Visual Studio Code 常见的配置、常用好用插件以及【vsCode 开发相应项目推荐安装的插件】
一、VsCode 常见的配置
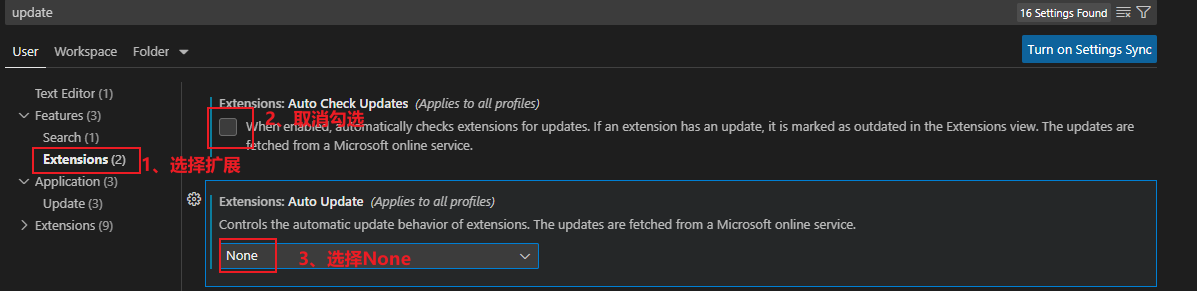
1、取消更新
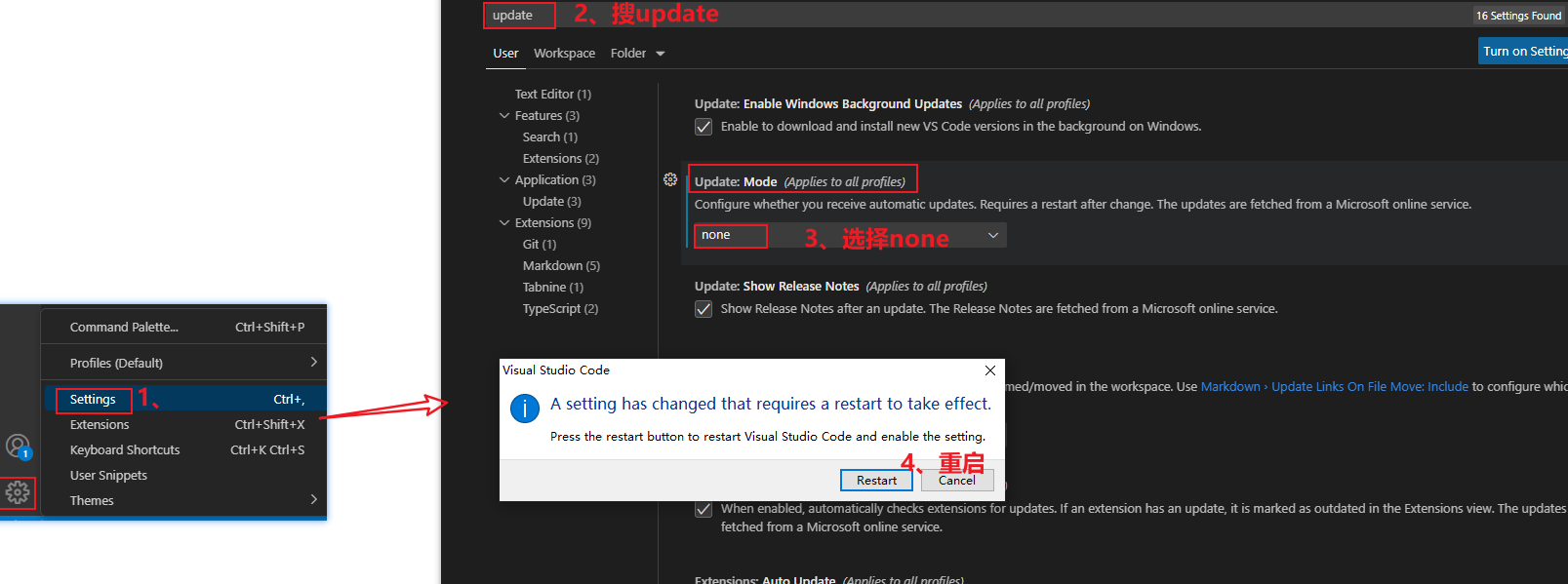
- 把插件的更新也一起取消了
2、设置编码为utf-8:默认就是了,不用设置了
