CSS色域、色彩空间、CSS Color 4新标准
引言
近期,三大主流浏览器引擎均发布最新版本,支持W3C的CSS Color 4标准,包含新的取色方法
color()
和相应语法,可展示更多的色域及色彩空间,这意味着web端能展示更丰富更高清的色彩。虽然目前只有最新版本的现代浏览器才支持,我们可以先提前了解一下这项新标准。
本文首先会先简单介绍几个色彩的基础概念,了解为何需要新标准,之后会介绍新标准中的方法和语法使用。
基础概念
色域(color gamut)
指颜色的可选范围。如sRGB色域,目前web广泛应用的色域标准,使用红(red)绿(green)蓝(blue)作为基础色,色值范围0~255,三种基础色互相混合起来可展示255*255*255种颜色,这大致可理解为sRGB的色域。
现代web css使用的sRGB色域仅满足基础性的色彩需求,能展示的色彩范围远小于人类肉眼所能感知的颜色范围,也远低于高清展示的要求。
以下是sRGB与其他几种色域标准的色值范围大小比较:
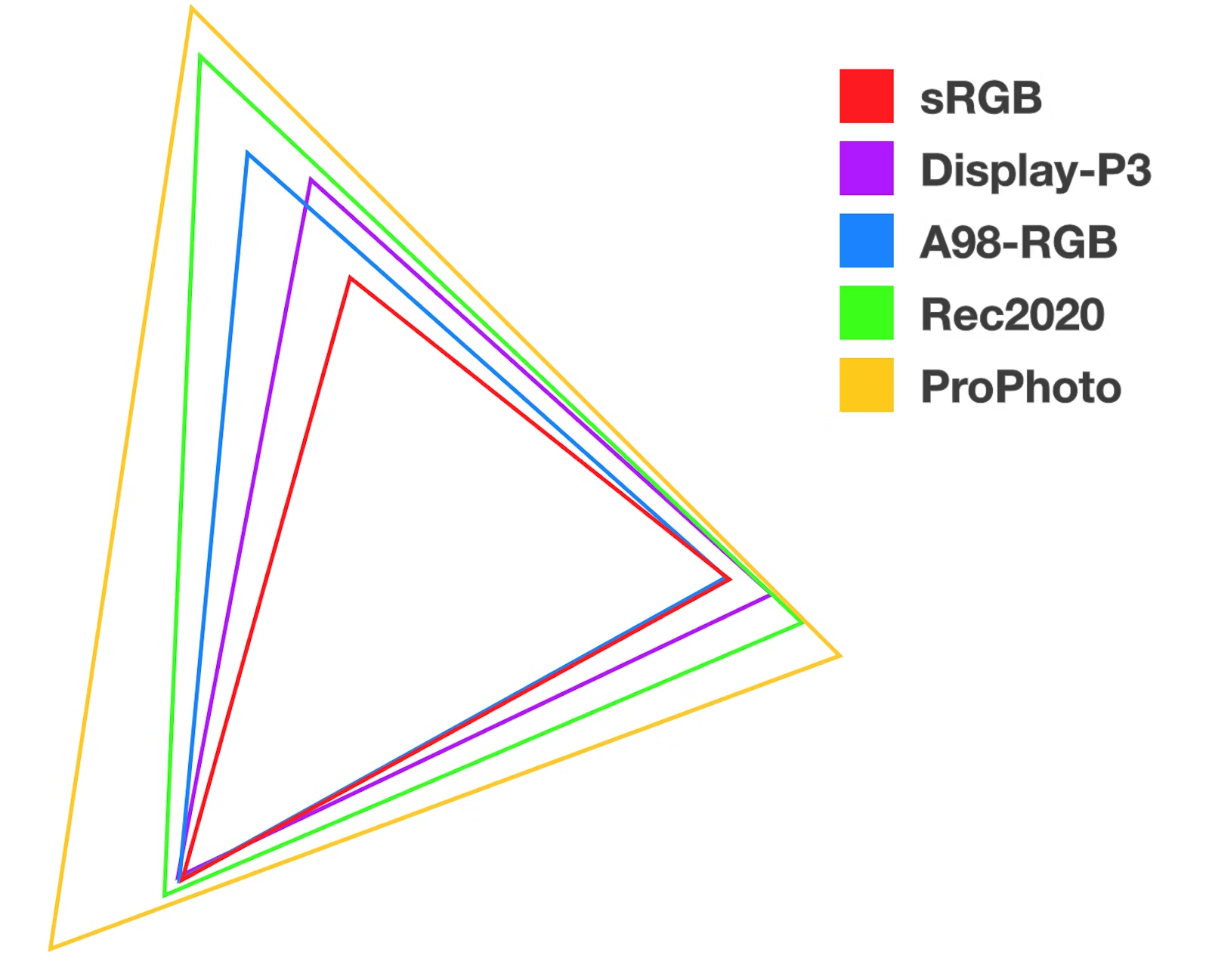
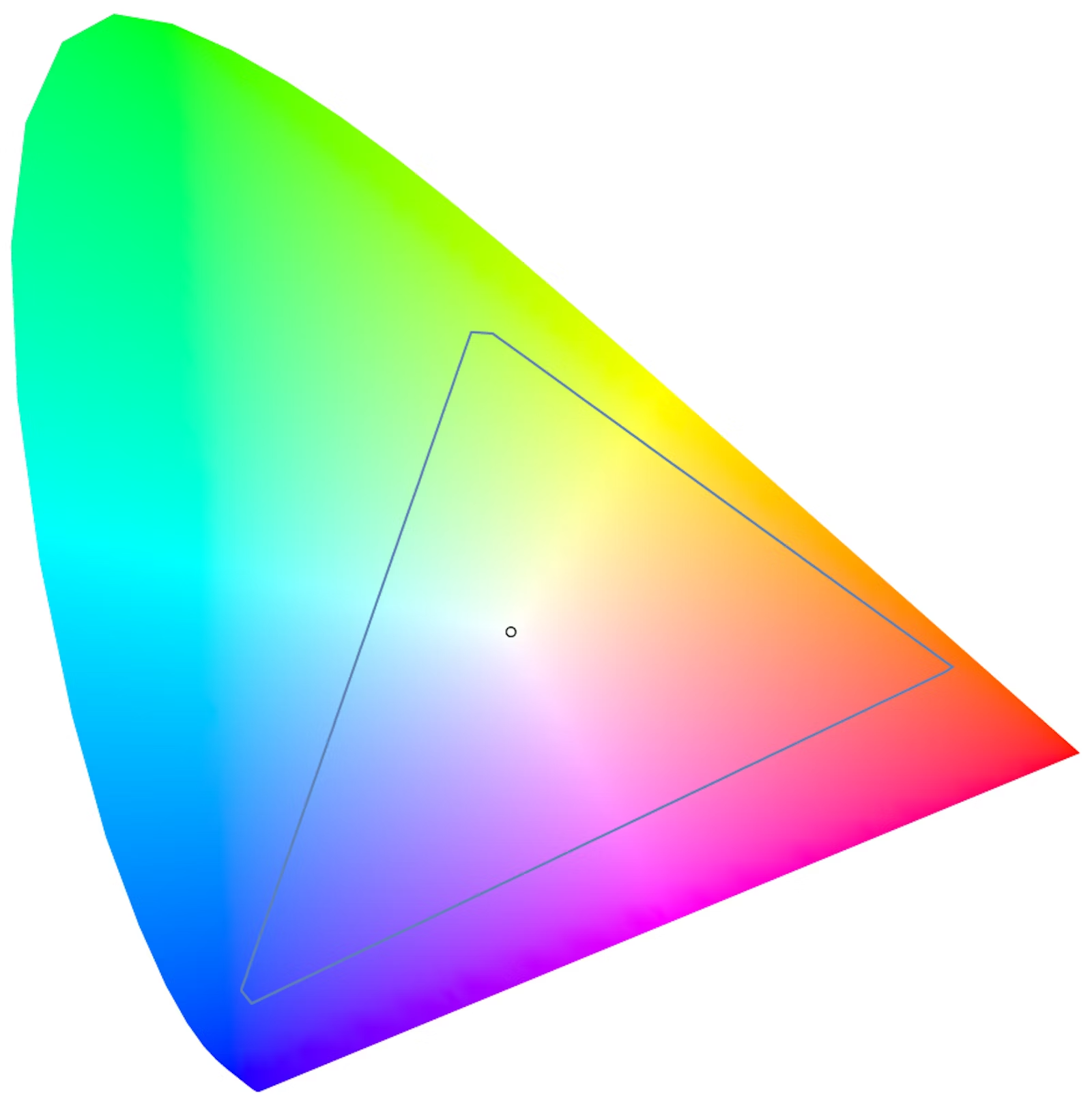
以下是sRGB与人类肉眼可感知的色域比较:
色彩空间(color space)
