我相信有不少小伙伴已经用过eureka,那么问题来了,Nacos是个啥?
看到这个标题,MySQL数据库与Nacos搭建监控服务,它们有什么关系么?
其实是Nacos支持连接MySQL,内部已配置好数据源、连接池供我们使用。如果使用其它数据源(比如信创要求,使用达梦数据库比较多),可以通过插件形式适配,模仿MySQL实现方式。具体如何实现,可参考 Nacos 的 github issues。
MySQL是什么?
一句话概括:一款社区活跃的开源数据库(database)软件,已被Oracle公司收购。
nacos是什么?
一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
nacos 官方文档:目前推荐2.x版本
https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html
nacos 样例
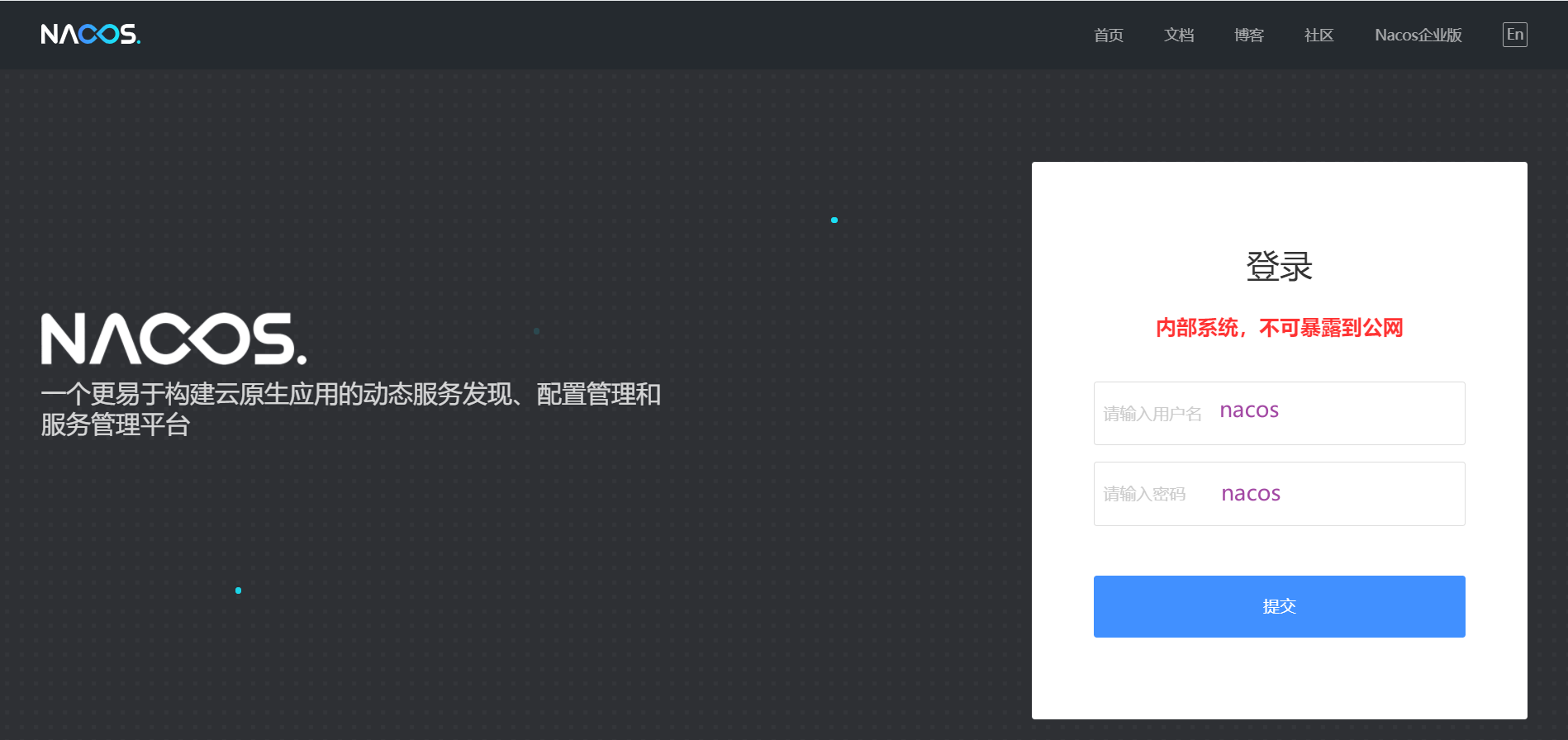
http://console.nacos.io/nacos/index.html#/login
默认用户名与密码均为:nacos
Nacos部署
项目环境
Nacos 依赖
Java
环境来运行。如果你是一名开发人员,或许需要准备如下环境:
- Maven 3.2.x+
- 64 bit JDK1.8+
- 64 bit OS,支持 Linux/Unix/Mac/Windows,
推荐选用 Linux/Unix/Mac
主要以Linux平台作为演示环境
。关于nacos 的获取(发行包、源码包),可以前往github开源仓库。
nacos开源仓库:
https://github.com/alibaba/nacos
目前nacos最新稳定版是2.2.1:
https://github.com/alibaba/nacos/releases/tag/2.2.1
下载很缓慢,可以使用在线工具箱加速(公共免费资源请适度使用):
https://tool.mintimate.cn/gh/
官方推荐版本为2.1.1:
您可以在Nacos的release notes及博客中找到每个版本支持的功能的介绍,当前推荐的稳定版本为2.1.1。
快速开始
解压nacos
unzip nacos-server-2.2.0.zip & tar -zxvf nacos-server-2.2.0.tar.gz
启动服务
Linux平台以单机模式启动nacos服务
:
sh startup.sh -m standalone
Windows平台以单机模式启动nacos服务
:
startup.cmd -m standalone
访问:
http://127.0.0.1:8848/nacos
后,进入登录界面:
服务注册、发现以及配置管理
服务注册
:
curl -X POST 'http://127.0.0.1:8848/nacos/v1/ns/instance?serviceName=nacos.naming.serviceName&ip=192.168.245.132&port=8080'
参数说明:
- serviceName:服务名
- ip:配置自己远程地址
- port:端口(外部访问需要放通)
服务发现
:
curl -X GET 'http://127.0.0.1:8848/nacos/v1/ns/instance/list?serviceName=nacos.naming.serviceName'
发布配置
:
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test&content=HelloWorld"
参数说明:
- dataId:数据Id。
- group:组名。
- content:发布配置输入的具体内容。
获取配置
:
curl -X GET "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test"
控制台显示输出内容:HelloWorld,代表配置成功。
