.NET周刊【10月第3期 2023-10-22】
国内文章
.NET 8 RC 2 发布,将在11月14日发布正式版
https://www.cnblogs.com/shanyou/p/17756172.html
微软于2023年10月10日发布了.NET 8 RC 2,预计在下个月的Net Conf 2023期间正式发布.NET 8。.NET 8的所有主要新功能已经推出,开发团队将在接下来的一个月内主要专注于改进功能和修复错误。此外,Tiobe编程语言排行榜显示,C#的上升趋势明显,预计在大约两个月内将超过Java。.NET团队还在官方博客上发布了一系列文章,介绍.NET 8框架以及相关的ASP.NET Core、MAUI、EF Core、Visual Studio 2022 17.8的功能特性。
OpenTelemetry学习笔记-Trace
https://mp.weixin.qq.com/s/X-aiCMaVIzcz0lSM22jpfQ
文章是关于OpenTelemetry的学习笔记,主要介绍了以下内容:
- OpenTelemetry是一个可观测性的框架和工具包,目的是创建和管理遥测数据,如traces、metrics和logs。
- OpenTelemetry有两个重要的优势:你可以拥有自己生成的数据,而不是被专有数据格式或工具;你可以学习一组API和约定。
- OpenTelemetry中trace表示一组有序的事件,描述了分布式系统中一个操作的生命周期。每个trace由一系列的span组成,每个span描述了一个子任务或步骤。
- OpenTelemetry中resource描述了程序正在消费的物理和虚拟信息结构,包括一些基本信息和配置设置。
- OpenTelemetry提供了一套通用的server attributes,用于描述服务端的属性。
.NET静态代码织入——肉夹馍(Rougamo)发布2.0
https://www.cnblogs.com/nigture/p/17753498.html
"肉夹馍"是一种实现AOP的组件,主要特点是在编译时完成AOP代码织入,减少应用启动的初始化时间,提高服务可用性,还能对静态方法进行AOP。2.0版本推出了新功能,包括部分织入,用户可以根据需要选择使用的功能,避免无形中增加目标程序集的大小,提高运行效率。例如,如果只想在方法执行成功或失败时执行日志操作,不需要重写参数、修改返回值或处理异常,可以通过重写Features属性来选择使用到的功能。
.NET高性能开发-位图索引(一)
https://www.cnblogs.com/InCerry/p/dotnet-bitmap-index-part-1.html
本文主要讨论了如何使用.NET构建内存位图索引优化搜索引擎计算速度。以机票搜索为例,由于航班数据量大且实时变动,传统数据库无法满足实时搜索需求。业界解决方案是将数据加载到内存进行计算,但如何在短时间内处理大量数据仍是挑战。文章提出了使用位图索引的方法,通过构建和使用位图索引,可以优化搜索引擎的计算速度。文章还将深入讨论位图索引的性能,如何通过SIMD加速位图索引的计算,以及构建高效的Bitmap内存索引库等问题。
WPF 笔迹算法 从点集转笔迹轮廓
https://www.cnblogs.com/lindexi/p/17758666.html
本文介绍了笔迹算法,这是一种基础数学算法,可以将用户输入的点集(如鼠标轨迹点或触摸轨迹点)转换为可在界面上绘制显示的笔迹画面。虽然本文以WPF的笔迹算法为例,但其基础数学计算理论上适用于任何支持几何绘制的UI框架。文章从简单到复杂描述了笔迹算法,包括最简单的笔迹轨迹算法,即通过创建一条几何图形(如折线)来构建笔迹轨迹。
【源码解读(一)】EFCORE源码解读之创建DBContext查询拦截
https://www.cnblogs.com/1996-Chinese-Chen/p/17761733.html
本文主要讲解了EFCore源码的一些关键部分。首先,文章解释了AddDbContext的作用,它是EFCore提供的几种扩展方法之一,用于设置DbContext和DBContextOption的生命周期。如果DBContext的生命周期是单例,Option的生命周期也应设置为单例。如果设置Option的委托不为空,那么DBContext的构造函数必须有一个参数。此外,文章还介绍了如何在EFCore的服务中获取Web注入的服务,拦截查询的方式,使用缓存查询方法提升性能,以及如何托管EFCORE的IOC容器等内容。
使用 OpenTelemetry 构建 .NET 应用可观测性(4):ASP.NET Core 应用中集成 OTel
https://www.cnblogs.com/eventhorizon/p/17760641.html
本文介绍了如何在ASP.NET Core应用中集成OTel SDK,并使用elastic构建可观测性平台展示OTel的数据。elastic提供了一套完整的可观测性平台,并支持OpenTelemetry protocol (OTLP)协议。elastic apm部署相对复杂,可以参考elastic的官方文档进行部署或直接购买elastic cloud。为了方便学习,作者提供了一个elastic的docker-compose文件,包含了elasticsearch、kibana、apm-server和fleet-server等组件。启动完成后,还需要一些配置才能启用apm-server。
