前几天写了篇关于fastjson的文章,
《fastjson很好,但不适合我》
。里面探讨到关于对象循环引用的序列化问题。作为spring序列化的最大竞品,在讨论fastjson的时候肯定要对比一下jackson的。所以我也去测试了一下Jackson在对象循环引用的序列化的功用,然后有了一点意外的小发现,在这里跟大家讨论一下。
首先还得解释一下,jackson的序列化是怎么跟@ControllerAdvice关联上的呢?
前篇文章里说过,对于对象循环引用的序列化问题,fastjson和jackson分别采取了两种态度,fastjson是默认处理了,而jackson是默认抛出异常。后者把主动权交给了用户。
既然这里抛出了异常,就涉及到异常的全局处理,跟事务一样,我们不可能以硬编码的方式在每个方法里分别处理异常,而是通过统一全局异常处理。
@ControllerAdvice 全局异常捕获
这里简单的做一下介绍,嫌弃啰嗦的朋友可直接略过,跳到第2部份。
Spring家族中,通过注解@ControllerAdvice或者 @RestControllerAdvice 即可开启全局异常处理,使用该注解表示开启了全局异常的捕获,我们只需在自定义一个方法使用@ExceptionHandler注解然后定义捕获异常的类型即可对这些捕获的异常进行统一的处理。
只要异常最终能够到达controller层,且与@ExceptionHandler定义异常类型相匹配,就能被捕获。
@RestControllerAdvice
public class GlobalExceptionHandler {
Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
@ExceptionHandler(value = Exception.class)
public Result exceptionHandler(Exception e){
logger.error(e.getMessage(), e);
return Result.error(e.getMessage());
}
@ExceptionHandler(value = RuntimeException.class)
public Result exceptionHandlerRuntimeException(Exception e){
logger.error(e.getMessage(), e);
return Result.error(e.getMessage());
}
// 或者其它自定义异常
}
再定义一个统一的接口返回对象:
点击查看代码
public class Result<T> implements Serializable {
private String code;
private Boolean success;
private T data;
private String msg;
public Result(String code, Boolean success, String msg) {
this.code = code;
this.success = success;
this.msg = msg;
}
public Result(String code, String msg, T data) {
this.code = code;
this.data = data;
this.msg = msg;
}
public Result() {
this.code = ReturnCodeEnum.OK.getCode();
this.success = true;
this.msg = ReturnCodeEnum.OK.getMsg();
}
public void serverFailed() {
this.serverFailed((Exception)null);
}
public void serverFailed(Exception e) {
this.code = ReturnCodeEnum.SERVER_FAILED.getCode();
this.success = false;
if (e == null) {
this.msg = ReturnCodeEnum.SERVER_FAILED.getMsg();
} else {
this.msg = e.getMessage();
}
}
public static <T> Result<T> success(T data) {
Result<T> success = new Result();
success.setData(data);
return success;
}
public static <T> Result<T> success() {
return new Result();
}
public static <T> Result<T> error() {
return new Result(ReturnCodeEnum.SERVER_FAILED.getCode(), false, ReturnCodeEnum.SERVER_FAILED.getMsg());
}
public static <T> Result<T> error(String message) {
return new Result(ReturnCodeEnum.SERVER_FAILED.getCode(), false, message);
}
public static <T> Result<T> error(String code, String message) {
return new Result(code, false, message);
}
public void resetWithoutData(Result result) {
this.success = result.getSuccess();
this.code = result.getCode();
this.msg = result.getMsg();
}
public void resetResult(ReturnCodeEnum returnCodeEnum, boolean isSuccess) {
this.code = returnCodeEnum.getCode();
this.success = isSuccess;
this.msg = returnCodeEnum.getMsg();
}
public static <T> Result<T> error(ReturnCodeEnum returnCodeEnum) {
Result<T> error = new Result();
error.code = returnCodeEnum.getCode();
error.success = false;
error.msg = returnCodeEnum.getMsg();
return error;
}
public String getCode() {
return this.code;
}
public Boolean getSuccess() {
return this.success;
}
public T getData() {
return this.data;
}
public String getMsg() {
return this.msg;
}
public void setCode(String code) {
this.code = code;
}
public void setSuccess(Boolean success) {
this.success = success;
}
public void setData(T data) {
this.data = data;
}
public void setMsg(String msg) {
this.msg = msg;
}
public boolean equals(Object o) {
if (o == this) {
return true;
} else if (!(o instanceof Result)) {
return false;
} else {
Result<?> other = (Result)o;
if (!other.canEqual(this)) {
return false;
} else {
label59: {
Object this$code = this.getCode();
Object other$code = other.getCode();
if (this$code == null) {
if (other$code == null) {
break label59;
}
} else if (this$code.equals(other$code)) {
break label59;
}
return false;
}
Object this$success = this.getSuccess();
Object other$success = other.getSuccess();
if (this$success == null) {
if (other$success != null) {
return false;
}
} else if (!this$success.equals(other$success)) {