关于curl命令教程,可以去curl官网(curl.se)找一找,还是很常用的。
关闭服务
Linux平台:
sh shutdown.sh
Windows平台:
.\shutdown.cmd
nacos2.2.0版本配置说明
以nacos2.2.0版本为示例说明
nacos配置文件,支持配置文件存储到数据库(DB)中保存。如果没有开放mysql数据源相应设置,默认使用本地存储数据源。
配置目录:
\nacos-server-2.2.0\conf
,文件清单,每个版本可能略微有所不同:
- application.properties
- application.properties.example
- derby-schema.sql
- mysql-schema.sql
- 1.4.0-ipv6_support-update.sql
- cluster.conf.example
- nacos-logback.xml
配置基本说明
以 .example 结尾,是示例配置,可供参考。以 update.sql 结尾的,则是sql更新脚本。
application.properties是nacos基本配置,例如端口、ip、数据源等等可以在此配置中修改,cluster.conf.example 是集群配置示例,nacos-logback.xml是日志相关配置。
mysql-schema.sql提供支持MySQL数据库SQL表结构,derby-schema.sql提供支持derby数据库SQL表结构。
如果和我一样使用的是MySQL数据库,
需要注意的配置文件是application.properties和mysql-schema.sql
,记住后续用得上。
导入表结构
新建数据库:库名命名为:nacos。编码最好指定为utf8mb4和utf8mb4_bin,避免导入后看到中文注释乱码。
create database nacos;
导入sql脚本到新建的库nacos中:mysql-schema.sql。库名并不是固定的,可以根据实际需求更改,比如nacos_config。如果你是从旧版本升级上来的,可能需要执行SQL脚本:
1.4.0-ipv6_support-update.sql
。
上面聊到 nacos 可以在配置文件中配置数据源,当然必不可少,需要部署MySQL数据库。
找到
application.properties
配置文件,配置MySQL数据源:
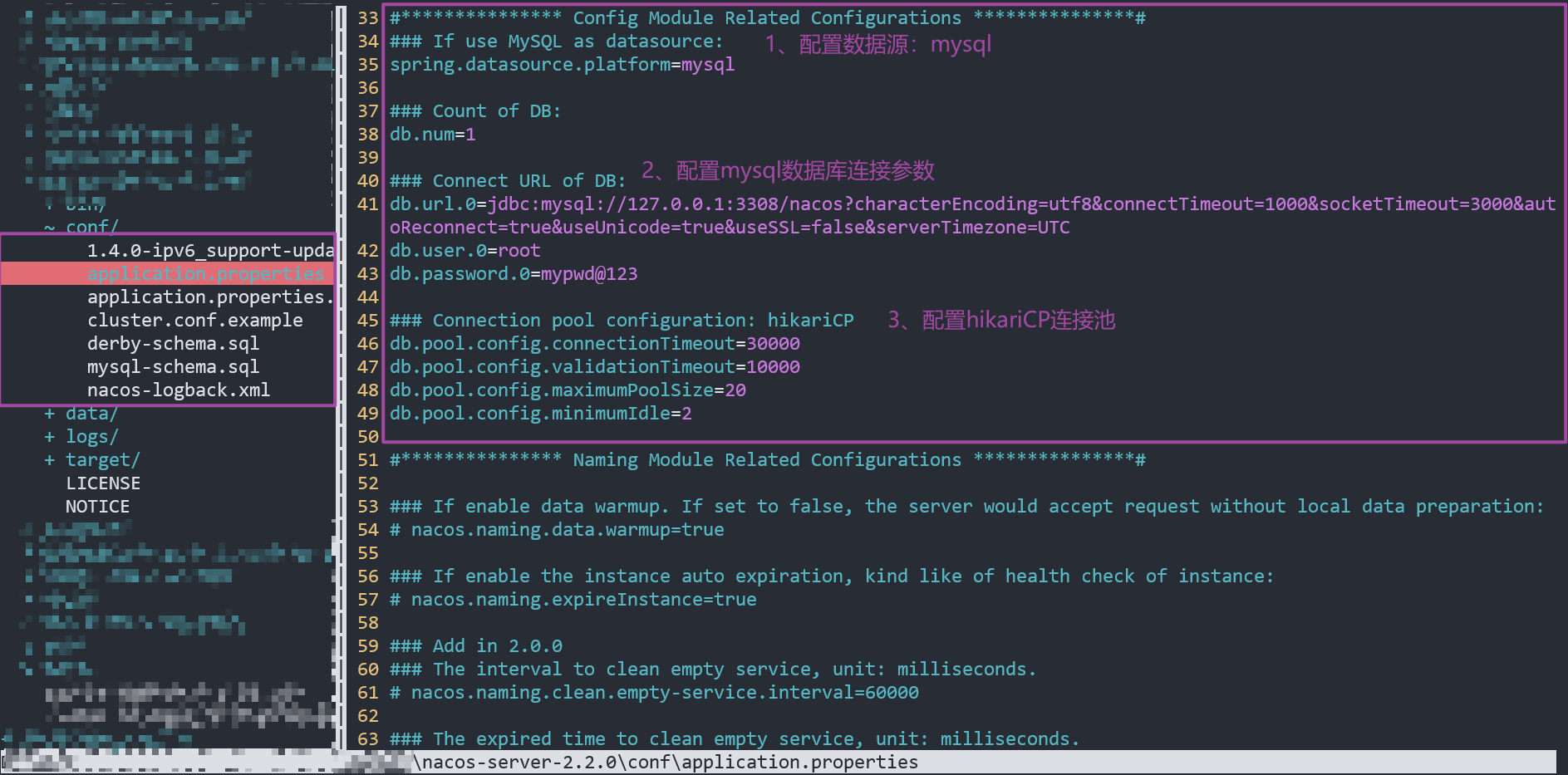
### If use MySQL as datasource:
spring.datasource.platform=mysql ### Count of DB:
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://192.168.245.132:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root db.password.0=mypwd@123
很奇怪的一个问题,第一次使用,只导入初始化sql脚本MySQL数据源:
[root@Centos9-Stream ~]# cat /usr/local/nacos-2.2.0/conf/mysql-schema.sql | mysql -uroot -p nacos
nacos以单机模式启动:sh startup.sh -m standalone,启动无异常,正常访问。
MySQL数据库已设置自启,排查数据库正常启动。第二天启动centos-stream-9,再次启动 nacos 服务,出现无法设置数据源,尝试屏蔽数据源配置文件,启动正常。猜测可能是初始化脚本出问题了,执行升级sql脚本:1.4.0-ipv6_support-update.sql,再次启动nacos服务正常。
如果你和我一样,使用的是
MySQL8.0.30
版本数据库,可以参考。
如果遇到
Public Key Retrieval is not allowed
