Lambda
前言 之前在学校,老师说,最好不要使用jdk8的一些新特性....代码阅读不方便。
然后我天真的以为,是新特性不好用,是新特性阅读体验不好,所以,我就从未使用,也从未了解。
直到参加工作,发现了同事使用新特性,跟同事交流了这个新特性的事情,才知道是大学老师怕我们糊涂,于是在假日深入研究了一下
从JDK1.8开始为了简化使用者进行代码的开发,专门提供有Lambda表达式的支持,利用此操作可以实现函数式的编程,对于函数式编程比较著名的语言有:Haskell、Scala,利用函数式的编程可以避免掉面向对象编程之中一些繁琐的处理问题。
Lambda入门小案例:
这是我自己写的工具方法
public static int calculateNum(IntBinaryOperator operator){
int a = 10;
int b = 20;
return operator.applyAsInt(a, b);
}
在用这个方法的时候,发现参数的类型是 IntBinaryOperator ,那么就直接查看源码
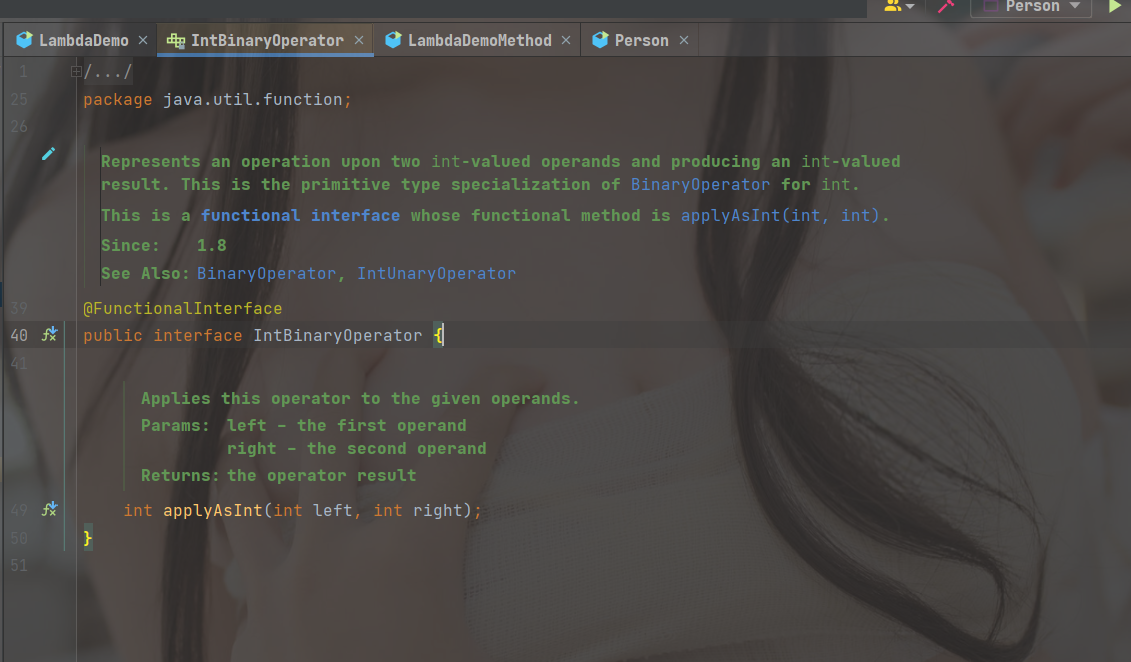
发现有个 方法叫applyAsInt ,含义就是说 接收 int 类型的 left、right 两个参数,最终我要返回得是 int 类型
那么我先用一个老式得方式来调用 这个 calculateNum 工具方法
// calculateNum 原始写法
/*
* IntBinaryOperator 是一个接口 在 idea 中,如果先写常规的语法的话,此时我想要用 Lambda 的话 ,
*/
int param = calculateNum(new IntBinaryOperator() {
@Override
public int applyAsInt(int left, int right) {
return left + right;
}
});
这是老式得写法了。
(小技巧:如果你使用得IDEA 那么可以使用 Alt + enter 快速生成匿名内部类 转变为Lambda表达式 或者 是Lambda表达式 生成匿名内部类)
那么我使用Lambda如何写呢?
int params = calculateNum( ( int a,int b) -> {
return a+b;
});
函数式接口 Functional Interface
抛出一个疑问:在我们书写一段 Lambda 表达式后(比如上一章节中匿名内部类的 Lambda 表达式缩写形式),Java 编译器是如何进行类型推断的,它又是怎么知道重写的哪个方法的?