4款.NET开源的Redis客户端驱动库
https://www.cnblogs.com/Can-daydayup/p/17760613.html
本文推荐了四款.NET开源免费的Redis客户端驱动库。Redis是一个开源的NoSQL数据库。NewLife.Redis是一个以高性能处理大数据实时计算为目标的Redis客户端组件,支持.NETCore/.NET4.0/.NET4.5。csredis是.NET Core或.NET Framework 4.0+的Redis客户端,支持同步和异步客户端。FreeRedis是基于.NET的Redis客户端,支持.NET Core 2.1+、.NET Framework 4.0+以及Xamarin。StackExchange.Redis是一个基于.NET的高性能Redis客户端,提供了完整的Redis数据库功能支持,并且具有多节点支持、异步编程模型、Redis集群支持等特性。此外,还介绍了DotNetGuide技术交流群,提供.NET开发者分享自己优质文章的群组和获取更多全面的C#/.NET/.NET Core学习资料、视频、文章、书籍,社区组织,工具和常见面试题资源。
.NET微服务系列之Saga分布式事务案例实践
https://www.cnblogs.com/linguicheng/p/17728458.html
本文主要分享了使用Wing进行Saga分布式事务的实践案例,以“跨行转账”为例。假设有“中国农业银行”和“中国工商银行”的账户,需要从农业银行转账1000元到工商银行。这个过程被分为两个事务单元处理:1. 当前账户扣减1000元,定义一个事务单元的数据传输模型和实现类。如果事务策略是“向前恢复”,则只需实现“Commit”方法,否则还需实现“Cancel”方法。
.NET 8 候选版本 2 (RC2) 现已可用
https://www.cnblogs.com/hejiale010426/p/17756402.html
".NET 8 候选版本 2 (RC2)已经发布,包含了许多ASP.NET Core的新改进。这是今年晚些时候发布的最终.NET 8版本之前的最后一个候选版本,大部分计划中的功能和更改都已包含在此版本中。新功能包括服务器和中间件的HTTP日志扩展性和更新到IdentityModel 7x,API创作中的表单文件支持,SignalR的Typescript客户端有状态重新连接支持,以及Blazor的多项改进。要开始使用.NET 8 RC2中的ASP.NET Core,需要安装.NET 8 SDK。如果在Windows上使用Visual Studio,建议安装最新的Visual Studio 2022预览版。如果使用的是Visual Studio Code,可以尝试新的C# Dev Kit。"
Util应用框架 7.x 来了
https://www.cnblogs.com/xiadao521/p/Util-7x.html
Util是一个.Net平台的应用框架,旨在提升中小团队的开发能力。最新版本7.x与.Net最新稳定版本同步更新,代码经过完全重写,提升了模块化程度,增加了对本地化、多租户等需求的支持。Util使用NgZorro作为UI基础组件库,封装了NgZorro绝大部分组件,并对常用功能进行扩展。新版本还集成和封装了Dapr微服务框架的几个常见构造块,并开发了基于Razor引擎的简易代码生成器。Util的所有项目发布时会在Github和Gitee进行同步更新。
Bridge 桥接模式简介与 C# 示例【结构型2】【设计模式来了_7】
https://www.cnblogs.com/hnzhengfy/p/SJMSLL_Bridge.html
本文介绍了桥接模式,这是一种结构型设计模式,通过将抽象与实现分离,实现松耦合。桥接模式可以使抽象和实现独立扩展,不会相互影响。例如,学生和餐品可以看作两个变化的类,老师就像桥接模式中的桥,学生想吃什么套餐,可以通过老师来对应到具体的套餐类别。桥接模式的优点包括分离抽象接口及其实现部分,提高系统的可扩展性,减少子类的个数。但使用桥接模式会增加系统的理解与设计难度,且使用范围具有一定的局限性。在游戏开发、网络编程、图形界面开发等场景中,桥接模式都有实际应用。
Semantic Kernel .NET SDK 的 v1.0.0 Beta1 发布
https://www.cnblogs.com/shanyou/p/17758153.html
Semantic Kernel(SK)是一个开源的SDK,将大型语言模型与流行的编程语言相结合,支持Java、Python和C#。它提供了添加内存和AI服务的连接器,支持来自不同提供商的插件,简化了AI服务的集成。SK的.NET SDK的v1.0.0 Beta1已发布,包括多项更改和改进,如将包和类从“技kill”重命名为“插件”,添加对多个AI模型的支持,重构规划器和内存配置等。如果需要从0.24版本升级到v1.0.0 Beta1,需要更新NuGet包和代码。此外,本文还介绍了如何简单地开始使用Semantic Kernel。
轻量通讯协议 --- MQTT
https://www.cnblogs.com/pandefu/p/17755762.html
