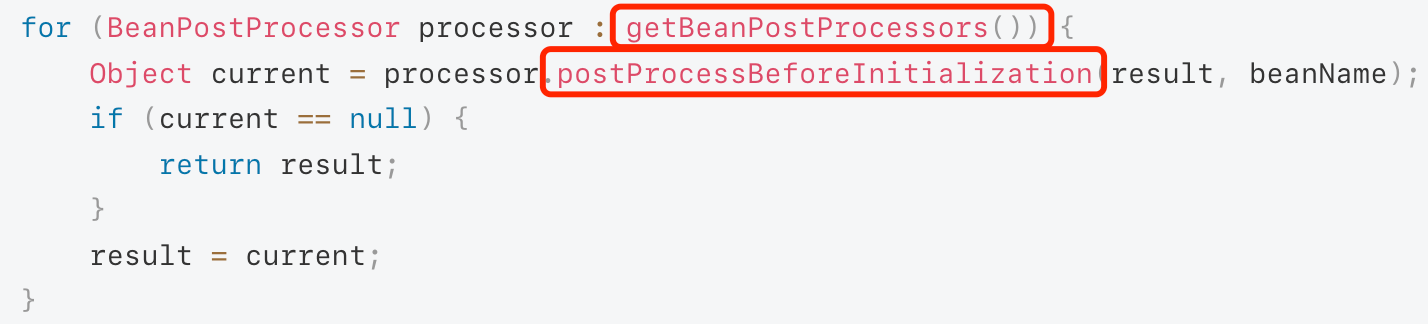
NPCAP 库是一种用于在
Windows
平台上进行网络数据包捕获和分析的库。它是
WinPcap
库的一个分支,由
Nmap
开发团队开发,并在
Nmap
软件中使用。与
WinPcap
一样,NPCAP库提供了一些
API
,使开发人员可以轻松地在其应用程序中捕获和处理网络数据包。NPCAP库可以通过
WinPcap API
进行编程,因此现有的WinPcap应用程序可以轻松地迁移到NPCAP库上。
与WinPcap相比,NPCAP库具有更好的性能和可靠性,支持最新的操作系统和硬件。它还提供了对
802.11
无线网络的本机支持,并可以通过
Wireshark
等网络分析工具进行使用。 NPCAP库是在
MIT
许可证下发布的,因此可以在免费和商业软件中使用。
该工具包分为两部分组成驱动程序及SDK工具包,在使用本库进行抓包时需要读者自行安装对应版本的驱动程序,此处读者使用的版本是
npcap-1.55.exe
当下载后读者可自行点击下一步即可,当安装完成后即可看到如下图所示的提示信息;

当驱动程序安装完成后,读者就可以自行配置开发工具包到项目中,通常只需要将工具包内的
include
及
lib
库配置到项目中即可,如下图所示配置后自行应用保存即可。

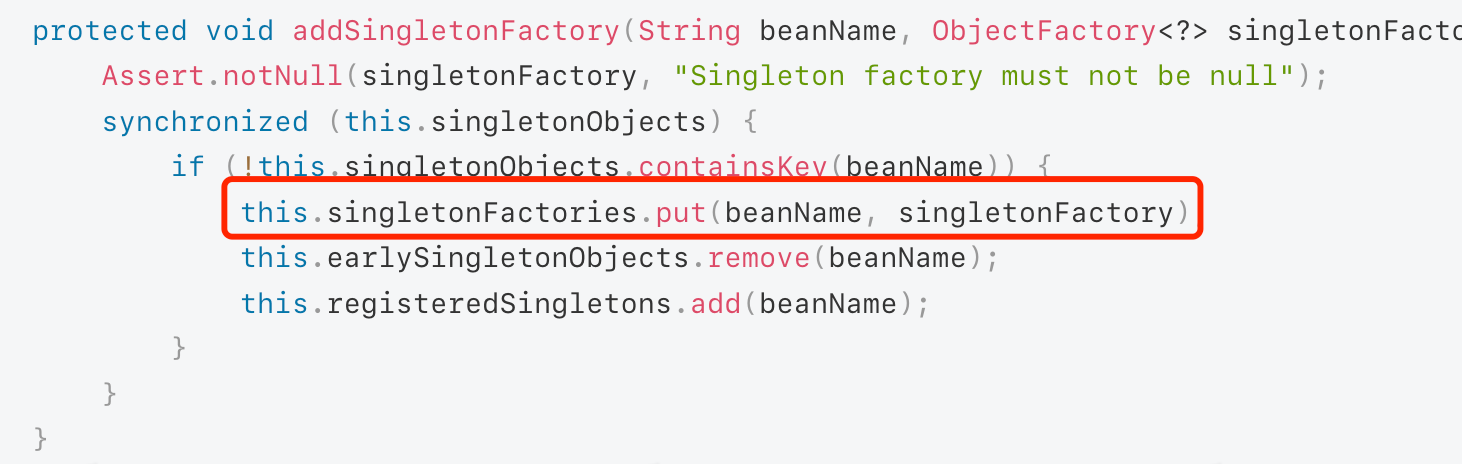
接着我们来实现第一个功能,枚举当前主机中可以使用的网卡信息,该功能的实现主要依赖于
pcap_findalldevs_ex()
函数,该函数用于获取当前系统中可用的所有网络适配器的列表。
函数的原型声明如下:
int pcap_findalldevs_ex(const char *source, struct pcap_rmtauth *auth,
pcap_if_t **alldevsp, char *errbuf);
其中,参数含义如下:
- source:指定远程接口的IP地址,或者为本地接口传入NULL。
- auth:一个指向
pcap_rmtauth
结构来指定远程的IP和用户名。
- alldevsp:一个指向指针,返回主机上可用的设备列表。
- errbuf:一个用于存储错误信息的缓冲区。
该函数允许开发者通过一个结构来检索所有网络适配器的详细信息。它允许指定一个过滤器,以匹配用户定义的网络适配器和属性。此外,
pcap_findalldevs_ex()
还提供用于存储错误信息的结构体,以便在函数调用失败时提供错误信息。
该函数返回值-1表示失败;否则,返回值为0表示操作成功,并将返回所有可用的网络适配器和它们的详细信息。这些详细信息包括适配器的名称、描述、MAC地址、IP地址和子网掩码等,当读者使用枚举函数结束后需要自行调用
pcap_freealldevs
函数释放这个指针以避免内存泄漏。
以下是pcap_freealldevs函数原型声明:
void pcap_freealldevs(pcap_if_t *alldevs);
其中,
alldevs
参数是指向
pcap_if_t
类型结构体的指针,该类型结构体记录了当前主机上所有可用的网络接口的详细信息。
pcap_freealldevs()
会释放传入的
pcap_if_t
型链表,并将所有元素删除。
调用
pcap_freealldevs()
函数时需要传入之前通过
pcap_findalldevs()
或
pcap_findalldevs_ex()
函数获取到的的指向链表结构的指针作为参数。
当有了这两个函数作为条件,那么实现枚举网卡则变得很简单了,如下代码所示则是使用该工具包实现枚举的具体实现流程,读者可自行编译测试。
#include <iostream>
