SpringBoot 集成 Quartz + MySQL
Quartz 简单使用
Java SpringBoot 中,动态执行 bean 对象中的方法
源代码地址 =>
https://gitee.com/VipSoft/VipBoot/tree/develop/vipsoft-quartz
工作原理解读
只要配置好 DataSource Quartz 会自动进行表的数据操作,
添加 Quartz Job 任务
保存 QRTZ_JOB_DETAILS、QRTZ_TRIGGERS => QRTZ_CRON_TRIGGERS
public void addJob(QuartzJob job) throws SchedulerException {
....
JobDetail jobDetail = JobBuilder.newJob(jobClass)
.withIdentity(jobKey)
.build();
// 放入参数,运行时的方法可以获取
jobDetail.getJobDataMap().put(ScheduleConstants.TASK_PROPERTIES, job);
//该行代码执行后,会将定时任务插入 QRTZ_JOB_DETAILS 等相关表
scheduler.scheduleJob(jobDetail, trigger);
....
}
//org.quartz.impl.jdbcjobstore.JobStoreSupport
public void storeJobAndTrigger(final JobDetail newJob, final OperableTrigger newTrigger) throws JobPersistenceException {
this.executeInLock(this.isLockOnInsert() ? "TRIGGER_ACCESS" : null, new JobStoreSupport.VoidTransactionCallback() {
public void executeVoid(Connection conn) throws JobPersistenceException {
JobStoreSupport.this.storeJob(conn, newJob, false); //数据保存 QRTZ_JOB_DETAILS 表
JobStoreSupport.this.storeTrigger(conn, newTrigger, newJob, false, "WAITING", false, false); //数据保存 QRTZ_TRIGGERS 表
}
});
}
public int insertTrigger(...){
INSERT_TRIGGER
insertExtendedTriggerProperties => INSERT_CRON_TRIGGER OR INSERT_BLOB_TRIGGER
}
详见:
org.quartz.impl.jdbcjobstore.StdJDBCDelegate
将 job.getJobDataMap(),对像序列化后,存入
JOB_DETAILS.JOB_DATA
字段,可以是一个对像,以执行定时任务时,会把该字段反序列化,根据前期设定的内容进行业务处理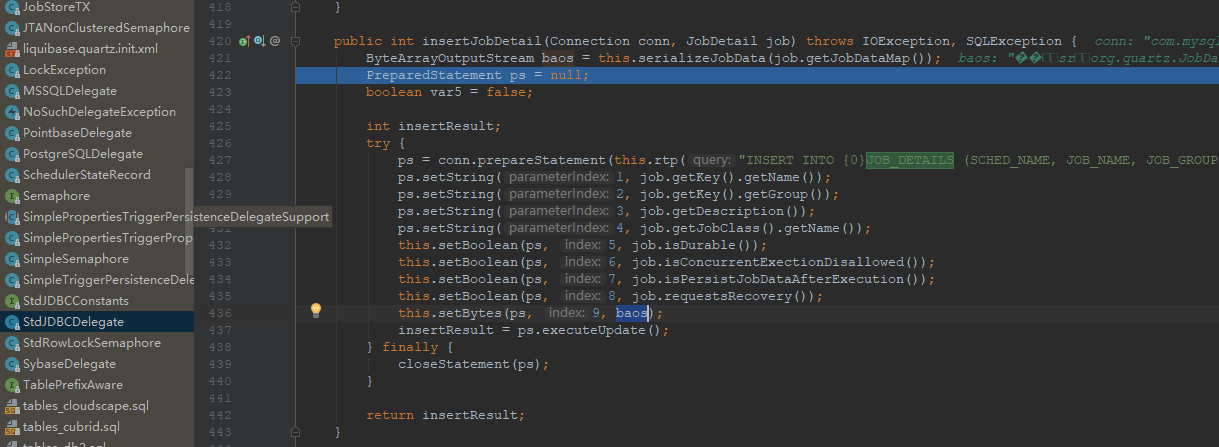
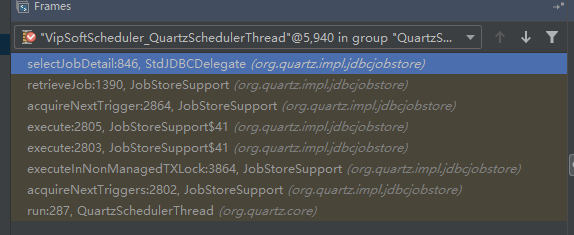
获取 Quartz Job 任务
执行计划任务时,获取 Job Detail
QuartzSchedulerThread.run()
=> qsRsrcs.getJobStore().acquireNextTriggers()
=> txCallback.execute(conn)
=> JobStoreSupport.acquireNextTriggers()
=> JobStoreSupport.retrieveJob()
=> StdJDBCDelegate.selectJobDetail()
删除 Quartz Job 任务
/**
* <p>
* Delete the base trigger data for a trigger.