本文介绍了MQTT(Message Queuing Telemetry Transport),这是一种轻量级的消息传输协议,常用于物联网和传感器网络中的通信。MQTT的特点包括轻量级、发布/订阅模型、可靠性、持久会话、QoS(Quality of Service)和适应性。MQTT还提供了QoS机制,以确保消息的可靠传递。此外,文章还介绍了MQTTnet,这是一个开源的、基于MQTT的通信的高性能.NET库。最后,文章介绍了Windows下的MQTT消息服务器的安装使用,包括Mosquitto和EMQX两种常见的MQTT服务器软件。
Skywalking APM监控系列(一丶.NET5.0+接入Skywalking监听)
https://www.cnblogs.com/GuZhenYin/p/17757705.html
本文主要介绍了Skywalking的使用和部署。Skywalking是一款分布式链路追踪组件,用于解决微服务架构中的问题,如服务故障定位、响应延迟原因分析、性能瓶颈定位等。Skywalking具有多种监控手段,支持多语言,轻量高效,模块化,并提供优秀的可视化解决方案。文章还详细介绍了如何通过Docker部署Skywalking和ES数据库。
C#学习笔记--复杂数据类型、函数和结构体
https://www.cnblogs.com/TonyCode/p/17757597.html
本文介绍了C#的复杂数据类型,包括枚举、数组和结构体。枚举是整型常量的集合,可以方便表示对象的各种状态,例如怪物的种类、玩家的动作状态等。数组是存储同一种特定变量类型的有序数据集合,可以是一维数组或多维数组。结构体是任意变量类型的数据组合成的数据块。这些复杂数据类型在编程中有广泛的应用,可以提高代码的可读性和可维护性。
Asp-Net-Core开发笔记:EFCore统一实体和属性命名风格
https://www.cnblogs.com/deali/p/17751279.html
本文介绍了如何在C#和数据库中实现命名风格的转换。在C#编码规范中,类和属性使用大写驼峰命名,而数据库通常使用小写蛇形命名。FreeSQL内置了命名风格转换功能,可以实现PascalCase到snake_case的转换。而EFCore没有这个功能,需要我们自行实现。我们可以使用正则表达式来实现这个功能,写一个扩展方法,该方法会在每个小写字母/数字与大写字母之间添加下划线,并把整个字符串转换为小写。然后,我们可以重写DbContext的OnModelCreating方法,对表名、列名、key、index的名称做转换。
使用Docker buildx 为 .NET 构建多平台镜像
https://www.cnblogs.com/shanyou/p/17765247.html
.NET团队的博客介绍了如何使用Docker的buildx工具在.NET 7以上的平台上构建多平台镜像。buildx是Docker的一个构建工具,可以快速、高效地构建Docker镜像,并支持多种平台的构建。用户可以在单个命令中构建多种架构的镜像,例如x86和ARM架构,而无需手动操作多个构建命令。buildx还支持Dockerfile的多阶段构建和缓存,这可以大大提高镜像构建的效率和速度。要使用buildx,需要Docker Engine版本号大于等于19.03。使用buildx构建跨平台镜像,需要先创建一个builder。然后,可以使用一条命令构建跨平台镜像。
Composite 组合模式简介与 C# 示例【结构型3】【设计模式来了_8】
https://www.cnblogs.com/hnzhengfy/p/SJMLLL_Composite.html
本文介绍了组合设计模式,这是一种针对树形结构的设计模式,所有节点实现同一接口,具有相同的操作,可以遍历全部节点。组合模式通过树形结构组合对象,表示部分和整体层次,属于结构型模式,多用于递归。优点包括高层模块调用简单,节点自由,简化了客户端代码。缺点包括叶子节点可能继承不需要的方法,组合类的引用开销可能大,需要运行时判断特殊组件。适用场景包括客户端可以忽略组合对象与单个对象的差异,以及对象层次具备整体和部分,呈树形结构。最后,文章提供了一个代码示例来解释这个概念。
OpenSSL 生成 RootCA (根证书)并自签署证书(支持 IP 地址)
https://www.cnblogs.com/aobaxu/p/17754721.html
本文介绍了如何在Ubuntu 22.04机器上生成HTTPS证书。首先,生成根CA的私钥和证书。然后,为特定IP(例如10.12.0.2)生成私钥和证书请求文件。接着,创建证书扩展文件以确保签名的证书能用作服务器身份验证。最后,使用根CA的证书为特定IP签名证书。此外,还介绍了如何在Ubuntu、CentOS和Windows上信任根CA的证书,以及如何在ASP.NET CORE应用中使用生成的证书。
为.NET打开新大门:OpenVINO.NET开源项目全新发布
https://www.cnblogs.com/sdflysha/p/20231015-sdcb-openvino-net.html
本文介绍了OpenVINO.NET开源项目的全新发布。OpenVINO是Intel开发的一款开源工具包,用于优化深度学习模型并进行推理部署,支持跨不同的Intel硬件平台。然而,对于.NET世界来说,OpenVINO的C API并没有一个合适且高质量的封装,因此作者开发了OpenVINO.NET项目。使用OpenVINO.NET的最简单方法是使用作者发布的NuGet包,包括Sdcb.OpenVINO和Sdcb.OpenVINO.runtime.win-x64等。作者还发布了一个基于Linux的镜像sdflysha/openvino-base,用于减轻部署压力。
