微服务 - 集群化 · 服务注册 · 健康检测 · 服务发现 · 负载均衡
集群化工具选择性很多,这里选 Consul 工具;官网:
https://www.consul.io
本篇计划用 Docker 辅助部署,所以需要了解点 Docker 知识;官网:
https://www.docker.com
一、Consul 概括
Consul 是由N多个节点
(台机/虚机/容器)
组成,每个节点中都有 Agent 运行着,各节点间用RPC通信,所有节点内相同的 Datacenter 名称为一个数据中心,节点又分三种角色 Client/Server/Leader:
- Agent:Consul 各成员节点的运行载体
- Client:不是必须存在的角色,数量也无上限,少量的资源开销,建议更多的 Client 角色存在。
- Server:必须的Server角色,每个Server下可多个Client,可以代替Client,对接收到的信息持久化;资源开销大,官方建议3/5台。
- Leader:一个数据中心内的 Server 选举产生一个 Leader 角色,将信息下发广播给所有 Server
默认端口
:
- 8500:Consul 对外提供注册查询UI等的专用端口
- 830x:Consul 内各节点间TCP/RPC等通信的专用端口
- 8600:Consul DNS 使用
- 21xxx:Consul 自动分配代理使用
整体架构示意图
:
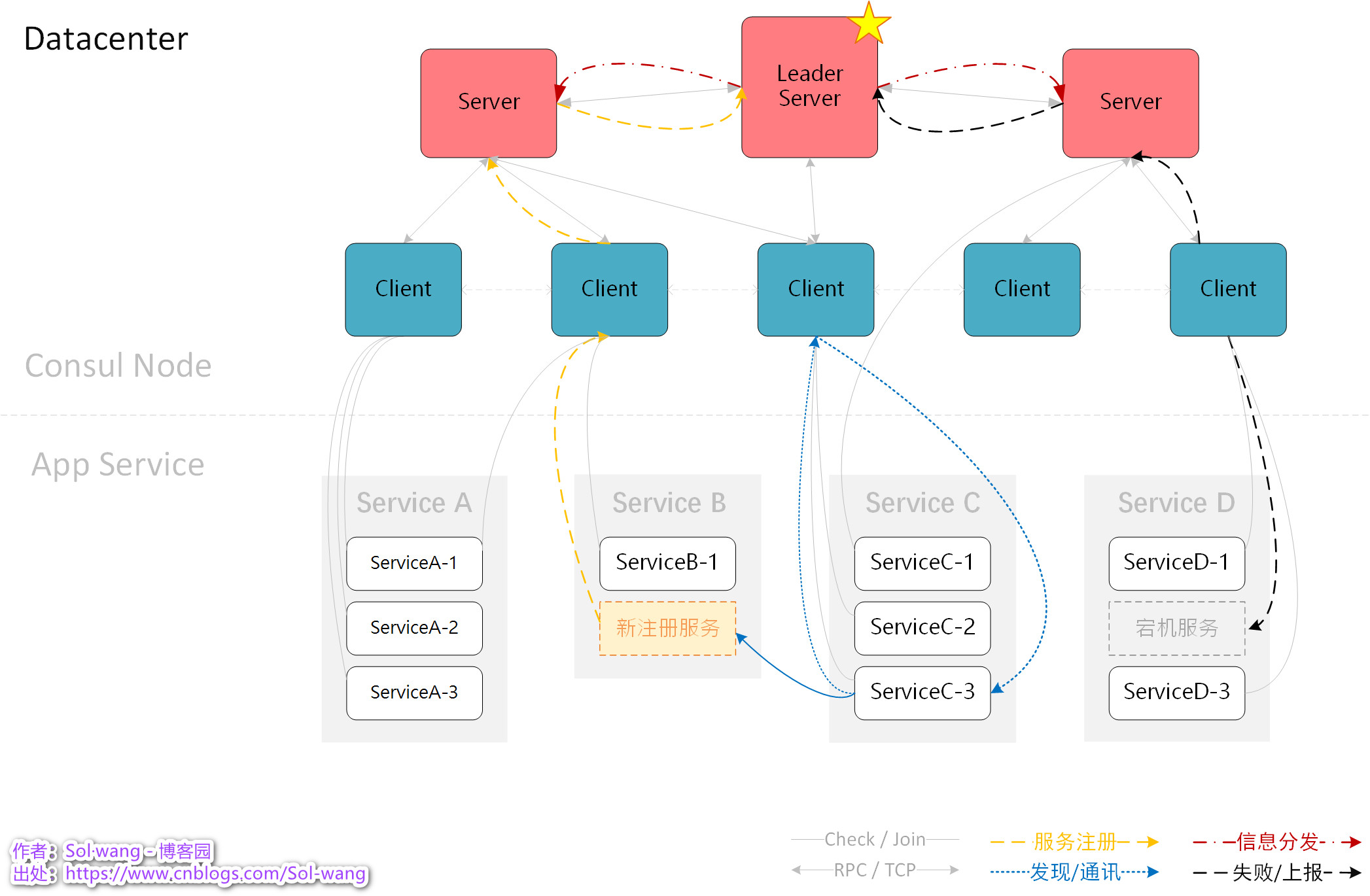
图解
:任意的 应用服务 Join 到任意的 Consul Node;任意的 Client Join 到任意的 Server;Node之间数据共享。
Consul 中的服务 与 注册的应用服务
Consul Node Server:是组成 Consul 整体运行的不可缺少的一种节点角色,注册于 Catalog 中,不如后续叫<
节点服务
>
Agent Register Service:是被 Consul 管理、发现、健康检测的目标业务应用,注册于 Agent 中,不如后续叫<
应用服务
>
作者:[
Sol·wang
] - 博客园,原文出处:
https://www.cnblogs.com/Sol-wang/p/17296278.html
二、Consul 功能
服务注册
所有的应用服务,都向 Consul 报告自己的存在及具体的信息;
新应用服务的加入,通过Client/Server上报给上级,直至Leader;Leader再向所有Server广播新服务的存在及具体信息,Consul 中所有节点共享新加入服务的信息;其中包括应用服务本身的连接及健康检测信息。
任何注销的应用服务,Consul 也会同步到各节点,关联的健康检测一并注销。
作者:[
Sol·wang
] - 博客园,原文出处:
https://www.cnblogs.com/Sol-wang
健康检测
Consul向各应用服务发起的连接过程,为了提供所有健康可用的应用服务,按提供的检测方式、检测地址、检测频率等,发起通信检测,识别服务状态,踢除异常及不可用的实例,保留健康可用的实例,并把结果上报给 Consul-Server/Leader。
检测方式分为:script / http / tcp / udp / ttl / rpc 等
比如:
脚本在各服务上的运行反馈
比如:
各服务提供HTTP请求的API
比如:
各服务提供TCP连接的端口
服务发现
在集群内外,任何想要连接集群内应用服务的信息,先通过 Consul-Server 拉取到健康可用的应用服务信息,才能连接到指定的应用服务;
新应用服务不断的注册/宕机/注销等,每个时间段所提供的各应用服务信息都可能是变化的;
这种 Consul-Server 提供的健康服务地址列表的过程,给出了所有可用的应用服务信息,就叫做服务发现。
比如:
Nginx需要知道[订单服务]的访问IP端口信息,才好转发请求
比如:
[订单服务]需要请求[产品服务]API,Consul提供了所有健康的[产品服务]访问IP端口信息,[订单服务]才能请求到[产品服务]API
按[订单]服务查询出健康可用的应用服务列表,屏蔽了异常状况的应用服务,达到了
故障转移
的效果。
K/V存储
动态的、可维护的、持久化的、键值对的存储方式;比较独立的一项Consul功能,我们可以把需要动态的内容放入KV中存储,它就像库一样,随时可变更查询。
key 唯一键;value 对应值;flags 64位整数可选值