* </p>
*
* @param conn
* the DB Connection
* @return the number of rows deleted
*/
public int deleteTrigger(Connection conn, TriggerKey triggerKey) throws SQLException {
PreparedStatement ps = null;
deleteTriggerExtension(conn, triggerKey);
try {
ps = conn.prepareStatement(rtp(DELETE_TRIGGER));
ps.setString(1, triggerKey.getName());
ps.setString(2, triggerKey.getGroup());
return ps.executeUpdate();
} finally {
closeStatement(ps);
}
}
清除数据
/**
* 清任务顺序
*/
public void clearData(Connection conn)
throws SQLException {
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(rtp(DELETE_ALL_SIMPLE_TRIGGERS));
ps.executeUpdate();
ps.close();
ps = conn.prepareStatement(rtp(DELETE_ALL_SIMPROP_TRIGGERS));
ps.executeUpdate();
ps.close();
ps = conn.prepareStatement(rtp(DELETE_ALL_CRON_TRIGGERS));
ps.executeUpdate();
ps.close();
ps = conn.prepareStatement(rtp(DELETE_ALL_BLOB_TRIGGERS));
ps.executeUpdate();
ps.close();
ps = conn.prepareStatement(rtp(DELETE_ALL_TRIGGERS));
ps.executeUpdate();
ps.close();
ps = conn.prepareStatement(rtp(DELETE_ALL_JOB_DETAILS));
ps.executeUpdate();
ps.close();
ps = conn.prepareStatement(rtp(DELETE_ALL_CALENDARS));
ps.executeUpdate();
ps.close();
ps = conn.prepareStatement(rtp(DELETE_ALL_PAUSED_TRIGGER_GRPS));
ps.executeUpdate();
} finally {
closeStatement(ps);
}
}
Demo 代码
MySQL 脚本
清除数据
DELETE FROM qrtz_simple_triggers ;
DELETE FROM qrtz_simprop_triggers ;
DELETE FROM qrtz_cron_triggers ;
DELETE FROM qrtz_blob_triggers ;
DELETE FROM qrtz_triggers ;
DELETE FROM qrtz_job_details ;
DELETE FROM qrtz_calendars ;
DELETE FROM qrtz_paused_trigger_grps ;
DELETE FROM qrtz_scheduler_state ;
DELETE FROM qrtz_locks ;
DELETE FROM qrtz_fired_triggers
Pom.xml
如果SpringBoot版本是2.0.0以后的,则在spring-boot-starter中已经包含了quart的依赖,则可以直接使用spring-boot-starter-quartz依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<!--Quartz 集成需要和数据库交互-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.0.8</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<!--hutool 工具类-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.7</version>
</dependency>

QuartzJob 参考上图,建立实体
点击查看代码
package com.vipsoft.web.entity;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.Size;
import java.io.Serializable;
/**
* 定时任务调度
*/
public class QuartzJob implements Serializable {
private static final long serialVersionUID = -6798153039624729495L;
/**
* 任务序号
*/
private int jobId;
/**
* 任务名称
*/
@NotBlank(message = "任务名称不能为空")
@Size(max = 10, message = "任务名称不能超过10个字符")
private String jobName;
/**
* 任务组名
*/
@NotBlank(message = "任务组名不能为空")
@Size(max = 10, message = "任务组名不能超过10个字符")
private String jobGroup;
/**
* 调用目标字符串
*/
private String invokeTarget;
/**
* 执行表达式
*/
private String cronExpression;
/**
* cron计划策略 0=默认,1=立即触发执行,2=触发一次执行,3=不触发立即执行
*/
private String misfirePolicy = "0";
/**
* 并发执行 0=允许,1=禁止
*/
private String concurrent;
/**
* 描述 -- 任务说明
*/
private String description;
/**
* 任务状态(0正常 1暂停)
*/
private String status;
public int getJobId() {
return jobId;
}
public void setJobId(int jobId) {
