白嫖一个月的ES,完成了与MySQL的联动
前言
《腾讯云 x Elasticsearch三周年》活动来了。文章写之前的思路是:在腾讯云服务器使用docker搭建ES。但是理想很丰满,显示很骨感,在操作过程中一波三折,最后还是含着泪美滋滋地,白嫖了一个月的腾讯云ES服务。
最后就是利用腾讯云的Elasticsearch和Kibana,和我在腾讯云服务器上搭建MySQL进行了一波联动,完成了数据库内部指标的展示。

<服务器搭建ES>
部分只用作记录,可以忽略直接看
<腾讯云领取ES的活动>
进行后续操作。
一. 服务器搭建ES
1.拉取ES镜像
本来想自己编写dockerfile生成镜像,没成想ES官网提供了docker镜像,这里就使用官方镜像,操作文档参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.6.2

2. 修改Linux系统句柄
# 在 /etc/sysctl.conf 末尾添加
vm.max_map_count=262144
修改之后重启或者使用以下命令使其生效:
/sbin/sysctl -p
3. 修改文件句柄和进程限制
# 在 /etc/security/limits.conf 末尾添加
* soft nofile 65536
* hard nofile 65536
4. docker安装
docker我也是提前安装好了,可以参考我之前的文章
yum -y install docker-ce
如果安装集群,还需要安装docker-compose,官网提供了此种安装方式,但是我的服务内存实在太小,尝试几次之后就果断放弃了。