3、设置常用的开发字体:Consolas, 默认就是了,不用设置了
- 字体对开发也很重要,不同字体,字母形态都不太一样,尤其是标点符号,逗号和分号的区分,有的字体看着这两者就很像
4、设置ctr+滚轮,改变字体大小
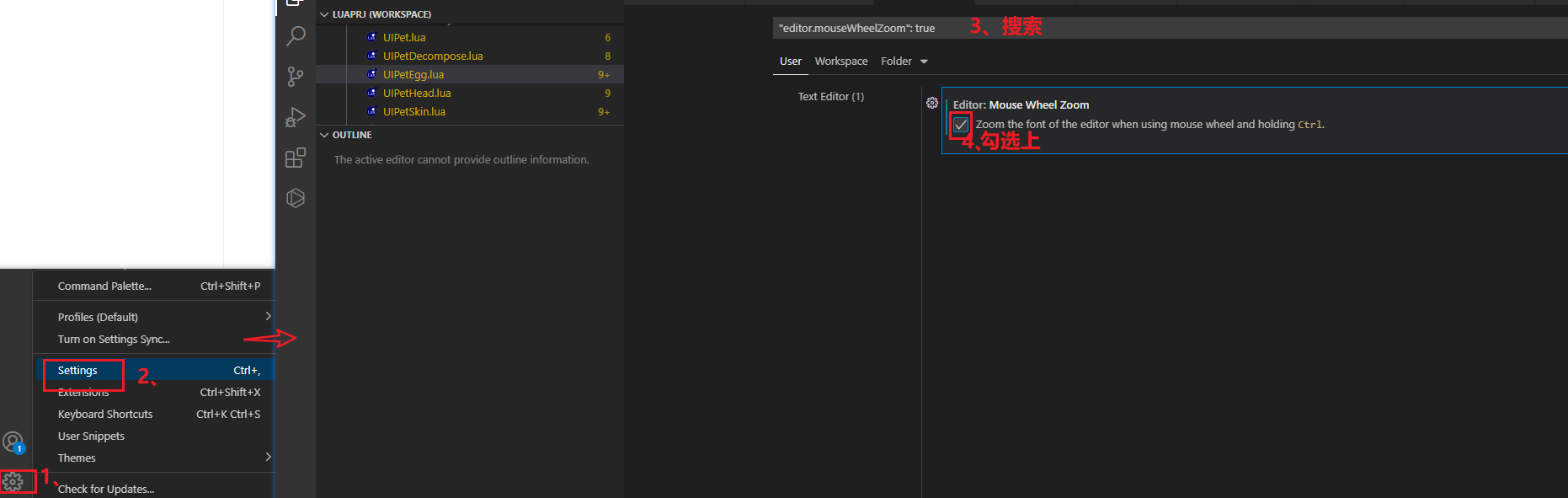
5、设置行号:默认就有,不用设置了
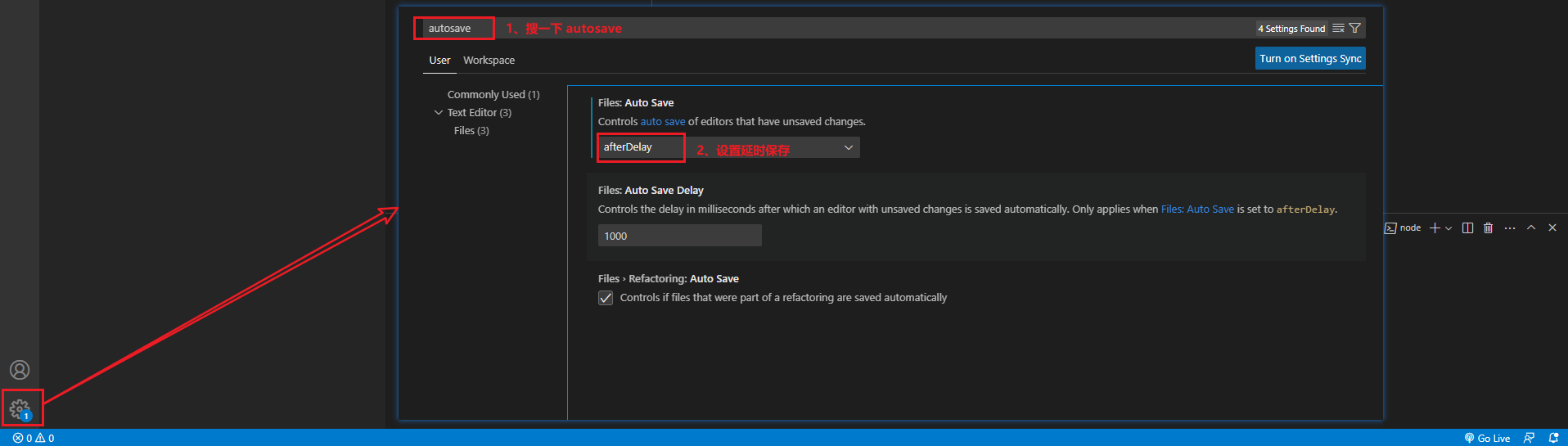
6、自动保存:
