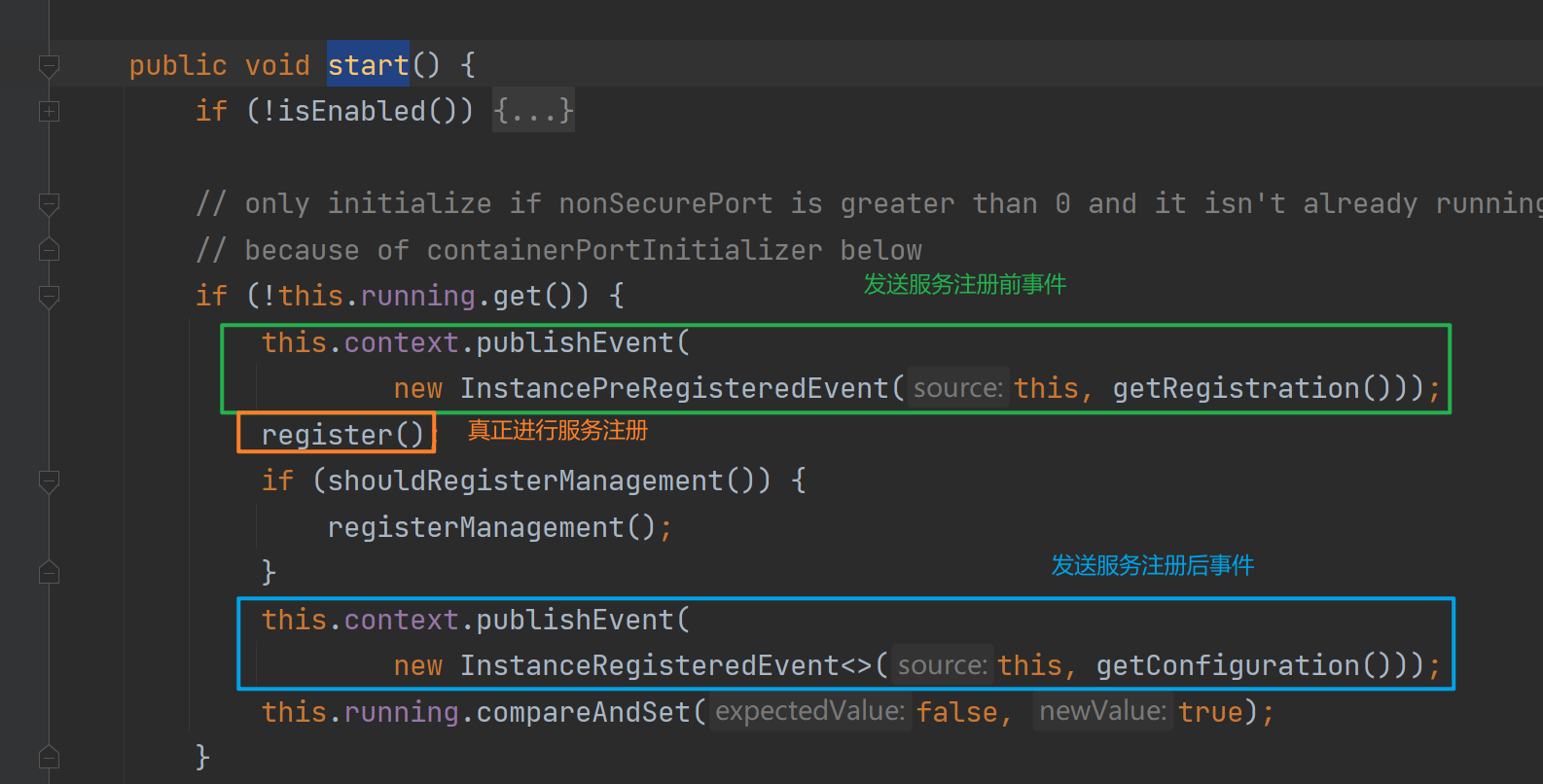
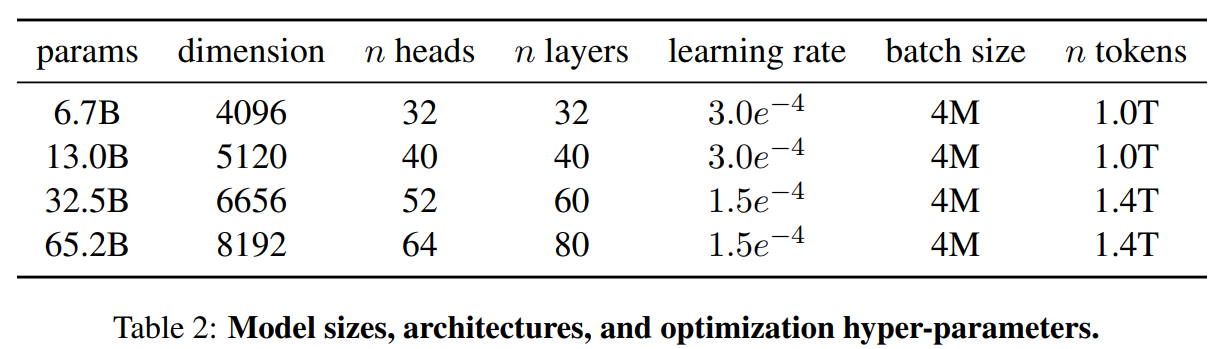
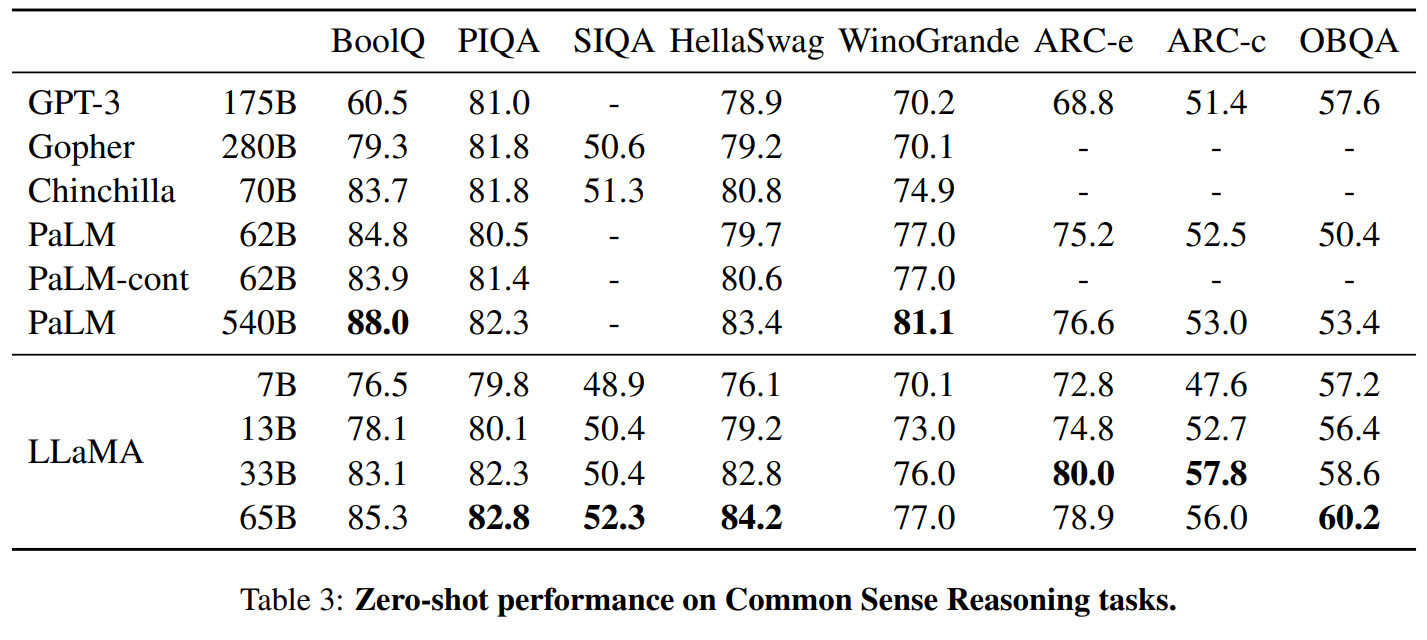
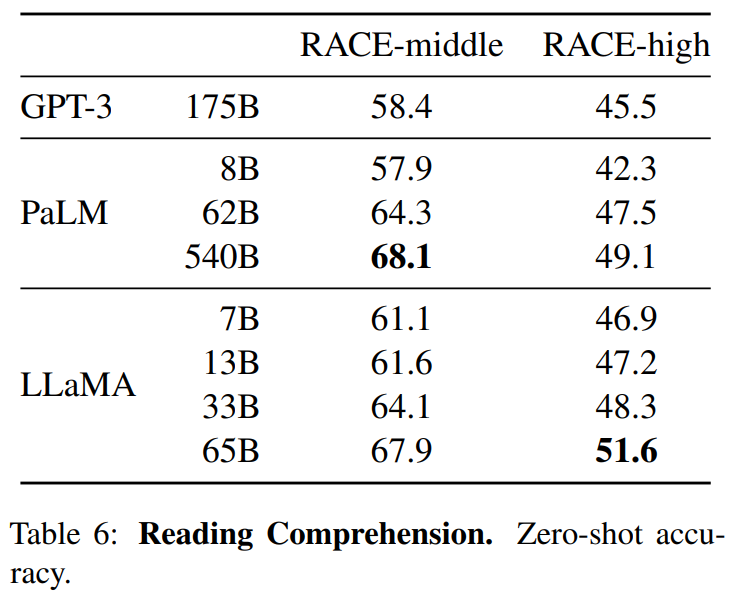
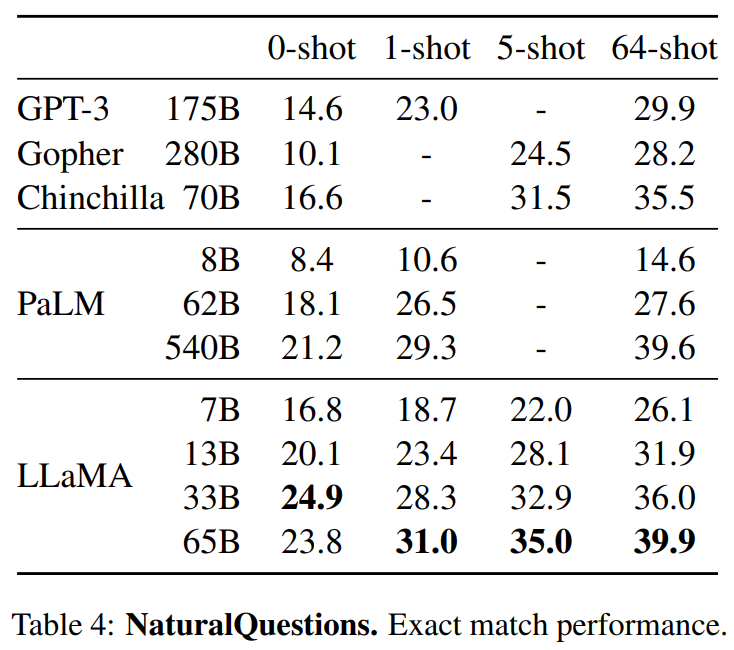
[MAUI 项目实战] 手势控制音乐播放器(二): 手势交互
@
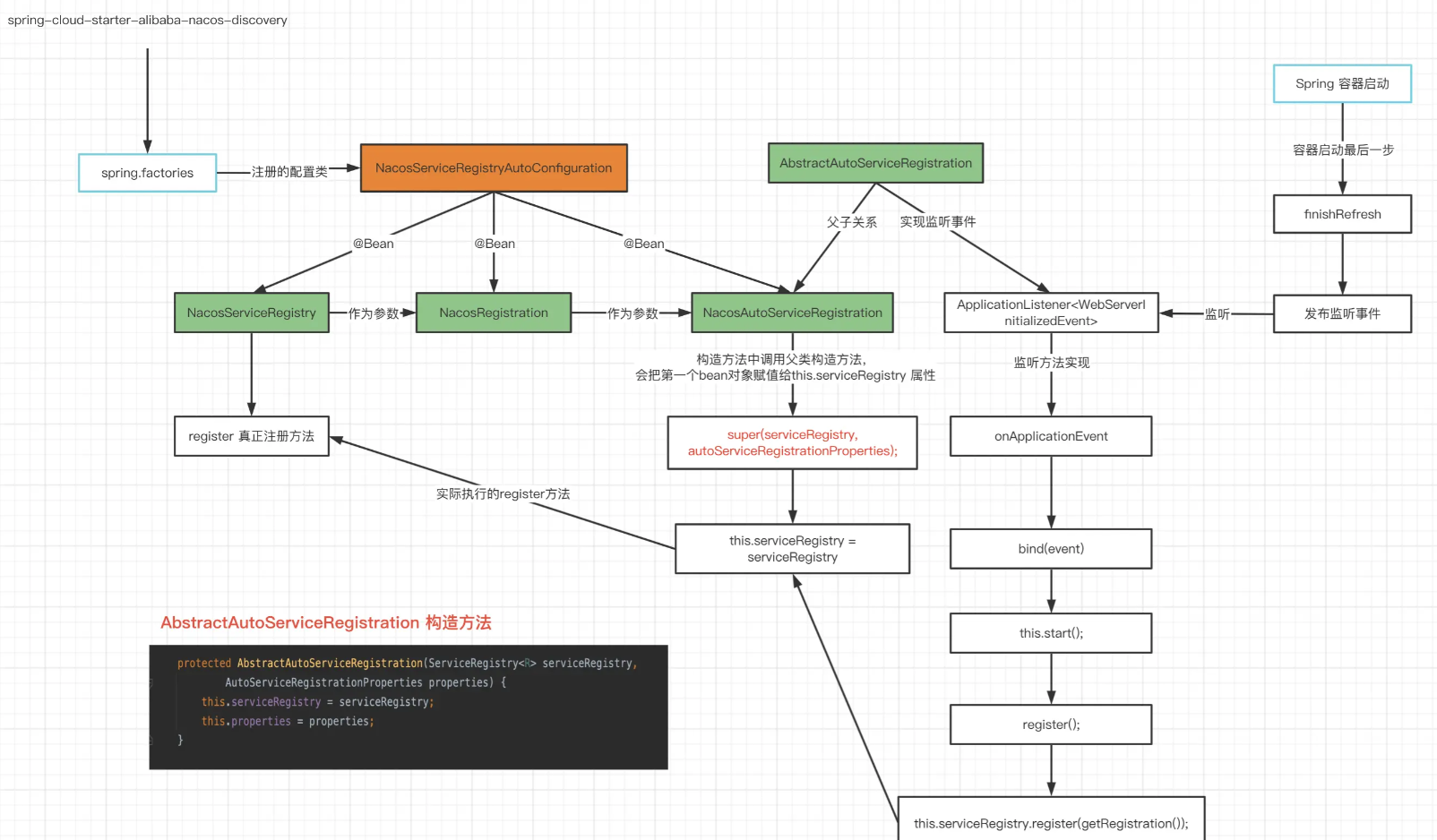
原理
定义一个拖拽物,和它拖拽的目标,拖拽物可以理解为一个平底锅(pan),拖拽目标是一个坑(pit),当拖拽物进入坑时,拖拽物就会被吸附在坑里。可以脑补一下下图:

你问我为什么是平底锅和坑,当然了在微软官方的写法里pan是平移的意思,而不是指代平底锅。只是通过同义词来方便理解
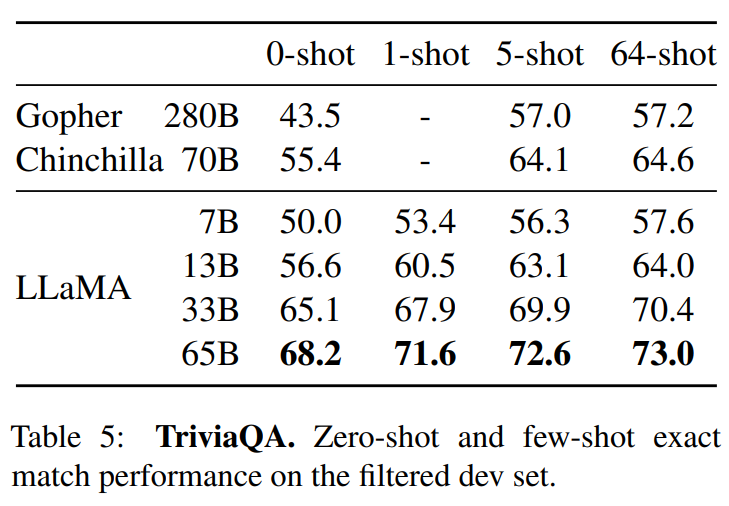
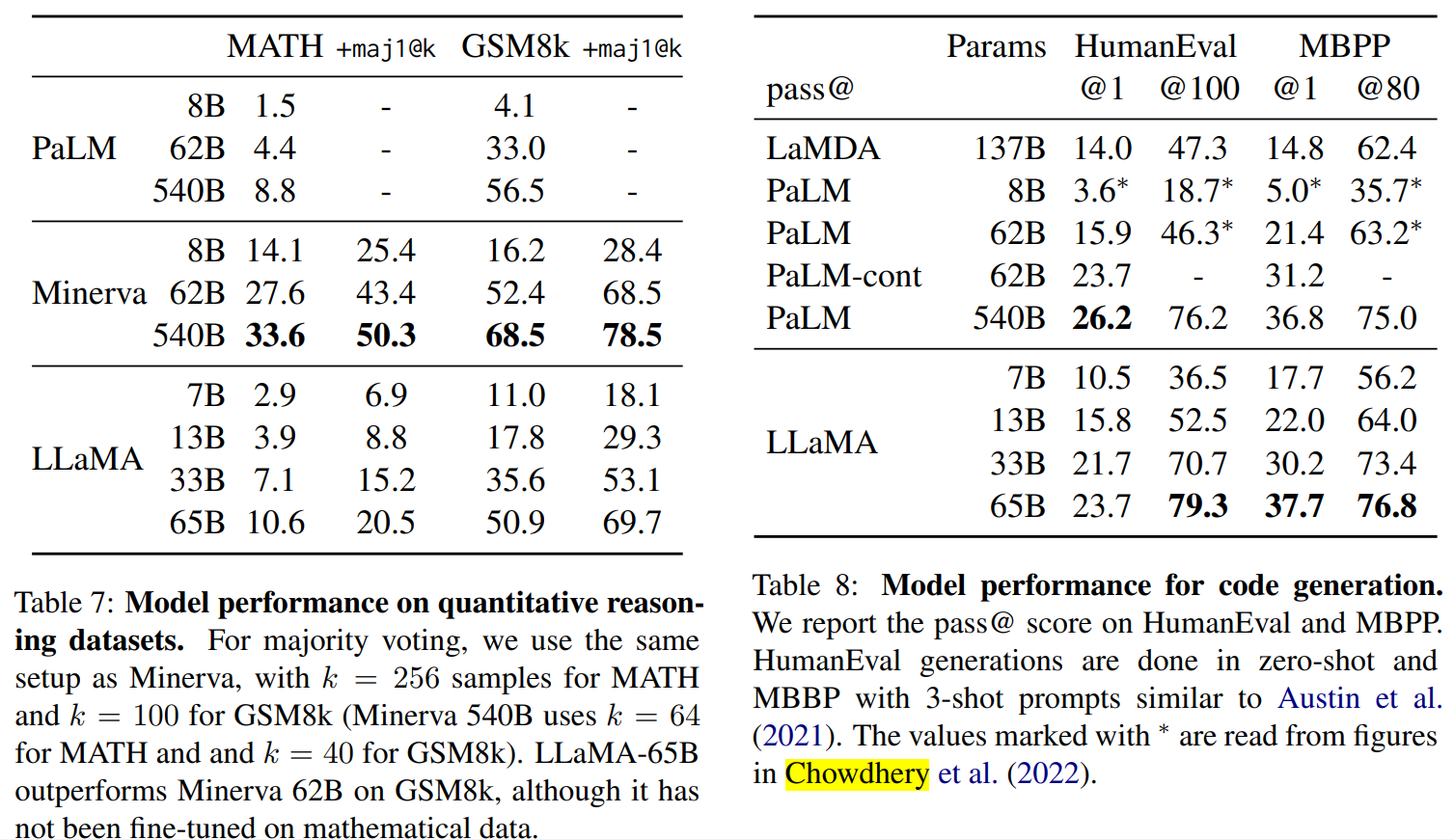
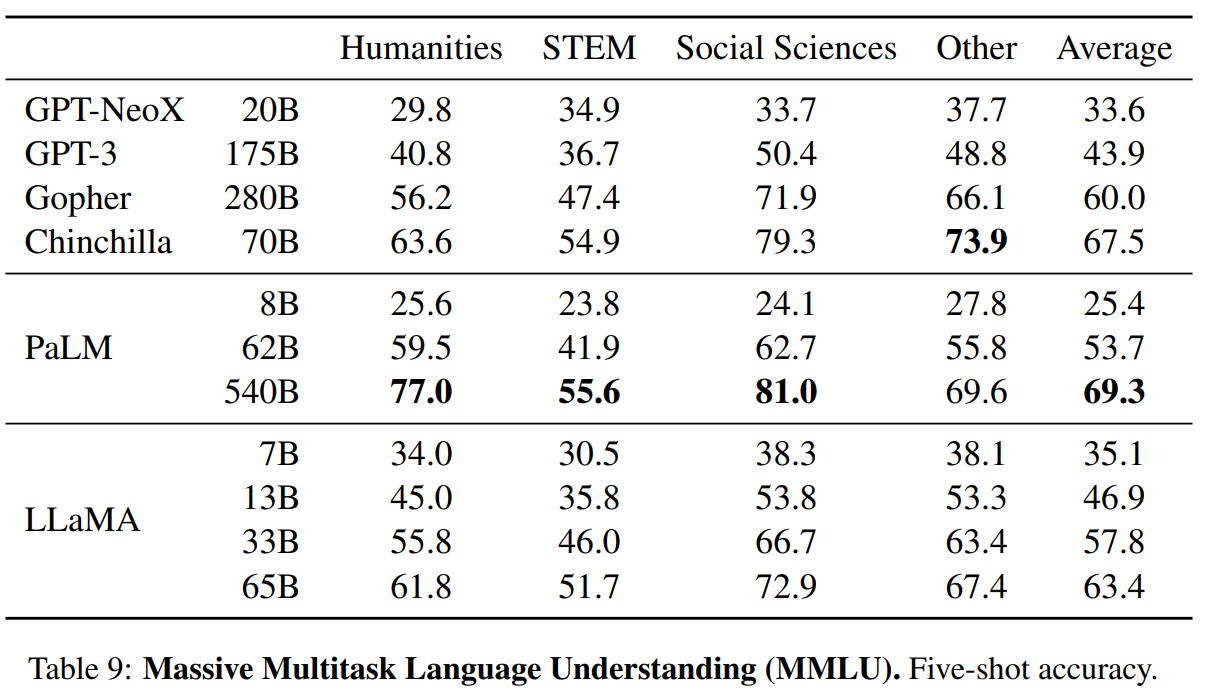
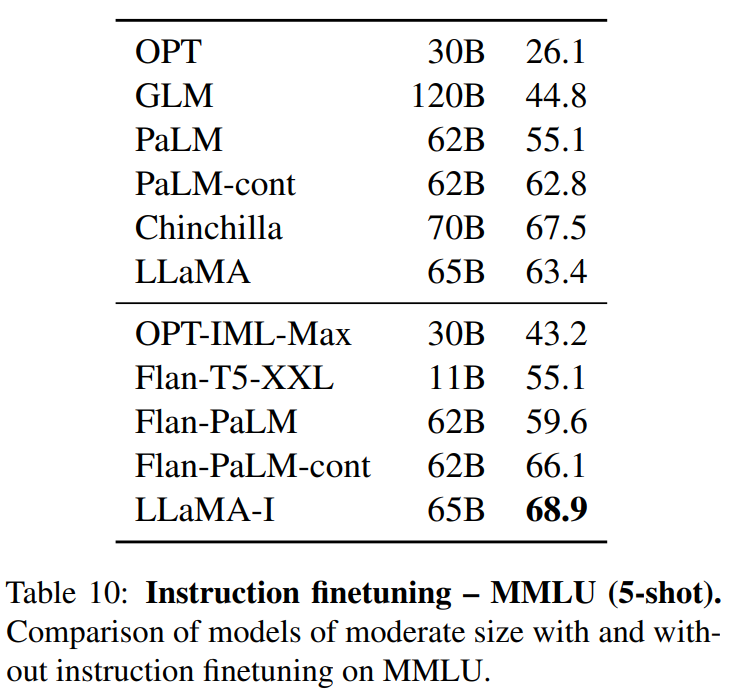
坑就是正好是平底锅大小的炉灶。正好可以放入平底锅。
pan和pit组成平移手势的系统,在具体代码中包含了边缘检测判定和状态机维护。我们将一步步实现平移手势功能
pit很简单,是一个包含了名称属性的控件,这个名称属性是用来标识pit的。以便当pan入坑时我们知道入了哪个坑,IsEnable是一个绑定属性,它用来控制pit是否可用的。
在这个程序中,拖拽物是一个抽象的唱盘。它的拖拽目标是周围8个图标。

交互实现
这里用Grid作为pit控件基类型,因为Grid可以包含子控件,我们可以在pit控件中添加子控件,比如一个图片,一个文字,这样就可以让pit控件更加丰富。
public class PitGrid : Grid
{
public PitGrid()
{
IsEnable = true;
}
public static readonly BindableProperty IsEnableProperty =