return false;
}
Object this$data = this.getData();
Object other$data = other.getData();
if (this$data == null) {
if (other$data != null) {
return false;
}
} else if (!this$data.equals(other$data)) {
return false;
}
Object this$msg = this.getMsg();
Object other$msg = other.getMsg();
if (this$msg == null) {
if (other$msg != null) {
return false;
}
} else if (!this$msg.equals(other$msg)) {
return false;
}
return true;
}
}
}
protected boolean canEqual(Object other) {
return other instanceof Result;
}
public int hashCode() {
int PRIME = true;
int result = 1;
Object $code = this.getCode();
int result = result * 59 + ($code == null ? 43 : $code.hashCode());
Object $success = this.getSuccess();
result = result * 59 + ($success == null ? 43 : $success.hashCode());
Object $data = this.getData();
result = result * 59 + ($data == null ? 43 : $data.hashCode());
Object $msg = this.getMsg();
result = result * 59 + ($msg == null ? 43 : $msg.hashCode());
return result;
}
public String toString() {
return "Result(code=" + this.getCode() + ", success=" + this.getSuccess() + ", data=" + this.getData() + ", msg=" + this.getMsg() + ")";
}
public Result(String code, Boolean success, T data, String msg) {
this.code = code;
this.success = success;
this.data = data;
this.msg = msg;
}
统一状态码:
点击查看代码
public enum ReturnCodeEnum {
OK("200", "success"),
OPERATION_FAILED("202", "操作失败"),
PARAMETER_ERROR("203", "参数错误"),
UNIMPLEMENTED_INTERFACE_ERROR("204", "未实现的接口"),
INTERNAL_SYSTEM_ERROR("205", "系统内部错误"),
THIRD_PARTY_INTERFACE_ERROR("206", "第三方接口错误"),
CRS_TOKEN_INVALID("401", "token无效"),
PERMISSIONS_ERROR("402", "业务权限认证失败"),
AUTHENTICATION_FAILED("403", "登陆超时,请重新登陆"),
SERVER_FAILED("500", "server failed 500 !!!"),
DATA_ERROR("10001", "数据获取失败"),
UPDATE_ERROR("10002", "操作失败"),
SIGN_ERROR("10010", "签名错误"),
ACCOUNT_OR_PASSWORD_ERROR("4011", "用户名或密码错误"),
ILLEGAL_PERMISSION("405", "权限不足"),
FORBIDDON("410", "已被禁止"),
TOKEN_TIME_OUT("4012", "session过期,需重新登录");
private String code;
private String msg;
public String getCode() {
return this.code;
}
public void setCode(String code) {
this.code = code;
}
public String getMsg() {
return this.msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
private ReturnCodeEnum(String code, String msg) {
this.code = code;
this.msg = msg;
}
}
再定义一个测试对象:
@Getter
@Setter
//@ToString
//@AllArgsConstructor
//@NoArgsConstructor
public class Person {
private String name;
private Integer age;
private Person father;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}
写一个测试接口,模拟循环依赖的对象,使用fastjson进行序列化返回。
public Result test2 (){
List<Person> list = new ArrayList<>();
Person obj1 = new Person("张三", 48);
Person obj2 = new Person("李四", 23);
obj1.setFather(obj2);
obj2.setFather(obj1);
list.add(obj1);
list.add(obj2);
Person obj3 = new Person("王麻子", 17);
list.add(obj3);
List<Person> young = list.stream().filter(e -> e.getAge() <= 45).collect(Collectors.toList());
List<Person> children = list.stream().filter(e -> e.getAge()< 18).collect(Collectors.toList());
HashMap map = new HashMap();
map.put("young", young);
map.put("children", children);
return Result.success(map);
}
开启fastjson的
SerializerFeature.DisableCircularReferenceDetect
禁用循环依赖检测,使其抛出异常。
访问测试接口,后台打印日志
ERROR 21360 [http-nio-8657-exec-1] [com.nyp.test.config.GlobalExceptionHandler] : Handler dispatch failed; nested exception is java.lang.StackOverflowError
接口返回
{
"code":"500",
"data":null,
"msg":"Handler dispatch failed; nested exception is java.lang.StackOverflowError",
"success":false
}
证明异常在全局异常捕获处被成功捕获。且返回了500状态码,证明服务端出现了异常。
jackson的问题
我们现在换掉fastjson,使用springboot自带的jackson进行序列化。同样还是上面的代码。
后台打印了日志:
[2023-04-01 15:27:42.230] ERROR 17156 [http-nio-8657-exec-2] [com.nyp.test.config.GlobalExceptionHandler] : Could not write JSON: Infinite recursion (StackOverflowError); nested exception is com.fasterxml.jackson.databind.JsonMappingException: Infinite recursion (StackOverflowError) (through reference chain: com.nyp.test.model.Person["father"]->com.nyp.test.model.Person["father"]....