,可能还需要加上
&allowPublicKeyRetrieval=true
。
在github issues查找解决方案,提到可能是MySQL8.0.x设置时区的问题,将默认serverTimezone=UTC修改为
serverTimezone=Asia/Shanghai
。
如果配置好MySQL,但还是遇到数据源无法找到,也许是数据库导入脚本没有升级,也许是数据库版本和时区问题
。
尝试重连,反复提醒 Public Key Retrieval 不被允许,反复提醒数据源没有设置。
java.sql.SQLNonTransientConnectionException: Could not create connection to database server. Attempted reconnect 3 times. Giving up.
Caused by: com.mysql.cj.exceptions.CJException:
Public Key Retrieval is not allowed
Caused by: com.alibaba.nacos.api.exception.NacosException: Nacos Server did not start because dumpservice bean construction failure :
No DataSource set
Caused by: java.lang.IllegalStateException:
No DataSource set
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure :
No DataSource set
也有可能是MySQL版本问题和设置时区问题,连接配置做如下调整:
### Connect URL of DB:
db.url.0=jdbc:mysql://192.168.245.132:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode =true&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=Asia/Shanghai
db.user.0=root
db.password.0=mypwd@123
Linux终端执行命令导入升级脚本:
cat /usr/local/nacos-2.2.0/conf/1.4.0-ipv6_support-update.sql | mysql -uroot -p nacos
问题排查
关于nacos大部分问题
,可以在官方仓库的 issues 找到解决方案:
https://github.com/alibaba/nacos/issues
总结配置数据源相关问题
:
- 导入初始化sql脚本缺失字段问题。
- 使用数据源配置jdbc,数据库时区设置问题。
- MySQL8.0.x数据库默认密码使用缓存算法(caching_sha2_password)问题。
MySQL部署
tips:下载注意使用带有GA(General Availability)标识,稳定版。
实际工作中,使用比较到的是下载离线安装包。安装方式主要有如下几种分类:
安装方式
Windows平台
:
- msi文件:直接双击进行安装,有可视化界面,安装较为容易,但不够灵活。
- 归档包(archive):以zip格式进行压缩,类似于Linux中的二进制包。比较灵活,只需几个命令即可安装服务和实例化。
- 源码包(source package):最灵活,可根据需求编译安装功能,难易度最高。
- docker形式安装:其实是在容器中安装。
Linux平台
:
- rpm & deb 包安装:最为简单,但不灵活,适合初学者使用。
- 二进制包(binary package):也称归档包(archive),编译好的源码包,比rpm包更灵活。个人认为是安装多个服务最佳选择。
- 源码包(source package):最灵活,可根据需求编译安装功能,难易度最高。