BindableProperty.Create("IsEnable", typeof(bool), typeof(CircleSlider), true, propertyChanged: (bindable, oldValue, newValue) =>
{
var obj = (PitGrid)bindable;
obj.Opacity = obj.IsEnable ? 1 : 0.8;
});
public bool IsEnable
{
get { return (bool)GetValue(IsEnableProperty); }
set { SetValue(IsEnableProperty, value); }
}
public string PitName { get; set; }
}
使用WeakReferenceMessenger作为消息中心,用来传递pan和pit的交互信息。
定义一个平移事件PanAction,在pan和pit产生交汇时触发。其参数PanActionArgs描述了pan和pit的交互的关系和状态。
public class PanActionArgs
{
public PanActionArgs(PanType type, PitGrid pit = null)
{
PanType = type;
CurrentPit = pit;
}
public PanType PanType { get; set; }
public PitGrid CurrentPit { get; set; }
}
手势状态类型PanType定义如下:
- In:pan进入pit时触发,
- Out:pan离开pit时触发,
- Over:释放pan时触发,
- ·Start:pan开始拖拽时触发
public enum PanType
{
Out, In, Over, Start
}
MAUI为我们开发者包装好了
PanGestureRecognizer
即平移手势识别器。
平移手势更改时引发事件
PanUpdated
事件,此事件附带的 PanUpdatedEventArgs对象中包含以下属性:
- StatusType,类型 GestureStatus为 ,指示是否为新启动的手势、正在运行的手势、已完成的手势或取消的手势引发了事件。