需要说明的是,不是每个接口都可以缩写成 Lambda 表达式。只有那些函数式接口(Functional Interface)才能缩写成 Lambda 表示式。
那么什么是函数式接口(Functional Interface)呢?
所谓函数式接口(Functional Interface)
就是只包含一个抽象方法的声明
。针对该接口类型的所有 Lambda 表达式都会与这个抽象方法匹配。
注意:你可能会有疑问,Java 8 中不是允许通过 defualt 关键字来为接口添加默认方法吗?那它算不算抽象方法呢?答案是:不算。因此,你可以毫无顾忌的添加默认方法,它并不违反函数式接口(Functional Interface)的定义。
总结一下:只要接口中仅仅包含一个抽象方法,我们就可以将其改写为 Lambda 表达式。为了保证一个接口明确的被定义为一个函数式接口(Functional Interface),我们需要为该接口添加注解:
@FunctionalInterface
。这样,一旦你添加了第二个抽象方法,编译器会立刻抛出错误提示。
示例代码:
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
注意:上面的示例代码,即使去掉
@FunctionalInterface
也是好使的,它仅仅是一种约束而已。
Lambda错误示例
interface IMessage {
public void send(String str);
public void say();
}
public class JavaDemo {
public static void main(String[] args) {
IMessage i = (str) -> {
System.out.println(str);
};
i.send("www.baidu.com");
}
}

Lambda表达式的几种格式
- 方法没有参数: () -> {};
- 方法有参数::(参数,…,参数) -> {};
demo
package com.yhn.Lambda;
import java.util.function.Function;
import java.util.function.IntBinaryOperator;
import java.util.function.IntConsumer;
import java.util.function.IntPredicate;
/**
一、什么情况下可以使用 Lambda 表达式?
Lambda表达式如果要想使用,那么必须要有一个重要的实现要求:SAM(Single Abstract Method),接口中只有一个抽象方法。
以IMessage接口为例,这个接口里面只是提供有一个send()方法,
interface IMessage {
public void send(String str);
}
除此之外没有任何其他方法定义,所以这样的接口就被称为函数式接口,
而只有函数式接口才能被Lambda表达式所使用。
二、 Lambda 表达式的格式
Lambda 表达式在Java语言中引入了一个操作符**“->”**,该操作符被称为Lambda操作符或箭头操作符。它将Lambda分为两个部分:
左侧:指定了Lambda表达式需要的所有参数
右侧:制定了Lambda体,即Lambda表达式要执行的功能。
方法没有参数: () -> {};
方法有参数::(参数,…,参数) -> {};
省略规则
参数类型可以省略
方法体只有一句代码时大括号return和唯一一句代码的分号可以省略
方法只有一个参数时小括号可以省略
以上这些规则都记不住也可以省略不记
*
*/
public class LambdaDemo {
public static void main(String[] args) {
printNum2(value -> value % 2 == 0, value -> value>4);
/* ------------------------------------------------------------------------------------------ */
// calculateNum 原始写法
/*
* IntBinaryOperator 是一个接口 在 idea 中,如果先写常规的语法的话,此时我想要用 Lambda 的话 ,
* 可以使用 Alt + enter 快速生成匿名内部类 转变为Lambda表达式 或者 是Lambda表达式 生成匿名内部类
*/
int param = calculateNum(new IntBinaryOperator() {
@Override
public int applyAsInt(int left, int right) {
return left + right;
}
});
// 使用 Lambda 写法
int params = calculateNum( ( int a,int b) -> {
return a+b;
});
/* ------------------------------------------------------------------------------------------ */
/*
* printNum IntPredicate 接口只有一个方法 test
*/
printNum(new IntPredicate() {
@Override
public boolean test(int value) {
return value%2==0;
}
});
printNum( (int a) -> {
return a%2 == 0;
});
/* ------------------------------------------------------------------------------------------ */
// 先解释 Function<T, R> 接口 - > Function<String, R>
// Function 接口 有个方法叫 apply 含义就是说 R 传什么类型 , 我最终都是要返回的是 T 类型 在此处是 String 类型
// 此时 我只需要 设定一个泛型即可
Integer result = typeConver(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.valueOf(s);
}
});
Integer results = typeConver( (String s) ->{
return Integer.valueOf(s);
});
// 扩展
String s1 = typeConver(s -> {
