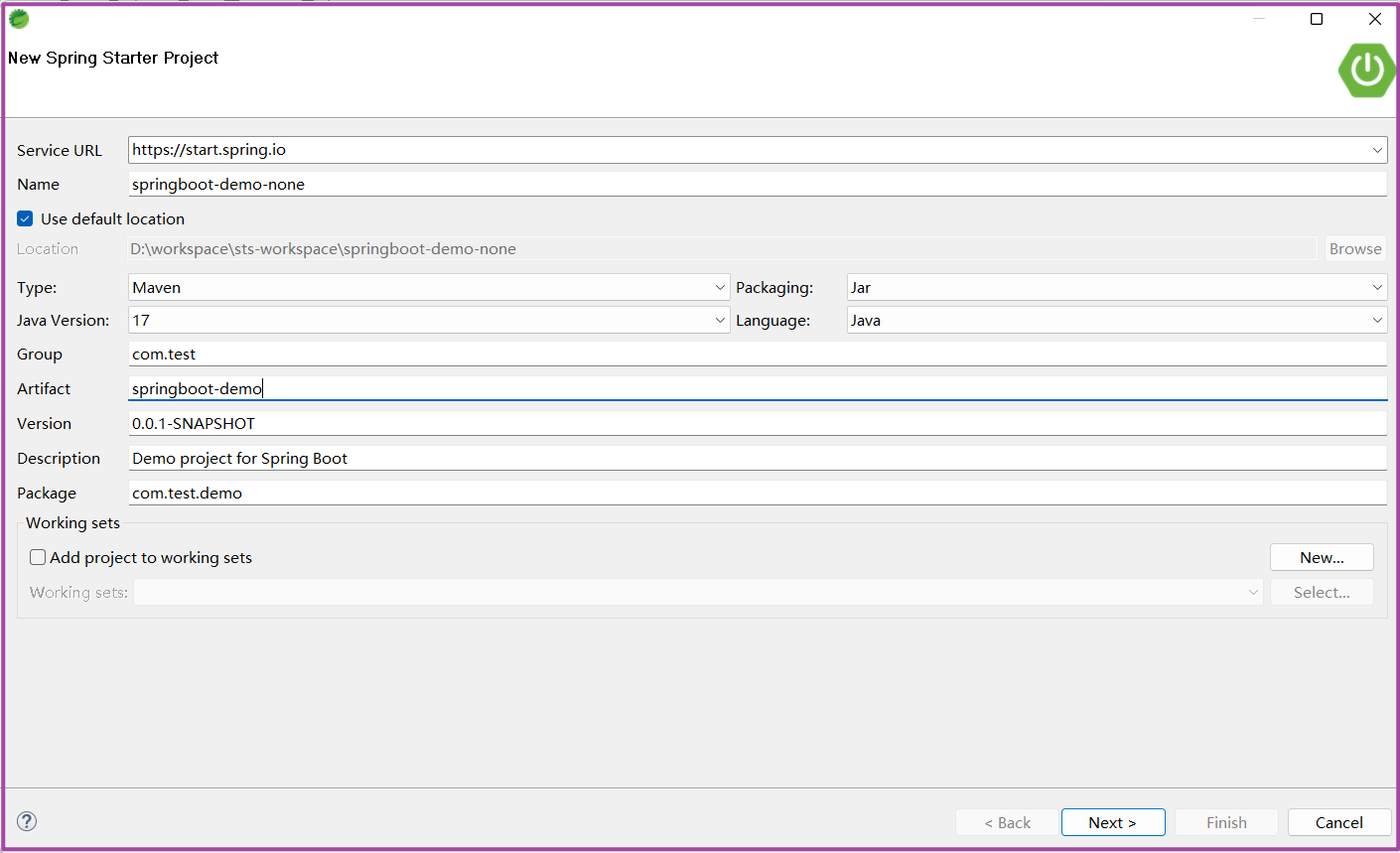
依次选择File-->new-->Spring Starter Project,或者使用快捷键ALT+SHIFT+N。
配置Project步骤一
具体含义参考上面官网构建时说明。
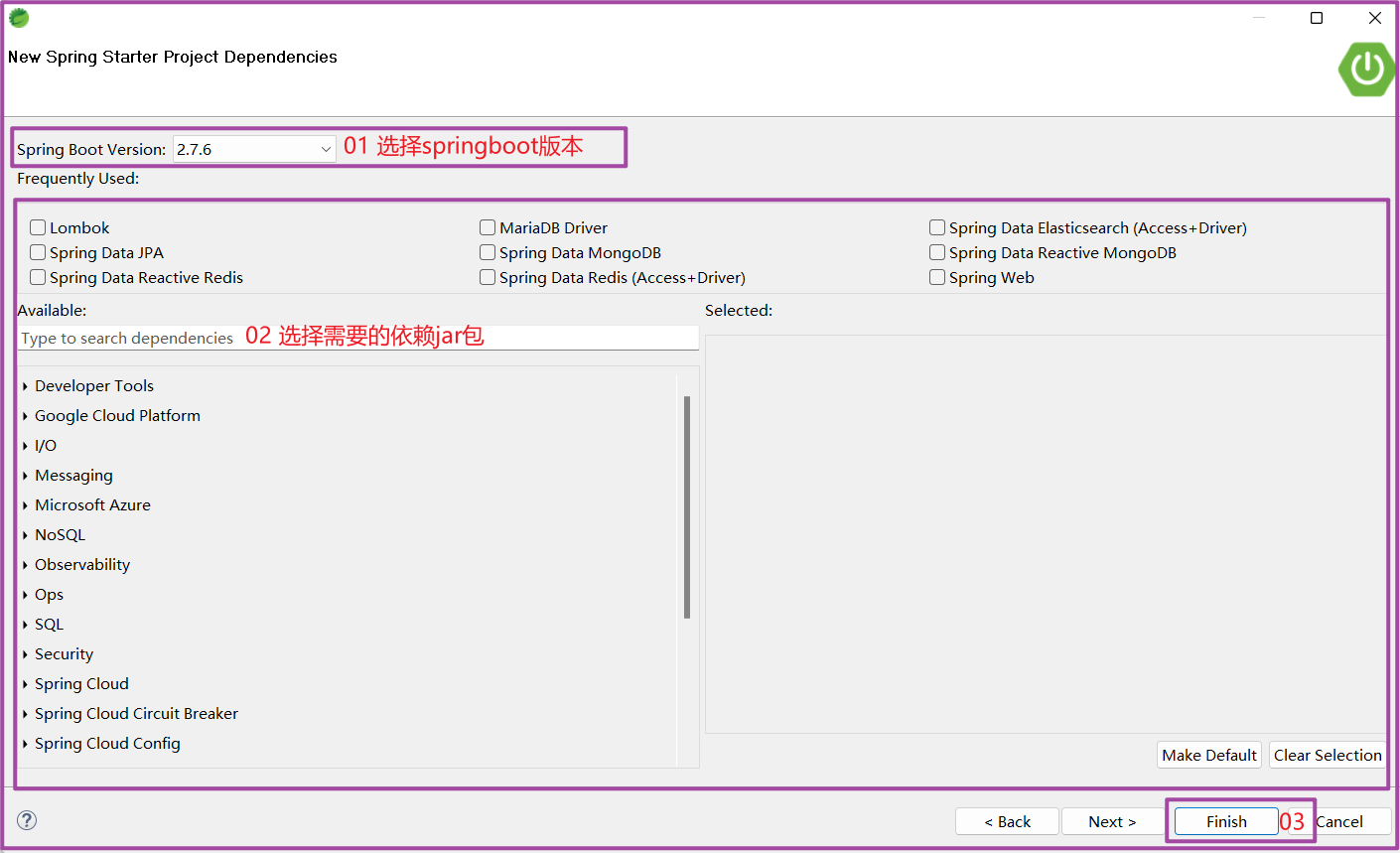
配置Project步骤二
选择springboot版本,以及配置所需要的pom.xml依赖。
如下图所示,
Spring Boot Version
个人选择的是springboot2.7.6稳定版本作为演示,目前最新稳定版本可选为springboot3.0.5。
Frequently Used
表示官方建议使用到的一些工具,讲几个个人使用过的。
Lombok用于简化实体类(bean、entity、repository)get、set方法以及log日志打印,个人开发很实用,团队中慎重使用。
MariaDB Driver是MariaDB数据库驱动,可以看做是MySQL替代产品。Spring Data JPA是对ORM持久化框架Hibernate近一步封装,简化了SQL操作。Spring Data MongoDB是nosql数据库中的一种,其它有Redis,主要用于做缓存使用。Spring Data Redis是nosql数据库中的一种,前面刚好介绍到了。
搜索框Type to search dependencies
,可以进行检索需要的依赖,也可以展开下面小箭头选择依赖。比如展开下图上的SQL选项,有多种数据库驱动依赖可供选择使用。
springboot集成微服务nacos
正式搭建之前,注意项目环境:使用Spring如何集成nacos?使用springboot如何集成nacos?使用springcloud微服务组件如何集成nacos?此处发出了三连问,也许你在使用时也会遇到。不同的环境,可能得到的结果不一样。
**下面将演示 springboot 项目集成微服务组件 nacos 过程 **。
1、启动示例
本地正常启动场景,使用127.0.0.1或者localhost,默认端口:8080。特殊情况在配置文件指定了固定IP地址。例如在application.properties 或者 application.yml 指定IP和端口,两种配置方式保留一种即可。
示例:application.properties
server.port=8081
server.address=192.168.1.666666
示例:application.yml
server:
port: 8081
address: 192.168.1.666666
springboot启动过程:
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.7.6)
2022-10-26 20:13:06.902 INFO 16620 --- [ main] com.test.demo.Application : Starting Application using Java 17.0.2 on kart with PID 16620 (...)