- TotalX,类型 double为 ,指示自手势开始以来 X 方向的总变化。
- TotalY,类型 double为 ,指示自手势开始以来 Y 方向的总变化。
容器控件
PanGestureRecognizer
提供了当手指在屏幕移动这一过程的描述我们需要一个容器控件来对拖拽物进行包装,以赋予拖拽物响应平移手势的能力。
创建平移手势容器控件:在Controls目录中新建PanContainer.xaml,代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<ContentView xmlns="http://schemas.microsoft.com/dotnet/2021/maui"
xmlns:x="http://schemas.microsoft.com/winfx/2009/xaml"
x:Class="MatoMusic.Controls.PanContainer">
<ContentView.GestureRecognizers>
<PanGestureRecognizer PanUpdated="PanGestureRecognizer_OnPanUpdated"></PanGestureRecognizer>
<TapGestureRecognizer Tapped="TapGestureRecognizer_OnTapped"></TapGestureRecognizer>
</ContentView.GestureRecognizers>
</ContentView>
为PanContainer添加PitLayout属性,用来存放pit的集合。
打开PanContainer.xaml.cs,添加如下代码:
private IList<PitGrid> _pitLayout;
public IList<PitGrid> PitLayout
{
get { return _pitLayout; }
set { _pitLayout = value; }
}
CurrentView属性为当前拖拽物所在的pit控件。
private PitGrid _currentView;
public PitGrid CurrentView
{
get { return _currentView; }