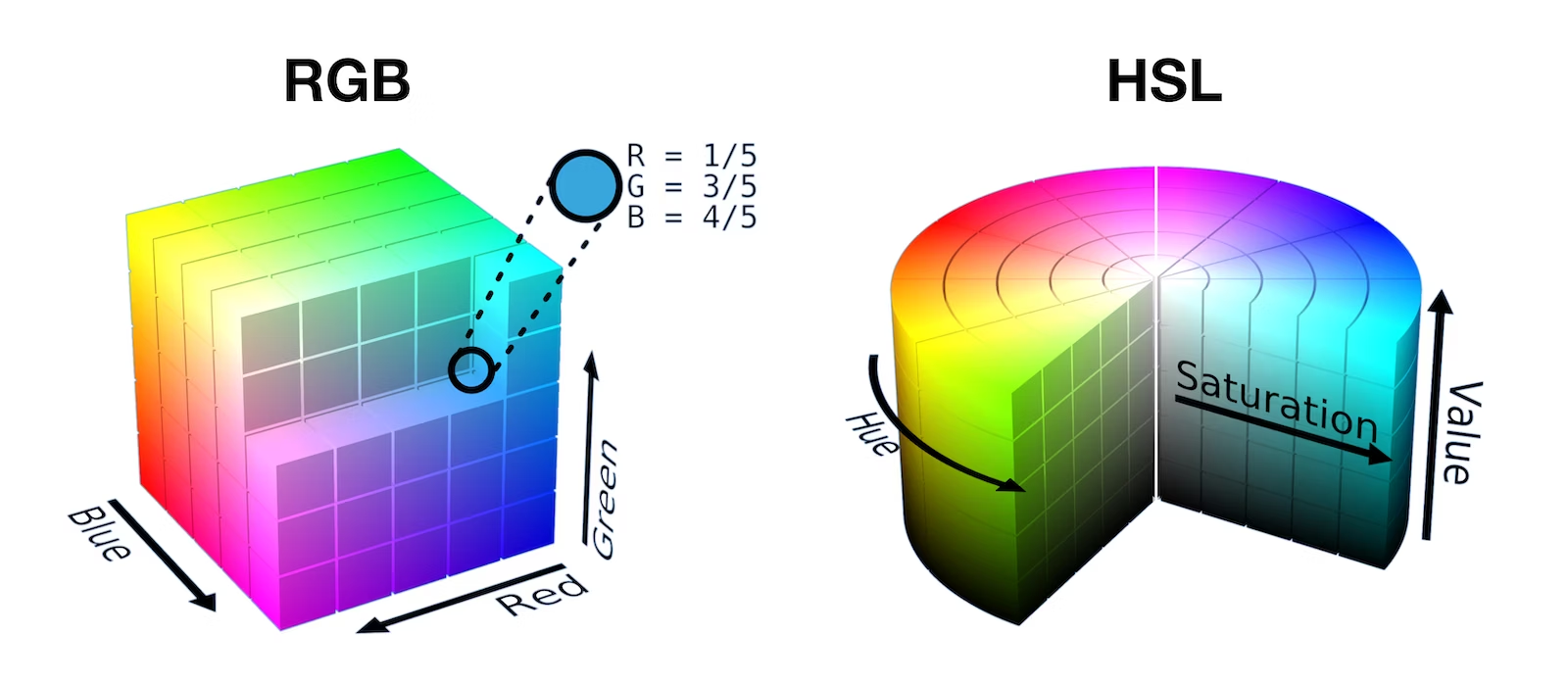
色彩空间可以理解为一个基于某一色域标准下构建的空间数学模型,例如一些简单的方块、圆柱的3D模型,可以用来标记出色域中每个颜色的空间位置,各个颜色之间的关系等。
再用sRGB举例,红(red)绿(green)蓝(blue)三种基础色可设置为3个直线坐标轴,每种颜色便可标记为这个立方体中的一个点,在css中便是使用rgb()方法来取色,参数为指定颜色在色彩空间中的坐标(R, G, B)。
再再比如css的另一个取色方法hsl(),使用的是一套完全不同的色彩空间HSL,H色相(hue)是取值范围为0~360的角度,可作为角轴;S饱和度(Saturation)和L亮度(Lightness)作为两个直线轴,可构建为一个圆柱形的空间,css中使用hsl(H, S, L)表示颜色。
一种色域标准可以使用不同的色彩空间来描述,不同的色域标准也可以使用的是同一类的色彩空间表示。例如sRGB可以使用
rgb()
、
hsl()
、
hwb()
等方式进行描述,而像Display-P3、Rec2020色域都可以使用(R,G,B)的色彩空间来描述,只是空间的边界范围有所不同。
为什么要支持高清色彩
高清意味着更高范围的色域,让我们先直观感觉一下窄色域与广色域的视觉差距:

在实际的css颜色取值中,我们常用的方法有很多
rgb()
、
rgba()
、
hsl()
、
hwb()
,对应不同的色彩空间,但取的都是同一色域范围内的颜色,即sRGB,大概只能展示人类肉眼可感知的色彩中的30%,仿佛在使用一台90年代的电视机播放4K电影。
虽然目前的网络显示设备很多还是sRGB标准,并不支持显示更广色域标准的色彩,仅部分HDR显示器、或视频录制设备、电影制造中使用了如Display P3这类更广的色域标准。但对于高清的需求只会越来越多,支持更广色域标准注定也是未来web端显示的目标之一。
为应对这一趋势,W3C的CSS Color 4标准定义了新方法
color()
和其他语法能更灵活的指定各种不同色域标准下的颜色,以及更好的色彩渐变展示。最近,主流三大web浏览器也都已支持了W3C的新标准。
CSS Color 4
回顾现有的色彩空间
2000年以来,我们有多种方式指定色值:
hex
色值(
#rgb
、
#rrggbb
)、
rgb()
、
rgba()
、或是一些特定颜色的字符(如
white
、
pink
等);2010年左右开始,浏览器开始支持
hsl()
方法;2017年,
hex
色值扩展了对于透明度的支持,
#rrggbbaa
;之后各种浏览器又陆续增加对
hwb()
方法的支持。
不同的方法对应的是不同的色彩空间,但色域都是同一个,即sRGB。
HEX

