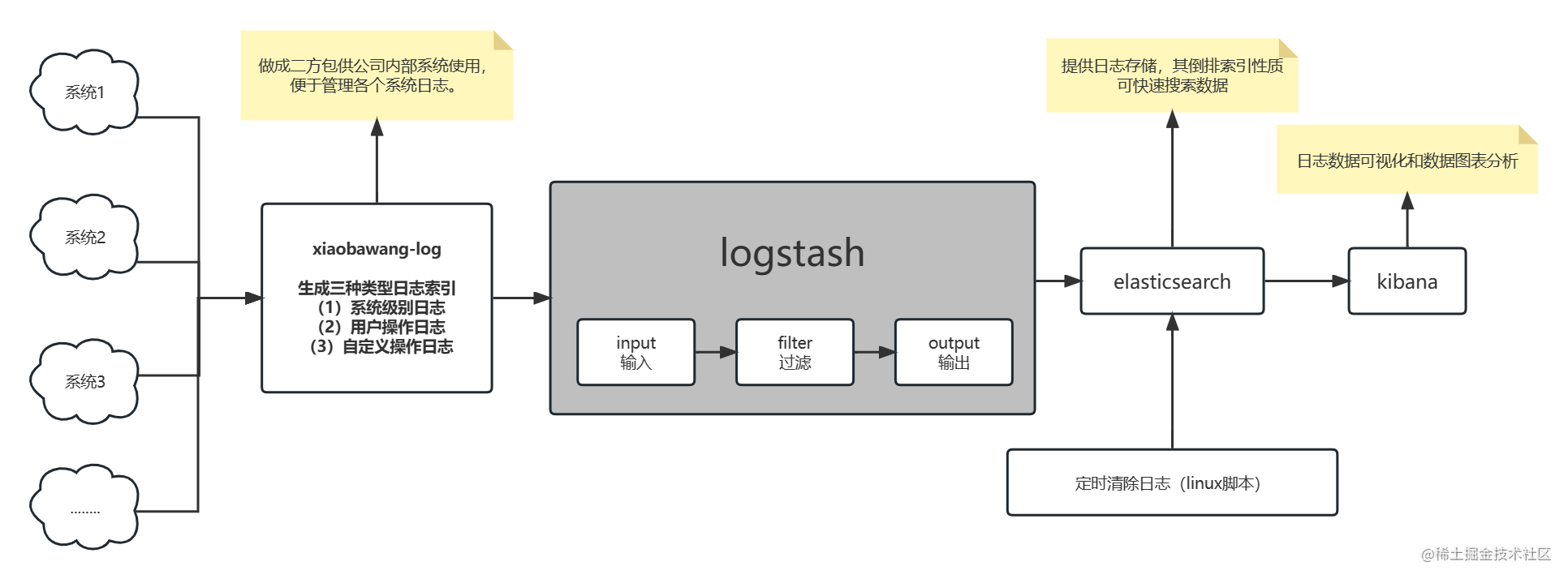
被动与主动侦察
在计算机系统和网络出现之前,孙子兵法在孙子兵法中教导说:“知己知彼,必胜不疑。” 如果您扮演攻击者的角色,则需要收集有关目标系统的信息。如果你扮演防御者的角色,你需要知道你的对手会发现你的系统和网络的什么
侦察(
recon
)可以定义为收集有关目标信息的初步调查。这是统一杀伤链在系统上获得初步立足点的第一步。我们将侦察分为:
在被动侦察中,您依赖于公开可用的知识。您无需直接与目标接触即可从公开可用资源中获取这些知识。把它想象成你从远处看着目标领土,而不是踏上那个领土

被动侦察活动包括许多活动,例如:
- 从公共 DNS 服务器查找域的DNS记录
- 检查与目标网站相关的招聘广告
- 阅读有关目标公司的新闻文章
另一方面,主动侦察无法如此谨慎地实现。它需要与目标直接接触。把它想象成你检查门窗上的锁,以及其他潜在的入口点
主动侦察活动的例子包括:
- 连接到公司服务器之一,例如
HTTP
、
FTP
和
SMTP
- 致电公司试图获取信息(
社会工程学
)
- 冒充修理工进入公司场所
考虑到主动侦察的侵入性,除非获得适当的法律授权,否则很快就会陷入法律困境

被动侦查
我们将学习三个命令行工具:
whois
查询
WHOIS
服务器
nslookup
查询
DNS
服务器
dig
查询
DNS
服务器
我们使用
whois
查询
WHOIS
记录,而我们使用
nslookup
和
dig
查询
DNS
数据库记录。这些都是公开可用的记录,因此不会提醒目标。
我们还将学习两种在线服务的用法:
这两个在线服务使我们能够在不直接连接到目标的情况下收集有关目标的信息
Whois
WHOIS 是遵循RFC 3912规范的请求和响应协议。WHOIS 服务器在TCP端口 43 上侦听传入请求。域名注册商负责维护其租用域名的 WHOIS 记录。WHOIS 服务器回复与所请求域相关的各种信息。特别感兴趣的是,我们可以学习:
- 注册商:域名是通过哪个注册商注册的?