return s + "new";
});
/* ------------------------------------------------------------------------------------------ */
foreachArr(new IntConsumer() {
@Override
public void accept(int value) {
System.out.println(value);
}
});
foreachArr((int value ) -> {
System.out.println(value);
});
// 进行省略
foreachArr( value -> System.out.println(value));
/* ------------------------------------------------------------------------------------------ */
}
public static void foreachArr(IntConsumer consumer){
int[] arr = {1,2,3,4,5,6,7,8,9,10};
for (int i : arr) {
consumer.accept(i);
}
}
public static <R> R typeConver(Function<String,R> function){
String str = "1235";
R result = function.apply(str);
return result;
}
public static void printNum2(IntPredicate predicate,IntPredicate predicate2){
int[] arr = {1,2,3,4,5,6,7,8,9,10};
for (int i : arr) {
if(predicate.and(predicate2).test(i)){
System.out.println(i);
}
}
}
public static void printNum(IntPredicate predicate){
int[] arr = {1,2,3,4,5,6,7,8,9,10};
for (int i : arr) {
if(predicate.test(i)){
System.out.println(i);
}
}
}
public static int calculateNum(IntBinaryOperator operator){
int a = 10;
int b = 20;
return operator.applyAsInt(a, b);
}
}
总结:
Lambda 表达式在Java语言中引入了一个操作符
“->”
,该操作符被称为Lambda操作符或箭头操作符。它将Lambda分为两个部分:
左侧:指定了Lambda表达式需要的所有参数
右侧:制定了Lambda体,即Lambda表达式要执行的功能。
方法没有参数: () -> {};
方法有参数::(参数,…,参数) -> {};
省略规则
参数类型可以省略
方法体只有一句代码时大括号return和唯一一句代码的分号可以省略
方法只有一个参数时小括号可以省略
以上这些规则都记不住也可以省略不记
方法引用
方法引用的三种形式
对象 :: 非静态方法
类 :: 静态方法
类 :: 非静态方法
类引用静态方法
语法格式: 类名称::static方法名称
第一步,我们自定义一个接口,该接口中只有一个抽象方法,是一个函数式接口。
第二步,随便建立一个类,创建一个方法。这里要注意,创建的方法返回值类型和形参列表必须和函数式接口中的抽象方法相同。
第三步,创建函数式接口的实现类,我们可以使用方法引用。相当于实现类里的重写的方法,就是方法引用的方法。这样才能方法引用。
public class LambdaDemoLei {
/**
* @FunctionalInterface,主要用于编译级错误检查,加上该注解,当你写的接口不符合函数式接口定义的时候,编译器会报错。
*/
@FunctionalInterface
interface IMessage<T,P> {
public T transfer(P p);
}
static class Supplier{
public static String getStr(Integer integer) {
return String.valueOf(integer);
}
}
public static void main(String[] args) {
// 类引用静态方法 类名称::static方法名称
IMessage<String, Integer> msg = Supplier::getStr;
System.out.println(msg.transfer(31415926));
}
// 输出 31415926
对象引用非静态方法
语法格式: 实例化对象::普通方法;
有了类引用静态方法的基础,相信大家已经有了一点感觉。
对象引用非静态方法,和类引用静态方法一致。要求我们对象引用的方法,返回值和形参列表要和函数式接口中的抽象方法相同。
public class LambdaDemoLei {
@FunctionalInterface
interface IMessage1 {
public double get();
}
static class Supplier1{
private Double salary;
public Supplier1() {
}
public Supplier1(Double salary){
this.salary = salary;
}
public Double getSalary() {
return this.salary;
}
}
public static void main(String[] args) {
// 对象引用非静态方法 语法格式: 实例化对象::普通方法
Supplier1 supplier = new Supplier1(9999.9);
IMessage1 msg1 = supplier::getSalary;
System.out.println(msg1.get());
}
// 输出 9999.9
}
类引用非静态方法
语法格式: 类::普通方法
类引用普通方法就有点难以理解了。
当抽象方法中有两个参数,且第一个参数是调用者,第二个参数是形参,则可以使用类::实例方法。
package com.yhn.Lambda;
import lombok.Data;
/**
* @Description
* @Author TuiMao
* @Date 2023/4/4 16:19
* @Version 1.0