详解.NET依赖注入中对象的创建与“销毁”
https://www.cnblogs.com/tenleft/p/17766501.html
本文主要介绍了DI容器如何创建和销毁对象。DI容器可以注册类型并创建其实例,如果类型实现了IAsyncDisposable或IDisposable接口,DI容器还会在适当的时候调用对象的DisposeAsync或Dispose方法。文章详细解释了DI容器中类的三种生命周期:Singleton(单例)、Scoped(局部单例)和Transient(每次都创建新对象)。在ASP.NET CORE中,每次请求会创建一个Scope,生命周期为Scoped的类在一次请求中只会创建一次。最后,文章深入探讨了ServiceProvider类在对象创建和销毁过程中的关键作用。
【分段传输】c#使用IAsyncEnumerable实现流式分段传输
https://www.cnblogs.com/1996-Chinese-Chen/p/17776939.html
本文主要讨论了使用C#的IAsyncEnumerable和ajax实现流式传输的方法。在使用SSE进行流式传输时,存在连接独占和数据格式固定的问题。而使用C#的IAsyncEnumerable可以解决这些问题,但返回的数据是在之前返回的基础上进行累加,需要自己处理。文章中提供了一个使用ajax实现的例子,通过监听请求的进度,可以获取到每一次写了哪些东西,从而实现流传输。同时,群友也提供了fetch的实现代码。
VS Code C# 开发工具包正式发布
https://www.cnblogs.com/Can-daydayup/p/17780747.html
微软正式发布了Visual Studio Code C#开发工具包,经过四个月的测试和调整,修复了350多个问题,并进行了300多项改进。C#开发工具包旨在提高在VS Code中使用C#的工作效率,它与C#扩展协同工作,打造了一个高性能、可扩展且灵活的工具环境。该工具包由一组VS Code扩展组成,提供丰富的C#编辑体验、AI驱动的开发、解决方案管理和集成测试。C#开发工具包的发布,提升了.NET的开发和工作效率。
Avalonia 实现视频聊天、远程桌面(源码,支持Windows、Linux、国产OS)
https://www.cnblogs.com/shawshank/p/17761146.html
本文介绍了基于.NET Core的跨平台UI框架Avalonia,它可以运行在任何支持.NET Core的平台上,包括Windows和Linux等。作者以一个视频聊天的Demo为例,展示了Avalonia的应用,该Demo支持视频聊天和远程桌面功能。用户可以向其他在线用户发送视频聊天或远程桌面请求,接受或拒绝其他用户的请求,开启视频聊天或远程桌面连接,也可以主动断开连接。该Demo的开发环境包括Visual Studio 2022,.NET Core 3.1和C#语言。
字符串 - 不可变性与驻留池
https://www.cnblogs.com/pandefu/p/17771369.html
本文主要讨论了字符串的性能优化,特别是StringBuilder和字符串驻留池的使用。StringBuilder由于其可变性,可以在原地修改字符串,避免了频繁的内存分配和回收,提高了性能。而字符串驻留池则是一种内存管理机制,它存储了字符串字面值的唯一实例,减少了内存使用并提高了性能。字符串的不可变性使得多个字符串字面值可以共享相同的内存实例,节省内存。此外,字符串驻留池的存在还带来了内存节省、性能提升、可靠性和代码简化等优点。
如何通过SK集成ChatGPT实现DotNet项目工程化?
https://www.cnblogs.com/hejiale010426/p/17771582.html
本文介绍了如何实现智能助手服务的天气插件。首先,我们需要了解SemanticKernel,它是一个SDK,将大型语言模型与传统编程语言集成在一起。然后,我们需要在项目中添加IKernel,OpenAIOptions.Model和OpenAIOptions.Key。在项目中,我们还有一个plugins文件夹,这是提供的插件目录。在BasePlugin目录下,有一个识别意图的插件。此外,config.json对应当前插件的一些参数配置,skprompt.txt则是当前插件使用的prompt。最后,我们需要注入IKernel。
[MAUI]深入了解.NET MAUI Blazor与Vue的混合开发
https://www.cnblogs.com/jevonsflash/p/17772897.html
本文介绍了如何在.NET MAUI中结合Vue进行混合开发,使得开发者可以使用熟悉的Vue语法,而无需重写现有项目。文章详细阐述了如何创建MAUI项目和Vue应用,并将Vue作为MAUI的一部分,使得在MAUI项目中可以直接使用Vue。同时,Vue的渐进性特性使得开发者可以根据需要逐步使用其框架特性。此外,文章还介绍了如何使用element-ui组件库,以及JavaScript和原生代码的交互方式。
记一次 .NET某新能源检测系统 崩溃分析
https://www.cnblogs.com/huangxincheng/p/17767410.html
本文描述了一位朋友的程序偶尔会崩溃,作者使用WinDbg工具进行分析。通过命令
!analyze -v
,作者发现崩溃点异常,且异常状态
80000004
