代码混淆与反混淆学习-第二弹
deflat 脚本学习【去除OLLVM混淆】
deflat脚本链接:
GitHub - cq674350529/deflat: use angr to deobfuscation
deflat 脚本测试
这里以
代码混淆与反混淆学习-第一弹
中的OLLVM 混淆样本为例进行去除。【LLVM-4.0】
| 控制流平坦前 | 控制流平坦后 |
|---|---|
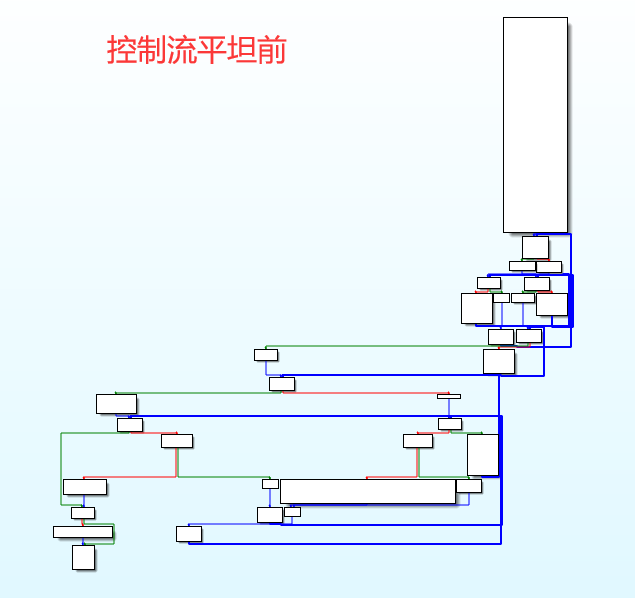 |
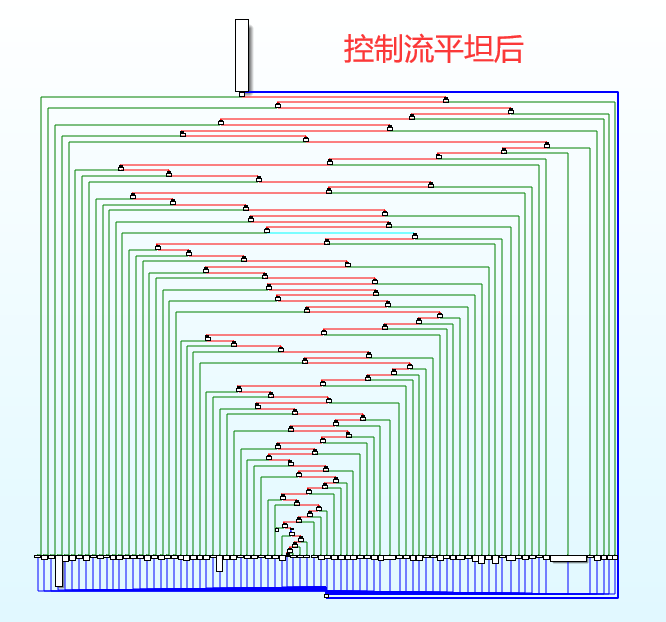 |
python deflat.py --file main-bcf --addr 0x401180
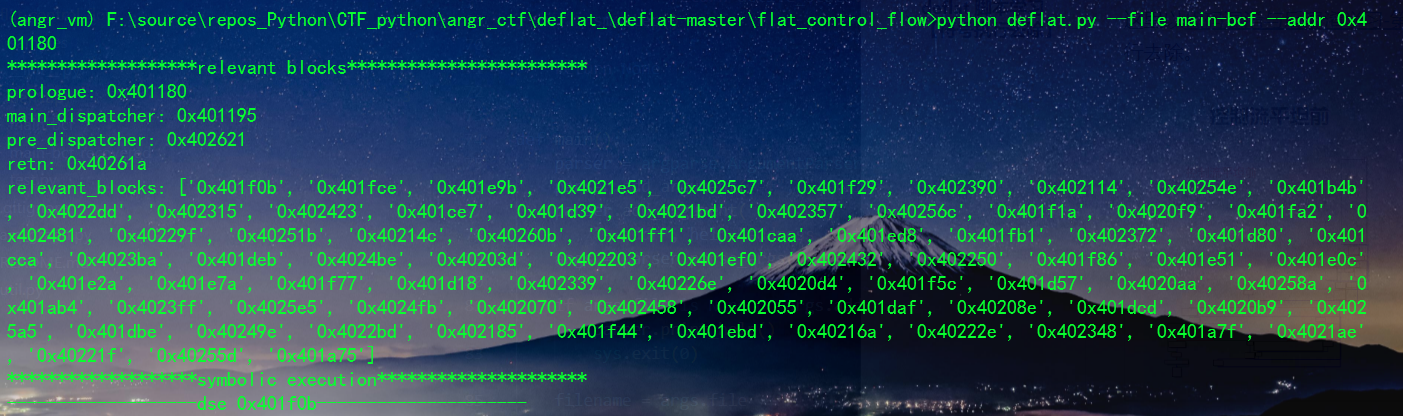

deflat.py 成功去除后效果:

|
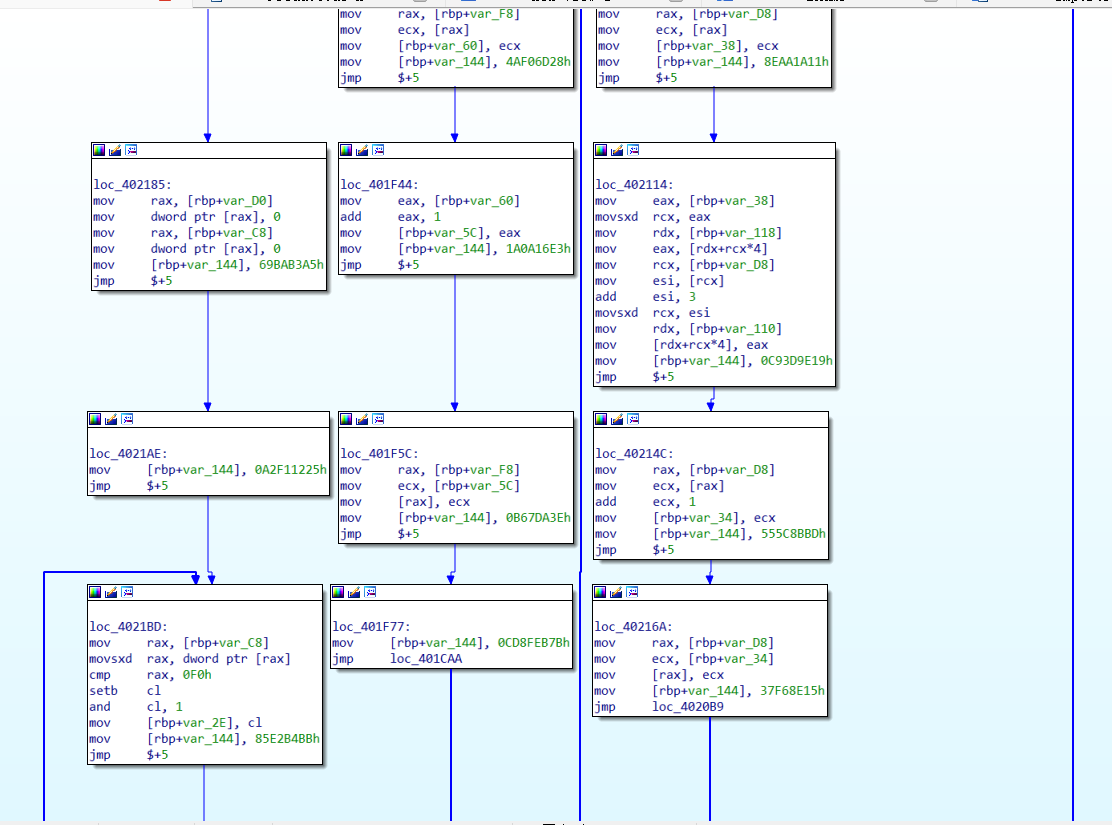