单节点ES搭建
启动ES的时候,会自动启用安全认证配置,包括:
- 生成安全证书:http_ca.crt
- elasticsearch.yml.:TLS(Transport Layer Security)配置
- ES用户密码
- Kibana的注册token
1. 启动单节点ES
# 创建es网络
docker network create elastic

2. 启动单节点ES
# 启动单节点ES
docker run --name es01 --net elastic -p 9200:9200 -it docker.elastic.co/elasticsearch/elasticsearch:8.6.2
在启动单节点ES的时候,终端会打印一个用户密码(用户名:
elastic
),和一个注册Kibana用的token。因为只会在第一次启动时输出,所以要保存好。

这里使用的是前台启动,在保存好密码之后,再使用docker start后台启动容器。
3. 安全证书
执行命令将http_ca.crt拷贝到宿主机。
docker cp es01:/usr/share/elasticsearch/config/certs/http_ca.crt .
4. 验证
使用下载的安全证书和用户密码访问ES服务。
curl --cacert http_ca.crt -u elastic https://localhost:9200
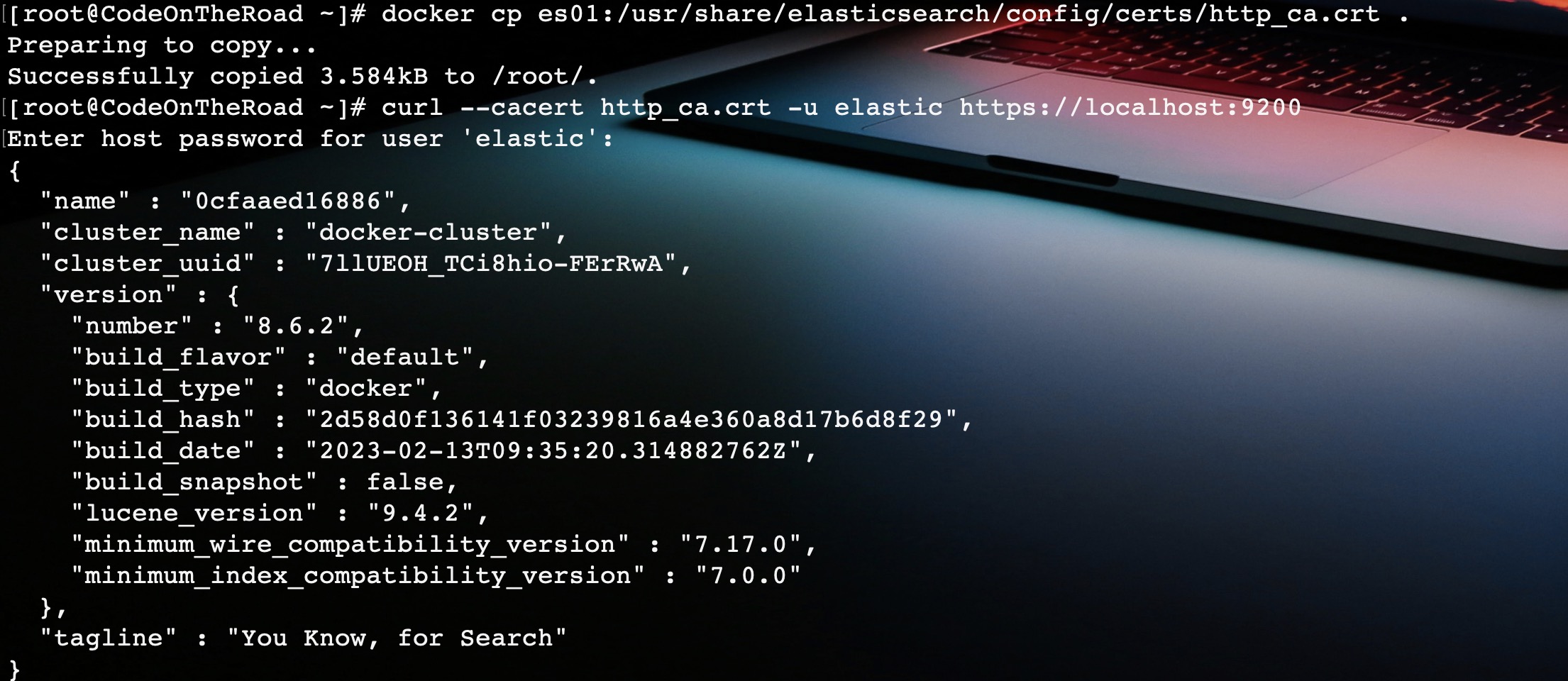
至此,ES搭建完成。