日志信息略有不同,是两种不同的序列化框架的差异,总之全局异常捕获也成功了。
再来看返回的结果如下:
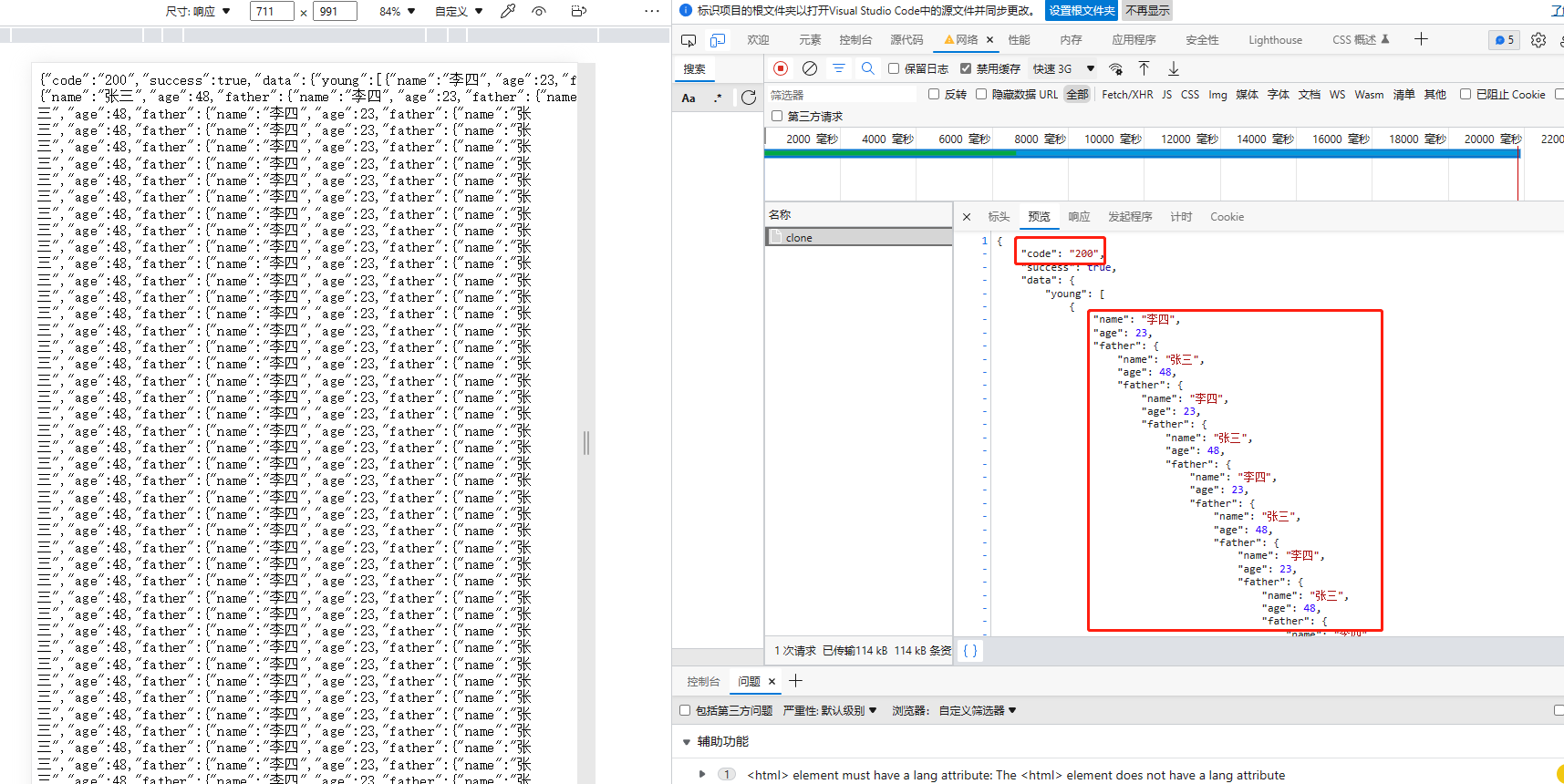
这就很明显不对劲,后台已经抛出异常,并成功捕获了异常,前端怎么还接收到了200状态码呢?而且 data里面还有循环嵌套的数据!