使用十六进制的数字来分别表示R、G、B、A的值
.valid-css-hex-colors {
/* 一般标准 */
--3-digits: #49b;
--6-digits: #4499bb;
/* 带透明度 */
--4-digits-opaque: #f9bf; /* 不透明 */
--8-digits-opaque: #ff99bbff; /* 不透明 */
--4-digits-with-opacity: #49b8; /* 透明度88% */
--8-digits-with-opacity: #4499bb88; /* 透明度88% */
}
RGB

使用0
255的十进制数字,或是0%
100%的百分比来指明R、G、B,透明度A使用百分比或0~1的数字表示
.valid-css-rgb-colors{
--classic:rgb(64, 149, 191);
--modern:rgb(64 149 191);
--percents:rgb(25% 58% 75%);
--classic-with-opacity-percent:rgba(64, 149, 191, 50%);
--classic-with-opacity-decimal:rgba(64, 149, 191, .5);
--modern-with-opacity-percent:rgb(64 149 191 / 50%);
--modern-with-opacity-decimal:rgb(64 149 191 / .5);
--percents-with-opacity-percent:rgb(25% 58% 75% / 50%);
--percents-with-opacity-decimal:rgb(25% 58% 75% / 50%);
--empty-channels:rgb(none none none);
}
HSL