- docker形式安装:其实是在容器中安装。
当然,MySQL同样支持macOS平台。
你也可以使用MySQL的妹妹MariaDB替代MySQL,是很好的选择。
由于测试使用,本人数据库使用比较新,MySQL8.0.30。说8.0新,其实也并不是很新,距离8.0第一个稳定版
Changes in MySQL 8.0.11 (2018-04-19, General Availability)
快5年了。
目前市面上主要以MySQL5.7为主,离停止维护不远了,未来应该会逐渐升级为MySQL8.0.x。看到官网将MySQL5.6文档页面转移了,已停止版本更新。
Windows 平台
此处省略安装过程。
请参考个人公众号里面的文章,有简易安装教程:SQL基础知识扫盲。
Linux平台(CentOS-Stream-9)部署MySQL
此处我只演示
Linux平台(CentOS-Stream-9)
其中最方便的一种部署方式。
Linux平台(CentOS-Stream-9)
通过RHEL系列自带的命令服务安装管理工具,yum与dnf二选一即可。
yum -y install mysql-server-8.0.30
dnf -y install mysql-server-8.0.30
安装后,查看mysql服务状态,默认服务名为mysqld.service。
systemctl status mysqld.service
默认没有启动,手动启动 mysqld 服务
systemctl start mysqld.service
登录mysql字符命令行界面
mysql -uroot -p
调试防火墙管理工具
如需远程登录,需要关闭防火墙相关服务,或者开放相应端口,个人建议采用开放相应端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent
由于MySQL默认端口3306可能被黑客利用通用扫描软件攻击,建议实际工作中进行修改。或者利用隧道转发功能。
如果只是在本地使用,改与不改并不影响。
重载firewalld服务
firewall-cmd --reload
MySQL用户权限
设置开机自启
systemctl enable mysqld.service
查看mysqld服务状态:看到enabled代表设置为自启
systemctl status mysqld.service
如果使用第三方管理工具,需要开放相应用户权限才能登录MySQL:
修改用户密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'mypwd@123';
创建用户root,主机地址%,匹配所有;如果是localhost,则只让本地使用,也可以是指定ip地址。
CREATE USER 'root'@'%' IDENTIFIED BY 'mypwd@123';
CREATE USER 'root'@'localhost' IDENTIFIED BY 'mypwd@123';
CREATE USER 'root'@'192.168.245.132' IDENTIFIED BY 'mypwd@123';
授权root用户所有权限(ALL),即可使远程登录。同样可以指定特定权限,只给查询(select)。
GRANT ALL ON *.* TO 'root'@'%' WITH GRANT OPTION;
GRANT ALL ON *.* TO 'root'@'localhost' WITH GRANT OPTION;
GRANT ALL ON *.* TO 'root'@'192.168.245.132' WITH GRANT OPTION;
如果遇到第三方工具连接提示密码插件规则不被支持问题:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'mypwd@123';
刷新权限
flush privileges;
更多权限细化设置请参考MySQL8.0.x官方文档第6章节Security。关于权限控制和账号(用户)管理介绍很详细。