#include <winsock2.h>
#include <Windows.h>
#include <string>
#include <pcap.h>
#pragma comment(lib,"ws2_32.lib")
#pragma comment(lib, "packet.lib")
#pragma comment(lib, "wpcap.lib")
using namespace std;
// 输出线条
void PrintLine(int x)
{
for (size_t i = 0; i < x; i++)
{
printf("-");
}
printf("\n");
}
// 枚举当前网卡
int enumAdapters()
{
pcap_if_t *allAdapters; // 所有网卡设备保存
pcap_if_t *ptr; // 用于遍历的指针
int index = 0;
char errbuf[PCAP_ERRBUF_SIZE];
/* 获取本地机器设备列表 */
if (pcap_findalldevs_ex(PCAP_SRC_IF_STRING, NULL, &allAdapters, errbuf) != -1)
{
PrintLine(100);
printf("索引 \t 网卡名 \n");
PrintLine(100);
/* 打印网卡信息列表 */
for (ptr = allAdapters; ptr != NULL; ptr = ptr->next)
{
++index;
if (ptr->description)
{
printf("[ %d ] \t [ %s ] \n", index - 1, ptr->description);
}
}
}
/* 不再需要设备列表了,释放它 */
pcap_freealldevs(allAdapters);
return index;
}
int main(int argc, char* argv[])
{
enumAdapters();
system("pause");
return 0;
}
编译并以管理员身份运行程序,则读者可看到如下图所示输出结果,其中第一列为网卡索引编号,第二列为网卡名称;

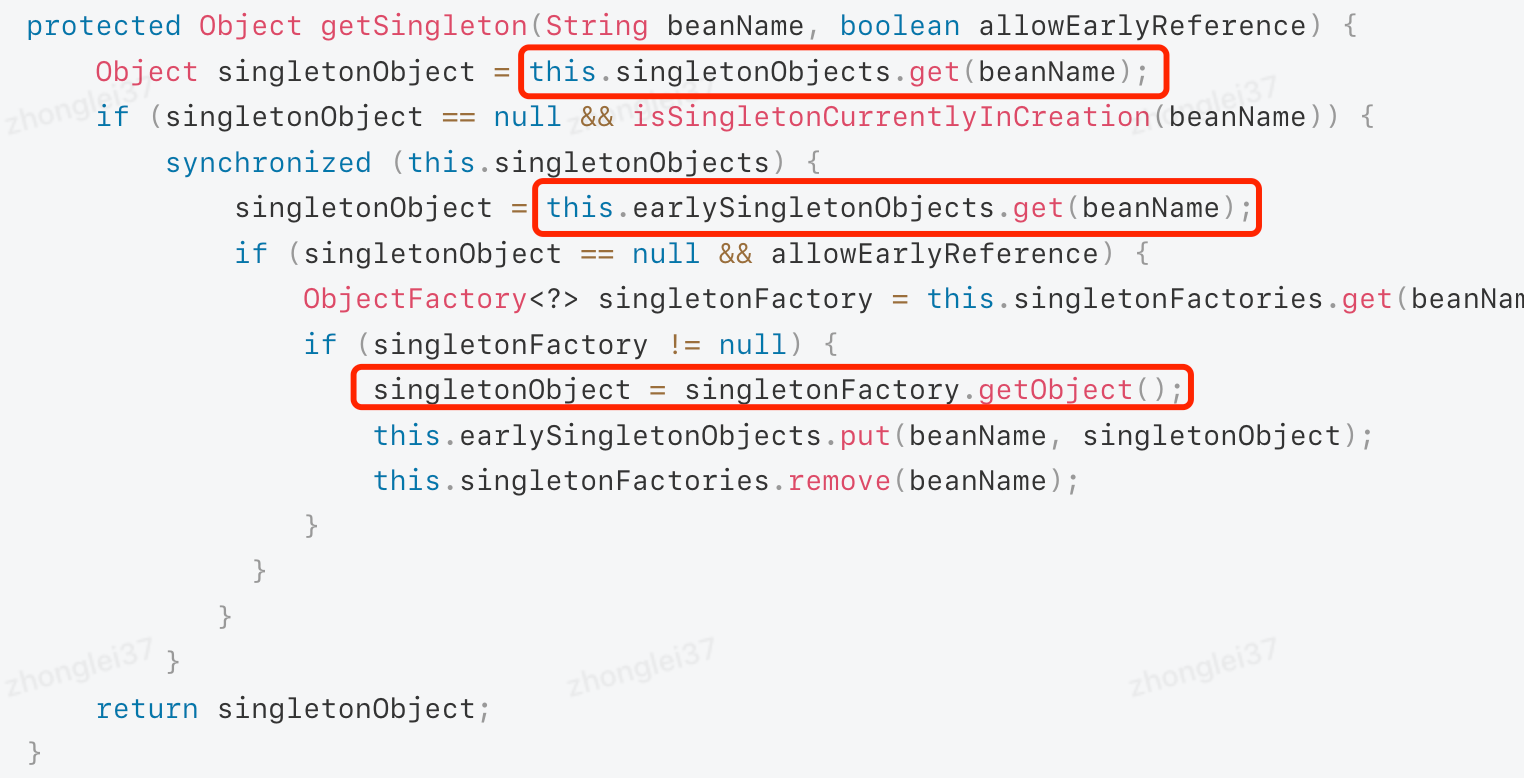
当有了网卡编号后则读者就可以对特定编号进行抓包解析了,抓包功能的实现依赖于
pcap_open()
函数,该函数用于打开一个指定网络适配器并开始捕获网络数据包,函数的原型声明如下所示:
pcap_t *pcap_open(const char *source, int snaplen, int flags, int read_timeout,
struct pcap_rmtauth *auth, char *errbuf);
其参数含义如下:
- source:要打开的网络接口的名称或者是保存在
pcap_open_live()
中获取的名称。
- snaplen:设置捕获数据包的大小。
- flags:设置捕获数据包的模式,在
promiscuous
控制器模式或非
promiscuous
模式下捕获。
- read_timeout:设置阻塞读函数的超时时间以毫秒为单位。
- auth:一个指向
pcap_rmtauth
结构,指定远程的IP和用户名。
- errbuf:一个用于存储错误信息的缓冲区。
该函数返回一个指向
pcap_t
类型的指针,该类型结构提供了与网络适配器通信的接口,可以用于捕获数据包、关闭网络适配器及其他操作,读者在调用
pcap_open()
函数时,需要指定要打开的网络适配器的名称
source
,如果需要设置为混杂模式的话,需要设置
flags
参数为