|
|---|
去混淆后,效果还算可以,能分析程序流程了。
deflat 脚本分析【angr】
利用符号执行去除控制流平坦化 - 博客 - 腾讯安全应急响应中心 (tencent.com)
利用angr符号执行去除控制流平坦化 - 0x401RevTrain-Tools (bluesadi.github.io)
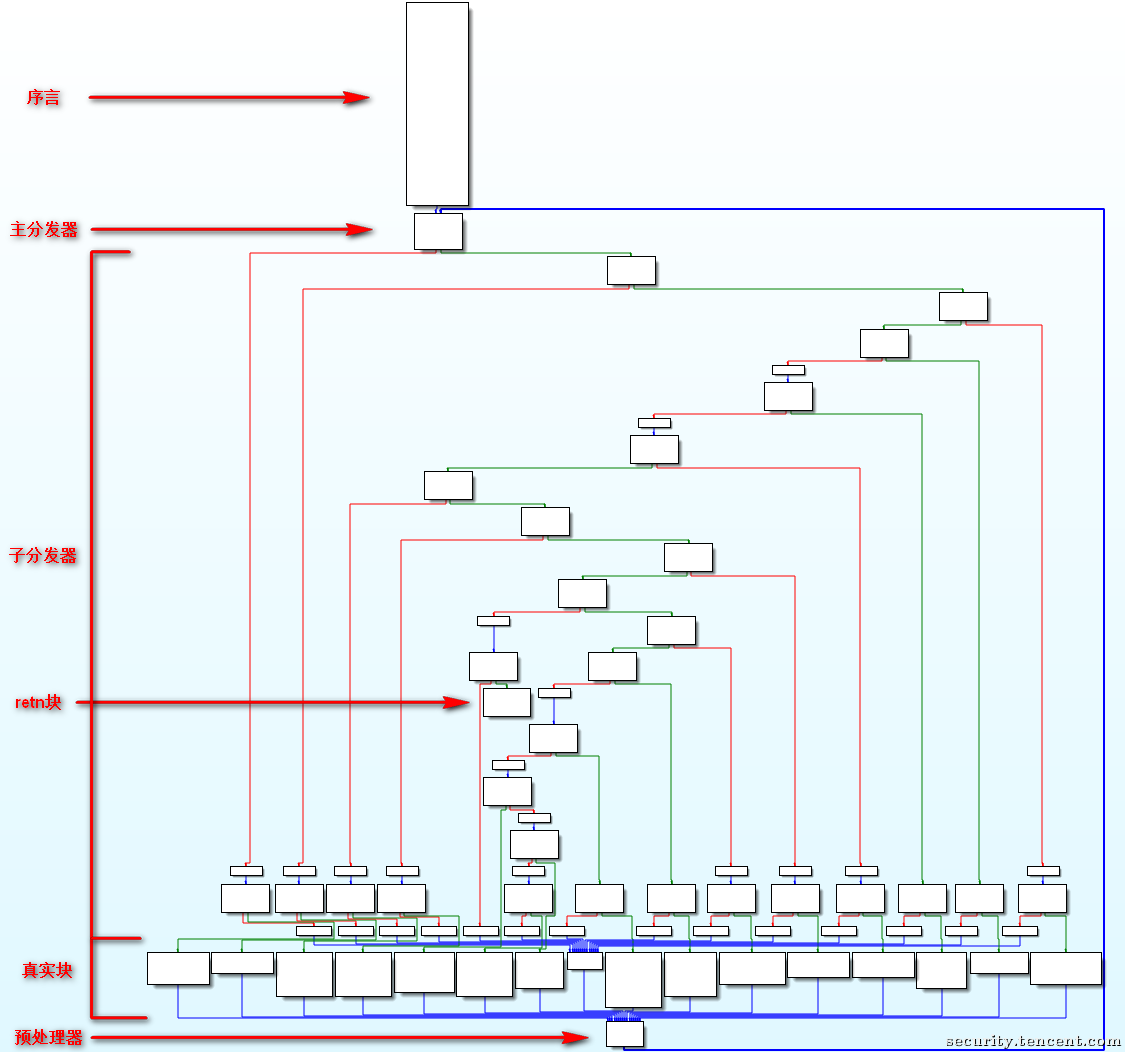
- 序言:函数的第一个执行的基本块
- 主(子)分发器:控制程序跳转到下一个待执行的基本块
- retn块:函数出口
- 真实块:混淆前的基本块,程序真正执行工作的版块
- 预处理器:跳转到主分发器
如第一弹中分析:OLLVM 的控制流平坦化是将程序的一般逻辑划分为很多个真实执行的块,然后通过分发器进行链接。其实就是一个Switch结构,每次执行完真实块后,进行预处理,再跳转到主分发器,继续分发,最终达到平坦化的效果。
显然,
去控制流平坦化