6.2 Access Control and Account Management
更多安装方式,你还可以参考个人持续更新的笔记:
https://blog.cnwangk.top/2023/03/15/MySQL8-0-x-简易安装教程
MySQL导入mysql-schema脚本
下面,将演示数据库创建以及
sql脚本导入
。
登录
mysql -uroot -p
创建数据库
create database nacos;
导入数据,执行sql脚本
关于数据导入,可以使用DB管理工具(MySQL workbench、DBeaver、SQLyog)连接导入,也可以使用cat或者zcat命令导入。
演示Linux平台使用cat命令导入sql脚本
:
[root@Centos9-Stream ~]# cat /usr/local/nacos-2.2.0/conf/mysql-schema.sql | mysql -uroot -p nacos
原本我也不知道这种用法,联想到以前使用过zabbix监控工具。灵机一动,我也可以将nacos的sql脚本这样导入数据库中。
查看nacos数据库表
:验证是否导入成功
mysql> use nacos;
mysql> show tables;
Springboot项目构建
如果你只是想体验nacos简单用法,可以跳过springboot项目集成nacos微服务
。
如果你是软件实施、运维人员,可以关注nacos官方文档运维监控文档(运维指南)。
介绍很详细,我也觉得我很啰嗦了,这已经属于开发范畴了。
目标
:项目中集成nacos服务,使用nacos监控到打包好并正常运行服务健康情况。集成spring-cloud-starter-alibaba-nacos-discovery和spring-cloud-starter-alibaba-nacos-config。nacos-discovery是服务发现组件,nacos-config则是服务配置组件。
项目环境
需要准备的环境
:
- Maven 3.6.3
- JDK17
- Linux环境(CentOS9-Stream)
Linux平台安装JDK
解压JDK
tar -zxvf jdk-17.0.4.1_linux-x64_bin.tar.gz
配置全局环境变量:vim /etc/profile
JAVA_HOME=/usr/java/jdk17
CLASS_PATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASS_PATH PATH
配置当前用户环境变量:vim .bash_profile 或者 .bashrc,加入配置全局变量我所列出的内容即可。
执行 source 命令立即生效
:
source /etc/profile
关于环境变量更多配置可参考个人公众号关于JDK17的介绍。
验证版本:
java -version
Linux平台安装maven
yum -y install maven
当然,你也可以到Maven官网下载打包好的二进制包,解压即可用。
unzip apache-maven-3.6.3-bin.zip
mv apache-maven-3.6.3 /usr/local/
加入环境变量:
# Maven Home
MAVEN_HOME=/usr/local/apache-maven-3.6.3
PATH=$PATH:$MAVEN_HOME/bin
export MAVEN_HOME PATH
执行source命令立即生效
:source /etc/profile
查看版本
[root@Centos9-Stream bin]# mvn --version
Apache Maven 3.6.3 (Red Hat 3.6.3-15)
Maven home: /usr/share/maven
Java version: 17.0.4.1, vendor: Oracle Corporation, runtime: /usr/java/jdk17