set { _currentView = value; }
}
添加PositionX和PositionY两个可绑定属性,用来设置拖拽物的初始位置。当值改变时,将拖拽物的位置设置为新的值。
public static readonly BindableProperty PositionXProperty =
BindableProperty.Create("PositionX", typeof(double), typeof(PanContainer), default(double), propertyChanged: (bindable, oldValue, newValue) =>
{
var obj = (PanContainer)bindable;
//obj.Content.TranslationX = obj.PositionX;
obj.Content.TranslateTo(obj.PositionX, obj.PositionY, 0);
});
public static readonly BindableProperty PositionYProperty =
BindableProperty.Create("PositionY", typeof(double), typeof(PanContainer), default(double), propertyChanged: (bindable, oldValue, newValue) =>
{
var obj = (PanContainer)bindable;
obj.Content.TranslateTo(obj.PositionX, obj.PositionY, 0);
//obj.Content.TranslationY = obj.PositionY;
});
订阅PanGestureRecognizer的PanUpdated事件:
private async void PanGestureRecognizer_OnPanUpdated(object sender, PanUpdatedEventArgs e)
{
var isInPit = false;
var isAdsorbInPit = false;
switch (e.StatusType)
{
case GestureStatus.Started: // 手势启动
break;
case GestureStatus.Running: // 手势正在运行
break;
case GestureStatus.Completed: // 手势完成
break;
}
}
接下来我们将对手势的各状态:启动、正在运行、已完成的状态做处理
手势开始
- GestureStatus.Started:手势开始时触发, 触发动画效果,将拖拽物缩小,同时向消息订阅者发送PanType.Start消息。
case GestureStatus.Started:
Content.Scale=0.5;
WeakReferenceMessenger.Default.Send<PanActionArgs, string>(new PanActionArgs(PanType.Start, this.CurrentView), TokenHelper.PanAction);
break;
手势运行
GestureStatus.Running:手势正在运行时触发,这个状态下,
根据手指在屏幕上的移动距离来计算translationX和translationY,他们是拖拽物在X和Y方向上的移动距离。
在X轴方向不超过屏幕的左右边界,即x不得大于this.Width - Content.Width / 2,不得小于 0 - Content.Width / 2
同理
在Y轴方向不超过屏幕的上下边界,即y不得大于this.Height - Content.Height / 2,不得小于 0 - Content.Height / 2
代码如下:
case GestureStatus.Running:
var translationX =
Math.Max(0 - Content.Width / 2, Math.Min(PositionX + e.TotalX, this.Width - Content.Width / 2));
var translationY =
Math.Max(0 - Content.Height / 2, Math.Min(PositionY + e.TotalY, this.Height - Content.Height / 2));

接下来判定拖拽物边界