这种色彩空间更符合人类自然理解,无需了解红绿蓝基础色是如何混合的。参数分别表示:
- H:hue,色相,取值0deg~360deg
- S:Saturation,饱和度,取值0%~100%
- L:Lightness,亮度,取值0%~100%
.valid-css-hsl-colors{
--classic:hsl(200deg, 50%, 50%);
--modern:hsl(200 50% 50%);
--classic-with-opacity-percent:hsla(200deg, 50%, 50%, 50%);
--classic-with-opacity-decimal:hsla(200deg, 50%, 50%, .5);
--modern-with-opacity-percent:hsl(200 50% 50% / 50%);
--modern-with-opacity-decimal:hsl(200 50% 50% / .5);
/* 无色相和饱和度,仅用亮度可表示黑白色 */
--empty-channels-white:hsl(none none 100%);
--empty-channels-black:hsl(none none 0%);
}
HWB

形式上和HSL类似,但使用的3个维度为:
- H:Hue,色相,取值0deg~360deg;
- W:Whiteness,白色的浓度(0~100%);
- B:Blackness,黑色的浓度(0~100%);
.valid-css-hwb-colors{
--modern:hwb(200deg 25% 25%);
--modern2:hwb(200 25% 25%);
--modern-with-opacity-percent:hwb(200 25% 25% / 50%);
--modern-with-opacity-decimal:hwb(200 25% 25% / .5);
/* 无色相和饱和度,仅用亮度可表示黑白色 */
--empty-channels-white:hwb(none 100% none);
--empty-channels-black:hwb(none none 100%);
}
新方法color()

新的
color()
方法的参数类似于
rgb()
方法,使用R、G、B三个直线轴上的数值来指明色彩,不同的是
color()
方法的第一个参数可以接收除sRGB以外的其他色域下的色彩空间标识符,且R、G、B的值仅支持0
1或0%
100%。
.valid-css-color-function-colors {
--srgb: color(srgb 1 1 1);
--srgb-linear: color(srgb-linear 100% 100% 100% / 50%);
--display-p3: color(display-p3 1 1 1);
--rec2020: color(rec2020 0 0 0);
--a98-rgb: color(a98-rgb 1 1 1 / 25%);
--prophoto: color(prophoto-rgb 0% 0% 0%);
--xyz: color(xyz 1 1 1);
}
方法定义:color(colorspace c1 c2 c3[ / A])
- 参数colorspace:标识符,指明使用哪种色彩空间,可选值包括:
srgb
,
srgb-linear
,
display-p3
,
a98-rgb
,
prophoto-rgb
,
rec2020
,
xyz
,
xyz-d50
, and
xyz-d65
. - 参数c1、c2、c3:可以是number(0~1)、百分比或none,对应指定色彩空间下的各参数值,比如
srgb
,
srgb-linear
,
display-p3
对应的是R、G、B的值,具体需要看指定色彩空间描述颜色的维度。 - 参数A:可选项,可以是number(0~1)、百分比或none,指明颜色的透明度
使用color()描述不同的色彩空间
sRGB
不再支持0
255取值,改为0
1范围,其实和百分比的形式是等价的。如果传了大于1的数值也默认当作1来解析。
.valid-css-srgb-colors{
--percents:color(srgb 34% 58% 73%);
--decimals:color(srgb .34 .58 .73);
--percents-with-opacity:color(srgb 34% 58% 73% / 50%);
--decimals-with-opacity:color(srgb .34 .58 .73 / .5);
/* 色值为none或空时,表示黑色 */
--empty-channels-black:color(srgb none none none);
--empty-channels-black2:color(srgb);
}
Linear sRGB
Linear sRGB和sRGB是不同的色彩空间,sRGB的取值是通过一个伽马曲线函数做过校正的,并不是线性变化的,更适应人眼的感知特性,即对明暗的感知是非线性的;而Linear sRGB的颜色变化是线性的,以下是明暗从0-1渐变时,两种色彩空间实际的渐变走向。