GET 查询/列表
# 命令行 查询全部
consul kv get -recurse
# 命令行 查询单个[列表]
consul kv get [-detailed] {key}
# API 查询全部
curl http://{host}:8500/v1/kv/?recurse
# API 查询单个
curl http://{host}:8500/v1/kv/{key}PUT 新增/修改
# 命令行 新增/修改
consul kv put [-flags=13] {key} {value}
# API 新增/修改
curl -X PUT -d '{value}' http://{host}:8500/v1/kv/{key}[?flag=13]DELETE 删除/全部
# 命令行 删除一个
consul kv delete {key}
# 命令行 删除列表(全部)
consul kv delete -recurse [key/prefix]
# API 删除列表(全部)
curl -X DELETE http://{host}:8500/v1/kv/{key/prefix}[?recurse]更多相关API参考:
https://developer.hashicorp.com/consul/api-docs/kv
Datacenter
数据中心算是一个概念吧。。。
以上几点内容大致体现了 Consul 的运作方式,综合起来也就是一个范围集群的说法,其中会按 Datacenter 名称的不同,区分为多个数据中心。比如在不同的地域提供不同的数据中心,或者相同的数据中心互通,以做候选备用等。
三、集群相关
负载均衡
在集群中,每种应用服务都可能不止一个运行实例,订单服务A调用产品服务B,通过ConsulAPI给出的产品服务B可用地址会是多个,同样都是产品服务,有的资源已用90%,有的资源才用10%,为了避免这种资源利用不均匀,如何做到负载均衡呢?
常用方式:随机、轮询、最小连接、权重 等。
- 随机方式
:实现起来比较简单,在拉取到的应用服务数据列表中,随意挑一个使用就好 - 轮询方式
:需要有个全局变量,记录当前已用到哪个地址了,下标+1的方式取列表中下个健康的地址 - 最小连接
:记录每个应用服务实例当前已产生多少连接,每次使用最小已连接的实例做为本次的连接 - 权重方式
:配置应用服务实例在整体服务中所占的使用比例上限,每次连接后计算更新已连接的占比
当然,Consul未提供此功能,或用第三方或自己编写实现;
比如:
写一个负载均衡的类库,每个服务已连接次数记录在 Consul 的 KV 中,调用方给出要调用的服务组名,使用类库得出本次要请求的具体服务地址等。
熔断降级
Consul 并没有提供这样的功能,作为集群中不可忽视的点,这里只有粗略叙述,以作了解。
熔断:存在于请求方与应用服务之间,当应用服务异常次数达到指定值,下次请求就在熔断处直接返回,不用再连接到异常应用服务上。
降级:也就是备用方案的启用;比如:DB异常时,用缓存的数据;缓存异常时,或保留请求信息做延迟处理;或默认数据的返回等。
Snapshot
对于集群的灾难与备份,上述有提到多数据中心同步可达到备份的效果,Consul 的快照方式也是一个可选项:
# 命令行 生成快照
consul snapshot save {backup-name}.snap
# API 生成快照
curl http://{host}:8500/v1/snapshot?dc={dc-name} --output {backup-name}.snap
# 命令行 恢复快照
consul snapshot restore {backup-name}.snap
# API 恢复快照
curl -X PUT --data-binary @{backup-name}.snap http://{host}:8500/v1/snapshot
# 命令行 快照详细
consul snapshot inspect {backup-name}.snap定期生成快照
consul snapshot agent
仅企业版可用
四、Consul 部署
以下用 docker 部署,docker 拉取镜像:
docker pull consul
不管是 Client / Server / Leader 哪种角色,都是 Agent 运行起来的 Node;以下通过两种方式来创建维护 Consul Node:
命令行方式管理节点