就是要找到真实块间的跳转逻辑,打破Switch结构束缚。
具体来说,有如下步骤:
- 静态分析CFG得到序言/入口块、主分发器、子分发器/无用块、真实块、预分发器和返回块。
- 利用符号执行恢复真实块的前后关系,重建控制流
- 根据第二步重建的控制流Patch程序,输出恢复后的可执行文件
静态分析
首先明确:
【以下结论针对OLLVM项目,其他大佬加料的OLLVM混淆还需要单独分析】
- 函数的开始地址为序言的地址
- 序言的后继为主分发器
- 后继为主分发器的块为预处理器
- 后继为预处理器的块为真实块
- 无后继的块为retn块
- 剩下的为无用块
angr 获取类似Ida的 CFG
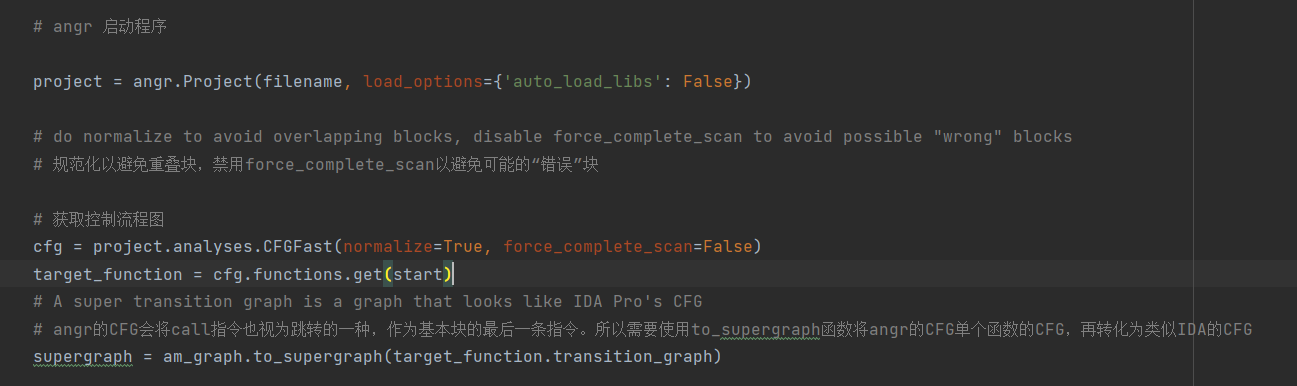
获取真实块、主分发器、预处理器、序言、retn块和无用块
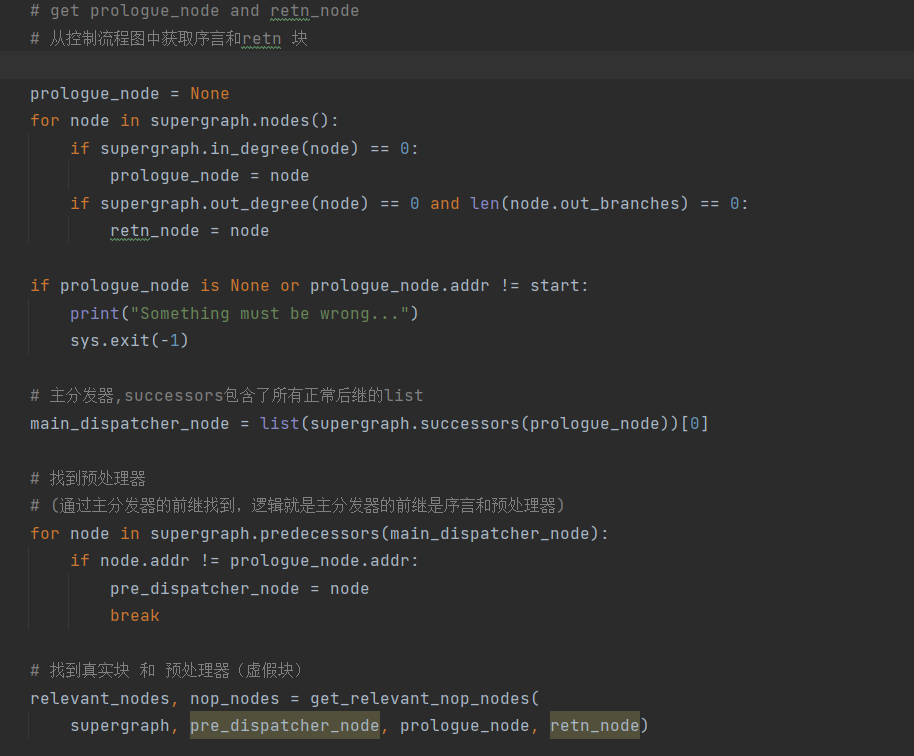
获取真实块的细节
