JS引擎(2):Java平台上JavaScript引擎—Rhino/Nashorn概述
可以后端开发的 javascript引擎有
Chrome V8 基于C++
java的Rhino引擎(JDK6被植入),Java8 被替换为Nashorn
Rhino和Nashorn都是用Java实现的JavaScript引擎。它们自身都是普通的Java程序,运行在JVM上
Rhino简介
Rhino [ˈraɪnəʊ]是一种使用 Java 语言编写的 JavaScript 的开源实现,原先由Mozilla开发。
Rhino 是一种动态类型的、基于对象的脚本语言,它可以简单地访问各种 Java 类库。
当时Netscape想用纯Java来实现新版浏览器,自然需要一个Java版的JavaScript引擎实现;另外也希望能在服务器端把JavaScript当作Java应用里的脚本语言使用。于是Rhino就诞生了。
官网自带
Rhino历史
,跟
Wikipedia上的Rhino词条
基本上一样,有兴趣的话可以去看看。
Parser
是从SpiderMonkey移植过来的。自然也是手写的纯递归下降式。
JavaScript对象的接口是org.mozilla.javascript.Scriptable。主要实现类是IdScriptableObject、ScriptableObject。用Object[]来存字段,挺高效的。
IdScriptableObject {
Object[] valueArray;
short[] attributeArray;
// ...
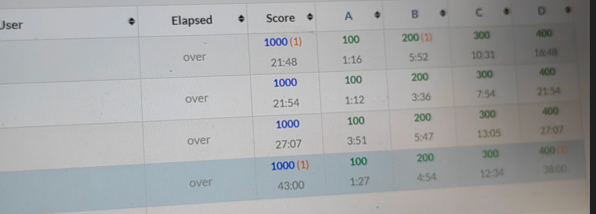
}Rhino可以通过参数从11个预设的优化基本中选择一个使用。只从JVM以上的层面看,Rhino既可以工作于纯解释模式(-1),也可以工作于纯编译模式(0-9)。
这11个级别分别是
:
Rhino 优化级别
当优化级别为-1时,
Rhino使用一个用Java写的字节码解释器来解释执行JavaScrip
t。
此时,Rhino的工作流程简单说是:( [ ... ]表示数据实体,( ... )表示Rhino处理数据的程序)
[ JavaScript源码 ] -> ( 语法分析器
Parser
) -> [ 抽象语法树(AST)
ast
] -> ( Rhino内部表现形式生成器
IRFactory
) -> [ Rhino内部表现形式
ScriptNode
] -> ( Rhino字节码生成器
CodeGenerator
) -> [ Rhino字节码
Icode
] -> ( Rhino解释器
Interpreter
) -> [ 运行结果 ]
这里说的Rhino字节码是Rhino内部用来表示JavaScript程序语义的一套字节码,跟JVM所支持的Java字节码没关系。
当优化级别为0~9时,Rhino使用一个用Java写的编译器将JavaScript编译为Java字节码;生成出来的Java字节码交由JVM直接执行
。至于底下的JVM是解释执行Java字节码,还是将Java字节码编译为机器码再执行,Rhino并不关心。
此时,Rhino的工作流程简单说是:
[ JavaScript源码 ] -> ( 语法分析器
Parser
) -> [ 抽象语法树(AST)
ast
] -> ( Rhino内部表现形式生成器
IRFactory
) -> [ Rhino内部表现形式
ScriptNode
] -> ( 可选优化
Optimizer
) -> ( Java字节码生成器
Codegen
) -> [ Java Class文件(包含Java字节码) ] -> JVM加载和执行生成的字节码 -> [ 运行结果 ]
只从JVM以上的层面看,Nashorn是一种单层的纯编译型JavaScript实现。所有JavaScript代码在首次实际执行前都会被编译为Java字节码交由JVM执行。
这种以编译的方式模式执行JavaScript,跟一个Java源码编译器(例如javac)把Java源码编译为Class文件然后交由JVM执行,过程是类似的。只不过Rhino做的优化不够多而且JavaScript的语义也远比Java动态,所以此时Rhino上运行JavaScript的性能仍然无法跟Java的性能比。
JDK6 JDK7 Rhino区别