- 注册人联系方式:姓名、单位、地址、电话等。(除非通过隐私服务隐藏)
- 创建、更新和到期日期:域名首次注册的时间是什么时候?最后一次更新是什么时候?什么时候需要更新?
- 名称服务器:请求哪个服务器来解析域名?
要获取这些信息,我们需要使用
whois
客户端或在线服务。许多在线服务提供
whois
信息;但是,使用本地
whois
客户端通常更快、更方便
语法是
whois DOMAIN_NAME
,其中
DOMAIN_NAME
是您尝试获取更多信息的域。考虑以下示例执行
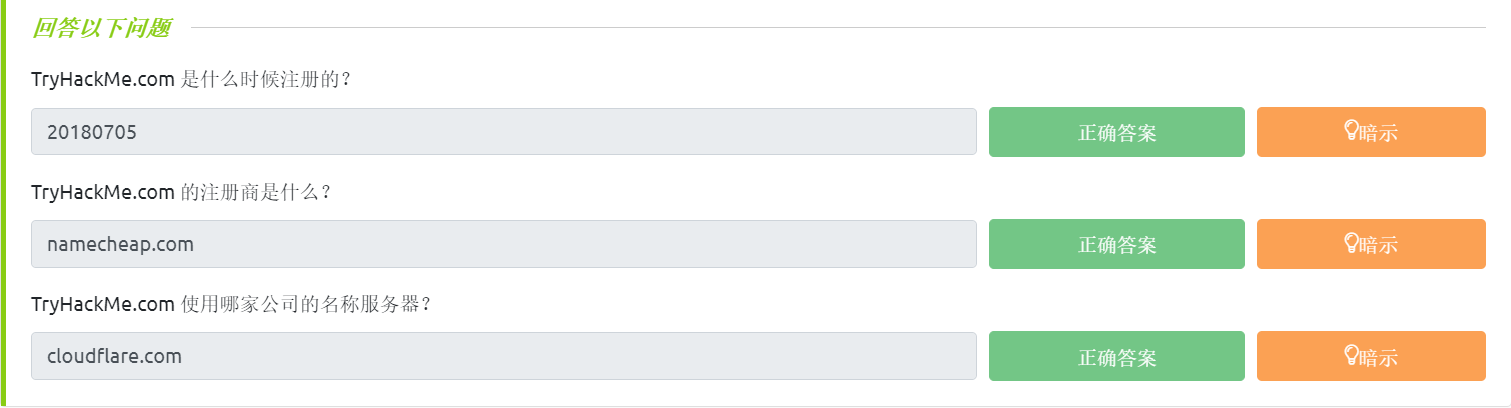
whois tryhackme.com
user@TryHackMe$ whois tryhackme.com
[Querying whois.verisign-grs.com]
[Redirected to whois.namecheap.com]
[Querying whois.namecheap.com]
[whois.namecheap.com]
Domain name: tryhackme.com
Registry Domain ID: 2282723194_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.namecheap.com
Registrar URL: http://www.namecheap.com
Updated Date: 2021-05-01T19:43:23.31Z
Creation Date: 2018-07-05T19:46:15.00Z
Registrar Registration Expiration Date: 2027-07-05T19:46:15.00Z
Registrar: NAMECHEAP INC
Registrar IANA ID: 1068
Registrar Abuse Contact Email: abuse@namecheap.com
Registrar Abuse Contact Phone: +1.6613102107
Reseller: NAMECHEAP INC
Domain Status: clientTransferProhibited https://icann.org/epp#clientTransferProhibited
Registry Registrant ID:
Registrant Name: Withheld for Privacy Purposes
Registrant Organization: Privacy service provided by Withheld for Privacy ehf
[...]