2022-10-26 20:13:08.091 INFO 16620 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
...
2022-10-26 20:13:10.260 INFO 16620 --- [ main] c.a.c.n.registry.NacosServiceRegistry : nacos registry, DEFAULT_GROUP springboot-test 192.168.245.1:8080 register finished
2022-10-26 20:13:10.579 INFO 16620 --- [ main] com.test.demo.Application : Started Application in 4.45 seconds (JVM running for 5.251)
2、配置pom.xml
springbot版本简要说明
:springboot GA(General Availability 表示稳定版本),各分支最新稳定版本2.3.12、2.4.13、2.5.14、2.6.14、2.7.10、3.0.5
<!-- springboot GA(最新稳定版本):2.3.12、2.4.13、2.5.14、2.6.14、2.7.10、3.0.5 -->
<!-- springboot pom.xml parent父类 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.6</version>
<relativePath/>
</parent>
统一版本管理
:JDK版本:17,spring-cloud-dependencies版本采用2021.0.4,spring-cloud-alibaba-dependencies版本采用:2021.0.4.0,和我保持一致,可以采用springboot2.7.x进行测试使用。目前,如果使用阿里云脚手架构建,springboot版本推荐不高于2.6.13。在nacos系列博文第一篇《MySQL数据库与Nacos搭建监控服务》中有写到如何构建,这里不在赘述。
<properties>
<java.version>17</java.version>
<spring-cloud-dependencies.version>2021.0.4</spring-cloud-dependencies.version>
<spring-cloud-alibaba-dependencies.version>2021.0.4.0</spring-cloud-alibaba-dependencies.version>
</properties>
pom依赖管理:dependency
主要注意版本对应:
- 微服务:spring cloud依赖
- 微服务:spring cloud alibaba依赖
- 微服务:nacos config依赖、nacos discovery依赖、bootstrap依赖
<!-- 总包管理 -->
<dependencyManagement>
<dependencies>
<!-- spring cloud依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud-dependencies.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- spring cloud alibaba依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba-dependencies.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!-- 引入相关依赖 -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 微服务 nacos config依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- 微服务 nacos discovery依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- 微服务 bootstrap依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