PCAP_OPENFLAG_PROMISCUOUS
,此外
snaplen
参数用于设置捕获数据包的大小,
read_timeout
参数用于设置阻塞读函数的超时时间,
auth
参数则用于指定远程的
IP
和用户名,
errbuf
参数用于存储错误信息。如果该函数返回空,则表示未成功打开指定的网络适配器。
另一个需要注意的函数是
pcap_next_ex()
该函数用于从打开的指定网络适配器中读取下一个网络数据包,通常情况下此函数需要配合
pcap_open()
一起使用,其原型声明:
int pcap_next_ex(pcap_t *p, struct pcap_pkthdr **pkt_header, const u_char **pkt_data);
参数含义如下:
- p:指向
pcap_t
类型结构体的指针,代表打开的网络适配器。
- pkt_header:一个指向指向
pcap_pkthdr
类型的指针,该类型结构体包含有关当前数据包的元数据,例如时间戳、数据包长度、捕获到数据包的网络适配器接口等。
- pkt_data:一个指向被捕获的数据包的指针。
它返回以下三种返回值之一:
- 1:成功捕获一个数据包,
pkt_header
和
pkt_data
则指向相关信息;
- 0:在指定的时间内未捕获到任何数据包;
- -1:发生错误,导致无法从网络适配器读取数据包。此时可以在
errbuf
参数中查找错误信息。
使用
pcap_next_ex()
函数时,需要提供一个指向
pcap_t
类型结构体的指针
p
用于确定要从哪个网络适配器读取数据包。如果读取数据包时成功,则将包的元数据存储在传递的
pcap_pkthdr
指针中,将指向捕获数据包的指针存储在
pkt_data
指针中。如果在指定的时间内未捕获到任何数据包,则函数返回0。如果在读取数据包时发生任何错误,则函数返回-1,并在
errbuf
参数中提供有关错误的详细信息。
当读者理解了上述两个关键函数的作用则就可以实现动态抓包功能,如下代码中的
MonitorAdapter
函数则是抓包的实现,该函数需要传入两个参数,参数1是需要抓包的网卡序列号,此处我们就使用7号,第二个参数表示需要解码的数据包类型,此处我们可以传入
ether
等用于解包,当然该函数还没有实现数据包的解析功能,这些功能的实现需要继续完善。
#include <iostream>
#include <winsock2.h>
#include <Windows.h>
#include <string>
#include <pcap.h>
#pragma comment(lib,"ws2_32.lib")
#pragma comment(lib, "packet.lib")
#pragma comment(lib, "wpcap.lib")
using namespace std;
// 选择网卡并根据不同参数解析数据包
void MonitorAdapter(int nChoose, char *Type)
{
pcap_if_t *adapters;
char errbuf[PCAP_ERRBUF_SIZE];
if (pcap_findalldevs_ex(PCAP_SRC_IF_STRING, NULL, &adapters, errbuf) != -1)
{
// 找到指定的网卡
for (int x = 0; x < nChoose - 1; ++x)
adapters = adapters->next;
// PCAP_OPENFLAG_PROMISCUOUS = 网卡设置为混杂模式
// 1000 => 1000毫秒如果读不到数据直接返回超时