URL of the ICANN WHOIS Data Problem Reporting System: http://wdprs.internic.net/
>>> Last update of WHOIS database: 2021-08-25T14:58:29.57Z <<<
For more information on Whois status codes, please visit https://icann.org/epp
我们可以看到很多信息;我们将按照显示的顺序检查它们。首先,我们注意到我们被重定向到
whois.namecheap.com
以获取我们的信息。在这种情况下,目前
namecheap.com
正在维护该域名的
WHOIS
记录。此外,我们可以看到创建日期以及最后更新日期和到期日期。
接下来,我们获取有关注册服务商和注册人的信息。我们可以找到注册人的姓名和联系信息,除非他们使用某些隐私服务。虽然上面没有显示,但我们得到了这个域的管理员和技术联系人。最后,如果我们有任何DNS记录要查找,我们会看到我们应该查询的域名服务器。
可以检查收集到的信息以发现新的攻击面,例如社会工程或技术攻击。例如,根据渗透测试的范围,您可能会考虑对管理员用户的电子邮件服务器或
DNS
服务器进行攻击,假设它们归您的客户所有并且在渗透测试的范围内。
需要注意的是,由于自动化工具滥用
WHOIS
查询来收集电子邮件地址,许多
WHOIS
服务都对此采取了措施。例如,他们可能会编辑电子邮件地址。此外,许多注册人订阅了隐私服务,以避免他们的电子邮件地址被垃圾邮件发送者收集并保护他们的信息的私密性
nslookup 和 dig
在前面的任务中,我们使用 WHOIS 协议来获取有关我们正在查找的域名的各种信息。特别是,我们能够从注册商那里获得DNS服务器。
使用 查找域名的
IP
地址
nslookup
,代表名称服务器查找。您需要发出命令
nslookup DOMAIN_NAME
,例如,
nslookup tryhackme.com
。或者,更一般地说,您可以使用
nslookup OPTIONS DOMAIN_NAME SERVER
. 这三个主要参数是:
- OPTIONS
包含查询类型,如下表所示。例如,您可以使用
A
IPv4
地址和
AAAA
IPv6
地址。
- DOMAIN_NAME
是您正在查找的域名。
- SERVER
是您要查询的
DNS
服务器。您可以选择任何本地或公共
DNS
服务器进行查询。
Cloudflare
提供
1.1.1.1
和
1.0.0.1
,
Google
提供
8.8.8.8
和
8.8.4.4
,
Quad9
提供
9.9.9.9
和
149.112.112.112
。如果您想要
ISP
的
DNS
服务器的替代方案,您可以选择更多的
公共DNS
服务器
|
查询类型
|
结果
|
| A |
IPv4
地址 |
AAAA
级 |
IPv6
地址 |
| 别名 |
规范名称 |
| MX |
邮件服务器 |
| 面向服务架构 |
授权开始 |
| TXT |
TXT
记录 |
例如,
nslookup -type=A tryhackme.com 1.1.1.1
(或者
nslookup -type=a tryhackme.com 1.1.1.1
因为它不区分大小写)可用于返回
tryhackme.com
使用的所有
IPv4
地址
user@TryHackMe$ nslookup -type=A tryhackme.com 1.1.1.1
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
Name: tryhackme.com
Address: 172.67.69.208
Name: tryhackme.com
Address: 104.26.11.229
Name: tryhackme.com
Address: 104.26.10.229
A
和
AAAA
记录分别用于返回
IPv4
和
IPv6
地址。这种查找有助于从渗透测试的角度了解。在上面的示例中,我们从一个域名开始,并获得了三个
IPv4
地址。如果这些
IP
地址在渗透测试的范围内,则可以进一步检查每个
IP
地址的不安全性
假设您想了解特定域的电子邮件服务器和配置。你可以发出
nslookup -type=MX tryhackme.com
. 这是一个例子:
user@TryHackMe$ nslookup -type=MX tryhackme.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
tryhackme.com mail exchanger = 5 alt1.aspmx.l.google.com.
tryhackme.com mail exchanger = 1 aspmx.l.google.com.
tryhackme.com mail exchanger = 10 alt4.aspmx.l.google.com.
tryhackme.com mail exchanger = 10 alt3.aspmx.l.google.com.
tryhackme.com mail exchanger = 5 alt2.aspmx.l.google.com.