Consul 中的每个节点都是用 Agent 运行的,创建节点的命令格式如下:
docker run -d --name={容器名称} -p 8500:8500 {image}
agent -server -ui -node={节点名称} -bootstrap-expect=3
下表列出了常用各参数的作用说明:
| agent | 必须;Consul 的应用,于每个节点中 |
| -server | 必须,服务角色;无:被视为Client角色 |
| -node | 必须;本节点名称 |
| -bootstrap-expect | 必须;定义Server角色的数量,必须够数,才能成为一个集群,否则集群不会运行 |
| -datacenter | 数据中心名称(群名称),默认 dc1 |
| -join | 加入的节点IP地址(Client/Server) |
| -retry-join | 尝试重新加入时的节点IP(Client/Server) |
| -data-dir | 指定运行时的数据存放目录 |
| -config-file | 使用指定的配置文件启动运行(文件内容与此表参数项作用相似) |
| -ui | 带管理Web页面;访问服务器IP http://{ip}:8500 进入页面管理方式 |
| -client | 连接限制,开放连接的客户端;浏览器连接打开UI、Client连接Server等 |
下面来部署一个 Consul Datacenter,计划有3个 Server 节点,3个 Client 节点。
创建3个 Server 节点
节点名称分别定为:ser-a / ser-b / ser-c;
由于 Datacenter 的默认值都是 dc1,所以就形成了一个名为 dc1 的数据中心。
# 第一个 Server Node,所以 Consul 会默认为 Leader 角色
docker run -d --name=cons-ser-a -p 8501:8500 consul agent -server -ui -node=ser-a -bootstrap-expect=3 -client=0.0.0.0
# 以下的 Server Node 都 Join 到 Leader Node 上
docker run -d --name=cons-ser-b -p 8502:8500 consul agent -server -node=ser-b -ui -client=0.0.0.0 -retry-join=172.17.0.2
docker run -d --name=cons-ser-c -p 8503:8500 consul agent -server -node=ser-c -ui -client=0.0.0.0 -retry-join=172.17.0.2起初创建 Leader Node 时
bootstrap-expect=3
,现在已经运行了3个 Server Node;
所以 Consul 已经启动完成并运转;可以打开UI界面:
http://{宿主机IP}:8501/
再创建3个 Client 节点
,并加入到不同的 Server Node
docker run -d --name=cons-cli-a -p 8511:8500 consul agent -node=cli-a -client=0.0.0.0 -retry-join=172.17.0.2
docker run -d --name=cons-cli-b -p 8512:8500 consul agent -node=cli-b -client=0.0.0.0 -retry-join=172.17.0.3
docker run -d --name=cons-cli-c -p 8513:8500 consul agent -node=cli-c -client=0.0.0.0 -retry-join=172.17.0.4以上节点的创建过程,是用宿主机的不同端口映射到各自容器节点的8500端口,所以用支持UI的对应宿主机端口都可以打开UI界面
计划的所有 Consul 节点创建完成,Consul 就是用这些节点来管理应用服务集群的,应用服务等后续再加入;以下先阐述节点的维护
查看 Datacenter 成员
# 命令行 列出所属 Datacenter 中的全部成员 [详细]
docker exec -t {容器名称} consul members [-detailed]