this.jobId = jobId;
}
public String getJobName() {
return jobName;
}
public void setJobName(String jobName) {
this.jobName = jobName;
}
public String getJobGroup() {
return jobGroup;
}
public void setJobGroup(String jobGroup) {
this.jobGroup = jobGroup;
}
public String getInvokeTarget() {
return invokeTarget;
}
public void setInvokeTarget(String invokeTarget) {
this.invokeTarget = invokeTarget;
}
public String getCronExpression() {
return cronExpression;
}
public void setCronExpression(String cronExpression) {
this.cronExpression = cronExpression;
}
public String getMisfirePolicy() {
return misfirePolicy;
}
public void setMisfirePolicy(String misfirePolicy) {
this.misfirePolicy = misfirePolicy;
}
public String getConcurrent() {
return concurrent;
}
public void setConcurrent(String concurrent) {
this.concurrent = concurrent;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
核心代码:QuartzJobServiceImpl
点击查看代码
package com.vipsoft.web.service.impl;
import cn.hutool.core.util.StrUtil;
import com.vipsoft.web.config.ScheduleConstants;
import com.vipsoft.web.entity.QuartzJob;
import com.vipsoft.web.exception.CustomException;
import com.vipsoft.web.job.CommonJob;
import com.vipsoft.web.service.IQuartzJobService;
import org.quartz.*;
import org.quartz.impl.matchers.GroupMatcher;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
@Service
public class QuartzJobServiceImpl implements IQuartzJobService {
@Autowired
Scheduler scheduler;
/**
* 新增任务
*
* @param job 调度信息
* @return 结果
*/
@Override
public void clearAll(QuartzJob job) throws SchedulerException {
scheduler.clear();
}
/**
* 新增任务
*
* @param job 调度信息
* @return 结果
*/
@Override
public void addJob(QuartzJob job) throws SchedulerException {
if (StrUtil.isEmpty(job.getStatus())) {
// 如果没值,设置暂停
job.setStatus(ScheduleConstants.Status.PAUSE.getValue());
}
Class<? extends Job> jobClass = CommonJob.class;
// 构建job信息
int jobId = job.getJobId();
String jobName = job.getJobName();
String jobGroup = job.getJobGroup();
JobKey jobKey = JobKey.jobKey(jobName, jobGroup);
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroup);
JobDetail jobDetail = JobBuilder.newJob(jobClass)
.withIdentity(jobKey)
.build();
// 放入参数,运行时的方法可以获取
jobDetail.getJobDataMap().put(ScheduleConstants.TASK_PROPERTIES, job);
// 表达式调度构建器
CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule(job.getCronExpression());
cronScheduleBuilder = handleCronScheduleMisfirePolicy(job.getMisfirePolicy(), cronScheduleBuilder);
// 按新的cronExpression表达式构建一个新的trigger
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity(triggerKey)
.withSchedule(cronScheduleBuilder)
.build();
// 判断是否存在
if (scheduler.checkExists(jobKey)) {
// 防止创建时存在数据问题 先移除,然后在执行创建操作
scheduler.deleteJob(jobKey);
}
scheduler.scheduleJob(jobDetail, trigger);
// 暂停任务
if (job.getStatus().equals(ScheduleConstants.Status.PAUSE.getValue())) {
scheduler.pauseJob(jobKey);
}
}
/**
* 设置定时任务策略
*/
public static CronScheduleBuilder handleCronScheduleMisfirePolicy(String misfirePolicy, CronScheduleBuilder cb) {