pit的边界是通过Region类来描述的,Region类有四个属性:StartX、EndX、StartY、EndY,分别表示pit的左右边界和上下边界。
public class Region
{
public string Name { get; set; }
public double StartX { get; set; }
public double EndX { get; set; }
public double StartY { get; set; }
public double EndY { get; set; }
}
对PitLayout中的pit进行遍历,判断拖拽物是否在pit内,如果在,则将isInPit设置为true。
判定条件是如果拖拽物的中心位置在pit的边缘内,则认为拖拽物在pit内。
```csharp
if (PitLayout != null)
{
foreach (var item in PitLayout)
{
var pitRegion = new Region(item.X, item.X + item.Width, item.Y, item.Y + item.Height, item.PitName);
var isXin = translationX >= pitRegion.StartX - Content.Width / 2 && translationX <= pitRegion.EndX - Content.Width / 2;
var isYin = translationY >= pitRegion.StartY - Content.Height / 2 && translationY <= pitRegion.EndY - Content.Height / 2;
if (isYin && isXin)
{
isInPit = true;
if (this.CurrentView == item)
{
isSwitch = false;
}
else
{
if (this.CurrentView != null)
{
isSwitch = true;
}
this.CurrentView = item;
}
}
}
}

isSwitch是用于检测是否跨过pit,当CurrentView非Null改变时,说明拖拽物跨过了紧挨着的两个pit,需要手动触发PanType.Out和PanType.In消息。