我们可以看到
tryhackme.com
当前的邮箱配置使用的是谷歌。由于
MX
正在查找邮件交换服务器,我们注意到当邮件服务器尝试发送电子邮件时
@tryhackme.com
,它将尝试连接到
aspmx.l.google.com
顺序为
1
的 。如果它繁忙或不可用,邮件服务器将尝试连接到下一个顺序邮件交换服务器,
alt1.aspmx.l.google.com
或
alt2.aspmx.l.google.com
Google
提供列出的邮件服务器;因此,我们不应期望邮件服务器运行易受攻击的服务器版本。但是,在其他情况下,我们可能会发现邮件服务器没有得到足够的保护或修补
当您继续对目标进行被动侦察时,这些信息可能会被证明是有价值的。您可以对其他域名重复类似的查询并尝试不同的类型,例如
-type=txt
. 谁知道您会在途中发现什么样的信息!
对于更高级的
DNS
dig
查询和其他功能,如果您好奇的话,可以使用
“Domain Information Groper”
的首字母缩写词。让我们使用
dig
来查找
MX
记录并将它们与
nslookup
. 我们可以使用
dig DOMAIN_NAME
,但要指定记录类型,我们会使用
dig DOMAIN_NAME TYPE
。(可选)我们可以使用选择我们想要查询的服务器
dig @SERVER DOMAIN_NAME TYPE
。
- SERVER
是您要查询的
DNS
服务器。
- DOMAIN_NAME
是您正在查找的域名。
- TYPE
包含
DNS
记录类型,如前面提供的表中所示。
user@TryHackMe$ dig tryhackme.com MX
; <<>> DiG 9.16.19-RH <<>> tryhackme.com MX
;; global options: +cmd
;; Got answer:
;; ->>HEADER<
nslookup
和的输出之间的快速比较
dig
表明
dig
返回了更多信息,例如默认情况下的
TTL(生存时间)
。可以使用DNS服务器
1.1.1.1
命令就是
dig @1.1.1.1 tryhackme.com MX
DNSDumpster
nslookup
和
dig
等
DNS
查找工具无法自行查找子域。您正在检查的域可能包含一个不同的子域,该子域可以揭示有关目标的大量信息。例如,如果
tryhackme.com
有子域
wiki.tryhackme.com
和
webmail.tryhackme.com
,你想了解更多关于这两个的信息,因为它们可以保存关于你的目标的大量信息。有可能这些子域之一已经设置并且没有定期更新。缺乏适当的定期更新通常会导致易受攻击的服务。但是我们怎么知道这样的子域存在呢?