</dependencies>
3、配置application.properties & application.yml & bootstrap.properties
如果使用开发环境多配置文件设置,可以使用:dev、prod、test进行区分,使用参数 spring.profiles.active=dev 进行指定为开发环境。
# api port
server.port=8080
# 开发环境多配置文件设置:dev、prod、test
spring.profiles.active=dev
# 服务名称
spring.application.name=springboot-test
###################################nacos配置#######################################
# nacos 打开监控 配合普罗米修斯进行监控 官方提供了MySQL初始化sql文件 在conf目录下:nacos-mysql.sql
# 暴露metrics数据
management.endpoints.web.exposure.include=*
# nacos 配置注册远程服务地址{config.server-addr和server-addr}
#spring.cloud.nacos.config.server-addr=192.168.245.132:8848
# nacos 配置注册与发现{discovery.server-addr}
spring.cloud.nacos.discovery.server-addr=192.168.245.132:8848
#spring.cloud.nacos.discovery.namespace=public
spring.cloud.nacos.config.file-extension=properties
###################################nacos配置#######################################
bootstrap.properties
#bootstrap.properties基础配置
#服务名称
spring.application.name=springboot-test
#暴露config配置服务地址(动态更新)
spring.cloud.nacos.config.server-addr=192.168.245.132:8848
#配置config文件扩展名(properties & yml)
spring.cloud.nacos.config.file-extension=properties
4、springboot入口:配置Application.java
- @SpringBootApplication:sringboot启动必备注解
- @EnableDiscoveryClient:用于nacos发现客户端注解
@SpringBootApplication //sringboot启动必备注解
@EnableDiscoveryClient //用于nacos发现客户端注解
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
TestController类引入测试代码:使用 Spring Cloud 原生注解,开启自动更新。
单一配置场景,通过@Value注解,配置动态配置获取测试。
多属性配置场景,可以通过@Autowired 注解注入自定义配置类。
@RestController
@RefreshScope // Spring Cloud 原生注解 开启自动更新
@RequestMapping(value = "/t")
public class TestController {
/** 使用动态配置获取测试 --BEGIN-- **/
@Value("${alibaba.config.discovery}")
private String discovery;
@Value("${alibaba.config.name}")
private String name;
@GetMapping("/getConfig")
public String getConfig() {
log.info("getConfig>>>>>>>>>>>");