.valid-css-srgb-linear-colors{
--percents:color(srgb-linear 34% 58% 73%);
--decimals:color(srgb-linear .34 .58 .73);
--percents-with-opacity:color(srgb-linear 34% 58% 73% / 50%);
--decimals-with-opacity:color(srgb-linear .34 .58 .73 / .5);
/* 色值为none或空时,表示黑色 */
--empty-channels-black:color(srgb-linear none none none);
--empty-channels-black2:color(srgb-linear);
}
Display P3、Rec2020
display P3是最早由苹果公司推行的。如今这一标准已成为HDR显示的基础标准,能显示的颜色比sRGB多50%。而Rec2020标准比display P3的色域更广,可以用来显示4K甚至8K的影像,但目前支持这一标准的终端显示器还很少。两种色域都是使用RGB来描述的。
.valid-css-display-p3-colors{
--percents:color(display-p3 34% 58% 73%);
--decimals:color(display-p3 .34 .58 .73);
--percent-opacity:color(display-p3 34% 58% 73% / 50%);
--decimal-opacity:color(display-p3 .34 .58 .73 / .5);
/* 无色度色相,展示为黑色 */
--empty-channels-black:color(display-p3 none none none);
--empty-channels-black2:color(display-p3);
}
.valid-css-rec2020-colors {
--percents: color(rec2020 34% 58% 73%);
--decimals: color(rec2020 .34 .58 .73);
--percent-opacity: color(rec2020 34% 58% 73% / 50%);
--decimal-opacity: color(rec2020 .34 .58 .73 / .5);
/* 无色度色相,展示为黑色 */
--empty-channels-black: color(rec2020 none none none);
--empty-channels-black2: color(rec2020);
}
CIE标准
让我们先回到开头的两张色域图,会发现基于RGB描述的色域基本是一个三角形,因为都是使用3个基础色混合而成,但人眼所能感知的色域是形似马蹄的图形(具体如何绘制出的,感兴趣的可自行搜索了解)。基于RGB标准的色彩空间,都很难完全覆盖人眼能感知的所有颜色。而基于CIE标准(国际照明委员会制定的一种测定颜色的国际标准,它描述了人眼对颜色的感知和色彩的测量方法)的色彩空间,理论上是能够包括人视觉所能感知到的所有颜色。
CSS Color 4新标准也新增了对于CIE标准色域的支持。下面介绍的lab()、lch()、oklab()、oklch()都是基于CIE的取色新方法。
lab()

lab()
方法描述的是基于CIE标准的色彩空间中的颜色,能够覆盖人眼所能看到的全色域。和与基于RGB来描述色彩的维度不同,lab使用的维度分别为:
- L:lightness,视觉上线性渐变的亮度,取值范围
0~100
或
0%~100%
; - A:代表更贴合人眼视觉特性的两个色轴之其一:红-绿,取值范围均为
-125~125
或
-100%~100%
。当A为正值,则为更偏红色;为负值时,更偏绿; - B:代表更贴合人眼视觉特性的两个色轴之其二:蓝-黄,取值范围均为
-125~125
或
-100%~100%
。值为正值,更偏黄;为负值,更偏蓝。
.valid-css-lab-colors{
--percent-and-degrees:lab(58% -16 -30);
--minimal:lab(58 -16 -30);
--percent-opacity:lab(58% -16 -30 / 50%);
--decimal-opacity:lab(58% -16 -30 / .5);
/* 后两个参数为none是可表示纯灰度 */
--empty-channels-white:lab(100 none none);
--empty-channels-black:lab(none none none);
}
lch()

lch使用的维度分别是:
- L:lightness,视觉上线性渐变的亮度,取值范围0
100或0%
100%; - C:chroma,颜色的纯度,类似于饱和度,取值范围0~230,但实际上,这个值是没有上限的;
- H:hue,色相,类似hsl和hwb,是个角轴,取值范围0deg~360deg;
.valid-css-lch-colors{
--percent-and-degrees:lch(58% 32 241deg);
--just-the-degrees:lch(58 32 241deg);
--minimal:lch(58 32 241);
--percent-opacity:lch(58% 32 241 / 50%);
--decimal-opacity:lch(58% 32 241 / .5);
/* 后两个参数为none是可表示纯灰度 */
--empty-channels-white:lch(100 none none);
--empty-channels-black:lch(none none none);
}
oklab()

oklab是校正版的lab,优化了图片处理质量,在CSS中意味着渐变优化和颜色处理函数优化,消除了色相偏移(hue shift,即在lab中改变颜色纯度,色相也会变化),使用的维度和lab()是一致的。
.valid-css-oklab-colors{
--percent-and-degrees:oklab(64% -.1 -.1);
--minimal:oklab(64 -.1 -.1);
--percent-opacity:oklab(64% -.1 -.1 / 50%);
--decimal-opacity:oklab(64% -.1 -.1 / .5);
/* 后两个参数为none是可表示纯灰度 */
--empty-channels-white:oklab(100 none none);
--empty-channels-black:oklab(none none none);
}
oklch()