pcap_t * handle = pcap_open(adapters->name, 65534, 1, PCAP_OPENFLAG_PROMISCUOUS, 0, 0);
if (adapters == NULL)
return;
// printf("开始侦听: % \n", adapters->description);
pcap_pkthdr *Packet_Header; // 数据包头
const u_char * Packet_Data; // 数据本身
int retValue;
while ((retValue = pcap_next_ex(handle, &Packet_Header, &Packet_Data)) >= 0)
{
if (retValue == 0)
continue;
// printf("侦听长度: %d \n", Packet_Header->len);
if (strcmp(Type, "ether") == 0)
{
PrintEtherHeader(Packet_Data);
}
if (strcmp(Type, "ip") == 0)
{
PrintIPHeader(Packet_Data);
}
if (strcmp(Type, "tcp") == 0)
{
PrintTCPHeader(Packet_Data);
}
if (strcmp(Type, "udp") == 0)
{
PrintUDPHeader(Packet_Data);
}
if (strcmp(Type, "icmp") == 0)
{
PrintICMPHeader(Packet_Data);
}
if (strcmp(Type, "http") == 0)
{
PrintHttpHeader(Packet_Data);
}
if (strcmp(Type, "arp") == 0)
{
PrintArpHeader(Packet_Data);
}
}
}
}
int main(int argc, char* argv[])
{
MonitorAdapter(7,"ether");
system("pause");
return 0;
}
当读者有了上述代码框架,则下一步就是依次实现
PrintEtherHeader
,
PrintIPHeader
,
PrintTCPHeader
,
PrintUDPHeader
,
PrintICMPHeader
,
PrintHttpHeader
,
PrintArpHeader
等函数,这些函数接收原始数据包
Packet_Data
类型,并将其转换为对应格式的数据包输出给用户,接下来我们将依次实现这些功能。
解码以太网层数据包
以太网数据包是一种在以太网上发送的数据包格式。它通常包括以太网头部和以太网数据部分。以下是它的各个部分的介绍:
以太网头部:包括目标MAC地址、源MAC地址以及类型/长度字段。目标MAC地址和源MAC地址是6个字节的二进制数,分别表示数据包的目标和来源。类型/长度字段用于表示数据部分的长度或指定所使用的网络层协议。如果类型/长度字段小于等于1500,则指示数据部分的长度;否则,它表示使用的协议类型。
以太网数据部分:包括所有的上层网络协议标头和数据。以太网数据部分的长度通常大于46个字节,并且最大长度为1500个字节。
以太网数据包通常用于在局域网上进行通信。使用以太网帧作为数据包格式,将数据包发送到这个网络上的所有设备。然后,目标设备根据目标MAC地址,接收和处理这些帧,其它设备会忽略这些帧。在以太网数据包中,目标MAC地址指的是数据包要发送到的目标设备的唯一MAC地址,而源MAC地址则指的是发送此消息的设备的MAC地址。
// 解码数据链路数据包 数据链路层为二层,解码时只需要封装一层ether以太网数据包头即可.