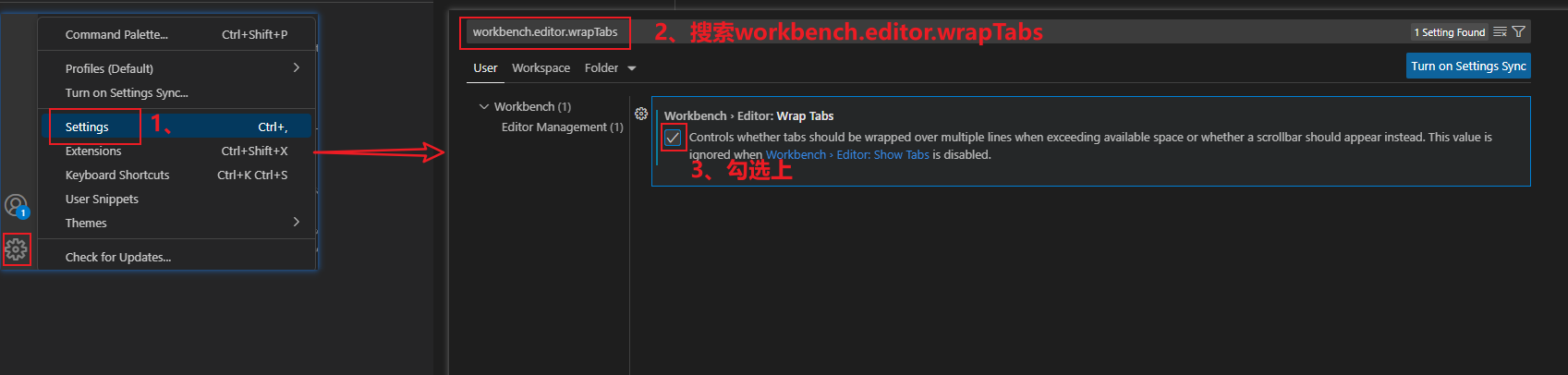
7、设置选项卡多行展示
- 这样打开了很多个文件,就不会导致有的打开的文件被隐藏
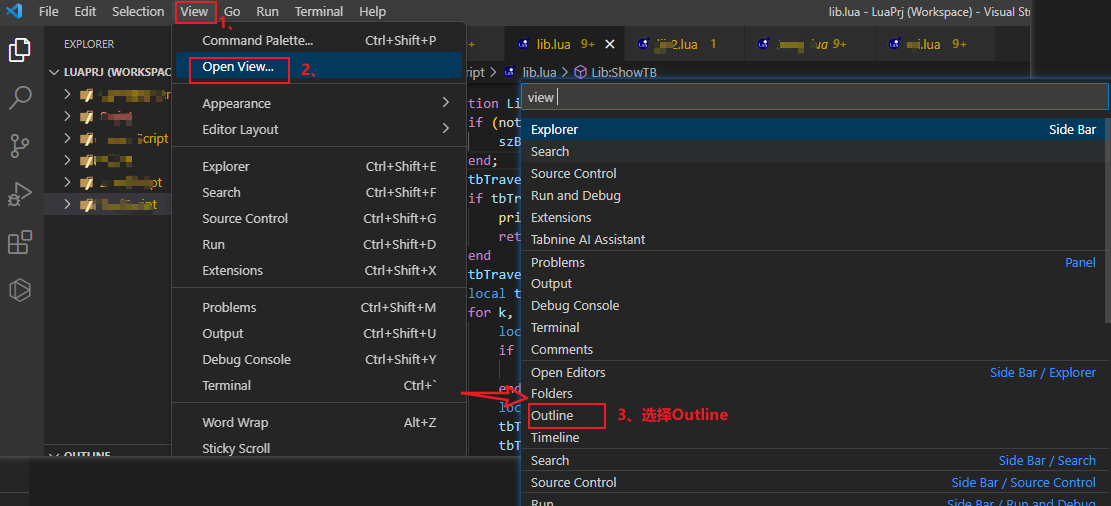
8、设置查看当前类或文件的结构 OUTLINE
- 相当于idea 查看当前类或接口的结构 Structure
二、VsCode 常用好用插件
1、实时刷新网页的插件:LiveServer