return "getConfig>>>>>>>>>>>>" + "发现:" + discovery + ">>>服务名称:" + name;
}
@Value("${custom.config.find}")
private String find;
@Value("${custom.config.say}")
private String say;
@GetMapping("/meet")
public String meet() {
log.info("meet>>>>>>>>>>>");
return "meet>>>>>>>>>>>>" + "偶遇老湿:" + find + ">>>你好:" + say;
}
/** 使用动态配置获取测试 --END-- **/
}
}
可以根据业务情况而定,将多个配置封装到一个类里面,如下所示,新建CustomConf类:
/**
* desc:对象配置类
* @Value
* @Component @ConfigurationProperties
*/
@Component
@ConfigurationProperties(prefix = "custom")
public class CustomConf {
private Integer one;
private Integer two;
private Integer three;
private String description;
// 此处省略掉了 get set 方法,实际需要补上
}
使用到注解:
- @Value :通常情况,使用注解取值。
- @Component :加入注解,便于被扫描到。
- @ConfigurationProperties:引入配置,通过prefix指定配置前缀。
在项目中注入:
@Autowired
private CustomConf custom;
@RequestMapping("/custom")
public String custom() {
return "[custom] " + custom;
}
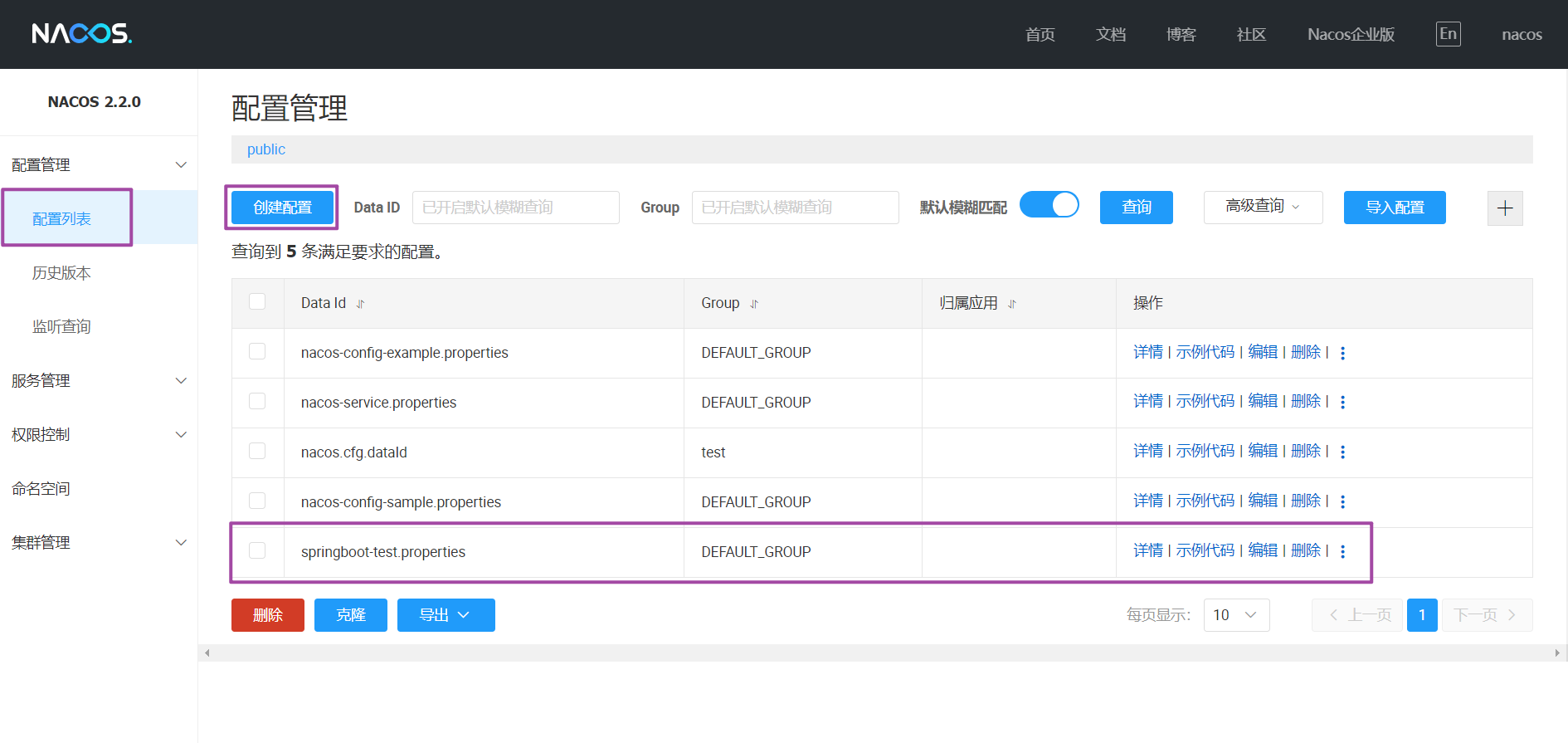
nacos 控制台:新建配置
:springboot-test.properties
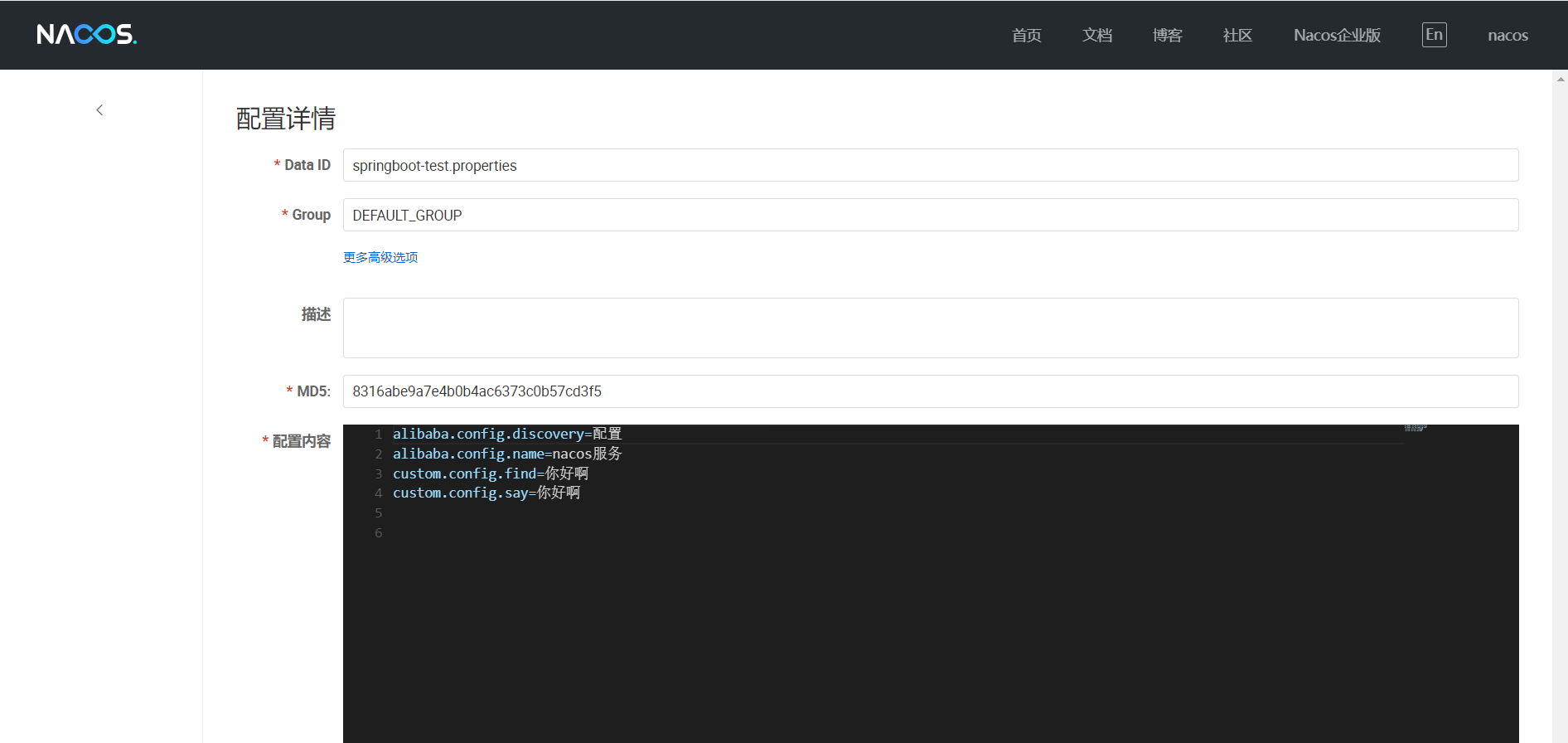
nacos 控制台:配置详情
:配置的比较随意,参考看看就行
运行服务
:
- nohup:代表脱离终端运行
- &:代表放入后台
- -Dspring.profiles.active=prod:指定为生产环境
[root@Centos9-Stream test]# nohup java -jar -Dspring.profiles.active=prod /opt/workspace/test/springboot-nacos-cloud-0.0.1-SNAPSHOT.jar > /opt/
workspace/test/springboot-nacos.log 2>&1 &
[1] 4628
测试接口
:
http://192.168.245.132:8082/t/getConfig
你也可以使用curl命令请求:
curl -X GET http://192.168.245.132:8082/t/getConfig
得到输出结果
:
getConfig>>>>>>>>>>>>发现:配置>>>服务名称:nacos服务
查看日志验证:
tail -n 5 springboot-nacos.log

验证成功,getConfig日志打印出来了。
至此,springboot集成微服务组件nacos联动完成,详细说明可以参考上一篇文章,文初有说明,这里不在赘述。
实际使用过程中,难免会遇到各种问题,此时不用慌,有详细官方文档可供参考。如下引入了nacos部分文档,解决搭建过程中遇到的问题,提供参考
。
nacos版本问题
如果你使用nacos 1.x升级到nacos 2.x版本,建议参考官方兼容性说明与升级文档
。
nacos2.0.0版本兼容性说明
兼容性说明:
https://nacos.io/zh-cn/docs/v2/upgrading/2.0.0-compatibility.html
目前官网推荐使用nacos2.1.1稳定版
,推荐的上一个稳定版本是2.0.3。