# 命令行 列出所属 Datacenter 中的 Server 角色成员
docker exec -t {容器名称} consul operator raft list-peersServer 加入到 Leader 下
# 如果要加 -datacenter 的话,必须与 join 参数目标的dc名称一致
docker run -d --name={容器名称} {image} agent -server -node={node-name} -join={leader-ip}Client 加入到 Server 下
# 创建时加入
docker run -d --name={容器名称} {image} agent -datacenter={有要一致} -node={name} -join {server-ip}
# 创建后加入
docker exec -t {容器名称} consul join {server-ip}下线指定节点
# 命令行 移除所处节点
consul leave
# 命令行 强制移除指定节点 [清楚未运行的节点]
consul force-leave {node-name} [-prune]不止命令行方式,Consul 也提供了 API 方式来管理节点。
API 方式管理节点
# API 列出所有成员
curl http://{host}:8500/v1/catalog/nodes
# API 加入新节点
# 参数文件 json 指明了节点名称/地址/端口等必要项
curl -X PUT -d @cli-d.json http://{host}:8500/v1/catalog/register
# API 注销节点
curl -X PUT -d '{"Datacenter":"dc1","Node":"cli-d"}' http://{host}:8500/v1//catalog/deregister有没有麻烦了点。。。 这种方式应该用的不多吧。。。
Consul 6个节点已部署完成,接下来该在 Consul Node 上部署微服务了。
五、应用服务部署
Consul Node 部署完成以后呢,剩下的就是告知 Consul 有哪些应用服务需要你管理,这告知 Consul 的方式有以下几种:
命令行方式注册服务
假设应用服务已经运行起来,然后按 Consul 定义的应用服务配置格式,编写配置文件,放到 Consul 任意节点的配置目录下,文件名称自定义,每次 Consul 启动的时候,都会读取配置目录下的所有文件。
配置内容也就是告诉 Consul 我是谁、我在哪、怎么与我联系、我的检测方式等;
1、配置示例格式如下:
{
"service": [
{
// 服务身份定义
"id": "AppService-Redis-aaaaa-bbbb-cccc-dddd-eeeee",
"name": "AppService-Redis",
"port": 80,
// 健康检测定义
"check": {
"id": "AppService-Redis-Check-TCP",
"name": "Redis Check TCP on port 80",
"tcp": "172.17.0.10:80",
"interval": "10s",
"timeout": "3s"
}
}
]
}2、重载此节点配置:
docker exec -t cons-ser-a consul reload
至此完成应用服务注册;如下效果图:

以上配置文件:有 Service 项 就是 服务注册,有 Check 项 就是 健康检测注册。
那。。。注销健康检测呢?注销服务呢?
删除 Check 项 就是注销健康检测;删除文件 就是 注销服务;记得重新加载配置
consul reload
API 方式注册服务
几乎命令行能做的事情,Consul 提供的 API 方式也可以做到。
假设应用服务已经运行起来了,同样是编写配置文件,以传参的方式请求注册的 API,完成 服务注册、健康注册、服务注销、健康注销等。
以下案例准备了服务注册所需的参数文件:AppService-kafka.json
{
"service": [
{
// 服务身份定义
"id": "AppService-Kafka-xxxxx-yyyy-zzzz-wwww-vvvvv",
"name": "AppService-Kafka",
"port": 80
}
]
}带文件参数请求注册服务的API接口:
curl -X PUT -d @AppService-kafka.json http://{host}:8500/v1/agent/service/register
当然,也可以单独请求注册健康检测的API接口:
curl -X PUT -d @AppService-health.json http://{host}:8500/v1/agent/check/register
同样的,API注销接口:
curl -X PUT http://{host}:8500/v1/agent/service/deregister/{app-service-id}
curl -X PUT http://{host}:8500/v1/agent/check/deregister/{app-check-id}
更所相关API接口参考官网:
https://developer.hashicorp.com/consul/api-docs
引用类库方式注册服务
1、
创建 .NET 项目
,并启用 Docker 方式,假设叫[订单服务],Nuget 安装 Consul
[订单服务]中必须要完成开发的事情:服务注册动作,健康检测定义,服务注销动作。
其实就是把 Consul 类库相关的参数赋值,由 Consul 类库自动完成注册/检测/注销。
2、
appsettings 相关配置
:
"Consul": {
"Service-Name": "AppService-Order",
"Service-Port": 80,
"Service-Health": "/Health",
// 应用服务 Join to Node Address
// 未来 Join 的 Node 不固定;所以 创建容器时 再传参
"Register-Address": null
}3、扩展 IApplicationBuilder
实现 注册/检测/注销
并启用
以下扩展方法创建后,并在管道中启用:
app.UseConsul(app.Configuration, app.Lifetime);
public static IApplicationBuilder UseConsul(this IApplicationBuilder app, IConfiguration conf, IHostApplicationLifetime lifetime)
{
// 取本机IP(告诉 Consul 健康检测的地址)
string? _local_ip = NetworkInterface.GetAllNetworkInterfaces()
.Select(p => p.GetIPProperties())
.SelectMany(p => p.UnicastAddresses)
.FirstOrDefault(p =>
p.Address.AddressFamily == AddressFamily.InterNetwork && !IPAddress.IsLoopback(p.Address)
)?.Address.ToString();
// 指明注册到的 Consul Node
var client = new ConsulClient(options =>
{
options.Address = new Uri(conf["Consul:Register-Address"]);
});
// 应用服务的 服务信息 / 健康检测
var registration = new AgentServiceRegistration
{
Name = conf["Consul:Service-Name"],
ID = $"Order-{Guid.NewGuid().ToString()}",
Address = _local_ip,
Port = Convert.ToInt32(conf["Consul:Service-Port"]),
Check = new AgentServiceCheck
{
Timeout = TimeSpan.FromSeconds(5),
Interval = TimeSpan.FromSeconds(10),
DeregisterCriticalServiceAfter = TimeSpan.FromSeconds(5),
HTTP = $"http://{_local_ip}:{conf["Consul:Service-Port"]}{conf["Consul:Service-Health"]}"
}
};
// 应用服务启动时 - 注册
lifetime.ApplicationStarted.Register(() =>