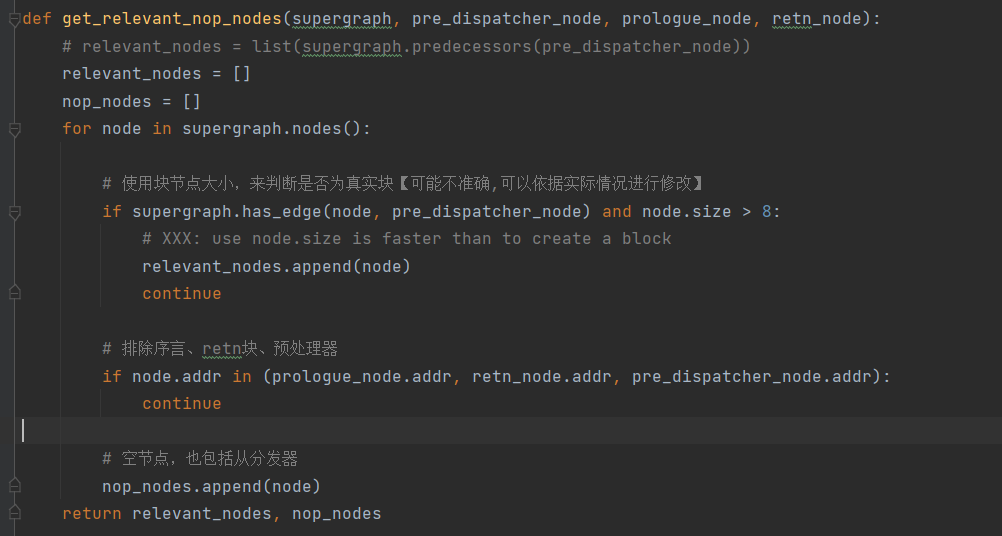
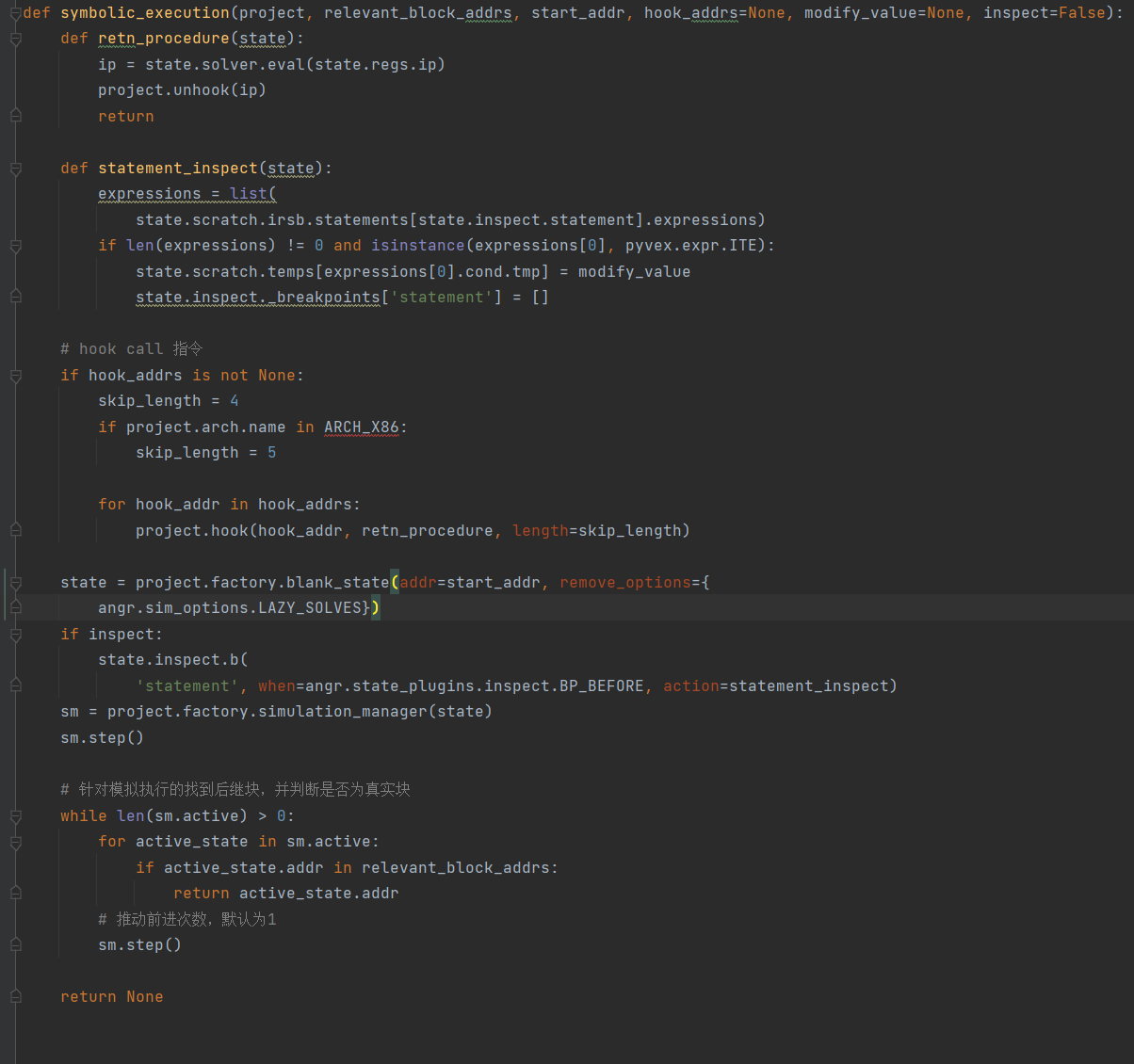
angr 恢复真实块执行逻辑,重建控制流
利用angr 强大的符号执行功能,找到各真实块的连接逻辑。
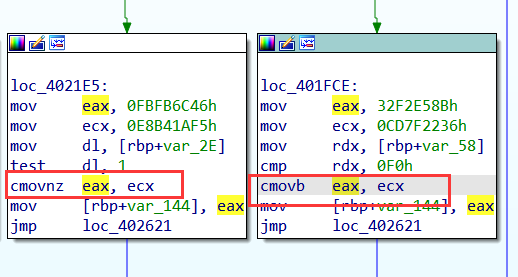
这里对于两个分支的模拟执行,只需关注
cmov
指令,就可以分别对应得到eax、ecx,然后获得后续真实块。【局限性很大】
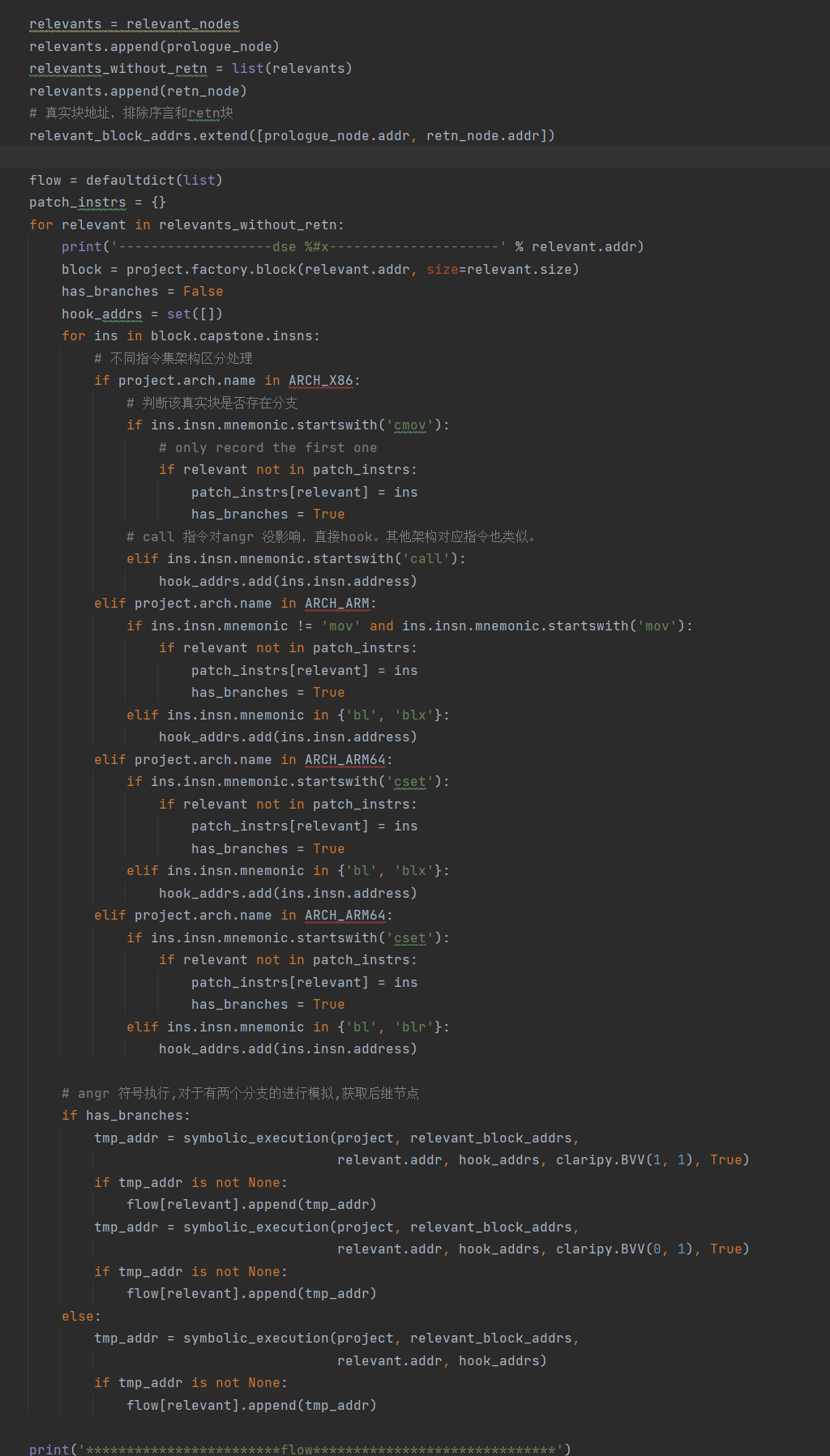
符号执行
symbolic_execution()
函数,返回后继真实块。
Patch程序恢复执行逻辑
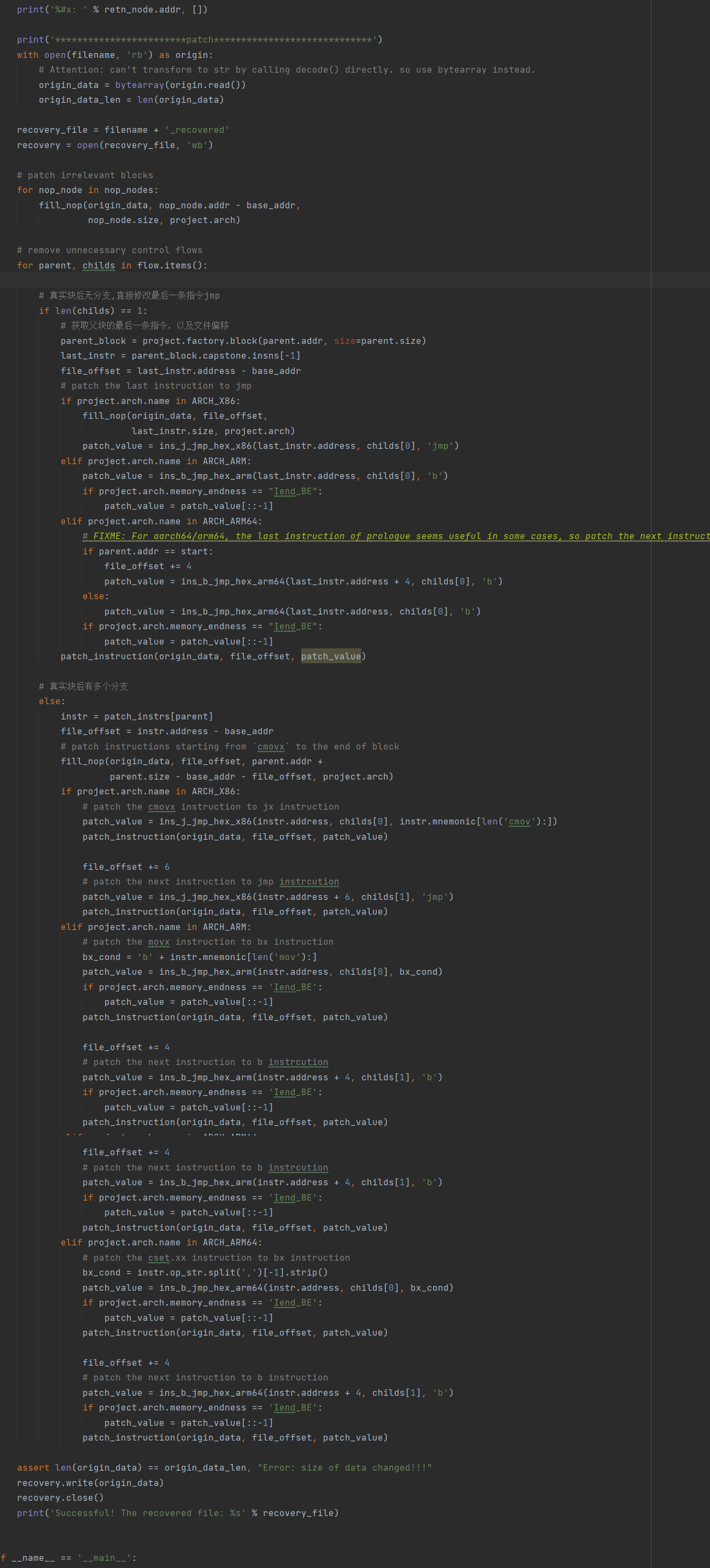
如此便完成了 deflat脚本的简单处理分析。
小结
分析下来,其实就是定位到所有真实块,然后
利用angr符号执行将真实块间的执行逻辑进行串联