Nacos2.0版本相比1.X新增了gRPC的通信方式,因此需要增加2个端口。新增端口是在配置的主端口(server.port)基础上,进行一定偏移量自动生成。
|
端口
|
与主端口的偏移量
|
描述
|
| 9848 |
1000 |
客户端gRPC请求服务端端口,用于客户端向服务端发起连接和请求 |
| 9849 |
1001 |
服务端gRPC请求服务端端口,用于服务间同步等 |
使用VIP/nginx请求时,需要配置成TCP转发,不能配置http2转发,否则连接会被nginx断开。
客户端拥有相同的计算逻辑,用户如同1.X的使用方式,配置主端口(默认8848),通过相同的偏移量,计算对应gRPC端口(默认9848)。
因此
如果客户端和服务端之前存在端口转发或防火墙时,需要对端口转发配置和防火墙配置做相应的调整
。
nacos升级文档
升级文档:
https://nacos.io/zh-cn/docs/v2/upgrading/2.0.0-upgrading.html
nacos版本与spring cloud对应关系
由于 Spring Boot 3.0,Spring Boot 2.7~2.4 和 2.4 以下版本之间变化较大,目前企业级客户老项目相关 Spring Boot 版本仍停留在 Spring Boot 2.4 以下,为了同时满足存量用户和新用户不同需求,社区以 Spring Boot 3.0 和 2.4 分别为分界线,同时维护 2022.x、2021.x、2.2.x 三个分支迭代。 为了规避相关构建过程中的依赖冲突问题,我们建议可以通过
云原生应用脚手架
进行项目创建。
2022.x 分支
适配 Spring Boot 3.0,Spring Cloud 2022.x 版本及以上的 Spring Cloud Alibaba 版本按从新到旧排列如下表(最新版本用*标记): (注意,该分支 Spring Cloud Alibaba 版本命名方式进行了调整,未来将对应 Spring Cloud 版本,前三位为 Spring Cloud 版本,最后一位为扩展版本,比如适配 Spring Cloud 2022.0.0 版本对应的 Spring Cloud Alibaba 第一个版本为:2022.0.0.0,第个二版本为:2022.0.0.1,依此类推)
|
Spring Cloud Alibaba Version
|
Spring Cloud Version
|
Spring Boot Version
|
| 2022.0.0.0-RC* |
Spring Cloud 2022.0.0 |
3.0.0 |
2021.x 分支
适配 Spring Boot 2.4,Spring Cloud 2021.x 版本及以上的 Spring Cloud Alibaba 版本按从新到旧排列如下表(最新版本用*标记): (注意,该分支 Spring Cloud Alibaba 版本命名方式进行了调整,未来将对应 Spring Cloud 版本,前三位为 Spring Cloud 版本,最后一位为扩展版本,比如适配 Spring Cloud 2021.0.1 版本对应的 Spring Cloud Alibaba 第一个版本为:2021.0.1.0,第个二版本为:2021.0.1.1,依此类推)
|
Spring Cloud Alibaba Version
|
Spring Cloud Version
|
Spring Boot Version
|
| 2021.0.5.0* |
Spring Cloud 2021.0.5 |
2.6.13 |
| 2021.0.4.0* |
Spring Cloud 2021.0.4 |
2.6.11 |
| 2021.0.1.0 |
Spring Cloud 2021.0.1 |
2.6.3 |
| 2021.1 |
Spring Cloud 2020.0.1 |
2.4.2 |
2.2.x 分支
适配 Spring Boot 为 2.4,Spring Cloud Hoxton 版本及以下的 Spring Cloud Alibaba 版本按从新到旧排列如下表(最新版本用*标记):
|
Spring Cloud Alibaba Version
|
Spring Cloud Version
|
Spring Boot Version
|
| 2.2.10-RC1* |
Spring Cloud Hoxton.SR12 |