顺带一提,Sun/Oracle JDK6 / OpenJDK6中自带的Rhino是经过裁剪的,去掉了Mozilla Rhino中的部分功能。其中一个被去掉的功能就是Rhino的编译模式。这意味着JDK6自带的Rhino只能用解释模式运行。
而Oracle JDK7 / OpenJDK7放宽了这一限制,当有SecurityManager时只能用解释模式,否则可以配置"rhino.opt.level"系统属性来设置Rhino的优化级别;默认仍然是用解释模式(优化级别默认为-1)。
Nashorn起初是Oracle内部一个实验项目,用于验证JSR 292功能的完整性、可用性、易用性。后来得到了内部的关注,决定将其产品化,作为默认的JavaScript实现替换掉从JDK6开始包含在JDK之中的Rhino。
Nashorn
Nashorn(读作Naz-horn[naːsˌɔn])是Oracle全新开发的JavaScript实现。高度兼容ECMAScript 5标准,并尽可能兼容Rhino。
它使用Java语言实现,运行在JVM上,借助JDK7开始包含的
JSR 292(invokedynamic)
新功能达到较高的性能
,同时保持代码的相对整洁
在2012年底Nashorn就已经达到可以完全通过
test262
测试套件的兼容性,就这点说它甚至比SpiderMonkey、V8更佳兼容于标准。
邮件列表:
http://mail.openjdk.java.net/mailman/listinfo/nashorn-dev兼容标准: ECMAScript 5.1
实现语言: Java
代码版本控制工具: Mercurial
开源许可证: GPLv2
Nashorn是一个纯编译的JavaScript引擎
。它没有用Java实现的JavaScript解释器,而只有把JavaScript编译为Java字节码再交由JVM执行这一种流程,跟Rhino的编译流程类似
。
Nashorn还在快速开发中,日新月异,所以它的工作流程在不断变化。简单来说,Nashorn的编译入口可以从Context.compile()开始看:
[ JavaScript源码 ] -> ( 语法分析器 Parser ) -> [ 抽象语法树(AST) ir ] -> ( 编译优化 Compiler ) -> [ 优化后的AST + Java Class文件(包含Java字节码) ] -> JVM加载和执行生成的字节码 -> [ 运行结果 ]
只从JVM以上的层面看,Nashorn是一种单层的纯编译型JavaScript实现。所有JavaScript代码在首次实际执行前都会被编译为Java字节码交由JVM执行。
(当然JVM自身可能是混合执行模式的,例如HotSpot VM与J9 VM。所以Nashorn在实际运行中可能需要一定预热才会达到最高速度)
Nashorn不但可以执行JavaScript,还可以当作库为其它工具提供一些基础服务。例如说
它现在为NetBeans IDE中的JavaScript编辑器提供语法高亮支持和调试支持
。
从Oracle JDK 8 build 82开始,Nashorn已经作为JDK8的一部分包含在安装包中。安装后可以在JDK安装目录的jre/lib/ext/nashorn.jar找到Nashorn的实现。
直接使用Java类的实例来容纳JavaScript对象的字段,在对象内嵌入字段而不放在spill array里的好处是:
对象更加紧凑,数据离得更近,局部性更好
数组访问有边界检查,而对象字段访问则没有,后者效率更高
参考内容:
Rhino 和 Nashorn 到底怎么运行? - RednaxelaFX的回答 - 知乎 https://www.zhihu.com/question/27631001/answer/37407481
各JavaScript引擎的简介,及相关资料/博客收集帖 https://hllvm-group.iteye.com/group/topic/37596
转载
本站
文章《
JS引擎(2):Java平台上JavaScript引擎—Rhino/Nashorn概述
》,
请注明出处:
https://www.zhoulujun.cn/html/webfront/browser/webkit/2020_0718_8520.html