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "5.14.0-148.el9.x86_64", arch: "amd64", family: "unix"
看到以上环境,证明你的Maven环境已经部署好了。
注意
:默认Maven镜仓库地址很慢,需要更换,推荐阿里云镜像源。
修改Maven配置文件:
[root@Centos9-Stream bin]# vim /usr/share/maven/conf/settings.xml
修改默认本地仓库存放目录
:找到localRepository,将如下内容开放:

<localRepository>/local/repo</localRepository>
配置Maven阿里镜像地址
,加入如下配置,
注意是在
加入
:
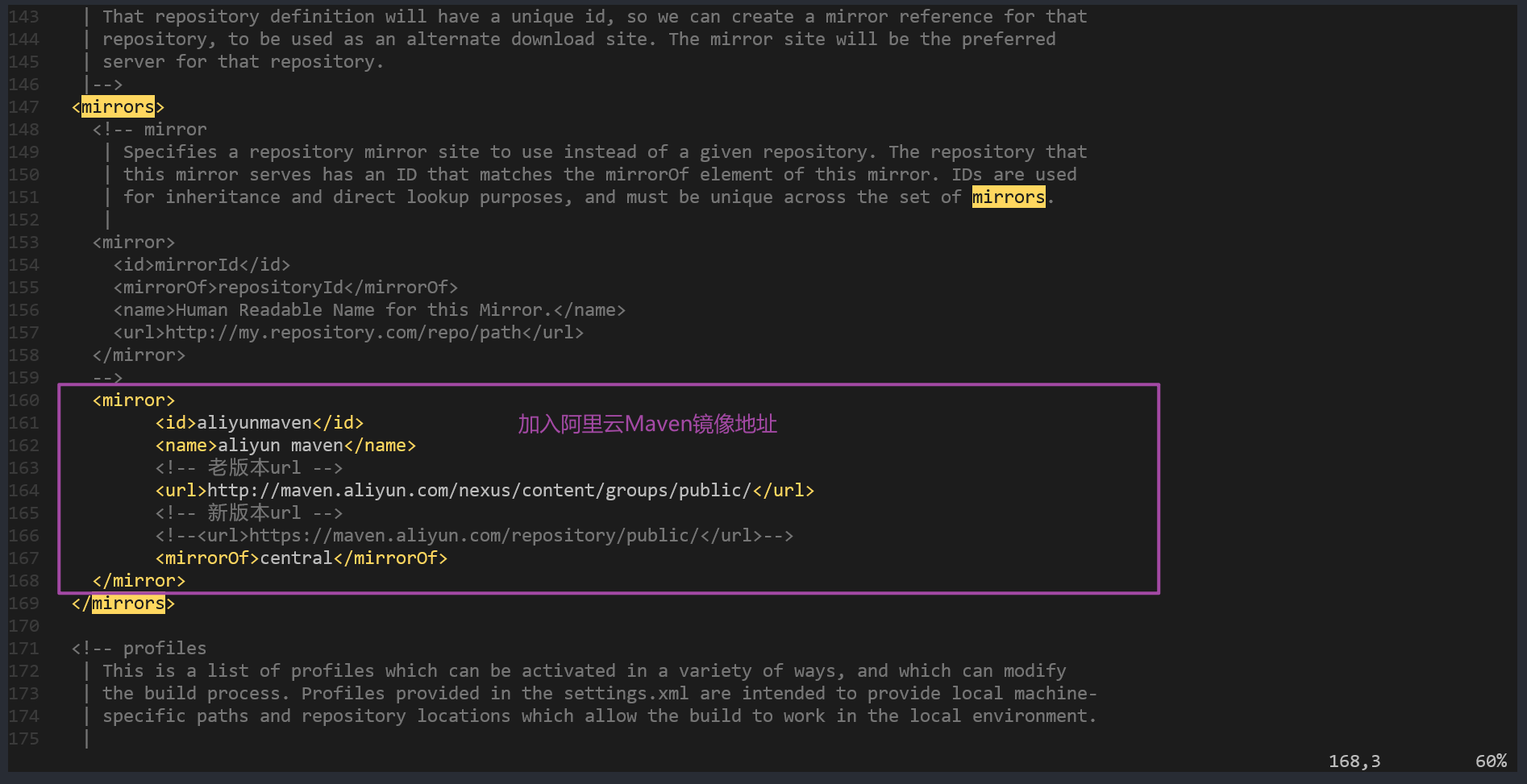
<mirrors>
<mirror>
<id>aliyunmaven</id>
<name>aliyun maven</name>
<!-- 老版本url -->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<!-- 新版本url -->
<!--<url>https://maven.aliyun.com/repository/public/</url>-->
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
项目构建
注意
:如果使用IDE工具构建,注意springboot、spring cloud以及spring cloud alibaba版本对应关系。尽量使用阿里云云原生应用脚手架官网推荐的版本,有助于后期遇到问题排查。当然还有一个好处,选择组件时有中文说明,一目了然。
如果你对于IDE工具使用,实在有困难,可以在线构建。
两种在线脚手架构建方式:
个人还是比较推荐使用阿里云云原生应用脚手架构建,便于在线选择nacos 等微服务相关组件。
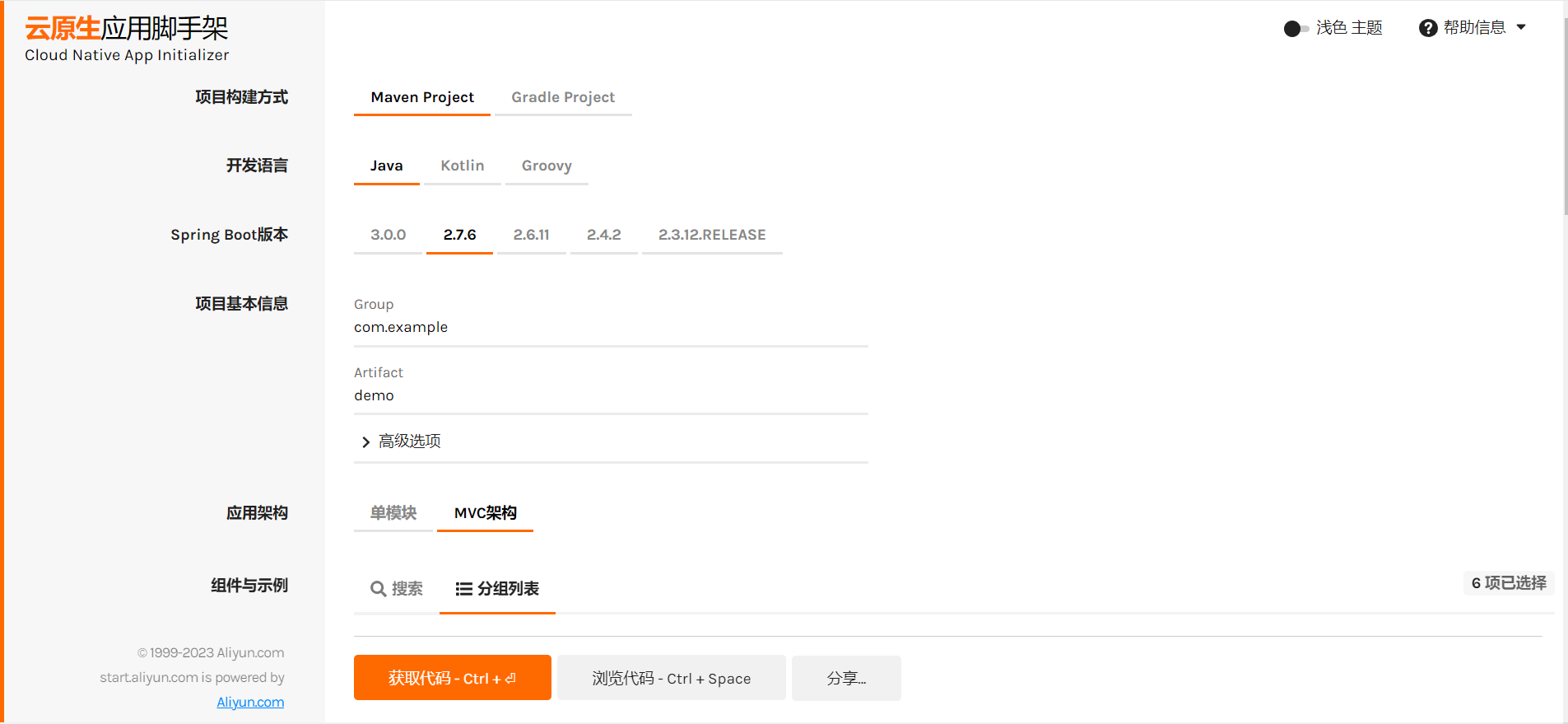
springboot版本可以自己调试,目前已经支持springboot2.7.6和3.0.0配置。之前建议版本为springboot2.6.11,如果使用高版本,选择nacos相关组件时灰色的。
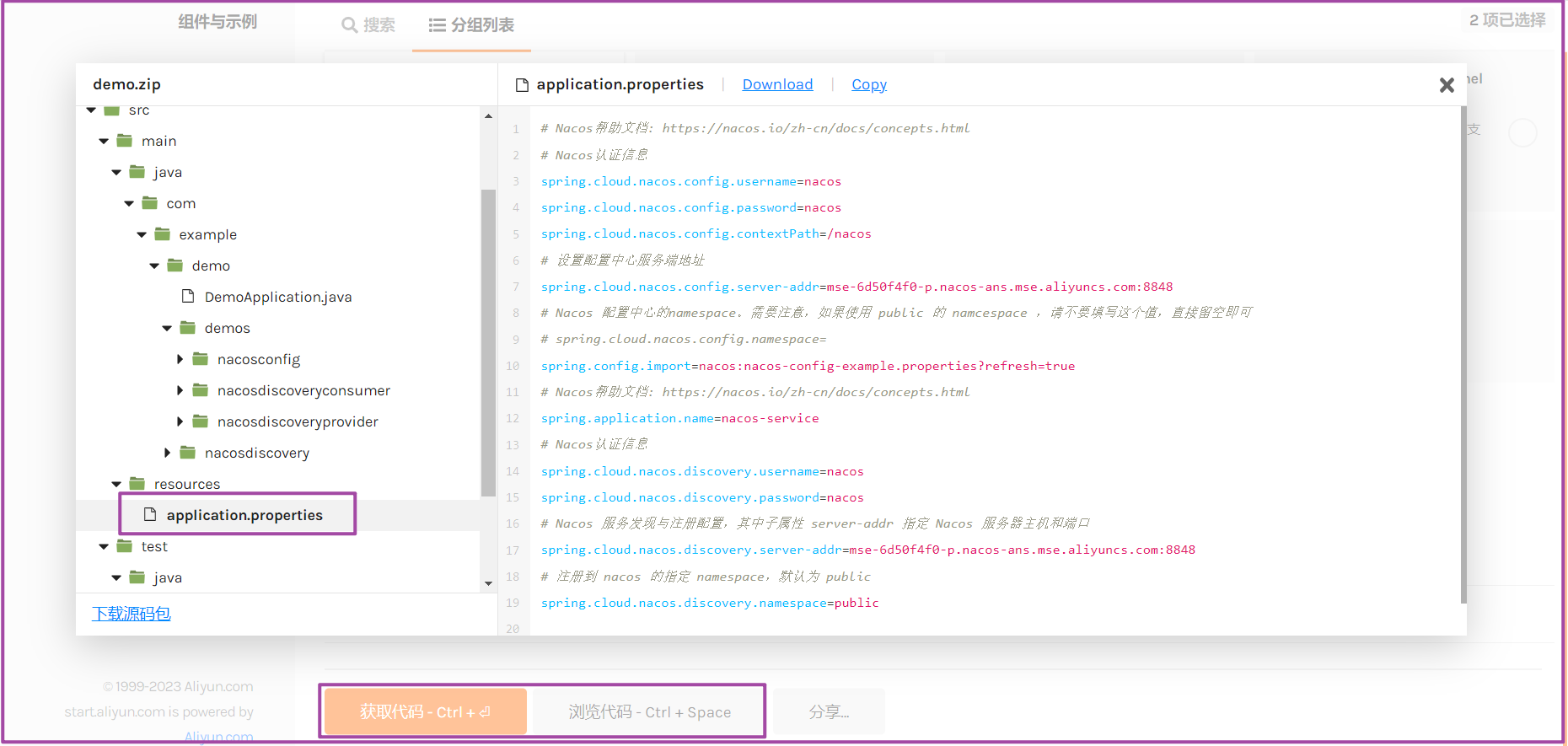
构建完成,如何打包成jar(目前使用比较多的时候jar包形式)?少不了JDK和Maven环境,参考环境准备步骤。老项目是有不少使用war包形式。
解压下载好的springboot项目demo.zip
unzip demo.zip
cd demo
执行Maven安装命令,这个过程可能有点缓慢,下载jar包越多,越耗时间:
[root@Centos9-Stream demo]# mvn install
如果新建的是单体应用,在根目录找到application.properties配置文件,如果构建mvc架构应用,则在demo-start子项目找到application.properties,然后修改spring.cloud.nacos.config.server-addr与spring.cloud.nacos.discovery.server-addr的IP地址。
示例如下
:

有点纳闷,也许是我本地环境问题,之前很少使用阿里脚手架构建项目。感觉使用阿里云云原生应用脚手架构建,会出现某些jar包(openfeign)找不到,使用Maven打包出现主清单文件找不到的问题。自己一步一步构建,添加微服务组件,配置nacos则是正常的。
Maven打包遇到找不到依赖:
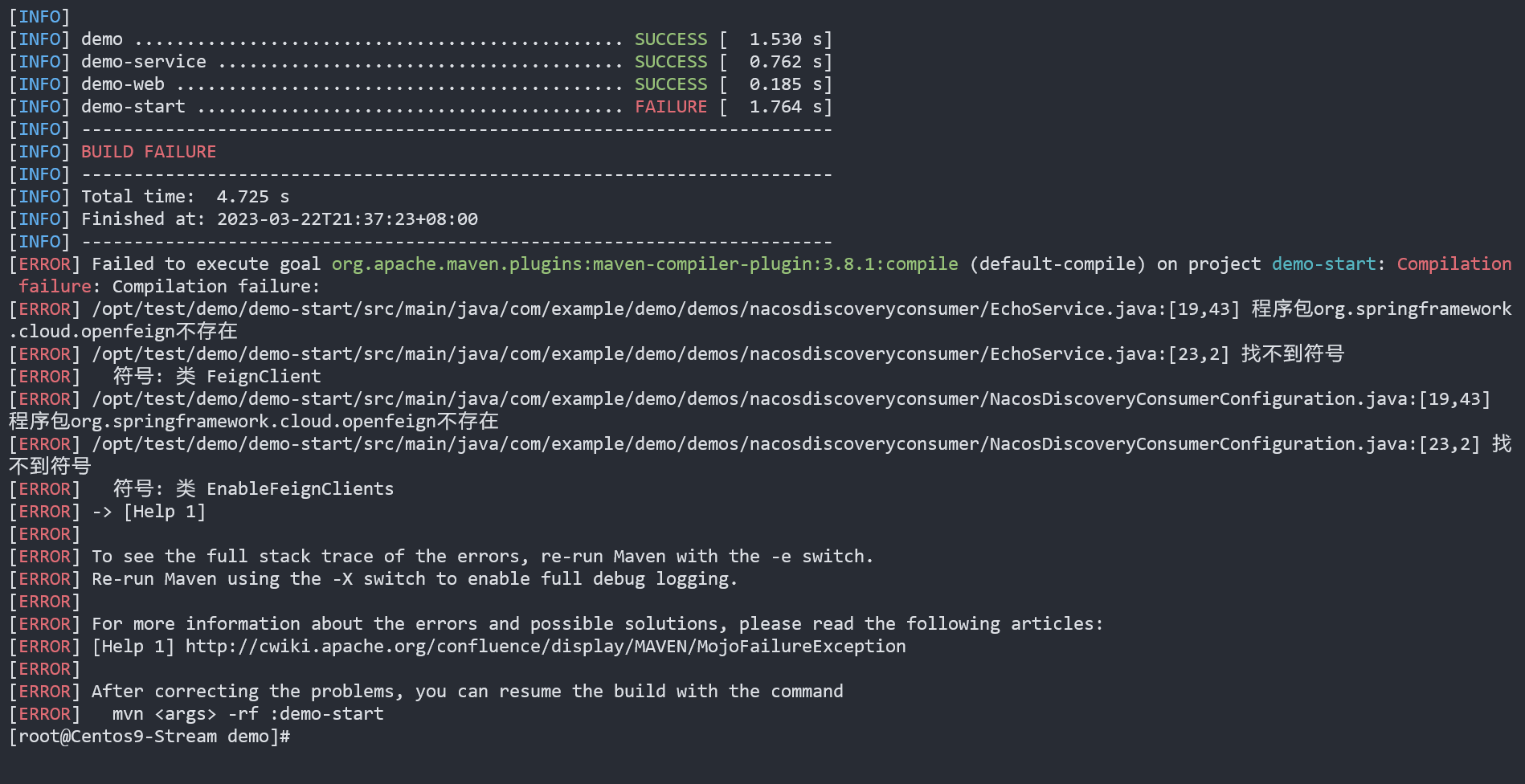
示例如下,引入openfeign
:
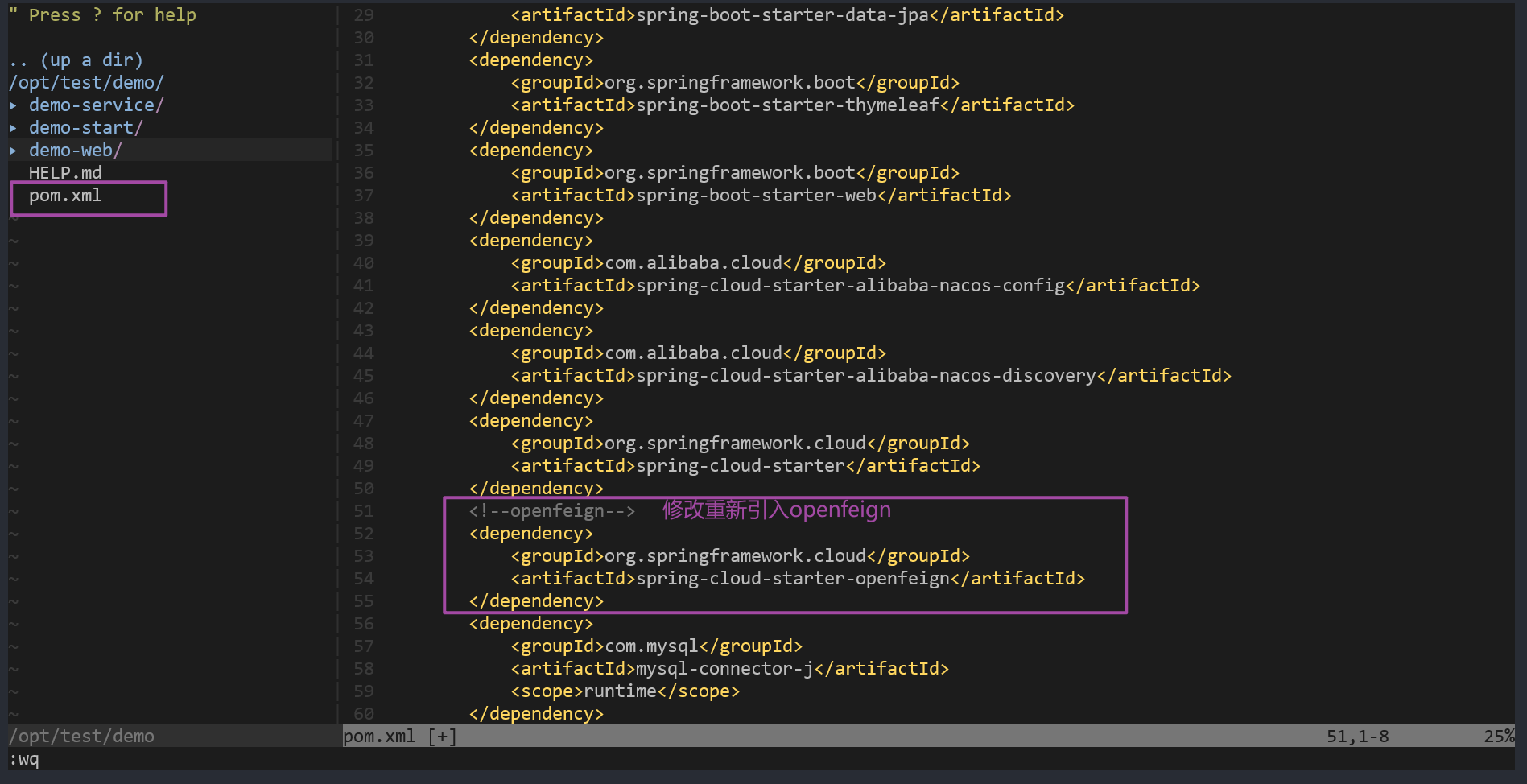
如果不出意外,正常打包,可以使用 java -jar 执行jar服务
。