外网无法访问服务器Docker中的ES
测试外网无法访问服务器中的ES,需要修改以下配置:
# /etc/sysctl.conf 默认为0,修改成1
net.ipv4.ip_forward = 1
重启网络和es:
systemctl restart network
docker restart es01
这样就可以外网访问到ES了。
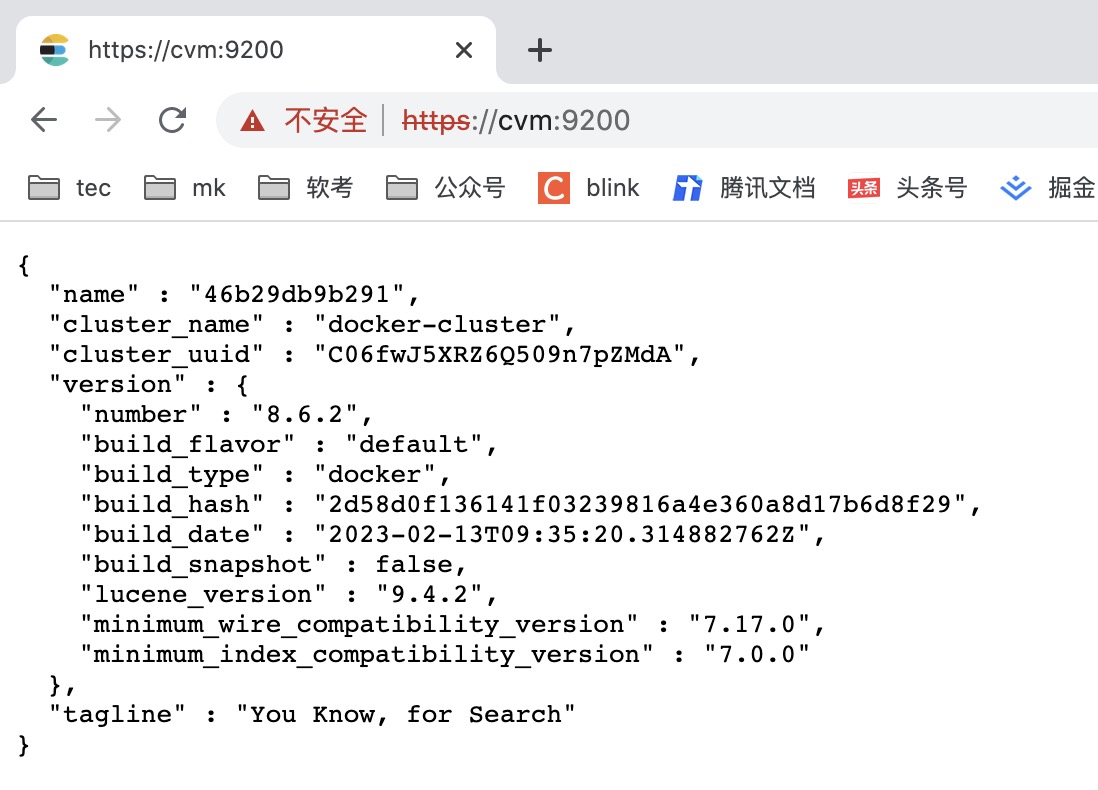
Kibana安装
docker pull docker.elastic.co/kibana/kibana:8.6.2
docker run --name kib-01 --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.6.2