#define hcons(A) (((WORD)(A)&0xFF00)>>8) | (((WORD)(A)&0x00FF)<<8)
void PrintEtherHeader(const u_char * packetData)
{
typedef struct ether_header
{
u_char ether_dhost[6]; // 目标地址
u_char ether_shost[6]; // 源地址
u_short ether_type; // 以太网类型
} ether_header;
struct ether_header * eth_protocol;
eth_protocol = (struct ether_header *)packetData;
u_short ether_type = ntohs(eth_protocol->ether_type); // 以太网类型
u_char *ether_src = eth_protocol->ether_shost; // 以太网原始MAC地址
u_char *ether_dst = eth_protocol->ether_dhost; // 以太网目标MAC地址
printf("类型: 0x%x \t", ether_type);
printf("原MAC地址: %02X:%02X:%02X:%02X:%02X:%02X \t",
ether_src[0], ether_src[1], ether_src[2], ether_src[3], ether_src[4], ether_src[5]);
printf("目标MAC地址: %02X:%02X:%02X:%02X:%02X:%02X \n",
ether_dst[0], ether_dst[1], ether_dst[2], ether_dst[3], ether_dst[4], ether_dst[5]);
}
由于以太网太过于底层,所以解析以太网我们只能得到一些基本的网卡信息,如下图所示;

解码IP层数据包
IP(Internet Protocol)数据包是在TCP/IP(传输控制协议/互联网协议)协议栈中的第三层。它通常包括IP头部和数据部分两部分。
IP头部通常包括以下内容:
- 版本号:表示所使用的IP协议版本号。
- 头部长度:表示整个IP头部的长度。TCP/IP协议中的长度都以字节(byte)为单位计数。
- 总长度:表示整个IP数据包的长度,包括头部和有效负载部分。
- TTL:生存时间,用于限制路由器转发该数据包的次数。
- 协议:表示上层使用的协议类型。
- 源IP地址:发送该数据包的设备的IP地址。
- 目标IP地址:发送该数据包的目标设备的IP地址。
- 数据部分则是上层协议中传输的实际数据。
IP数据包是在网络层传输的,它的主要功能是为互联网中的各种应用程序之间提供包传输服务。它使用IP地址来确定数据包从哪里发出,以及数据包应该被路由到达目标设备。
在接收到IP数据包时,网络设备首先检查数据包头的目标IP地址,然后使用路由表来找到传输该数据包所需的下一个节点(下一跳),并将数据包传递到该节点。如果某个路由器无法将数据包传递到下一个节点,则该数据包将被丢弃。每个节点都会检查数据包的TTL值,并将其减少1。如果TTL值变为0,则数据包会被丢弃,以防止数据包在网络中循环。
// 解码IP数据包,IP层在数据链路层的下面, 解码时需要+14偏移值, 跳过数据链路层。
void PrintIPHeader(const u_char * packetData)
{
typedef struct ip_header
{
char version : 4;
char headerlength : 4;
char cTOS;
unsigned short totla_length;
unsigned short identification;
unsigned short flags_offset;
char time_to_live;
char Protocol;
unsigned short check_sum;
unsigned int SrcAddr;
unsigned int DstAddr;
}ip_header;
struct ip_header *ip_protocol;
// +14 跳过数据链路层
ip_protocol = (struct ip_header *)(packetData + 14);
SOCKADDR_IN Src_Addr, Dst_Addr = { 0 };
u_short check_sum = ntohs(ip_protocol->check_sum);
int ttl = ip_protocol->time_to_live;
int proto = ip_protocol->Protocol;
Src_Addr.sin_addr.s_addr = ip_protocol->SrcAddr;
Dst_Addr.sin_addr.s_addr = ip_protocol->DstAddr;
printf("源地址: %15s --> ", inet_ntoa(Src_Addr.sin_addr));
printf("目标地址: %15s --> ", inet_ntoa(Dst_Addr.sin_addr));
printf("校验和: %5X --> TTL: %4d --> 协议类型: ", check_sum, ttl);
switch (ip_protocol->Protocol)
{
case 1: printf("ICMP \n"); break;
case 2: printf("IGMP \n"); break;
case 6: printf("TCP \n"); break;
case 17: printf("UDP \n"); break;
case 89: printf("OSPF \n"); break;
default: printf("None \n"); break;
}
}
针对IP层数据包的解析可能会较为复杂,因为
IP
协议上方可以包含
ICMP,IGMP,TCP,UDP,OSPF
等协议,在运行程序后读者会看到如下图所示的具体信息;

解码TCP层数据包
TCP(Transmission Control Protocol)层数据包是在TCP/IP(传输控制协议/互联网协议)协议栈中的第四层。它包括TCP头部和数据部分两个部分。
TCP头部通常包括以下内容:
- 源端口号:表示发送该数据包的应用程序的端口号。
- 目的端口号:表示接收该数据包的应用程序的端口号。
- 序列号:用于将多个数据包排序,确保它们在正确的顺序中到达接收方应用程序。
- 确认号:用于确认接收方已经成功收到序列号或最后一个被成功接收的数据包。
- ACK和SYN标志:这些是TCP头部中的标志位,用于控制TCP连接的建立和关闭。
- 窗口大小:用于控制数据流发送的速率,并确保不会发送太多的数据包,导致网络拥塞。
- 校验和:用于校验TCP头部和数据部分是否被损坏或篡改。
- 数据部分则是上层应用程序传递到TCP层的应用数据。
TCP是一个面向连接的协议,因此在发送数据之前,TCP会先在发送方和接收方之间建立连接。该连接建立的过程包括三次握手(three-way handshake)过程,分别是客户端发起连接请求、服务器发回确认、客户端再次发送确认。完成连接后,TCP协议根据确认号和序列号来控制数据包的传输次序和有效性(如ACK报文的确认和重传消息),以提供高效的数据传输服务。
当TCP数据包到达目标设备后,TCP层将在接收方重新组装TCP数据,将TCP报文分割成应用层可用的更小的数据块,并将其发送到目标应用程序。如果发送的TCP协议数据包未被正确地接收,则TCP协议将重新尝试发送丢失的数据包,以确保数据的完整性和正确性。
// 解码TCP数据包,需要先加14跳过数据链路层, 然后再加20跳过IP层。
void PrintTCPHeader(const unsigned char * packetData)
{
typedef struct tcp_header
{
short SourPort; // 源端口号16bit
short DestPort; // 目的端口号16bit
unsigned int SequNum; // 序列号32bit
unsigned int AcknowledgeNum; // 确认号32bit
unsigned char reserved : 4, offset : 4; // 预留偏移
unsigned char flags; // 标志
short WindowSize; // 窗口大小16bit
short CheckSum; // 检验和16bit
short surgentPointer; // 紧急数据偏移量16bit
}tcp_header;
struct tcp_header *tcp_protocol;
// +14 跳过数据链路层 +20 跳过IP层
tcp_protocol = (struct tcp_header *)(packetData + 14 + 20);
u_short sport = ntohs(tcp_protocol->SourPort);
u_short dport = ntohs(tcp_protocol->DestPort);
int window = tcp_protocol->WindowSize;
int flags = tcp_protocol->flags;
printf("源端口: %6d --> 目标端口: %6d --> 窗口大小: %7d --> 标志: (%d)",
sport, dport, window, flags);
if (flags & 0x08) printf("PSH 数据传输\n");
else if (flags & 0x10) printf("ACK 响应\n");
else if (flags & 0x02) printf("SYN 建立连接\n");
else if (flags & 0x20) printf("URG \n");
else if (flags & 0x01) printf("FIN 关闭连接\n");
else if (flags & 0x04) printf("RST 连接重置\n");
else printf("None 未知\n");
}
针对TCP的解析也较为复杂,这是因为TCP协议存在多种状态值,如
PSH、ACK、SYN、URG、FIN
和
RST
这些都是
TCP
报文段中用于标识不同信息或状态的标志位。这些TCP标志位的含义如下:
- PSH(Push):该标志位表示接收端应用程序应立即从接收缓存中读取数据。通常在发送方需要尽快将所有数据发送给接收方时使用。
- ACK(Acknowledgment):该标志位表示应答。用于确认已经成功接收到别的TCP包。在TCP连接建立完成后,所有TCP报文段都必须设置ACK标志位。
- SYN(Synchronous):该标志位用于建立TCP连接。指示请求建立一个连接,同时序列号以随机数ISN开始。发送SYN报文的一端会进入SYN_SENT状态。
- URG(Urgent):该标志位表示紧急指针有效。它用于告知接收端在此报文段中存在紧急数据,紧急数据应该立即送达接收端的应用层。
- FIN(Finish):此标志用于终止TCP连接。FIN标志位被置位的一端表明它已经发送完所有数据并要求释放连接。
- RST(Reset):该标志用于重置TCP连接。当TCP连接尝试建立失败,或一个已关闭的套接字收到数据,都会发送带RST标志的数据包。
这些标志位的设置和使用可以帮助TCP在应用层和网络层之间进行可靠的通信,保证数据的传输和连接的建立以及关闭可以正确完成,我们工具同样可以解析这些不同的标志位情况,如下图所示;

解码UDP层数据包
UDP(User Datagram Protocol)层数据包是在TCP/IP(传输控制协议/互联网协议)协议栈中的第四层。它比TCP更简单,不保证数据包的位置和有效性,也不进行连接的建立和维护。UDP数据包仅包含UDP头部和数据部分。
UDP头部包括以下内容:
- 源端口号:表示发起该数据包的应用程序的端口号。
- 目的端口号:表示接收该数据包的应用程序的端口号。
- 数据长度:表示数据包中包含的数据长度。
- 校验和:用于校验UDP头部和数据部分是否被损坏或篡改。
- 数据部分和TCP层数据包类似,是上层应用程序传递到UDP层的应用数据。
UDP协议的优点是传输开销小,速度快,延迟低,因为它不进行高负载的错误检查,也不进行连接建立和维护。但这也意味着数据包传输不可靠,不保证数据传输的完整性和正确性。如果未能正确地接收UDP数据包,则不会尝试重新发送丢失的数据包。UDP通常用于需要快速、简单、低延迟的应用程序,例如在线游戏、视频和音频流媒体等。
// UDP层与TCP层如出一辙,仅仅只是在结构体的定义解包是有少许的不同而已.