返回的报文很长,仔细观察最后面,发现后面同时也返回了500状态码及异常信息。
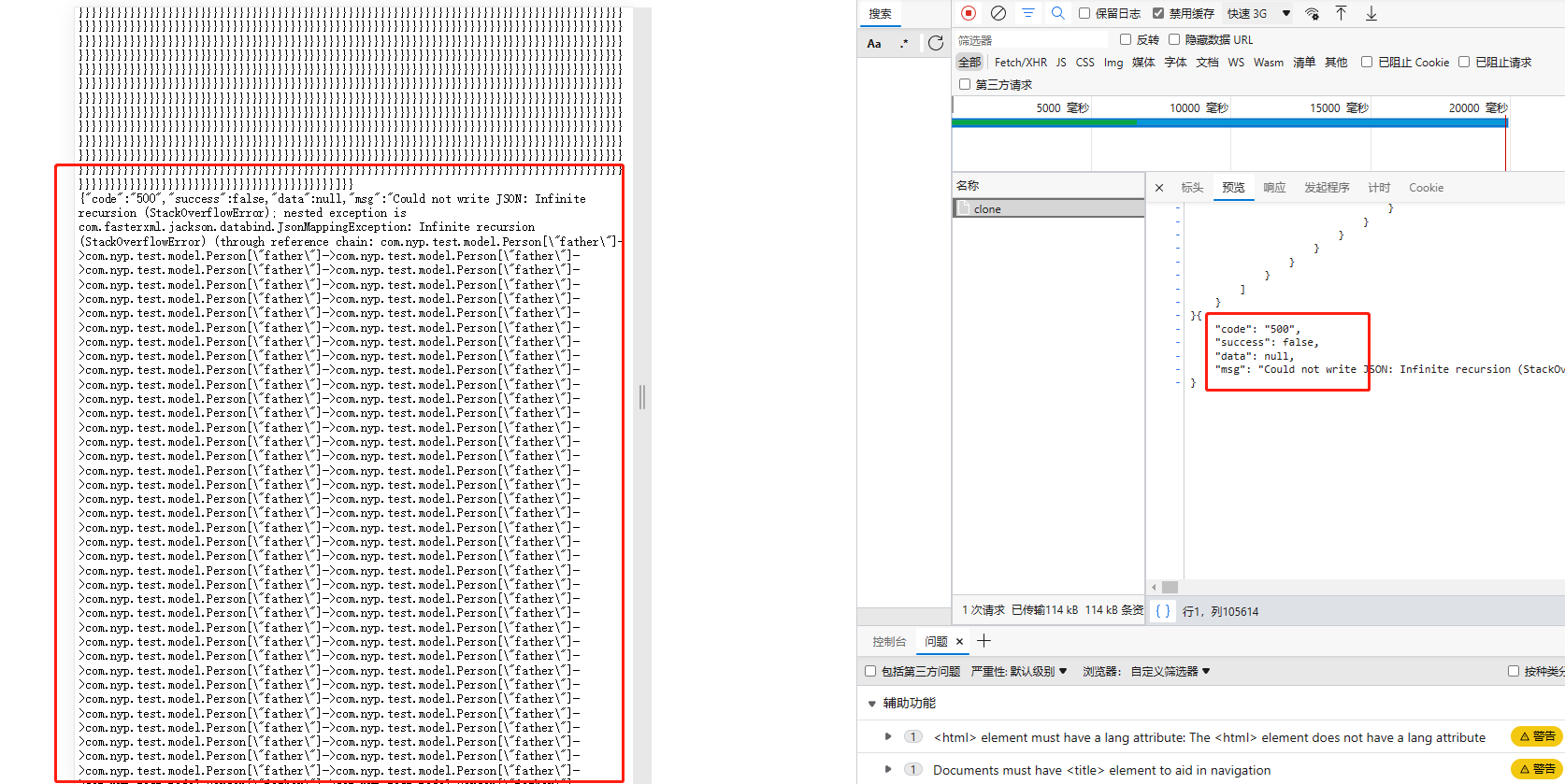
长话短说,相当使用jackson,在默认情况下,对于循环对象引用,在添加了全局异常处理情况下,接口同时返回了两段相反的报文:
{
"code":"200",
"data":{"young":[{"name":"李四","age":23,"father":{"name":"张三","age":48}]}"
"success":true
}
{
"code":"500",
"data":null,
"msg":"Handler dispatch failed; nested exception is java.lang.StackOverflowError",
"success":false
}

小朋友你是否有很多问号??