。最后进行patch程序,重建控制流。
但显然存在一些问题,我们默认了如下规则:
- 函数的开始地址为序言的地址
- 序言的后继为主分发器
- 后继为主分发器的块为预处理器
- 后继为预处理器的块为真实块
- 无后继的块为retn块
- 剩下的为无用块
但是在实际去除控制流平坦化过程中,上面的默认思路已经被加混淆的开发者做了处理。
例如:
- 后继为预处理器的块不一定是真实块;
- 预处理器不一定存在;
- 存在分支的真实块跳转的判断逻辑,不一定是
cmov
指令; - deflat脚本默认模拟执行最多两个分支,但真实情况可能不只两个分支;
- 可能存在一个
向前更新的数组,依据程序运行进行更新
,决定当前真实块的跳转【这导致
angr对于该块的模拟执行
得不到正确的跳转】 - 程序在加混淆前,已经被添加了花指令或其他处理,
程序CFG图
已经被打破; - 某个块存在死循环,会使angr符号执行卡死……
这也导致了,这个
deflat脚本的普适性较低
,除了能够处理OLLVM官方项目做的混淆,对加了其他PASS或者处理的混淆,基本用不了。
所以对于去除不了的OLLVM混淆,我们需要
根据程序的实际混淆效果,对deflat脚本进行修改
,再进行去混淆。
【这也要求对deflat 脚本比较熟悉,可以更快上手】
失败的花指令控制流平坦化尝试
使用
代码混淆与反混淆学习-第一弹
中加了花指令的程序,进行OLLVM控制流平坦化混淆,看看效果。
源代码如下:
# clang 执行内联汇编加 -fasm-blocks 或者 -fms-extensions 或者 -masm=intel
clang -mllvm -fla -mllvm -split -mllvm -split_num=3 main-call-加花.cpp -lm -fasm-blocks -o main-call-加花
# 需要对源代码作一些修改
存在较大的问题,我的OLLVM 环境是在Ubuntu上搭建的,对于上述内联汇编加的花指令无法编译通过!