2.3.12.RELEASE |
| 2.2.9.RELEASE* |
Spring Cloud Hoxton.SR12 |
2.3.12.RELEASE |
| 2.2.8.RELEASE |
Spring Cloud Hoxton.SR12 |
2.3.12.RELEASE |
| 2.2.7.RELEASE |
Spring Cloud Hoxton.SR12 |
2.3.12.RELEASE |
| 2.2.6.RELEASE |
Spring Cloud Hoxton.SR9 |
2.3.2.RELEASE |
| 2.2.1.RELEASE |
Spring Cloud Hoxton.SR3 |
2.2.5.RELEASE |
| 2.2.0.RELEASE |
Spring Cloud Hoxton.RELEASE |
2.2.X.RELEASE |
| 2.1.4.RELEASE |
Spring Cloud Greenwich.SR6 |
2.1.13.RELEASE |
| 2.1.2.RELEASE |
Spring Cloud Greenwich |
2.1.X.RELEASE |
| 2.0.4.RELEASE(停止维护,建议升级) |
Spring Cloud Finchley |
2.0.X.RELEASE |
| 1.5.1.RELEASE(停止维护,建议升级) |
Spring Cloud Edgware |
1.5.X.RELEASE |
组件版本关系
版本说明
:
https://github.com/alibaba/spring-cloud-alibaba/wiki/版本说明
每个 Spring Cloud Alibaba 版本及其自身所适配的各组件对应版本如下表所示(注意,Spring Cloud Dubbo 从 2021.0.1.0 起已被移除出主干,不再随主干演进):
|
Spring Cloud Alibaba Version
|
Sentinel Version
|
Nacos Version
|
RocketMQ Version
|
Dubbo Version
|
Seata Version
|
| 2021.0.5.0 |
1.8.6 |
2.2.0 |
4.9.4 |
~ |
1.6.1 |
| 2.2.10-RC1 |
1.8.6 |
2.2.0 |
4.9.4 |
~ |
1.6.1 |
| 2022.0.0.0-RC1 |
1.8.6 |
2.2.1-RC |
4.9.4 |
~ |
1.6.1 |
| 2.2.9.RELEASE |
1.8.5 |
2.1.0 |
4.9.4 |
~ |
1.5.2 |
| 2021.0.4.0 |
1.8.5 |
2.0.4 |
4.9.4 |
~ |
1.5.2 |
| 2.2.8.RELEASE |
1.8.4 |
2.1.0 |
4.9.3 |
~ |
1.5.1 |
| 2021.0.1.0 |
1.8.3 |
1.4.2 |
4.9.2 |
~ |
1.4.2 |
| 2.2.7.RELEASE |
1.8.1 |
2.0.3 |
4.6.1 |
2.7.13 |
1.3.0 |
| 2.2.6.RELEASE |
1.8.1 |
1.4.2 |
4.4.0 |
2.7.8 |
1.3.0 |
| 2021.1 or 2.2.5.RELEASE or 2.1.4.RELEASE or 2.0.4.RELEASE |
1.8.0 |
1.4.1 |
4.4.0 |
2.7.8 |
1.3.0 |
| 2.2.3.RELEASE or 2.1.3.RELEASE or 2.0.3.RELEASE |
1.8.0 |
1.3.3 |
4.4.0 |
2.7.8 |
1.3.0 |
| 2.2.1.RELEASE or 2.1.2.RELEASE or 2.0.2.RELEASE |
1.7.1 |
1.2.1 |
4.4.0 |
2.7.6 |
1.2.0 |
| 2.2.0.RELEASE |
1.7.1 |
1.1.4 |
4.4.0 |
2.7.4.1 |
1.0.0 |
| 2.1.1.RELEASE or 2.0.1.RELEASE or 1.5.1.RELEASE |
1.7.0 |
1.1.4 |
4.4.0 |
2.7.3 |
0.9.0 |
| 2.1.0.RELEASE or 2.0.0.RELEASE or 1.5.0.RELEASE |