*/
@Data
public class Person {
@FunctionalInterface
interface IMessage<T, P> {
// 要看成 T res = p1.compare(p2);
public T compare(P p1, P p2);
}
@FunctionalInterface
interface IMessage2<T, P, V> {
// public T create(P p1, V p2); 符合抽象方法的要求
public T create(P p1, V p2);
}
@FunctionalInterface
interface IMessage1<T, P, V> {
// 看成 T res = p1.compare(p2);
// public int compareTo(String anotherString){} 符合抽象方法的格式
// int res = str1.compare(str2);
public T compare(P p1, V p2);
}
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
private String name;
private Integer age;
public boolean equal(Person per) {
return this.name.equals(per.getName()) && this.age.equals(per.getAge());
}
public static void main(String[] args) {
Person person1 = new Person("张三", 22);
Person person2 = new Person("张三", 23);
// 符合T res = p1.compare(p2);
IMessage<Boolean, Person> msg = Person::equal;
System.out.println(msg.compare(person1, person2));
System.out.println("----------");
// 类引用普通方法 语法格式: 类::普通方法 当抽象方法中有两个参数,且第一个参数是调用者,第二个参数是形参,则可以使用类::实例方法。
IMessage1<Integer,String,String> stringCompare = String::compareTo;
Integer compare = stringCompare.compare("adc", "abd");
System.out.println(compare);
System.out.println("----------");
// 构造引用 语法格式: 类名称::new
IMessage2<Person,String,Integer> msg1 = Person::new;
Person person = msg1.create("张三", 20);
System.out.println(person);
}
}
Lambda 访问外部变量及接口默认方法
在本章节中,我们将会讨论如何在 lambda 表达式中访问外部变量(包括:局部变量,成员变量,静态变量,接口的默认方法.),它与匿名内部类访问外部变量很相似。
访问局部变量
在 Lambda 表达式中,我们可以访问外部的
final
类型变量,如下面的示例代码:
// 转换器
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
final int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3
与匿名内部类不同的是,我们不必显式声明
num
变量为
final
类型,下面这段代码同样有效:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3
但是
num
变量必须为隐式的
final
类型,何为隐式的
final
呢?就是说到编译期为止,
num
对象是不能被改变的,如下面这段代码,就不能被编译通过:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
num = 3;
在 lambda 表达式内部改变
num
值同样编译不通过,需要注意, 比如下面的示例代码:
int num = 1;
Converter<Integer, String> converter = (from) -> {
String value = String.valueOf(from + num);
num = 3;
return value;
};
访问成员变量和静态变量
上一章节中,了解了如何在 Lambda 表达式中访问局部变量。与局部变量相比,在 Lambda 表达式中对成员变量和静态变量拥有读写权限:
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
class Lambda4 {
// 静态变量
static int outerStaticNum;
// 成员变量
int outerNum;
void testScopes() {
Converter<Integer, String> stringConverter1 = (from) -> {
// 对成员变量赋值
outerNum = 23;
return String.valueOf(from);
};
Converter<Integer, String> stringConverter2 = (from) -> {
// 对静态变量赋值
outerStaticNum = 72;
return String.valueOf(from);
};
}
}
访问接口的默认方法
@FunctionalInterface
interface Formula {
// 计算
double calculate(int a);
// 求平方根
default double sqrt(int a) {
return Math.sqrt(a);
}
}
当时,我们在接口中定义了一个带有默认实现的
sqrt
求平方根方法,在匿名内部类中我们可以很方便的访问此方法:
Formula formula = new Formula() {
@Override
public double calculate(int a) {
return sqrt(a * 100);
}
};
但是在 lambda 表达式中可不行:
Formula formula = (a) -> sqrt(a * 100);
带有默认实现的接口方法,是