【或许可以在
Windows 上移植OLLVM,进行编译(好像挺难的)
】
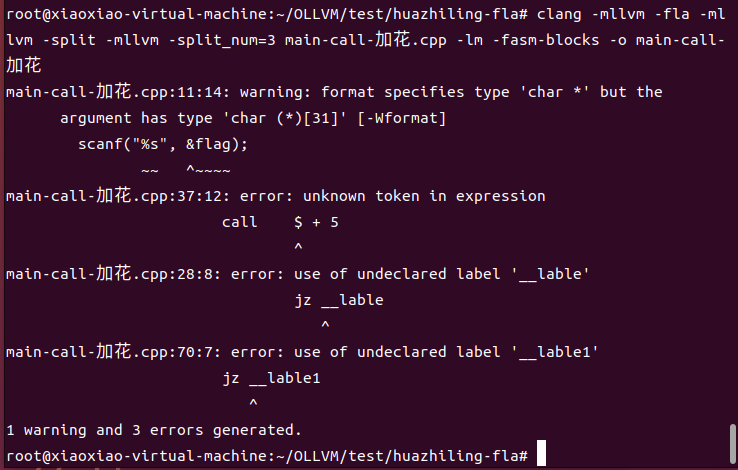
可以看到,花指令用到的标签、$ 出现报错。
【最终也没解决编译问题,或许本就不可以,ollvm 不具备这样的处理能力,也可能是我代码的问题,
如果博客前的你有任何想法,欢迎与我交流
】
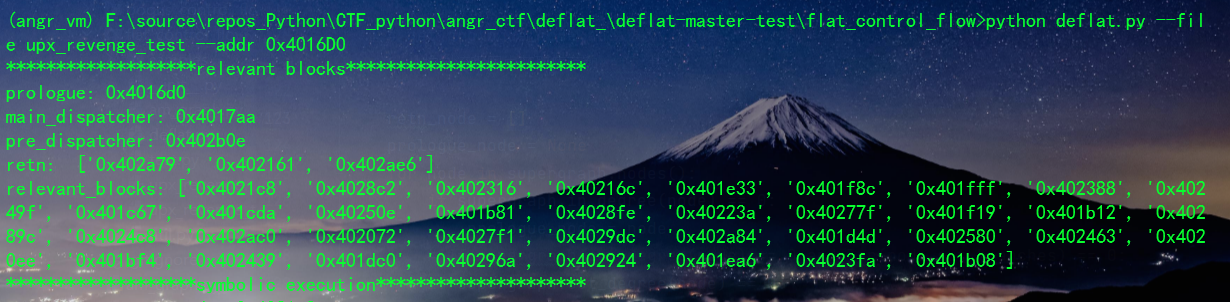
TSCTF-J 2022-upx_revenge实战分析
对
upx_revenge
题目进行分析。
首先直接使用deflat 脚本。
python deflat.py --file upx_revenge_test --addr 0x4016D0

发现没有找到retn 块。
处理多个retn块
回到ida 查看cfg 图发现原因:存在其他的退出块。
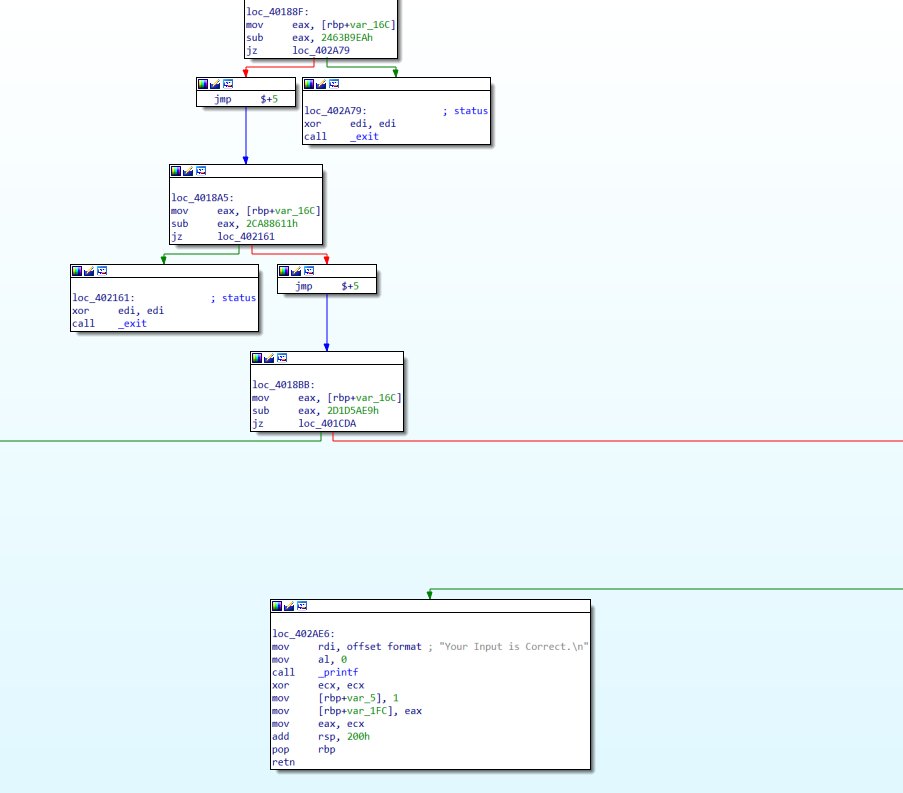
这里需要改进deflat 脚本,使其存在很多retn块。
# 其他位置的retn_node,对应改为list处理
if supergraph.out_degree(node) == 0:
retn_node.append(node)
成功运行,但是去除效果不行。
| 去除后CFG图 |
|---|
 |
多个comv的处理
很明显看出,程序的真实块间的逻辑串联失败,也就是重建控制流失败。
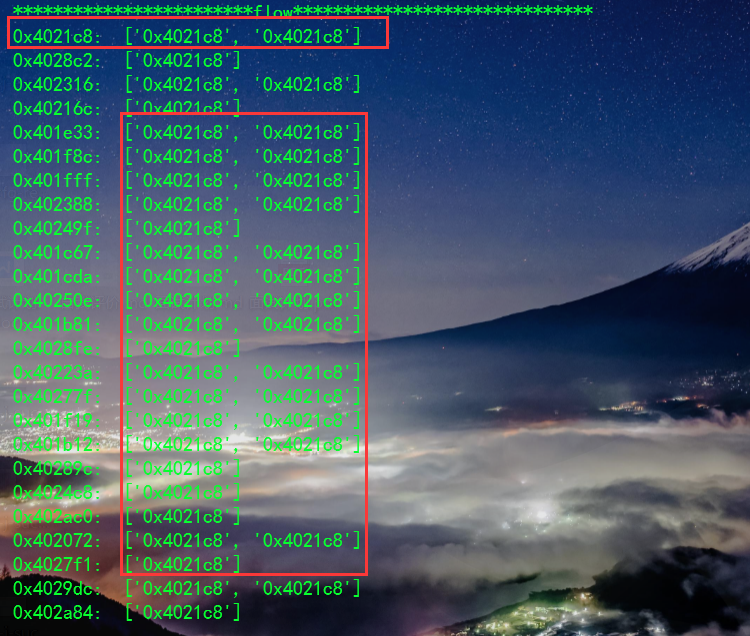
产生原因
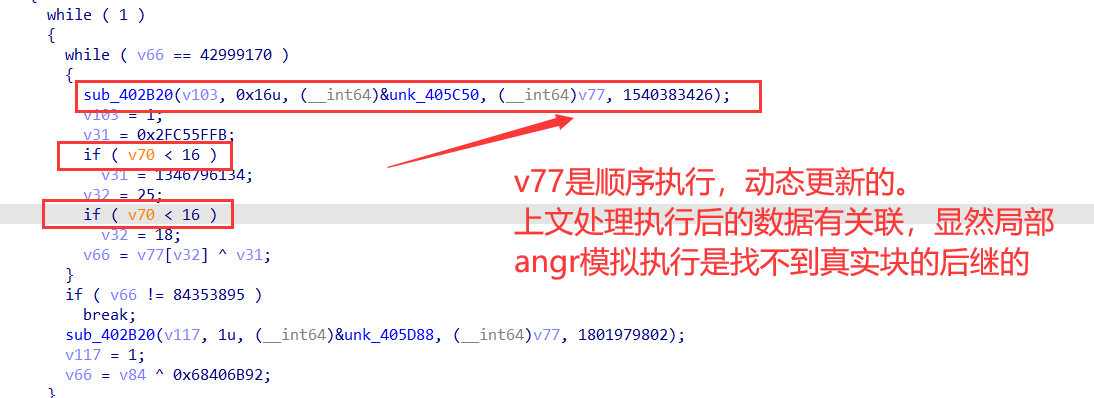
|
|---|
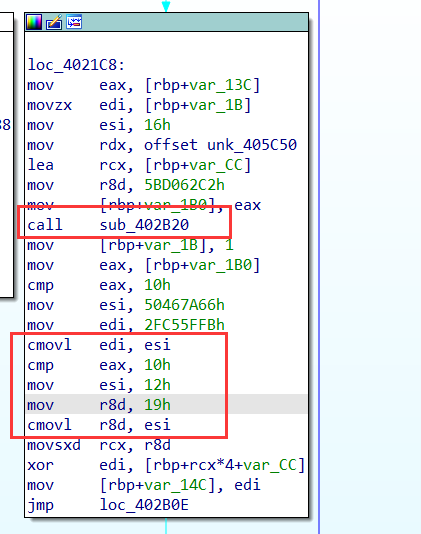 |
显然,这里存在2个分支,因为有两个
cmov