2、open in browser
支持快捷键与鼠标右键快速在浏览器中打开html文件,支持自定义打开指定的浏览器,包括:Firefox,Chrome,Opera,IE以及Safari

补充一下:LiveServer 和 open in browser 区别:注意观察浏览器地址栏
- open in browser:直接打开HTML文件就是通过File协议打开的
- LiveServer: 通过http 协议打开的,地址栏会上看到主机名, Live Server启动了一个本地开发服务器,静态和动态页面都可以实时重载。
3、自动闭合HTML/XML标签:Auto Close Tag

4、图片自动检查:Image preview

5、资源树目录:vscode-icon
它不仅能够给文件夹、文件添加上舒适的图标,而且可以自动检测项目,根据项目不同功能配上不同图标

6、AI 智能提示的插件:Tabnine
用IDE编写代码的时候可以给出智能提示,写的越多提示的越准确

选择性安装的插件
像颜色提示、主题那种,还有语法检查、语法智能提示等
本地历史代码记录: local history
git相关的插件:Git History
- Git History提供了一个可视化的git日志。不再需要在终端查看git日志。可以比较各个分支、提交和跨提交的文件。
HTML CSS Support
- 智能提示CSS类名以及id
HTML Snippets
- 智能提示HTML标签,以及标签含义
JavaScript(ES6) code snippets
- ES6语法智能提示,以及快速输入,不仅仅支持.js,还支持.ts,.jsx,.tsx,.html,.vue,省去了配置其支持各种包含js代码文件的时间
jQuery Code Snippets
- jQuery代码智能提示
CSS Peek
- 使用此插件,你可以追踪至样式表中 CSS 类和 ids 定义的地方。当你在 HTML 文件中右键单击选择器时,选择“ Go to Definition 和 Peek definition ”选项,它便会给你发送样式设置的 CSS 代码。
一、VsCode 开发相应项目推荐安装的插件
1、开发 Vue 项目必装的插件
(1)【vue2】安装一个方便阅读 vue 代码的插件:Vetur
- 安装之后,vue 代码,文本颜色开始发生变化[注释是绿色的哈哈哈],不安装,代码全是白色的。
Vetur插件介绍:功能包括-
语法高亮
,智能提示,emmet,错误提示,格式化,自动补全,debugger。vscode官方钦定Vue插件,Vue开发者必备。
- vue3 使用的是插件 Vue Language Features (Volar)

2、开发 Lua 项目必装的插件
(1) 安装一个方便阅读 lua 代码的插件:lua

如果本文对你有帮助的话记得给一乐点个赞哦,感谢!