这种现象是在return后面抛出异常引起?
这就有点意思了。
造成这种现象的原因,我初步怀疑是在方法return返回过后再抛出异常导致的。
我这怀疑也不是毫无理由,具体请看我的另一篇文章
当transcational遇上synchronized
,里面提到过,
spring使用动态代理加AOP实现事务管理。那么一个加了注解事务的方法实际上需要简化成至少3个步骤:
void begin();
@Transactional
public synchronized void test(){
//
}
void commit();
// void rollback();
如果在读已提交及以上的事务隔离级别下,test方法执行完毕,更新了数据但这时候还没到commit事务,但已经释放了锁,另一个事务进来读到的还是旧数据。
类似地,这里的test方法实际上是一样的,jackson在做序列化操作在return之前,那么会不会return返回了一次200,在return过后再抛出异常后再返回了一次500状态码?
那就使用
TransactionSynchronization
模拟一次在return后面的异常看返回给前端什么信息。
@Transactional
@RequestMapping( "/clone")
public Result test2 (){
List<Person> list = new ArrayList<>();
Person obj1 = new Person("张三", 48);
Person obj2 = new Person("李四", 23);
obj1.setFather(obj2);
obj2.setFather(obj1);
list.add(obj1);
list.add(obj2);
Person obj3 = new Person("王麻子", 17);
list.add(obj3);
List<Person> young = list.stream().filter(e -> e.getAge() <= 45).collect(Collectors.toList());
List<Person> children = list.stream().filter(e -> e.getAge()< 18).collect(Collectors.toList());
HashMap map = new HashMap();
map.put("young", young);
map.put("children", children);
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
@Override
public void afterCommit() {
if (1 == 1) {
throw new HttpMessageNotWritableException("test exception after return");
}
TransactionSynchronization.super.afterCommit();
}
});
return Result.success(map);
}
重启调用测试接口,后台打印日志
[http-nio-8657-exec-1] [com.nyp.test.config.GlobalExceptionHandler] : test exception after return
返回客户端信息:
{"code":"500","success":false,"data":null,"msg":"test exception after return"}
测试表明,并不是这个原因造成的。
到这里,可能细心的朋友也发现了,对于前面的猜想,关于
jackson在做序列化操作在return之前,那么会不会return返回了一次200,在return过后再抛出异常后再返回了一次500状态码?
其实是不合理的。
我们在最开始接触java web开发的时候肯定是先学servlet,再学spring,springmvc,springboot这些框架,现在再回到最初的美好,想想servlet是怎样返回数据给客户端的?