在微软官方文档中显示为单步跟踪造成,这是作者首次遇到的情况。尽管自动化分析的信息不尽人意,但作者根据经验,查看了异常前的状态,寻找新的线索。
通过 Radius 实现Dapr 云原生应用程序开发协作
https://www.cnblogs.com/shanyou/p/17775795.html
微软Azure孵化团队推出了名为Radius的新开放应用程序平台,这是一个开源项目,支持在私有云、Microsoft Azure和Amazon Web Services上部署应用程序。该团队还推出了多个流行的开源项目,如Dapr、KEDA和Copacetic,这些都是云原生计算基金会(CNCF)项目。Dapr是一个分布式应用程序运行时,为开发现代应用程序提供了新方法,可以安装在任何可以运行Docker的计算机上。然而,基于Dapr开发的应用程序的构建、管理和运营存在挑战。为此,微软Azure孵化团队发布了Radius,该平台将应用程序置于每个开发阶段的中心,重新定义应用程序的构建、管理与理解方式。
探究 - C# .NET 代码混淆/加壳
https://www.cnblogs.com/magicMaQaQ/p/17702951.html
本文介绍了如何使用Obfuscar工具进行.NET代码混淆。首先,通过NuGet在项目中安装Obfuscar。然后,找到Obfuscar.Console.exe并将其复制到需要加密的文件夹中。最后,创建一个名为Obfuscar.xml的文件,设置相关参数,如输入路径、输出路径和是否保留公共API等。通过这种方式,可以有效地保护.NET代码,防止被轻易阅读和修改。
IL编织器 - Fody
https://www.cnblogs.com/pandefu/p/17775991.html
"Fody"是一个用于.NET程序集的可扩展工具,它可以在构建过程中操纵程序集的中间语言(IL)。Fody通过可扩展的插件模型消除了大量需要了解MSBuild和Visual Studio的API的底层代码。Fody使用Mono.Cecil和基于插件的方法在编译时修改.NET程序集的IL,不需要额外的安装步骤来构建,不需要部署运行时依赖项。此外,基于Fody库,诞生了许多插件库,如AutoProperties.Fody,PropertyChanged.Fody,InlineIL.Fody等,为用户提供了更多的功能和便利。
.NET开源简单易用、内置集成化的控制台、支持持久性存储的任务调度框架 - Hangfire
https://www.cnblogs.com/Can-daydayup/p/17766499.html
本文介绍了.NET开源任务调度框架Hangfire。Hangfire是一个简单易用的库,可以在.NET应用程序中执行后台的、延迟的和定期的任务,无需使用Windows服务或任务计划程序。它具有简单易用、可靠性强、高性能、扩展性好、持久化存储、任务监控和多种任务类型支持等特点。Hangfire可以与Redis、SQL Server、SQL Azure和MSMQ集成,提供了多种持久化存储方案。此外,Hangfire还提供了多种监控工具,可以实时查看任务的执行情况、错误信息、性能指标等。
Util应用框架Web Api开发环境搭建
https://www.cnblogs.com/xiadao521/p/17769405.html
本文主要介绍了如何使用Util应用框架开发项目,包括搭建开发环境和安装Visual Studio企业版。首先,需要安装Windows 10或以上版本的操作系统,然后下载并安装Visual Studio企业版,过程中需要联网。安装完成后,需要重启电脑。然后,打开Visual Studio,创建一个Web Api项目,以验证Visual Studio是否安装成功。在创建项目时,选择ASP.NET Core Web API项目类型,框架选择.Net 7.0。
C# 实现MD5加密
https://www.cnblogs.com/yangyongdashen-S/p/YiRenXiAn_CSharp_MD5.html
本文介绍了在C#中使用MD5进行数据加密的方法。MD5是一种hash算法,可以对任意长度的数据进行加密,生成固定长度的消息摘要,且加密结果不可逆。在C#中,可以使用MD5CryptoServiceProvider和MD5两种类型进行MD5加密,但在.NET6及以上版本中,MD5CryptoServiceProvider已过时,建议使用MD5。加密后的数据可以通过BitConverter方法或循环字节数组转成字符串的方式转换为32位数字和字母组成的字符串。此外,文件、图片等其他数据也可以转换成字节数组进行加密。完整的帮助类已上传至Gitee,可供下载使用。
再学Blazor - 扩展方法
https://www.cnblogs.com/known/p/17766595.html
本文主要介绍了Blazor组件的扩展方法实现思路。扩展方法是C#类型添加新方法的一种方式,可以对任何类型进行扩展,只需新建一个扩展类型。扩展方法需要添加扩展类和方法,都必须声明static修饰符,方法的第一个参数必须是扩展类型,并有this关键字。文章还介绍了如何扩展HTML元素和自定义组件,以及如何使用RenderTreeBuilder的原生方法。最后,文章提供了一个HTML元素扩展类的代码示例,用于扩展HTML元素。
一款简单漂亮的WPF UI - AduSkin
https://www.cnblogs.com/Can-daydayup/p/17778563.html
