中值滤波原理
中值滤波就是用一个奇数点的移动窗口(要求奇数主要是为了保证整个模板有唯一中心元素),将窗口中心点的值用窗口内个点的中值代替。假设窗口内有5点,其值为80、90、200、110和120,那么此窗口内各点的中值即为110。
设有一个一维序列
\(f_1,f_2,...,f_n\)
,取窗口长度(点数)为m(m为奇数),对其进行中值滤波,就是从输入序列中相机抽出m个数
\(f_{i-v},...,f_{i-1},f_i,f_{i+1},...,f_{i+v}\)
(其中
\(f_i\)
为窗口中心点值,
\(v=(m-1)/2\)
),再将这m个点按其数值大小排序,取其序号为中心点的那个数作为滤波输出。用数学公式表示为:
\[y_i=Median\{f_{i-v},...,f_{i-1},f_i,f_{i+1},...,f_{i+v}\},i\in N,v=\frac{m-1}{2}
\]
如:以3*3的领域为例求中值滤波中像素5的值。
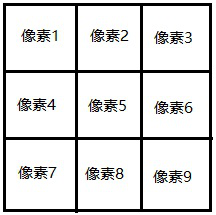
- int pixel[9]中存储像素1,像素2...像素9的值;
- 对数组pixel进行排序操作;
- 像素5的值即为数组pixel的中值pixel[4]。
代码实现
void medianFilter(cv::Mat& src, cv::Mat& dst, cv::Size size) {
/*step1:判断窗口size是否为奇数*/
if (size.width % 2 == 0 || size.height % 2 == 0) {
cout << "卷积核窗口大小应为奇数!\n";
exit(-1);
}
/*step2:对原图进行边界扩充*/
int h = (size.height - 1) / 2;
int w = (size.width - 1) / 2;
Mat src_border;
copyMakeBorder(src, src_border, h, h, w, w, BORDER_REFLECT_101);
/*step3:卷积操作*/
map<uchar, Point> mp; // 定义容器存储每个卷积窗口内各像素点的<像素值, 像素位置>
for (int i = h; i < src.rows + h; i++) {
for (int j = w; j < src.cols + w; j++) {
mp.clear();
for (int ii = i - h; ii <= i + h; ii++) {
for (int jj = j - w; jj <= j + w; jj++) {
Point point(jj, ii);
uchar value;
if (src.channels() == 1) {
// 灰度图像,存储灰度值
value = src_border.at<uchar>(ii, jj);
}else {
// 彩色图像,存储亮度值
uchar value_b = src_border.at<cv::Vec3b>(ii, jj)[0];
uchar value_g = src_border.at<cv::Vec3b>(ii, jj)[1];
uchar value_r = src_border.at<cv::Vec3b>(ii, jj)[2];
value = 0.114 * value_b + 0.587 * value_g + 0.299 * value_r;
}
mp[value] = point;
}
}
// 将窗口中心点的值用窗口内个点的中值代替
auto iter = mp.begin();
int count = 0;
Point pixel;
int median_size = mp.size() / 2;
while (iter != mp.end()) {
if (count == median_size) {
pixel = Point(iter->second.x, iter->second.y);
break;
}
count++;
iter++;
}
if (src.channels() == 1) {
dst.at<uchar>(i - h, j - w) = src_border.at<uchar>(pixel.y, pixel.x);
}
else {
dst.at<cv::Vec3b>(i - h, j - w)[0] = src_border.at<cv::Vec3b>(pixel.y, pixel.x)[0];
dst.at<cv::Vec3b>(i - h, j - w)[1] = src_border.at<cv::Vec3b>(pixel.y, pixel.x)[1];
dst.at<cv::Vec3b>(i - h, j - w)[2] = src_border.at<cv::Vec3b>(pixel.y, pixel.x)[2];
}
}
}
}
代码讲解
copyMakeBorder(src,src_border,h,h,w,w,BORDER_REFLECT_101);
在模板或卷积的加权运算中的图像边界问题:当在图像上移动模板(卷积核)至图像边界时,在原图像中找不到与卷积核中的加权系数相对应的N个像素(N为卷积核元素个数),即卷积核悬挂在图像的边界上,这种现象在图像的上下左右四个边界上均会出现。例如,当模板为:
\[\frac{1}{9}
\begin{bmatrix} %该矩阵一共3列,每一列都居中放置
1 & 1 & 1\\ %第一行元素
1 & 1 & 1\\ %第二行元素
1 & 1 & 1\\ %第二行元素
\end{bmatrix}
\]
设原图像为:
\[\begin{bmatrix} %该矩阵一共3列,每一列都居中放置
1 & 1 & 1 & 1 & 1\\ %第1行元素
2 & 2 & 2 & 2 & 2\\ %第2行元素
3 & 3 & 3 & 3 & 3\\ %第3行元素
4 & 4 & 4 & 4 & 4\\ %第3行元素
\end{bmatrix}
\]
经过卷积操作之后图像为:
\[\begin{bmatrix} %该矩阵一共3列,每一列都居中放置
- & - & - & - & -\\ %第1行元素
- & 2 & 2 & 2 & -\\ %第2行元素
- & 3 & 3 & 3 & -\\ %第3行元素
- & - & - & - & -\\ %第3行元素
\end{bmatrix}
\]
"-"表示无法进行卷积操作的像素点。
解决方法有2种:①忽略图像边界数据(即不管边界,卷积操作的范围从整张图缩小为边界内缩N圈,N的值随卷积核尺寸变化)。②将原图像往外扩充像素,如在图像四周复制源图像边界的值,从而使得卷积核悬挂在原图像四周时也就而已正常进行正常的计算。
opencv边框处理copyMakeBorder:
https://zhuanlan.zhihu.com/p/108408180
value=0.114*value_b+0.587*value_g+0.299*value_r;
对于彩色图像,我们取图像亮度的中间值,亮度值的计算方法为:
\[luminance = 0.299R + 0.587G + 0.114B
\]
map<uchar, Point> mp;
map为C++的stl中的关联性容器,为了实现快速查找,map内部本身就是按序存储的(map底层实现是红黑二叉树)。在我们插入<key, value>键值对时,就会按照key的大小顺序进行存储,其中key的类型必须能够进行 < 运算,且唯一,默认排序是按照从小到大便利记忆联想到需要支持小于运算。
因此,将亮度值或灰度值作为键,map将自动进行按键排序,无需手动书写排序代码。
实现效果
卷积核size为(5, 5)。




