switch (misfirePolicy) {
case ScheduleConstants.MISFIRE_DEFAULT:
return cb;
case ScheduleConstants.MISFIRE_IGNORE_MISFIRES:
return cb.withMisfireHandlingInstructionIgnoreMisfires();
case ScheduleConstants.MISFIRE_FIRE_AND_PROCEED:
return cb.withMisfireHandlingInstructionFireAndProceed();
case ScheduleConstants.MISFIRE_DO_NOTHING:
return cb.withMisfireHandlingInstructionDoNothing();
default:
throw new CustomException(60001, "策略配置异常 " + misfirePolicy);
}
}
/**
* 更新任务
*
* @param job 调度信息
* @return 结果
*/
@Override
public void updateJob(QuartzJob job) throws SchedulerException {
// 判断是否存在
JobKey jobKey = JobKey.jobKey(job.getJobName(), job.getJobGroup());
if (scheduler.checkExists(jobKey)) {
// 防止创建时存在数据问题 先移除,然后在执行创建操作
scheduler.deleteJob(jobKey);
}
addJob(job);
}
/**
* 删除任务
*
* @param job
* @Date 2016年1月16日
* @since 2.0.0
*/
@Override
public void deleteJob(QuartzJob job) throws SchedulerException {
JobKey jobKey = JobKey.jobKey(job.getJobName(), job.getJobGroup());
if (this.scheduler.checkExists(jobKey)) {
this.scheduler.deleteJob(jobKey);
}
}
/**
* 立即运行任务
*
* @param job 调度信息
* @return 结果
*/
@Override
public void run(QuartzJob job) throws SchedulerException {
JobKey jobKey = JobKey.jobKey(job.getJobName(), job.getJobGroup());
scheduler.triggerJob(jobKey);
}
/**
* 暂停任务
*
* @param job 调度信息
* @return 结果
*/
@Override
public void pauseJob(QuartzJob job) throws SchedulerException {
JobKey jobKey = JobKey.jobKey(job.getJobName(), job.getJobGroup());
this.scheduler.pauseJob(jobKey);
}
/**
* 恢复任务
*
* @param job 调度信息
* @return 结果
*/
@Override
public void restartJob(QuartzJob job) throws SchedulerException {
JobKey jobKey = JobKey.jobKey(job.getJobName(), job.getJobGroup());
this.scheduler.resumeJob(jobKey);
}
/**
* 获取quartz调度器的计划任务
*
* @param job 调度信息
* @return 调度任务集合
*/
@Override
public List<QuartzJob> listJob(QuartzJob job) throws SchedulerException {
List<QuartzJob> scheduleJobVOList = new ArrayList<>();
GroupMatcher<JobKey> matcher = GroupMatcher.anyJobGroup();
Set<JobKey> jobKeys = this.scheduler.getJobKeys(matcher);
for (JobKey jobKey : jobKeys) {
List<? extends Trigger> triggers = this.scheduler.getTriggersOfJob(jobKey);
for (Trigger trigger : triggers) {
JobDetail jobDetail = this.scheduler.getJobDetail(jobKey);
QuartzJob scheduleJobVO = (QuartzJob) jobDetail.getJobDataMap().get(ScheduleConstants.TASK_PROPERTIES);
Trigger.TriggerState triggerState = this.scheduler.getTriggerState(trigger.getKey());
scheduleJobVO.setStatus(triggerState.name());
// 判断trigger
if (trigger instanceof SimpleTrigger) {
SimpleTrigger simple = (SimpleTrigger) trigger;
scheduleJobVO.setCronExpression("重复次数:" + (simple.getRepeatCount() == -1 ? "无限" : simple.getRepeatCount()) + ",重复间隔:"
+ (simple.getRepeatInterval() / 1000L));
scheduleJobVO.setDescription(simple.getDescription());
}
if (trigger instanceof CronTrigger) {
CronTrigger cron = (CronTrigger) trigger;
scheduleJobVO.setCronExpression(cron.getCronExpression());