本文推荐了一款简单漂亮的WPF UI库——AduSkin。WPF是一个强大的桌面应用程序框架,用于构建具有丰富用户界面的Windows应用。AduSkin是一款融合多个开源框架组件的WPF UI,为个人定制的UI,可供学者参考和使用。在Nuget搜索"AduSkin"即可直接导包使用。更多项目实用功能和特性,可以前往项目开源地址查看。此外,该项目已被收录到C#/.NET/.NET Core优秀项目和框架精选中。
主题
.NET 2023 年 10 月更新 – .NET 7.0.12、.NET 6.0.23 - .NET 博客
https://devblogs.microsoft.com/dotnet/october-2023-updates/
.NET 7 和 6 的 2023 年 10 月更新已发布。
此版本包括多个错误修复和改进以及三个安全修复。
- CVE-2023-44487 – .NET 拒绝服务漏洞
- ASP.NET Core Kestrel Web 服务器中的拒绝服务漏洞允许恶意客户端引发精心设计的 HTTP/2 请求。
- Microsoft 安全通报 CVE-2023-44487:.NET 拒绝服务漏洞 · 问题 #277 · dotnet/announcements
- CVE-2023-38171 – .NET 拒绝服务漏洞
- MsQuic.dll 中的空指针拒绝服务漏洞
- CVE-2023-36435 – .NET 拒绝服务漏洞
- MsQuic.dll 中的内存泄漏拒绝服务漏洞
宣布 .NET 8 候选版本 2 - .NET 博客
https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-rc2/
.NET 8 候选版本 2 已发布。
- .NET 库包自述文件
- MSBuild+ 基于 CLI 的简单项目评估
- SDK容器发布:发布到tar.gz存档
- .NET 的张量基元简介
.NET 8 候选版本 2 中的 ASP.NET Core 更新 - .NET 博客
https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-rc-2/
关于使用 .NET 8 候选版本 2 更新 ASP.NET Core。
- 服务器和中间件
- HTTP 日志记录可扩展性
- 更新到 IdentityModel 7x
- API 编写
- 支持具有新表单绑定的表单文件
- SignalR
- 对 TypeScript 客户端的状态重新连接支持
- Blazor
- 与 Blazor Web Apps 的全球交互
- Blazor WebAssembly 模板更新
- 文件范围@rendermode Razor指令
- 增强的导航和表单处理改进
- 当交互式服务器组件消失时连接断开
- 改进的表单模型绑定
- 将 HttpContext 作为级联参数访问
- Blazor Web 应用程序中的持久组件
- 将密钥服务注入组件
- 支持对话框取消和关闭事件
- 错误页面支持
- 身份
- Blazor 身份用户界面
- 单页应用程序(SPA)
- 从命令行运行新的 SPA 模板
EF Core 8 候选版本 2:EF8 中的较小功能 - .NET 博客
https://devblogs.microsoft.com/dotnet/announcing-ef8-rc2/
介绍 Entity Framework Core 8 候选版 2 的发布以及 EF Core 8 中的新功能。
- 哨兵值和数据库默认值
- 更好的执行更新和执行删除
- 更好地使用“IN”查询
- SQL Azure/SQL Server 中的数字行版本
- 消除括号
在 .NET 8 候选版本 2 中宣布 .NET MAUI:更高质量 - .NET 博客
https://devblogs.microsoft.com/dotnet/announcing-dotnet-maui-in-dotnet-8-rc-2/
关于 .NET 8 候选版本 2 中的 .NET MAUI 更新。
除了介绍此版本中的质量改进之外,文章还提到了针对 .NET 7 的 .NET MAUI 服务版本 8 的发布以及与 Xcode 15 和 Android 14 的兼容性。
.NET Framework 2023 年 10 月安全和质量汇总更新 - .NET 博客
.NET Framework 的 2023 年 10 月安全修复程序和累积更新已发布。
此版本不包含任何新的安全修复,但包含一些错误修复。
VMMap v3.4 - Microsoft 社区中心
https://techcommunity.microsoft.com/t5/sysinternals-blog/vmmap-v3-4/ba-p/3958601VMMap
v3.4 已发布。
VMMap是Windows上的内存分析工具。此版本还支持 .NET 6 到 8。
https://x.com/sysinternals/status/1714731087119675416?s=12
ASP.NET Core 8 中的性能改进 - .NET 博客
https://devblogs.microsoft.com/dotnet/performance-improvements-in-aspnet-core-8/
关于 .NET 8 候选发布版 2 中的 ASP.NET Core 性能改进。
- 服务器