通过
HttpServletResponse
获取一个输出流,不管是
OutputStream
还是
PrintWriter
,将我们手动序列化的json串输出到客户端。
@WebServlet(urlPatterns = "/testServlet")
public class TestServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
// 通过PrintWriter 或者 OutputStream 创建一个输出流
// OutputStream outputStream = response.getOutputStream();
PrintWriter out = response.getWriter();
try {
// 模拟获取一个返回对象
Person person = new Person("张三", 23);
out.println("start!");
// 手动序列化,并输出到客户端
Gson gson = new Gson();
out.println(Result.success(gson.toJson(person)));
// outputStream.write();
out.println("end");
} finally {
out.println("成功!");
out.close();
}
super.doGet(request, response);
}
}
我没看过springmvc这块的源码,想来也是同样的逻辑处理对吧。
在dispatchServlet里面invoke完毕目标controller获得了返回对象以后,再调用序列化框架jackson或者fastjson得到一个json对象,再通过输出流输出前端,最后一步操作可能是在servlet里也可能直接在序列化框架里面直接操作。
总之不管是在哪步,都有点不合理,如果是在序列化的时候,序列化框架直接异常了,也不应该输出200和500两段报文。
不管怎样,这里也算是验证了@ControolerAdvice能不能捕获目标controller方法在Return以后抛出的异常,答案是可以。
现在我们可以再来看看Fastjson在return以后进行序列化发生异常的时候,为什么不会输出200和500两段报文。
fastjson为什么没有问题
通过前文我们知道,在同样的情况下,fastjson序列化是可以正常返回给客户端500异常的报文。
我们现在将springmvc的序列化框架切换到fastjson。通过断点走一遍源码。观察为什么fastjson可以正常抛出异常。