1.6.3 |
1.1.1 |
4.4.0 |
2.7.3 |
0.7.1 |
排查错误
启动时报错
Connection is unregistered.
或
Client not connected,current status:STARTING
.
原因是
客户端gRPC无法和服务端创建连接
,请先使用
telnet ${nacos.server.address}:${nacos.server.grpc.port}
进行测试,查看网络是否畅通,服务端端口是否已经正确监听。
Nacos2.0增加了9848,9849端口来进行GRPC通信,我需要在application.properties中额外配置吗?
不需要,这两个端口在Nacos2.0内部是通过8848+1000以及8848+1001这种偏移量方式计算出来的,不需要用户额外在配置文件中配置。但如果使用的是docker或存在端口转发方式启动,需要把这两个端口进行配置。
启动nacos2.0时希望用nginx 代理,9848这个端口怎样处理,要通过nginx暴露出来么?以及docker是否需要映射?
如果存在防火墙或者nginx端口转发问题,需要进行相应的端口暴露配置。如在nginx中,在已经暴露8848(x)的基础上,需要额外暴露9848(x+1000)。
解决版本冲突问题时遇到端口未开放
2022-12-07 20:08:13.792 INFO 17152 --- [t.remote.worker] com.alibaba.nacos.common.remote.client : [236c02fe-157b-475e-9540-b11bf110f49e_config-0] Fail to connect server, after trying 2 times, last try server is {serverIp = '192.168.245.132', server main port = 8858}, error = unknown
2022-12-07 20:08:16.213 ERROR 17152 --- [ main] c.a.n.c.remote.client.grpc.GrpcClient : Server check fail, please check server 192.168.245.132 ,port 9858 is available , error ={}
分析问题
:检查192.168.245.132服务器的端口9858是否可用。如果参考了上面文档,你会发现我默认端口为8858,nacos2.x使用gRPC通信方式,+1000偏移量检测9858是否可用,由于防火墙或端口转发等原因,需要开发相应端口。
开放相应端口
firewall-cmd --zone=public --add-port=9858/tcp --permanent
firewall-cmd --zone=public --add-port=9859/tcp --permanent
重载firewall-cmd服务
firewall-cmd --reload
查看开放的端口
[root@Centos9-Stream nacos-2.0.4]# firewall-cmd --list-all
public (active)
...
ports: 8848/tcp 9001-9010/tcp 8081/tcp 3000/tcp 8082/tcp 8083/tcp 8858/tcp 9858/tcp
...
启动多个nacos server服务导致nacos-server.jar占用 PID 问题
定位问题:查看nacos.log日志文件
2022-12-07 20:19:02,601 INFO Starting Nacos v2.0.3 on Centos9-Stream with PID 34970 (/usr/local/nacos/target/nacos-server.jar started by root in /usr/local/nacos-2.0.4)
参考资料
:
切记切记,以上总结,仅供参考!别人提供的是思考方向,具体实践还需亲自测试印证。
有不足的地方,还望各位大佬轻喷。
END----
静下心来,才发现原来不会的还有很多。
一分耕耘,一分收获。
多总结,你会发现,自己的知识宝库越来越丰富。