启动Kibana的时候会输出一个地址,去浏览器中配置。
复制ES启动时生成的token填入。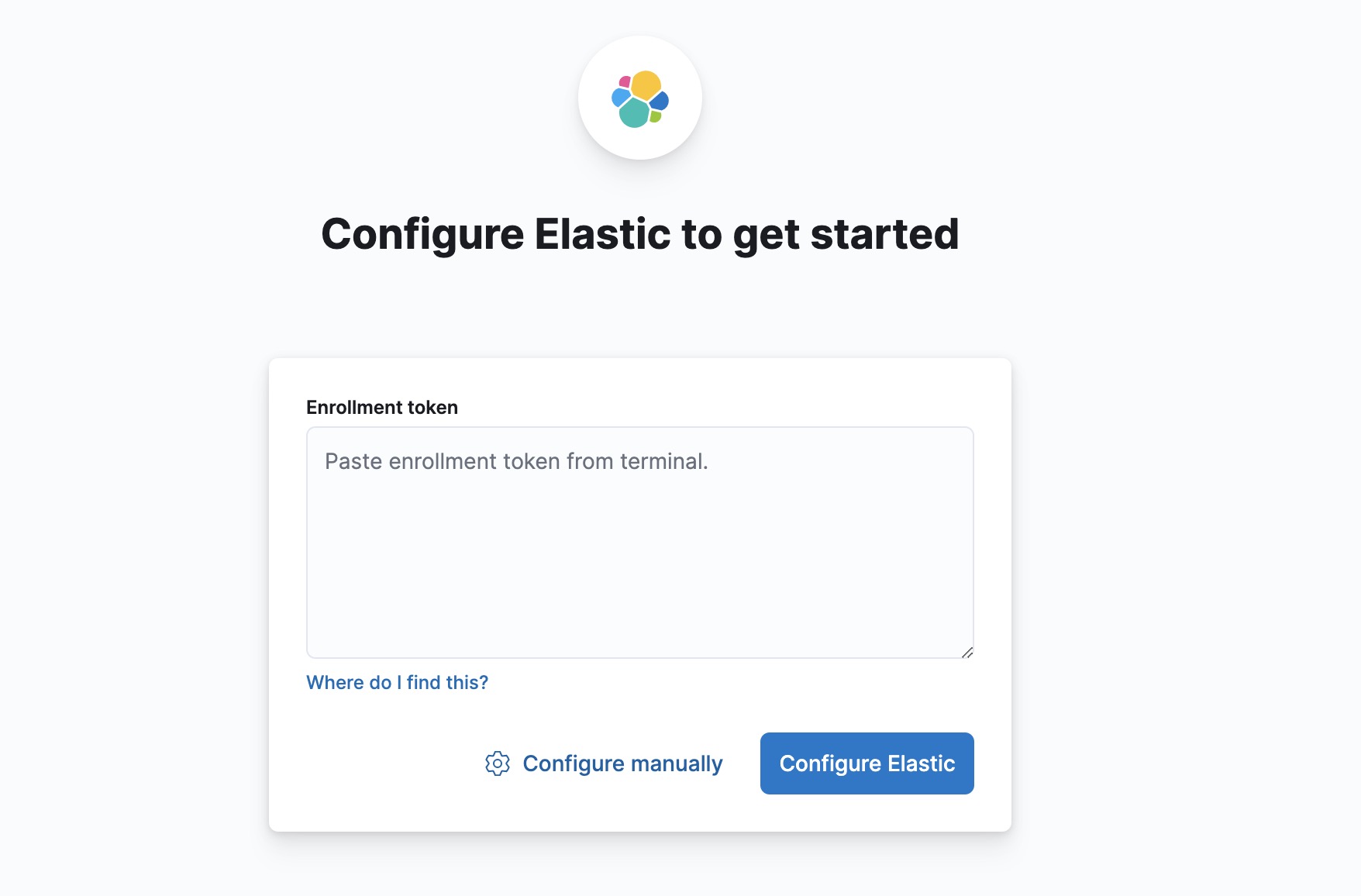
token过期了,可以再生成一个。
docker exec -it es01 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
花了老大的劲才忙活到这儿,™然后启动kibana就CPU狂飙,丐版服务器终究错付。搞了一下午无果,决定还是去腾讯云看看能不能白嫖。

二. 腾讯云ES0元活动
果然到有ES白嫖一月的活动,呜呜呜呜。觉得自己是个铁憨憨。
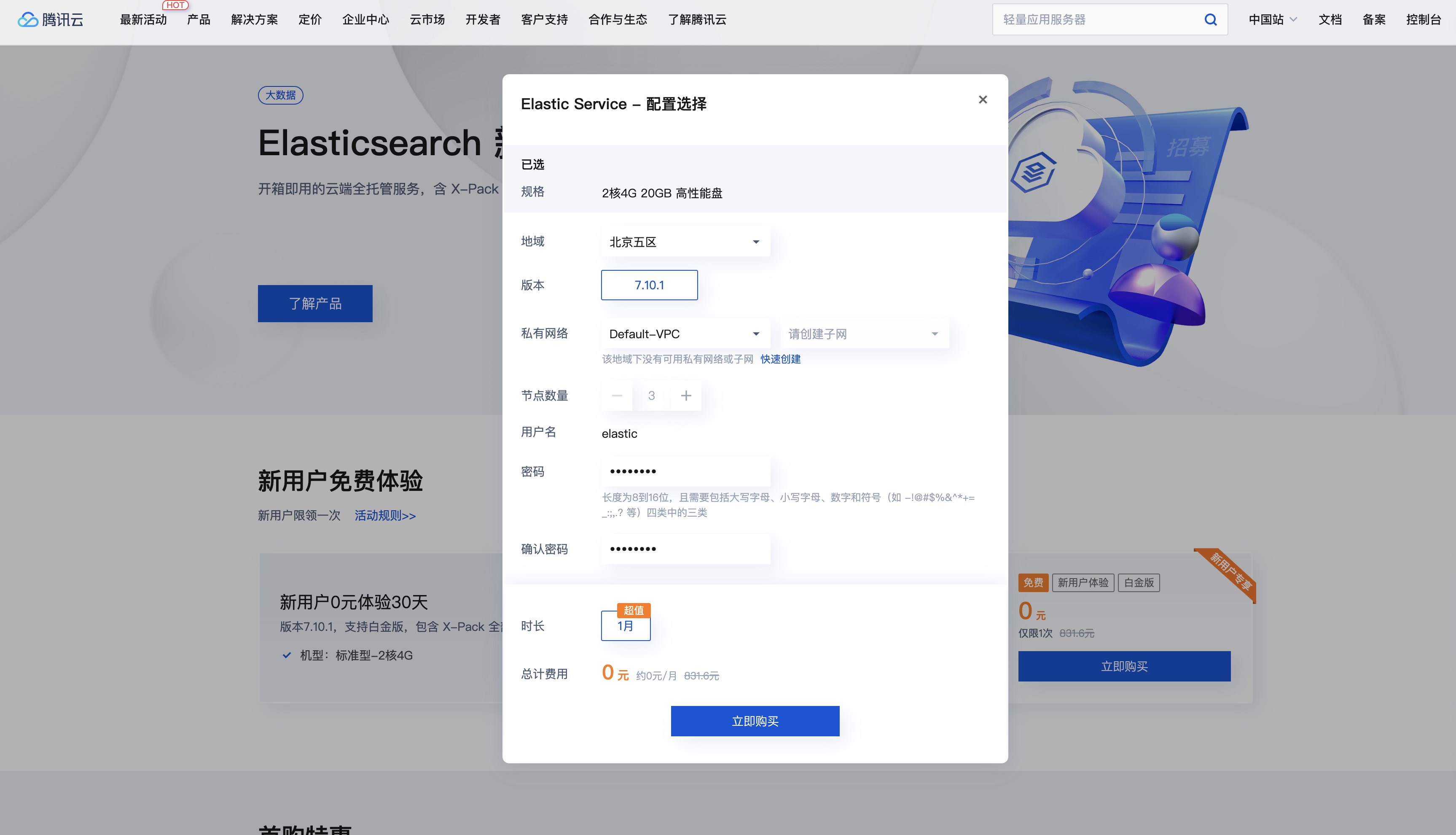
购买付款。