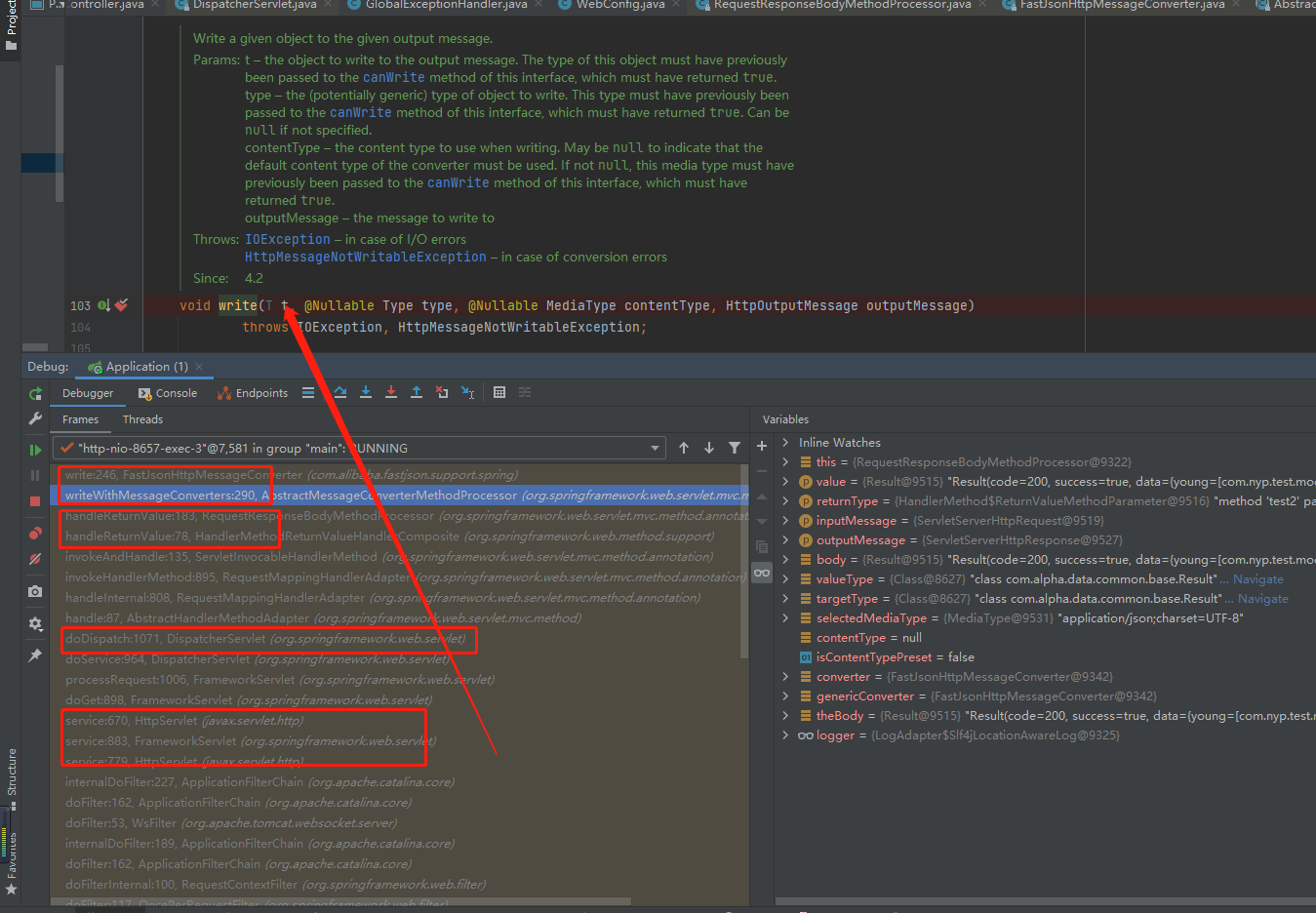
通过调用栈信息,我们可以很明显的观察到我们很熟悉的
distpatchServlet
,再到
handleReturnValue
调用完成目标controller拿到返回对象,现到
AbstractMessageConverterMethodProcessor.writeWithMessageConverters
,最终到达
GenericHttpMessageConverter.write()
通过注释,哪怕是方法名和参数名,我们也知道这里就是开始调用具体的序列化框架重写这个方法输出返回报文到客户端了。
那么在这里开始打个断点,这是个接口方法,它有很多实现类,这里打断点会直接进入到具体实现类的方法。
最终来到了FastJsonHttpMessageConverter.writeInternal()

重点来了,如上图所示,执行到line 314行,也就是标记为1的地方就抛出异常,然后到了finally里面去了,
跳过了line 337即2处真正执行write输出到客户端的操作
。
我们不用去管line 314处所调用方法内部的序列化具体操作,我们只需要知道,它在序列化准备阶段直接异常了,并没有真正执行向客户端进行write的操作。
然后异常最终被@RestControllerAdvice所捕获,输出到客户端500。
jackson的输出流程
现在作为对比,再回过头来看看jackson是怎样完成上述的操作的。
打到与上小节fastjson一样的断点,最终进入了jackson的序列化方法,通过右边
inline watches
可以看到将要被序列化的value从对象的循环引用变成了具体的若干层嵌套循环了。

再一路断点,来到UTF8JsonGenerator,可以观察到,jackson不是将整个返回值value一起进行序列化,而是一个对象一个field顺序进行序列化。

这些值将临时进入了一个buffer缓冲区,在大于
outputend=8000
,就flush直接输出到客户端。
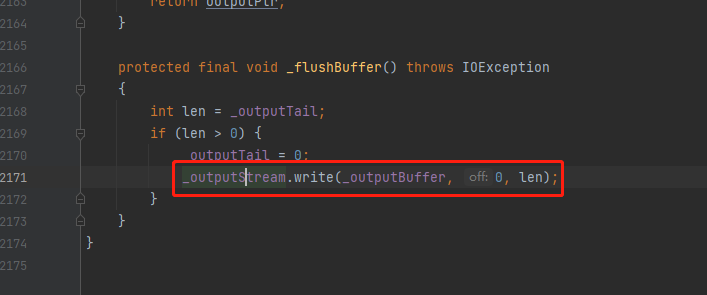
这里的_outputstream就是java.io.OutputStream对象。
小结
这里可以做一个小结了。
jackson为什么会在对象循环引用的时候同时向客户端输出200和500两段报文?
因为jackson的序列化是分阶段进行的,它使用了一种类似于
fail-safe
机制,延迟到后面再失败,而在失败之前,已经将200状态码的报文输出到客户端。
fastjson为什么能正常的只输出500报文?