java -jar demo-web/target/demo-web-0.0.1-SNAPSHOT.jar
在nacos控制台服务管理可以监控到服务,比如我搭建测试环境,给应用区名称为:springboot-test。
Nacos联动测试
新建配置
:springboot-test.properties
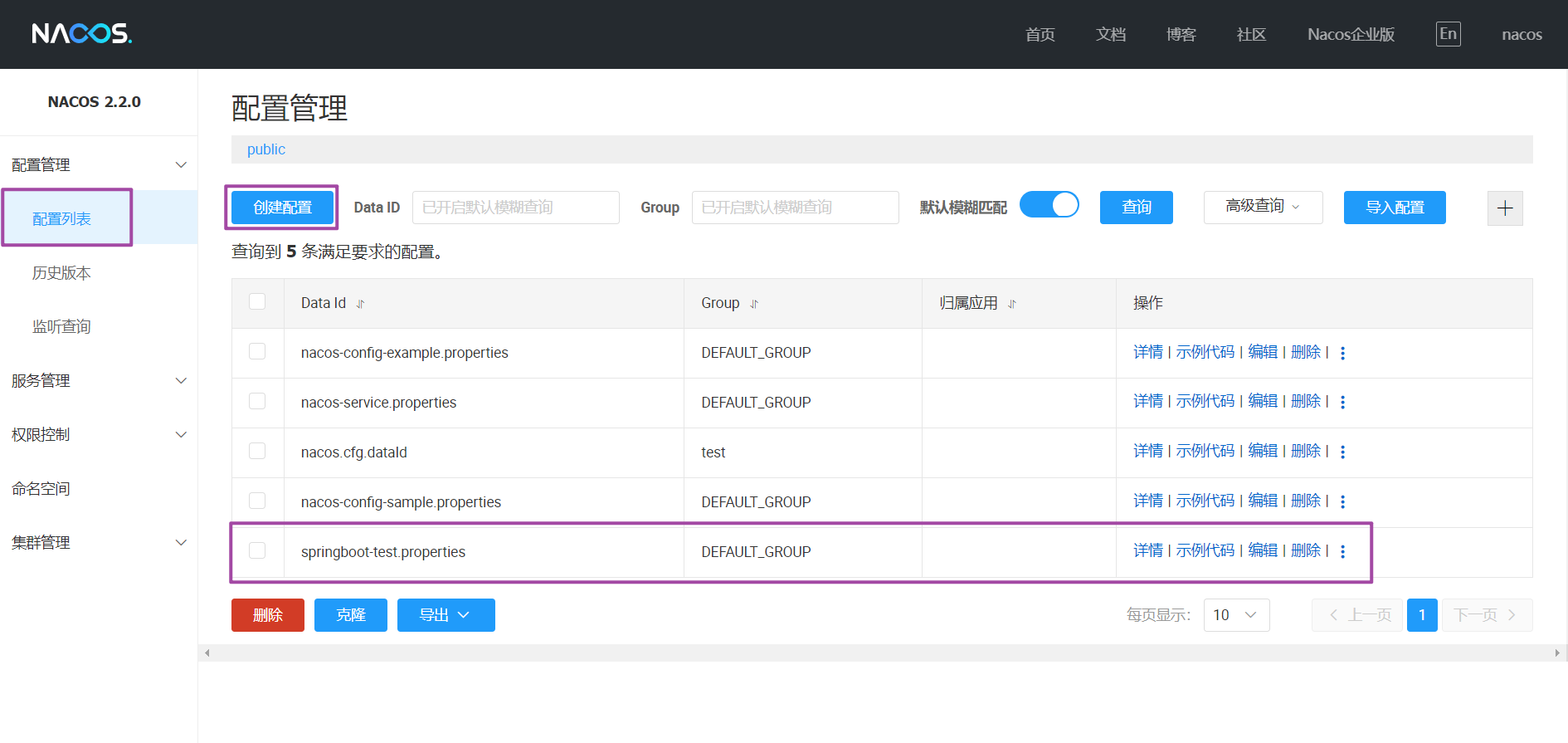
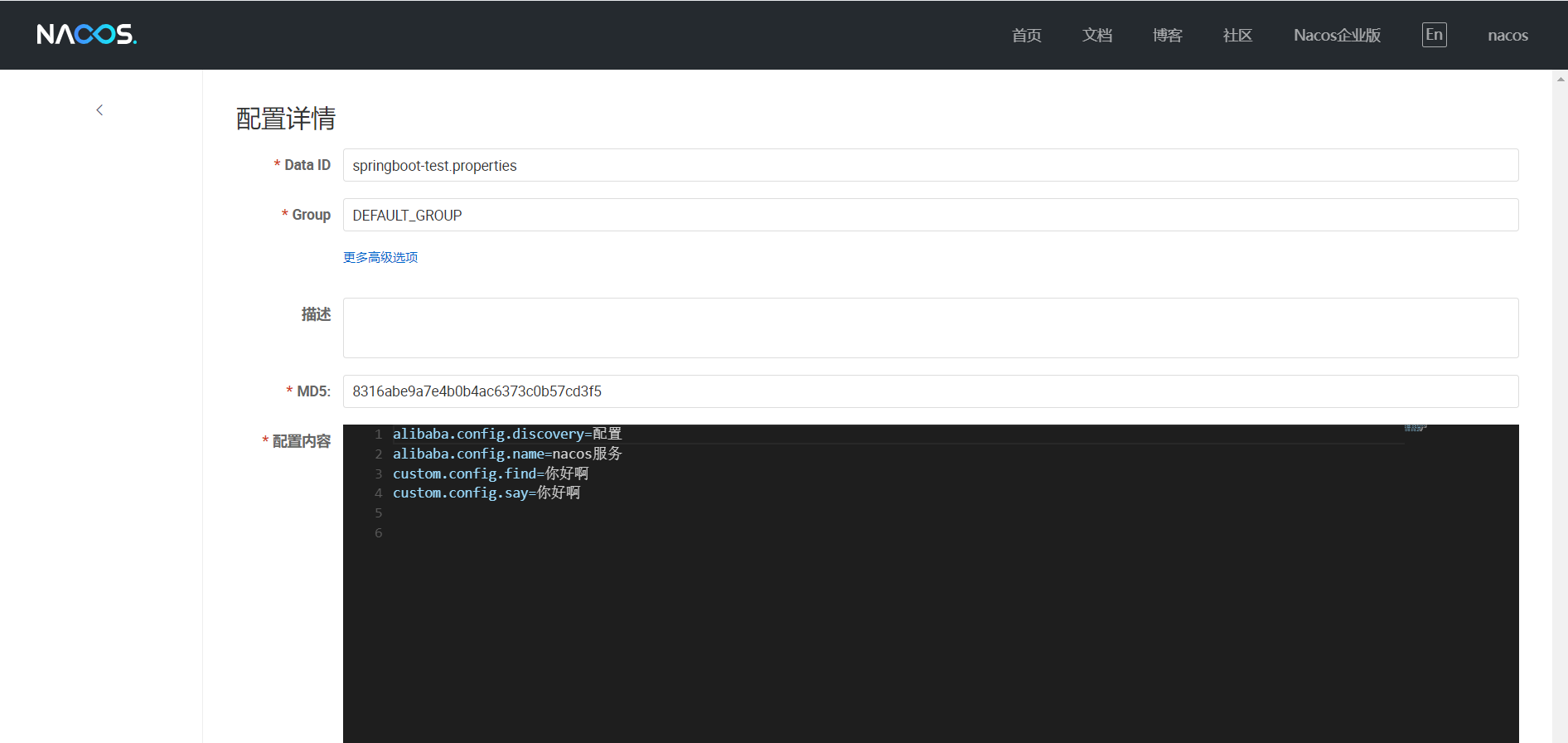
配置详情
:配置的比较随意,参考看看就行
当然,你也需要在controller层 Java 代码里加入如下匹配:
/** 使用动态配置获取测试 --BEGIN-- **/
@Value("${alibaba.config.discovery}")
private String discovery;
@Value("${alibaba.config.name}")
private String name;
@GetMapping("/getConfig")
public String getConfig() {
log.info("getConfig>>>>>>>>>>>");
return "getConfig>>>>>>>>>>>>" + "发现:" + discovery + ">>>服务名称:" + name;
}
@Value("${custom.config.find}")
private String find;
@Value("${custom.config.say}")
private String say;
@GetMapping("/meet")
public String meet() {
log.info("meet>>>>>>>>>>>");
return "meet>>>>>>>>>>>>" + "偶遇老湿:" + find + ">>>你好:" + say;
}
/** 使用动态配置获取测试 --END-- **/
提供一种思路。可以根据业务情况而定,将多个配置封装到一个类里面,如下所示,新建CustomConf类:
/**
* desc:对象配置类
* @Value
* @Component @ConfigurationProperties
*/
@Component
@ConfigurationProperties(prefix = "custom")
public class CustomConf {
private Integer one;
private Integer two;
private Integer three;
private String description;
// 此处省略掉了 get set 方法,实际需要补上
}
使用到注解:
- @Component :加入注解,便于被扫描到。
- @ConfigurationProperties:引入配置,通过prefix指定配置前缀。
在项目中注入:
@Autowired
private CustomConf custom;
@RequestMapping("/custom")
public String custom() {
return "[custom] " + custom;
}
准备好集成nacos服务的jar包:
[root@Centos9-Stream test]# ll springboot-nacos-cloud-0.0.1-SNAPSHOT.jar
-rw-rw-r--. 1 kart kart 77534357 2月 12 18:44 springboot-nacos-cloud-0.0.1-SNAPSHOT.jar
运行服务
:
nohup 代表脱离终端运行,&代表放入后台
[root@Centos9-Stream test]# nohup java -jar -Dspring.profiles.active=prod /opt/workspace/test/springboot-nacos-cloud-0.0.1-SNAPSHOT.jar > /opt/