两分钟完事儿,进入控制台。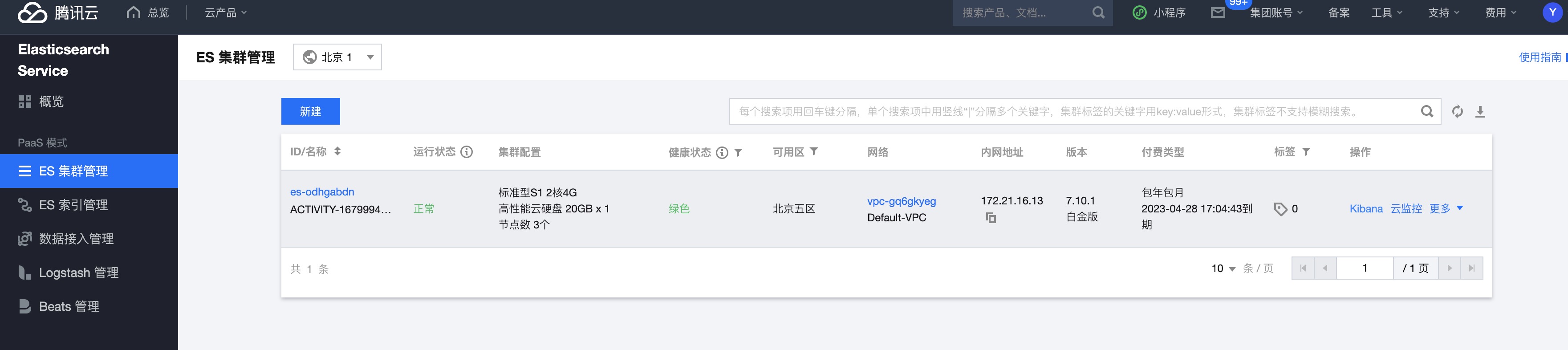
可以看到集群已经分配好,查询集群架构可以发现一共三个ES、一个Kibana。

在
可视化配置
中添加本机的IP到白名单,就可以访问Kibana。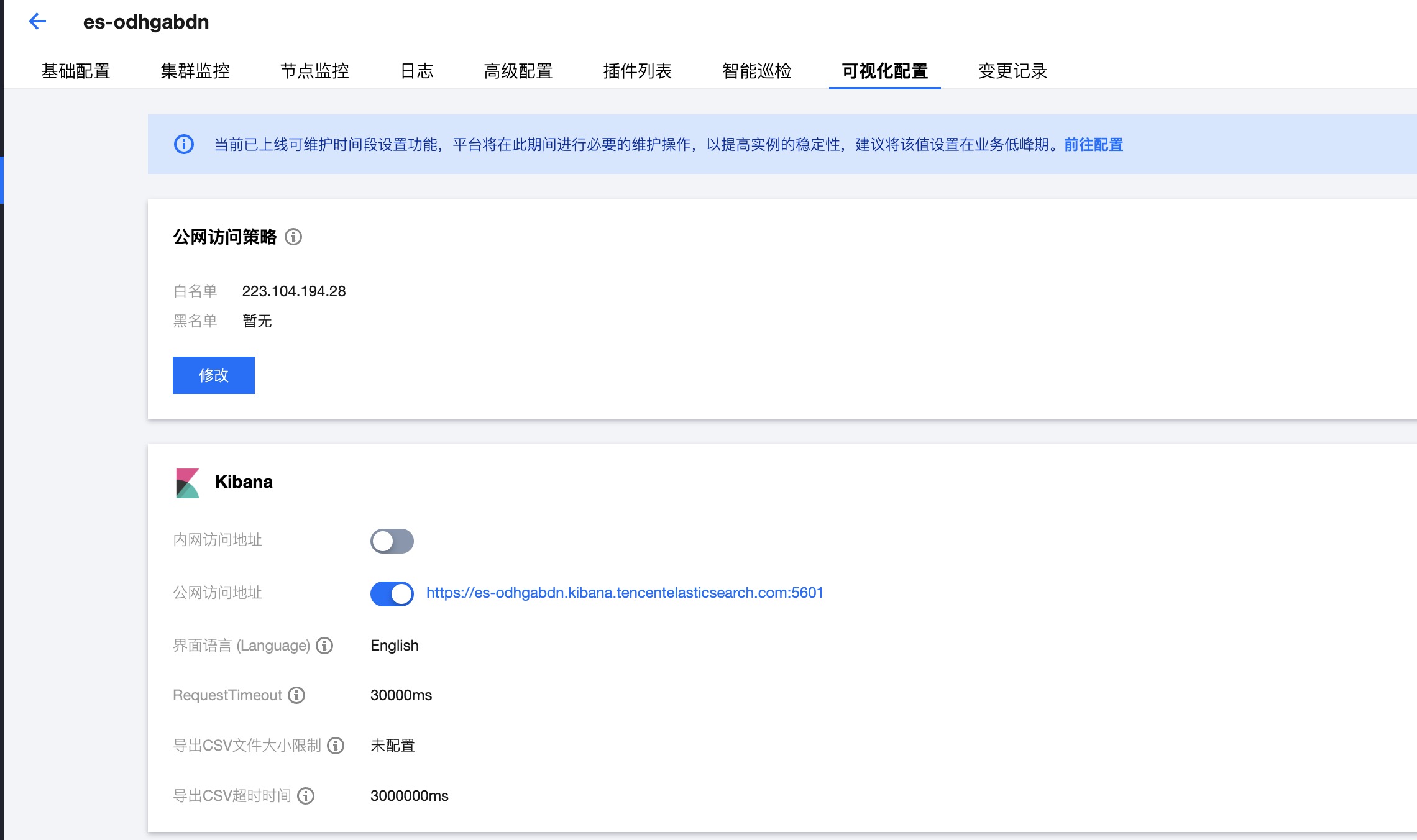
点击公网访问地址,进入Kibana。
三.实践应用
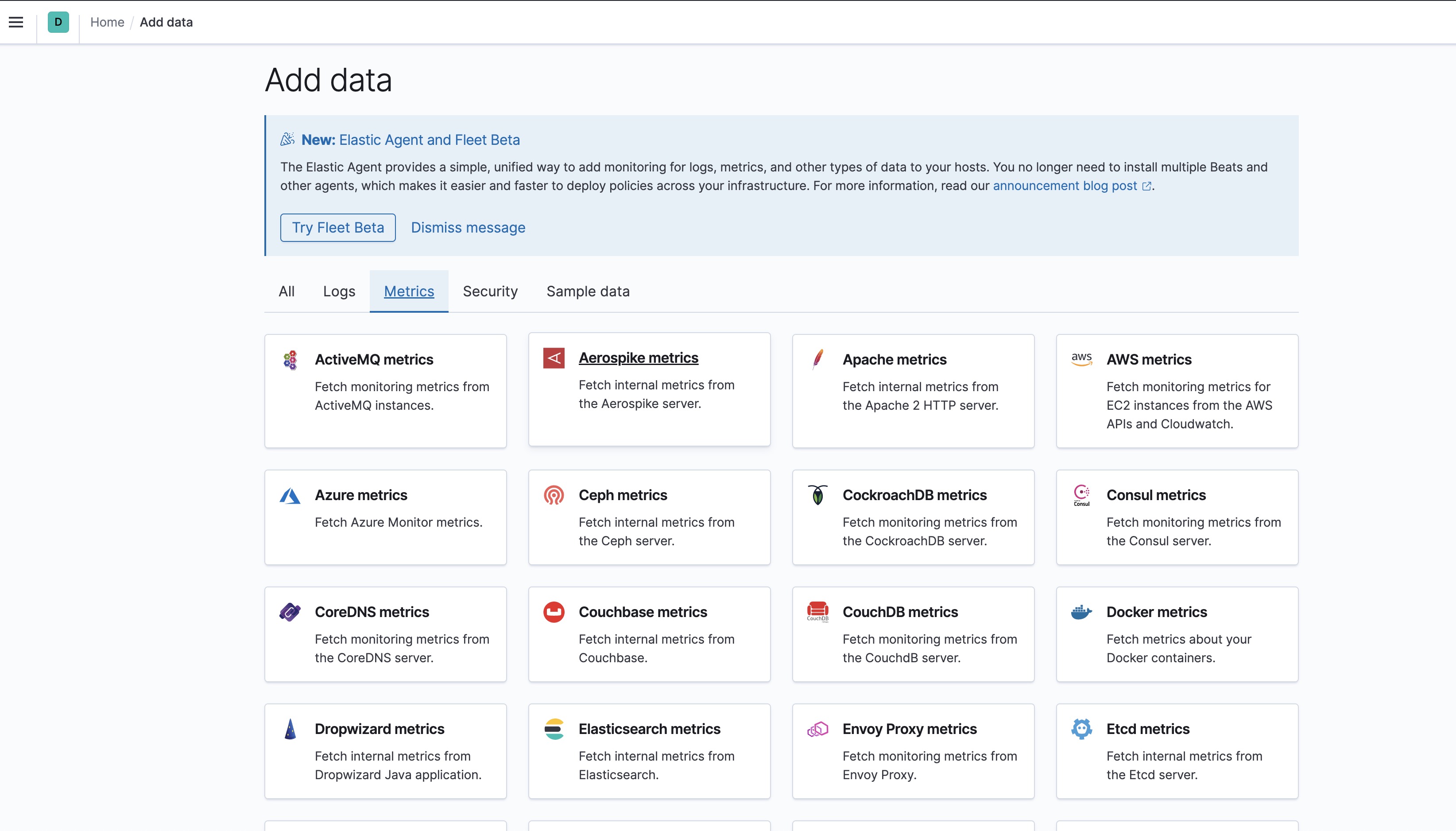
1. 添加数据
在Kibana首页,进入
Add data
,可以添加很多种类数据源。这里挑选进行操作
2. MySQL Metrics
选择
MySQL metrics
,这个可以获取MySQL的内部指标。首先下载
metricbeat