因为Fastjson的序列化有一种
fail-fast
机制,它判断到有对象循环引用时可以直接抛出异常,然后被全局异常处理,最终只会向客户端输出500状态码报文。
@ControllerAdvice失效的场景
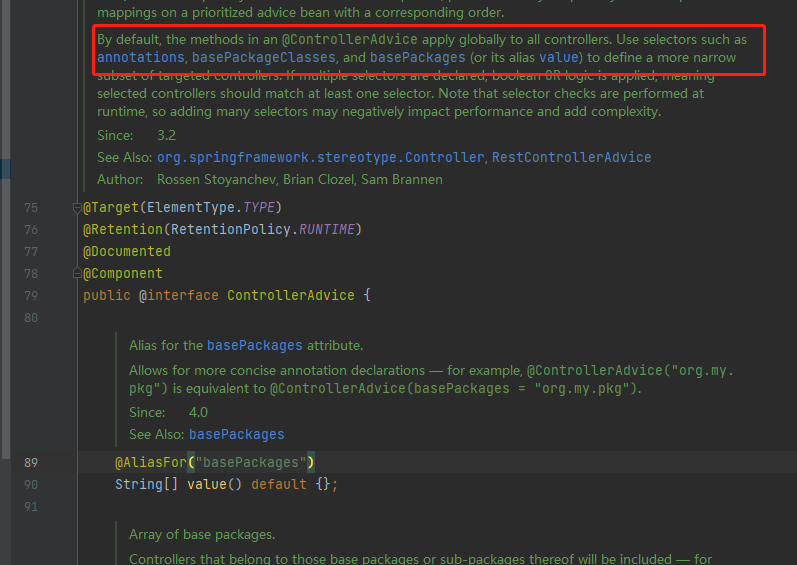
通过注释,我们知道@ControllerAdvice默认作用于全部的controller类方法。也可以手动设置package.
@RestControllerAdvice("com.nyp.test.controller")
或者
@RestControllerAdvice(basePackages = "com.nyp.test.controller")
那么让它失效的场景就是
1.异常到不了controller层,比如在service层里通过try-catch把异常吞了。又比如到达了controller层也抛出了,但在其它AOP切面通知里通过try-catch处理了。
2.或者不指向controller层或部份controller层,比如通过@RestControllerAdvice(basePackages = "com.nyp.test.else")
等等。
其它只要不触碰到以上情况,正确的配置了,即使是在return后面抛出异常也可以正确处理。
具体到本文jackson的这种情况,严格意义上来讲,@ControllerAdvice也是起了作用的。只不过是jackson在序列化的过程中本身出的问题。
总结
- @ControllerAdvice完全安全吗?
只要正确配置,它是完全安全的。本文属于jackson这种特殊情况,它造成的异常情况不是@ControllerAdvice的问题。
2.造成同时返回200和500报文的原因是什么?
因为jackson的序列化是分阶段进行的,它使用了一种类似于
fail-safe
机制,延迟到后面再失败,而在失败之前,将200状态码的报文输出到客户端,失败之后,又将500状态码的报文输出到客户端。
而Fastjson的序列化因为有一种
fail-fast
机制,它判断到有对象循环引用时可以直接抛出异常,然后被全局异常处理,最终只会向客户端输出500状态码报文。
3. 怎么解决这种问题?
这本质上是一个jackson循环依赖的问题。通过注解
@JsonBackReference
@JsonManagedReference
@JsonIgnore
@JsonIdentityInfo
可以部份解决。
比如:
@JsonIdentityInfo(generator= ObjectIdGenerators.IntSequenceGenerator.class, property="name")
private Person father;
返回:
{
"code": "200",
"success": true,
"data": {
"young": [{
"name": "李四",
"age": 23,
"father": {
"name": 1,
"name": "张三",
"age": 48,
"father": {
"name": 2,
"name": "李四",
"age": 23,
"father": 1
}
}
}, {
"name": "王麻子",
"age": 17,
"father": null
}],
"children": [{
"name": "王麻子",
"age": 17,
"father": null
}]
},
"msg": "success"
}
同时,对于对象循环引用这种情况,在代码中就应该尽量去避免。
就像spring处理依赖注入的情况,一开始使用@lazy注解解决,后面spring官方通过三层缓存来解决,再到后面springboot官方默认不支持依赖注入,如果有依赖注入默认启动就会报错。
一言以蔽之,本文说的是,关于spring mvc&spring boot使用jackson做序列化输出的时候,如果没有处理好循环依赖的问题,那么前端不能正确感知到服务器异常这个问题。
但是循环依赖并不常见,遇到了也能有解决方案,所以看起来本文好像并没有什么卵用。
不过,没人规定必须要解决吧,当我还是一个新手的时候,我没解决循环依赖,而同时前端又没有接收到正确的服务端异常时,总是会有疑惑的。
而且如果扩展开来的话,jackson在序列化中途导致失败,都有可能发生这种情况。
从这个角度来说,算不算是jackson的一个问题呢?
不管怎样,希望本文对你能够有所启发。