相应的,oklch是lch的校正版,取色的逻辑和hsl类似,在圆色盘中选择一个角度从而选中一个色相,再通过调节亮度和纯度,也就是hsl中的饱和度,纯度和饱和度基本可认为是等价的,区分仅在于纯度和亮度的调节通常是同步进行的,否则纯度很容易超出目标色域的范围。这里有一个
oklch的拾色器
,可以体验下。
.valid-css-oklch-colors{
--percent-and-degrees:oklch(64% .1 233deg);
--just-the-degrees:oklch(64 .1 233deg);
--minimal:oklch(64 .1 233);
--percent-opacity:oklch(64% .1 233 / 50%);
--decimal-opacity:oklch(64% .1 233 / .5);
/* 后两个参数为none是可表示纯灰度 */
--empty-channels-white:oklch(100 none none);
--empty-channels-black:oklch(none none none);
}
color-mix()

除了新增的一些取色方法外,新标准还有一个混色函数,可以将上边提到的各种不同色彩空间的中颜色进行混合计算出新颜色。
color-mix(in lch, plum, pink);
color-mix(in lch, plum 40%, pink);
color-mix(in srgb, #34c9eb 20%, white);
color-mix(in hsl longer hue,hsl(120 100% 50%) 20%, white);
方法定义:color-mix(method, color1[ p1], color2[ p2])
- 参数method:指定混色的色彩空间,以 in
的形式, 包含: srgb,srgb-linear,lab,oklab,xyz,xyz-d50,xyz-d65,hsl,hwb,lch, oroklch - 参数color1、color2:为对应method中指定色彩空间中的任一颜色;
- 参数p1、p2:为可选参数,取值范围为0%~100%,可以指明混色的比例,如果为空,默认color1和color2各为50%;
项目中如何使用高清色彩
在我们应用一项新语法时,我们通常会有两种策略:优雅降级和渐进增强,具体实施方案:
优雅降级
这种实施起来比较简单,即同时使用新旧取色方法,让浏览器自动判断展示哪种
/* 原代码 */
color: red;
color:color(display-p3 1 0 0);
/* 如果浏览器不支持display-p3,则会只解析第一行 */
color: red;
/* 如果浏览器支持,则会最终使用第二行 */
color:color(display-p3 1 0 0);
渐进增强
使用@supports和@media先判断当前浏览器是否支持新的色域标准,并在条件的情况下提供新的色值。
色域媒体查询
- dynamic-range
:取值standard或high,用于判断当前硬件设备是否支持高清、高对比度、高色彩精度,不过这一属性判断的比较笼统,并不能准确判断浏览器是否支持新色域和色彩空间。

@media(dynamic-range: high){
/* safe to use HD colors */
color: color(display-p3 34% 58% 73%);
}
- color-gamut
:取值 srgb、p3 或 rec2020,对应可判断用户设备是否支持sRGB、Display P3 或 REC2020色域。

@media(color-gamut: srgb){
/* safe to use srgb colors */
color: #4499bb;
}
@media(color-gamut: p3){
/* safe to use p3 colors */
color: color(display-p3 34% 58% 73%);
}
@media(color-gamut: rec2020){
/* safe to use rec2020 colors */
color: color(rec2020 34% 58% 73%);
}
除了可以直接使用css媒体查询,还可用途JavaScript中的
window.matchMedia()
方法来进行媒体查询。

const hasHighDynamicRange = window.matchMedia('(dynamic-range: high)').matches;
console.log(hasHighDynamicRange);// true || false
const hasP3Color = window.matchMedia('(color-gamut: p3)').matches;
console.log(hasP3Color);// true || false
色彩空间查询
- 使用
[@supports](https://my.oschina.net/u/688773)
判断某个css方法或属性是否支持