IsInPitPre用于记录在上一次遍历中是否已经发送了PanType.In消息,如果已经发送,则不再重复发送。
if (isInPit)
{
if (isSwitch)
{
WeakReferenceMessenger.Default.Send<PanActionArgs, string>(new PanActionArgs(PanType.Out, this.CurrentView), TokenHelper.PanAction);
WeakReferenceMessenger.Default.Send<PanActionArgs, string>(new PanActionArgs(PanType.In, this.CurrentView), TokenHelper.PanAction);
isSwitch = false;
}
if (!isInPitPre)
{
WeakReferenceMessenger.Default.Send<PanActionArgs, string>(new PanActionArgs(PanType.In, this.CurrentView), TokenHelper.PanAction);
isInPitPre = true;
}
}
else
{
if (isInPitPre)
{
WeakReferenceMessenger.Default.Send<PanActionArgs, string>(new PanActionArgs(PanType.Out, this.CurrentView), TokenHelper.PanAction);
isInPitPre = false;
}
this.CurrentView = null;
}

最后,将拖拽物控件移动到当前指尖的位置上:
Content.TranslationX = translationX;
Content.TranslationY = translationY;
break;
手势结束
- GustureStatus.Completed:手势结束时触发,触发动画效果,将拖拽物放大,同时回弹至原来的位置,最后向消息订阅者发送PanType.Over消息。