void PrintUDPHeader(const unsigned char * packetData)
{
typedef struct udp_header
{
uint32_t sport; // 源端口
uint32_t dport; // 目标端口
uint8_t zero; // 保留位
uint8_t proto; // 协议标识
uint16_t datalen; // UDP数据长度
}udp_header;
struct udp_header *udp_protocol;
// +14 跳过数据链路层 +20 跳过IP层
udp_protocol = (struct udp_header *)(packetData + 14 + 20);
u_short sport = ntohs(udp_protocol->sport);
u_short dport = ntohs(udp_protocol->dport);
u_short datalen = ntohs(udp_protocol->datalen);
printf("源端口: %5d --> 目标端口: %5d --> 大小: %5d \n", sport, dport, datalen);
}
针对UDP协议的解析就变得很简单了,因为UDP是一种无状态协议所以只能得到源端口与目标端口,解析效果如下图所示;

解码ICMP层数据包
ICMP(Internet Control Message Protocol)层数据包是在TCP/IP协议栈中的第三层。它是一种控制协议,用于网络通信中的错误报告和网络状态查询。ICMP数据包通常不携带应用数据或有效载荷。
ICMP数据包通常包括以下类型的控制信息:
- Echo Request/Reply: 用于网络连通性测试,例如ping命令(12/0)
- Destination unreachable: 该类型的ICMP数据包用于向发送者传递对目标无法到达的消息(3/0、3/1、3/2、3/3、3/4、3/5、3/6、3/7、3/8、3/9、3/10)
- Redirect: 用于告知发送方使用新的路由器来发送数据(5/0、5/1、5/2)
- Time exceeded: 用于向发送方报告基于TTL值无法到达目的地,表示跃点数超过了最大限制(11/0、11/1)
- Parameter problem: 用于向发送者报告转发器无法处理IP数据包中的某些字段(12/0)
ICMP数据包还用于其他用途,例如Multicast Listener Discovery(MLD)和Neighbor Discovery Protocol(NDP),用于组播和IPv6网络通信中。
ICMP数据报通常由操作系统或网络设备自动生成,并直接发送给操作系统或网络设备。然后,它们可以通过网络分析工具进行检测和诊断,以确定网络中的错误或故障。
// 解码ICMP数据包,在解包是需要同样需要跳过数据链路层和IP层, 然后再根据ICMP类型号解析, 常用的类型号为`type 8`它代表着发送和接收数据包的时间戳。
void PrintICMPHeader(const unsigned char * packetData)
{
typedef struct icmp_header {
uint8_t type; // ICMP类型
uint8_t code; // 代码
uint16_t checksum; // 校验和
uint16_t identification; // 标识
uint16_t sequence; // 序列号
uint32_t init_time; // 发起时间戳
uint16_t recv_time; // 接受时间戳
uint16_t send_time; // 传输时间戳
}icmp_header;
struct icmp_header *icmp_protocol;
// +14 跳过数据链路层 +20 跳过IP层
icmp_protocol = (struct icmp_header *)(packetData + 14 + 20);
int type = icmp_protocol->type;
int init_time = icmp_protocol->init_time;
int send_time = icmp_protocol->send_time;
int recv_time = icmp_protocol->recv_time;
if (type == 8)
{
printf("发起时间戳: %d --> 传输时间戳: %d --> 接收时间戳: %d 方向: ",
init_time, send_time, recv_time);
switch (type)
{
case 0: printf("回显应答报文 \n"); break;
case 8: printf("回显请求报文 \n"); break;
default:break;
}
}
}
针对ICMP协议的解析也很简单在抓包时我们同样只能得到一些基本的信息,例如发送时间戳,传输时间戳,接收时间戳,以及报文方向等,这里的方向有两种一种是0代表回显应答,而8则代表回显请求,具体输出效果图如下所示;

解码HTTP层数据包
HTTP(Hypertext Transfer Protocol)层数据包是在TCP/IP协议栈中的第七层,它主要用于Web应用程序中的客户机和服务器之间的数据传输。HTTP数据包通常包括HTTP头部和数据部分两个部分。
HTTP头部通常包括以下内容:
- 请求行:用于描述客户机发起的请求。
- 响应行:用于描述服务器返回的响应。
- 头部字段:用于向请求或响应添加额外的元数据信息,例如HTTP版本号、日期、内容类型等。
- Cookie:用于在客户端和服务器之间来保存状态信息。
- Cache-Control:用于客户端和服务器之间控制缓存的行为。
- 数据部分是包含在HTTP请求或响应中的应用数据。
HTTP协议的工作方式是客户端向服务器发送HTTP请求,服务器通过HTTP响应返回请求结果。HTTP请求通常使用HTTP方法,如GET、POST、PUT、DELETE等,控制HTTP操作的类型和行为。HTTP响应通常包含HTTP状态码,如200、404、500等,以指示客户端请求结果的状态。
在实际的网络通信中,HTTP层数据包的格式和内容通常由应用程序或网络设备生成和分析,例如Web浏览器和Web服务器。
// 解码HTTP数据包,需要跳过数据链路层, IP层以及TCP层, 最后即可得到HTTP数据包协议头。