【相同判断】,并且call 函数,对分支跳转是有作用的,这里var_CC是顺序执行,动态更新的。
【deflat 脚本只处理了执行有一个
cmov
指令的情况,且hook了call函数】
【由于var_CC是顺序执行,动态更新也可以看出,deflat 脚本的模拟执行思路已经无法对真实块的后继进行确定了】
但这里做个测试,不hook call 看是什么效果。
可以知道,取消hook call 对真实块后继的查找毫无影响,这是因为deflat中的模拟执行,只是基于
comv
处的模拟。对前文并无任何关联。
显然,该deflat脚本的无法处理了。【】
总结
angr
就
upx_revenge
这道题而言,
deflat 脚本中angr 对局部的模拟执行显然无法获取真实块间的执行顺序,重建控制流显然也无从谈起。当然静态查找各个控制流平坦化的功能块效果还是可以的。
那么如何通过angr,有序的、联系上文地进行模拟执行,获取真实块的执行逻辑,显然是关键点!
【??? 后续学习了,有思路再更新】
unicorn
[
原创]ARM64 OLLVM反混淆-Android安全-看雪论坛-安全社区|安全招聘|bbs.pediy.com (kanxue.com)
Unicorn反混淆:恢复被OLLVM保护的程序(一) - 简书 (jianshu.com)
使用unicorn 模拟执行框架获取真实块间的执行顺序,重建控制流。
【还没学过 unicorn 使用,,,】
ida
使用IDA microcode去除ollvm混淆(上) - 先知社区 (aliyun.com)
GitHub - PShocker/de-ollvm: IDA Python Script for anti ollvm
利用ida 现成的CFG 图,以及idc 脚本,动态运行程序,获取真实块的执行顺序,从而恢复控制流。