case GestureStatus.Completed:
Content.TranslationX= PositionX;
Content.TranslationY= PositionY;
Content.Scale= 1;
WeakReferenceMessenger.Default.Send<PanActionArgs, string>(new PanActionArgs(PanType.Over, this.CurrentView), TokenHelper.PanAction);
break;
使用控件
拖拽物
拖拽物可以是任意控件。它将响应手势。在这里定义一个圆形的250*250的半通明黑色BoxView,这个抽象的唱盘就是拖拽物。将响应“平移手势”和“点击手势”
<BoxView HeightRequest="250"
WidthRequest="250"
Margin="7.5"
Color="#60000000"
VerticalOptions="CenterAndExpand"
HorizontalOptions="CenterAndExpand"
CornerRadius="250" ></BoxView>
创建pit集合
MainPage.xaml中定义一个
PitContentLayout
,这个AbsoluteLayout类型的容器控件,内包含一系列控件作为pit,这些pit集合将作为平移手势容器的判断依据。
<AbsoluteLayout x:Name="PitContentLayout">
<--pit控件-->
...
</AbsoluteLayout>
在页面加载完成后,将PitContentLayout中的pit集合赋值给平移手势容器的PitLayout属性。
private async void MainPage_Appearing(object sender, EventArgs e)
{
this.DefaultPanContainer.PitLayout=this.PitContentLayout.Children.Select(c => c as PitGrid).ToList();
}
至此我们完成了平移手势系统的搭建。

这个控件可以拓展到任何检测手指在屏幕上的移动,并可用于将移动应用于内容的用途,例如地图或者图片的平移拖拽等。