我们可以考虑使用多个搜索引擎来编制一个公开的子域列表。一个搜索引擎是不够的;此外,我们应该期望至少浏览数十个结果才能找到有趣的数据。毕竟,您正在寻找未明确公布的子域,因此没有必要使其进入搜索结果的第一页。另一种发现此类子域的方法是依靠暴力查询来查找哪些子域具有
DNS
记录。
为避免这种耗时的搜索,可以使用提供DNS查询详细答案的在线服务,例如
DNSDumpster
。如果我们在
DNSDumpster
中搜索,我们将发现典型
DNS
tryhackme.com
查询无法提供的子域。此外,
DNSDumpster
将以易于阅读的表格和图表的形式返回收集到的
DNS
信息。
DNSDumpster
还将提供有关侦听服务器的所有收集信息。
blog.tryhackme.com
我们将在
DNS Dumpster
上搜索,让您大致了解预期的输出。在结果中,我们得到了我们正在查找的域的
DNS
服务器列表。
DNSDumpster
还将域名解析为
IP
地址,甚至尝试对它们进行地理定位。我们还可以看到
MX
记录;
DNSDumpster
将所有五个邮件交换服务器解析为各自的
IP
地址,并提供有关所有者和位置的更多信息。最后,我们可以看到
TXT
记录。实际上,单个查询就足以检索所有这些信息
tryhackme.com

DNS Dumpster
还将以图形方式表示收集到的信息。
DNSDumpster
将之前表格中的数据显示为图表。您可以看到 DNS**** 和
MX
分支到各自的服务器并显示
IP
地址


Shodan.io
Shodan.io
这样的服务可以帮助您了解有关客户端网络的各种信息,而无需主动连接到它。此外,在防御方面,您可以使用
Shodan.io
的不同服务来了解属于您组织的已连接和暴露的设备
Shodan.io
试图连接到每一个可在线访问的设备,以构建一个连接“事物”的搜索引擎,而不是网页搜索引擎。一旦得到响应,它就会收集与该服务相关的所有信息并将其保存在数据库中以便于搜索。考虑其中一个
tryhackme.com
服务器的保存记录

这条记录显示了一个网络服务器;然而,如前所述,Shodan.io 收集与它可以找到的任何在线连接设备相关的信息。在 Shodan.io 上搜索,tryhackme.com至少会显示上图所示的记录。通过这个 Shodan.io 搜索结果,我们可以了解到与我们的搜索相关的几件事,例如:
您也可以尝试搜索从
DNS
查找中获得的
IP
地址。当然,这些更容易发生变化。在他们的帮助页面上,您可以了解
Shodan.io
上可用的所有搜索选项,我们鼓励您加入
TryHackMe
的
Shodan.io
概括
在这个房间里,我们专注于被动侦察。特别是,我们介绍了命令行工具
whois
、
nslookup
和
dig
。我们还讨论了两个公开可用的服务
DNSDumpster
和
Shodan.io
。此类工具的强大之处在于,您可以在不直接连接目标的情况下收集有关目标的信息。此外,一旦您掌握了搜索选项并习惯阅读结果,使用此类工具可能会发现大量信息
|
目的
|
命令行示例
|
| 查找 WHOIS 记录 |
whois tryhackme.com |
| 查找DNS A 记录 |
nslookup -type=A tryhackme.com |
| 在 DNS 服务器上查找DNS MX 记录 |
nslookup -type=MX tryhackme.com 1.1.1.1 |
| 查找DNS TXT 记录 |
nslookup -type=TXT tryhackme.com |
| 查找DNS A 记录 |
dig tryhackme.com A |
| 在 DNS 服务器上查找DNS MX 记录 |
dig @1.1.1.1 tryhackme.com MX |
| 查找DNS TXT 记录 |
dig tryhackme.com TXT |
主动侦察
我们专注于主动侦察和与之相关的基本工具。我们学习使用网络浏览器来收集有关目标的更多信息。
ping
此外,我们还讨论了使用
traceroute
、
telnet
和 等简单工具
nc
来收集有关网络、系统和服务的信息
正如我们在上一个房间中了解到的那样,被动侦察可以让您在没有任何直接参与或联系的情况下收集有关目标的信息。您正在远距离观看或查看公开信息。

主动侦察要求您与目标进行某种接触。这种联系可以是打电话或拜访目标公司,借口是收集更多信息,通常是社会工程的一部分。或者,它可以直接连接到目标系统,无论是访问他们的网站还是检查他们的防火墙是否打开了
SSH
端口。把它想象成你正在仔细检查窗户和门锁。因此,必须记住,在获得客户签署的合法授权之前,不要从事主动侦察工作