scheduleJobVO.setDescription(cron.getDescription() == null ? ("触发器:" + trigger.getKey()) : cron.getDescription());
}
scheduleJobVOList.add(scheduleJobVO);
}
}
return scheduleJobVOList;
}
}
ScheduleConfig
点击查看代码
package com.vipsoft.web.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import javax.sql.DataSource;
import java.util.Properties;
@Configuration
public class ScheduleConfig {
/**
* 设置属性
*/
private Properties quartzProperties() {
// quartz参数
Properties prop = new Properties();
prop.put("org.quartz.scheduler.instanceName", "VipSoftScheduler");
prop.put("org.quartz.scheduler.instanceId", "AUTO");
// 线程池配置
prop.put("org.quartz.threadPool.class", "org.quartz.simpl.SimpleThreadPool");
prop.put("org.quartz.threadPool.threadCount", "20");
prop.put("org.quartz.threadPool.threadPriority", "5");
// JobStore配置
prop.put("org.quartz.jobStore.class", "org.quartz.impl.jdbcjobstore.JobStoreTX");
// 集群配置
prop.put("org.quartz.jobStore.isClustered", "true");
prop.put("org.quartz.jobStore.clusterCheckinInterval", "15000");
prop.put("org.quartz.jobStore.maxMisfiresToHandleAtATime", "1");
prop.put("org.quartz.jobStore.txIsolationLevelSerializable", "true");
// sqlserver 启用
// prop.put("org.quartz.jobStore.selectWithLockSQL", "SELECT * FROM {0}LOCKS UPDLOCK WHERE LOCK_NAME = ?");
prop.put("org.quartz.jobStore.misfireThreshold", "12000");
prop.put("org.quartz.jobStore.tablePrefix", "QRTZ_");
return prop;
}
@Bean
public SchedulerFactoryBean schedulerFactoryBean(DataSource dataSource) {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setDataSource(dataSource);
// //获取配置属性--通过加载配置文件的方式获取配置
// PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
// propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
// //在quartz.properties中的属性被读取并注入后再初始化对象
// propertiesFactoryBean.afterPropertiesSet();
// factory.setQuartzProperties(propertiesFactoryBean.getObject());
//用于quartz集群,加载quartz数据源配置
factory.setQuartzProperties(this.quartzProperties());
factory.setSchedulerName("VipSoftScheduler");
//QuartzScheduler 延时启动,应用启动完10秒后 QuartzScheduler 再启动
factory.setStartupDelay(10);
// 可选,QuartzScheduler
// 启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了
factory.setOverwriteExistingJobs(true);
// 设置自动启动,默认为true
factory.setAutoStartup(true);
factory.setApplicationContextSchedulerContextKey("applicationContextKey");
return factory;
}
}
暂停后,qrtz_triggers 表的 TRIGGER_STATE = PAUSED
运行效果
http://localhost:8088/schedule/add
http://localhost:8088/schedule/pause
http://localhost:8088/schedule/restart
{"jobName":"测试","jobGroup":"DEFAULT","invokeTarget":"scheduletask.execute('VipSoft Quartz')","cronExpression":"0/10 * * * * ?","misfirePolicy":2,"concurrent":1,"status":"0"}
参考
实现方式参考:若依(RuoYi),他是新建了一张中间表,通过 init() 方法,利用中心中间表进行定时任务的初始化
/**
* 项目启动时,初始化定时器
主要是防止手动修改数据库导致未同步到定时任务处理(注:不能手动修改数据库ID和任务组名,否则会导致脏数据)
*/
@PostConstruct
public void init() throws SchedulerException, TaskException
{
scheduler.clear();
List<SysJob> jobList = jobMapper.selectJobAll();
for (SysJob job : jobList)
{
ScheduleUtils.createScheduleJob(scheduler, job);
}
}