void PrintHttpHeader(const unsigned char * packetData)
{
typedef struct tcp_port
{
unsigned short sport;
unsigned short dport;
}tcp_port;
typedef struct http_header
{
char url[512];
}http_header;
struct tcp_port *tcp_protocol;
struct http_header *http_protocol;
tcp_protocol = (struct tcp_port *)(packetData + 14 + 20);
int tcp_sport = ntohs(tcp_protocol->sport);
int tcp_dport = ntohs(tcp_protocol->dport);
if (tcp_sport == 80 || tcp_dport == 80)
{
// +14 跳过MAC层 +20 跳过IP层 +20 跳过TCP层
http_protocol = (struct http_header *)(packetData + 14 + 20 + 20);
printf("%s \n", http_protocol->url);
}
}
针对HTTP协议的解析同样可以,但由于HTTP协议已经用的很少了所以这段代码也只能演示,在实战中一般会使用HTTPS,如下则是一个HTTP访问时捕获的数据包;

解码ARP层数据包
ARP(Address Resolution Protocol)层数据包是在TCP/IP协议栈中的第二层。ARP协议主要用于将网络层地址(如IP地址)映射到数据链路层地址(如MAC地址)。
ARP数据包通常包括以下内容:
- ARP请求或响应:ARP请求用于获取与IP地址关联的MAC地址,而ARP响应用于提供目标MAC地址。
- 发送者的MAC地址:发送ARP请求或响应的设备的MAC地址。
- 发送者的IP地址:发送ARP请求或响应的设备的IP地址。
- 目标的MAC地址:目标设备的MAC地址。
- 目标的IP地址:目标设备的IP地址。
ARP协议工作的过程如下:
- 发送者主机发送一个ARP请求,包含目标IP地址。
- 网络中的所有设备都收到该ARP请求。
- 如果有设备的IP地址与ARP请求中的目标IP地址匹配,该设备会回复ARP响应,包含自己的MAC地址。
- 发送者主机使用响应中的MAC地址来与该设备通信。
ARP协议的工作主要是在本地网络中实现地址映射,主要包括确定哪个设备的MAC地址与特定的IP地址关联,以及应答IP地址转化成相应的MAC地址的映射请求。ARP通常用于以太网和WiFi网络中,以实现局域网内的设备通信。
// 解码ARP数据包
void PrintArpHeader(const unsigned char * packetData)
{
typedef struct arp_header
{
uint16_t arp_hardware_type;
uint16_t arp_protocol_type;
uint8_t arp_hardware_length;
uint8_t arp_protocol_length;
uint16_t arp_operation_code;
uint8_t arp_source_ethernet_address[6];
uint8_t arp_source_ip_address[4];
uint8_t arp_destination_ethernet_address[6];
uint8_t arp_destination_ip_address[4];
}arp_header;
struct arp_header *arp_protocol;
arp_protocol = (struct arp_header *)(packetData + 14);
u_short hardware_type = ntohs(arp_protocol->arp_hardware_type);
u_short protocol_type = ntohs(arp_protocol->arp_protocol_type);
int arp_hardware_length = arp_protocol->arp_hardware_length;
int arp_protocol_length = arp_protocol->arp_protocol_length;
u_short operation_code = ntohs(arp_protocol->arp_operation_code);
// 判读是否为ARP请求包
if (arp_hardware_length == 6 && arp_protocol_length == 4)
{
printf("原MAC地址: ");
for (int x = 0; x < 6; x++)
printf("%x:", arp_protocol->arp_source_ethernet_address[x]);
printf(" --> ");
printf("目标MAC地址: ");
for (int x = 0; x < 6; x++)
printf("%x:", arp_protocol->arp_destination_ethernet_address[x]);
printf(" --> ");
switch (operation_code)
{
case 1: printf("ARP 请求 \n"); break;
case 2: printf("ARP 应答 \n"); break;
case 3: printf("RARP 请求 \n"); break;
case 4: printf("RARP 应答 \n"); break;
default: break;
}
}
}
解析ARP协议同样可以实现,ARP协议同样有多个状态,一般
1-2
代表请求与应答,
3-4
代表RARP反向请求与应答,ARP协议由于触发周期短所以读者可能很少捕捉到这类数据,如下图时读者捕捉到的一条完整的ARP协议状态;

本文作者: 王瑞
本文链接:
https://www.lyshark.com/post/526b8a6.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!