不能
在 lambda 表达式中访问的,上面这段代码将无法被编译通过。
JDK8自带函数式接口
在JDK1.8之中,提供有Lambda表达式和方法引用,但是你会发现如果由开发者自己定义函数式的接口,往往都需要使用@FunctionalInterface来进行大量的声明,于是很多的情况下如果为了方便则可以引用系统中提供的函数式接口。
在系统之中专门提供有一个java.util.functional的开发包,里面可以直接使用函数式接口,在这个包下面一共有如下几个核心的接口供我们使用。
功能型函数式接口
|
接口定义
|
接口作用
|
接口使用
|
@FunctionalInterface
public interface Function<T,R> |
消费 T 类型参数,返回 R 类型结果 |
如下所示 |
function 相当于是给一个参数,然后返回一个结果。
如果是给两个参数,返回一个结果,那么就是 BiFunction。Bi 前缀即使 binary 的缩写。
import java.util.function.*;
/*
@FunctionalInterface
T是参数类型
R是返回类型
public interface Function<T,R>{
public R apply(T t);
}
*/
class StringCompare {
// 给一个 String 类型的参数,返回布尔类型,符合功能性函数式接口的抽象方法
public static boolean test(String t) {
return t == null;
}
}
public class JavaDemo {
public static void main(String[] args) {
// 直接静态引用
Function<String,Boolean> func1 = StringCompare::test;
System.out.println(func1.apply(null));
}
}
// true
消费型函数式接口
消费性函数式接口,只能进行数据的处理操作,而没有返回值
· 在进行系统输出的时候使用的是:System.out.println();这个操作只是进行数据的输出和消费,而不能返回,这就是消费性接口。
|
接口定义
|
接口作用
|
接口使用
|
@FunctionalInterface
public interface Consumer |
接收一个 T 类型参数,但是不返回任何东西,消费型接口 |
如下 |
其实最常见的消费型接口的实现,就是 System.out.println(xxx) 了。 我们只管往方法中输入参数,但是并没有返回任何值。
Consumer 相当于是有来无回,给一个参数,但是无返回。
而如果是两个参数,无返回,那么就是 BiConsumer。
public class JavaDemo {
public static void main(String[] args) {
Consumer<String> consumer = System.out::println;
consumer.accept("Hello World!");
}
}
// Hello World!
当然我们也可以自定义消费性接口
class StringCompare {
// 接收 StringBuilder ,但是不返回任何数据。
public void fun(StringBuilder sb) {
sb.append("World!");
}
}
public class JavaDemo {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
sb.append("Hello ");
Consumer<StringBuilder> consumer = new StringCompare()::fun;
consumer.accept(sb);
System.out.println(sb.toString());
}
}
供给型函数式接口
|
接口定义
|
接口作用
|
接口使用
|
@FunctionalInterface
public interface Supplier |
啥也不接受,但是却返回 T 类型数据,供给型接口 |
如下 |
Supplier 相当于是无中生有,什么也不传,但是返回一个结果。
像 String 类里的 toUpperCase() 方法,也是不接受参数,但是返回 String 类型,就可以看成这个供给型函数式接口的一个实现。
public String toUpperCase() {
return toUpperCase(Locale.getDefault());
}
import java.util.function.*;
public class Demo01 {
public static void main(String[] args) {
Supplier <String> sup = "WWW.BAIDU.COM" :: toLowerCase;
System.out.println(sup.get());
}
}
断言型函数式接口
|
接口定义
|
接口作用
|
接口使用
|
| @FunctionalInterface public interface Predicate |
传入 T 类型参数,返回布尔类型,常常用于对入参进行判断 |
如下 |
class StringFilter {
// 对集合中的数据进行过滤,传入断言型接口进行判断
public static List<String> filter(List<String> list, Predicate<String> predicate) {
List<String> stringList = new ArrayList<>();
for (String str : list) {
if (predicate.test(str)) {
stringList.add(str);
}
}
return stringList;
}
}
public class JavaDemo {
public static void main(String[] args) {
List<String> stringList = Arrays.asList("好诗", "好文", "好评", "好汉", "坏蛋", "蛋清", "清风", "风间");
List<String> filterList = StringFilter.filter(stringList, list -> list.contains("好"));
System.out.println(filterList);
}
}
如果JDK本身提供的函数式接口可以被我们所使用,那么就没必要重新去定义了。