{
client.Agent.ServiceRegister(registration).Wait();
});
// 应用服务停止时 - 注销
lifetime.ApplicationStopping.Register(() =>
{
client.Agent.ServiceDeregister(registration.ID).Wait();
});
return app;
}4、
编写健康检测 API
这里健康检测选用 HTTP API 方式;为此,需要编写 WebApi。
# 服务中追加健康检测接口,供 Consul 调用
# 与 appsettings 配置保持一致的控制器
# 比较简单,达到通信正常,就被视为服务运行正常
public class HealthController : ControllerBase
{
[HttpGet]
public IActionResult Get()
{
return Ok();
}
}5、
生成 Docker 镜像并运行
每个应用服务都会运行多个实例,把已开发的[订单服务]用Docker运行多个实例,模仿集群环境:
# 项目根目录 生成 docker 镜像
docker build -t order.serv.cons:dev -f ./Order-Web/Dockerfile .
# docker 运行 [订单服务],这里运行2个吧(多实例)
# 还记得 appsettings 中的注册节点地址么...这里传参指明注册的节点
docker run -d --name=order-serv-cons.a -p 5001:80 order.serv.cons:dev --Consul:Register-Address='http://172.17.0.6:8500'
docker run -d --name=order-serv-cons.b -p 5002:80 order.serv.cons:dev --Consul:Register-Address='http://172.17.0.7:8500'测试验证效果
运行2个 [订单服务] 后的 Consul-UI 图示:

新的服务 AppService-Order 下有两个运行健康的实例,注册与检测都是类库帮助实现的,并显示出IP及注册节点。
相同的服务,有多个运行实例;不同的服务,组成完整的微服务集群;被 Consul 的6个 Node 时时管理着。
测试服务发现
1、Consul API 方式 指定服务的健康实例查询:
http://{host}:8501/v1/health/service/{service-name}?passing
2、Consul 类库方式 拉取指定服务的健康实例地址:
// 指明一个节点地址
var _consul_node = new ConsulClient(options =>{ options.Address = new Uri(_conf["Consul:Node-Address"]); });
// 向 Consul 拉取 指定服务 健康实例的列表
var _order_result = await _consul_node.Health.Service("AppService-Order", null, true, _query_options);
var _order_instance_list = _order_result.Response.Select(i => $"http://{i.Service.Address}:{i.Service.Port}");服务异常测试
docker 停止一个容器后,只剩一个运行实例:

当然,docker 容器再启动后,实例还会再回来。
服务间的相互调用,X服务 -> 订单服务,通过以上方式得出多个可用的实例地址,假如用轮询方式实现了
负载均衡
;
后续也可以把各应用服务的可用列表,时时的提供给网关(如Nginx),实现网关中的
负载均衡
。
Consul:Service Mesh & Gateways
consul connect proxy:集群代理,通过调用代理者的端口,实现与被代理者的连接(像是两台机的端口映射似的,被代理者端口不被暴露)
Consul Service Mesh:在多个集群和环境间建立连接,创建全球化的跨平台服务网络;下有多个Mesh Gateway,每个Mesh Gateway 下是 Datacenter。
待续...