。然后根据官方步骤完成配置:
- 修改
metricbeat.yml
中的es和kibana的配置

- 修改
modules.d/msyql.yml
中的mysql的配置,把query那行注释掉,否则会报错。
官方操作文档: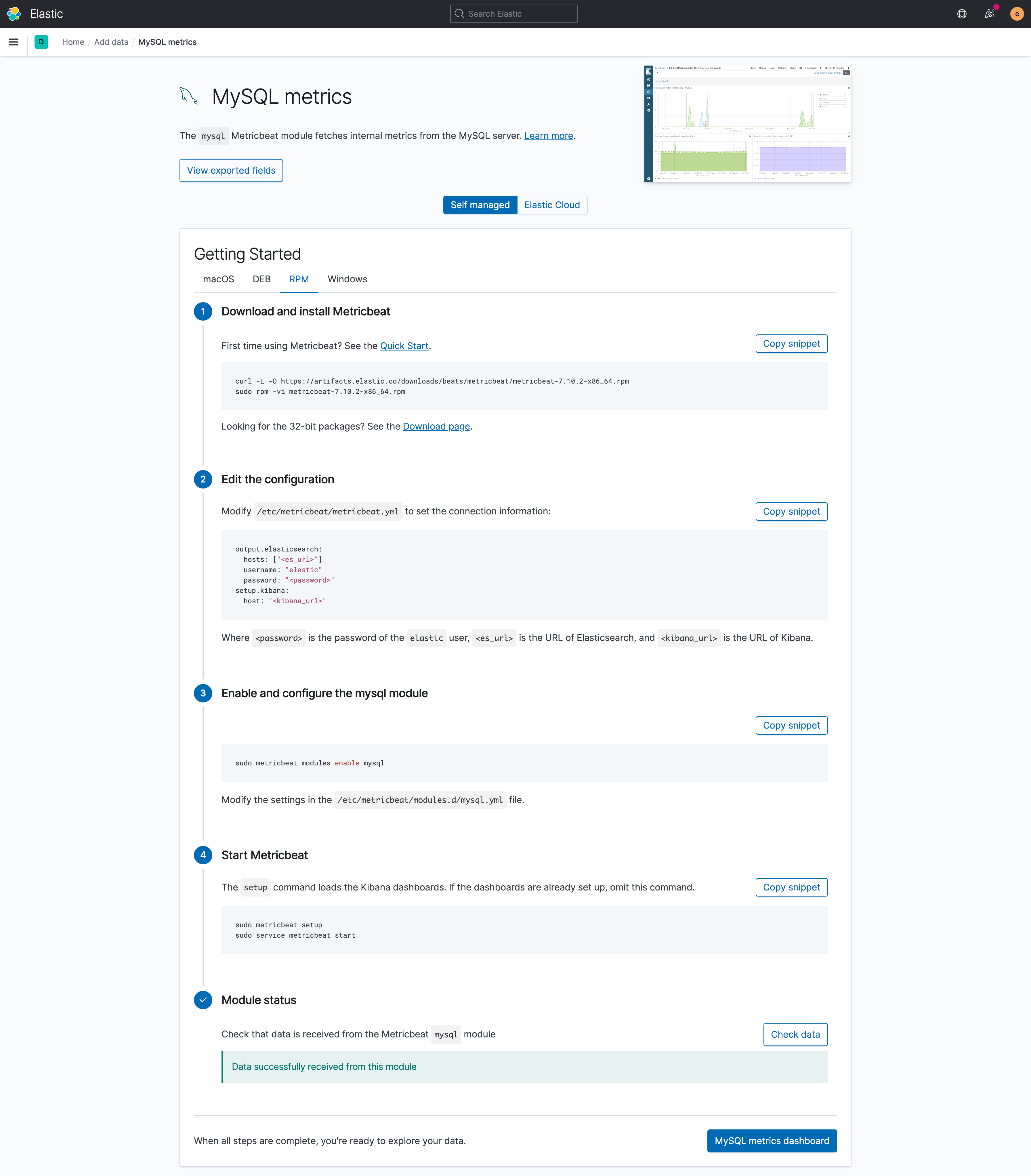
数据加载完成之后,点击
check data
会提示数据成功接收。
3. Dashboard
在Kibana首页找到
Dashboard
。

选择导入的MySQL指标数据。

如图,MySQL各种指标就展示出来了。

结语
在控制台点击几下,就完成了一下午的工作量,不得不感叹SaaS有点东西。如果对Elasticsearch和Kibana有兴趣的,在腾讯云白嫖一个挺合适的。