在这个房间里,我们专注于主动侦察。主动侦察始于与目标机器的直接连接。任何此类连接都可能在日志中留下信息,显示客户端 IP 地址、连接时间和连接持续时间等。但是,并非所有连接都是可疑的。可以让您的主动侦察显示为常规客户活动。考虑网页浏览;在数百名其他合法用户中,没有人会怀疑浏览器连接到目标网络服务器。作为红队(攻击者)的一部分工作时,您可以使用这些技术来发挥自己的优势,并且不想惊动蓝队(防御者)。
在这个房间里,我们将介绍通常与大多数操作系统捆绑在一起或很容易获得的各种工具。我们从
Web
浏览器及其内置的开发人员工具开始;此外,我们还向您展示了如何“武装”网络浏览器以使其成为高效的侦察框架。之后,我们讨论其他良性工具,例如
ping
、
traceroute
和
telnet
。所有这些程序都需要与目标建立联系,因此我们的活动将受到主动侦察。
任何想要熟悉基本工具并了解如何在主动侦察中使用它们的人都会对这个房间感兴趣。Web 浏览器开发人员工具可能需要一些努力才能熟悉,尽管它提供了图形用户界面。所涵盖的命令行工具使用起来相对简单
Web浏览器
Web
浏览器可以是一个方便的工具,特别是它在所有系统上都很容易使用。您可以通过多种方式使用
Web
浏览器收集有关目标的信息。
在传输层,浏览器连接到:
- 通过
HTTP
访问网站时,默认使用
TCP
端口
80
- 通过
HTTPS
访问网站时默认使用
TCP
端口
443
由于 80 和 443 是HTTP和 HTTPS 的默认端口,因此 Web 浏览器不会在地址栏中显示它们。但是,可以使用自定义端口来访问服务。例如,
https://127.0.0.1:8834/
将通过 HTTPS 协议在端口 8834 连接到 127.0.0.1(本地主机)。如果有 HTTPS 服务器侦听该端口,我们将收到一个网页
在浏览网页时,您可以Ctrl+Shift+I在 PC 上按 或在 Mac 上按Option + Command + I( ) 以打开 Firefox 上的开发者工具。⌥ + ⌘ + I类似的快捷方式也可以让您开始使用 Google Chrome 或 Chromium。开发人员工具可让您检查浏览器已接收并与远程服务器交换的许多内容。例如,您可以查看甚至修改 JavaScript (JS) 文件、检查系统上设置的 cookie 并发现站点内容的文件夹结构。
下面是 Firefox 开发者工具的截图。Chrome DevTools 非常相似

还有很多适用于
Firefox
和
Chrome
的附加组件可以帮助进行渗透测试。这里有一些例子:
FoxyProxy
可让您快速更改用于访问目标网站的代理服务器。当您使用 Burp Suite 等工具或需要定期切换代理服务器时,此浏览器扩展非常方便
User-Agent Switcher and Manager
,您能够假装从不同的操作系统或不同的 Web 浏览器访问网页。换句话说,您可以假装使用
iPhone
浏览网站,而实际上您是从 Mozilla Firefox 访问它
Wappalyzer
提供有关所访问网站所用技术的见解。这种扩展很方便,主要是当您像任何其他用户一样在浏览网站时收集所有这些信息时。Wappalyzer 的屏幕截图如下所示

概括
后面的也懒得搬运了
在这个房间里,我们介绍了许多不同的工具。很容易通过 shell 脚本将它们中的几个放在一起来构建一个原始的网络和系统扫描器。您可以使用traceroute映射到目标的路径,ping检查目标系统是否响应 ICMP Echo,并telnet通过尝试连接来检查哪些端口是开放的和可访问的。可用的扫描仪在更先进和复杂的水平上执行此操作,没有说道
Nmap
,最主要还是使用
Nmap
|
命令
|
例子
|
| ping |
ping -c 10 MACHINE_IP在Linux或 macOS上 |
| ping |
ping -n 10 MACHINE_IP在 Windows 上 |
| traceroute |
traceroute MACHINE_IP在Linux或 macOS上 |
| tracert |
tracert MACHINE_IP在 Windows 上 |
| telnet |
telnet MACHINE_IP PORT_NUMBER |
| netcat 作为客户端 |
nc MACHINE_IP PORT_NUMBER |
| netcat 作为服务器 |
nc -lvnp PORT_NUMBER |
尽管这些是基本工具,但它们在大多数系统上都很容易获得。特别是,几乎每台计算机和智能手机上都安装了 Web 浏览器,它可以成为您武器库中的重要工具,用于在不发出警报的情况下进行侦察
|
操作系统
|
开发者工具快捷方式
|
| Linux或 MS Windows |
Ctrl+Shift+I |
| 苹果系统 |
Option + Command + I |