- Kestrel
- HTTP.sys
- 原生AOT
- 请求委托生成器
- 运行时 API
- SearchValues
- Span
- FrozenDictionary
- 其他
- 正则表达式
- 分析仪
- 字符串生成器
Visual Studio 2022 17.8 预览版 3 现已推出!- Visual Studio 博客
https://devblogs.microsoft.com/visualstudio/visual-studio-2022-17-8-preview-3-is-here/
Visual Studio 2022 17.8 预览版 3 已发布。
- 生产力
- Visual Studio更新通知
- C++ 游戏开发
- 虚幻引擎宏说明符建议
- 结构化诊断
- 将 SQL Server Data Tools 从 MDS 3.0 升级到 MDS 5.0
Visual Studio 中的 F# 代码修复大修 - .NET 博客
https://devblogs.microsoft.com/dotnet/overhauled-fsharp-code-fixes-in-visual-studio/
在 Visual Studio 中修复 F# 代码的改进。
.NET Conf 2023 议程
https://www.dotnetconf.net/agenda
.NET Conf 2023 的时间表/会议列表已发布。
https://x.com/dave_dotnet/status/1711432833594532083?s=12
发布版本 v2.58.0 · grpc/grpc-dotnet
https://github.com/grpc/grpc-dotnet/releases/tag/v2.58.0
gRPC (grpc-dotnet) v2.58.0 已发布。
此版本包括多个错误修复、调试改进以及从某些项目中删除 .NET Standard 1.5。
文章、幻灯片等
使用 .NET MAUI 和 Evergine 构建 3D 应用程序和内容 - .NET 博客
https://devblogs.microsoft.com/dotnet/dotnet-maui-3d-app-with-evergine/
介绍如何组合 .NET MAUI 和 Evergine 以在 .NET MAUI 应用程序之上托管 3D。
在 .NET 项目中使用 Stryker 进行突变测试
https://medium.com/@hamed.shirbandi/mutation-testing-with-stryker-in-net-projects-ff1f05ddce8f
了解如何使用 Stryker 在 .NET 项目中执行突变测试。
使用 Husky.NET 进行预提交挂钩 - 在 Git 提交之前构建、格式化和测试您的 .NET 应用程序
https://www.code4it.dev/blog/husky-dotnet-precommit-hooks/
介绍如何使用 Git 提交挂钩通过 Husky.NET 进行构建、测试、格式化等。
混合 C# 和 Rust - 互操作
https://fractalfir.github.io/generated_html/rustc_codegen_clr_v0_0_3_2.html
有关为 Rust 开发针对 .NET 的后端的系列。本文涉及实现和考虑如何从 Rust 调用 .NET。
C# 中双精度数的内存对齐
https://minidump.net/memory-alignment-of-doubles-in-c-1d13e3ce741
深入研究 .NET 中的双精度(64 位浮点)数组内存对齐。
如何在 EF Core 中将 UTC 保存的日期和时间转换并显示为 JST
https://zenn.dev/hat_kotap/articles/785960b233e5f0
如何使用 Entity Framework Core 和 PostgreSQL 在数据库中存储 UTC 日期和时间,并在显示时将其显示为 JST。
Rider 2023.3 EAP 3:全局使用支持的改进等等。| .NET 工具博客
https://blog.jetbrains.com/dotnet/2023/10/17/rider-2023-3-eap-3/
Rider 2023.3 EAP 3 已发布。
此版本包括改进的对全局使用的支持、对无根容器的支持、改进的 HTTP 客户端中的 JSON 请求正文完成、URL 路径引用的自动代码完成、AI 助手插件的更新等等。
.NET 8 中 Docker 映像的更新:探索 .NET 8 预览版 - 第 10 部分
https://andrewlock.net/exploring-the-dotnet-8-preview-updates-to-docker-images-in-dotnet-8/
使用 .NET 8 更新的 Docker 映像的详细说明。
RazorSlices - 使用 ASP.NET Core 最小 API 的 Razor 视图
https://khalidabuhakmeh.com/razorslices-razor-views-with-aspnet-core-minimal-apis
引入 RazorSlices,它允许您通过最少的 API 使用 Razor,而无需依赖 ASP.NET Core MVC 或 Razor Pages。