workspace/test/springboot-nacos.log 2>&1 &
[1] 4628
指定为生产环境:-Dspring.profiles.active=prod
测试接口:
http://192.168.245.132:8082/t/getConfig
你也可以使用curl命令请求:
curl -X GET http://192.168.245.132:8082/t/getConfig
得到输出结果:
getConfig>>>>>>>>>>>>发现:配置>>>服务名称:nacos服务
查看日志验证:

验证成功,getConfig日志打印出来了。
Nacos监控(控制台)
官方文档比我演示介绍要更详细,如果进一步使用,请参考官方文档(运维指南)。
控制台手册
:
https://nacos.io/zh-cn/docs/console-guide.html
基本功能演示
nacos 功能比较丰富
:
- 配置管理:动态更新配置、查看历史版本、监听查询;
- 服务管理:查看、创建服务、查看订阅者列表;
- 权限列表:管理用户、角色、权限配置;
- 命名空间:默认保留空间(public)
- 集群管理:管理各个节点。
登录mysql,切换到nacos数据库
,查看原始users表只有一条数据,存储nacos用户。
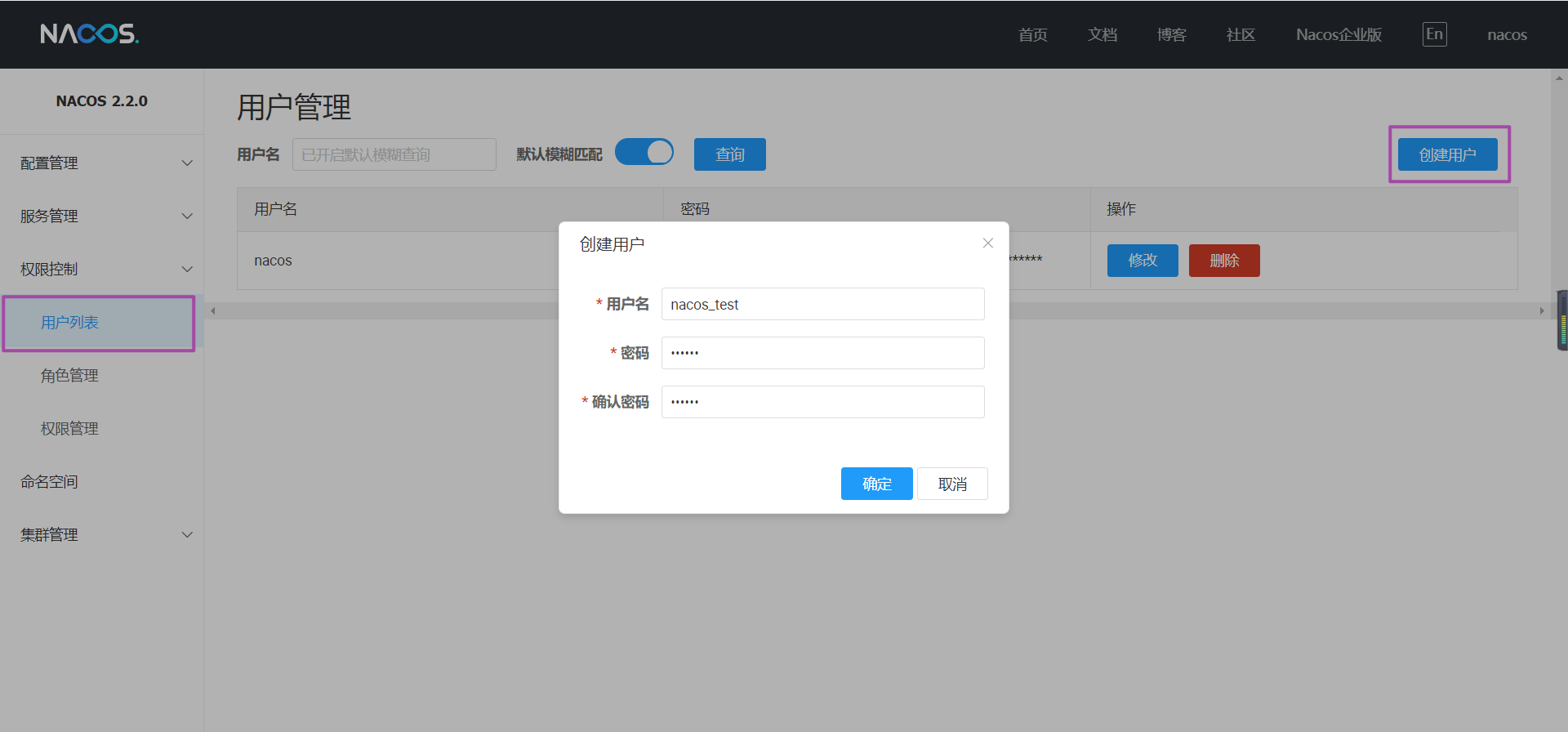
此处只演示一下连接上MySQL数据库后,在控制台左侧菜单栏找到权限控制,新建用户。
示例如下
:
验证数据库表
验证users表
,发现多了一条数据,nacos_test成功存入到数据库,至此MySQL与nacos联动完成。
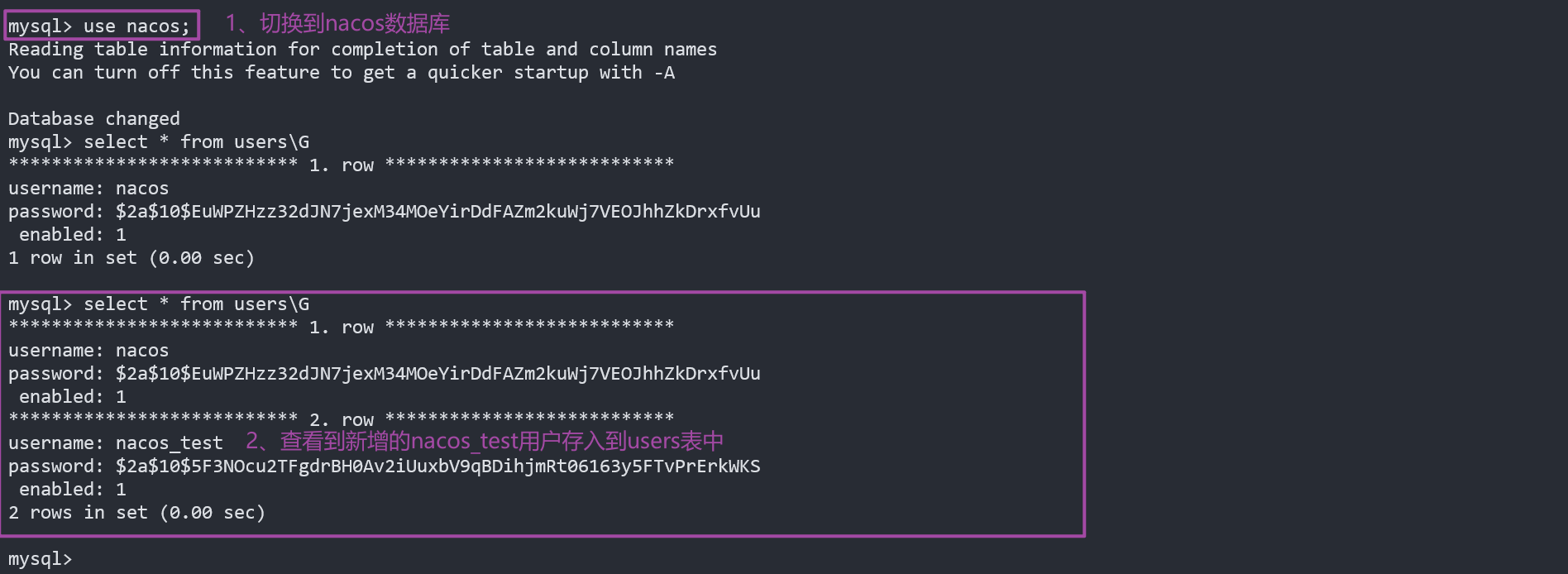
mysql> select * from users\G
*************************** 1. row ***************************
username: nacos
password: $2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu
enabled: 1
*************************** 2. row ***************************
username: nacos_test
password: $2a$10$5F3NOcu2TFgdrBH0Av2iUuxbV9qBDihjmRt06163y5FTvPrErkWKS
enabled: 1
2 rows in set (0.00 sec)
新增配置,对照数据库表
use nacos;
show tables;
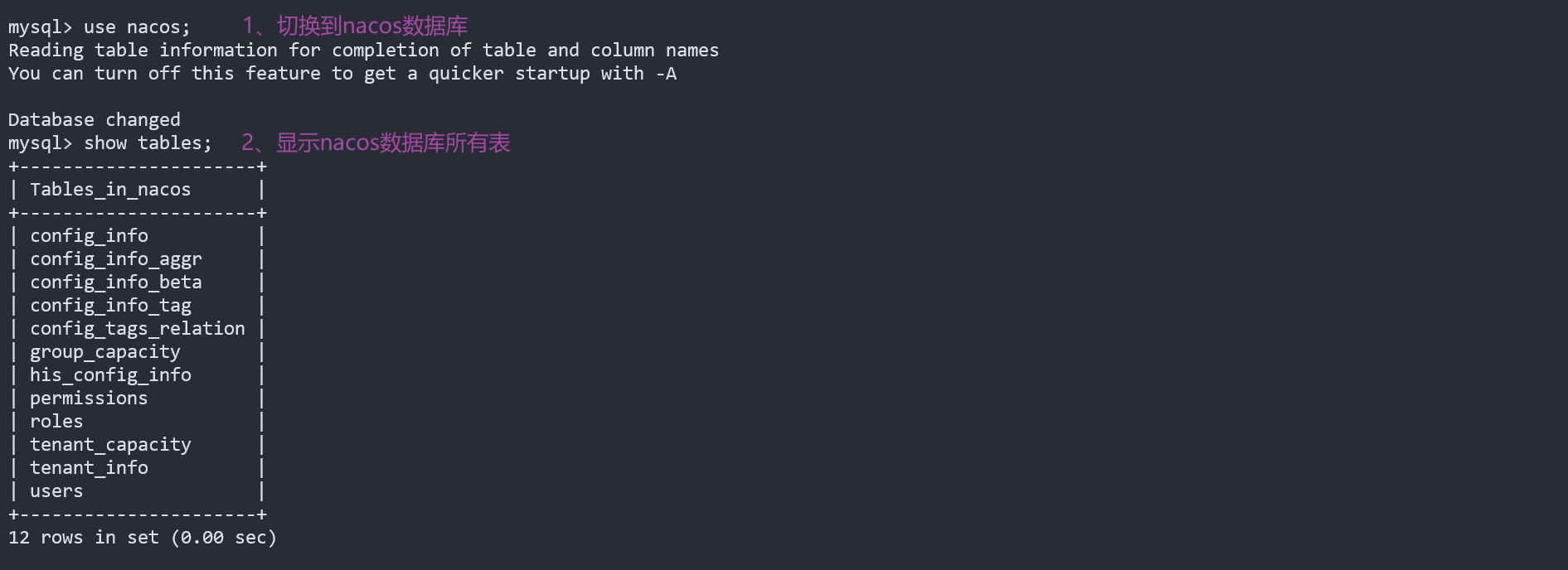
- 新增配置会保存在:nacos_config
- 历史配置会保存在:his_config_info
- 用户相关配置保存在:users
- 角色相关配置保存在:roles
- 权限相关配置保存在:permissions
监控方法可以配合prometheus以及grafana使用。关于nacos更多用法,目前还在摸索中。
下面这张流程图思路,可供参考:
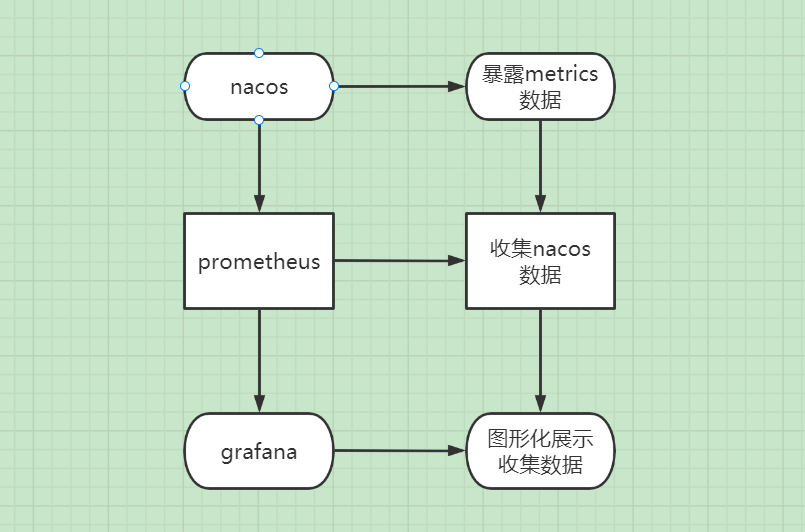
参考资料
:
- nacos2.x官方文档:
https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html
- nacos2.x github issues:
https://github.com/nacos-group/nacos-docker/issues/251
- MySQL8.0.x官方文档第6章节Security:
https://dev.mysql.com/doc/refman/8.0/en/access-control.html
最后,希望对你的工作有所帮助。如果觉得写得还不错,可以点个小小的赞。
以上总结仅供参考。
——END——