@supports(background:rgb(0 0 0)){
/* rgb color space supported */
background:rgb(0 0 0);
}
@supports(background:color(display-p3 0 0 0)){
/* display-p3 color space supported */
background:color(display-p3 0 0 0);
}
@supports(background:oklch(0 0 0)){
/* oklch color space supported */
background:oklch(0 0 0);
}
应用实例
在实际应用中,在新旧标准过渡期间,可以综合使用上边的查询方法,下面是一个兼容新旧标准的实例:
:root{
--neon-red:rgb(100% 0 0);
--neon-blue:rgb(0 0 100%);
}
/* 设备是否支持展示高清 */
@media(dynamic-range: high){
/* 浏览器是否能解析display-p3 */
@supports(color:color(display-p3 0 0 0)){
/* 安全使用display-p3 */
--neon-red:color(display-p3 1 0 0);
--neon-blue:color(display-p3 0 0 1);
}
}
开发调试
如果更新了最新版本的chrome浏览器的话,就能发现DevTools里的拾色器已经支持了CSS Color 4中的新语法,点击页面元素中的颜色属性,在弹出的拾色器中,中间色值右侧的箭头,之前的版本中,点击箭头是在hex、rgb、hsl和hwb之间切换,但新版本中,点击箭头会出现下拉框,可以看到所有新增的色彩空间和方法,以及当前色值所对应的可替换色值。
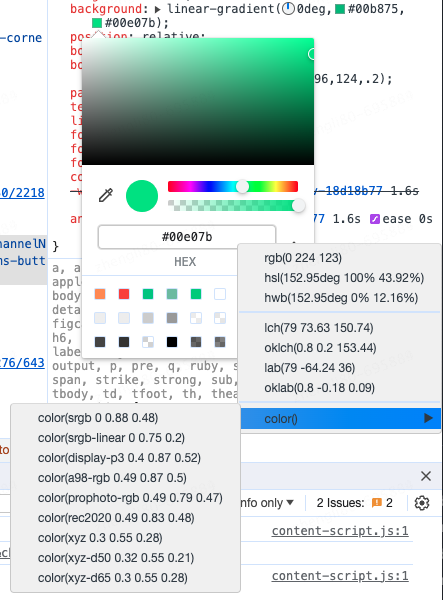
同时在选择了不同的色彩空间后,色彩的可调节参数也会相应改变。
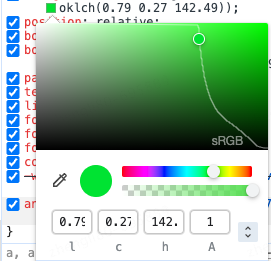
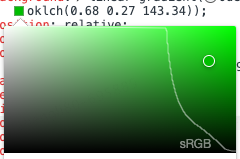
当我们选择了一个非sRGB色域的色值后,会发现拾色器的上方区域里会展示一条sRGB的分界线,可以清晰地看出当前选择的颜色所在的色域。这能帮助开发者分辨高清色与非高清色。
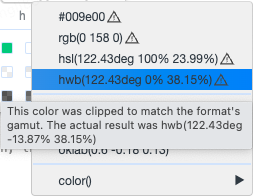
而当我们选择一个超出sRGB范围的颜色后,再来点击色值右侧的箭头弹出选项列表时,会发现sRGB色域下的色值后边会带上一个三角叹号。这说明当前色值已超出了sRGB所能描述的范围,只能使用相近的颜色作为替代。
关于chrome DevTools更多关于高清颜色的更新,可参阅
官方文档
。
总结
sRGB之外的色域和色彩空间目前虽然还刚刚在web端起步,但未来的设计和开发要求可能会慢慢出现,尤其是H5动画、游戏、3D图像等等,对于色彩显示的要求不会永远停留在sRGB阶段,希望本文简陋的介绍能让大家多少开始了解一些关于色彩的东西。如有错误或疏漏,欢迎指正讨论。
参考文章:
1.
https://web.dev/articles/color-spaces-and-functions?hl=en
2.
https://developer.chrome.com/articles/high-definition-css-color-guide/
3.
https://developer.mozilla.org/en-US/docs/Web/CSS/color_value/color
作者:京东科技 郑莉
来源:京东云开发者社区 转载请注明来源