更好地查看 Visual Studio 活动日志
https://dev.to/karenpayneoregon/view-visual-studio-activity-logs-better-2id8
如何检索和查看 Visual Studio 本身的活动日志。
使用 Scrutor 改进 ASP.NET Core 依赖注入
https://dev.to/milanjovanovictech/improving-aspnet-core-dependency-injection-with-scrutor-48e3
如何使用 Scrutor 来处理 ASP.NET Core 的依赖注入,它扩展了 Microsoft.Extensions.DependencyInjection。
.NET Conf 2023 上的 Visual Studio 创新:节省时间 - Visual Studio 博客
请注意,.NET Conf 2023 上将介绍 Visual Studio。
C# 13 的计划
https://ufcpp.net/blog/2023/10/triage2023/
关于 C# 13 的最近分类。
将 Blazor 组件渲染为字符串:探索 .NET 8 预览 - 第 9 部分
https://andrewlock.net/exploring-the-dotnet-8-preview-rendering-blazor-components-to-a-string/
了解如何使用 .NET 8 中添加的 HtmlRenderer 将 Blazor 组件呈现为字符串。
更新到预览版 3 (VS 2022 17.8) 后,MSFT_VSInstance 类从 WMI 目录中删除
关于从 Visual Studio 2022 17.8 Preview 3 中的 WMI 目录中删除 MSFT_VSInstance。要继续使用它,您需要指定一个命名空间。
https://x.com/skitoy4321/status/1714857655154651192?s=12
Wrathmark:有趣的计算工作负载(第 1 部分)
https://ricomariani.medium.com/wrathmark-an-interesting-compute-workload-part-1-47d61e0bea43
按版本比较本机和 .NET JIT 性能。
库、存储库、工具等。
microsoft/vs-dapr:在 Visual Studio 中查看、管理和诊断 Dapr 服务。
https://github.com/microsoft/vs-dapr
在 Visual Studio 中支持(查看、管理和诊断)Dapr 的扩展。
由于它正在开发中,目前尚未从 Visual Studio Marketplace 分发。
Cysharp/Utf8StringInterpolation:ZString 的后继者;基于 UTF8 的零分配高性能字符串插值和 StringBuilder。
https://github.com/Cysharp/Utf8StringInterpolation
一个用于高效生成 UTF-8 字符串的库,主要使用字符串完成表达式。
https://x.com/neuuecc/status/1711911200274153689?s=12
网站、文档等
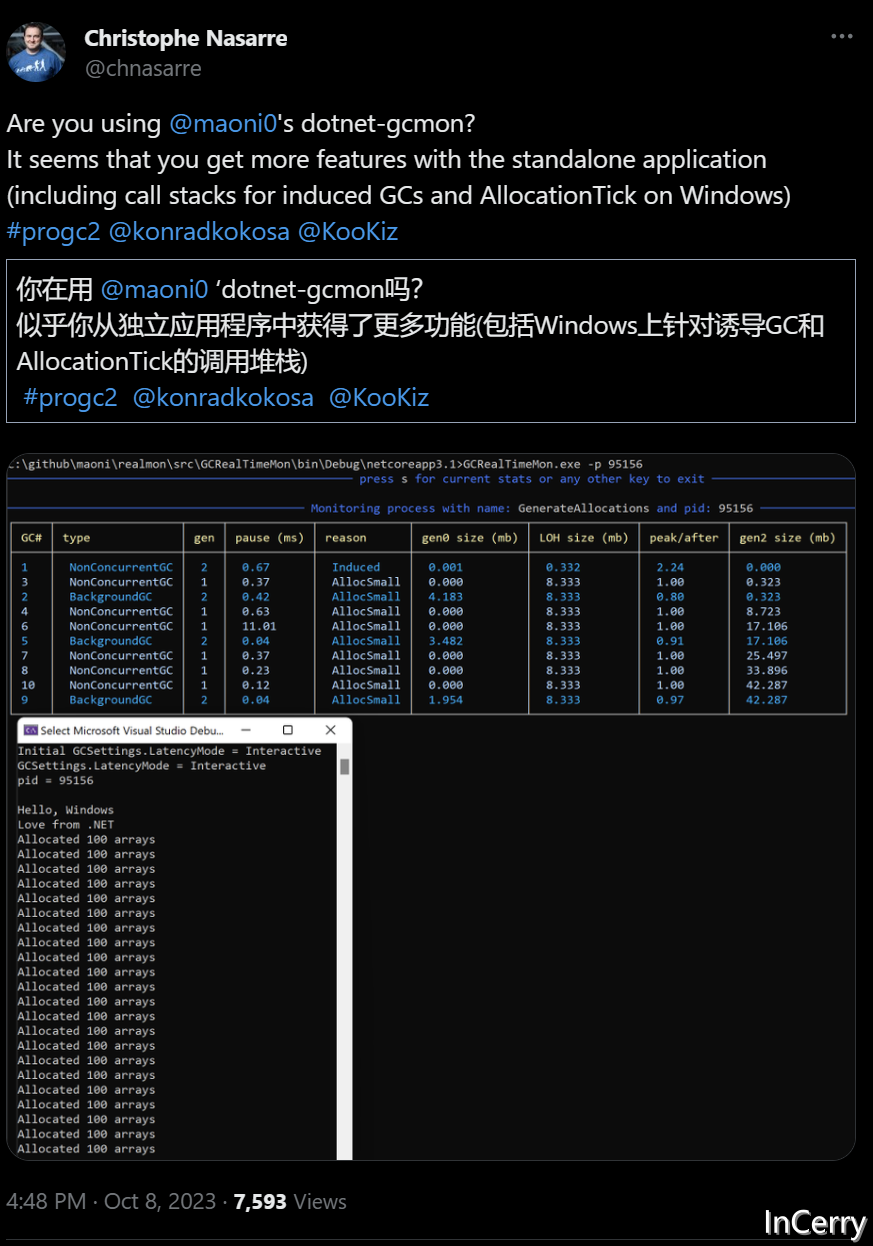
推文
https://x.com/chnasarre/status/1710940207950733496?s=12
版权声明
- 国内板块由 InCerry 进行整理 :
https://github.com/InCerryGit/WeekRef.NET - 其余内容来自 Myuki WeekRef,由InCerry翻译(已获得授权) :
https://github.com/mayuki/WeekRef.NET
由于笔者没有那么多时间对国内的一些文章进行整理,欢迎大家为《.NET周刊-国内文章》板块进行贡献,需要推广自己的文章或者框架、开源项目可以下方的项目地址提交Issue或者在我的微信公众号私信。
格式如下:
- 10~50字左右的标题
- 对应文章或项目网址访问链接
- 200字以内的简介,如果太长会影响阅读体验
https://github.com/InCerryGit/.NET-Weekly
.NET性能优化交流群
相信大家在开发中经常会遇到一些性能问题,苦于没有有效的工具去发现性能瓶颈,或者是发现瓶颈以后不知道该如何优化。之前一直有读者朋友询问有没有技术交流群,但是由于各种原因一直都没创建,现在很高兴的在这里宣布,我创建了一个专门交流.NET性能优化经验的群组,主题包括但不限于:
- 如何找到.NET性能瓶颈,如使用APM、dotnet tools等工具
- .NET框架底层原理的实现,如垃圾回收器、JIT等等
- 如何编写高性能的.NET代码,哪些地方存在性能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET性能问题和宝贵的性能分析优化经验。
目前一群已满,现在开放二群。
如果提示已经达到200人,可以加我微信,我拉你进群:
ls1075
另外也创建了
QQ群
,群号: 687779078,欢迎大家加入。
抽奖送书活动预热!!!
感谢大家对我公众号的支持与陪伴!为庆祝公众号一周年,抽奖送出一些书籍,请大家关注公众号后续推文!